Задача
Задачу я встретил, решая упражнения из книги Структура и Интерпретация Компьютерных Программ). Обычно её называют SICP (читается сик-пи) — это аббревиатура названия на английском языке.
Раздел 2.3 посвящён цитированию в LISP и символическим вычислениям.
Обычные — несимволические — вычисления сводятся к расчётам с помощью арифметических операций. Например, если я попрошу вас вычислить производную функции в точке
, вы можете сделать это по формуле при каком-нибудь не очень большом значении
.
Подгоняя , мы можем вычислить производную с хорошей точностью.
Символические же вычисления позволяют нам применить правила выведения производных и получить значение абсолютно точно.
При значение производной будет абсолютно точно равно
.
Реализация на Scheme
SICP предлагает вычислять производную с помощью цитирования. По-английски этот механизм называется quotation.
Если мы вводим в интерпретатор Scheme любое выражение, он вычисляет его сразу.
(+ (/ 1 1) (/ 1 1) (/ 1 2) (/ 1 6) (/ 1 24) (/ 1 120) (/ 1 720) (/ 1 5040))
; => 2.7182539682539684Но если мы предваряем его кавычкой (quote), Scheme сохраняет выражение в виде списка, не вычисляя.
'(+ (/ 1 1) (/ 1 1) (/ 1 2) (/ 1 6) (/ 1 24) (/ 1 120) (/ 1 720) (/ 1 5040))
; => (+ (/ 1 1) (/ 1 1) (/ 1 2) (/ 1 6) (/ 1 24) (/ 1 120) (/ 1 720) (/ 1 5040))Таким образом, мы получаем корректное выражение на LISP и можем обработать его, как любой другой список, в частности, преобразовать по правилам вычисления производной.
Вот простая функция, которая строит производную сумм и произведений.
(define (variable? x) (symbol? x))
(define (same-variable? v1 v2)
(and (variable? v1) (variable? v2) (eq? v1 v2)))
(define (make-sum a1 a2) (list '+ a1 a2))
(define (make-product m1 m2) (list '* m1 m2))
(define (sum? x)
(and (pair? x) (eq? (car x) '+)))
(define (addend s) (cadr s))
(define (augend s) (caddr s))
(define (product? x)
(and (pair? x) (eq? (car x) '*)))
(define (multiplier p) (cadr p))
(define (multiplicand p) (caddr p))
(define (deriv exp var)
(cond ((number? exp) 0)
((variable? exp)
(if (same-variable? exp var) 1 0))
((sum? exp)
(make-sum (deriv (addend exp) var)
(deriv (augend exp) var)))
((product? exp)
(make-sum
(make-product (multiplier exp)
(deriv (multiplicand exp) var))
(make-product (deriv (multiplier exp) var)
(multiplicand exp))))
(else
(error "Unknown expression type"))))Очевидным недостатком функции является сложность получаемых выражений.
(deriv '(+ x 3) 'x)
; => (+ 1 0), это означает 1 + 0
(deriv '(* x y) 'x)
; => (+ (* x 0) (* 1 y)), это озачает 0 * x + 1 * y
(deriv '(* (* x y) (+ x 3)) 'x)
; => (+ (* (* x y) (+ 1 0)) (* (+ (* x 0) (* 1 y)) (+ x 3))), а это вообще сложноИх надо упрощать, для чего может быть написана отдельная функция. Упрощение выражений также рассматривается в SICP.
Реализация на F#
Цитирование на F# всё ещё похоже на цитирование.
let expSquare = <@ fun x -> x * x @>
// => val expSquare : Quotations.Expr<(int -> int)> = Lambda (x, Call (None, op_Multiply, [x, x]))Чтобы получить вместо кода его представление в виде сложного объекта, заключим код в своеобразные кавычки — <@ и @>.
Результатом будет значение типа Expr, с которым можно работать также, как с деревьями выражений в C#.
