Бессерверные сервисы облачных вычислений появились в 2014 году с AWS Lambda, которая позволяла запускать код без выделения серверов или управления ими. AWS Lambda — пример функции как услуги (FaaS), где результат обработки событий не зависит от состояния памяти сервера и содержимого локальной файловой системы. Такие эластичные вычисления позволяли быстро наращивать и высвобождать ресурсы процессоров, памяти и средств хранения без необходимости что-то планировать и предпринимать меры для обработки пиковых нагрузок.
За AWS Lambda быстро последовали решения от Microsoft Azure и Google Cloud. Позже облачные провайдеры начали предлагать и другие услуги в бессерверной форме. Это последний, новый взгляд на облачные сервисы, и на практике бессерверные архитектуры за счет возможностей масштабирования часто обходятся в разы дешевле, чем постоянные серверы, предназначенные для выполнения тех же нагрузок.
Сейчас бессерверных решений все больше, в том числе пару лет назад появились и первые проекты в России. На Хабре о бессерверных вычислениях есть раздел, но куда менее популярный, чем он того заслуживает. Попытаемся это исправить.
Итак, Serverless. Крупным планом.
Что значит бессерверность?

Несмотря на название, бессерверность не означает, что серверы не используются. Просто вам не нужно заказывать и поддерживать выделенные машины как таковые. Не нужно управлять инфраструктурой, мониторить ее, конфигурировать, распределять ресурсы. Когда на бессерверную службу придет запрос на выполнение кода, облачный провайдер просто выделит специально под его обработку виртуальную машину или модуль (набор контейнеров, обычно управляемых Kubernetes). А когда выполнение бессерверного кода завершится, выделенные ресурсы возвратятся в общий пул. Вы платите только за реально затраченные ресурсы серверов — в зависимости от потребовавшихся мощностей и времени активности процесса.
Бессерверные функции могут вызывать друг друга (или другие службы), записывать информацию в общие файловые системы и базы данных. Одним из их самых больших технических преимуществ является невероятная масштабируемость. В отличие от выделенных серверов, которые могут быть перегружены скачками трафика, новые бессерверные модули или виртуальные машины просто запускаются для каждого нового события, которое в них нуждается. Любой пик трафика проходится автоматически. А когда ресурсы становятся не нужны, все они автоматически возвращаются в пул.
Что происходит, когда модуль подходящего размера недоступен в пуле при поступлении очередного запроса? Облачный провайдер просто создает новый. Правда, может возникать некоторая задержка в обработке запроса, вплоть до нескольких секунд. Если такая большая задержка является проблемой для вашего use case, можно заплатить, чтобы некоторые функции всегда были инициализированы и готовы к ответу. AWS, например, называет эту услугу Provisioned Concurrency. У других облачных провайдеров названия другие, но смысл один и тот же: они полагаются на предзагрузку некоторых функций, чтобы уменьшить задержку их ответа до сотен миллисекунд даже в крайнем случае. Как говорит сама Amazon, это идеально подходит для реализации интерактивных сервисов, в том числе веб-серверов для мобильных устройств, чувствительных к задержкам микросервисов или синхронных API.
Бессерверные функции и службы обычно показывают очень высокую стабильность, так как для их обработки провайдеры выделяют избыточные вычислительные мощности, распределенные физически. И нет никакой разницы, какая именно из машин будет обрабатывать код. Вероятность потерять всё при сгорании одного ЦОД — стремится к нулю.
В дополнение к бессерверным услугам от провайдеров существует множество разных независимых платформ и SDK, предназначенных для создания бессерверных приложений. В том числе Kubeless, Pulumi, OpenFaaS, OpenWhisk и Serverless Framework.
Детальнее о принципах работы бессерверных архитектур можно почитать в этой статье (англ.).
Чем отличаются бессерверные базы данных

