Практически в каждой современной компании присутствуют информационные ресурсы, где происходит работа с документами, в т.ч. с конфиденциальными. В крупных и средних компаниях роль таких ресурсов отведена системам управления корпоративным контентом (ECM - Enterprise content management) и СЭД (системам электронного документооборота). В небольших организациях это могут быть также CRM-системы и любые другие корпоративные порталы, где происходит просмотр документов, их загрузка/выгрузка и последующий обмен с контрагентами в электронном или распечатанном виде.
С точки зрения информационной безопасности, такие системы в приличной степени уязвимы, т.к. большинство продуктов (в т.ч. DLP), направленных на борьбу с утечками документов, перестают работать, как только сотрудники решают скомпрометировать документ при помощи фото на собственный смартфон.
Для противодействия подобному типу утечек одно из возможных решений – применение технологии невидимой маркировки конфиденциальных документов. Она представляет собой микросмещения, которые происходят со всеми объектами на странице, позволяя создать уникальные копии для каждого пользователя при любом взаимодействии.
Такая маркировка наносится автоматически при просмотре содержимого документа в системе, при отправке на печать, пересылке по почте или обмене с 3-ми лицами. Рассмотрим подробнее варианты ее интеграции в различные корпоративные системы на примере решений от компании EveryTag.
Два типа интеграции невидимой маркировки
HTTP проксирование
Системы электронного документооборота и другие ресурсы, где происходит работа с документами, — это только один из каналов утечек в современной информационной среде наряду с виртуальными комнатами данных, почтовыми отправлениями, распечатываемыми копиями и другими уязвимыми каналами обмена информацией. Но именно здесь может произойти утечка наиболее важной и конфиденциальной информации, компрометация которой может привести к серьёзным репутационным и финансовым рискам. Для маркировки документов в системах документооборота нашей компанией были разработаны два программных продукта Web Access и ILD, основное отличие которых заключается в способе их интеграции.
Если информационная система веб-ориентированная, а доступ к ней осуществляется через стандартный веб-браузер (обмен информацией между пользователем и такой системой происходит на уровне HTTP запросов), тогда для интеграции используется продукт Web Access. Это решение построено на базе реверсивного прокcи (NGINX) и перехватывает из заголовков запросов все обращения к документам в СЭД, будь то их предпросмотр, загрузка или выгрузка. Web Access встраивается в инфраструктуру заказчика бесшовным образом, а маркировка документов происходит на лету. Развернуть данное ПО можно на виртуальных или физических серверах на стороне заказчика, а также использовать любое доверенное облако. Примечательно, что сотрудники не замечают каких-то изменений в их привычном процессе работы. Им не требуется менять сценарий работы с документами, а компаниям ранее утверждённый регламент по корпоративному документообороту.
На диаграмме последовательности ниже отображены два основных сценария работы программного продукта Web Access.
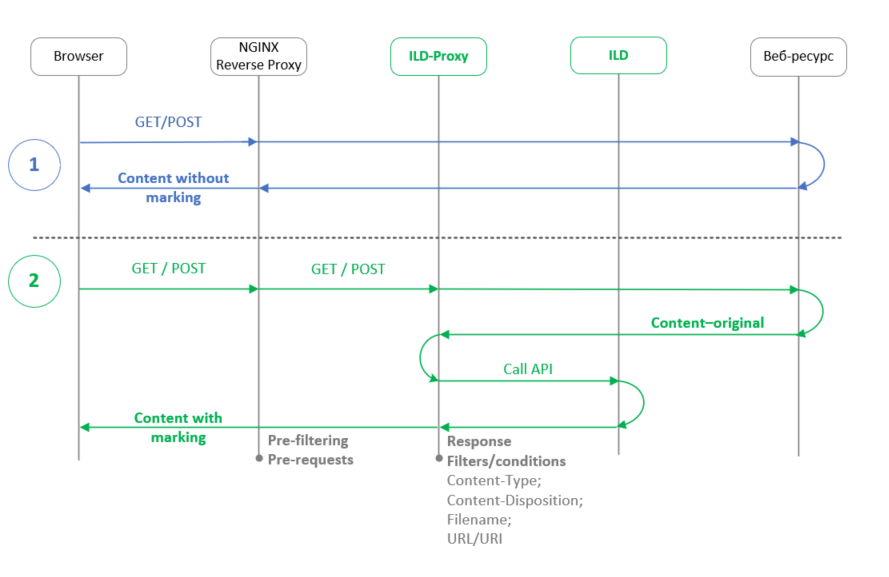
Вариант HTTP-запроса от пользователя к информационной системе, в котором отсутствует обращение к документу. В данном случае веб-сервер NGINX, на базе которого работает Web Acсess, осуществляет фильтрацию заголовков (pre-filtering; pre-requests), после чего отправляет данный запрос на целевой веб-ресурс, а пользователю в браузер возвращается результат такого запроса. Здесь Web Access не производит никакой работы по маркированию, а все запросы, в которых нет обращений к документам, обрабатываются прозрачным образом.
-
