Предисловие

Serverless подход в разработке уже давно пользуется большой популярностью. По разным опросам, разработчики отмечают следующие преимущества в serverless технологиях:
гибкое масштабирование;
быстрота разработки;
уменьшение времени или затрат на администрирование приложений;
быстрые релизы.
Преимущества выглядят заманчивыми и многообещающими. Так ли все это? Пришло время познакомиться с serverless технологиями. Буду разбираться с новым подходом через призму опыта создания “классических” приложений. Это значит, что обязательно должны быть тесты, возможность запускать локально, возможность дебажить, несколько окружений, логи, метрики и т.д. Нет смысла знакомиться на уровне hello world приложений, которые красиво выглядят на экране. Я возьму задачу с похожими на реальность сценариями. Конечно, в сети очень много разных статей и инструкций, но нет таких, после которых ты сможешь сделать как надо, подумав обо всех проблемах заранее, а не после релиза. Поехали.
Начнем с задачи. Буду делать REST API для небольшого баг трекера. У нас есть проекты, есть люди, которые работают на этих проектах. Есть карточки - таски, которые назначаются на людей. У карточек, само собой, есть статус выполнения. У каждого проекта есть свой репозиторий на гитхабе. Выглядит это примерно так:

Я буду реализовывать следующие методы:
получить проект по идентификатору с информацией о людях, которые на нем работают, а также информацией об открытых PR;
обновить информацию о проекте;
добавить человека на проект;
убрать человека с проекта.
Конечно, задача не боевая, рисковать нервами и чутким сном не хочу, но важно, чтобы она была приближенной к реальности. Я не собираюсь учиться кодировать, не буду весь код показывать, я хочу попробовать serverless подход и буду концентрироваться на этом. А поэтому неважно, какой код у меня используется для выполнения запроса к БД, важно, где и с какими параметрами этот код вызывается . Практически в любом проекте есть хранилище. Я буду использовать MySQL. У меня будет своя интеграция с 3rd party service через REST API в методе про получение информации о проекте.
Какого провайдера выбрать? В последнее время их становится все больше, даже у оракла появляется свой serverless. Начну с флагмана, с Amazon. Хочется верить, что он там максимально стабильный, понятный, обкатанный, да и искать ответы на вопросы будет быстрее и проще.
План будет примерно такой:
Разбираемся с лямбда функциями, делаем первую простую лямбда функцию.
Разворачиваем БД.
Интегрируем лямбда функцию с БД.
Создаем REST API и подключаем ранее созданные функции.
Выходим в “прод”, нюансы о которых не надо забывать.
Глава 1. Первые шаги. Первая лямбда
Для начала мне надо подготовить рабочее место:
любимая среда разработки (я буду пользоваться VSCode);
система контейнеризации Docker;
AWS аккаунт с полными правами (в дальнейшем затронем этот вопрос детальнее).
С чего начать? Начнем с кубиков, из которых и состоит классическое serverless приложение - у Amazon это сервис AWS Lambda. Лямбда-функции - это функция, которая обрабатывает события из разных источников, начиная от очередей сообщений и заканчивая событиями от S3 об обновлении/добавлении файла. Лямбда принимает на вход json объект, представляющий это событие, делает с ним, что требуется, и возвращает ответ.
Выбираем язык программирования
И вот тут у нас возникает первый серьезный вопрос: на каком языке писать? Казалось бы, можно писать на чем угодно, но все не так просто. И для того, чтобы понять, в чем проблема, придется немного погрузиться в документацию и рассмотреть вопрос, как лямбда работает.
Жизненный цикл лямбды состоит из трех фаз:
Init
Invoke
Shutdown
Как следует из названия, в фазе Init происходит создание окружения, среды выполнения, где код лямбды будет работать, происходит скачивание кода функции, запускаются конструкторы, код инициализации. Эта фаза “поднимает” лямбду в облаке. Происходит это один раз за все время жизни экземпляра лямбда функции.
После фазы init наступает фаза Invoke. В фазе Invoke происходит непосредственный вызов кода обработчика лямбды функции. В отличие от фазы Init, которая происходит один раз, эта фаза может повторяться много раз; зависит от того, сколько событий будет доступно для обработки. Как только обработчик вернул результат, Amazon “замораживает” окружение, пока не появится новое событие для обработки. При появлении нового события, Amazon “размораживает” окружение. Если в процессе работы фазы происходит критическая ошибка или время выполнения выходит за пределы, то Amazon пытается пересоздать среду выполнения.
Ну и фаза Shutdown “убивает” лямбду и освобождает все ее ресурсы. Происходит это по прошествии какого-то времени, когда никакие события не приходили, и моя функция ничем не занималась. В документации не описано “время простоя”, но оно есть.
