
Люди чертовски плохо разбираются в величинах, особенно в тех, которые не могут воспринимать биологически. Например, мы интуитивно понимаем, насколько тяжелее предмет массой 10 кг предмета массой 1 кг.
Ощущение величин можно улучшить, преобразовав их каким-нибудь образом в сигналы, знакомые мозгу.
Смотрели ли вы эти видео?
Второе нравится мне больше всего. Ежедневно я съедаю по чашке риса, так что измеряю состояние Джеффа не только наглядно, но и своим желудком.
Совсем недавно я внёс несколько оптимизаций в код, что помогло мне интуитивно понять, насколько быстро может работать компьютер. И я решил, что этим нужно поделиться.
Что мы оптимизируем?
Функция выглядит примерно так:
# учтите, что это сокращённый вид настоящей функции
def aggregate(input_df):
weights = initialize_weights(len(input_df))
# input_df содержит три столбца: timestamp, score и id
output_df = group_by_id(input_df)
# выполняется сортировка в группе
output_df = sort_by_time(output_df)
output_df = sort_by_score(output_df, desc=True)
# выполняется ранжирование в группе
output_df = rank_within_id(output_df)
# добавляется столбец "results"
output_df = multiply_weights(output_df, weights)
results = results_sum_in_each_group(output_df)
return results # списокЭто функция агрегации показателей, используемая одним из моих сервисов машинного обучения (Machine Learning, ML). Эта функция критически важна для того, чтобы модель работала. Нужно учесть, что вывод этой функции должен быть вычислен менее чем за 500 мс, чтобы она хотя бы попала в продакшен (где нам нужно менее чем за 500 мс выполнить 400-800 вызовов этой функции). Меня попросили её оптимизировать.
Давайте измерим. насколько быстро работает эта функция при 1000 вызовах (предположим, что каждые входящие данные имеют максимум 10 элементов).

Для выполнения 1000 вызовов понадобилось около 8 секунд. Очень плохо. Я хотел попробовать сделать 1 миллион вызовов, но для этого бы понадобилось более 20 минут. Посмотрим, как можно улучшить ситуацию.
Оптимизация 1: пишем алгоритм без Pandas + тривиальные улучшения алгоритма
Библиотека Pandas языка Python отлично подходит для экспериментов с данными, но ужасна в продакшене. Если оказалось, что вы используете её в продакшене, то настало время повзрослеть. [Примечание: не поймите меня неверно. Pandas достаточно быстра для типичного массива данных, но не для обработки, которая в моём случае замедляла pandas. Медленным может быть сам процесс создания объектов Pandas. Если вам нужно сгруппировать + отсортировать 1 миллион строк, то Pandas будет быстрее, чем чистый Python. Но если вашему сервису нужно реагировать менее чем за 500 мс, то вы прочувствуете на себе влияние каждой строки кода Pandas (и любые излишние траты, накладываемые абстрагированием).] Я заменил Pandas простыми списками Python и вручную реализовал алгоритм группировки и сортировки.
Кроме того, в каждом вызове функция вычисления весов инициализировалась заново, но единственное, что она делала — инициализировала ту же последовательность весов для какого-то размера массива. Это оказалось бонусом для меня и я начал вычислять веса предварительно.
Вот как выглядела функция:
WEIGHTS = initialize_weights(99999)
def aggregate_efficient(input_lists):
global WEIGHTS
# input_lists содержит 2 списка
output_lists = algorithm_wizardry(input_lists)
# добавляем столбец "results"
output_lists = multiply_weights(output_lists, WEIGHTS)
results = results_sum_in_each_group(output_lists)
return results # список
aggregate_efficient(ip_list)И теперь 1 миллион вызовов занимает вот столько:

Мы снизили время с 20 минут до 12 секунд! Скорость приблизительно увеличилась на 9900%.
Этого достаточно, чтобы функция попала в продакшен. Но зачем останавливаться на этом?
Оптимизация 2: улучшаем функции с помощью Cython
Один из простейших трюков для ускорения функции на Python заключается в том, чтобы просто написать её на Cython. Вот как это сделать:
- Создаём функцию
.pyx
Чем большеcdefмы сможем в неё поместить, тем лучше оптимизация.def aggregate_efficient_cyth(double[:] score_array, double[:] time_array, double[:] weights): results = algorithm_wizardry(score_array, time_array, weights) return results - Определяем файл setup.py
Добавляем флаги компилятора, чтобы всё работало быстро. Некоторые говорят, что флаг -O3 опасен, но мы пойдём таким путём.from distutils.core import setup from Cython.Build import cythonize from distutils.extension import Extension from Cython.Distutils import build_ext ext_modules = [ Extension("agg_cython", ["agg_cython.pyx"], libraries=["m"], extra_compile_args = ["-O3", "-ffast-math", "-march=native", "-fopenmp" ], extra_link_args=['-fopenmp'], language="c++") ] setup(name="agg_cyth_pure",cmdclass = {'build_ext': build_ext}, ext_modules=ext_modules,)
И вот как быстро выполняется 1 миллион вызовов:
Около
6,59 секунды, то есть увеличение скорости примерно на 82%. Нам получилось почти вдвое сократить время по сравнению с предыдущей оптимизацией. Потрясающе!Но на этом мы не остановимся. Давайте начнём творить полное безумие.
Оптимизация 3: пишем функцию на чистом C++
Вот тут-то и начинается веселье. Это один из самых важных навыков, добавленных мной в свой технический инструментарий (благодаря Рагсу), и если производительность очень важна, то вам поможет это:
- Реализуем функцию на чистом C++
#include "agg_cyth_fast.hpp" using namespace std; double agg_efficient(double score_array[], long time_array[], double weight_lookup[], int N){ vector<double> results = algorithm_wizardry(score_array, time_array, weight_lookup, N); return results; } - Подготовим файл заголовка
#ifndef AGG_H #define AGG_H #include <iostream> #include <map> #include <vector> #include <algorithm> double agg_efficient(double[], long[], double[], int); #endif - Напишем файл
.pyxдля общения с C++import numpy as np from math import exp from libc.math cimport exp as c_exp from cython.parallel import prange cimport cython cdef extern from "agg_cyth_fast.hpp" nogil: double agg_efficient(double[], long[], double[], int) def agg_efficient_fs(double[:] score_array, long[:] time_array, double[:] weight_lookup): cdef int N = len(time_array) cdef double Y; Y = agg_efficient(&score_array[0], &time_array[0], &weight_lookup[0], N); return Y
Далее мы используем файл setup.py, похожий на файл из предыдущей оптимизации, и соберём нашу функцию. По сути, это позволит нам передавать объекты Python функции на чистом C++.
Вот какой получается скорость 1 миллиона вызовов:

Чистый C++ может быть безумно быстрым. Мы ускорили вычисления примерно на 119%!
Но мы ещё не закончили. Часть кода файла .pyx в этом разделе сокрыта, но внимательный наблюдатель может догадаться о следующей оптимизации по импортам.
Оптимизация 4: настало время уничтожить Global Interpreter Lock (GIL)
В Python есть раздражающая вещь под названием GIL, которая не позволяет выполнять многопоточный код на Python быстрее, чем однопоточный.
Если уж вы хотите по-настоящему напрячь компьютер, то зачем использовать только одно ядро?
Теперь мы используем prange для параллелизации наших вычислений.
Просто добавим следующий код в файл
.pyx:@cython.boundscheck(False)
@cython.wraparound(False)
def agg_efficient_fs_batch(double[:,:] score_array,
long[:,:] time_array,
double[:] weight_lookup):
cdef int M = len(score_array)
cdef double[:] Y = np.zeros(M)
cdef int i, N
for i in prange(M, nogil=True):
N = len(time_array[i])
Y[i] = agg_efficient(&score_array[i][0],
&time_array[i][0],
&weight_lookup[0], N);
return YВот сколько нужно времени, чтобы выполнить параллельно тот же 1 миллион вызовов на машине с четырьмя ядрами:

Ускорение приблизительно на 237% по сравнению с предыдущей оптимизацией.
Подведём итог для 1 миллиона вызовов:
| Оптимизация | Потрачено времени | Ускорение по сравнению с исходной функцией |
|---|---|---|
| Нет | 1200 с | - |
| Избавляемся от Pandas + улучшаем алгоритм | 12 с | около 9 900% |
| Добавляем Cython | 6,59 с | около 18 109,4% |
| Реализация на чистом C++ | 3 c | около 33 326,2% |
| Параллельный C++ на 4 ядрах | 890 мс | около 134 731% |
| Параллельный C++ на 32 ядрах | 201 мс | около 596 915% |
Думаю, именно настолько быстрыми могут быть компьютеры.
Комментарии (215)

Akon32
08.07.2022 14:20+5Не хватает сравнения с JIT-компилятором (numba).

CloseToAlgotrading
08.07.2022 21:50Numba будет медленее чем реализация на чистом c++. Если говорить про питон, то я бы посоветовал посмотреть в сторону RAPIDS (у них там есть реализация датафреймов как пандас но на gpu), но только если имеется cuda. :)
зы. пару месяцев назад ради интереса я тут потестил как ускорить расчет максимальной возможной просадки используя монтекарло и лучший результат конечно был c++ cuda, но из питона мы можем отлично получить почти такую же скорость... Постить тут не буду, но кому интересно может глянуть на моем ютбчике.