Вот простая функция, которая строит производную сумм и произведений.
open Microsoft.FSharp.Quotations
open Microsoft.FSharp.Quotations.Patterns
open Microsoft.FSharp.Quotations.DerivedPatterns
let make_sum left right =
let left = Expr.Cast<float> left
let right = Expr.Cast<float> right
<@ %left + %right @> :> Expr
let make_prod left right =
let left = Expr.Cast<float> left
let right = Expr.Cast<float> right
<@ %left * %right @> :> Expr
let deriv (exp: Expr) =
match exp with
| Lambda(arg, body) ->
let rec d exp =
match exp with
| Int32(_) ->
Expr.Value 0.0
| Var(var) ->
if var.Name = arg.Name
then Expr.Value 1.0
else Expr.Value 0.0
| Double(_) ->
Expr.Value 0.0
| SpecificCall <@ (+) @> (None, _, [left; right]) ->
make_sum (d left) (d right)
| SpecificCall <@ (*) @> (_, _, [left; right]) ->
let left = Expr.Cast<float> left
let right = Expr.Cast<float> left
make_sum (make_prod left (d right)) (make_prod (d left) right)
| _ -> failwith "Unknown expression type"
d body
| _ -> failwith "Expr.Lambda expected"
<@ fun (x: double) -> x * x @>
// => Lambda (x, Call (None, op_Multiply, [x, x]))
deriv <@ fun (x: double) -> x * x @>
// => Call (None op_Addition,
// [Call (None, op_Multiply, [x, Value (1.0)]),
// Call (None, op_Multiply, [Value (1.0), x])])Реализация на C#
В C# существует аналог цитирования — деревья выражений. В отличие от F#, здесь нет специальных кавычек для выделения кода. Вместо этого мы указываем тип выражения Expression, а всё остальное делает механизм вывода типов.
Обычные выражения вычисляются сразу.
Func<double, double> square = x => x * x;
sqaure(2) // 4Выражения, которые приводятся к типу Expression, складываются в древовидную структуру, которую мы сможем потом обработать.
Expression<Func<double, double>> expSquare = x => x * x;
expSquare.Compile()(2) // 4Деревья выражений хорошо знакомы многим программистам на C#, поскольку они применяются в библиотеке Entity Framework. Однако, с их помощью можно делать и более сложную обработку.
Вот функция, которая получает на вход лямбда-функцию и применяет её к самой себе.
static Expression<Func<double, double>> DoubleFunc(Expression<Func<double, double>> f)
{
var parameter = Expression.Parameter(typeof(double));
var inner = Expression.Invoke(f, parameter);
var outer = Expression.Invoke(f, inner);
return Expression.Lambda<Func<double, double>>(outer, parameter);
}
var expFourth = DoubleFunc(expSquare);Если два раза применить функцию возведения в квадрат к какому-то числу, мы получим возведение в четвёртую степень.
expFourth.Compile()(2) // 16Я разработал пакет SySharp, который умеет генерировать производные функции по деревьям выражений. Исходный код пакета открыт.
Symbolic.Derivative(x => x * x).ToString()
// => x => ((x * 1) + (1 * x))Там же реализован код для упрощения выражений.
Symbolic.Derivative(x => x * x).Simplify().ToString()
// => x => (2 * x)В отличие от F#, в C# очень просто из дерева выражения получить работающий код.
var d = (Func<double, double>)Symbolic.Derivative(x => x * x).Compile();
d(17)
// => 34Комментарии (21)

NeoCode
06.06.2022 10:31Я знаю C# весьма поверхностно, и не знал что лямбда-функции могут компилироваться в деревья выражений. Как это происходит? Вывод типов настолько мощный, что для выражения
Expression<Func<double, double>> expSquare = x => x * x;он понимает, что не нужно генерировать код для лямбды, а нужно превратить ее в синтаксическое дерево? А для каких объектов это еще работает, кроме лямбд?

markshevchenko Автор
06.06.2022 10:59+3Да, в C# 3.5 завезли именно такой мощный вывод типов. Завозили, чтобы там работал LINQ и им было удобно пользоваться. Работает эта штука и для лямбд, и для других выражений, где используются деревья. Скажем, если LINQ запрос приводить к
IQueryable<T>, он тоже не будет выполняться сразу, его нужно будет во что-то скомпилировать. В Entity Framework такие запросы компилируют в SQL, но можно обращаться и к обычным коллекциям дотнета.

qw1
06.06.2022 19:48imho, тут не нужен вывод типов. Компилятор всегда заранее знает (из контекста), интерпретировать выражение как AST (Expression) или как вычисляемое непосредственно.
