Если вы хоть раз сохраняли фото в формате JPEG, вы возможно знаете, насколько ужасно могут выглядеть джипеги. Десятилетия доминирования этого формата привели к тому, что у многих интернет-пользователей сформировалась стойкая аллергия к тому, что называется «артефакты JPEG».

Лувр. 480×245 пикселей, сильно сжатый JPEG
Без сомнения, никто бы не хотел делиться таким месивом пикселей с кем-то. Если бы вы спросили меня, что конкретно не так с этим изображением, я бы сказал, что в целом оно выглядит довольно близко к оригиналу: нет существенных искажений цветов, объекты узнаваемы. Однако я бы сказал, что тут есть две огромные проблемы:
- Мягкие градиенты выглядят как раздельные блоки или цветные полосы. Это особенно хорошо заметно на небе, но то же самое можно заметить и на земле.
- Есть паразитные цветовые градиенты вокруг четких объектов (взгляните на крышу) и мелких объектов. Такой эффект называется «звон».
Позвольте показать немного магии. Сейчас я применю эти два эффекта независимо друг от друга!
| Оригинал | Звон | Цветовые полосы |
|---|---|---|
 |
 |
 |
Итак, левая картинка — это ориентир с максимальным качеством. Центральное изображение сильно сжато, но на нем есть только артефакты звона, тогда как на правом изображении только цветовые полосы. Все три изображения — настоящие джипеги, созданные с помощью обычной библиотеки libjpeg, никакого фотошопа.
Оба изображения, со звоном и с цветовыми полосами, выглядят неприемлемо. Но тут есть один трюк, на самом деле я слегка увеличил размеры картинок на этой странице. То что вы видите — это картинка шириной 480 пикселей в сумме, растянутая до 600 CSS-пикселей на экране. Можно сказать, что это плотность пикселей 0.8x. Современные экраны часто имеют плотность пикселей 2x и даже больше. Для таких экранов привычной техникой является распространение изображений с плотностью пикселей 2x (относительно CSS-пикселей) с минимально возможным качеством.
Так что изменится, если мы попытаемся сделать то же самое с картинками с двойной плотностью пикселей на экране? Вот те же самые эффекты:
| Оригинал | Звон | Цветовые полосы |
|---|---|---|
 |
 |
 |
Признайтесь, вы подумали на секунду, что тут какая-то ошибка? Тут нет ошибки, центральное изображение действительно выглядит превосходно, почти как левое. В отличие от правого, которое выглядит так же ужасно, как это было при плотности пикселей 0.8x.
Просто потрясающе, что человеческий глаз не чувствителен к артефактам звона при маленьком масштабе. Если увеличить страницу, можно увидеть, что сильный звон всё еще присутствует, просто мы его не замечаем.
Постановка проблемы
То, что мы не видим звон — само по себе очень интересно, но какую пользу мы можем извлечь из этого факта? Ключ к пониманию выше. Для плотности пикселей 2x нам нужно выбирать «минимально возможное качество» (хотя это в принципе верно для любой плотности пикселей). Мы должны выбрать качество, которое не приведет к появлению значительных артефактов.
Проблема заключается в том, что с уменьшением качества, и звон, и цветовые полосы начинают появляться на изображении. На практике это означает, что чаще всего нам приходится выбирать качество, которое не приводит к появлению цветовых полос.
Но что если бы мы могли уменьшить качество ещё сильнее и это бы не приводило появлению цветовых полос?
Чтобы ответить на этот вопрос, нужно разобраться в том, как работает сжатие JPEG. Но не переживайте, описание будет сильно упрощенным.
Краткий экскурс в сжатие JPEG
Первое, что нужно знать — JPEG сжимает изображение небольшими блоками, размером 8x8 пикселей. Вы даже могли их заметить на любом примере сильно сжатых изображений выше. И да, границы цветовых полос совпадают с этими блоками.
Далее, кодек JPEG не сохраняет значения пикселей напрямую. Вместо этого, каждый блок сопоставляется с 64 возможными шаблонами частот, и коэффициенты для этих шаблонов сохраняются в файле. Подробнее об этом процессе вы можете прочитать в статье Потери качества JPEG (eng).
