
Существует великое множество статей об оптимизации PostgreSQL — эта «кроличья нора» весьма глубока. Когда несколько лет назад я начал разрабатывать бэкэнд аналитического сервиса, у меня уже был опыт работы с другими СУБД, такими как MySQL и SQL Server. Тем не менее, раньше мне не приходилось так фокусироваться на производительности. В прошлых проектах, над которыми я работал, либо не было жестких требований к времени обработки (DS/ML), либо не требовалось обрабатывать много строк одновременно (обыкновенные веб-приложения). Однако в этот раз мои запросы:
состояли из 3-10 JOIN-ов по коррелирующим запросам;
yielded от 10 до 1 000 000 строк;
должны были выполняться в течение времени, определенного UX-ом;
не могли быть hinted — пока Cloud SQL, управляемый PostgreSQL в Google Cloud, не стал поддерживать pg_hint_plan в конце 2021 года;
запрещали прямой доступ к серверному процессу, чтобы, например, хакнуть некоторые perf — потому что PostgreSQL был managed.
Получение целого миллиона строк в одном API endpoint сигнализирует о проблеме в алгоритме или архитектуре. Конечно, все можно переписать и перепроектировать, но за это нужно платить.
У нас не нашлось «заклинания», которое решило бы все проблемы с производительностью SQL. Тем не менее, я упомяну здесь несколько дельных предложений, которые помогли нам и, надеюсь, смогут помочь читателю. Разумеется, это не какие-то сакральные знания. Но когда мы начинали оптимизацию, я был бы рад их прочитать или услышать.
Тайное преимущество LEFT JOIN
Каждый, кто писал SQL-запросы, должен знать разницу между INNER JOIN и LEFT JOIN. В книгах часто упускается тот момент, как эти разновидности объединения влияют на планировщик запросов, если общие столбцы взаимосвязаны. Предположим, что у нас есть две таблицы:

pull_requests содержит записи о pull request’ах на GitHub. commits содержит записи о коммитах на GitHub. merge_commit_id в pull_requests ссылается на {0,1}-1 id в commits. Все id имеют очень высокую селективность. Учитывая INNER JOIN между таблицами,
SELECT pr.*, c.sha AS merge_commit_sha
FROM pull_requests pr
INNER JOIN commits c ON pr.merge_commit_id = c.id
WHERE pr.repository_id IN (...)планировщик PostgreSQL, скорее всего, предскажет лишь малое количество результирующих строк и выдаст Nested Loop Join. Это произойдет, потому что PostgreSQL не знает, что наши идентификаторы коммитов являются коррелирующими, и перемножает их селективности в формуле оценки количества объединенных строк. Поэтому производительность нашего запроса стремительно падает, если мы обрабатываем более 10k строк. Давайте рассмотрим, как поведет себя LEFT JOIN:
SELECT pr.*, c.sha AS merge_commit_sha
FROM pull_requests pr
LEFT JOIN commits c ON pr.merge_commit_id = c.id
WHERE pr.repository_id IN (...)Планировщик, скорее всего, предскажет такое же количество результирующих строк, как и отфильтрованных в pull_requests, и правильно запланирует Hash Left Join на ~10k. Чтобы избежать хэширования всех коммитов, мы можем воспользоваться знанием того, что PR и коммиты всегда находятся в одном и том же репозитории.
SELECT pr.*, c.sha AS merge_commit_sha
FROM pull_requests pr
LEFT JOIN commits c ON pr.merge_commit_id = c.id
AND pr.repository_id = c.repository_id
WHERE pr.repository_id IN (...)Второе условие JOIN является искусственным и не влияет на результат. Однако PostgreSQL достаточно умна, чтобы хэшировать коммиты, предварительно отфильтрованные по тем же repository_id, что и pull_requests. Наш запрос должен выполняться быстрее, поскольку под рукой имеются все необходимые индексы.
Реальное преимущество этого подхода проявляется в «многоэтажных» JOIN-ах. PostgreSQL кэширует предварительно отфильтрованные хэш-таблицы, и их объединение обходится «недорого», в то время как кэширование вложенного цикла невозможно. В результате нам удалось добиться 10x-100x повышения производительности при переходе от INNER JOIN к LEFT JOIN. Важный момент: вы должны пост-фильтровать null'ы, если не уверены, что разные JOIN'ы возвращают эквивалентные результаты.