NeoCode
06.06.2022 23:09Если я напишу что-то вроде
var v = x => x * x;то что такое v - лямбда или дерево?
qw1
07.06.2022 01:15Это недопустимое выражения для C#
А вот если написать
или такvar v = (int x) => x * x;
будет лямбда, тип указан снаружи, в контексте использования выражения. А такFunc<int,int> v = x => x * x;
Уже будет Expression. Компилятору нужны подсказки из контекста.Expression<Func<int,int>> t = x => x * x;

Refridgerator
06.06.2022 11:04Ещё производные можно считать при помощи дуальных чисел. Это будет попроще манипуляций с деревом выражений и поточнее конечной разности — за исключением особых случаев типа sin(x)/x при x=0.

belch84
06.06.2022 11:31Ещё производные можно считать при помощи дуальных чисел. Это будет попроще манипуляций с деревом выражений и поточнее конечной разности — за исключением особых случаев типа sin(x)/x при x=0.
Аналитическое и численное дифференцирование — это совершенно разные области вычислений. При численном дифференцировании часто требуется находить значения первой и высших производных для функции, заданной не формулой, а поточечно. При этом могут использоваться несколько соседних точек, они позволяют вычислять производную в заданной точке намного точнее.
Кстати, формула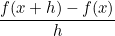 , которую автор приводит в начале публикации, имеет точность порядка h, а формула для вычисления по предыдущей и последующей точкам
, которую автор приводит в начале публикации, имеет точность порядка h, а формула для вычисления по предыдущей и последующей точкам 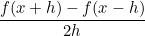 — точность порядка h^2
— точность порядка h^2Refridgerator
06.06.2022 12:00Википедия предлагает ещё вариант с 4-мя и более точками. А если значения функции заданы поточечно, то имеет смысл использовать полиномиальную интерполяцию или МНК.
belch84
06.06.2022 12:38У многоточечных формул для численного дифференцирования есть существенный недостаток — для их применения требуется, чтобы шаг изменения аргумента был постоянным. В общем же случае, например, при применении МНК приходится для каждой точки решать системку линейных уравнений, зависящую от соседних точек — для линейной аппроксимации второго порядка, для квадратичной — третьего и т.д.
Refridgerator
06.06.2022 13:09требуется, чтобы шаг изменения аргумента был постоянным
Не требуется, это просто в готовых формулах используют для удобства — на вики даже ссылка есть для произвольного количества произвольных. Они же получаются тоже из полиномиальной интерполяции — строим аналитический полином по n точкам, а затем он очень просто дифференцируется до нужного порядка. Другой вопрос, что вычислительную точность таким образом увеличить не получится, и это имеет смысл только для производных высшего порядка. А для обычных имеет смысл использовать расширенную точность в промежуточных вычислениях.belch84
06.06.2022 13:38Не требуется, это просто в готовых формулах используют для удобства — на вики даже ссылка есть для произвольного количества произвольных
Сходил по ссылке, не увидел, как там можно пользоваться не равноотстоящими точками. Т.е. пользоваться то можно, конечно, но при изменении относительного положения точек формула изменяется, для получения этой формулы нужно решить систему линейных уравнений, различную для различных значений шагаПоследняя точка - половинный шаг
Когда-то писАл программу, в которой использовалось численное дифференцирование, там формируется и решается маленькая системка на каждом шагеПроцедура для численного дифференцированияprocedure DiffTsNumLS(N:integer; var X,F,DF:LongVector; var RC:SmallInt); { получение производной временного ряда линейной МНК-аппроксимацией } { по соседним точкам } var DiffPnts : integer; i, j, k, jlo, jhi : integer; R, A11, A12, A21, A22, B1, B2, D : real; begin { кол-во точек, по которым стррится линейная аппроксимация } DiffPnts:=2*RcnSmoo+1; for i:=1 to TsCnt do begin { в крайних точках вычисляем по формулам дифференцирования } { назад (в начале) и вперед (в конце) второго порядка } if i <= round((DiffPnts)/2) then begin D:=X[i+1]-X[i]; DF[i]:=(-3*F[i]+4*F[i+1]-F[i+2])/(2*D); end else if i >= TsCnt-round((DiffPnts-1)/2) then begin D:=X[i]-X[i-1]; DF[i]:=(F[i-2]-4*F[i-1]+3*F[i])/(2*D); end { иначе используем линейную аппроксимацию } else begin jlo:=i-round((DiffPnts-1)/2); jhi:=i+round((DiffPnts-1)/2); { формируем лин.систему второго порядка для коэфф.лин.аппрокс.} R:=0.0; for j:=jlo to jhi do R:=R+sqr(X[j]-X[i]); A11:=R; R:=0.0; for j:=jlo to jhi do R:=R+(X[j]-X[i]); A12:=R; A21:=A12; A22:=DiffPnts; R:=0.0; for j:=jlo to jhi do R:=R+F[j]*(X[j]-X[i]); B1:=R; R:=0.0; for j:=jlo to jhi do R:=R+F[j]; B2:=R; { значение производной-коэфф. A в выражении Y=A(X-X0)+B } DF[i]:=(B1*A22-B2*A12)/(A11*A22-A12*A21); end; end; end;
Refridgerator
06.06.2022 14:25Для различных значений шага систему линейных уравнений решать не надо, потому что решение в общем виде достаточно легко выводится через произведение корней и сложение (лень подробно расписывать). Ну типа x*(x-x1)*(x-x2)*(x-x3)… очевидно что в точках x=x1,x=x2,x=x3 полином будет равен нулю.
