Введение
Наша компания еженедельно размечает порядка 10 миллиардов аннотаций. Чтобы обеспечивать высокое качество аннотаций для такого огромного объёма данных, мы разработали множество методик, в том числе sensor fusion для выявления подробностей о сложных окружениях, активный инструментарий для ускорения процесса разметки и автоматизированные бенчмарки для измерения и поддержания качества работы разметчиков. С расширением количества заказчиков, разметчиков и объёмов данных мы продолжаем совершенствовать эти методики, чтобы повышать качество, эффективность и масштабируемость разметки.
Как мы используем ML
Обширные объёмы передаваемых компании данных предоставляют ей бесценные возможности обучения и надстройки наших процессов аннотирования, и в то же время позволяют нашей команде разработчиков машинного обучения обучать модели, расширяющие набор доступных нам функций.
Мы используем модели ML на протяжении всего конвейера аннотирования, в том числе и в следующих аспектах:
- Предразметке (pre-labeling) для снижения объёма ручного труда разметчиков

- Активном инструментарии для максимизации скорости и эффективности разметчиков
- ML-линтерах для проверки аннотаций разметчиков на наличие потенциальных ошибок
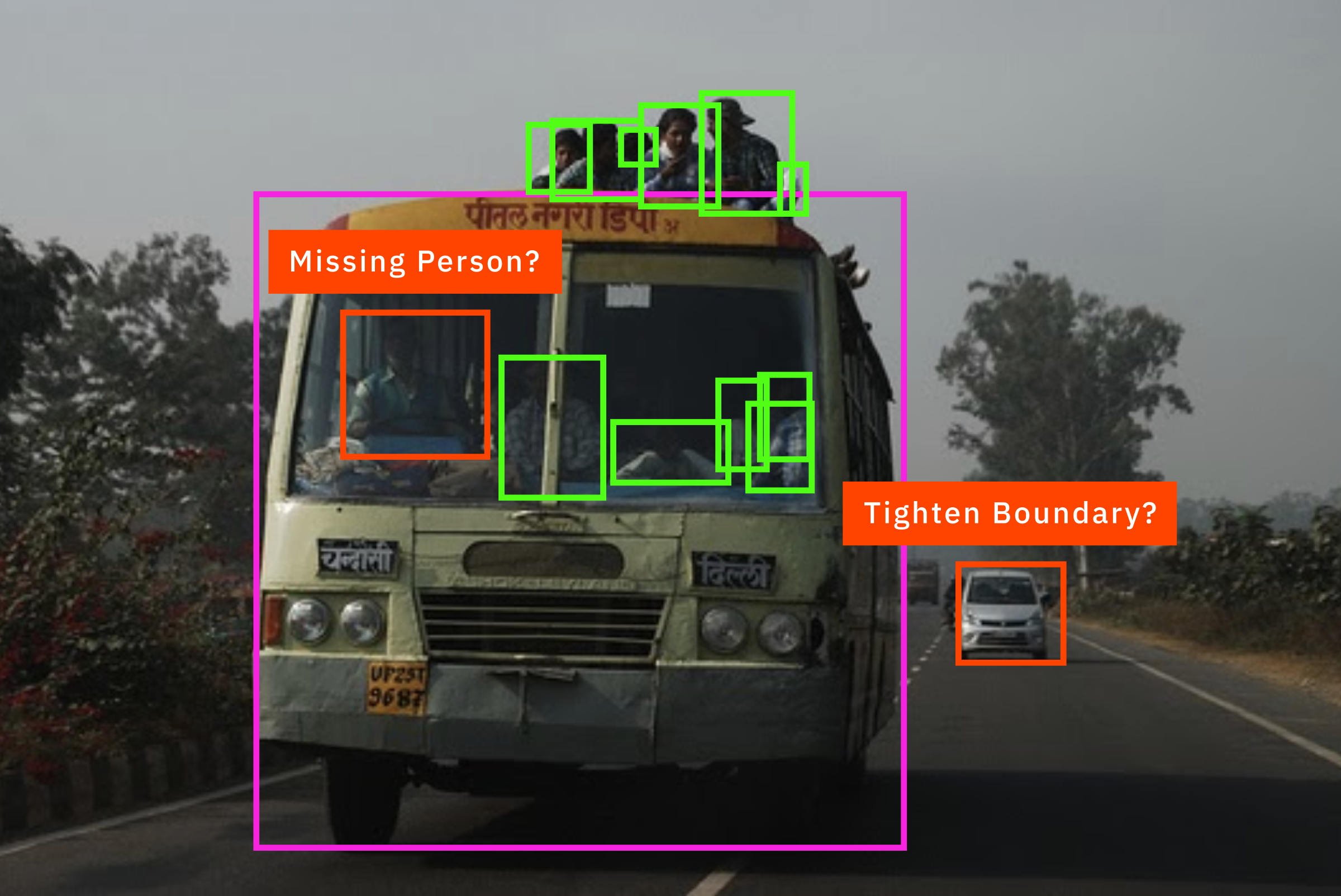
Мы заметили, что модели ML обеспечивают улучшения на порядки величин для каждого компонента нашего конвейера аннотаций. Для наших клиентов это выражается в повышении качества и скорости обработки, а также в снижении стоимости. Поскольку потенциал ML настолько высок, важно, чтобы наши модели имели не только высокую точность, но и высокую масштабируемость. Это означает, что мы сможем предпринимать осознанные шаги по масштабированию машинного обучения для различных клиентов, типов задач и массивов данных.