По словам Джима Уокера из Cockroach Labs, создателя CockroachDB, бессерверная база данных работает на основании девяти основных принципов:
- Практически полное отсутствие ручного управления сервером
- Автоматическое гибкое масштабирование приложений и сервисов
- Встроенная отказоустойчивость и изначально отказоустойчивый сервис
- Всегда в наличии + мгновенный доступ
- Механизм выставления счетов за услуги на основе потребления
- Возможность выжить в случае любого отказа
- Географический масштаб, распределенность
- Гарантии транзакции
- Элегантность реляционного SQL
При этом принципы 1-5 являются основными, их можно применить по отношению к любой бессерверной службе. А принципы 6-9 относятся только к глобальным базам данных SQL.
Традиционным способом подключения к большинству баз данных является установление постоянного TCP-соединения от клиента к серверу. Но для бессерверных баз данных это не подходит: настройка TCP-соединения для обработки каждой функции может занять чересчур много времени. В идеале клиент должен подключаться к бессерверной конечной точке почти мгновенно (менее 100 мс) и получать ответ на свой запрос в течение секунды. Чтобы обеспечить это, некоторые бессерверные БД (например, Amazon Aurora Serverless) поддерживают соединения HTTP (HTTPS) и работают над пулом соединений, необходимым для поддержки масштабирования и создания практически мгновенных соединений.
Как бессерверные БД могут сэкономить вам деньги

Традиционные базы данных должны быть рассчитаны на максимальную ожидаемую нагрузку запросов. А значит, и деньги на ее поддержку тратятся «по максимуму». Если же БД можно масштабировать вверх и вниз без необходимости переноса данных, можно экономить деньги, увеличивая нагрузку ЦП в периоды высокой нагрузки и уменьшая ее в периоды низкой нагрузки.
В бессерверной архитектуре клиент платит не за резервируемые (по максимуму) мощности, а за конкретные операции чтения, записи, удаления или время активной работы модулей. Что позволяет с легкостью проходить пиковые периоды, и не терять лишние деньги во время «застоя». Также этот подход позволяет более точно рассчитать экономику проекта в условиях невозможности точно спрогнозировать его масштабы. Снимается большая боль бизнеса — оплата мощностей за время простоя. Можно платить только за те вычисления, которые действительно были проведены.
Бессерверные базы данных обычно вообще не нуждаются в изменениях размеров. Вы не платите за мощности, пока не отправляется запрос, а когда он отправляется, вы получаете столько ресурсов, сколько нужно для выполнения вашего запроса. Затем плата взымается за использованную мощность, помноженную на время активности БД. Вы платите только за те вычисления, которые вам нужны, и, в зависимости от масштаба и характера вашего трафика, это может стать для вас огромным экономическим преимуществом. По данным Amazon, вы можете сэкономить до 90% стоимости поддержки вашей базы данных с помощью Aurora Serverless.
Бессерверные архитектуры выигрывают от значительного снижения эксплуатационных расходов, сложности и времени разработки. Но взамен вы увеличиваете зависимость от конкретных поставщиков и можете не получить полного пакета услуг, к которому привыкли — из-за сравнительной молодости всей экосистемы.
В каких случаях бессерверные БД не оптимальны

Рекомендуемые варианты использования бессерверных баз данных — это случаи переменных или непредсказуемых рабочих нагрузок, управления парком корпоративных баз данных, приложения «ПО как услуга» и масштабируемые базы данных, разделенные на несколько серверов.
Но у serverless есть и минусы. Так, из-за отсутствия стандартизации любые бессерверные функции, которые вы используете у одного поставщика, другим поставщиком будут реализованы слегка по-другому. И если вы захотите сменить поставщика, вам почти наверняка потребуется обновить свои операционные инструменты и, вероятно, модифицировать свой код (например, чтобы удовлетворить другой интерфейс FaaS). Может, даже потребуется изменить дизайн или архитектуру, поскольку у конкурирующих поставщиков услуг есть серьезные отличия в реализации.
Ну и конечно, если пиковых нагрузок и периодов затухания нет, главного преимущества serverless вы лишаетесь. Базы данных с предсказуемой и постоянной нагрузкой проще и дешевле обрабатывать путем развертывания традиционных серверов. Даже те БД, которые сильно загружены в рабочие дни и потом простаивают в выходные и праздничные дни, обычно лучше обрабатываются серверами, а не бессерверными системами — при условии, что вы отключаете серверы на каждые выходные и праздники. Несмотря на развитие serverless, такой подход в основном остается более рентабельным.
Но бессерверные вычисления — это все еще довольно новый, неизведанный мир. Имеющиеся недостатки здесь постепенно устраняются, экосистема развивается, а преимущества технологии становятся все более очевидными.
Примеры бессерверных баз данных
На момент написания этой статьи свободно доступны не так много бессерверных баз данных. Некоторые, как, например, MongoDB Atlas, предлагают бессерверные функции пока только в формате превью. Но большинство лидеров, следуя за Amazon, вышли со своими serverless-решениями. Так что выбрать уже есть из чего.
Amazon Aurora Serverless