Хеширование VALUES
Рассмотрим типичный запрос "fat IN":
SELECT *
FROM pull_requests
WHERE repository_id IN (...более 9000 идентификаторов...)Этот запрос обычно планируется как Index или Bitmap Scan. Мы можем переписать его, используя выражение VALUES:
SELECT *
FROM pull_requests
WHERE repository_id = ANY(VALUES (101), (102), ...)PostgreSQL создает другой план с HashAggregate над Values Scan и, вероятно, Hash Join, если прогнозируемое количество строк достаточно велико. Влияет ли это на производительность? В отдельных случаях — да. Я заметил, что такой подход полезен в запросах с несколькими JOIN.
P.S.: не стоит вставлять более 9000 идентификаторов непосредственно в тело SQL-запроса.
WHERE repository_id = ANY($1::text::bigint[])WHERE repository_id = ANY(SELECT * FROM unnest($1::text::bigint[]))--где $1 - аргумент, переданный по бинарному протоколу$1 = '{...более 9000 идентификаторов....}'Обратите внимание на двойное приведение $1::text::bigint[]. Прямое приведение к bigint[] может не сработать из-за неверного определения типа параметра внутри asyncpg (ожидался размерный итерируемый контейнер (а получен тип 'str')).
Расширенная статистика
В продолжение предыдущего SQL, давайте добавим еще одно условие в WHERE:
SELECT *
FROM pull_requests
WHERE repository_id IN (...) AND merge_commit_id IN (...)И repository_id, и merge_commit_id имеют высокую селективность. Эти два столбца являются для PostgreSQL «черным ящиком», поэтому он, скорее всего, существенно занизит полученное количество строк. Пессимистичный прогноз о количестве строк приводит к принятию ошибочных решений, таких как Nested Loop вместо Hash Join для LEFT JOIN commits, и производительность падает.
Существует приемлемое решение этой проблемы: расширенная статистика.
CREATE STATISTICS ids_correlation ON repository_id, merge_commit_id FROM pull_requests;Благодаря ids_correlation, PostgreSQL выше 13 версии поймет, что repository_id и merge_commit_id коррелируют, и скорректирует оценку количества строк.
Расширенная статистика оказалась особенно полезной для корректировки прогнозов планировщика, когда мы использовали шардинг по ID клиентского счета. Вновь мы получили Hash Joins вместо Nested Loops и 10-100-кратное ускорение.
Тип первичного ключа имеет значение
Раньше у нас была немного другая схема, взгляните на нее:
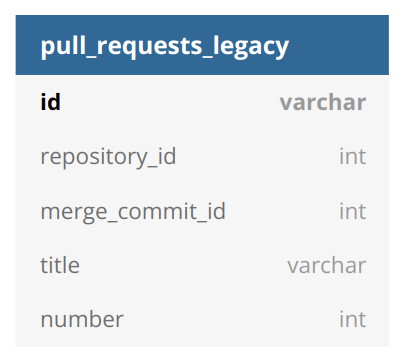
Старая схема БД с типом varchar для идентификатора запроса.
GitHub присваивает так называемый идентификатор ноды каждому объекту API, например, pull request. Это непрозрачная строка: например, athenianco/api-spec#66 - это PR_kwDOFlTa5c4zPMUj. Мы решили использовать идентификаторы узлов в качестве первичных ключей. Все работало хорошо, пока GitHub не изменил формат ID ноды. Нам было сложно перестроиться, и в итоге мы перешли на глобальные целочисленные ID, сопоставленные с ID нод. Извлеките урок из нашей ошибки: не стоит полагаться на внешние ID, потому что вы их не контролируете.
Когда наши первичные ключи превратились в целые числа вместо строк, мы были в восторге от 2-5-кратного ускорения JOIN-ов по этим столбцам. Целые числа занимают меньше памяти, их быстрее сравнивать и хешировать. Нет ничего удивительного в том, что производительность так сильно возросла.
CLUSTER
Продолжим исследовать pull_requests.
SELECT *
FROM pull_requests
WHERE repository_id IN (...) AND number > 1000Предположим, что у нас уже есть подходящий индекс:
CREATE INDEX pull_requests_repository_id ON pull_requests (repository_id, number).Можем ли мы сделать что-нибудь еще, чтобы ускорить выполнение запроса? Я вижу два варианта:
Поместить столбцы, упомянутые в SELECT *, в INCLUDE-часть покрывающего индекса. Получится сканирование только по индексу.