Взгляните на таблицу:
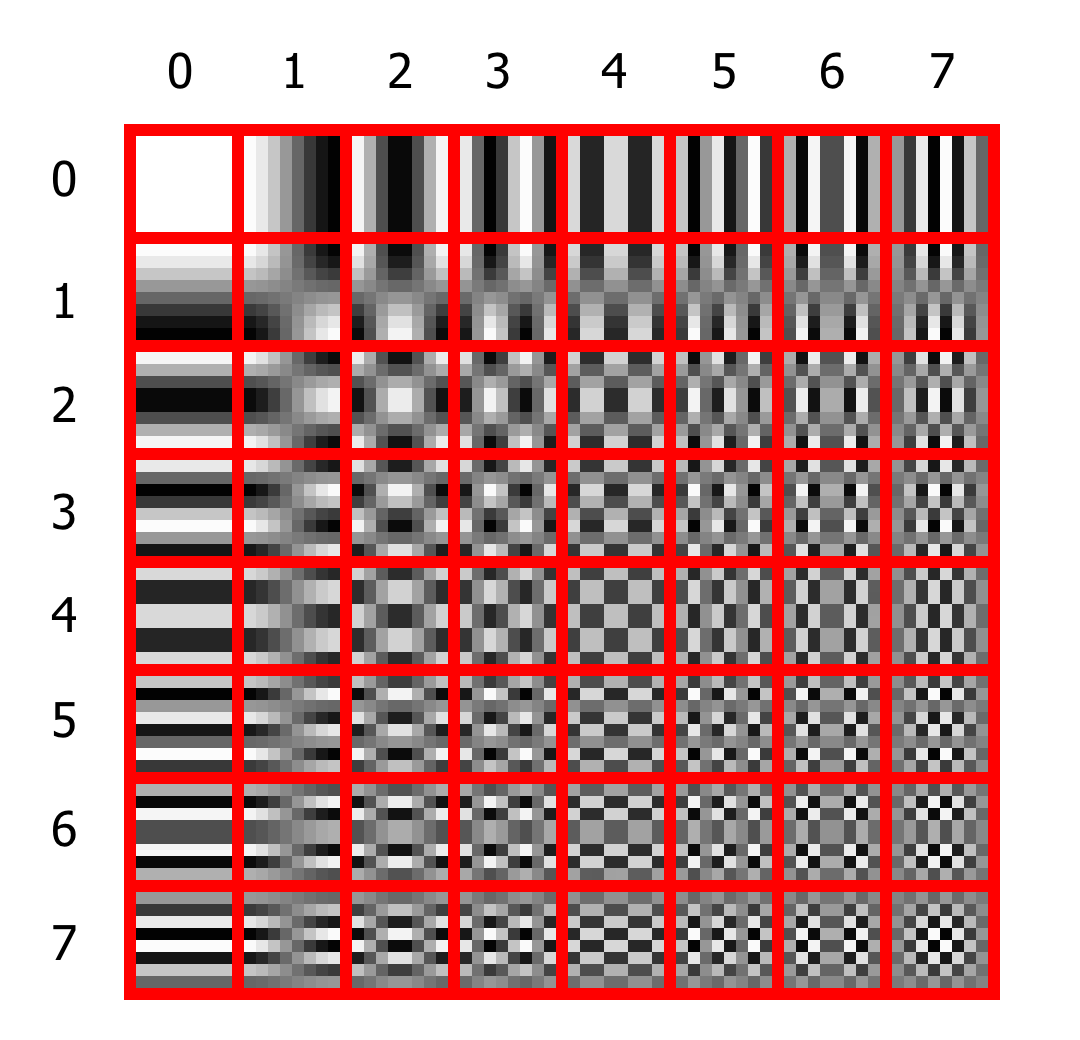
Шаблоны частот для блока 8×8 пикселей
Каждая ячейка имеет до 7 переходов цвета сверху вниз и до 7 слева направо. Шаблоны первой строки не имеют перехода сверху вниз, шаблоны второй строки имеют один такой переход и так далее. То же самое для колонок и горизонтальных переходов.
Вы можете восстановить любой блок изображения, взяв каждый шаблон с определенным коэффициентом. Например, если все пиксели внутри блока имеют одинаковый цвет, вам нужен коэффициент только для первой ячейки, все остальные коэффициенты будут равны нулю. Для более сложных узоров нужны будут коэффициенты для нескольких шаблонов. Такое преобразование называется Дискретной Косинусной Трансформацией (DCT).
