Всем привет! Меня зовут Ольга и я разработчик в Ингосстрахе. В этой статье-туториале хочу поделиться способом партиционирования оооочень большой таблицы в Oracle 12c. Итак, погнали!
В жизни любой давно функционирующей системы наступает момент, когда уже невозможно хранить все исторические данные без разбору и пора думать, что это надо как-то поделить. Старое отправить на архивный или отчётный сервер, а оперативный слой существенно проредить. И самый очевидный и распространенный путь – партиционировать таблицу, а старые секции перенести на другое хранилище.

Условия
У нас есть Oracle 12c, небольшая таблица на 15 миллиардов строк, общим объемом около 2 Тб без учета индексов;
Скорость поставки данных в таблицу в час: от 40 тысяч глухой ночью, до полутора миллионов днем.
Задача
Партиционировать таблицу таким образом, чтобы от 20 до 50 сессий в минуту ночью и до 500 днем ничего не заметили;
Урезать
осетраданные до глубины 3 года.
Задача упрощалась тем, что в выбранное для работ время требовался мгновенный доступ к данным только за последний час. Отчеты ночью тоже никто не формирует и запросы требующие наличия индексов не выполняются.
Варианты решений
Рассматривать вариант с переносом необходимых данных на архивный сервер с последующим удалением на проде мы не стали, ибо отсекание всего лишнего (80%) дарит непроходящую радость от конкуренции на индексе как пользователям, так и DBA.
Пробовать партиционирование всей таблицы в лоб – энтузиастов не нашлось. Это в лучшем случае очень длительная операция, а если имеются LOB-поля, то можно и вообще никогда в жизни не дождаться.
Вариант с использованием реорганизации таблиц DBMS_REDEFINITION хорош, но требует очень много места.
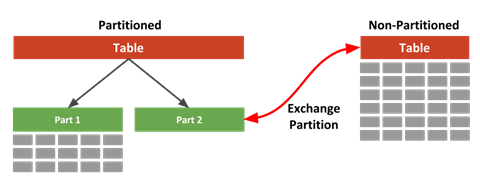
Оставалось одно: создать транзитную таблицу, быстро загрузить в нее необходимые данные и произвести подмену текущей таблицы транзитной. Самый симпатичный способ подобной подмены Exchanging Partitions. В этом случае операция выполняется над словарем данных, практически мгновенно, без инвалидаций и простоев.
Работает эта прелесть так
Короче, к делу (а для особо озорных в скрытом тексте полный скрипт с созданием исходной таблицы и генерацией 2 Тб данных для неё).
Скрытый текст
Ладно-ладно, я пошутила, 300 Гб вполне достаточно, чтобы прочувствовать…
CREATE TABLE Scott.TEST_EXCHANGE
(
ISN NUMBER NOT NULL,
HISTESTIMATIONISN NUMBER NOT NULL,
SOURCECODE CHAR(1 BYTE) NOT NULL,
SOURCEISN NUMBER NOT NULL,
VALUECODE CHAR(1 BYTE) NOT NULL,
VALUENAME VARCHAR2(255 BYTE),
DATAVALUE CLOB,
CREATED DATE NOT NULL,
CREATEDBY NUMBER NOT NULL,
UPDATED DATE NOT NULL,
UPDATEDBY NUMBER NOT NULL
)
LOB (DATAVALUE) STORE AS BASICFILE (
TABLESPACE TDATA
ENABLE STORAGE IN ROW
CHUNK 8192
RETENTION
)
tablespace TDATA
;
alter session enable parallel query;
alter session enable parallel DML;
declare
V_size number := 0.300; -- объем в Тб
V_rows number := 5000000; /* количество записей, с которого
перепроверяем полученный объем, чтобы не
опрашивать на каждом проходе и не считать лишнего*/
v_pks number := 100000; -- размер пачки
i number := 0;
s number;
v_sql varchar2(32000);
begin
/*Сгенерируем нужный(V_size) объем данных в табличку, надеюсь ваша
база не совсем пустая, так как данные я планирую позаимствовать из
нее что бы не перенапрягать генераторы случайных значений*/
loop
for r in (
/* Для большей наглядности воспользуемся вложенными запросами, а то
много скобок и не так красиво.