Кластеризовать таблицу по pull_requests_repository_id.
Первый вариант хорош, если количество дополнительных столбцов невелико. Второй способ более продвинут. В нем используются знания о стандартных способах обращения к таблице. В частности, интересны PR, сгруппированные по хранилищам: мы, скорее всего, хотим получать только самые последние PR (моделируемые числом > 1000). Следовательно, мы объявляем индекс как CLUSTER:
CLUSTER pull_requests USING pull_requests_repository_idПосле завершения этой команды все записи таблицы перестроятся на диске в соответствии с порядком индексированных столбцов. Чем больше строк вернет наш запрос, тем больше IOPS мы сэкономим благодаря загрузке меньшего количества страниц с коррелирующими данными.
Как и многие другие, мы столкнулись с препятствием при внедрении CLUSTER ... USING в прод. Эту команду необходимо выполнять регулярно, поскольку PostgreSQL не может автоматически поддерживать кластерное состояние. К сожалению, CLUSTER устанавливает эксклюзивную блокировку на таблицу, и ожидающие запросы чтения/записи блокируются. Спасением стал pg_repack — легкая альтернатива без блокировок.
Ускорение на проде составило около 2-5 раз, особенно CLUSTER помог с «холодными» запросами, которые должны были читать с диска буферы.
pg_hint_plan
Руководство PostgreSQL всегда выступало против SQL-хинтов. Ситуация напоминает запрет дженериков в Go — за исключением того, что 13 лет спустя дженерики в Go появились, а PostgreSQL не хочет добавлять хинты уже больше 36 лет. К счастью, хинты можно подключить с помощью pg_hint_plan, японского проекта на GitHub. Cloud SQL поддерживает pg_hint_plan с конца 2021 года.
Мне всегда доставляло удовольствие делать что-то, что авторы яростно запрещают, если я уверен, что в данной ситуации проблем не возникнет. Это чувство похоже на джейлбрейк телефона после окончания гарантии. Или как когда сталкиваешься с проблемой в веб-сервисе и напрямую обращаешься к техническому персоналу вместо того, чтобы терять время с первой линией поддержки. Как и политики, разработчики программного обеспечения любят налагать ограничения, отчасти потому что в противном случае именно им придется разбираться в возникшем бардаке.
pg_hint_plan позволяет делать множество классных трюков. Ниже приведены наиболее удачные из них.
Избыточные условия в WHERE
Мы можем ускорить Hash Joins, если добавим в запрос дополнительные ограничения. Они не меняют результат, но уменьшают количество чтений индекса.
Рассмотрим запрос из раздела о LEFT JOIN.
SELECT pr.*, c.sha AS merge_commit_sha
FROM pull_requests pr
LEFT JOIN commits c ON pr.merge_commit_id = c.id
AND pr.repository_id = c.repository_id
WHERE pr.repository_id IN (...)Мы можем переписать его следующим образом:
SELECT pr.*, c.sha AS merge_commit_sha
FROM pull_requests pr
JOIN commits c ON pr.merge_commit_id = c.id
WHERE pr.repository_id IN (...) AND c.repository_id IN (...)Как я уже отмечал ранее, планировщик, скорее всего, неправильно предскажет количество строк, поскольку он не знает, что repository_id коррелируют. Однако, у нас есть супер-оружие, и мы можем подправить этот прогноз.
/*+
Rows(pr c *100)
*/
SELECT pr.*, c.sha AS merge_commit_sha
FROM pull_requests pr
JOIN commits c ON pr.merge_commit_id = c.id
WHERE pr.repository_id IN (...) AND c.repository_id IN (...)Фактический коэффициент умножения должен усредняться по нескольким типичным запросам. Описанный подход имеет свои плюсы и минусы.
???? Явный INNER JOIN лучше выражает суть.
???? Он подходит, если нам приходится писать INNER JOIN.
???? Когда статистика таблицы меняется, нужно снова пересмотреть коэффициент умножения. На практике лучше перестраховаться, чем потом жалеть, поэтому избыточно большие значения лишь слегка ухудшают производительность, если количество строк невелико.
PREDICTION от Oracle
Если мы будем искать PR с заданными хэшами коммитов слияния, мы снова столкнемся с неправильной оценкой количества строк.