Вплоть до этого момента не происходит компрессии с потерями. Вы можете совершенно точно восстановить оригинальное изображение используя коэффициенты для DCT. Чтобы сократить реальное количество данных, которое хранится в файле, используются таблицы квантования. Таблица всего лишь говорит кодировщику, сколько данных нужно срезать с каждого коэффициента. Вот например базовая таблица квантования из библиотеки libjpeg:
static const unsigned int std_luminance_quant_tbl[DCTSIZE2] = {
16, 11, 10, 16, 24, 40, 51, 61,
12, 12, 14, 19, 26, 58, 60, 55,
14, 13, 16, 24, 40, 57, 69, 56,
14, 17, 22, 29, 51, 87, 80, 62,
18, 22, 37, 56, 68, 109, 103, 77,
24, 35, 55, 64, 81, 104, 113, 92,
49, 64, 78, 87, 103, 121, 120, 101,
72, 92, 95, 98, 112, 100, 103, 99
};Первый элемент, 16, означает, что кодировщик должен поделить коэффициент для первого шаблона на 16 прежде чем сохранить в файл. Поэтому, вместо сохранения значения от 0 до 255 (8 бит), нужно будет хранить лишь значения от 0 до 15 (4 бита), что займет существенно меньше места.
Выходит, что чем больше значения в таблице квантования, тем более агрессивная компрессия применяется и тем ниже качество конечного JPEG файла.
Как работает параметр quality
Допустим, что так и есть, но откуда берется эта таблица при сохранении файла? Было бы ужасным усложнением, если бы для каждого файла нужно было бы придумать и передать кодировщику 64 независимых значения таблицы. Вместо этого большинство кодировщиков JPEG предоставляют простой интерфейс, который позволяет выставить все 64 значения одновременно. Это тот самый хорошо известный параметр quality, изменяемый от 0 до 100. Кодировщик получает от нас число и просто масштабирует значения в некой базовой таблице квантования. Чем выше заданное quality, тем меньше будут значения в конечной таблице квантования.
Теперь, когда мы знаем как работает компрессия JPEG, мы можем наконец сказать, что цветовые полосы — это всего лишь результат слишком сильного квантования низкочастотных коэффициентов, то есть слишком больших значений в верхнем левом углу таблицы квантования.
Хорошая новость заключается в том, что хотя большинство кодировщиков позволяют задать параметр quality, некоторые из них так же позволяют задать произвольные таблицы квантования при сохранении. А ещё мы можем прочитать уже готовые таблицы из ранее сохраненных файлов. Это означает, что можно достать таблицу квантования кодировщика для определенного уровня quality и поменять её как нам нужно, не придумывая её с нуля:
from io import BytesIO
from PIL import Image
qtables_by_q = []
empty = Image.new('RGB', (8, 8))
for q in range(101):
with BytesIO() as buf:
empty.save(buf, format='JPEG', quality=q)
qtables = Image.open(buf).quantization
qtables_by_q.append(qtables)
Image.open('in.jpg').save('out.jpg', qtables=qtables_by_q[10])Решение
Мы уже поняли, что нужно исправить низкочастотные значения в верхнем левом углу таблицы квантования. Но какие именно и как исправить?
После долгих экспериментов я пришел к выводу, что только самый первый элемент оказывает наибольшее влияние на цветовые полосы. Для теста я ограничил максимальное значение в таблице для канала яркости значением 10, а для цветовых каналов 16. Такие значения делают цветовые полосы едва ли различимыми для меня.