Ну и при чем тут язык программирования? А при том, что он напрямую влияет на фазу Init. У нас есть лямбда, нет никаких созданных экземпляров этой лямбды, не приходят события. Прилетает первое событие. В облаке некому обработать это событие (также это бывает, когда все экземпляры заняты обработкой других событий). Провайдер начинает создавать для моего события экземпляр лямбды. “Срабатывает” фаза init. В этот момент я просто жду, когда появится рабочее окружение для лямбды. После того, как фаза отработала, на следующей фазе Invoke лямбда делает полезную (для клиента) работу. Эта ситуация называется cold start — когда нет доступных для обработки экземпляров функций и тратится время на поднятие этих функций (примерно как мы тратим время на прогрев двигателя автомобиля зимой в -30). Чем быстрее пройдет фаза Init, тем быстрее начнется обработка события, тем быстрее клиент получит ответ, тем меньше будет время ответа. В силу своей природы cold start у разных языков программирования разный. У интерпретируемых языков (python, nodejs) он существенно меньше, чем у компилируемых (java, c#). Но у компилируемых есть преимущество в лучшем использовании ресурсов, у таких лямбд “КПД” выше, если надо использовать несколько ядер, больше памяти. Поэтому, если нужно минимальное время cold start, берем что-то из интерпретируемых языков; если нужно по максимуму выжимать ресурсы из окружения, то лучше взять компилируемые.
Я провел небольшой тест, создал лямбды с hello world обработчиком на разных языках программирования. Ниже представлены длительности init фазы в зависимости от языка:
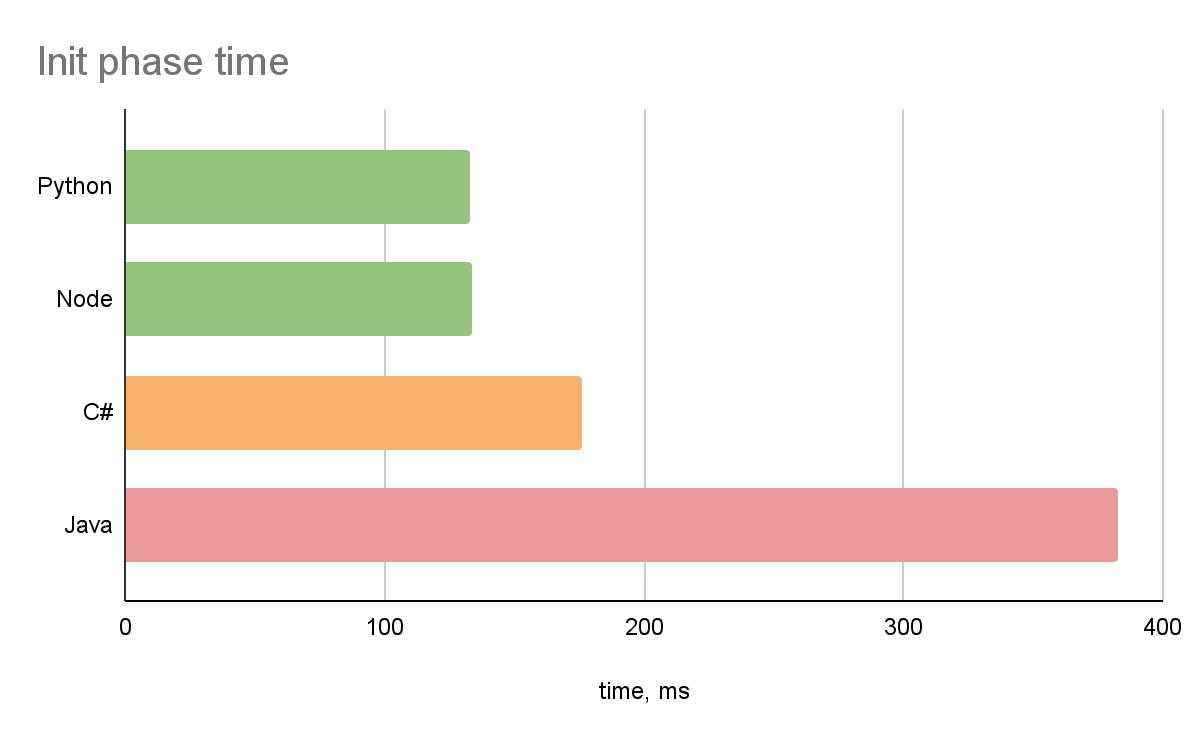
Основываясь на этих данных и на своих знаниях ЯПов, я остановил свой выбор на NodeJS.
Структура проекта
Начну с лямбды для получения информации о проекте. Код в принципе можно писать прямо в редакторе в Amazon Console. Достаточно создать hello world лямбду, дальше можно редактировать код этой лямбда функции. Очевидно, что этот вариант в любом не hello-world проекте обречен, не получится построить нормальный CI/CD, да и вообще это будет неудобно. Можно создавать лямбду с нуля, а можно взять за основу готовый шаблон. Поможет мне в этом SAM framework, расширение AWS Cloudformation (далее CF) для Serverless-приложений. Он может создать мне hello-world шаблон для лямбда функции, поможет с деплоем в облако и не только.