SELECT pr.*, c.sha AS merge_commit_sha
FROM pull_requests pr
JOIN commits c ON pr.merge_commit_id = c.id
WHERE c.sha IN (...100 элементов...)Мы можем воспользоваться знаниями о том, что
IN содержит только коммиты слияния.
Каждый коммит слияния соответствует одному pull request.
Следовательно, мы устанавливаем количество строк равным размеру IN:
/*+
Rows(pr c #100)
*/
SELECT pr.*, c.sha AS merge_commit_sha
FROM pull_requests pr
JOIN commits c ON pr.merge_commit_id = c.id
WHERE c.sha IN (...100 элементов...)Выходим за пределы set join_collapse_limit=1
Порядок, в котором следует JOIN'ить несколько таблиц, может иметь решающее значение. Официальная документация предлагает установить параметр join_collapse_limit равным 1. Продолжая предыдущий запрос, предположим, что мы ищем по многим коммитам слияния и решили принудительно искать в хэш-таблице:
SELECT pr.*, c.sha AS merge_commit_sha
FROM pull_requests pr
JOIN commits c ON pr.merge_commit_id = c.id
WHERE c.sha = ANY(VALUES ...) AND ...другие пункты...Другие условия могут запутать планировщик PostgreSQL, поэтому он запланирует HashAggregate после объединения двух таблиц. Тогда последствия для производительности будут катастрофическими. Давайте исправим эту неприятность.
/*+
Leading(*VALUES* c pr)
*/
SELECT pr.*, c.sha AS merge_commit_sha
FROM pull_requests pr
JOIN commits c ON pr.merge_commit_id = c.id
WHERE c.sha = ANY(VALUES ...) AND ... другие пункты...Или, если другие условия являются очень строгими для pull_requests и мы ожидаем меньшее количество PR, чем количество хэшей коммитов слияния, мы можем применить другие условия перед объединением с отфильтрованными коммитами:
/*+
Leading(pr (*VALUES* c))
*/
...Беспощадные переопределения индексов