Автоматически масштабируемая конфигурация, доступная по требованию для Amazon Aurora. Предполагает автоматическое подключение, отключение и масштабирование ресурсов в зависимости от потребностей приложения. Позволяет запускать базу данных в облаке, исключая необходимость управления ее ресурсами вручную. Достаточно создать адрес сервера базы данных, указать желаемые пределы изменения ресурсов БД и подключить нужные приложения.
Совместима с MySQL и PostgreSQL. Является частью сервиса Amazon Relational Database Service (RDS), поэтому есть интеграции с MariaDB, Oracle и SQL Server.
Плата за ресурсы начисляется на посекундной основе. При этом между конфигурациями Standard и Serverless можно быстро переключиться в консоли управления Amazon RDS.
Amazon DynamoDB
Полностью управляемая бессерверная база данных NoSQL, предназначенная для запуска высокопроизводительных приложений любого масштаба. Предлагает встроенную защиту, непрерывное резервное копирование, автоматическую репликацию в нескольких регионах, кэширование в памяти и удобные инструменты экспорта данных.
Azure SQL Database Serverless
Это версия Microsoft SQL Server, которая автоматически масштабирует вычислительные ресурсы в зависимости от вашей рабочей нагрузки. Счета выставляются за количество вычислений, используемых в секунду. При этом платформа автоматически приостанавливает работу баз данных в периоды неактивности, и тогда выставляет счета только за их хранение. При восстановлении активности работа БД автоматически возобновляется.
Как и AWS, Azure предлагает 1 миллион вызовов и 400 000 ГБ-секунд бесплатно каждый месяц. Дальше — по 20 центов за каждый последующий миллион вызовов
Azure Synapse Serverless
Позволяет использовать T-SQL для запроса данных из озера данных в Azure, а не выделять под это ресурсы заранее. Вы платите только за выполненные запросы, а стоимость зависит от объема данных, обработанных каждым запросом.
CockroachDB Serverless
Бесплатная опция, которая в настоящее время находится в стадии бета-тестирования в облаке Cockroach Labs, совместимом с PostgreSQL. Может использовать высокодоступные кластеры в AWS или Google Cloud в многопользовательской конфигурации. Ограничения для бесплатного использования: 250 млн запросов в месяц и 5 ГБ для хранения.
Fauna
Гибкая, удобная для разработчиков транзакционная база данных, предоставляемая в виде безопасного и масштабируемого бессерверного облачного API с собственным GraphQL. Сочетает в себе гибкость систем NoSQL с реляционными запросами и транзакционными возможностями БД SQL. Поддерживает как язык запросов Fauna, так и GraphQL.
Google Cloud Firestore
Бессерверная документно-ориентированная база данных NoSQL, которая является частью Google Firebase. В отличие от базы данных SQL, в Cloud Firestore нет таблиц или строк. Вместо этого вы храните данные в документах, которые организованы в коллекции. Каждый документ содержит набор пар ключ-значение.
Cloud Firestore оптимизирован для хранения больших коллекций небольших документов. Все документы должны храниться в коллекциях. Документы могут содержать вложенные коллекции и вложенные объекты, которые могут включать в себя примитивные поля, например, строки, и сложные объекты, такие как списки.
СУБД разработана в качестве замены Realtime Database с возможностью быстрых запросов и масштабирования. Вкупе с нативными SDK и удобной аутентификацией, Google рассчитывает, что этот вариант займет свою нишу в сфере мобильных и веб-приложений, которые планируют не выходить за лимиты масштабирования.