Я воспользуюсь hello-world шаблоном. Следующая консольная команда создаст hello world проект с лямбда функцией с использованием Node JS, а созданная лямбда функция при сборке будет упаковываться в zip архив.
serverless-bugtracker> sam init --package-type Zip --runtime nodejs14.x --app-template hello-world --name serverless-bugtrackerСтруктура первой лямбда функции получается такой:
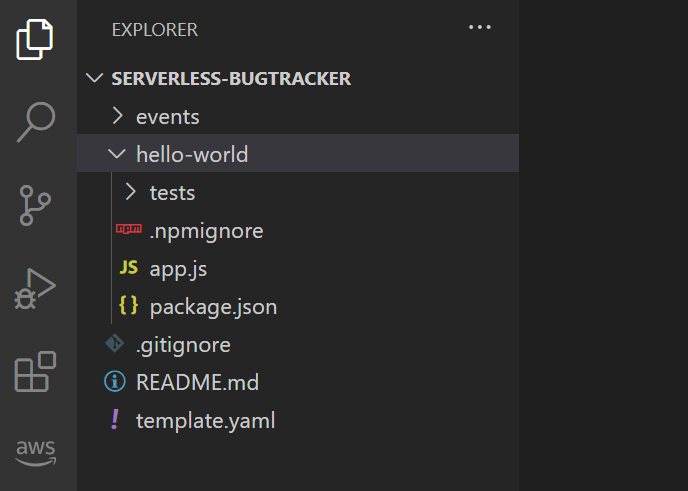
template.yaml — это конфиг SAM framework, описывающий компоненты, которые задействованы в моем проекте. SAM шаблон совместим с CF шаблоном. Он добавляет способы быстро и просто создать специфичные для serverless приложений типы ресурсов (лямбды, api gateway, и т.д.). CF развернет из этого конфига ресурсы, которые в нем указаны. Если в template.yaml будет описано 10 лямбда-функций, RDS, SQS, то он это все создаст. Но здесь надо соблюдать грани разумного, ведь даже в serverless мире можно создать serverless-монолит, когда десятки разных ресурсов, которые могут быть не связаны между собой, находятся в одном конфиге. Такой подход делает поддержку приложения сложнее.
Приложение с лямбда функциями очень похоже на приложение с микросервисной архитектурой. Каждую лямбду можно рассматривать как отдельный микросервис. Поэтому для максимальной изоляции и независимости я буду размещать код функций в различных папках, со своими отдельными независимыми package.json. Оставлю корневой package.json для запуска тестов.
Финальная структура проекта:
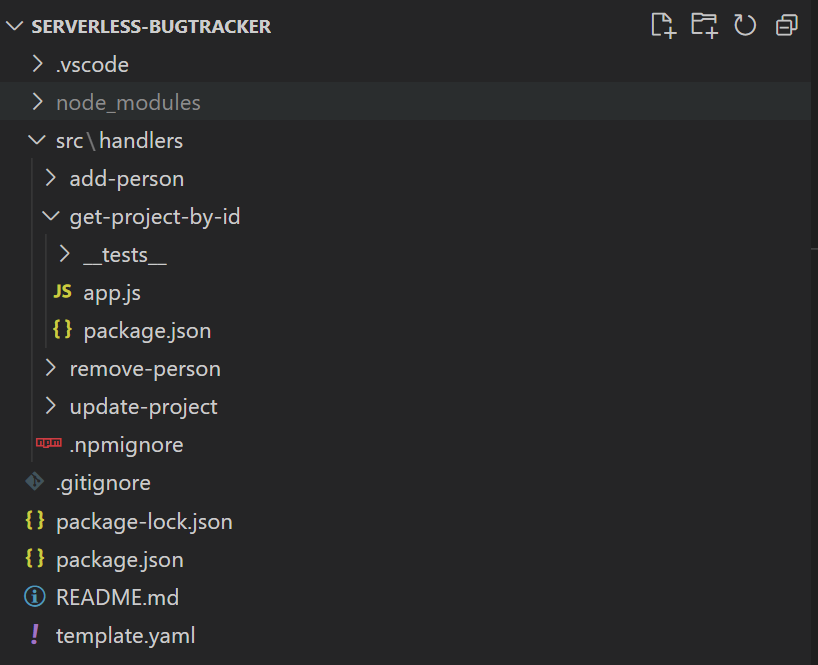
Сделаю еще одну остановку и чуть подробнее посмотрю на template.yaml. Из каких частей он состоит, для чего они нужны?
SAM шаблон
Начну с самой неинтересной части, которая содержит информацию о версии формата шаблон CF и о том, что это SAM шаблон:
AWSTemplateFormatVersion: '2010-09-09'
Transform: AWS::Serverless-2016-10-31Есть отдельный блок для текстового описания и глобальных настроек:
Description: >
serverless-bugtracker
My bug tracker.Uses Amazon serverless stack
Globals:
Function:
Timeout: 3Один из самых важных блоков — блок описания ресурсов, в нем описываются все ресурсы для развертывания: лямбды, базы данных и прочие сервисы. Например, ниже приведен пример описания лямбда функции:
Resources:
GetProjectByIdFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: src/handlers/get-project-by-id
Handler: app.lambdaHandler
Runtime: nodejs14.x
Events:
HelloWorld:
Type: Api
Properties:
Path: /hello
Method: getЛюбой ресурс в шаблоне обладает уникальным логическим именем. Используя это имя, можно обращаться к свойствам этого ресурса. В моем примере логическое имя функции GetProjectByIdFunction. Переменная Runtime говорит о том, какую среду надо использовать для запуска кода. CodeUri и Handler определяют путь до файла с кодом и имя функции обработчика. Блок Events описывает виды событий, обрабатываемые функцией.
