
Ссылки на другие части:
В предыдущей части я создал первую лямбда функцию, которая разворачивается при помощи SAM. Эта лямбда работает в облаке, может запускаться локально. В этой части займусь базой данных.
Для моего проекта требуется классическая реляционная БД, я остановлюсь на MySQL. Amazon предоставляет облачный сервис AWS RDS для работы с БД.
Архитектура приложения с базой данных
Для того, чтобы развернуть БД в AWS RDS, требуется для начала создать VPC.
VPC — это способ организации выделенной виртуальной сети в AWS, то есть фактически я получу виртуальную приватную сеть, в которой и разверну все ресурсы своего проекта. После создания нового AWS аккаунта уже есть VPC по умолчанию, которую AWS создал для меня самостоятельно. Но хорошей практикой является создание отдельной VPC для нужд проекта, так называемой проектной VPC - это позволит безопасно и удобно организовывать полностью изолированную инфраструктуру для проекта. И, собственно, для своего проекта я создам отдельную проектную VPC, в которой я буду разворачивать все необходимые для моего проекта ресурсы.
В AWS VPC есть понятие публичных и приватных подсетей, целевое назначение которых легко уловить из их названия. В моем случае имеет смысл разворачивать RDS в приватной подсети, т.к. фактически кроме моих лямбда функций никто больше к БД обращаться не будет. Плюс это более безопасный и простой на первый взгляд механизм организации доступа к БД — то есть, вот такая примерно картина была в моей голове, когда я решил развернуть БД в приватной подсети:
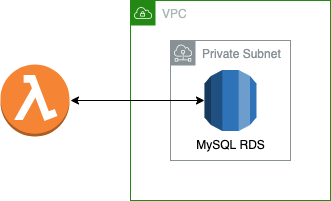
А теперь конечный результат, который по итогу был реализован:
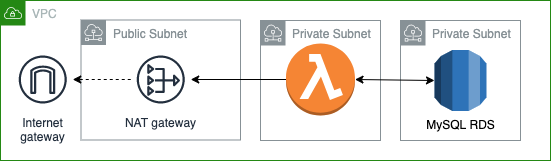
Как можно заметить, появилось много ресурсов, которых изначально не было — а вот, собственно, и причины появления некоторых из этих ресурсов:
Internet Gateway и Nat Gateway нужны, чтобы моя лямбда могла взаимодействовать с Интернетом. Так как, после того, как лямбда будет запущена в VPC, без этих ресурсов у нее не будет доступа в Интернет;
публичная подсеть нужна для работы Nat Gateway;
пустая приватная подсеть нужна для RDS: одно из требований при создании RDS — наличие двух подсетей. Судя по документации AWS, вторая подсеть используется для хранения резервных копий и журналов и может использоваться для целей организации высокой доступности в случае развертывания Multi-AZ конфигураций.
Каким образом все это можно создать? Обилие ресурсов говорит о том, что делать такие вещи вручную — подписать себе приговор. В этом случае получается некий микс из SAM-приложения, которое разворачивается двумя командами с использованием IaaC-подхода, и “ручными” ресурсами. В своем приложении я буду добиваться максимального единообразия и автоматизации, чтобы можно было в будущем легко и быстро настроить CI/CD.
У меня есть SAM. Сможет ли он развернуть такую инфраструктуру?
В самом начале статьи я уже упоминал, что SAM — это расширение CF для Serverless-приложений, то есть фактически SAM добавляет специфичные для serverless-подхода ресурсы, при этом никак не ограничивая использование обычных CF ресурсов в sam-шаблоне. Для развертывания VPC, RDS, NAT буду использовать стандартные ресурсы из CF.
Организация SAM шаблонов в приложении
С инструментом я определился. Как организовать SAM и CF шаблоны? Пользоваться одним шаблоном для всех ресурсов? Такой подход кажется временной мерой. С ростом объектов поддерживать постоянно разрастающийся файл станет сложно, напрашивается какая-то декомпозиция.
AWS предоставляет несколько вариантов организации ресурсов:
использовать макрос AWS::Include;
использовать вложенные стеки — Nested Stacks;
использовать отдельный независимый стек для RDS и сопутствующих ресурсов.