belch84
06.06.2022 14:31Для различных значений шага систему линейных уравнений решать не надо, потому что решение в общем виде достаточно легко выводится через произведение корней и сложение (лень подробно расписывать)
Возможно, когда вам будет не лень, вы таки выпишете выражения для коэффициентов в общем виде, можно будет сравнить, а пока мне кажется, что приведенная выше работающая процедура является приемлемым простым решениемRefridgerator
07.06.2022 07:09Всё уже придумано до нас и решение в общем виде известно как "Интерполяционный многочлен Лагранжа". Для равноотстоящих точек значения в явном виде выражаются через биномиальные коэффициенты, для произвольных чуть сложнее, но по схожей процедуре, через свёртку — программно несложно реализовать. В сети наверняка есть посвящённые этому работы, написанные чуть более авторитетными людьми.
приведенная выше работающая процедура является приемлемым простым решением
Если вы о процедуре(f(x+h) - f(x-h)) / (2*h)— то она тоже верна только для равноотстоящих точек. Немного погоняв её по тестам подбирая h, я не смог получить точность результата выше половины исходной. Если двукратная потеря точности допустима — то да, вполне приемлемое решение. Но как я уже писал вам когда-то давно, в обработке сигналов такой фокус не всегда прокатит из-за наложения спектра, а коэффициенты (и их необходимое количество) считаются явным образом из произведения производной sinc-функции на оконную функцию. Да и в прочих случаях нет оснований полагать, что исходная функция наилучшим образом аппроксимируется именно полиномом.belch84
07.06.2022 07:42Если вы о процедуре (f(x+h) — f(x-h)) / (2*h) — то она тоже верна только для равноотстоящих точек.
Нет, я о процедуре численного дифференцирования в этом комментарии. Она предназначена для дифференцирования при помощи линейной аппроксимации, работает для переменного шага и позволяет поэкспериментировать с количеством соседних точек. Её можно бы и обобщить, добавив туда параметром степень полинома для аппроксимации, но это уже намного сложнее. И кстати, в результате получится примерно то же самое, что предлагаете вы.
Вообще, как уже неоднократно бывало в дискуссиях с вами, в случае, когда япредлагаюдемонстрирую готовое работающее решение, вы обычно оперируете понятиями типа «программно несложно реализовать». В данном конкретном случае я не хочу сказать ничего кроме того, что явную формулу для численного дифференцирования по соседним точкам имеет смысл выписывать только для постоянного шага, иначе нужно писАть программу (для постоянного шага тоже нужна программа, но простая, состоящая из примененной множество раз одной формулы)Refridgerator
07.06.2022 09:21я предлагаю демонстрирую готовое работающее решение, вы обычно оперируете понятиями типа «программно несложно реализовать»
Ну да. Я могу сделать намного больше, чем уже сделал. И «несложно» не значит написать за 5 минут, а результат уместить в комментарий. «Несложно» значит, что можно написать за несколько часов/дней, а все проблемы в процессе решаются первой строчкой гугла.