И последний блок, о котором мне надо сейчас знать — это блок Outputs, своего рода результат выполнения развертывания. Имеет смысл в этот раздел добавлять значения, которые могут потребоваться для дальнейшей работы или для интеграций, например, урлы созданных апишек, хостнейм поднятой БД и так далее. Amazon показывает эти значения в консоли после развертывания. Значения отображаются, как они есть, поэтому ни в коем случае не надо показывать в этом блоке пароли или секретные ключи.
Outputs:
GetProjectByIdFunctionApi:
Description: "ApiGateway endpoint URL for Prod stage for GetProjectByIdFunction"
Value: !Sub "https://${ServerlessRestApi}.execute-api.${AWS::Region}.amazonaws.com/Prod/hello/"
GetProjectByIdFunction:
Description: "GetProjectByIdFunction Lambda Function ARN"
Value: !GetAtt GetProjectByIdFunction.Arn
GetProjectByIdFunctionIamRole:
Description: "Implicit IAM Role created for GetProjectByIdFunction function"
Value: !GetAtt GetProjectByIdFunctionRole.ArnКак видно из сниппетов, SAM также создает API, запросы которого обрабатываются лямбда функциями. В Outputs, помимо идентификаторов лямбда функции (все ресурсы в амазоне обладают уникальных идентификатором ARN), возвращается урл для взаимодействия с этим API. Пока сконцентрируюсь на лямбда функциях, к построению API вернусь позже.
Запуск лямбда функции
Напишу первую лямбда функцию, которая вернет фиксированные данные по идентификатору проекта:
// ./src/handlers/get-project-by-id/app.js
exports.lambdaHandler = async (event, context) => {
return {
id: 123,
title: 'My first project',
description: 'First project to work with serverless. No cards. No members.',
cards: [],
members: []
};
};AWS поддерживает несколько подходов в написании обработчиков на nodejs:
использование async/await конструкций. В этом случае обработчик может вернуть готовое значение или promise;
использование callback функций. В этом случае в обработчик добавляется третий аргумент callback, используя который, можно возвращать ответ;
представление обработчика в виде ES модуля (совсем недавно nodejs среда стала поддерживать эту возможность).
Далее я буду использовать первый подход, так как для организации кода он более удобный и привычный для меня.
Вроде все готово для первого запуска. Я хочу иметь возможность запускать лямбда функции локально в режиме отладки, так я быстрее смогу искать, исправлять ошибки и проверить, что все работает, как надо. В SAM есть возможность запускать лямбды локально. Для локального запуска используется специальный докер образ от Amazon. Созданный таким образом контейнер мало отличается от среды выполнения в облаке.
Запустить код локально можно несколькими способами.
Сборка и запуск при помощи SAM
Прежде чем запустить код локально в консоли, его необходимо собрать.
Сборка приложения происходит при помощи команды:
serverless-bugtracker> sam buildЭта команда подготавливает артефакты для последующего развертывания или запуска. Результат сборки для каждой лямбда функции — это папка, в которой находятся все файлы из директории, прописанной в CodeUri в шаблоне. Если CodeUri отсутствует, то копируются все файлы из корневой директории. Также в этой папке устанавливаются все зависимости из package.json, который расположен в папке прописанной в CodeUri.
При выбранной ранее структуре проекта получается, что все артефакты будут независимыми и не будут содержать код, относящийся к другим лямбда функциям.
Другой подход к структуре проекта
Встречаются и другие подходы к структуре проекта. Даже в примерах от Amazon можно встретить вариант, когда файлы всех функций находятся в одной папке с одним package.json, CodeUri параметр тоже указывает на одну и ту же директорию (либо вообще отсутствует). Пример проекта с несколькими функциями от Amazon:
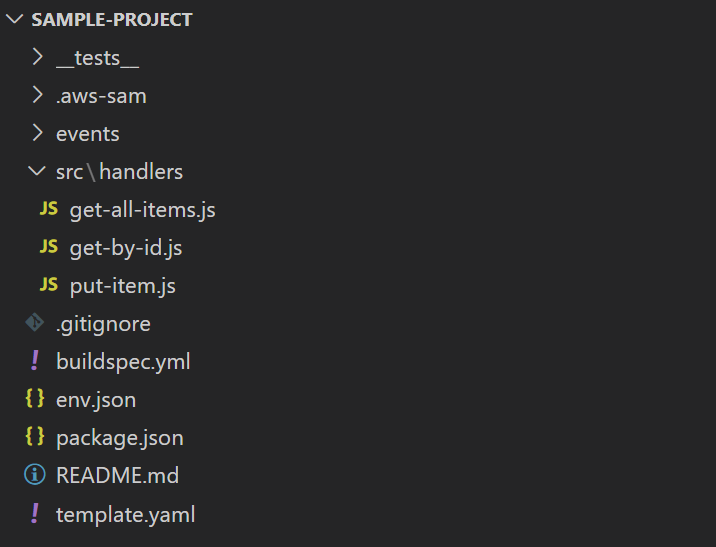
Объявление функции в SAM шаблоне:
Resources:
getAllItemsFunction:
Type: AWS::Serverless::Function
Properties:
Handler: src/handlers/get-all-items.getAllItemsHandler
Runtime: nodejs14.x
...
getByIdFunction:
Type: AWS::Serverless::Function
Properties:
Handler: src/handlers/get-by-id.getByIdHandler
Runtime: nodejs14.x
...
putItemFunction:
Type: AWS::Serverless::Function
Properties:
Handler: src/handlers/put-item.putItemHandler
Runtime: nodejs14.x
...При таком подходе артефакты для разных функции будут идентичными. Например, первая лямбда работает с БД, а вторая работает с S3. В артефакте первой и второй лямбды будут обе зависимости. При таком подходе не получается полной изоляции, к тому же одни и те же зависимости повторяются по многу раз.