Сложности работы с объёмными и разнообразными данными
Простейшим решением было бы обучение модели для массива данных каждого из клиентов. Однако такой подход не масштабируется. Если каждый раз, когда клиенту нужен новый массив данных, придётся обучать и внедрять новую модель, это будет очень затратно. Также потребуется существенное время подготовки, прежде чем мы разметим достаточно данных для построения применимой модели. Ещё более важно то, что, судя по исследованиям Google AI, «точность модели растёт логарифмически в зависимости от объёма данных обучения». У нас есть обширный и постоянно растущий объём размеченных данных. Это значит, что обучение отдельных моделей на крошечной доле доступных данных приведёт к пустым потерям потенциального огромного роста точности.
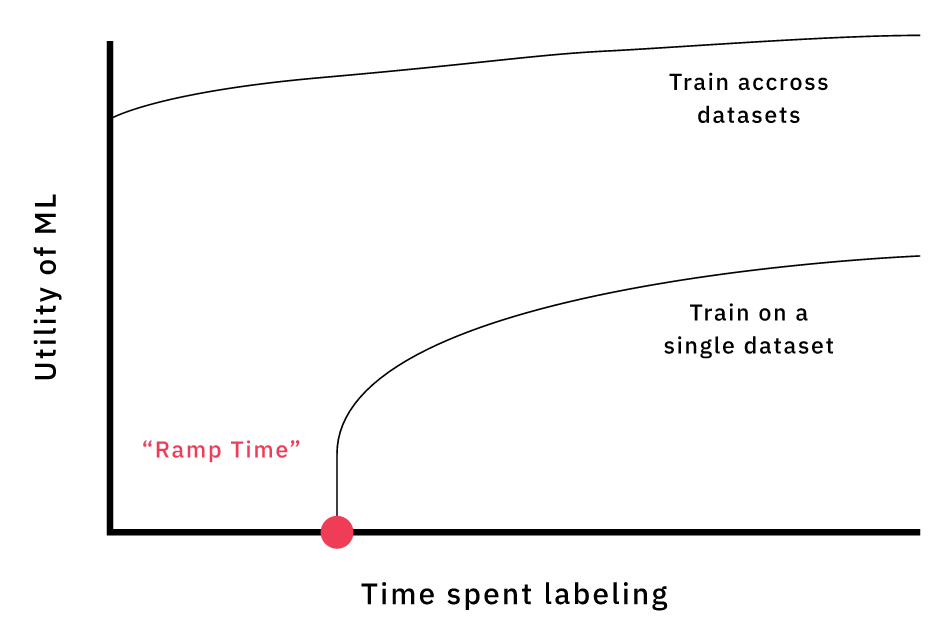
Если обучать модель для каждого массива данных, то придётся тратить время на аннотирование достаточного для использования ML массива обучения. Обучение моделей на разных массивах данных улучшает точность, повышает обобщённость и позволяет не тратить время на подготовку.
Чтобы эффективно использовать наше преимущество в количестве данных, нам необходимо обучать модели на массивах данных разных клиентов. Это снижает затраты на разработку отдельной модели для каждого массива данных, позволяет не тратить время на подготовку, необходимую для обучения практичной модели, а также значительно повышает точность модели. В конечном итоге, это улучшает продукт, создаваемый для наших клиентов. Однако использование моделей для массивов данных различных клиентов усложнено тем, что каждый массив уникален. Основными различиями между массивами данных клиентов являются предметная область данных и таксономия меток.
Предметная область данных

Изображения из разных массивов данных (COCO, Mapillary, KITTI, NuScenes, Waterloo), подчёркивающие разницу предметных областей.
В контексте машинного обучения под предметной областью понимают распределение, из которого были сэмплированы наши данные. Например, в общей предметной области изображений для беспилотного транспорта есть различные факторы, влияющие на распределение данных. В частности:
- Погодные условия и освещённость. (Например, день или ночь, снег или дождь, солнечная или облачная погода.)
- Тип датчика. Он может влиять на перспективу изображения, размеры объектов, контрастность цветов и т. д. Камеры на капоте автомобиля будут считывать данные, отличающиеся от данных, считываемых боковыми камерами.
- Локация. В городской среде больше объектов перекрыто другими объектами по сравнению с шоссе. Мотоциклы встречаются в Таиланде чаще, чем в Германии.
Точность моделей выше всего, когда распределение данных обучения репрезентативно для целевого распределения. В идеале данные обучения и целевые данные должны браться из одной предметной области. Однако в массивах данных наших клиентов присутствуют все перечисленные вариации, а также многие другие.