Ну вот накидал я класс для работы с полиномами в C#:кодusing System; using System.Text; namespace Polynomial { public class Polynomial { public double[] data; int order = 0; public int Order { get { return order; } } private Polynomial(int order) { this.order = order; data = new double[order + 1]; } public Polynomial(params double[] args) { order = args.Length - 1; data = new double[order+1]; Array.Copy(args, 0, data, 0, args.Length); } public double this[int index] { get { if (index >= data.Length) return 0; return data[index]; } set { if (index >= data.Length) { order = index; double[] data2 = new double[index + 1]; Array.Copy(data, 0, data2, 0, data.Length); data = data2; } data[index] = value; } } public void Scale(double v) { for (int i = 0; i <= order; i++) data[i] *= v; } public double Calc(double x) { double y = 0; for (int i = order; i > 0; i--) { y += data[i]; y *= x; } y += data[0]; return y; } public static Polynomial Add(Polynomial p1, Polynomial p2) { Polynomial p3 = new Polynomial(Math.Max(p1.order, p2.order)); for (int i = 0; i <= p3.order; i++) p3.data[i] = p1[i] + p2[i]; return p3; } public static Polynomial Sub(Polynomial p1, Polynomial p2) { Polynomial p3 = new Polynomial(Math.Max(p1.order, p2.order)); for (int i = 0; i <= p3.order; i++) p3.data[i] = p1[i] - p2[i]; return p3; } public static Polynomial Multiply(Polynomial p1, Polynomial p2) { Polynomial p3 = new Polynomial(p1.order + p2.order + 1); for (int i = 0; i <= p1.order; i++) for (int j = 0; j <= p2.order; j++) p3.data[i + j] += p1.data[i] * p2.data[j]; return p3; } public override string ToString() { string format = "0.0"; StringBuilder sb = new StringBuilder(); sb.Append(data[0].ToString(format)); for (int i = 1; i <= order; i++) { var v = data[i]; if (v >= 0.0) { sb.Append(" + "); sb.Append(v.ToString(format)); if (i == 1) { sb.Append("*x"); } else { sb.Append("*x^"); sb.Append(i.ToString()); } } else { sb.Append(" - "); sb.Append((-v).ToString(format)); if (i == 1) { sb.Append("*x"); } else { sb.Append("*x^"); sb.Append(i.ToString()); } } } return sb.ToString(); } } }
И что? Мне он сейчас не нужен, вам он не нужен тем более, на практике потребуется оптимизация для частных случаев, чтобы не терять в производительности. Впустую потраченное время.
 , которую автор приводит в начале публикации, имеет точность порядка h, а формула для вычисления по предыдущей и последующей точкам
, которую автор приводит в начале публикации, имеет точность порядка h, а формула для вычисления по предыдущей и последующей точкам  — точность порядка h^2
— точность порядка h^2
belch84
Упрощение выражений, конечно же, следует производить прямо в процессе вычисления производной, обрабатывая соответствующие варианты типа: X+0 = X, X*0 = 0, X*1 = X,
это существенно ускорит дальнейшую обработку при дифференцировании сложных выражений с большой вложенностью
markshevchenko Автор
В SICP это предлагают делать именно так, но здесь я предпочёл писать (относительно) простые методы, каждый из которых делают свою работу. Своеобразное переложение принципа единственной ответственности для методов.
В таком подходе есть свои плюсы. Рядом можно написать независимую функцию интегрирования и упрощать её результаты с помощью готового метода. Или написать функцию сложения или умножения выражений, и тоже упрощать результат, просто вызывая
Symplify.Кент Бек советовал следовать трём правилам при написании кода: сначала надо сделать так, чтобы код работал правильно; потом переписать его так, чтобы он был понятен; и лишь в конце его следует оптимизировать, если это, конечно, надо.
Возможно, и есть задачи, где требуется быстро дифференцировать десятки тысяч сложных выражений с большой вложенностью. Пожелаем удачи программистам, которые это пишут. Она им пригодится.
belch84
Есть и еще один аспект — выражения, упрощенные в процессе отыскания выражения для производной, при отладке намного удобнее того, что может получиться при дифференцировании даже относительно простых выражений без упрощений
markshevchenko Автор
Я ещё раз перечитал, прикинул и, думаю, вы правы.