JordanCpp
08.07.2022 14:46+10Показательная статья. Представьте, сколько неоптимального кода выполняется на миллиардах устройств каждый день, 24.7 Особенно у питонистов, не юзающих cython?:) Я бы даже обобщил, на все языки. Спрятавшись за абстракциями и оправдывающихся временем программиста.
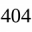
amarao
08.07.2022 15:01+29Не временем. Основная (истинная) задача любого кода - скрытие сложности. Современные системы на многие порядки сложнее старых систем (например 70ого года, когда уже считать научились быстро), и вываливание этого на программиста приведёт либо к вываливанию этого на пользователя (когда вы последний раз выставляли объём оперативной памяти вашего телефона с помощью джамперов?), либо к отсутствию фич. Каких? Например, способности показать одновременно русский и арабский на экране. Или работе в произвольном разрешении экрана на устройствах разных вендоров. Если вы посмотрите на "быстрый старый софт", то там очень много giga (garbage in garbage out) и "действий оператора" (см выше про джамперы с размером оперативной памяти).
Вы готовы вводить адрес начального загрузчика на телефоне каждый раз, когда он "просыпается" в восьмеричном формате?
JordanCpp
08.07.2022 15:12+3Отчасти согласен, но поддержка языков и произвольное разрешение, уверен занимает малую часть от производительности современных мобильных и десктопных процессоров. Причина, все же в другом.
amarao
08.07.2022 15:20+42Если вы под "поддержкой" подразумеваете потраченное машинное время, то а) оно существенно (вы смотрели сколько стоит отрендерить ненормализованную unicode-строку с помощью ttf-шрифта с субпискельным сглаживанием?)
И б), основное, это то, что основная задача программного кода - прятать сложность. Если вы оставите автора вашей любимой программы с необходимостью самому нормализовать unicode и сделать субпиксельный рендеринг с хинтами, то он просто плюнет и сделает вам обычную lookup-таблицу пререндереных символов, aka, растровый шрифт. И только на том подмножестве языков, которые знает (т.е. минус арабский/иврит, минус корейский и т.д.).
Современные компьютерные системы невообразимо сложны. Для того, чтобы человек имел возможность делать что-то осмысленное, ему нужна упрощённая модель, поддерживаемая кодом. Именно отсюда возникает а) огромная блобища, потому что абстракция, которая нужна программисту написана программистом с использованием абстракций слоем ниже б) невероятная скорость создания и возможности современного софта.
Быстрый пример: вы считаете совершенно нормальным, что вы копируете картинку с одного места в другое. Вы хотя бы примерно представляете себе какая это сложная задача? Потому что картинка может быть растром, может быть svg, может быть в одном из 100500 общеупотребимых форматов или быть в другом color space, не говоря уже о том, что понятие "картинки" может радикально различаться между программами во внутреннем представлении. А ведь оно почти в любом софте работает "из коробки". Но вы это принимаете как granted, и человек, написавший программу, тоже принимает как granted, хотя ему нужно лишние 10-20 строчек для правильной поддержки copy-paste написать. Всё остальное - слоем ниже. И ещё слоем ниже. И ещё. И так до самого низа, где низкоуровневый код операционной системы общается с ПО в оборудовании, написанном с помощью фреймворка и работающем в своей ОС.
JordanCpp
08.07.2022 15:44+7Спасибо за развернутый ответ. Но опять согласен отчасти:) 20 лет назад тоже рендерили юникод строки. За это время изменилось разрешение экрана, но и мощности подросли на порядки. Область вывода скакнула с 800-600 до 4k. Хорошо я согласен, что пр таком разрешении пользователь видит больше текста и объектов. Но ведь не 100500 раз, больше:) Тормозить будет, если фигачить юникод строки, 60 раз в секунду без кеширвания и т.д Пример браузер, много текста и объектов, но даже на моем текущем пк athlon x4 640, большинство сайтов работает шустро. Ноутбуке с ryzen 5 по ощущениям раза в два в серфинг быстрее.
Копировали картинки и сложные объекты и 20 лет назад. Зависит от размера и сложности объекта.
Всегда держим в голове, что производительность выросла на порядки. Этого для растеризации шрифтов недостаточно? Сколько нужно? 10гц, для плавного хинтинга?
Программа и вправду может тормозить, вот только современный софт потребляет в среднем как видеокомбайн или аналог 3dMax 2005 года. Думаю, вы и сами сталкивались с таким софтом.
Пример. Открыл каталог system32 и перемещаю ползунок верх и вниз по каталогу, не очень то и быстро перемещаю. Загрузка ЦП 23%, Double Commander при прокрутке выедает 1 ядро на 100% Доколе:)

Проверю на ноуте с ryzen 5, и отпишу. Вдруг современный проц, сможет вывести настолько ресурсоемкую операцию:)

panzerfaust
08.07.2022 16:04+4Забавная история в ту же копилку. Был у меня смартфон самсунг 2017 года. Его мощщи стало не хватать, чтобы в скайпе открыть список смайликов, выбрать один и послать. Зависон на 40с был.
Со временем я купил самсунг 2021 года. Не из-за скайпа, само собой. Теперь скайп стал работать сказочно быстро. Но после последнего обновления на той же операции снова висямба на 10с.
Мне прям дико любопытен стек вызовов на операции "показать список смайликов". Почему тот же телеграм их без всяких проблем мгновенно выдает?
JordanCpp
08.07.2022 16:09+6Похоже, что он лезет на сервер, скачивает смайлики, загружает в приложение и после этого вы можете выбрать смайлик. И так каждый раз:)
Меня телеграм радует своей производительностью. У меня чатов 50, обычно 100-200 мб. Бывают всплески при звонке. Но тормоза не наблюдал. Только если задержки в сети.
uoak
08.07.2022 17:57+2Вот кстати качество аудиозвонков у меня в телеграмме стабильно и заметно хуже чем в whatsapp. При том что во всем остальном телеграмм субъективно значительно превосходит whatsapp …

tempick
08.07.2022 21:09да, со звонками в тг действительно бывают проблемы, особенно через мобильную сеть помехи и лаги нередки. Как ни странно, лучше всего для звонков у меня работает вк. Мало того, что связь там очень стабильная даже при слабом соединении, он еще и шумы при звонке подавляет очень хорошо.

Lexicon
09.07.2022 12:18-1Качество звонков из моего опыта, как не странно лучшее в Discord, особенно проклятое шумоподавление Krisp. Боже, ехать на самокатах и общаться, не слушая ветер 90% времени это что-то внеземное.
tempick
08.07.2022 21:07+4Не в обиду, но зачем вообще нужен скайп в 2022? Меня как фрилансера иногда прям раздражают общения в скайпе, ватсапе и прочем, когда есть куча приложений куда более быстрых и простых в использовании.
Последний заказчик (из США) тоже просил зарегаться в ватсапе, но я предложил ему попробовать телеграм просто, и с тех пор так и общаемся там, и он подтвердил что телеграм действительно удобнее.
Я еще могу понять ватсап/вайбер, но камон, какой скайп в 22? Зачем?
karabas_b
09.07.2022 05:15+2Есть дофига фирм, в которых скайп до сих пор используется как корпоративный мессенджер. То есть тупо предустановлен на всех компах фирмы. А телегу установить наоборот низя, потому что стороннее приложение, на согласование уйдет полгода.
alexzen
09.07.2022 19:40+1Затем, что не всем нужны шашечки. Если мне надо совершить видеозвонок, то мне совершенно без разницы в какой программе его делать. Для меня главное это качественная связь и чтобы программой умел пользоваться собеседник. А будет это скайп, зум, телеграм дело десятое. Все современные мессенджеры похожи друг на друга и отличаются какими-то незначительными нюансами.
amarao
08.07.2022 16:15+3Юникод в 2000ом году и в 2022 - совершенно разные вещи. Цветные эмодзи с кодами цвета кожи чего стоят, например.
Насчёт перехода с 1280 на 4k. 1280x1024 (реальное разрешение старого ноута, не самое плохое, кстати) - это 1.3Mpx. 4k - это 9.8 Mpx. Разница в 7.5 раз.
Процессор тех лет существенно медленее современного райзена, но не в сотни раз (нотубук о котором я говорю - это уже Intel Core, так что разница как раз примерно эти 7.5 и получается).
На другой машине я делал апгрейд как раз с Core 2 Quad (4 ядра 2.5GHz), на AMD Ryzen 5 5600X (6 ядер, 3.4GHz), на невероятно репрезентативной задаче (зато вычислительной и своей), и у меня между ними разница (в один поток) получилась "Запись в QuadTree с использованием f64 — улучшение в 2 раза. Поиск по дереву стал быстрее в 4.6 раза." (цитата). Получается, что разрешение вырасло в 7.5 раза, а скорость, дай бог, в 5 раз.
JordanCpp
08.07.2022 16:24Добавил ваши и мои пк. Производительность на 1 ядро. Добавил проц 2003 года, athlon 64 3000+.
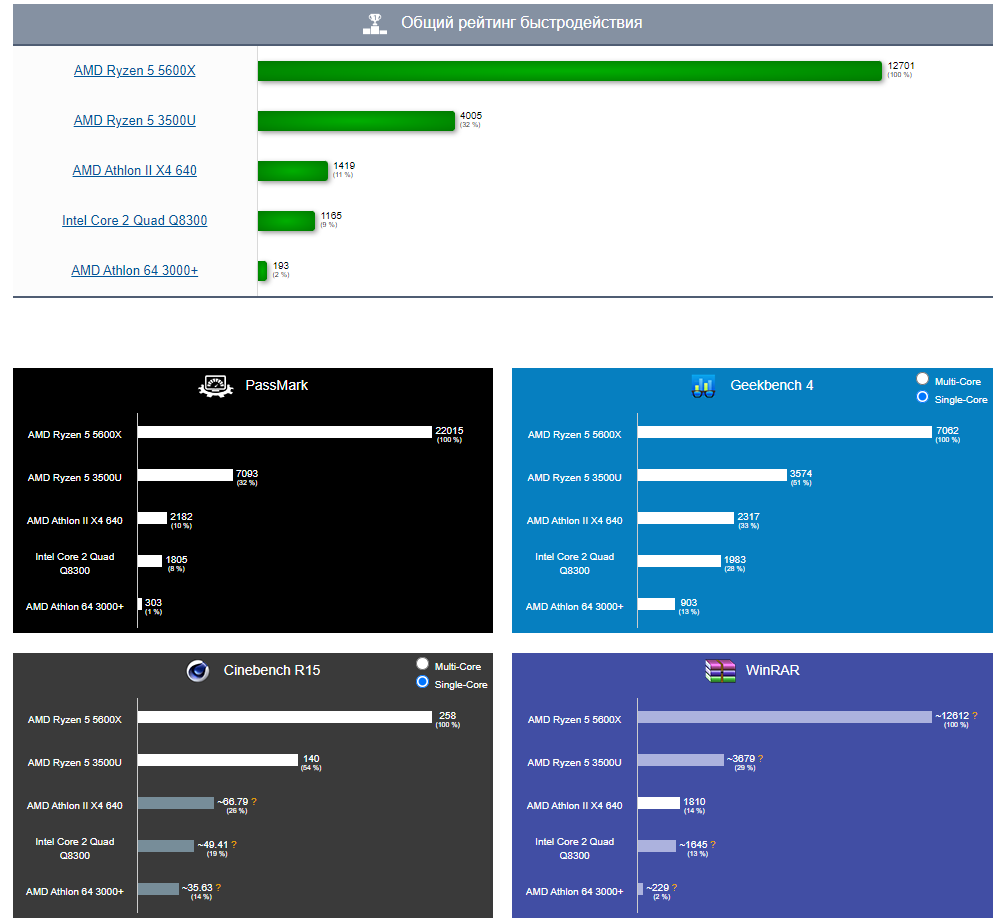
За 10 лет производительность выросла конечно, не в 10 раз. Но если сравнивать с компами с 2000+ года, то в десятки раз. И там таки был юникод:)
amarao
08.07.2022 17:26Вот, кстати, выглядит как брехня. Потому что у меня вставка в QuadTree (binary tree на плостности с 4мя квадрантами) стала быстрее всего в 2 раза. Я понимаю, что f64 - это вам не видео декодировать и всё серьёзно, но всё равно. По вашим бенчмаркам почти 10-кратное улучшение, по моим (в рамках вычислительно-графовой задачи) - от 2 до 5 (per core).
JordanCpp
08.07.2022 17:29Общую производительность я бы не брал в расчет. Смотрите производительность на ядро.