Таксономия меток
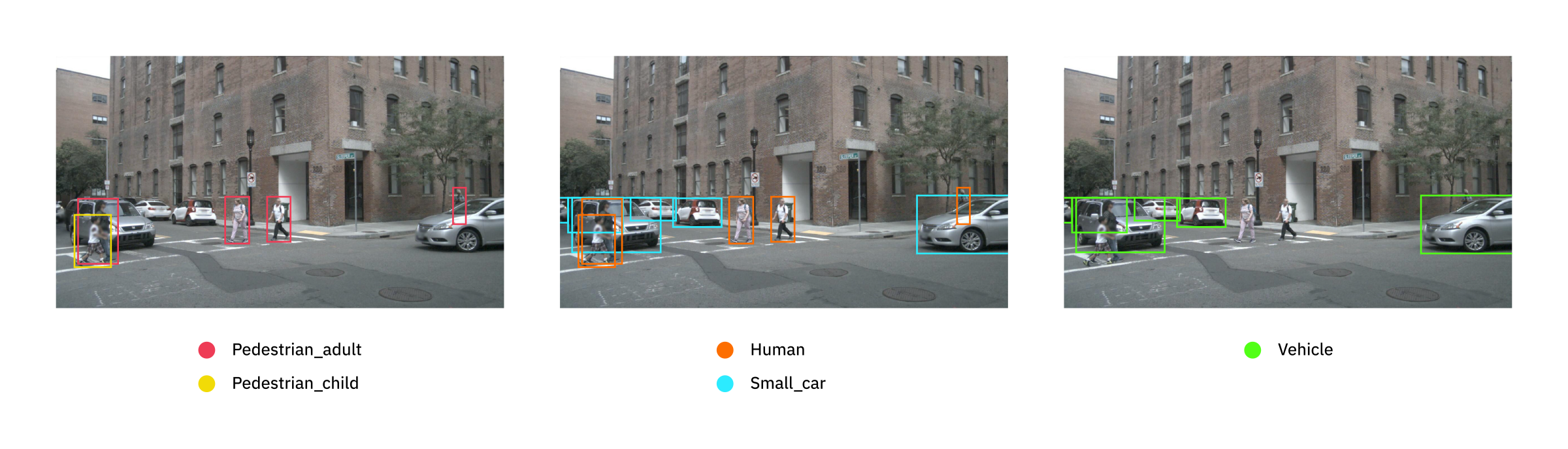
Изображение NuScenes, размеченное согласно трём разным клиентским таксономиям, демонстрирует проблемы с наименованиями и пропущенными метками.
Даже если данные обучения взяты из того же базового распределения, что и целевые данные, метки обучения также должны являться репрезентативными для целевых меток. Однако всем нашим клиентам размечать данные нужно по-разному. Для конкретного массива данных клиент определяет перечень правил, в которых говорится, какие объекты размечать, какие названия им давать, насколько точными должны быть ограничивающие прямоугольники, и т. п. Таксономия (taxonomy) — это сочетание всех таких правил. Различия в клиентских таксономиях создают множество сложностей для обучаемых моделей.
Наиболее очевидная проблема заключается в том, что клиентские таксономии используют разные названия для разметки одинаковых классов объектов. Например, некоторые клиенты могут размечать любого человека как «Human», а другие различают «Pedestrian_adult» и «Pedestrian_child». За время своей стажировки я узнал гораздо больше о нюансах разметки людей, транспорта и дорожных знаков, чем мне бы хотелось.
Ещё бОльшие трудности возникают, когда клиентские таксономии размечают разные массивы классов объектов. Например, на показанном выше рисунке таксономия А размечает только людей, таксономия C — только транспорт, а таксономия B размечает и людей, и транспорт. При обучении распознавателя в объектах людей и транспорта для максимизации точности нам бы хотелось использовать данные из всех трёх таксономий. Однако изображения из таксономии A с неразмеченным транспортом мотивируют модель не распознавать транспорт, а изображения из таксономии C с неразмеченными людьми мотивируют модель не распознавать людей. Эта сложность особенно проблематична, потому что такие «пропущенные метки» систематичны. Как мы говорили в статье Quantity is no Panacea, случайные ошибки разметки можно устранить повышением качества данных обучения, однако систематические ошибки серьёзно влияют на точность модели.
Решение дилеммы таксономий
В этом разделе мы расскажем о шагах, которые мы предпринимаем для решения этих проблем. Обучение на массивах данных различных клиентов должно предоставлять нашим моделям большой и разнообразный массив данных обучения, позволяющий справляться с различиями предметных областей. Однако, чтобы справиться с различиями в таксономиях, нам нужны новые инновационные идеи. Для простоты мы будем рассматривать задачу распознавания 2D-объектов и воспользуемся моделью распознавания объектов SOTA EfficientDet, недавно выпущенной Google Brain. Мы подробно расскажем о трёх разных методиках, исследованных нами для решения дилеммы таксономий: с использованием архитектуры модели, массива данных и функции потерь. В процессе чтения вы узнаете, почему изменение функции потерь при помощи Taxonomy Loss Masking обеспечивает наилучшее решение.