PlanetScale
Совместимая с MySQL бессерверная платформа базы данных на базе Vitess. Vitess — это система кластеризации баз данных для горизонтального масштабирования MySQL (а также Percona и MariaDB). Vitess также поддерживает Slack, Square, GitHub, YouTube и многое другое.
Yandex Database
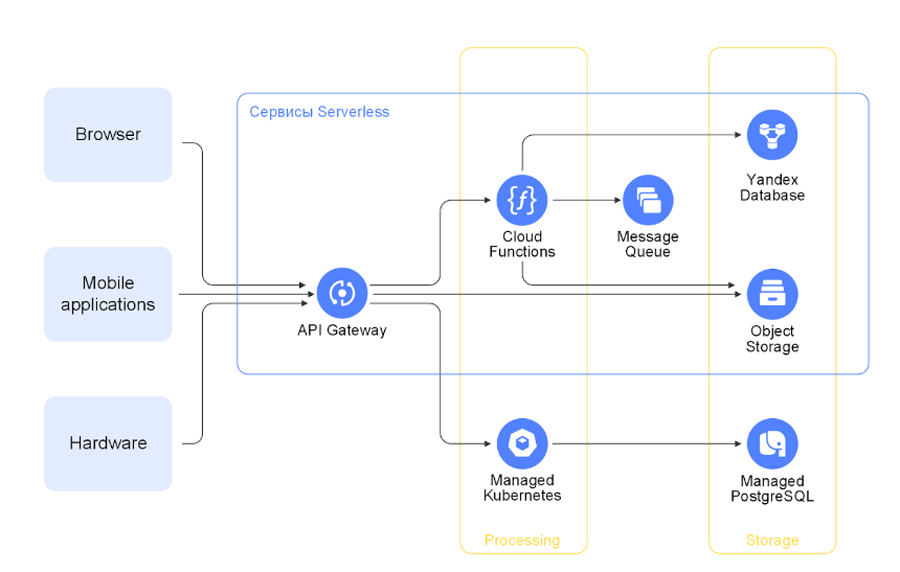
Уже полтора года при создании базы данных в YDB можно выбрать один из двух режимов работы: Serverless или Dedicated. Режим потом не может быть изменен. Бессерверная Yandex Database — это распределённая NewSQL СУБД. Она поддерживает реляционную модель данных и оперирует таблицами с предопределённой схемой.
Работает язык запросов YQL (Yandex Query Language), диалект SQL. API сервиса в режиме бессерверных вычислений совместим с API Amazon DynamoDB, с помощью него можно выполнять операции над документными таблицами.
Подробнее на Хабре информация по YDB есть тут.
Oracle Cloud Functions
Одна из очень свежих бессерверных платформ, первой реализации меньше двух лет. Выгодный вариант, если запросов у вас не очень много. Первые 2 миллиона вызовов функций в месяц — бесплатно, дальше вы платите по $0,2 за каждый последующий миллион (для сравнения, у MongoDB будет $0,3 за 5 млн). Функции интегрируются с Oracle Cloud Infrastructure, сервисами платформы и приложениями SaaS. Поскольку Cloud Functions основан на проекте Fn с открытым исходным кодом, разработчики могут создавать приложения, которые можно легко переносить в другие облачные и локальные среды.
Redis Enterprise Cloud
Полностью управляемая бессерверная база данных, работающая в AWS, Azure и Google Cloud. Корпоративные модули могут расширять Redis из простого хранилища структуры данных типа «ключ-значение» до мощного инструмента с поддержкой JSON и искусственного интеллекта.
Redis Enterprise выполняет автоматическое повторное сегментирование и перебалансировку, сохраняя при этом низкую задержку и высокую пропускную способность для транзакционных нагрузок. Функция Redis on Flash (RoF) позволяет размещать часто используемые данные в памяти, чтобы дополнительно уменьшить задержку при их вызове. Но бесплатного хранилища здесь предлагается всего 30 МБ.
Как видим, бессерверные базы данных предлагают высокомасштабируемое облачное хранилище, не требуя от вас никакой предварительной подготовки. Все они предлагают оплачивать только то, что вы используете, а многие, пытаясь приманить пользователей, на небольших объемах даже являются полностью бесплатными — особенно если вас устраивает ограниченная максимальная скорость обработки запросов.
Бессерверные БД отлично подходят для небольших мобильных и веб-приложений, для тестирования MVP, для стартапов. Возможность быстро и дешево доставлять решения на рынок, а потом масштабировать их в зависимости от фактического спроса, дает огромное конкурентное преимущество.
В то же время бессерверные решения подходят не всем, поэтому будьте осторожны с теми, кто говорит, что они заменят все ваши существующие архитектуры. Сложная отладка, проблемы с мониторингом, зависимость от конкретного поставщика услуг и возможное повышение задержки при росте количества запросов означают, что для крупных и устоявшихся систем, с сотнями миллионов обращений к БД ежедневно, традиционные решения окажутся более предпочтительными.
Промокод для читателей нашего блога:
— 15% на все тарифы VDS (кроме тарифа Прогрев) — HabrFIRSTVDS.
Более 50 тысяч активных серверов и 10 тысяч клиентов, которые с нами больше 5 лет.
Комментарии (20)