0x131315
09.07.2022 09:47+2Нормально выглядит. Просто в одном случае сравнивается производительность одиночной операции в одном вычислительном блоке, а в другом - полная производительность всех вычислительных блоков.
У двух процессоров может быть одинаковая производительность по операциям, например одна частота и одна скорость выполнения в тактах, но при этом совершенно разная производительность: один имеет один alu, а другой десятки, и ещё всякие avx-расширения, так что способен через себя за тоже время пропускать огромные потоки.
Бенчмарки естественно сравнивают полную противоположность - именно то, что будет использовать оптимизированный прикладной софт. А одиночная линейная операция покажет совершенно другие цифры - всё таки процессоры растут больше вширь, а не вглубь, поэтому оптимизации под железо сейчас так важны - нужно нагружать все исполнительные блоки железа по-максимуму чтобы код был действительно быстрый.
Для своих задач сравниваю производительность в архиваторах, и рост за десятилетие там тоже впечатляет.
Вот например мои тесты:
WinRAR
Armv7 Neon (2012) 2c/2t 1GHz 300kb/s
Intel HT (2005) 1c/2t 3GHz 300kb/s
Amd APU (2012) 2c/4t 4GHz 3000kb/s
Amd Ryzen 7 (2020) 8c/16t 5GHz 32000kb/s (3300kb/s single thread)
Все первые тесты в многопотоке были. Рост за 15 лет впечатляет, 2 порядка.
Половина современного ядра по вычислительной мощности превосходит совокупно все ядра прошлых поколений, работающие вместе.
JordanCpp
09.07.2022 10:30Спасибо за объяснение. Рост на порядки есть. Современные фреймворки, просто переводят данную производительность в тепло:)

cepera_ang
08.07.2022 16:25Но ведь задачи большинства программ не масштабируются линейно с ростом количества пикселей на экране. Тем более, что для этого есть такой специальный сопроцессор, померьте насколько быстрее на нём стал работать код :)
amarao
08.07.2022 17:24Если вы рендерите шрифты на весь экран, то в общем случае у вас нет никаких средств акселерации. Да, у вас есть "быстрый bitblt", но с учётом что форма символа зависит от положения символа в строке (т.к. кернинг мы уважаем теперь, да?) то рендерить его приходится снова и снова. Есть кеш, который частично нагрузку снимает, но рисование на экране ttf шрифтами по правилам (т.е. правильным кернингом и сабпиксельным рендерингом) - это чистая задача на CPU.
Хотя спор опять куда-то в производительность ползёт, а речь про количество кода, на самом деле.
JordanCpp
09.07.2022 10:37Шрифты рисуются на современных цпу. Я приводил пример браузера. Это не сверх задача, подсчитать размеры кернинг, сгладить и вывести на экран. К примеру я просто, колесиком перемещаюсь по данной статье в браузере, нагрузка на 1 ядро 100% и это нормально, браузер рисует шрифты, что то кеширует, перемещается по DOM дереву и т.д И кстати тормозов нет на ЦП 2010 года, процу 12 лет он вывозит эти ваши кернинги, ttf и сглаживание:)
Quark-Fusion
11.07.2022 07:38вроде сейчас браузеры всю работу по отрисовке и компоновке на GPU выполняют уже
amarao
11.07.2022 11:02Компоновка - конечно. А вот как на GPU рисовать TTF - я бы хотел почитать. Или вы просто махнули рукой, мол, там всё умеют и вроде на GPU? Я вот одну статью нашёл, но там ни слова про хинтинг. А это, простите, код для виртуальной машины, который надо исполнять.

dartraiden
09.07.2022 17:43Пример. Открыл каталог system32 и перемещаю ползунок верх и вниз по каталогу, не очень то и быстро перемещаю. Загрузка ЦП 23%, Double Commander при прокрутке выедает 1 ядро на 100% Доколе:)
В Проводнике могут быть расширения Проводника, установленные сторонним ПО. И они почти никогда не написаны идеально. Нужно сравнивать на чистой системе.
cepera_ang
08.07.2022 16:12+5(вы смотрели сколько стоит отрендерить ненормализованную unicode-строку с помощью ttf-шрифта с субпискельным сглаживанием?)
Все хитрости с хинтингами уже в виндовс 98 были, а субпиксельное сглаживание всего 20 лет назад в XP. К тому же, выводить строки на современных экранах с фантастическим разрешением -- наоборот проще, можно со всем этим (почти) не заморачиваться, сглаживание автоматически лучше, тупо за счёт размера пикселей.
Ну и нормализация строк и подобное -- не в ней дело, когда любая программа на телефоне с холодного старта появляется на экране за 3-5 секунд (на вполне среднем аппарате, с многими миллиардами операций выполняемых в каждую секунду). При этом она не показывает особо никакого текста, пока загружается, просто пустой экран.
amarao
08.07.2022 16:20+10Вы реально мой тезис игнорируете. Вам очень хочется, чтобы я говорил про то, что программам надо много делать и они заняты рендерингом тяжёлых вещей.
А я говорю, что программистам, которые делают так, чтобы программы много делали, нужно иметь ограниченную по сложности задачу. Потому что если любому человеку попросить вот это вот отрендерить с нуля (вот тебе API ядра для bitblt и запрос для определения текущего разрешения и области вывода), то это будет нерешаемая за разумные сроки задача.
Значит, человек берёт готовый код. Не потому что он ленивая жопа которой лень пошевелиться ради быстрой программы, а потому что срок реализации программы без всех этих фреймворков (построенных на фреймворках, и так до самого дна, которое в свою очередь ABI между одним процессором и программой на другом процессоре) превысит срок жизни человека.
JordanCpp
08.07.2022 16:27Другими словами, есть проблемы с фрейворками, с их оптимальной реализацией? Это уже ближе.
amarao
08.07.2022 17:32+20Нет, это не проблемы. Проблемы с ожиданием поведения от софта. От каждой утилиты мы ожидаем правильной обработки всего юникода. Unix-подход (байтстринг на вход, байтстринг на выход) уже не катит.
От каждого редактора сообщений ожидают эмодзи, картинок и ещё чёрта в ступе. От каждого приложения - работу во всех мыслимых и немыслимых разрешениях и DPI, понимание 100500 форматов, часовых поясов, локалей, направлений ввода текста, и правильную обработку обрезания арабского текста.
Соответственно, каждая программа это должна уметь. Единственный метод "уметь" - использовать библиотеки/фреймворки, которые эту нагрузку на себя ведут.
Грубо говоря, у вас такой жирный и медленный редактор, потому что он в любой момент в рантайме готов вам показать правильно свёрстаную корейскую надпись посредине статьи на идише. И это не вопрос "обрезайте при компиляции". Этот функционал ожидают от софта, и он должен быть на месте. Вместе с эмоди, для того, чтобы склеить иконку "третьего тона кожи" с "двумя детьми" и "одним взрослым" и правильно посчитать кернинг для получившегося.
Это мы ещё не затронули несколько сетевых протоколов с простынями алгоритмов шифрования, подсветку синтаксиса 100500 языков и т.д.
И всё это ожидается, что есть и работает. Это очень много кода, который пассивно ждёт своего момента.
cepera_ang
08.07.2022 17:48-3Но наличие этого кода не значит, что он вызывается каждый раз. Почему нельзя иметь оптимизированный common case?

insecto
08.07.2022 19:02Можно, но кто-то должен написать оптимизированный common case. А неоптимизированный уже есть, бери пользуйся.

0xd34df00d
09.07.2022 02:27+3Потому что фанаты скорости пишут на языках вроде C, где очень тяжело с композабельностью. Откройте кишки wc из coreutils и полюбуйтесь этой прелестью на 330 строк — я даже не прошу туда что-нибудь добавить или поменять.
А потом сравните с каким-нибудь хаскелем и чистоту реализации, и производительность.
cepera_ang
09.07.2022 04:04+1Можно с каким-нибудь toybox сравнить тогда уж. Тоже на С, только не GNU прелесть :) И половина кода нужна, чтобы странную POSIX херню обрабатывать.