pg_hint_plan дает нам в руки мощное оружие: IndexScan и IndexOnlyScan. Эти два параметра отменяют решение планировщика использовать индекс. К сожалению, если что-то меняется в SQL или статистике, планировщик сбивается с пути и сообщает об "undefined behavior".
Пример:
CREATE INDEX impossible ON pull_requests (merge_commit_id);/*+
IndexScan(pr impossible)
*/
SELECT *
FROM pull_requests pr
WHERE repository_id IN (...) AND number > 1000;Планировщик выполнит последовательное сканирование. Если autovacuum не успевает за записью в таблицу, план будет выглядеть чрезвычайно странно. Например, будет использоваться нужный индекс, но индексированные столбцы будут игнорироваться, а фильтрация начнется с нуля. В любом случае, autovacuum запаздывает.
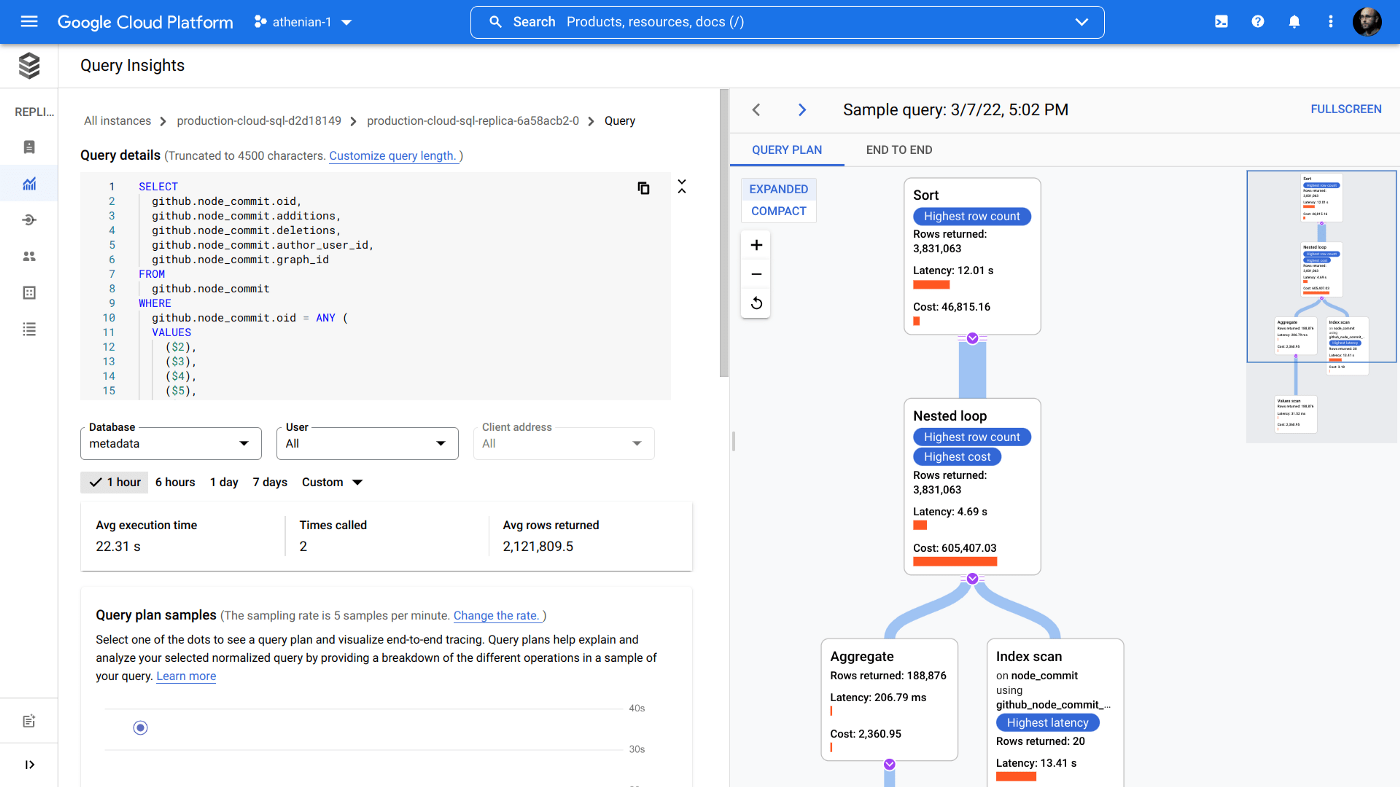
Бонус: визуальный EXPLAIN
EXPLAIN (ANALYZE, BUFFERS) — это мои Альфа и Омега, если речь идет об оптимизации очередного запроса. Я перепробовал несколько веб-приложений, и моим любимым является explain.tensor.ru.

Преимущества:
Рекомендации, что нужно исправить или подстроить. Они далеко не тривиальны и оказываются чрезвычайно полезными для новичков.
Круговая диаграмма «узких мест» и другие наглядные инструменты.
Очень надежный анализатор планов.
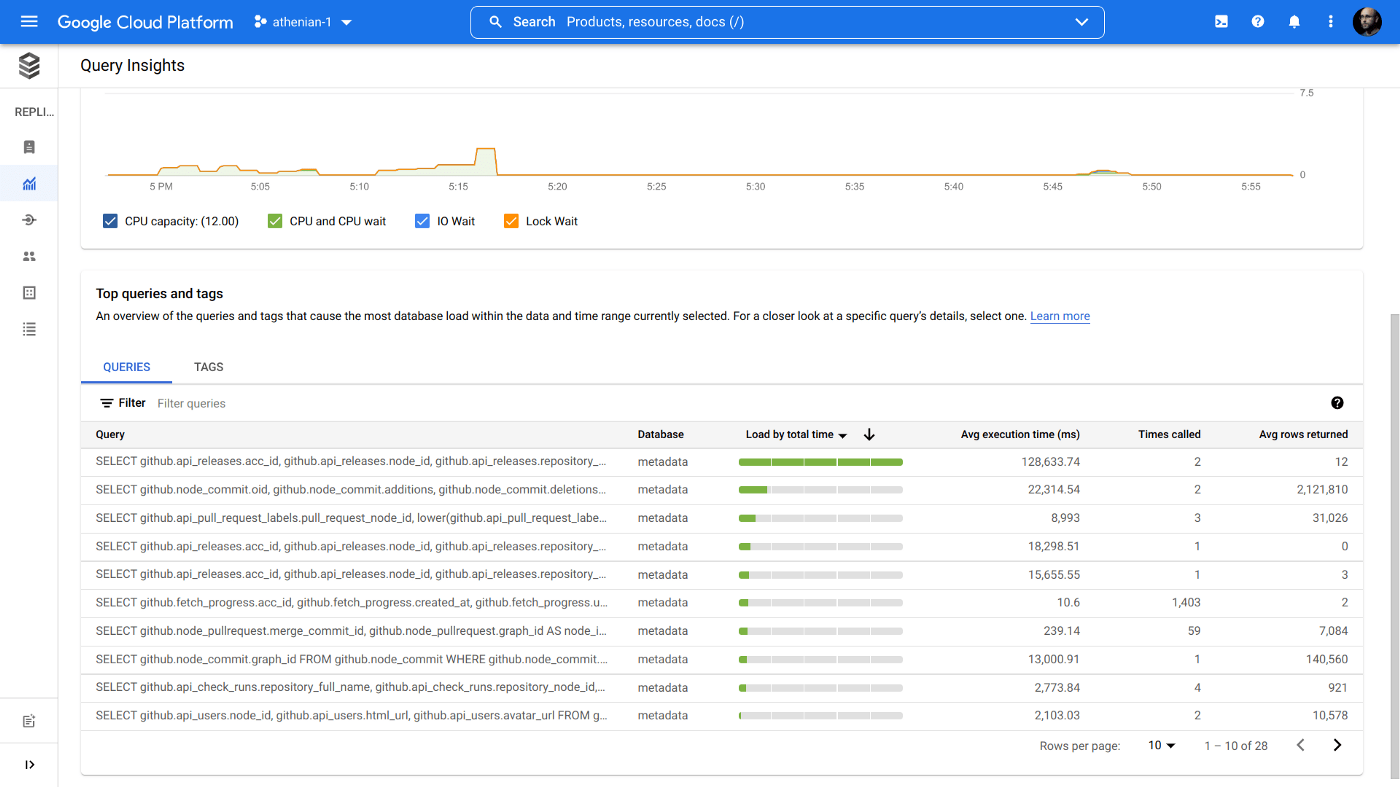
Бонус: Cloud SQL Insights
Google Cloud запустил новый инструмент, встроенный в Cloud SQL: Cloud SQL Insights. Не сосчитать, сколько раз этот инструмент спасал нас от фиаско:
Когда бэкенд подвергал БД DDoS-атаке медленными запросами, мы в панике пытались исправить ситуацию в кратчайшие сроки. Cloud SQL Insights сразу же указал на конкретного «виновника».
Когда наша подсистема извлечения данных (та, что зеркалирует данные из GitHub, JIRA и т.д.) выполняла запросы слишком быстро, автовакуум не справлялся, и некоторые таблицы «портились». Опять же, Cloud SQL Insights быстро указал, что нужно срочно выполнить VACUUM ANALYZE.