express
10.05.2022 18:44+1Я так и не понял в каких сценариях это реализуемо. Можно примеры этих невероятно выгодных временных "вычислений на БД", которым не нужны предыдущие данные, сохранение текущих и пр.?

mentin
10.05.2022 20:16Serverless не отменяет хранение данных, предыдущие есть, текущие сохраняются. Но данные отдельно (и за их хранение оплата идёт всегда), вычисления отдельно (оплата только при использовании).

VUDU_TEAM
10.05.2022 22:34+2Может не увидел в статье, но есть ли ограничения на пиковые нагрузки, которые задает сам клиент? Например, как защита от кривых рук. Ведь если на обычном сервере сделал что-то не так, его мощностей на хватило, БД упала - быстро заметил, починил. А тут получается заметишь когда счет в конце месяца выставят? Или неверно понимаю процесс предоставления услуги?

visirok
10.05.2022 22:50Поддерживаю. Механизмы защиты от ситуаций, за которые придут астрономические счета, в облачных сервисах сейчас один из самых важных.

maxzh83
10.05.2022 23:32А тут получается заметишь когда счет в конце месяца выставят?
Всегда казалось, что такие случаи и приносят основной доход serverless провайдерам. Примерно как возможность уйти в минус у банков или опсосов. Все, конечно же, ради блага клиента.

TimsTims
11.05.2022 01:58А тут получается заметишь когда счет в конце месяца выставят?
В этом и "прелесть" облаков - платишь за каждый чих. Если у тебя небольшой проект, то может влететь в копеечку. А если у тебя крупный проект типа FB, то тебе выгоднее поднимать свои облака. Выгодны облака для тех, кто где-то по середине: средний бизнес, у которого непонятно, что будет завтра, и при этом им норм платить $100 000 за серверы, т.к. они принесли на чёрную пятницу им в сотню раз больше выручки. Но и там уже сидят матёрые DevOps, которые умеют считать все эти операции.
mentin
11.05.2022 08:30В больших облаках вроде AWS, GCP, Azure есть всевозможные cost control. Но конечно надо правильно настроить, что часто бывает не очевидно. В мелких облаках с этим сложнее, да и в целом опасения верны - все ограничения на нагрузки обычно появляются не сразу, а вводятся когда первые пользователи начинают жаловаться :)

FlashHaos
11.05.2022 11:03В выпуске linkmeup sysadmins про бигдату описывался именно такой случай - когда кривой запрос обошёлся компании в круглую сумму. И описывалось принятое по результатам решение, когда специальная подсистема контролировала сложность запроса и алертила админам бд о слишком масштабных потребностях аналитиков.
TimsTims
11.05.2022 02:03+1Так и не понял в чем прелесть бессерверных БД. Они запускаются по несколько секунд (если спят). Если они спят, значит они не сжирают ваши деньги (значит, вы их экономите). А значит, вы тратите $0.
Но если вас устраивает то, что такой сервер будет подниматься несколько секунд при каждом (первом/случайном) запросе (значит, высокие задержки вас устраивают), и вам хочется очень сильно экономить, то разве не проще поднять самую дешманскую виртуалку за $2, которая будет вообще всегда онлайн, и также за 1 секунду отдавать данные вообще в любое время?
Ещё добавляем сюда проблему из предыдущей ветки комментариев - что ты не знаешь, сколько тебе по итогу предъявят счет за операции чтения. Это будет $0, это будет $100 или $10k. Ведь мы хотим экономить, и мы не хотим обслуживать сервер БД, а значит, мы не хотим поднимать тучу мониторингов, который бы за нас считал выгоду такого решения...
Короче одни противоречия.
mentin
11.05.2022 08:35+2Поднимаются несколько секунд это про те, где разделение пользователей на уровне VM или контейнера. Многим DB это не надо, скажем Google BigQuery (аналитическая база для больших данных) просто держит большой пул машин и при запросе выдает вам часть свободных, за миллисекунды решая кому какие ресурсы, в зависимости от нагрузки.
Если вам достаточно одной VM, то да - это часто не имеет смысла. А если надо тысячу машин для больших данных - то держать их самому дорого, используются то они только на время запроса, пока аналитик думает машины простаивают. А получить их на время интерактивного запроса дёшево и оправдано даже тем что результат получаешь за 10 секунд, а не час на одной своей машине.