Сравню подходы, выберу самый удобный и подходящий.
Первый способ — использовать макрос AWS::Include
Этот способ максимально простой в понимании, макрос позволяет вставить фрагмент в конфигурационный файл.
Вот пример template.yaml c AWS::Include:
# ./global-resources/template.yaml
Resources:
'Fn::Transform':
Name: 'AWS::Include'
Parameters:
Location : global-resources/rds.yaml# ./global-resources/rds.yaml
DB:
Type: 'AWS::RDS::DBInstance'
Properties:
Engine: MySQL
...В момент развертывания CF заменит этот макрос фрагментом и далее уже будет работать с измененным конфигурационным файлом.
Этот вариант подходит для случаев:
когда уже хочется сделать какую-то логическую разбивку в небольшом шаблоне.
если хочется использовать некоторые фрагменты повторно в одном или нескольких шаблонах CF.
Не подходит:
когда планируется создать развесистую многоуровневую структуру вложенных ресурсов (Amazon не разрешает Include включать в другой Include фрагмент).
когда количество ресурсов в шаблоне подходит к ограничениям AWS.
Второй способ — использовать вложенные стеки — Nested Stacks.
Внутри корневого шаблона создаются ресурсы с типом AWS::Serverless::Application. Каждый такой ресурс представляет из себя вложенный CF стек. При развертывании корневого стека будут развернуты все его вложенные стеки.
Структура может быть такой:
# ./global-resources/template.yaml
...
Resources:
RDS:
Type: AWS::Serverless::Application
Properties:
Location: rds.yaml# ./global-resources/rds.yaml
AWSTemplateFormatVersion: 2010-09-09
Description: "AWS CloudFormation for creating an Amazon RDS DB instance"
Resources:
DB:
Type: 'AWS::RDS::DBInstance'
Properties:
Engine: MySQL
...В отличие от Include, который вставляет только фрагмент конфига, ресурсы AWS::Serverless::Application являются полноценным стеками, которые можно отдельно разрабатывать и развертывать. Этот подход позволяет масштабировать приложения и создавать большее число ресурсов, чем может поддерживаться в одном файле.
Этот вариант достаточно универсальный, гибкий. Можно разбивать приложение на сколь угодно хитрые части, разрабатывать части отдельно от других стеков.
Третий способ — использовать отдельный независимый CF стек.
Самый очевидный вариант — сделать отдельный независимый стек для RDS и сопутствующих ресурсов. Отдельный файл, отдельный стек, никаких связей между конфигурационными файлами.
Кажется, что этот способ лишний, ведь второй покрывает все случаи жизни. В каком случае этот подход может быть удобным?
В моем приложении требуется хранилище данных. Для экономии денег можно использовать один инстанс БД для нескольких окружений, используя разные имена баз данных на уровне MySQL. Также я могу использовать этот инстанс для локальной разработки. Тогда dev, qa, feature environments будут взаимодействовать с одним инстансом. При использовании первого или второго подхода для каждого стека будет разворачиваться отдельный инстанс БД. Ну и, само собой, чем больше разработчиков в команде, тем больше feature environments потребуется, тем “громче” будет звон монет, списываемых AWS в конце месяца с моей карты.
Таким образом, третий подход применим в случае существования глобальных по отношению к проекту ресурсов, когда один ресурс применяется на нескольких окружениях. Примеры: общая БД, общая VPC (в которой крутятся все элементы приложения), общие роли и т.д.
Я не вижу смысла переплачивать за отдельные БД на каждом окружении в моем случае, поэтому БД будет глобальной. Соответственно, я остановился на некоем миксе второго и третьего варианта: третий вариант — для организации единых между окружениями глобальных ресурсов, а второй — для декомпозиции одного большого стека на части. Внутри стека с глобальными ресурсами у меня есть две компоненты: rds и vpc. Их для удобства поддержки я размещу в отдельных nested stack.