Lex20
09.07.2022 14:37Какой-то мудрец догадался туда avx2 засунуть, но не догадался что ввод-вывод дороже будет чем сам подсчёт. Да и не у всех этот avx2 есть, гнать таких мудрецов надо, чтобы не мусорили. Зачем мне в памяти держать код работы с avx, sse, 100500 драйверов на устройства, которых у меня нет? Кто-нибудь об этом подумал? И ещё, я 100% не буду себе на комп ставить программы, за разработку которых мне платят деньги. Не потому что я плохо что-то делаю, а потому что над программой ещё десяток криворуких мудрецов поиздевались.
0xd34df00d
09.07.2022 17:48+1Какой-то мудрец догадался туда avx2 засунуть, но не догадался что ввод-вывод дороже будет чем сам подсчёт.
Не будет, если у вас достаточно быстрое IO, или файл уже по каким-то причинам в кэше ФС.
Да и не у всех этот avx2 есть, гнать таких мудрецов надо, чтобы не мусорили. Зачем мне в памяти держать код работы с avx, sse, 100500 драйверов на устройства, которых у меня нет?
Соберите себе генту.
Lex20
09.07.2022 19:22Мне по коду всё ясно, это вам нужно собирать. Кеш процессора, построенный на sram памяти, будет всегда быстрее чего угодно. Длина avx инструкций будет больше коротких процессорных, для задачи подсчёта количества оно точно не надо, там кроме сумматора ничего не надо.
0xd34df00d
09.07.2022 20:07+1Кеш процессора, построенный на sram памяти, будет всегда быстрее чего угодно.
Есть две версии функции, одна с avx2, другая — с sse 4.2. Сколько места в кэшах каждого из уровней они займут на вашей машине по сравнению со случаем, когда была только одна функция?
Длина avx инструкций будет больше коротких процессорных, для задачи подсчёта количества оно точно не надо, там кроме сумматора ничего не надо.
Бенчмарки показывают, что надо.
Мне по коду всё ясно, это вам нужно собирать.
Так вы собирайте не чтобы посмотреть, а чтобы вы все нужные use-флаги включили, а ненужные — выключили, и собрали код без ненужных вам avx2-инструкций.
0xd34df00d
09.07.2022 21:16+4Да, вчера как раз заказал свой первый компьютер, послезавтра доставят. Как раз летние каникулы, самое оно сейчас изучать вычислительную технику, а то осенью будем дроби проходить, а это требует концентрации.
По существу-то можете что-нибудь сказать?
Lex20
09.07.2022 21:29(: Могу, там avx видимо для здоровых чисел нужен, поскольку uintmax_t lines, words, chars, bytes. Так что да, пусть будет. Но я так и не понял почему 64 бита не хватает. И вдруг 256 не хватит, тогда что, avx уже маловат, код в мусорку, и всё по новой. Скорости он там точно никакой не даёт, fread банальный урежет её. Просто кто-то поленился писать на асме сложение для длинных чисел, а оно там элементарное.
0xd34df00d
09.07.2022 21:50+2Могу, там avx видимо для здоровых чисел нужен
avx там, видимо, нужен потому, что вы за один такт можете обработать больше данных, чем без векторных инструкций. В итоге с явными интринсиками можно работать раза в два-три быстрее, чем даёт компилятор (который тоже векторизует).
Скорости он там точно никакой не даёт, fread банальный урежет её.
Не урежет. Олсо, кроме fread есть mmap, чтобы делать поменьше копирований.
И вдруг 256 не хватит, тогда что, avx уже маловат, код в мусорку, и всё по новой.
Ага. Станет популярно avx-512 — будет версия и для avx-512.
И да, возвращаясь к исходному вашему «нафига мне засирать память ненужными avx2» — отвечу за вас. Если у вас есть N вариантов функций, каждая из которых собрана под/с конкретным набором инструкций, из которых вы используете одну, а остальные N-1 — нет, то место на диске они, конечно, занимать будут, а вот место в L2-кэше — только с точностью до попадания на границу кэшлайна, так что, считайте, тоже нет. Место в μop-кэше/I-кэше/етц — тем более нет.
cepera_ang
09.07.2022 21:53+1Даёшь разработку только под самые последние версии процессоров (знаменитое «у кого нет Ice Lake могут идти …»). Тогда и производительность максимальная и в памяти ничего не засирается :)
А то пишут на своём чистом C с таргетом компиляции i386 и бухтят о том, что они единственные, кто самый оптимизированный код дают и что процессоры нифига не ускорились за 10 лет. А, ну да, особенно ещё надо двусвязных списков нахерачить, бинарных деревьев и летать по всей памяти как угорелый.
0xd34df00d
09.07.2022 22:00+1Даёшь разработку только под самые последние версии процессоров (знаменитое «у кого нет Ice Lake могут идти …»). Тогда и производительность максимальная и в памяти ничего не засирается :)
Ну я уже не могу полноценно пользоваться tabnine, например, потому что они посылают всех, у кого avx2 нет (а у меня на основной машине i7 3930k, который сэнди бридж).
А то пишут на своём чистом C с таргетом компиляции i386
Кстати, и gcc, и с относительно недавних версий clang умеют генерировать трамплины для разных версий одной функции, реализованной с разными
__attribute__("target:чётотам"), не помню точный синтаксис.
cepera_ang
09.07.2022 23:01Ну вот, сначала сами не обновляются по 10 лет, а потом жалуются, что производительность не растёт :) А софт не может использовать новые фичи, потому что у 99% пользователей их нет.
0xd34df00d
09.07.2022 23:13+1- Я и не обновляюсь потому, что не растёт. 3-5% прироста каждого следующего поколения интелов в годы до зена — это смешно. Но последние несколько лет это не аргумент, да.
- Я жалуюсь не на то, что производительность железа не растёт, а на то, что ресурсоёмкость аналогичного ПО растёт.
- Софт вполне может использовать новые фичи, если особо ресурсоёмкие части сделать в нескольких вариантах.
Lex20
09.07.2022 22:05Ну двухсвязный можно рекурсивно строить, из стека. Сам так делал, понравилось, кроссплатформенно, любой микроконтроллер со стеком поймёт чего я хочу. Но адреса возврата малость мешают, но никто не запрещает дефрагментацию стека делать (:
Lex20
09.07.2022 22:00Ну вот вы и попали в ловушку маркетологов. Теперь кроме intel и amd ничего на всей планете нет :). Не, avx там только для жирных чисел нужен, сам сперва подумал что кто-то чего-то ускоряет, но таки нет, видимо кому-то нужно интернет в байтах, словах и линиях мерять.
0xd34df00d
09.07.2022 22:08+1Теперь кроме intel и amd ничего на всей планете нет :)
И что? Если я пишу личный опенсорс или контрибьючу в какую-нибудь популярную библиотеку, то я напишу несколько реализаций под разные наборы инструкций потому, что это просто прикольно, и потому, что кто-то может сидеть на 10- или 15-летнем железе.
Не, avx там только для жирных чисел нужен
Ясно.

dayllenger
08.07.2022 17:53+6Есть близкий пример, который большей частью опровергает ваш тезис:
Человек в свободное время без особых амбиций написал терминал с поддержкой рендеринга любого текста (большей частью моноширинного, но с поддержкой эмодзи, арабского и пр.), чтобы показать, насколько Windows Terminal жирный и медленный. Причём он рендерит текст лучше, чем Windows Terminal. И да, он рисует на GPU.