У команды sam build есть парочка полезных ключей. Ключ -p позволяет вести сборку параллельно. По умолчанию все ресурсы собираются последовательно. Ключ -c позволяет кешировать сборку. Если не происходило изменений в файлах, то в качестве артефакта будет использован закешированный артефакт. Если используется структура проекта с общей папкой для всех функций, то ключ -c работать не будет, SAM каждый раз будет пересобирать все заданные в шаблоне функции, поскольку всегда будет видеть изменения. Использование отдельных папок позволяет SAM четко определять изменения и собирать только измененные части приложения. В целом, эти ключи позволяют ускорить сборку и не делать лишнюю работу.
По умолчанию сборка происходит в папку ./.aws-sam/build. Помимо артефактов функций, в ./.aws-sam/build есть еще template.yaml. Этот файл похож на мой файл из корня проекта, только все функции в нем настроены на сборочную директорию ./.aws-sam/build.
После выполнения команды сборки:
serverless-bugtracker> sam build -c -pВ консоли можно увидеть подсказки от SAM по дальнейшим действиям:
Build Succeeded
Built Artifacts : .aws-sam\build
Built Template : .aws-sam\build\template.yaml
Commands you can use next
=========================
[*] Invoke Function: sam local invoke
[*] Deploy: sam deploy --guidedКак видно из этой подсказки, для локального запуска функции необходимо использовать команду local invoke. Для запуска необходимо указать имя функции (логическое имя из шаблона). Опционально можно указать событие, которые должно быть обработано функцией. Для передачи события используется ключ -e. Если его не указать, то событие будет пустым. Можно указывать путь до файла с json объектом, представляющим это событие, или указать -, чтобы событие считывалось с stdin.
serverless-bugtracker> echo {"message": "Hey, are you there?" } | sam local invoke GetProjectByIdFunction --event -Первый запуск занимает обычно много времени, потому что скачивается докер образ. По окончанию работы в консоли можно увидеть результат выполнения
START RequestId: afebe87a-84a8-4b69-a430-08ec7f06828b Version: $LATEST
END RequestId: afebe87a-84a8-4b69-a430-08ec7f06828b
REPORT RequestId: afebe87a-84a8-4b69-a430-08ec7f06828b Init Duration: 0.29 ms Duration: 98.90 ms Billed Duration: 100 ms Memory Size: 128 MB Max Memory Used: 128 MB
{"id":123,"title":"My first project","description":"First project to work with serverless. No cards. No members.","cards":[],"members":[]}Запуск при помощи VSCode
Запускать локально функцию можно прямо из VSCode. Для этого мне потребуется плагин для VSCode AWS Toolkit. Этот плагин позволит быстрее деплоить из любимой среды разработки, ставить точки прерывания и инспектировать свой код. После установки необходимо его настроить — добавить креды аккаунта, чтобы плагин имел доступ к облаку.
После установки плагина, над функцией появляется команда создания конфигурации запуска:

Плагин предлагает несколько режимов:
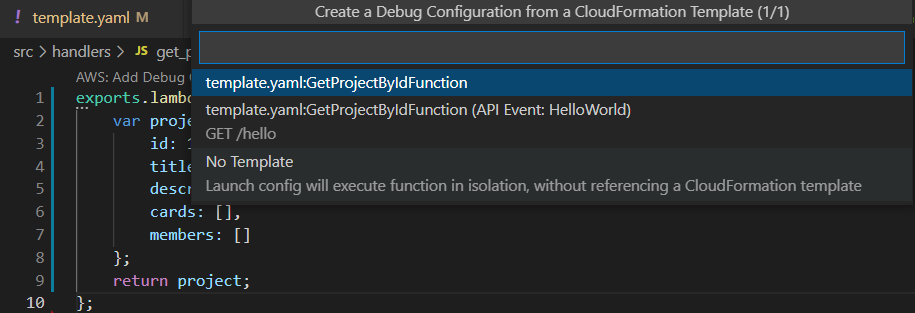
Первые две опции похожи, обе используют SAM шаблон, отличие только в типе события, с которым вызывается функция. В первом случае это может быть произвольное событие, во втором случае — это http запрос. VSCode создаст файл .vscode/launch.json, в котором будет настройка локального запуска лямбда функции. Я буду запускать лямбду первым способом, к работе с API вернусь в последующих статьях. Получится такой конфиг запуска в VSCode:
// .vscode/launch.json
{
"configurations": [
{
"type": "aws-sam",
"request": "direct-invoke",
"name": "serverless-bugtracker:GetProjectByIdFunction",
"invokeTarget": {
"target": "template",
"templatePath": "${workspaceFolder}/template.yaml",
"logicalId": "GetProjectByIdFunction"
},
"lambda": {
"payload": {
"json": {
"id": 123
}
},
"environmentVariables": {}
}
}
]
}Третий вариант просто запускает код из директории, в этом случае игнорируется код в SAM шаблоне. Для работы третьего варианта потребуется установить компилятор typescript. Конфигурация этого запуска:
{
"type": "aws-sam",
"request": "direct-invoke",
"name": "get-project-by-id:app.lambdaHandler (nodejs14.x)",
"invokeTarget": {
"target": "code",
"projectRoot": "${workspaceFolder}/src/handlers/get-project-by-id",
"lambdaHandler": "app.lambdaHandler"
},
"lambda": {
"runtime": "nodejs14.x",
"payload": {
"json": {
"id": 123
}
},
"environmentVariables": {}
}
},В секции payload можно указать json объект — событие, которое будет обработано функцией. Результат запуска любого из вариантов один и тот же — приложение запускается локально в режиме отладки.