Методика 1: отдельные задачи
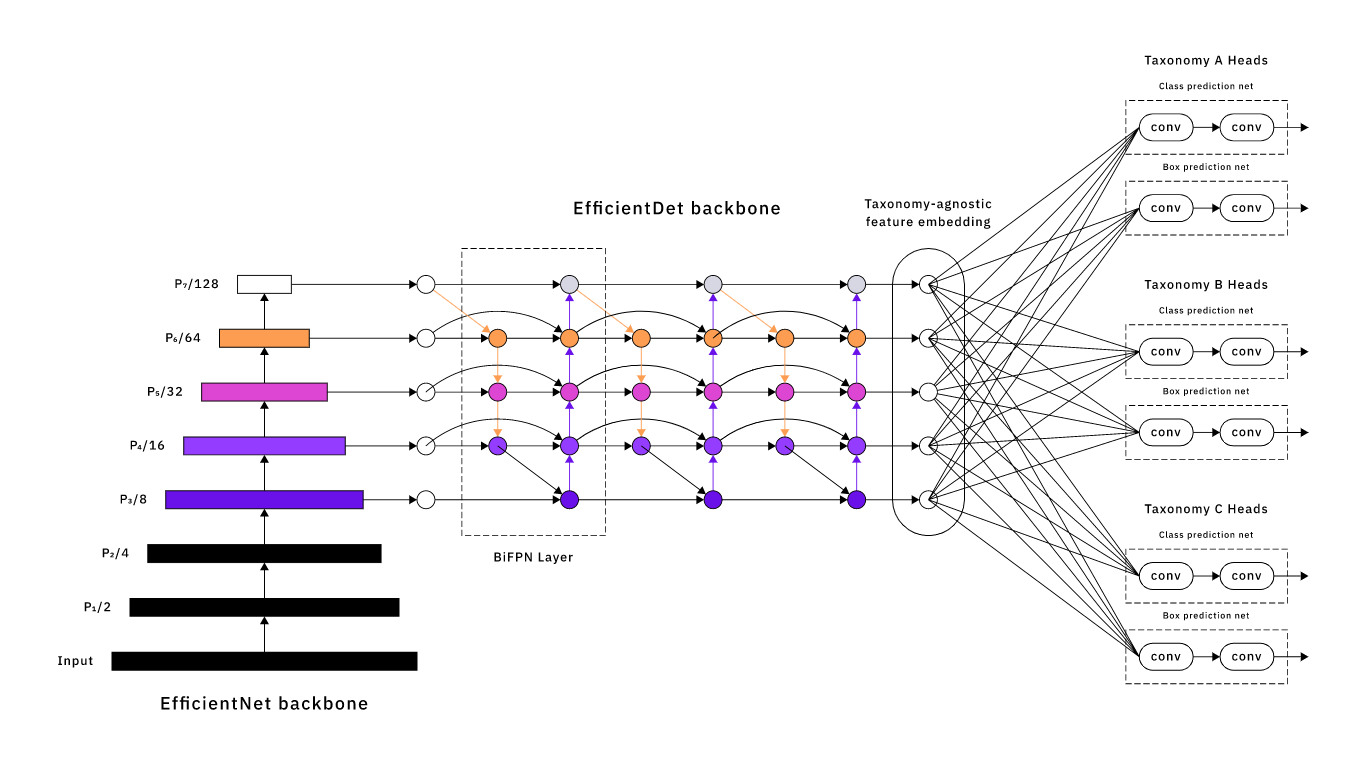
Структура EfficientDet с тремя парами классификаций и regression heads (изменённая версия структуры EfficientDet).
В своей первой методике мы рассмотрели перспективы многозадачного обучения — мы обрабатывали прогноз по таксономии каждого клиента как отдельную задачу. В такой ситуации у нас была общая структура, генерирующая независимый от таксономии эмбеддинг признака, а также пару классификации и regression heads для каждой целевой таксономии клиента (см. рисунок выше). Чтобы учитывать различия в таксономиях, heads таксономий обучались только на примерах, размеченных согласно этой клиентской таксономии. Для обучения/выводов на примере из клиентского массива данных A прогноз выполняют классификация и regression heads таксономии А.
К сожалению, как и в случае обучения модели для каждого массива данных, такой многозадачный подход требует времени на подготовку — нужно аннотировать достаточно примеров для обучения новой head таксономии. Кроме того, затраты на такой подход масштабируются с количеством клиентских таксономий, поскольку нам нужно обучать пару heads для каждой. Более того, эта многозадачная методика заходит в тупик из-за классической проблемы многозадачного обучения: каждая head «борется за объём» (Андрей Карпати, ICML 2019). Существуют сложные корреляции между задачами, поэтому структуре сложно понять репрезентацию, удовлетворяющую им всем. Мы сталкивались с этими явлениями, поскольку наша модель имела посредственную точность.
В этой первой методике используется архитектура модели под названием «class-specific heads», позволяющая справляться с различиями в клиентских таксономиях. Однако нам не удаётся передать модели критически важную информацию: клиентские таксономии тесно связаны.
Супертаксономия
В следующих двух подходах используется понятие «супертаксономии» (super-taxonomy). Вместо того, чтобы напрямую различать клиентские таксономии, мы можем задать общую «супертаксономию», включающую их все. Затем мы можем сопоставить метки в клиентских таксономиях с метками в супертаксономии. Это позволяет нам кодировать наши знания об отношениях между клиентскими таксономиями, обрабатывая каждую из них как подмножество супертаксономии.
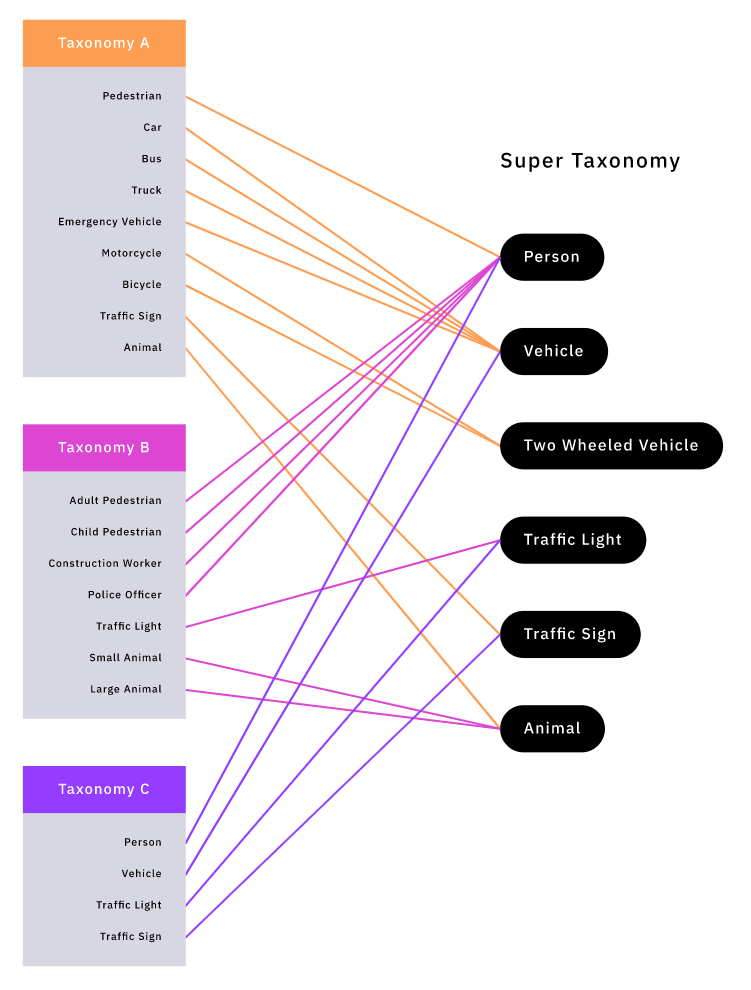
Сопоставление клиентских таксономий и супертаксономии.