Stas911
11.05.2022 04:16Пользуюсь DynamoDB последние три года в куче проектов. Все прекрасно работает и покрывает 99% процентов наших кейсов, нужных при разработке приложений. Репорты и дашборды - те да, удобнее SQL когда есть.

DmitryKoterov
11.05.2022 05:00+4Я как-то считал, во сколько раз дороже Aurora for PostgreSQL обходится просто обычного арендованного сервера в Hetzner той же мощности. Получилось ни много ни мало в 8 раз дороже.
«Но ее же не надо админить, и она отказоустойчива!» - скажет неопытный обыватель. Но нет: за 3 года на Aurora было в среднем по 2 многочасовых аутаджа каждый год. И в эти моменты делать ничего другого, кроме как тупо сидеть и ждать, было нельзя по сути (в половине случаев даже консоль не работала). Суппорт говорит «ничего не знаем, делайте кросс-региональный кластер». Что для небольшого сервиса просто смехотворно.
Вот вам и «бессерверная» и “cost efficient”.

fishHook
11.05.2022 10:32Когда на безсерверную службу придет запрос на выполнение кода, облачный провайдер просто выделит специально под его обработку виртуальную машину или модуль (набор контейнеров, обычно управляемых Kubernetes).
Как это работает, более-менее понятно, а как это программировать то? Допустим, у меня есть веб-сервер на python + Django. Он состоит из набора view, каждая вьюшка - функция, казалось бы - вот оно. Но есть же еще, скажем, ОРМ. Для инициализации моделей, построения дерева отношений и пр. требуется время. В обычном "серверном" сценарии мы жертвуем несколькими секундами "на разогрев" на этапе импорта, один раз для процесса. Далее обработка каждого входящего запроса - ну то есть каждого вызова функции - эта работа не нужна, все уже в памяти процесса. Правильно ли я понимаю, что с модными молодежными безсерверными технологиями мне прийдется вручную строить SQL запросы в стиле PHP пятнадцатилетней давности?
Ivan22
Юзаю snowflake для DWH уже второй год и просто балдею от удобства. После всех этих плясок с админскуим бубном вокруг гринплама, просто рай.
p.s. "И если вы захотите сменить поставщика, вам почти наверняка потребуется обновить свои операционные инструменты и, вероятно, модифицировать свой код "
А так-то при смене поставщика серверной субд ничего делать не надо ага, с mssql на postges например столько переделывать, проще с нуля все написать
virtual_explorer Автор
От поставщика serverless-технологий в любом случае зависимость выше. А с учетом нынешней нестабильной ситуации это может внезапно аукнуться. Что нужно учитывать.
slonpts
Несколько раз приходилось добавлять нового провайдера СУБД в разные проекты.
Сильно зависело от кода: какой ORM, сколько аналитических запросов. Условные ~80% запросов - стандартные SELECT / UPDATE / INSERT / DELETE, и они просто работают либо легко их изменить на работающие везде.
Сложные (как правило, аналитические) иногда приходилось решать через что-то вроде
switch (dbType) {case DbType.MSSQL:
...
case DbType.Postgres:
Но все решалось, хотя иногда для этого требовались недели-месяцы....
}
Если были юнит-тесты - они экономили время в несколько раз. В очередной раз убеждался, что это их основной use-case :)
warhamster
А как юнит-тесты помогают при миграции на другую базу? Они же с самой базой, по идее, не взаимодействуют вообще никак, иначе это уже и не юнит-тесты. Или что-то еще имеется в виду?
imageman
Видимо имеется в виду, что тесты показывают на проблемное место (что бы тотально все 100% кода не проверять вручную).
BugM
MySQL можно ничего не делая перенести в любой датацентр любого хостера. Админ средней руки справится за недельку.
А вот завязавшись на поставщика услуг вы уже никуда не переедете без огромных проблем. Не для всех проектов этот риск значим, но помнить о нем обязательно надо.
amarao
При смене поставщика серверной СУБД вы просто поднимаете её на мощностях другого поставщика.
Если вы хотели сказать, что смена СУБД - это сложно, то тут немного другая ситуация. Код вы запускаете там где хотите и имеете SLA, юридические требования т.д. какие хотите.
А в случае сервиса вы не можете уйти к другому поставщику без существенных издержек, и поднять на "других" мощностях не можете. И вообще, ничего не можете. Но удобно. Молочко в бутылочке, попу подтирают, выбраться за пределы кроватки не дают.