Далее в этом запросе читать комментарии снизу вверх: */
Select owner, table_name, column_name, num_rows
, nvl(varchar2_col,'null') varchar2_col, n
, RPAD (ncols, LENGTH (ncols) + (3 - n) * 2, ',0') ncols
--если колонок меньше 3 достраиваем нулями.
From (Select owner, table_name, column_name, ' '||ncols ncols
, num_rows, varchar2_col
, nvl((LENGTH(ncols)
- LENGTH(TRANSLATE (ncols, 'x,', 'x')))/2
,0) n /* считаем сколько у нас в этой таблице
вышло пригодных для инсерта колонок*/
From (Select l.owner, l.table_name, l.column_name
, t.num_rows, varchar2_col
, NVL (
SUBSTR (l.ncols
,1
,INSTR (l.ncols, ',', 1, 3*2+1) - 1)
, l.ncols) ncols
/* отбрасываем в списке колонок лишнее, нам
нужно только 3 числа, первичный
ключ мы присвоим уникальный,
а ключ будущего партиционирования
HISTESTIMATIONISN будем генерить */
From (Select l.owner
, l.table_name
, l.column_name
, max(case when l.column_name = c.column_name
then c.data_type end) lob_type
, max(case when c.data_type = 'VARCHAR2'
then c.column_name end) varchar2_col
, LISTAGG (Case When c.data_type = 'NUMBER'
Then ',nvl(' ||c.column_name||',0)' End)
--так как not null полей может не хватить прицепим nvl
Within Group (Order By c.nullable Desc, c.column_id)
ncols
-- собираем колонки с типом NUMBER
From dba_lobs l
Join all_tab_columns c
On c.owner = l.owner And c.table_name = l.table_name
/*воспользуемся таблицами с лобами и вытащим из них
лобы и числа, что бы не дергать dbms_random
и не кипятить проц*/
Group By l.owner, l.table_name, l.column_name) l
join dba_tables t
on t.table_name = l.table_name and t.owner = l.owner and num_rows>0
join all_tab_privs p
on p.table_name = t.table_name and p.table_schema = t.owner
--что бы на наступить на гранты
where lob_type='CLOB'))
order by case when num_rows > v_pks then 1 else 0 end desc
) loop
v_sql :=
'INSERT /*+ APPEND PARALLEL(16) */
INTO Scott.TEST_EXCHANGE (ISN, HISTESTIMATIONISN, CREATEDBY, UPDATEDBY,
SOURCEISN, DATAVALUE, VALUECODE, SOURCECODE, VALUENAME, CREATED, UPDATED)'|| chr(10)||
/* ключики себе генерим для ПК последовательно, для будущего ключа
партиционирования c разбросом ~50 значений по пачке d 100 000 (v_pks)*/
'SELECT rownum+:i, floor((rownum+:i)/(:v_pks/50)) '
||r.ncols||' ,'||r.column_name||
--чтобы не писать много двойных кавычек используем конструкцию q'{...}'
q'{,decode(mod(rownum,10),1,'V',2,'R',3,'A',4,'D',5,'P',6,'B',7,'T',8,'W',9,'E','S'),'N', substr(}'
||r.varchar2_col||',1,200) ,sysdate,sysdate
FROM '||r.owner||'.'||r.table_name ||'
SAMPLE BLOCK ('||case when ceil(100*v_pks/r.num_rows)> 100
then 99 else ceil(100*v_pks/r.num_rows) end||')
--'||r.num_rows||'
WHERE ROWNUM <=:v_pks';
execute immediate v_sql using i,i,v_pks,v_pks;
i:=i+sql%rowcount;
commit;
if i>= V_rows then /*с этого количества строк начинаем проверять
размерчик*/
select sum(bytes)/power(1024,4) into s
from (select sum(bytes) bytes
from dba_segments