Я приведу несколько примеров, где левое изображение — минимальное приемлемое по моему мнению качество с таблицами квантованию по-умолчанию, изображение по центру — минимальное приемлемое качество с исправленными таблицами, а изображение справа — изображение с таблицами квантованию по-умолчанию, но максимально приближенные по размеру к исправленному варианту.
| Сопоставимое качество | Исправление | Сопоставимый размер |
|---|---|---|
 |
 |
 |
| Q50, 23 Kb | Q15 + fix, 11 Kb | Q18, 11.1 Kb |
 |
 |
 |
| Q50, 24.5 Kb | Q20 + fix, 14.6 Kb | Q22, 14.5 Kb |
 |
 |
 |
| Q40, 24.5 Kb | Q20 + fix, 15.8 Kb | Q22, 15.8 Kb |
 |
 |
 |
| Q25, 18.4 Kb | Q16 + fix, 15 Kb | Q19, 15.3 Kb |
 |
 |
 |
| Q32, 22 Kb | Q24 + fix, 19.5 Kb | Q26, 19.4 Kb |
 |
 |
 |
| Q30, 25.6 Kb | Q24 + fix, 24.1 Kb | Q27, 24 Kb |
 |
 |
|
| Q11, 19.8 Kb | Q10 + fix, 20.3 Kb |
Очевидно, что результат отличается от картинки к картинке. В редких случаях размер с исправленной версией получается сопоставимый или даже слегка больше, чем с таблицами по-умолчанию. Тем не менее, нет сомнений, что паттерн, который страдает от излишних цветовых полос, часто встречается среди различных изображений. Без данного фикса приходится сильно задирать quality, чтобы избавиться от цветовых полос.
На практике, вы часто не можете подбирать значение quality для каждого изображения вручную. Приходится выбирать единое значение, которое бы не портило большинство обрабатываемых изображений. Без данного фикса, такое качество находится на уровне 50, в то время как с данным фиксом, quality можно уменьшить до 25. В среднем это дает 33% уменьшение размера файлов для 2x плотности пикселей, что является огромным выигрышем.
Текущий статус
С самого начала мы не давали нашим пользователям выставлять уровень quality в виде числа. На то было много причин: одно и то же число означает разное для разных форматов и даже кодеков. Число не дает выставить другие параметры компрессии, например субсэмплинг (eng) . И, возможно, самое важное, указание качества через число не совместимо с автовыбором формата, когда один и тот же URL возвращает изображения в разном формате для разных клиентов.
Вместо этого, мы предлагаем пользователям выбрать один из пяти уровней качества и ещё два «умных» уровня, когда качество для изображения подбирается индивидуально используя компьютерное зрение.
Сегодня мы ещё раз можем убедиться в правильности такого подхода.
Так как для двойной плотности пикселей мы уже отдавали quality ниже 50, сейчас мы остановились на том, что ограничили первый элемент в таблице квантования для всех JPEG файлов. Это привело к тому, что для уровней качества, рассчитанных на двойную плотность пикселей, размер файла мог увеличиться от 2% до 5%. Но зато мы полностью избавились от цветовых полос.
Открытие того, что пользователь по-разному воспринимает артефакты сжатия в зависимости от плотности пикселей очень важно. Это дает простор для дальнейшего уменьшения размера файлов без значительной визуальной потери качества. Я намерен и дальше экспериментировать c таблицами квантования, т.к. очевидно, что таблицы по-умолчанию были разработаны для одинарной плотности пикселей и не соответствуют современным требованиям.
Комментарии (15)

nin-jin
24.06.2022 08:39Открытие того, что пользователь по-разному воспринимает артефакты сжатия в зависимости от плотности пикселей очень важно. Это дает простор для дальнейшего уменьшения размера файлов без значительной визуальной потери качества.
Уменьшить число пикселей в 4 раза, но увеличить уровень качества? Ели человек не различает столь мелких деталей, то их можно безболезненно убрать.

Tarakanator
24.06.2022 09:16я думаю примерно так думали создатели видеоформатов. Где снизили цветовое разрешение, но оставив яркостное.

homm Автор
24.06.2022 12:13+5> Если человек не различает столь мелких деталей
Если бы не замечал, не было бы никакого смысла в большей плотности пикселей. А он точно есть. Сравните два изображения, первое q=15 + fix, subsampling=420, второе q=79 без субсемплинга, оба 25 кб. Разница колоссальная.

Тут несколько иное, видимо мы не замечаем флуктуаций на мелком масштабе, они сглаживаются. А более устойчивые детали вполне замечаем.nin-jin
24.06.2022 12:25-3Так в нём и нет никакого смысла. И ваши примеры это прекрасно иллюстрируют - никакой разницы я как пользователь не вижу - обе картинки шакальные. Что уж говорить про людей с не таким хорошим зрением, как у меня..
homm Автор
24.06.2022 14:49+1Давайте уточним: вы смотрите комментарий выше (именно комментарий, а не открываете картинки чтобы зазумить на 800%) на high DPI экране (иначе как вы хотите увидеть разницу) и не видите разницу между первой (2x плотность пикселей) и второй картинкой (1x плотность пикселей)?
nin-jin
24.06.2022 14:56-1Открою вам секрет - обычные пользователи не играют в игру "найди 10 отличий" с каждым изображением и не зумят шакальные картинки на 800%.