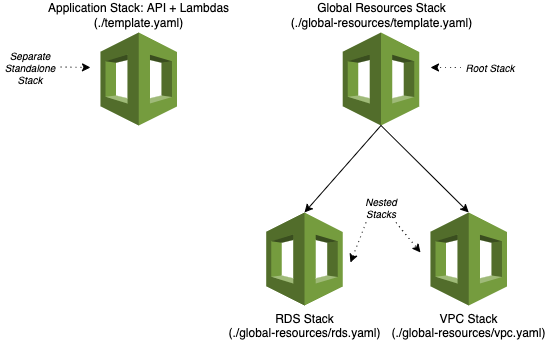
Итоговая структура файлов, в которых расположены ресурсы приложения, получится такой:
serverless-bugtracker/
├── global-resources
│ ├── rds.yaml
│ ├── template.yaml
│ └── vpc.yaml
└── template.yamlГде:
-
./global-resources/template.yaml - шаблон глобальных ресурсов;
./global-resources/rds.yaml - вложенный шаблон для настроек БД;
./global-resources/vpc.yaml - вложенный шаблон для настроек VPC и связанных ресурсов.
./template.yaml - шаблон для ресурсов serverless приложения (лямбды).
Развертывание базы данных при помощи SAM шаблона
Настройка VPC
Начну с настройки VPC и компонентов, с ним связанными. Для упрощения создания VPC и всех связанных ресурсов проще всего, в качестве отправной точки взять практически готовый к использованию шаблон от AWS - AWS CloudFormation VPC template - AWS CodeBuild. Он реализует VPC с двумя публичными и двумя приватными подсетями, Internet и Nat gateway, необходимые таблицы маршрутизации и т.д. Но я немного подправил указанный шаблон для своих нужд — в частности, я убрал вторую публичную подсеть и Nat Gateway для нее, а также часть параметров шаблона.
Шаблон для создания VPC получается довольно объемным, так что все содержимое приводить здесь я не буду, приведу небольшие фрагменты. По ссылке можно увидеть конечный результат.
Добавлю некоторые пояснения.
Для вложенного стека vpc.yaml я сделал параметр RootStackName. Это значение (имя родительского стека) активно участвует при составлении имен ресурсов. Это я сделал намеренно, чтобы по именам можно было быстро и легко определить приложение и родительский стек.
Лямбда функциям необходима настройка VPC параметров, но соответствующие ресурсы находятся в другом стеке. Я не могу напрямую использовать ресурсы из других стеков, для этих целей в CF существует механизм cross-stack reference, который предоставляет возможность ссылаться и использовать данные между стеками.
Для создания cross-stack reference используется настройка Export для Outputs данных. Эта настройка задает уникальное для региона имя в AWS аккаунта.
Чтобы в дальнейшем импортировать это значение, нужно знать Export имя и имя стека. Создание VPC и всех связанных ресурсов реализовано в виде отдельного вложенного стека. Имя этого стека получается из имени родительского стека, логического имени ресурса AWS::Serverless::Application в шаблоне родителя и дополнительной генерируемой Amazon строки. Если я буду пересоздавать вложенный стек, то эта генерируемая строка будет другой.
Получается, что имя вложенного стека может меняться, в отличии от имени стека родителя, которое я задаю сам. Удобнее работать с неизменяемыми именами. Поэтому я настроил экспорт переменных из родительского шаблона ./global-resources/template.yaml.
Таким образом, для того, чтобы сделать данные из стека с vpc доступными для других сторонних стеков, мне необходимо:
передать нужные значения из ./global-resources/vpc.yaml в ./global-resources/template.yaml;
задать Export для Outputs значений в ./global-resources/template.yaml;
# ./global-resource/vpc.yaml
Outputs:
...
PrivateSubnet00:
Description: A reference to the private subnet in the 1st Availability Zone
Value: !Ref PrivateSubnet00
LambdaSecurityGroup:
Description: "Security group for Lambda Functions"
Value: !Ref LambdaSecurityGroupРанее я использовал блок Outputs в шаблоне только для того, чтобы посмотреть выходные значения в консоле. Теперь я их использую для передачи данных из вложенного стека в родительский.