where owner = 'Scott'
and segment_name = 'TEST_EXCHANGE'
union
select sum(bytes)
from dba_lobs l
Join dba_segments s
on l.OWNER = s.OWNER
and l.SEGMENT_NAME = s.SEGMENT_NAME
where l.owner = 'Scott'
and l.TABLE_NAME = 'TEST_EXCHANGE');
exit when s >=v_size;
end if;
end loop;
--если табличек с лобами не достаточно, придется по ним еще раз пробежаться
select sum(bytes)/power(1024,4) into s
from (select sum(bytes) bytes
from dba_segments
where owner = 'Scott' and segment_name = 'TEST_EXCHANGE'
union
select sum(bytes)
from dba_lobs l
Join dba_segments s
on l.OWNER = s.OWNER and l.SEGMENT_NAME = s.SEGMENT_NAME
where l.owner = 'Scott' and l.TABLE_NAME = 'TEST_EXCHANGE');
exit when s >=v_size;
end loop;
exception when others then
DBMS_OUTPUT.put_line (v_sql);
raise;
end;
CREATE UNIQUE INDEX Scott.PK_TEST_EXCHANGE ON Scott.TEST_EXCHANGE
(ISN) parallel 32;
Alter index Scott.PK_TEST_EXCHANGE noparallel;
CREATE INDEX Scott.X_TEST_EXCHANGE_HISTORY ON Scott.TEST_EXCHANGE
(CREATED, SOURCECODE, VALUECODE, VALUENAME) parallel 32;
Alter index Scott.X_TEST_EXCHANGE_HISTORY noparallel;
ALTER TABLE Scott.TEST_EXCHANGE ADD (
CONSTRAINT CHK_TEST_EXCHANGE_VALUECODE
CHECK (ValueCode in ( 'V', 'R', 'A', 'D', 'P', 'B', 'T', 'W', 'E','S','I','H','C'))
ENABLE NOVALIDATE
, CONSTRAINT PK_TEST_EXCHANGE
PRIMARY KEY
(ISN)
USING INDEX Scott.PK_TEST_EXCHANGE
ENABLE VALIDATE);/*Создаем промежуточную таблицу по структуре аналогичную партиционируемой,
но с необходимым партицоинированием*/
Create Table Scott.TEST_EXCHANGE_buf
(
isn Number Not Null
, histestimationisn Number Not Null
, sourcecode Char (1) Not Null
, sourceisn Number Not Null
, valuecode Char (1) Not Null
, valuename Varchar2 (255)
, datavalue Clob
, created Date Not Null
, createdby Number Not Null
, updated Date Not Null
, updatedby Number Not Null
)
Tablespace TDATA
Partition By Range (histEstimationIsn)(Partition p_maxvalue Values
Less Than (maxvalue))
Enable Row Movement;
/*Для скорости одним куском*/
begin
/*Перенос данных за последний час*/
Lock Table Scott.TEST_EXCHANGE In Exclusive Mode Nowait;
insert into Scott.TEST_EXCHANGE_buf
select /*+ index (c X_TEST_EXCHANGE_HISTORY) parallel(32) */ *
from Scott.TEST_EXCHANGE where created>sysdate-1/24;
/*меняем местами промежуточную и основную*/
execute immediate 'Alter table Scott.TEST_EXCHANGE_BUF
Exchange partition p_maxvalue
With table Scott.TEST_EXCHANGE
Without validation'; /*требуется если на исходной или на промежуточной
таблицах есть констрейнты, только так операция будет быстрой*/
end;
/*партиционируем маленькую таблицу*/
Alter table Scott.TEST_EXCHANGE modify
PARTITION BY RANGE (HISTESTIMATIONISN)
INTERVAL (2000000)
(Partition part_1 values less than (2000000))
COMPRESS
Online Parallel 16 Enable row movement;
/* Создание секций заранее вставкой суррогатных данных существенно снизит
конкуренцию при переносе данных в PARALLEL_EXECUTE.