perfect_genius
08.07.2022 20:41+8обрезания арабского текста
У них даже текст обрезается?!
amarao
08.07.2022 23:42+1Нет, у них при обрезании текста оставшийся увеличивается в длине. Эппл на этом попалась.
cepera_ang
08.07.2022 16:30+1Я принимаю этот тезис. Просто хочу добавить, что на программиста давят экономические соображения (сделать быстрее == прибыль), но при этом эти экономические соображения тянут с пользователя. Разница только в том, что пользователь -- не разработчик и не специалист, он не знает как могло бы всё работать и поэтому проглатывает эти косты молча. А разработчик знает (или как минимум должен знать), и поэтому он мог бы быть адвокатом в пользу пользователей хотя бы немного. Но он конечно бенефициар сложившейся ситуации и поэтому никакой мотивации так делать, кроме, не знаю, профессиональной гордости, у него нет.
Между "писать всё с нуля, начиная с бутлоадера" до "пишем на питоне, заворачиваем в докер контейнер с постгресом в соседнем и клиента на электрон и всё это простое десктопное приложение" -- есть некоторая пропасть.
amarao
08.07.2022 17:34А какую часть из этого вы ходите оптимизировать? Выкинуть постгрес? Докер? Переписать клиента на нативном API для каждой ОС? Переписать код на питоне в код на (you-favorite-here)?
Akon32
08.07.2022 19:23Просто хочу добавить, что на программиста давят экономические соображения (сделать быстрее == прибыль), но при этом эти экономические соображения тянут с пользователя.
Пока всё работает, проблем нет. Проблемы начинаются, когда глючный код перестаёт работать, или когда программе пора работать, но программист ещё упражняется с ассемблером. Это полный провал! В итоге все предпочитают условный питон, который работает раз в 25 раз медленнее, чем следовало бы, но позволяет кодить левой пяткой и всё равно в 5 раз быстрее и надёжнее.
Разница только в том, что пользователь -- не разработчик и не специалист, он не знает как могло бы всё работать и поэтому проглатывает эти косты молча.
Уж лучше пусть не знает, чем знает наполовину или на 5%. Как правило, частичное знание приводит к мечтам о бесконечной оптимизации, но ничего не говорит ни о затратах на оптимизацию, ни о корректных методах оптимизации. Когда-то я пытался объяснять таким продвинутым пользователям механизмы работы виртуальной памяти, но для не-программистов это слишком подробное погружение в тему. Увы, чтобы понять подобные вещи, нужно потратить примерно несколько семестров на соответствующей специальности или прочитать несколько толстых книг. Пользователям есть чем заняться кроме этого, они могут быть специалистами вообще в другой области.
cepera_ang
08.07.2022 19:31+4Мы ведём обсуждение под примером, где 25х питона на самом деле обозначают 6 000х.
Пользователь не знает не того, как устроен компьютер с его виртуальной памятью, а насколько он быстр несмотря на всю свою сложность. Практически все задачи на компьютере должны выполняться за <0.1с (блин, да именно за это время гугл успевает пролистать индекс всего интернета, провести рекламный аукцион и ещё миллион дел и выдать результат). Все реакции на клики, запуск программ, все обычные действия могут быть так быстры. Но пользователи привыкли, что всё запускается произвольно долго и поэтому даже не замечают и не понимают, что это долго. Вернее замечают конечно, но думают, что это неизбежно (ведь никто не думает на программистов плохо, что те сознательно выбирают простоту для себя, а не комфорт для пользователя).
Akon32
09.07.2022 08:13Практически все задачи на компьютере должны выполняться за <0.1с
Не все задачи могут выполняться за 0.1с, т. к. не все задачи одинаковы. Сжатие видео тоже должно выполняться за 0.1с? А чтение произвольного объёма данных с диска?
должны выполняться за <0.1с (блин, да именно за это время гугл успевает пролистать индекс всего интернета, провести рекламный аукцион и ещё миллион дел и выдать результат)
пролистать индекс всего интернета
Гугл выполняет поиск на кластере из тысяч машин. Производительность у него совершенно другая, чем у домашнего компьютера. Вы не захотите иметь такой кластер дома, он большой, дорогой, требует дорогого обслуживания и т. д.
Идея индексирования как раз в том, чтобы не просматривать весь индекс. У меня от выделенной в цитате фразы возникают подозрения, что вы недостаточно хорошо понимаете, как работает поиск, map reduce, параллельное программирование вообще, раз приводите сильно распараллеленную задачу в противопоставление коду на десктопе, где ядер-то не больше десятка, а задействуется чаще всего одно ядро. Это противопоставление некорректно.
Естественно, хорошо параллелизуемая задача может выполняться за 0.1с на кластере из тысяч компьютеров, поддерживаемом штатом инженеров, с отдельной электростанцией, соответствующей системой охлаждения и т.п. Но если ваша задача - например, считать данные с диска, чтобы запустить программу, то объём, что вы успеете вытянуть за 0.1с с одного типичного ssd - всего 20-50МБ. Хорошо, если программа занимает 20МБ, ведь её ещё нужно слинковать с библиотеками и инициализировать... А если бинарник вместе с библиотеками мегабайт на 400, они только считываться будут секунду, и обойти это сложно.
cepera_ang
09.07.2022 09:36+1Сжатие видео не должно выполняться за 0.1 секунды, но начало воспроизведения — должно. Открытие любой папки должно происходить за это время. Запуск программ — тоже. 20-50мб с типичного SSD — это размер кода за глаза достаточный для старта, если конечно программа не несёт в себе целый внутренний мир. 400 мегабайт — это больше размера целой операционной системы, такой как Windows 2000 — весь этот код точно нужен для того, чтобы показать начальное окошко? А если у меня nvme ssd на 7.5GB/sec, то за 0.1с у меня будет читаться даже почти в два раза больше — почему это не помогает запускать программы мгновенно? Сама идея, что для запуска программы нужно прочитать полгигабайта — не кажется вам сомнительной?
Akon32
09.07.2022 10:38+1400 мегабайт — это больше размера целой операционной системы, такой
как Windows 2000 — весь этот код точно нужен для того, чтобы показать
начальное окошко?Объем такого порядка занимает одна лишь библиотека Cuda для операций над матрицами... И что теперь, матрицы не на gpu перемножать? Win 2000, к слову, решает другую задачу.
почему это не помогает запускать программы мгновенно?
Найдётся какая-нибудь ещё инициализация, которая займёт время.
Сама идея, что для запуска программы нужно прочитать полгигабайта — не кажется вам сомнительной?
Таки кажется, но это от сложности программы зависит.
JordanCpp
09.07.2022 10:42А сколько в библиотеке Cuda на 400 мб, собственно этих самых мб относятся непосредственно реально к функционалу библиотеки? Может там примеры, документация и т.д
И если перемножение матриц занимает 400 мб so или dll, что там может занимать столько места?
Akon32
09.07.2022 11:10Это dll имеют размер такого порядка (точно размер я не помнил, посмотрел сейчас: старые библиотеки cudnn - 270МБ, cufft - 128МБ, cublas - 50МБ - всё же меньше, чем 400). А место в них, по-видимому, занимает gpu-код, который скомпилирован под ~десяток архитектур GPU, да ещё и с инлайнами всех вызываемых процедур, да ещё и на С++ подобных шаблонах. Зато работает быстро и почти на всех GPU.
JordanCpp
09.07.2022 11:18Тогда ваш пример опровергает концепцию ожиревшего и тормозного кода. Библиотека занимает столько, сколько нужно для расчетов на GPU. Работает быстро, еще и совместимо как с новыми, так и старыми видеокартами.
cepera_ang
09.07.2022 21:27В куде 400Мбайт потому что скопилировано на все возможные архитектуры гпу. И что теперь, загружать все четыреста в память, только для того, чтобы запустить пяток функций из этого? Естественно ни одна ОС так не делает, мапят в память только необходимые страницы.
Опять же, даже если программе строго нужна вся куда, то очень сомнительно, что она нужна в первый момент запуска программы. Скорее всего это зависимость какого-нибудь дальнего меню «посчитать Х на гпу» и вполне разумно ожидать, что это не будет влиять на начальную загрузку.
0xd34df00d
08.07.2022 16:56+5У меня есть одно личное приложение для десктопа на плюсах, которое я пишу по фану (правда, последнее время, не очень активно) года с 2006-го. Так вот, несколько месяцев назад я заметил, что оно загружается секунды полторы, даже если отключить почти все фичи. Посмотрел профайлером — этак 300-500 мс на одну только инициализацию кишок fontconfig'а (понятия не имею, что оно там делает).
cepera_ang
08.07.2022 15:13А точно отсутствие необходимости вводить адрес бутлоадера вручную даёт время загрузки телефона с 4-8 трёхгигагерцовыми ядрами в десятки секунд? Может можно как-то оптимизировать поиск этого адреса, чтобы и вручную не вводить, и не выглядело, будто в коде sleep(10000ms) стоит :)
JordanCpp
08.07.2022 15:15+14Сразу вспомнилось:) Если заменить ошибку, на тормозной код.

amarao
08.07.2022 15:24+12А сколько он сэкономил человеколет своей программой?

MentalBlood
08.07.2022 15:41+1Наверное Джон настолько плохой программист, что пишет только ошибки
amarao
08.07.2022 16:08+11А почему тогда 10 миллионов человек используют "только ошибки" которые пишет Джон? Как же так получилось, что пользователь номер 9999999 видя как страдали пользователи до него и как он страдает (а почему страдает, если в коде только ошибки? Оно же просто не работает) посоветовал программу пользователю номер 10000000.
Не складывается шутка, не складывается.
MentalBlood
08.07.2022 17:42А Джон это не собирательный образ программиста, это отдельный программист, который только ошибки пишет (чем, кстати, может создавать рабочие места)

speshuric
08.07.2022 16:52+16Иронично, но ваш комментарий приложен в виде картинки объёмом более 400 КиБ, а весь текст - примерно 2 КиБ в UTF-8. И почему браузеры/компьютеры/программы стали так медленно работать?
JordanCpp
08.07.2022 21:19-1Картинку вывести ПК вообще на изи.:) И нет браузеры/компьютеры/программы тормозят не иза моей картинки на 400кб:) Инфа 146%

klounader
10.07.2022 10:47+4ваша картинка весила 423 кб из-за непонимания или нехотения того, как вы эту картинку произвели на этот свет. зашакаленный джипег в пнг — это, конечно, весело, но вот вам немного оптимизации, где размер картинки уменьшен до 32 кб без потери полезной информации в ней. разница примерно в 13 раз. и это далеко не предел по факту, если сделать картинку по-человечески.

а теперь вот открытые в просмотрщике картинок ваша и моя картинка. угадайте, в каком окне ваша, а в каком моя, если учесть, что сама программа без открытых картинок потребляет 2 метра оперативки.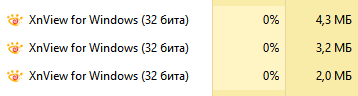
если вам кажется, что всё это ерунда полная, то на самом деле проблема состоит не из-за этой голимой картинки, а в общем и целом из маленьких мелочей, которые в итоге оптом вырастают в огромную картинку.
вы же сами жалуетесь своим постом, где В софте все всрато и становится еще всратее и сами же пренебрегаете довольно очевидными вещами, деля на ноль эту самую статью.
если бы мракософт хоть немножко задумывался о том, что он делает и как в плане оптимизации, то вангую, что последняя венда могла бы весить, например, раз в 15 меньше, то бишь мегабайт 300-350 вместо 5 гигов. а если конкретно так психанула бы, то и вовсе в ~100 мегабайт уложилась. но это сложно, да, там программировать надо, а не мышкой по красивым кнопочкам тыкать.
производители игрушек на таких мелочах зарабатывают миллиарды долларов, используя систему микротранзакций. пользователи с удовольствием относят им туда свои бабки. им кажется, что 15 центов ерунда, но 15 раз по 15 центов это $2.25. за эти деньги можно неплохо пообедать дома, ну или купить шавуху. а если играть каждый день в такую игрушку, в месяц это почти 5 тыщ рублей. а жизнь состоит не только из одной игрушки. таких микроплатежей море и в реальном мире.
таким образом можно понять, сколько своего и чужого пространства, энергии и времени расходуется непонятно как, лишь бы ничего не делать. но эта лень в итоге приводит к тому, что нужно покупать всё более мощные железки, которые оправдывали бы свою предыдущую лень, чтобы продолжать лениться и дальше.
пока каждый думает, что от его всратой говнистости ему пофиг на окружающих, то он забывает, что с таким поведением все остальные думают точно также и бумеранг возвращается не один.
вот создал один программист одно всратое приложение и этим приложением пользуются все. даже этот же самый программист. а если он не хочет пользоваться своим говноподелием, то для него есть сюрприз — он не одинок в этом мире. программист из соседней конторы тоже создал какое-то говноподелие, которое внезапно нужно первому программисту. вот так оба программиста нахаляву говна поели, как в том анекдоте, а создатель инструмента для всратого программирования повысил свою рентабельность на рынке как владелец той самой стодолларовой купюры (банк), укрепивший свою валюту. но программистов миллионы, а главный герой один и пользуется он явно не одним приложением, а десятками, и все они одинаковы с лица, и все они говно. и вот ему приходится страдать и бежать покупать очередное новое железо, потому что старое уже не вывозит всего этого дерьма. а деньги зарабатывают на самом деле не программисты, а корпорации, на которые они работают. говнокодеры и прочие генераторы говна сами же помогают производителям делать ещё более мощное железо для своей ещё более мощной будущей лени, причём абсолютно бесплатно.
чем больше говна генерируется, тем больше на вас заработают. и мракософт всё это говно всецело поощряет. нужно больше всратого говна богу всратого говна.
не ожидал, конечно, что родится такой поток сознания, но с возможностью комментирования раз в сутки — и так сойдёт.
Akon32
08.07.2022 19:01+6И правда, цитировать следовало не картинкой, а перепечатав текст, чтобы сэкономить драгоценные байты и такты. Цитата картинкой противоречит вашим тезисам. И, осознав это, вы начнёте понимать программистов, которые пишут неоптимальный код.
JordanCpp
08.07.2022 21:17-7Такое себе сравнение. Софт потребляющий сверх своих возможностей, это констатация факта. Картинка в 400 КБ, почти ничего не стоит пользователям в сравнении, даже в общей скорости и затратам по цп при загрузке данной статьи с комментариями.
Akon32
09.07.2022 07:37+13Вы сами использовали 400КБ, чтобы кодировать 500 символов - это 800 байт на символ (!), и утверждаете, что программисты используют компьютер недостаточно эффективно. Если бы вы перепечатали вручную текст, вы бы их поняли чуть лучше. Но на самом деле всем плевать, 400 байт там, 400КБ или 400МБ, пока система выполняет свои функции.
amarao
08.07.2022 15:24+4Да, именно так. Потому что для того, чтобы не вводить адрес вручную, нужно иметь систему загрузчика, который в свою очередь должен поддерживать миллион разных опций, и для этого есть ВООТ ТАКЕННЫЙ фрейворк (я плохо телефонные потрохи знаю, но для мира PC это UEFI). И этот фреймворк запускает другой фреймворк, который вам и dual partition для загрузки, и шифрование, и дисковое кеширование, и всё остальное.
Вы не поняли моей иронии. Если вы кто-то не написал 100500 кода для поддержки suspend/resume, то каждый раз, когда вы тыкаете кнопку на телефоне, вам бы надо было бы вводить адрес загрузчика. Потому что телефон бы загружался как какой-нибудь мейнфрейм. Для которого процесс загрузки - это метод упростить жизнь программистам, которым больше не надо кодировать реальные адреса для переходов вручную в ассемблере под конкретную модель. (да-да, первый в мире загрузчик назывался initial orders и занимался именно этим - релоцировал программу и расставлял в ней адреса переходов).
JordanCpp
08.07.2022 16:00Сейчас именно так и происходит. Ставим Windows + Docker + redis и уже гб 2 ушло.
В линуксе примерно такая же картина. Не спорю контейнеры очень удобны, всякие flatpack и иже с ним. Но ведь они тянут с собой все зависимости. И большой вопрос в том, что разработчики просто не озаботились вкомпилить в бинарник только используемый код. Пару функций из Qt Core, еще нескоько виджетов из QtGui, а загружается весь фреймворк. То же самое и с GTK. И если программа написана не на С++, без возможности статической линковки, это сделать невозможно. Будут загружены все библиотеки.
JordanCpp
08.07.2022 16:04Ремарка. Будут загружен весь фреймворк, но для всех приложений его использующих.