Функция Ref умеет делать две вещи:
вернуть значение параметра по его логическому имени;
вернуть идентификатор ресурса по его логическому имени
# ./global-resources/template.yaml
Outputs:
LambdaSubnet:
Description: "Export the ID of created Subnet for Lambda Stack"
Value:
!GetAtt [VPC, Outputs.PrivateSubnet00]
Export:
Name: !Sub '${AWS::StackName}-LambdaSubnet'
LambdaSecurityGroup:
Description: "Export the ID of created SecurityGroup for Lambda Stack"
Value:
!GetAtt [VPC, Outputs.LambdaSecurityGroup]
Export:
Name: !Sub '${AWS::StackName}-LambdaSecurityGroup'Из вложенного стека vpc.yaml я вернул идентификаторы PrivateSubnet00 и LambdaSecurityGroup. Используя CF встроенную функцию GetAtt, можно получить любое свойство ресурса. В том числе свойства Outputs из вложенных стеков.
Встроенная функция Sub заменяет в строке переменные вида ${MyVar} на заданные значения. В моем случае я использую глобальную переменную AWS::StackName, которая заменяется на название стека, где происходит развертывание.
Настройка RDS
Теперь пришла очередь RDS. Как и в случае с VPC, я передам параметр RootStackName для именования ресурсов.
# ./global-resources/rds.yaml
DB:
Type: 'AWS::RDS::DBInstance'
Properties:
DBInstanceIdentifier:
Fn::Join:
- ""
- - !Ref RootStackName
- '-db'
DBInstanceClass: !Ref DBInstanceClass
AllocatedStorage: !Ref DBAllocatedStorage
Engine: MySQL
MasterUsername: MyName
MasterUserPassword: MyPassword
В свойстве DBInstanceIdentifier я задаю имя инстанса, которое собирается из имени стека. Тип инстанса и размер диска для БД я тоже сделал параметром. Это те параметры, которые будут отличаться у инстансов на разных окружениях, например, на проде машинки могут быть гораздо мощнее, в тоже время для разработки и нижних окружений может хватить и db.t3.micro инстанса.
У меня уже есть VPC, необходимо ее прописать в настройки RDS вместе с надстройками подсетей, это требуется для запуска RDS в приватной подсети. Для этого мне нужно передать параметры из vpc.yaml в rds.yaml. Поскольку оба этих стека имеют одного и того же родителя, то для передачи данных между ними мне достаточно передать параметры через родительский стек.
# ./global-resources/template.yaml
RDS:
Type: AWS::Serverless::Application
Properties:
Location: rds.yaml
Parameters:
RootStackName: !Ref AWS::StackName
DBInstanceClass: !Ref DBInstanceClass
DBAllocatedStorage: !Ref DBAllocatedStorage
PrivateSubnet00: !GetAtt VPC.Outputs.PrivateSubnet00
PrivateSubnet01: !GetAtt VPC.Outputs.PrivateSubnet01
DBSecurityGroup: !GetAtt VPC.Outputs.DBSecurityGroup
DependsOn:
- VPCСвойство DependsOn позволяет задать очередность создания ресурсов. Очевидно, что RDS ресурс должен быть создан после VPC.
Для запуска БД в VPC необходимо настроить DBSubnetGroup и VPCSecurityGroups.
# ./global-resources/rds.yaml
Parameters:
PrivateSubnet00:
Type: String
Description: The shared value will be passed to this parameter by parent stack.
PrivateSubnet01:
Type: String
Description: The shared value will be passed to this parameter by parent stack.
DBSecurityGroup:
Type: String
Description: The shared value will be passed to this parameter by parent stack.
Resources:
DBSubnetGroup:
Type: "AWS::RDS::DBSubnetGroup"
Properties:
DBSubnetGroupName:
Fn::Join:
- ""
- - !Ref RootStackName
- '-dbsubnetgn'
DBSubnetGroupDescription: Subnet Group for DB
SubnetIds:
- !Ref PrivateSubnet00
- !Ref PrivateSubnet01
DB:
Type: 'AWS::RDS::DBInstance'
…
Properties:
...
DBSubnetGroupName: !Ref DBSubnetGroup
VPCSecurityGroups:
- !Ref DBSecurityGroupХранение настроек в облаке
Затрону еще один немаловажный момент при создании RDS — каким образом задать необходимые login/pass и имя базы данных.
Как видно, сейчас у меня значения просто зашиты в шаблон, что, само собой, недопустимо в настоящем нормальном проекте.