Вариант HTTP-запроса от пользователя к целевому веб-ресурсу (например, любая веб-ориентированная СЭД), где происходит обращение к документу (например, в форматах PDF или DOC). Веб-сервер NGINX осуществляет предварительную фильтрацию по заголовкам и определяет, что в запросе действительно присутствует обращение к документу. На этом шаге веб-сервер отбирает возможные запросы к документам, которые необходимо промаркировать перед возвращением ответа в браузер пользователя. Для этого запрос направляется на внутренний микросервис ILD-Proxy, а тот, в свою очередь, ещё раз опрашивает целевой ресурс, и по его ответу понимает, действительно ли в нем присутствует документ.
Выборка может происходить по различным заголовкам (сontent-type; content-disposition и прочим). Если веб-ресурс действительно возвращает в ответе документ, то он уже отправляется на микросервис ILD, который выполняет маркировку. По итогу пользователь получает промаркированный документ. При этом Web Access сохраняет оригинал документа в файловое хранилище лишь один раз, а ключи всех преобразований хранятся в базе данных и занимают мало места (в среднем 16кб для одной страницы текста А4).
Каждый ключ преобразования фактически хранит в себе атрибуты, которые содержат всю основную информацию о промаркированной копии документа и для кого, в какое время и когда она была создана.
Rest API
Также на рынке всё ещё присутствуют такие версии информационных систем, доступ и работа с которыми осуществляется через собственную программную оболочку (толстый-клиент), а не веб-браузер. В этом случае использовать метод проксирования HTTP трафика невозможно, т.к. передача данных здесь происходит уже на уровне собственных проприетарных протоколов и программных библиотек. При этом часть бизнес-логики в таких системах может осуществляться на стороне АРМ, где установлен толстый-клиент. В такой ситуации используется продукт ILD.
Взаимодействие информационных систем с ILD происходит через программный интерфейс приложений Rest API. Когда пользователь информационной системы выполняет предпросмотр документа или его выгрузку, то такой документ предварительно отправляется на наш сервер маркировки, маркируется, и после чего уже персонализированная копия отображается в формате превью или выгружается на компьютер пользователя. Здесь же, как и в случае с Web Access, интеграция продукта осуществляется бесшовным образом.
Технически взаимодействие между пользователем, целевой системой документооборота и ПО ILD можно разделить на несколько шагов, которые включают в себя:
Первоначальную загрузку документа пользователем в систему документооборота.
Его распознавание и маркировку со стороны ПО ILD.
Присвоение уникального идентификатора для дальнейшего обращения к документу по его ID и возврат данного ID в информационную систему.
Пользователь получает подтверждение, что документ загружен и зарегистрирован в системе.
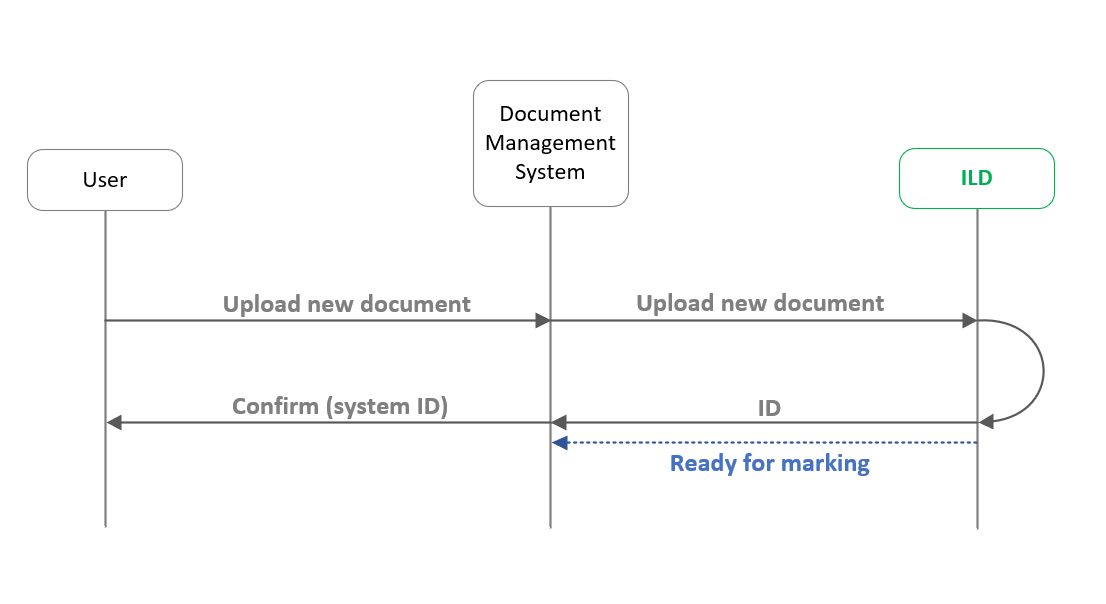
После этого все последующие обращения к документу (например, предпросмотр, скачивание) будут приводить к тому, что перед выдачей документа пользователю, предварительно будет осуществляться его маркирование.
Этот шаг можно разделить ещё на два. В зависимости от используемой системы документооборота и параметров настройки, запрос может обрабатываться синхронно или асинхронно. В первом случае (синхронно) обращение пользователя к документу приводит к тому, что система документооборота обращается к ПО ILD по заранее известному ID документа, с запросом подготовки для пользователя маркированной копии. ПО ILD в этом случае сообщает системе документооборота, что подготовка копии в процессе и возвращает идентификатор операции. После подготовки пользователь получает персонализированную копию. Синхронный тип обработки подходит для документов небольшого размера.