oficsu
09.07.2022 17:31И большой вопрос в том, что разработчики просто не озаботились вкомпилить в бинарник только используемый код
А имеют ли разработки такое право? А готовы ли они принять последствия?
cepera_ang
08.07.2022 16:22+2Я всё-таки думаю, что телефон включается или перезагружается дольше 0.1секунды (чего достаточно на выполнение 2.580.1 = 2 млрд (!) операций, а в реальности получается 400 млрд) только потому, что такой задачи никто не ставил, а все корпоративные incentives и разработка by committee ведут к появлению монстров типа UEFI (как будто там нельзя было проще и быстрее сделать, можно было, но этим нужно Х, чтобы не переделывать, тем нужно У, сем нужно Z, чтобы потом какие-нибудь патенты энфорсить и т.д.).
А вот когда кому-то это вдруг надо, то оказывается, что все эти вот-такенные фреймворки можно оптимизировать вусмерть, и вот уже всякие firecracker'ы способны загрузить полноценную ВМ за 30мс, а исследователи смотрят как сделать unikernel, который стартует уже за десятки-сотни микросекунд.
JordanCpp
08.07.2022 21:27Плюс быстрых фреймворков в том, что из юзают миллионы людей в виде конечного софта. То есть экономим ресурсы на миллионах устройств. Но так как устройства и так очень быстрые, в чем выгода для компаний тратить ресурсы на такие глупости. Проект работает, а фигли надо:) Выкатили премии получили. Короче замкнутый круг.

fougasse
08.07.2022 19:03+2uboot он такой, да, пока подумает, пока попробует, и FPGA образы тоже небыстро, а потом еще и линукс, и всё каждый раз заново в RO разделы.
А там еще и баги есть, и в самом загрузчике, и в загружаемых образах.
А пользователь хочет, чтобы телефон стартовал всегда, даже, когда завис и получил hard-reset, вытащили батарейку и т.п., а не подключать UART или распаивать JTAG, когда игрушка за штуку баксов окирпичится из-за «непредвиденной последовальности действий» или космической частицы, или когда где-то i2c подвиснет чуть дольше, чем допустимо.
Вот там вам и резервные разделы, и хитрый апдейт.
А ещё подписывание, шифрование, противостояние взлому. В бутерброде из множества супервизоров/ОС, которые работают одна поверх другой.
В «примитивном» смартфоне для лайканья сисек и фотканья котиков.

Alexey2005
09.07.2022 17:08А пользователю точно-точно нужно подписывание, шифрование и противостояние взлому в смартфоне для лайканья сисек?
Вот тут мы подходим к ещё одному фактору, зря сжирающему ресурсы — т.н. «безопасности». Вся эта секьюрная лабуда вечно тормозит, глючит и куда больше вредит самому пользователю, чем потенциальному злоумышленнику.
Контейнеризация, виртуалки, эмуляция, полная изоляция работающих программ друг от друга и постоянная проверка прав доступа — это всё очень дорого стоит в плане ресурсов. Создание «песочниц» изначально дорогущая операция. А ведь во времена MS-DOS машины как-то работали и без всего этого. Даже защищённого режима в процессорах — и того не было.
П.С.: одна из самых прожорливых программ на ноуте любого пользователя — это антивирусник с эвристиками и активной защитой, навешанной на каждый вызов API любой программы. После его удаления скорость работы системы обычно возрастает в разы.oficsu
09.07.2022 17:38+1Я верно понимаю, что вы предлагаете пользователю иметь два телефона – один для соцсетей и лайканья, а второй, где озаботились безопасностью, под банковское приложение?
А ведь во времена MS-DOS машины как-то работали и без всего этого
Если мы вдруг откатим эти технологии вспять, вы осознаёте, какое раздолье появится для вирусов, развивавшихся годами? Вы готовы прямо сейчас опубликовать все ваши личные пароли в открытый доступ? Ибо такова цена
Akon32
10.07.2022 08:35Это ведь сарказм, да?
А пользователю точно-точно нужно подписывание, шифрование и противостояние взлому в смартфоне для лайканья сисек?
Если в смартфоне бывают банковские данные - точно нужно.
Создание «песочниц» изначально дорогущая операция. А ведь во времена MS-DOS машины как-то работали и без всего этого
Работали, но как-то не очень. Скорее даже "дико глючили", чем "работали".
Контейнеризация, виртуалки, эмуляция, полная изоляция работающих программ друг от друга и постоянная проверка прав доступа — это всё очень дорого стоит в плане ресурсов.
Контейнеризация практически ничего не стоит, это просто трансляция файловых путей, сетевых имён, портов и т.д. для отдельных процессов, выполняемых на том же ядре ОС. Изоляция программ, к счастью, поддерживается процессором на аппаратном уровне.

vikarti
10.07.2022 11:08Контейнеризация, виртуалки, эмуляция, полная изоляция работающих программ друг от друга и постоянная проверка прав доступа — это всё очень дорого стоит в плане ресурсов. Создание «песочниц» изначально дорогущая операция. А ведь во времена MS-DOS машины как-то работали и без всего этого. Даже защищённого режима в процессорах — и того не было.
И на ровном месте были BSOD'ы в той же Win95. После установки изврат-методами(потому что 12 Mb RAM) NT4 — BSOD'ы пропали на тех же задачах а быстродействие не упало (Ну только что с играми возникли сложности)

Alex_ME
08.07.2022 16:12+1Между вводом адреса загрузки в восьмеричном формате и кучей неотпимального говнокода на python есть огромная пропасть. Uboot - далеко не главный пожиратель ресурсов.
amarao
08.07.2022 16:22+2Да, конечно. Но альтернативой неоптимальному говнокоду на питоне будет оптимальная программа на... Только не говорите про раст, пожалуйста. Такого прожирателя места ещё поискать (а всё потому что кому-то лениво писать код без generic'ов). Видимо, на ассемблере? С годом сдачи заказа ...
time.ctime((2**31))?Alex_ME
08.07.2022 18:06В зависимости от задачи и требований: оптимальный говнокод на питоне, на JS (все еще быстрее питона), на Lua, на C#, Java, Go, C++, на C, на Haskell ну и на Rust, в конце концов.
а всё потому что кому-то лениво писать код без generic'ов
Разве при мономорфизации объем кода не будет такой же, как если бы мы "нелениво" раскрыли все дженерики руками копипастой?
cepera_ang
08.07.2022 18:15+1Это наверное без учёта трёхгигабайтного докер-контейнера, который к типичной программе на питоне пойдёт :)
amarao
08.07.2022 23:44Я недавно изучал вопрос про оверхед от отсутствия shared libraries при запуске питонов. Я обнаружил, что 500 контейнеров жрут столько же памяти, как и 500 процессов (питона) без контейнера. К своему удивлению, надо сказать.
(тесты были на простом rest-сервере на базе flask и netmiko),
amarao
08.07.2022 23:46Нет, альтернативой мономорфизации будет динамическая диспетчеризация. И тогда разница в размере кода будет колоссальной (особенно при должной кардинальности функций вида fn<T,U,V,X,Z>
oficsu
09.07.2022 17:42-1Дженерики – не шаблоны и кажется, что технически нет препятствия для того, чтобы это стало заботой оптимизирующего компилятора. Если же компилятор (и его разработчик) считает, что без динамической диспетчеризации будет быстрее – нам ли его винить?
Alexey2005
09.07.2022 17:16Lazarus? Из всех современных сред выглядит как наилучший компромисс между простотой кодирования и производительностью/размером программ.









cepera_ang
08.07.2022 15:11+3Да, наглядный пример. Только не оптимизации, как думал автор, а тотальной изначальной неоптимальности. Преждевременная оптимизация зло, бла-бла-бла, но если сортировка 10*1000 элементов занимает почти десять секунд -- то можно и задуматься.

dendron
08.07.2022 16:47+17***Краткая история оптимизация программы на Python***
Ускоряли как-то Python
Cython скомпилили в "сишку"
Вызвали из "сишки" - "сишку"
"Сишка", "сишка", "сишка", "сишка".

Red_Nose
09.07.2022 00:07+1По-идее Python про "удобно", но когда нужна производительность, то тут прям хоть "вешайся".