Плагин использует те же команды sam build и sam local invoke, только с другой сборочной директорией.
Развертывание в облако
Теперь я попробую сделать первый деплой в облако. Как и с локальным запуском, это можно сделать двумя способами. Первый способ — использовать консоль, второй — использовать плагин. Проверю оба варианта.
Развертывание при помощи консольных команд
Попробуем сделать деплой, вооружившись консолью и SAM.
Прежде чем начать разворачивать приложение, необходимо его собрать. Команду я описал выше.
Непосредственно для развертывания мне потребуется команда sam deploy. Команда sam deploy архивирует и копирует собранные артефакты в S3 бакет и разворачивает приложения в облаке. Все собранные ресурсы создаются внутри стека. CF стек (далее просто стек) это набор ресурсов в облаке, которые были развернуты при помощи CF шаблона. Каждый стек имеет уникальное для аккаунта имя. Первый раз лучше запустить команду с ключом --guided. Тогда запустится интерактивный режим, где потребуется ввести имя создаваемого стека, регион, имя S3 бакета для хранения кода и прочее. Но самое интересное в этом режиме то, что все выбранные опции можно сохранить в отдельный файл с определенным профилем (по умолчанию файл samconfig.toml, имя профиля по умолчанию default). Тогда в следующий раз не придется указывать никаких параметров, кроме имени профиля. Я сохранил все под профилем chapter1:
version = 0.1
[chapter1]
[chapter1.deploy]
[chapter1.deploy.parameters]
stack_name = "serverless-bugtracker-ch1"
s3_bucket = "serverless-bugtracker-sam"
s3_prefix = "serverless-bugtracker-ch1"
region = "us-east-1"
confirm_changeset = true
capabilities = "CAPABILITY_IAM"В следующий раз для развертывания достаточно просто указать имя профиля:
serverless-bugtracker> sam deploy --config-env=chapter1Развертывание при помощи плагина
При нажатии правой кнопкой мыши на template.yaml файл в контекстном меню появится новый пункт ”Deploy SAM Application”.
Плагин спросит:
какой template файл развернуть (у меня он только один):

aws регион:
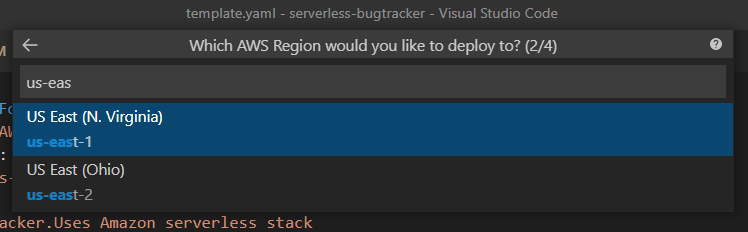
s3 bucket, который SAM будет использовать. Можно создать новый:

имя CF стека:

После прохождения всех шагов, AWS Toolkit запустит sam build, а потом sam deploy. Единственное отличие, что директория для сборки отличается от ./.aws-sam
К сожалению, плагин не умеет запоминать выбор значений параметров, поэтому каждый раз требуется вводить одни и те же данные. В этом плане запуск через консоль удобнее.
В обоих случаях в конце в консоле я увидел заветную строчку Successfully deployed SAM Application to CloudFormation Stack: serverless-bugtracker-ch1. И вот моя лямбда крутится в облаке. Amazon сам придумал имя моей функции:

В SAM шаблоне у меня у функции нет никакого имени. Amazon берет имя стека, логическое имя функции в шаблоне и генерирует какую-то случайную последовательность символов. Избавиться от этого можно, если использовать свойство FunctionName в SAM шаблоне, тогда имя функции будет то, которое указать в этом поле.