Кроме того, есть мониторинг производительности, дополняющий Sentry.
Резюме
В этой статье я рассказал о нескольких приемах повышения производительности PostgreSQL, которые позволили нам ускорить выполнение запросов в 100 раз:
LEFT JOIN вместо INNER JOIN помогает планировщику делать более точные прогнозы количества строк. Добавление избыточных ONclauses улучшает Hash Joins.
= ANY(VALUES ...) вместо IN может обеспечить выполнение хэш-агрегации с большим количеством элементов.
Расширенная статистика информирует планировщик о коррелирующих столбцах.
Делать первичный ключ таблицы varchar — плохая идея.
Если запрос возвращает много связанных строк, используйте CLUSTER.
pg_hint_plan — полезный и мощный инструмент, который в ряде случаев может дать существенный прирост производительности.
explain.tensor.ru — превосходный и полезный сервис.
Cloud SQL Insights — это must-have для всех, кто пользуется Cloud SQL.
P.S. Облачный сервис «PostgreSQL-as-a-Service»
#CloudMTS в бета-версии предоставляет вычислительные ресурсы облачной платформы с установленной СУБД PostgreSQL. Вы уже можете протестировать сервис PostgreSQL, зарегистрировавшись по ссылке.
Комментарии (2)

beduin01
14.04.2022 14:54А как вы вообще проводите тестирование? У вас есть копия реальной базы 1к1 и на ней проводите замеры?
Каким образом сбрасываете кэш запросов, Посгрес перезапускаете или есть варианты лучше?
makar_crypt
статья как отличный пример. что разработчики задроты дальше носа не видят. Увидели проблему, начали решать теме же способами. А на самом деле надо было поднять голову и увидеть что проблема в архитектуру, решается с помощью Континуес Квери как в Рейвене или ksqldb подобными инструментами.