Благодаря сопоставлению клиентских меток с метками в супертаксономии отдельные клиентские массивы данных можно объединить в «супермассив» с согласованной схемой наименований. Однако такой супермассив данных страдает от систематической «проблемы утерянных меток», которую мы обсуждали в разделе Таксономия меток.
В качестве пробного базового уровня мы попытались выполнять обучение непосредственно на этом супермассиве данных. Мы были настроены оптимистично, ведь известно, что «для массива данных PASCAL VOC утеря (случайным образом) 30% аннотаций снижает точность всего на 5%» (Soft Sampling for Robust Object Detection). Но даже после использования дополнительных трюков, например, Background Recalibration Loss, получившаяся модель имела ужасающие результаты; вероятно это вызвано тем, что утерянные метки были систематическими, а не случайными.
Методика 2: отдельные массивы данных
При второй методике мы решаем проблему утерянных меток разделением супермассива на отдельные классовые супермассивы, по одному для каждой метки в супертаксономии. Как показано на рисунке ниже, мы решаем проблему утерянных меток в каждом из классовых супермассивов, включая в них только те клиентские таксономии, которые размечают соответствующий класс. Это позволяет нам обучать классовую модель для каждого классового супермассива. Для получения выводов модели мы просто пропускаем изображение через все этих классовые модели и комбинируем их результаты.
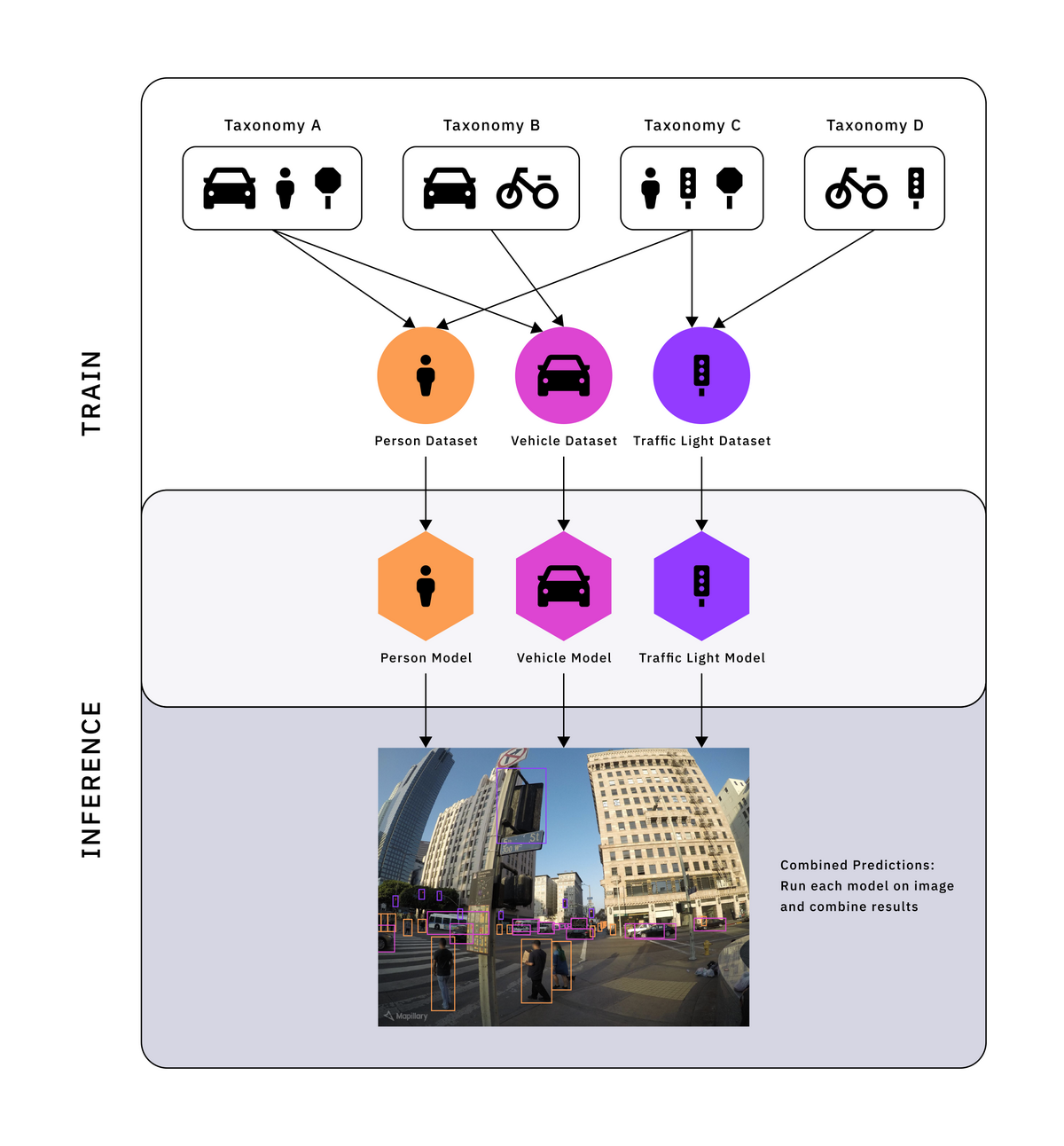
В классовые супермассивы включаются только те клиентские таксономии, которые размечают соответствующий класс. Мы обучаем по одной классовой модели для каждого классового супермассива данных. Результаты работы всех этих моделей комбинируются для получения вывода.