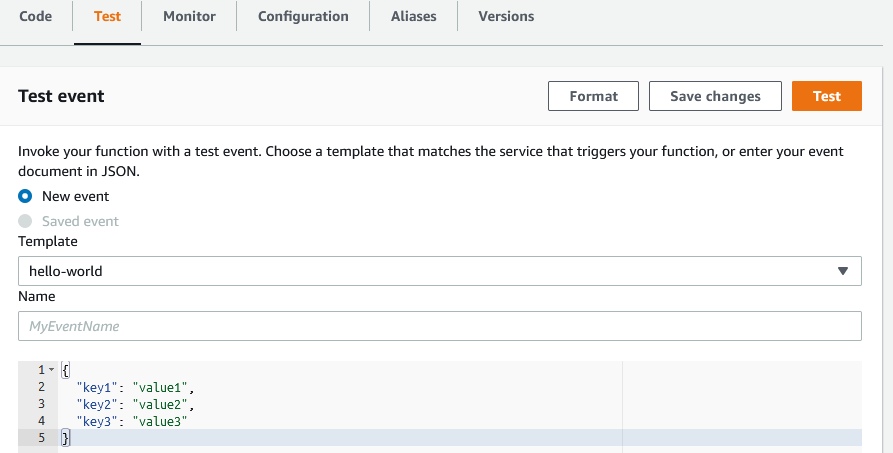
Функцию можно протестировать, используя AWS Console. Если открыть lambda функцию, у нее будет специальная вкладка test. Тут я могу послать любой json в качестве события (похоже на payload json, который я использовал в локальном запуске):
Подведение итогов
Подведем итог:
Сделал каркас приложения. Используется подход, при котором лямбда функции независимы и располагаются в разных директориях.
Реализовал одну лямбда функцию. Она пока не очень умная и умеет возвращать мой фиксированный объект.
Приложение создано при помощи SAM. Использую подход IaaC.
Для локальной разработки установлен плагин к VSCode, с помощью которого могу запустить лямбду локально в режиме отладки.
Лямбду можно развернуть из среды разработки или при помощи консольных команд.
Код можно найти по ссылке.
В следующих главах я разверну БД и научу свою функцию взаимодействовать с базой данных. Создам реализации и для других функций.
P.S. Спасибо oN0 за помощь в написании статьи.
Комментарии (28)

vlad4kr7
17.03.2022 18:30Немного из собственного опыта:
локальная разработка на яве? дебаг (только JS?) появился совсем недавно, хотя самой лямбде уже лет 5+
unit тестирование? хорошо если integration test, и как следствие:
проверка совместимости версий ваших лямбд между собой и схемой базы? - скорей всего будет проще сказать, что в вашем проекте, этого не потребуется и закрыть вопрос
ограничение по времени - если вы думаете делать что-то, что занимает время (пакетная обработка, длительные транзакции) сразу нет
усложненный доступ - надо дополнительно конфигурировать (gateway) api
каждый вызов поднимает свою JVM, и новый коннект к базе -- кеширование (в памяти) и пулы коннектов - уже не модно.

lair
17.03.2022 18:36+1У меня C#/.net (и немного питона), но отличия от Java должны быть пренебрежимы.
unit тестирование?
Я прекрасно гоняю юнит-тесты против кода, который ложится в лямбду.
каждый вызов поднимает свою JVM,
Так не должно быть. Новый инстанс поднимается только если (а) старый опустился из-за неактивности и/или (б) пришел запрос, когда старый инстанс занят, а лимит на конкурентность еще не выбран. Иными словами, если у вас есть стабильный поток запросов, у вас поднимется нужно число инстансов для его обработки, а дальше они будут теплыми пока поток не кончится.
vlad4kr7
17.03.2022 18:44я честно рад за C#/.net, но в JVM было вот так.
Я прекрасно гоняю юнит-тесты против кода, который ложится в лямбду.
а если не в VS, a в CI/CD Azure pipelines, Github Actions или в jenkins?
по другим вопросам возражений нет?
lair
17.03.2022 18:48а если не в VS, a в CI/CD Azure pipelines, Github Actions или в jenkins?
Без проблем. Они гоняются стандартным раннером
dotnet test, ничем не отличаются от любых других юнит-тестов.я честно рад за C#/.net, но в JVM было вот так.
Вы проверяли, что у вас лямбда не успела лечь по таймауту? Пока я не настроил грелку, у меня тоже так было.
по другим вопросам возражений нет?
Ну, у меня нет проблем с совместимостью версий, но это потому, что у меня хранилище выкатывается тем же деплоем, что и сама лямбда, поэтому оно заведомо консистентно. И необходимость api gateway я не считаю усложнением — он позволяет делать много полезных штук, а когда они не нужны, есть другие способы развертывания кода, кроме лямбды, и другие способы вызвать лямбду, кроме HTTP.
А с остальным согласен, да, есть такие ограничения. Больше всего дебаг бесит, но для него, в принципе, есть решения тоже.
vlad4kr7
17.03.2022 19:14Вы проверяли, что у вас лямбда не успела лечь по таймауту?
что значит лечь? лямбда, как stateless функция и состояния между вызовами не держит, это относится к пулам коннектов, и кешам - их просто не будет. Это не такой хитрый аппсервер, а просто интерфейс к скриптам.
Ну, у меня нет проблем с совместимостью версий, но это потому, что у меня хранилище выкатывается тем же деплоем, что и сама лямбда, поэтому оно заведомо консистентно.
основной особенностью лямбд заявляется независимый деплой (как в микросервисах), а если деплоить все консистентно, то чем это отличается от монолита? ну кроме возможности интеграции с S3 events и прочим vendor lock
lair
17.03.2022 19:19+1что значит лечь?
Значит "инстанс опустили".
лямбда, как stateless функция состояния между вызовами не держит, это относится к пулам коннектов, и кешам — их просто не будет.
Ммм, вы уверены? У для .net состояние между вызовами сохраняется, пока инстанс горячий. И для питона то же самое. Мне кажется странным, что для JVM исключение сделали.