расчетное количество секций 2970.*/
begin
commit;
for i in 1..2970 loop
Insert Into scott.TEST_EXCHANGE
Values ( 28803, 21364838103 + (i * 2000000), 'F', 100, 'R'
, '', '', date'2021-11-07', 0, date'2021-11-07', 0);
rollback;
end loop;
end;
/*перенос из старой таблицы в новую данных за последние 3 года*/
Declare
misn Number;
v_job_name Varchar2 (500) := 'RUN_COPY_TEST_EXCHANGE';
n Number;
Begin
/*ограничиваем по Isn перенос, чтобы не наступить на уже перенесенный
последний час */
Select MIN (isn) Into misn From Scott.TEST_EXCHANGE;
/*перенос из старой таблицы в новую данных за последние 3 года*/
Select COUNT (1)
Into n
From dba_parallel_execute_tasks
Where task_name = 'copy TEST_EXCHANGE';
If n > 0
Then
Dbms_Parallel_Execute.drop_task ('copy TEST_EXCHANGE');
End If;
Dbms_Parallel_Execute.create_task ('copy TEST_EXCHANGE');
Dbms_Parallel_Execute.create_chunks_by_rowid ('copy TEST_EXCHANGE', 'Scott'
, 'TEST_EXCHANGE_BUF', True
, 1000000);
Dbms_Parallel_Execute.run_task ('copy TEST_EXCHANGE' , 'begin
insert into Scott.TEST_EXCHANGE select /*+rowid(h)*/ *
from Scott.TEST_EXCHANGE_BUF h where rowid between :start_id and :end_id
and created>=add_months(trunc(sysdate),-36) and isn < ' || misn || ';
end;', Dbms_Sql.native, parallel_level => 64);
End;
/*создание индекса */
CREATE INDEX Scott.X_TEST_EXCHANGE_HISTESTIMATIONISN
ON Scott.TEST_EXCHANGE(HISTESTIMATIONISN) LOCAL TABLESPACE IDXDATA COMPRESS
parallel 32;
Alter index Scott.X_TEST_EXCHANGE_HISTESTIMATIONISN noparallel;
alter table Scott.TEST_EXCHANGE noparallel;Время условной недоступности составило около секунды. Вуаля!

Комментарии (6)

MaksimIvanov
18.05.2022 12:47-1Спасибо за статью.
Вариант с голденгейтом не рассматривали?
Ну т.е.: слепить, какую надо, целевую таблицу, с какими надо индексами, грантами.
И запустить на неё репликацию из исходной (старой) таблицы.
Когда среплициуются все, или, хотя бы - какие надо строки, собрать цбо-стату на новую таблицу, выставить лок на старую таблицу, репликацию остановить, старую таблицу переименовать, создать синоним на новую таблицу, провайдящий старое имя, доработать целевую таблицу (триггеры например, если надо, создать) валидировать всё что развалидось от удаления старой таблицы.
sirotka Автор
18.05.2022 13:18-1У нас слишком много процессоров, очень дорого. Репликация исторически самописная... одним словом не рационально.
Да и без гейта есть масса вариантов, это просто один из.

belth
19.05.2022 09:40Привет, коллега!
Вариант из топика применялся на боевой задаче? Сколько по времени заняло такое создание чанков? Мне всегда казалось что в этом случае СУБД будет фуллсканить таблицу-источник:небыстрый вариант для непараллельного режима.
А почему секционирование по номеру, а не по дате изменения, например? В дальнейшем не планировалось поддерживать глубину хранения в 3 года?
sirotka Автор
19.05.2022 13:15Да, это вполне пром задача, правда с некоторыми изменениями, исходная чуть шире.
Отдельно чанкование не смотрела, весь перенос целиком - 1 час 30 минут 17 секунд. Создание чанков не фулсканит таблицу при чанках по ROWID.
Не по дате - поскольку запросы к таблице не содержат дат, зато поголовно содержат выбранный ключ партиции. А поле генеримое из сиквенса при наличии поля created позволяет легко поддерживать нужную глубину.
C_M_A
С дебютом ))
o-vakhrusheva
Спасибо!))