Другой простой способ — воспользоваться параметрами CF, которые можно передавать во время создания стека. В этом случае параметры будут в открытом виде передаваться в CF. Конечно, такой подход не годится для передачи секретных параметров (пароли, ключи). Такой вариант не сильно удобен, потому что эти параметры придется вводить каждый раз при развертывании. Можно, конечно, задать значения по умолчанию. Но это приведет к тому, что имена аккаунтов/пароли будут в текстовом виде представлены в коде шаблона.
Еще один возможный вариант — воспользоваться одним из сервисов AWS для хранения параметров. При использовании таких сервисов, в моем шаблоне не будет параметров в открытом виде.
Amazon предоставляет несколько сервисов для хранения разных параметров, в том числе и секретных данных (пароли, ключи, токены, и т.д.):
Systems Manager Parameter Store (далее SSM);
Secrets Manager;
С точки зрения хранения и использования сервисы Secrets Manager и SSM обладают очень схожим базовым функционалом, но Secrets Manager, в отличие от SSM, имеет несколько дополнительных возможностей:
генерация паролей по расписанию;
ротация паролей для RDS, Redshift и др.
Соответственно, использовать этот сервис имеет смысл, если указанный выше функционал необходим в приложении. Также Secrets Manager обходится чуть дороже Parameter Store.
AppConfig — это решение с другими возможностями. Если предыдущие сервисы по сути позволяют работать с параметрами поштучно, то этот сервис позволяет работать со всей конфигурацией разом. Для изменений конфигурации предусмотрен аналог CD процесса, когда эти параметры постепенно или сразу применяются на окружения. Этот сервис хорошо применим для меняющихся динамических настроек, тогда как первые 2 сервиса заточены больше под работу со статическими, неизменяемыми (или редко меняющимися) параметрами. Идеальный сценарий для AppConfig — feature toggles.
Я не планирую делать автоматическую ротацию паролей, мой сценарий достаточно простой, а параметры не будут меняться в процессе работы приложения на лету, поэтому для своего приложения буду использовать сервис SSM.
SSM хранит любые параметры, по сути, это обычное key-value хранилище. Для секретных параметров есть специальный secured тип данных. Логин буду хранить в обычном String поле, а пароль я положу в SecureString поле. CF можно использовать для создания параметров в SSM. Но это работает только для обычных типов данных. Secured поле придется создавать руками. Для единообразия я создам все параметры в SSM руками.
Пока у меня в аккаунте только один сервис/компонента, я могу называть свои параметры как угодно. Но как только появятся еще приложения, то придется наводить порядок, поэтому я сразу буду действовать на опережение. Хорошей практикой является сохранение параметров в виде иерархической модели, например, в формате /{environment}/{service}/{parameter}. Это позволит в будущем свободно ориентироваться в десятках разных значений для разных приложений и окружений. У меня есть 2 глобальные настройки (логин и пароль) и одна, которая будет отличаться на разных окружениях (имя базы данных на сервере):

Осталось дело за малым — передать параметры и настройки RDS в соответствующие свойства.
Работать с параметрами в SAM/CF шаблоне можно двумя способами:
использовать параметры стека;
использовать динамические ссылки.
Вариант 1. Используем дополнительную секцию в SAM шаблоне - Parameters.
В этом блоке можно описать параметры шаблона, значения которых я могу задавать при развертывании стека. Для того, чтобы в качестве значения параметра использовалось значение из SSM, нужно задать тип AWS::SSM::Parameter::Value:
Parameters:
DbLogin:
Description: Required. Password stored in SSM
Type: AWS::SSM::Parameter::Value<String>
Default: /global/serverless-bugtracker/db-login
CF возьмет параметры из SSM с именем ключа, указанным в значении Default.
Теперь я могу работать со значениями DbLogin в шаблоне при помощи функции Ref:
Resources:
DB:
Type: 'AWS::RDS::DBInstance'
Properties:
...
Engine: MySQL
MasterUsername: !Ref DbLoginНо такой подход не поддерживается в CF с SecureString параметрами. Как быть с паролем?
Вариант 2. Используем динамические ссылки.
Динамическая ссылка — это строка вида:
'{{resolve:ssm:parameter-name:version}}' — для обычных параметров;
'{{resolve:ssm-secure:parameter-name:version}}' — для шифрованных параметров.