Для обработки растровых документов (например, многостраничных PDF, полностью состоящих из сканов) большого размера, асинхронный тип обработки запроса является более предпочтительным, т.к. во время подготовки персонализированной копии для пользователя в системе документооборота может отображаться индикатор выполнения, по завершении которого пользователь получает запрашиваемый документ.

Процесс обработки запроса в асинхронном варианте выглядит следующим образом:
Пользователь обращается к документу в системе документооборота, та в свою очередь обращается в ПО ILD по заранее известному идентификатору данного документа.
ПО ILD возвращает ответ в систему документооборота о том, что данный ID документа ей известен.
СЭД отправляет запрос на создание персонализированной копии для конкретного пользователя, который обращается к документу.
ПО ILD возвращает идентификатор операции, также сообщая, что копии в процессе подготовки.
На этой итерации СЭД может запрашивать статус подготовки маркированной копии документа. ПО ILD отвечает No (50%) или Yes в зависимости от фактической готовности копии.
Последней итерацией ПО ILD возвращает уже промаркированную копию документа пользователю.
Что делать, если произошла утечка промаркированного документа?
В том случае, если произошла утечка промаркированного конфиденциального документа, то по любому найденному скомпрометированному фрагменту офицер службы безопасности сможет установить источник такой утечки.
Источником является тот пользователь, для кого была подготовлена конкретная копия документа, просочившаяся в общее информационное поле (ресурсы СМИ, соц. сети и прочее).
Найденный фрагмент (в виде скриншота, скана/ксерокопии, фотографии распечатанного документа и отображаемого на экране монитора) загружается в модуль экспертизы. После чего офицер безопасности получает итоговый результат с указанием на фактический источник утечки и дополнительные атрибуты: дата/время получения копии и логин в информационной системе.

Вместо заключения
Использование технологии невидимой маркировки – это новаторский подход в защите от утечек. Подобный метод отличается от всем известных водяных знаков, которые легко распознать и удалить. Кроме того, это отличный вариант для дополнения существующих DLP и DRM решений, чтобы создать более комплексную защиту в компании.
Комментарии (5)

4eyes
19.04.2022 13:33+1Подобный метод отличается от всем известных водяных знаков, которые легко распознать и удалить.
А теперь сделаем курсовую работу по OpenCV и ImageMagick:
Преобразовать все цвета к 4 битам на канал. 4096 цветов хватит всем.
Распознать прямоугольные границы букв в документе и измененить кернинг и межстрочный интервал в случайных границах. Кернинг запоминаем для кадой пары букв в строке, чтобы у читателя глаза не повытекали.
Определить прямоугольные границы иллюстраций, подвинуть каждую из них в случайном направлении, растянуть на 1-5% по каждой оси и повернуть на случайный угол в пределах +- 2 градуса. Если косинус угла поворота картинки умноженный на её ширину меньше, чем 1 мм, увеличивать угол поворота в 2 раза до тех пор, пока не станет больше.
Бонусное задание: перед обработкой документа выровнять межстрочные интервалы и левую/правую границу текста в пределах +/- треть буквы.

xSVPx
19.04.2022 15:11А потом окажется, что промаркировали точками переноса, либо заменой букв с похожим начертанием, либо ещё как-то. (да хоть синонимы вставляй)
У "злодея" бесконечное количество вариантов "спалиться", рано или поздно приличная служба безопасности прищучит.


randomsimplenumber
Спасибо, буду пользоваться OCR.