Такая методика даёт хорошую точность, поскольку метки в каждом массиве данных согласованы и каждая модель обучается хорошей общей репрезентации для своего класса. Использование такого количества моделей будет неприменимо на практике для наших клиентов, занимающихся беспилотным транспортом, из-за ограниченных вычислительных ресурсов и строгих требований к задержкам, связанным с восприятием. Однако такие ограничения неприменимы к нам, поскольку разметка выполняется в течение гораздо большего интервала времени, чем происходит восприятие. Кроме того, использование отдельных моделей даёт и ещё одно преимущество — мы разрываем связь точности между классами; например, мы можем повторно обучить модель распознавания транспорта, не влияя на точность всех остальных классов.
При такой методике затраты на обучение и выводы масштабируются в зависимости от количества классов в нашей супертаксономии, а не от количества клиентских таксономий. Если супертаксономия мала, то это серьёзный шаг вперёд по сравнению с методикой многозадачности. Однако наши супертаксономии часто довольно велики. Такой подход нежелателен, потому что требует наличия множества отдельных моделей, которые в теории могут иметь одинаковые признаки. Мы бы предпочли использовать единую модель.
Методика 3: Separate Loss — Taxonomy Loss Masking
Что если не будем сообщать модели о различиях в клиентских таксономиях через архитектуру или через отдельные массивы данных, а будем вносить это разделение через функцию потерь? Чтобы ответить на этот вопрос, надо внимательнее присмотреться к тому, как обучается модель.
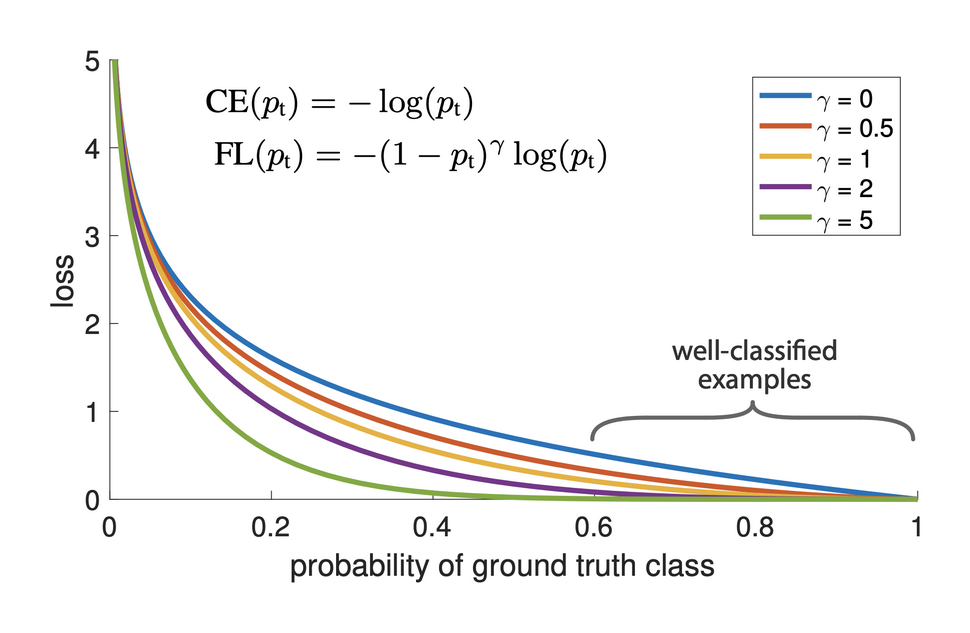
Focal Loss устраняет дисбаланс классов, изменяя веса бинарной перекрёстной энтропии.
Одноэтапные распознаватели наподобие EfficientDet распознают объекты, делая прогнозы во множестве заранее заданных anchor boxes. Пусть A — количество anchor boxes, а K — количество целевых классов объектов. Head классификатора EfficientDet прогнозирует матрицу вероятностей P ∈ RAxK, где Pij — вероятность того, что в anchor i есть экземпляр класса j. Модель обучается при помощи Focal Loss — стандартной функции потерь для устранения крайнего дисбаланса классов в одноэтапных распознавателях. Как показано на рисунке ниже, эта функция потерь применяется к прогнозам для «положительных» и «отрицательных» anchors. Функция потерь не применяется к прогнозам для «неназначенных» anchors — эти значения маскируются при обучении, потому что они передают модели неоднозначные сигналы.
Мы поняли, что поскольку распознаватель учитывает классы (в отличие от более общей, не учитывающей классы Region Proposal Network в двухэтапных распознавателях), можно использовать похожую схему маскировки потерь, чтобы решить дилемму таксономий. Кроме маскирования потерь, возникающих в связи с anchors (строками) на основании IoU, мы маскируем потери, возникающие в связи с целевыми классами объектов (столбцами), если класс «отсутствует» в соответствующей клиентской таксономии. Если пример для обучения взят из клиентской таксономии, не содержащей «Vehicle», то мы знаем, что объекты «Vehicle» не размечаются, поэтому вероятность «Vehicle» для каждого anchor box игнорируется, а соответствующие значения потерь маскируются. Мы задаём «маску отсутствующей метки» ∈ (0,1)K для каждой клиентской таксономии, сообщающую, какие классы (столбцы) нужно маскировать при обучении на примере из этой клиентской таксономии. При создании выводов модель создаёт прогнозы для всех классов. Мы называем эту методику Taxonomy Loss Masking.