То есть я вот прямо в логах вижу: инит лямбды тогда-то, вот у меня залогалось всякое там во время инита, а вот несколько вызовов без логов инита, они в тот же инстанс упали. Потом она уснула, выгрузилась, пришел вызов — снова инит.
Это не такой хитрый аппсервер, а просто интерфейс к скриптам.
Да нет, AWS Lambda — это как раз хитрый аппсервер, со своим собственным состоянием.
основной особенностью лямбд заявляется независимый деплой (как в микросервисах), а если деплоить все консистентно, то чем это отличается от монолита?
Неа, основной особенностью лямбд является то, что про сервер думать не надо при провижнинге. А вот деплоить можно так, как хочется.
Иными словами, дихотомия "микросервисы/монолит" — это другая дихотомия нежели "серверлесс/сервер-бейсд". Можно писать микросервисы без лямбды, можно писать лямбды для не-микросервисных архитектур.
А можно, кстати, выделять небольшие куски консистентности, которые деплоятся целиком, и поэтому внутри себя консистентны, а наружу говорят по заранее определенному контракту, поэтому проблемы версионирования решаются так, как они решаются для внешних контрактов.
lair
17.03.2022 20:30лямбда, как stateless функция и состояния между вызовами не держит, это относится к пулам коннектов, и кешам — их просто не будет.
Даже документация с вами не согласна:
You can add initialization code outside of your handler method to reuse resources across multiple invocations. When the runtime loads your handler, it runs static code and the class constructor. Resources that are created during initialization stay in memory between invocations, and can be reused by the handler thousands of times.
Описанное поведение консистентно с тем, которое я вижу для .net и python.
vlad4kr7
17.03.2022 20:44Я рад за описание, но реальность запуска явы показывала другое, но это не исключает, что могли исправить.

ak0oval Автор
17.03.2022 21:09ограничение по времени - если вы думаете делать что-то, что занимает время (пакетная обработка, длительные транзакции) сразу нет
у вас длительность выходила за максимальное время жизни лямбды? пробовали Fargate для длительных операций?
vlad4kr7
17.03.2022 21:19Да по timeout AWS просто убивает все процессы и все ваши коннекты и транзакции откатываются. Очень не приятно было это обнаружить в проде на реальных объемах.
Fargate тогда не было, решили переездом кода на EC2.



git-merge
20.03.2022 10:28В следующих главах я разверну БД и научу свою функцию взаимодействовать с базой данных. Создам реализации и для других функций.
Я давно смотрю на serverless, но руки не доходили попробовать. Да и стимула не было пробовать, поскольку с ними совершенно непонятно что делать с CI/CD.
CI/CD упомянут Вами в статье. Будет здорово, если об этом будет что-либо в продолжении.Я пока вижу это так:
развёртываем боевую отдельно и тестовую лямбду отдельно
на тестовую (может быть и на боевую) натравливаем тестирующий её код. При этом могут вноситься изменения в БД, если лямбда над БД
соответственно кажется, что нормальный CI/CD можно построить только при наличии serverless в docker, иначе придётся писать солидную инфраструктуру над serverless провайдера (или он её уже написал?)
В общем если кто-то взялся освещать информацию о serverless, то было бы крайне интересно увидеть примеры/ответы на эти вопросы.
addewyd
Ничего не понял.
Можно попроще, без амазона, докера и вот этого всего?
lair
Мммм, вы хотите serverless без облачного провайдера?
addewyd
Как по мне, так этот самый облачный провайдер и есть сервер.
lair
А что такое тогда serverless, по-вашему?
addewyd
«Бессерверный», надо думать.
lair
Я боюсь, ваше понимание не совпадает с тем, которое использует сам облачный провайдер, когда продает свои решения как серверлесс.
И где же это "бессерверное" выполняется?
addewyd
Когда я увидел заголовок, сразу представилось нечто вроде сети с равноправными узлами.
И я так и не понял, почему «serverless»
Спросил у гугла…
Как это… когнитивный диссонанс.
lair
Формальный ответ звучит так: потому что вы не менеджите ресурсы сервера, и даже не знаете, сколько их там. Вы запускаете вычислительную задачу, а где она выполняется, на одном устройстве, на сотне — вас не волнует.
И в этом контексте AWS Lambda — честный serverless.
addewyd
\zanuda on
на сервере…
vlad4kr7
serverless лямбда без амазона и докера называется хранимки (stored procedure), но это 'фу' и плохо
lair
А почему она serverless, если она выполняется на сервере БД?
vlad4kr7
понятие serverless подразумевает выделенный appserver, не клиентскую обработку (совсем без сервера)
lair
Хм, первый раз об этом слышу.
Переформулируем: почему хранимка — это serverless, а функция в апп-сервере — нет?
vlad4kr7
почему нет? выполнение кода и в хранимке, и в лямбде будет serverless.
Но считается, что хранимки это плохо, а лямбда - хорошо и модно.
lair
А при чем тут лямбда? Я про апп-сервер спросил, это не лямбда.
Иными словами, что не серверлесс?
Ну, у меня есть мое собственное мнение, почему хранимки — это плохо, но оно никак не связано с тем, являются ли они серверлесс.