Sun-ami
08.07.2022 17:01+2Показательно, но автор как-то рано остановился - не задействовал видеокарту.
cepera_ang
08.07.2022 17:47+1Это же сетевой код, вызываемый через RPC, значит надо было на FPGA на SmartNIC нести :)

Boilerplate
08.07.2022 21:55Как минимум можно было:
1) Выкинуть STL и писать на C-массивах;
2) Попробовать развернуть циклы обработки массива и постараться оптимизировать проверки с помощью ассемблера;
3) Таки-да, задействовать всю мощь параллельной обработки данных на видеокарте;
4) Возможность стоило подумать про отдельное аппаратное решение данной проблемы на FPGA;
5) Следующим способом ускорить алгоритм является переход к решению на ASIC-ах, надо только написать оптимальную структуру с учетом разработок на FPGA.Kelbon
09.07.2022 12:581) Выкинуть STL и писать на C-массивах;
Ужасный код, замедлит выполнение
2) Попробовать развернуть циклы обработки массива и постараться оптимизировать проверки с помощью ассемблера;
Ужасный код, замедлит выполнение, лучше компилятора вы не сделаете, нет кроссплатформенности
3) Таки-да, задействовать всю мощь параллельной обработки данных на видеокарте;
Ужасный код, куча зависимостей, нет кроссплатформенности, производительность упадёт, т.к. функция часто вызывается с маленьким объемом данных(уверен, что в статье создаются треды каждый раз вместо использования тредпула и это уже половину времени занимает)
4) Возможность стоило подумать про отдельное аппаратное решение данной проблемы на FPGA;
Не имеет смысла

amazed
08.07.2022 18:42+9Компьютеры реально быстры и мы этого реально не знаем.
Бывает тебе показывают экранную форму с данными и она грузится 2 секунды, ты такой "а почему я должен ждать 2 секунды?", а тебе отвечают типа, "там показывается много полей, они должны быть прочитаны из базы и размещены в представление, надо развернуть много экранных элементов и заполнить их в тяжелом фреймворке...", а ты такой "люди, что же вы делаете, компьютер же может выполнить миллиард гребаных операций за секунду, ну почему ему нужно 2 миллиарда операций, чтобы показать несчастные 30 полей с данными?", а тебе так, это фреймворки, это технологии, ты просто не понимаешь...
smile_artem
08.07.2022 19:02а что делает сам компьютер в это время? простаивает или выполняет бессмысленные для конкретной задачи вычисления?
cepera_ang
08.07.2022 19:18+3Бывает по-разному. Может какой-нибудь О(n^2) алгоритм считать (весьма популярная причина для замедления — достаточно быстро, чтобы попасть в продакшн, и достаточно медленно, чтобы начать тупить уже при небольшом росте задачи), может какие-нибудь неожиданные блокировки ждать, но чаще всего конечно просто делает кучу работы, которая не имеет отношения к задаче, а на втором месте то, что делает эту кучу работы рыхлым, неэффективным кодом, каким-нибудь питончиком/джаваскриптом, прыгает по памяти по иерархии объектов и т.д..
amazed
09.07.2022 00:31+2а что делает сам компьютер в это время? простаивает или выполняет бессмысленные для конкретной задачи вычисления?
Если бы кто знал!
Я представляю себе это примерно так. Допустим, мы можем нарисовать на экране элементы просто через некую базовую графическую библиотеку. Но это неудобно, поэтому кто-то пишет библиотеку, которая позволяет создать объекты-графические примитивы с множеством сложных функций и нарисовать элементы с помощью этих классов. Это медленнее чем исходный вариант раз в 10, но это все еще очень быстро и никого не волнует. Дальше, эти элементы будут не просто рисовать себя библиотекой. Они будут еще описывать как себя рисовать каким нибудь xml который надо парсить. Потом поверх этого напишут библиотеку со всякими анимациями и байндингом, потом кто-то возьмет библиотеку с этими элементами и поверх напишет свою новую супер библиотеку с гораздо большими функциями и опциями в разных версиях, в разных вариантах.
Получается очень сложное здание из множества слоев, каждый из которых тормозит работу в n раз. N умножается на n и снова на n, получается медленно, но все еще не плохо. А потом из за сложности кто-то где-то забывает написать какую-то функцию оптимально. В итоге все начинает тормозить неимоверно, но прогресс пошел уже дальше, никто не хочет копаться в кишках, все хотят еще больше возможностей, еще больше слоев.
В итоге мы имеем на компе довольно примитивные мессенджеры которые падают как будто это виндовс 95 и жрут как будто это целая IDE. Но зато все обеспечены работой, очень сложной и требующей высочайшей квалификации.
Это нормально. Печально только когда программисты забывают насколько на самом деле быстро работает компьютер и начинают искренне верить, что диалог в принципе никак не может выскочить без ощутимого лага, если в нем "много" элементов.
Но это моя теория.
smile_artem
09.07.2022 09:27А опенсорс, где каждая библиотека выполняет одну конкретную функцию - это панацея, если любой сможет оптимизировать любую библиотеку и она сразу при следующей компиляции любого проекта где она используется будет браться из репозиториев и перекомпиляции?

vassabi
08.07.2022 19:37+1с одной стороны С\С++ отличный - на нем код разных нативных функций работает быстро,
а с другой стороны (смотрит как печально компилируется большой ынтерпрайз С++ проект с нуля), мне чистый питон тоже нравится

nmrulin
09.07.2022 02:37+2Ну это чисто С++ маразмы. На Паскале например всё быстро компилируется и скорость работы не сильно хуже.
JordanCpp
09.07.2022 12:57Не соглашусь. Компилятор gcc это миллионы строк кода, где 80% процентов это оптимизация, эвристики и т.д
Думаю, что сильно хуже будет.
Мне Паскаль нравится, на нем первый p код реализовали. И сам язык более целостный.
nmrulin
10.07.2022 17:04Ну с Free Pascal да, в 3 раза различие - https://habr.com/ru/post/563078/ .Но даже PascalABC по производительности его побеждает - http://pascalabc.net/stati-po-pascalabc-net/28-meryaem-proizvoditelnost
Но при этом на ABC лучший результат был в статье 0.45 с , а на Delphi я получал 0,25с. Так что низкая производительность Pascal в тестах часто связанна с конкретной реализацией.
Kelbon
09.07.2022 12:54+2Он хотя бы на компиляции ошибки находит, а питон просто сломается по дороге
vassabi
09.07.2022 20:16-1ошибки компиляции все компиляторы находят.
Ошибки рантайма С++ тоже только в рантайме обнаружит.
к чему этот снобизм ?
0xd34df00d
09.07.2022 21:17+2Множество ошибок, которое находит компилятор плюсов во время компиляции, и не имеющих отношения непосредственно к особенностям плюсов, достаточно малое.
Kelbon
09.07.2022 21:23Что это вообще значит? Вы поняли что сказали?
Все ошибки, которые находит компилятор языка Х во время компиляции непосредственно вытекают из правил языка Х иначе это какой-то бред
0xd34df00d
09.07.2022 21:25+2Да, понял.
На плюсах трудно выразить достаточно ограничений (особенно в духе «эта функция не занимается вводом-выводом и не лезет в глобальное состояние»), чтобы их нарушение стало ошибкой компиляции.
Kelbon
09.07.2022 21:41+1На плюсах можно много чего выразить, даже очень много.
Запрет глобального состояния (ввод вывод это тоже глобальное состояние)- объявите функцию constexpr
Можете ещё noexcept поставить, говоря что она точно не аллоцирует и не фейлится
0xd34df00d
09.07.2022 21:56+3Запрет глобального состояния (ввод вывод это тоже глобальное состояние)- объявите функцию constexpr
Вы ведь достаточно хорошо знаете плюсы, чтобы знать, что это ни на что не влияет? Вот это вполне валидная функция:
int global = 0; constexpr int foo(int bar) { if (bar > 42) return bar + global; return bar; }А это, к слову, невалидная:
int global = 0; constexpr int foo(int bar) { if (bar > 42) return bar + global; else if (bar <= 42) return bar + global; else return bar; }но имеющийся у меня компилятор плюсов на неё не ругается и спокойно её компилирует. И, более того, он имеет полное право на неё не ругаться (потому что требовать от компилятора решать проблему останова — перебор даже для составителей стандарта плюсов), и ровно так же имеет право отформатировать ваш жёсткий диск при запуске этой программы (потому что это IF/NDR, которым он имеет право молчаливо воспользоваться).
Можете ещё noexcept поставить, говоря что она точно не аллоцирует и не фейлится
Чё, тоже компилятор проверит? Так же, как с
constexprвыше?Kelbon
09.07.2022 22:05constexpr запрещает static переменные в функции.
И вообще, вы начали с того, что компилятор не находит ошибки. Использование глобального состояния - не ошибка. Это просто стиль, который ВЫ должны контролировать в ВАШЕМ коде
0xd34df00d
09.07.2022 22:09+3Ошибка — это то, что я называю ошибкой. Если чистая функция вдруг лезет в глобальное состояние (или ворует мои ключи от биткоина), это ошибка.
Kelbon
09.07.2022 22:10А что вы назвали чистой функцией? Этого понятия просто нет в С++
P.S. тогда я называю декларацию типа ошибкой. С++ не видит ошибок, какой ужас...
0xd34df00d
09.07.2022 22:11+4Ну вот мы и приходим к тому, что ошибки, которые ловит C++ — они в основном сводятся к синтаксису и семантике плюсов, а не вашего кода.
cepera_ang
09.07.2022 21:32+1Он хотел сказать, что некоторые языки проверяют только относящуюся к языку ерунду, которая не помогает программисту делать меньше ошибок логики. А другие помогают написать не только синтаксически, но и логически верные программы.
Kelbon
09.07.2022 21:43В С++ такая свобода создания своих абстракций, что вы можете написать себе сколь угодно сложную логику проверки чего-либо на компиляции.
cepera_ang
09.07.2022 21:56+1Разница между «вы можете написать что угодно» и «этот компилятор заставляет вас проверять вот эти конкретные вещи» — это небо и земля. По простой причине — то, что «можно, но не обязательно» будет выкинуто при первом же давлении обстоятельств. Посмотрите как люди защищают «продуктивность разработчика» и вы предлагаете её выкинуть куда-то и вместо этого начать писать на С++ сколь угодно сложную логику проверки каких-то инвариантов?
Kelbon
09.07.2022 22:08Используйте библиотеки, которые уже написаны и проверяют свои инварианты. Например стандартная библиотека.
Пока это всё на уровне "ну я пишу плохой код, значит С++ не даёт возможности писать хороший".
Почему же вы тогда не пишете про то, как упадёт эффективность разработчика, если его форсить писать всё "доказуемо на компиляции"(при том что большинство эффективного кода тогда просто будет невозможно)
0xd34df00d
09.07.2022 22:11+3при том что большинство эффективного кода тогда просто будет невозможно
Почему?
Кстати, к соседнему комментарию о бинарном дереве — можете сделать динамический массив, доступ к которому вне его границ тоже будет ошибкой компиляции?
cepera_ang
09.07.2022 23:08+3Почему же вы тогда не пишете про то, как упадёт эффективность разработчика
Или не упадёт, а перераспределится. С поиска непонятных зависаний и сегфолтов будет немного времени тратить при разработке. А некоторые ещё дальше идут и даже всякие формальные спецификации пишут, а то уж сильно сложно стало разные распределённые системы проектировать. Но вот всё доказывать пока ещё не получается — слишком много.
Понимаете, что есть разница между «доказывать всё формально» и «доказывать важные вещи формально» и «программист из головы должен сделать сам всё правильно»?
0xd34df00d
09.07.2022 22:09+3Очень круто. Покажете, как написать юзабельное в рантайме бинарное дерево, чтобы его несбалансированность была ошибкой компиляции?
Kelbon
09.07.2022 22:15Утверждаю, что это возможно. Только количество работы, которое вам придётся проделать будет велико.
И конечно же вы всегда можете ошибиться на уровне доказательства, так что ваша ошибка компиляции ничего не будет говорить, либо вовсе будет ложной. И так будет на любом даже теоретическом языке программирования.
А теперь представьте какого писать на языке, на котором вам придётся это ВСЕГДА описывать. Не даром такие языки не пользуются популярностью - на них просто хрен что напишешь
0xd34df00d
09.07.2022 23:11+3Утверждаю, что это возможно.
А я утверждаю, что нет, невозможно.
И конечно же вы всегда можете ошибиться на уровне доказательства, так что ваша ошибка компиляции ничего не будет говорить, либо вовсе будет ложной. И так будет на любом даже теоретическом языке программирования.
Нет. Ошибку на уровне доказательства поймает компилятор, в этом его и смысл.
Ошибиться я бы мог на уровне формулировки того, что я собираюсь доказывать, но, скажем, формулировка
maximum pathLengths - minimum pathLengths ≤ 1не оставляет особого простора для фантазии.cepera_ang
09.07.2022 23:15+2Да что вы сразу в какие-то дебри. Спросили бы хотя бы, можно ли убедиться, что в программе на С++ хотя бы выходов за границу массива нет :)
JordanCpp
09.07.2022 23:22Можно если юзать array или vector в дебаг режиме, вроде не только в методе at проверка есть, но и в []. Будет terminate, а не гребля по чужой памяти:)
cepera_ang
09.07.2022 23:25+1В рантайме же? Но при этом ничего не помешает кому-то написать без вектора и ходить напрямую как хочет и я об этом не узнаю, если не прочитаю лично весь этот код?
JordanCpp
09.07.2022 23:30Да. Можно обмазать санитайзерами и т.д Я вообще C# разработчик так что мои слова проверяйте. Я этот ваш C++ не понимаю:)
cepera_ang
08.07.2022 19:46+3Перечитал ещё раз и дошло, что «датафрейм», который в исходном варианте 20 минут обрабатывался — это массивчик 3*10 чисел, который пару раз сортируют, а потом умножают на константу и суммируют. Блин, ну это же просто ничтожный объём обработки данных. «Вау, компьютеры очень быстрые, наша функция, которая перемножает 30 чисел теперь занимает всего 201нс * 3 * 5 * 32 = 96 480 операций».
vassabi
08.07.2022 20:38он это проделывал 1000 раз ("Давайте измерим. насколько быстро работает эта функция при 1000 вызовах"(С) ), но в целом - я с вами солидарен