CF при развертывании кода заменяет эти динамические ссылки на конкретные ресурсы. И у динамических ссылок есть ограничения — ssm-secure параметры поддерживаются только ограниченным списком сервисов, среди которых есть RDS, Redshift. Например, таким образом нельзя передать параметры в лямбда функции.
Получается для настроек RDS при передачи паролей я могу пользоваться только динамическими ссылками, а для передачи логина — обоими вариантами.
Я сделаю единообразной работу с параметрами RDS — буду использовать динамические ссылки. Если бы у меня в шаблоне эти значения использовались несколько раз, то использование динамических ссылок было бы менее удобным. В случае переименования имени параметра пришлось бы менять код в нескольких местах.
# ./global-resources/rds.yaml:
Engine: MySQL
MasterUsername: '{{resolve:ssm:/global/serverless-bugtracker/db-login}}'
MasterUserPassword: '{{resolve:ssm-secure:/global/serverless-bugtracker/db-password}}'У каждой записи в SSM есть версия. Можно ссылаться на конкретную версию параметра из истории изменений, а можно всегда использовать последнюю актуальную. Я не указываю версию, CF возьмет самую последнюю.
Итак, VPC готова, БД готова.
Разверну мой новый стек в облаке под именем serverless-bugtracker-global-resources. AWS создал несколько стеков:
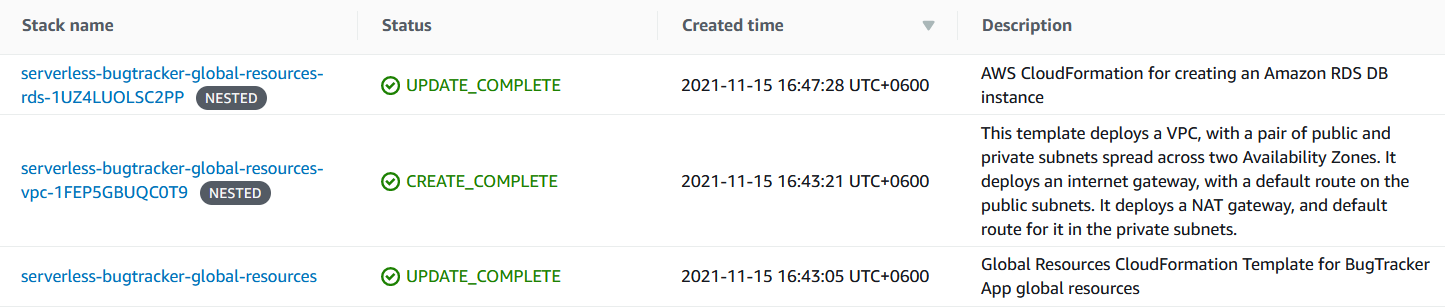
Если присмотреться, то можно увидеть, что каждому nested стеку AWS добавляет сгенерированную строку.
Стек создан в облаке и теперь я могу использовать следующие переменные в других шаблонах:
serverless-bugtracker-global-resources-LambdaSecurityGroup;
serverless-bugtracker-global-resources-LambdaSubnet.
Я оставлю за скобками вопросы о создании структуры БД, и о том, как данные там оказываются, все-таки статья не об этом. Это могут быть обычные DDL скрипты, или эти данные и таблицы могут быть созданы руками. Можно использовать специальные программы для управления структурой БД: flyway, liquibase и другие.
Подведение итогов
Для развертывания общих глобальных ресурсов я создал отдельный SAM шаблон.
При помощи SAM я развернул БД в отдельной VPC. Новые ресурсы развернуты в стеке под именем serverless-bugtracker-global-resources.
В развернутом стеке настроены cross-stack reference для передачи параметров.
В следующей раз я настрою лямбда функции на работу с развернутой БД.
P.S. Спасибо oN0 за помощь в написании статьи.
lair
Правильный ответ, на самом деле, переходить на AWS CDK (особенно учитывая, что вы все равно на JS пишете), тогда вам будут доступны все инструменты вашего языка для управления этой сложностью.
ak0oval Автор
Спасибо за совет. До AWS CDK еще не добрался. Обязательно посмотрю.