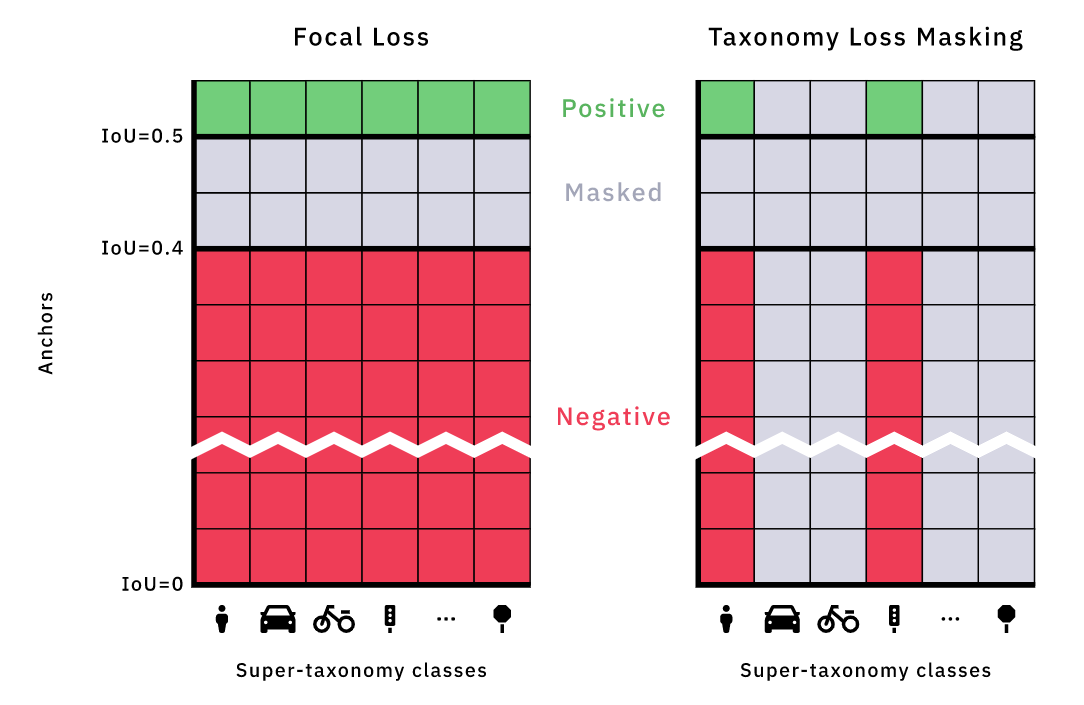
Слева: маскировка в Focal Loss. Мы показали P ∈ RAxK — матрицу вероятностей, спрогнозированную head таксономии, где Pij — вероятность наличия в anchor i экземпляра класса j. Anchors (строки) отсортированы по IoU с ближайшими эталонными данными аннотаций: зелёные строки имеют IoU >= 0.5, а красные строки — IoU менее 0,4. Focal Loss применяется к этим «положительным» и «отрицательным» anchors. Однако anchors с IoU в интервале [0,4, 0,5) не являются ни положительными, ни отрицательными. Они «не назначены» и их потери маскируются. Справа: Taxonomy Loss Masking. При обучении на примере из клиентской таксономии, размечающей только Traffic Light и Person, потери для всех остальных классов (столбцов) маскируются.
По сути, Taxonomy Loss Masking — это многозадачная методика для классов супертаксономии без параметров задач, использующая только полностью общую архитектуру и изменяющая только функцию потерь. Такая методика использует максимум информации об априорном распределении: таксономии тесно связаны, в некоторых таксономиях систематически «отсутствуют метки», и модель должна иметь возможность объединять признаки между классами. Эта методика не только проще двух предыдущих, но и обеспечивает отличную точность; ещё она дешевле и лучше масштабируется.
Хотя мы в основном занимаемся распознаванием 2D-объектов в области изображений для беспилотного вождения, можно использовать вариации Taxonomy Loss Masking в разных предметных областях и для разных типов задач, в том числе для распознавания 3D-объектов, семантической сегментации в 2D/3D, и т. д.
Вы можете задаться вопросом
«Модель прогнозирует метки только в супертаксономии, но не в самих клиентских таксономиях. Разве она не является неполной?»
Хороший вопрос. Мы можем прогнозировать метки в клиентских таксономиях при помощи иерархии классификаторов и иерархической супертаксономии. Каждый уровень иерархии классификаторов делает более точный прогноз в супертаксономии и использует свою «маску отсутствующих меток». Классификаторы даже могут прогнозировать атрибуты объектов: например, транспортное средство может быть припарковано или частично перекрыто другим объектом.
Но помните, что наши модели используются для помощи и ускорения работы наших живых разметчиков. Так как наши разметчики выполняют распознавание объектов, самой сложной частью разметки является распознавание. Классификацию выполнять очень просто, поскольку это всего лишь вопрос с несколькими вариантами ответа. Хоть мы и пытались решить задачу полностью, на самом деле нам это не нужно; нам достаточно сосредоточиться на самой затратной части — распознавании. Во время стажировки это различие показалось мне особенно интересным и важным.
«Есть ли другие различия в клиентских таксономиях, которые приходится учитывать?»
У некоторых клиентов есть отличающиеся правила разметки. Например, одним клиентам нужно, чтобы ограничивающие транспортные средства прямоугольники включали в себя боковые зеркала, а другим — чтобы в них был только кузов автомобиля. Допустим, мы хотим, чтобы модель включала боковые зеркала. Если мы обучаем её на данных из Таксономии A, учитывающей боковые зеркала, и Таксономии B, не учитывающей их, то вес потерь регрессий для экземпляров из Таксономии A будет выше. Ещё один способ научить модель включать боковые зеркала — создать избыток выборки данных из Таксономии A во время обучения или точно настроить модель на Таксономии A после обучения.