iShrimp
24.06.2022 17:40Похоже, на правом фото мелкие детали ещё и испорчены отсутствием гамма-коррекции (gamma-aware алгоритм не позволил бы светлым штрихам потерять яркость).


vasilisc
Увлёкся нейронными сетями, в том смысле, что запускаю их на своих мощностях и пытаюсь разбираться в их сферах применимости. В коллекции много нейронных сетей и среди них есть SwinIR, которая умеет убирать артефакты сжатия JPEG (JPEG Compression Artifact Reduction), НО только для gray изображений.
https://github.com/JingyunLiang/SwinIR
http://vasilisc.com/learn-neural-networks
homm Автор
А почему нельзя тот же алгоритм применить к трем каналам (YCbCr) по отдельности, чтобы получить полноцветное изображение? Потенциальные проблемы могут быть с субсемплингом, но в крайнем случае можно лишний раз свернуть цветовые каналы, применить алгоритм, развернуть снова.
Alexey2005
«Съедаются» текстуры. И в случае нескольких каналов этот эффект становится в разы заметнее. Для примера очистил нейронкой КДПВ из вашей статьи. Согласитесь,
Выхлоп нейронки:
homm Автор
Результат выглядит в разы лучше, чем КДПВ.
В последнее время я вообще много думаю над философией сжатия с потерями. Пока что, я пришел к пониманию, что глобально есть два, можно сказать, противоположнонаправленных юзкейса.
Хранение. Нужно сохранить максимум информации из оригинально изображения, при этом допускается равномерная потеря информации. То, с чем классический JPEG справляется отлично и с успехом конкурирует с новыми форматами на высоких битрейтах.
Демонстрация. Тут количество потерянной информации уже играет второстепенную роль, на первый план выходит непротиворечивость изображения при меньшем битрейте. То есть, условно, мы можем смириться, что какая-то текстура или дымка пропадут с изображения полностью, если это не будет выглядеть шакально.
И вот во втором юзкейсе JPEG уже значительно проигрывает современным форматам. Главным образом потому что ограничен окном 8x8 пикселей и за пределами него не может решить потерять детали. Очень рекомендую прочитать раздел What is 'acceptable quality' этой замечательной статьи.
И ваш результат как раз пример работы «современного» кодека, когда результат бесконечно далек от оригинала, но на данном битрейте (если считать входными данными зажатый JPEG) выдает абсолютно непротиворечивую картинку.
В этом смысле данная статья — попытка приблизить JPEG к современным форматам, используя «хак» нашего зрения. Многие изображения из примеров потеряли массу деталей на картинках с исправленными таблицами, но если бы вы не увидели пример с большим битрейтом, вы бы об этом не догадались.
asen_kurin
Года 3 назад я как часть задачи обучал мелкую нейронку для восстановления JPEG артефактов, опубликована https://github.com/vlesu/SNet-pytorch вместе с коэффициентами. Пример ее работы с файлом из статьи:
Мне кажется, эффект "съедания" текстур можно побороть правильным обучением нейронки, чтобы она "догадывалась" о правильной текстуре. Как в GAN сетях, только здесь-то сколько-то информации в JPEG коэффициентах есть...
homm Автор
> Checkpoint trained 20 epoch on JPEG quality 20.
Тут, конечно, звезды сошлись. Пример как раз libjpeg с q=20.
asen_kurin
Мне и нужно было восстанавливать как раз quality 20, до которого некоторые любят принудительно дожимать публикуемые изображения.
За 3 года сеточки улучшились, можно допилить и доучить, качество поднимется.
Т.е. видится некая библиотечка для перфекционистов "нейросетевой распаковщик пережатого JPEGа". Все публикуют картиночки как им совесть позволяет, размер файлов маленький, а эстетическое чувство у зрителей не страдает :)