Различия в правилах разметки. В левый ограничивающий прямоугольник включены боковые зеркала, а в правый нет.
Operation Vacation
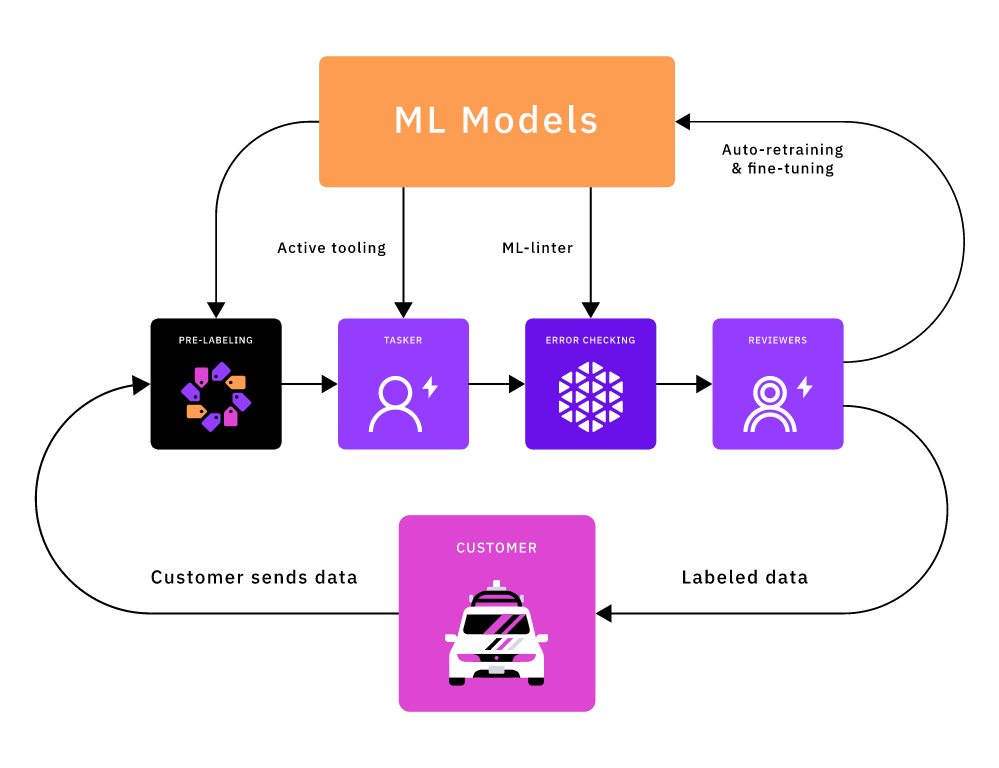
Модели машинного обучения стали огромным подспорьем для нашего цикла аннотирования данных. Пока наши клиенты будут присылать свои данные, а наши разметчики будут продолжать разметку, наши модели будут совершенствоваться, ускоряя процесс разметки и продлевая этот эффективный цикл.
Выше уже говорилось, что важно обучать наши модели на максимально возможном объёме данных. Количество наших данных для обучения растёт по двум основным осям — по количеству массивов данных клиентов и по времени, которое мы тратим на разметку этих массивов данных. Taxonomy Loss Masking позволила нам масштабировать данные для обучения модели по оси клиентов. Так как наши разметчики постоянно размечают данные, а размер массивов данных со временем растёт, важно обеспечивать масштабирование и по оси времени. Иными словами, мы должны продолжать обучать модели в процессе получения новых размеченных данных.
Недавняя совместная работа PyTorch, Дэниела Хавира из Scaliens и Нэйтана Хейфлика показала, как мы способны использовать асинхронный поток данных для обучения на основе крупных и увеличивающихся массивов данных. Эта методика наряду с инновационной облачной инфраструктурой и распределённым обучением позволяет нам автоматически обучать модели в процессе накопления новых данных. Мы используем эту систему для расширения возможностей производительности моделей как в обучении на супертаксономиях, так при точной настройки под отдельные клиентские массивы данных.
Кроме того, Дэниел и Нэйтан продемонстрировали, как мы используем хэширование для получения согласованного разделения увеличивающегося массива данных на данные для обучения и тестирования. Это значит, что наши массивы для обучения и тестирования смогут расти с одинаковой скоростью. Сделав постоянным тестовый массив, мы можем ожидать повышение точности модели при продолжении обучения на увеличивающемся массиве для обучения. С другой стороны, если сделать постоянной модель, мы сможем исследовать точность на когортах старых и новых примеров в тестовом массиве. Изменения в точности модели по этой оси говорят о постепенном дрейфе распределения данных, и это означает, что клиент отправляет нам другие данные. Это пример того, как мы можем автоматически отслеживать точность моделей.
Аналогично Operation Vacation Андрея Карпати, мы используем эти системы обучения и мониторинга для автоматизации процесса обучения модели. Это экономит время на разработку и позволяет нашей команде машинного обучения сосредоточиться на поиске новых способов совершенствования конвейера аннотирования с ML. Пока наши клиенты будут присылать свои данные, а наши разметчики будут продолжать разметку, мы сможем «взять отпуск». Наши модели будут совершенствоваться, ускоряя процесс разметки и продлевая этот эффективный цикл.
zartdinov
Кажется, на первой картинке не отметили человека слева, который собирается переходить дорогу.