greck
08.07.2022 20:33Спасибо!
Тема также раскрыта в https://youtu.be/1nx3YXq6gG4
Научно технический-рэп, Папа может в Си
JordanCpp
08.07.2022 21:23+3Если сделать вывод. То программисты под влиянием бизнеса, а бизнес под условиями рыночка, всрали всю производительность, софт и фреймворки могут быстро работать, но в текущих условиях это невыгодно, а значит не нужно. Пара-пара-пам,:)
vassabi
08.07.2022 23:45+3как только "продукт продается" - то дальше оптимизировать невыгодно.
Вот реально - оптимизировали мы игровой движок в два раза, тут же набежали дизайнеры и вкрячили в два раза больше объектов в сцену.
Итого ФПС вписался в бюджет ? - все, значит следующий раунд оптимизации и рефакторинга "отложен до лучших времен" ...
dartraiden
09.07.2022 16:16+1но в текущих условиях это невыгодно
Даже не то, чтобы не выгодно, а практически вредно. Пока вы годами вылизываете производительность, конкурент уже выпустил продукт, продаёт его и разрабатывает следующее поколение продукта. К тому времени, когда ваш продукт выйдет на рынок, он уже будет безнадёжно опоздавшим. Оптимизированным, но никому не нужным, а на вас показывают пальцем «смотрите, они смогли догнать фирму А спустя 5 лет».cepera_ang
09.07.2022 21:35«Годами вылизываете» — это такой straw-man аргумент. А если мы не годами вылизываем производительность, а просто уделяем этому на 10х внимания, чем конкурент (т.е. в типичном случае не 0.5%, а 5% ресурсов, а то и вообще достаточно лишь не выбирать всегда не глядя строго «удобство разработчика» vs «производительность»).

avdx
08.07.2022 21:27+11По моему это статья не про то, насколько быстрыми могут быть компьютеры, а про то, насколько медленным может быть код на Python.
JordanCpp
08.07.2022 21:28-1Добавил статью в закладки, и буду кидать ее коллегам, кто скажет может попробуем питон. Не для всякой аналитики, а прям в прод.

dyadyaSerezha
09.07.2022 08:17Очень сильно от типа задач зависит. Во многих случаях можно и Питон в прод, легко.
JordanCpp
09.07.2022 10:45Но зачем? Греть воздух в серверной сильнее?:)
dyadyaSerezha
09.07.2022 17:59Можно и погреть, если на Севере)
Или если задача запускается иногда, по таймеру.
vikarti
10.07.2022 11:21И вспоминается мне EVE Online. Где и сервер и клиент внезапно написаны на питоне.
Правда там рендер там совсем не на питоне и питон не обычный а Stackless и куча хитрых оптимизаций(которые CCP не особо и скрывали) чтобы работало нормально а если начинает тормозить — чтобы тормозило для всех одинаково.

economist75
11.07.2022 07:44Плохой не Python и Pandas, плохой был первичный код, который в оригинале статьи - отсутствует. Статья понравилась. Она на самом деле повествует о том что несколько сомнительных преобразований сделали зачем-то в Pandas, причем обернули их во вложенные функции, вызов которых в Python и мн. других динамических языках - дорог. Писали, например, датасатанисты, которые в Pandas делают все, даже файловые операции. Видимо это работало, приносило прибыль. Но прод затребовал realtime. Дальше классика. Оптимизировал программист, наивно, без Pandas, на чистом Python и получил... внезапный прирост в ~100 раз. Ничего удивительного что плохой код можно улучшить многократно, просто переписав его "на месте", тем же языком, только правильно.
А вот все дальнейшие оптимизации были стандартны и предсказуемы. Они дали ускорение с 12 сек. до 0,2 сек. (в 60 раз), что хорошо подтверждается другими подобными статьями и кейсами. Но там никакого чуда нет - вынос тяжелых функций в C/Numba/Nuitka итд хорошо известен. Да, однопоточный Python медленнее статических многопоточных языков в ~60 раз, это всем хорошо известно и питонистами не оспаривается. Потому что в 98% задач это замедление незаметно никак. А если вспомнить что на Питоне пишется в в 100 раз быстрее - то рост его популярности становится не таким уж парадоксальным.Вывод: не стоит никого отговаривать данной статьей. Одни программисты ошибаются - другие исправляют, третьи пишут статьи с процентами ускорения вместо более понятных кратностей, видимо, для пущей важности. В промилле было бы еще быстрее.
cepera_ang
11.07.2022 07:54+1А если вспомнить что на Питоне пишется в в 100 раз быстрее
citation needed, как говорится.

kivsiak
08.07.2022 22:45Есть еще один ньюанс. Код на С должен выполняться не в 2 и не в 10 а сотни раз быстрее аналогичного кода на питоне. Но возникают проблемы c преобразованием типов из питона и обратно. К примеру небольшие функции смысла портировать нет. расходы на конвертацию съедят все.
nmrulin
09.07.2022 02:49Да, уж, убили Паскаль. Потом опять создали простой язык - Питон, но который в 100 раз медленее. Вот так "прогресс" и идёт.
dyadyaSerezha
09.07.2022 08:22+1Не читал кучу комментариев выше, но мне одному странно, что в реализации на С++ функция объявлена как double agg_efficient(), а возвращает вектор?
Ну и вообще, если вся реализация теперь на С++, то каким боком тут внешняя обёртка из Питона?
JordanCpp
09.07.2022 11:01Я тут разрабатываю в свободное время небольшую либу, как реализую базовый функционал надо будет написать на хабре статью.(Пока даже управление потоками нет)
https://github.com/JordanCpp/Lt
В ней и реализую разные концепции, возможность использовать аллокаторы, статическую линковку, pimpl на уровне заголовочных файлов и т.д
Lex20
09.07.2022 15:14И у меня есть такая помойка https://github.com/Alexey1994/Engine
Помойка только потому что ни мне ни кому-либо из моих знакомых оно не надо. Писал потому что мог и хотел.
Kelbon
09.07.2022 12:13+1Библиотека Pandas языка Python отлично подходит для экспериментов с данными, но ужасна в продакшене. Если оказалось, что вы используете её в продакшене, то настало время повзрослеть.
Если вы используете питон в продакшне, то пора повзрослеть.
В статье не рассмотрен ещё вариант с ХОРОШИМ кодом на С++
JordanCpp
09.07.2022 12:29-2Будьте осторожнее, за отрицание использования питона в проде минусуют:)
Lex20
09.07.2022 13:28А какая разница? Длина члена от этого не уменьшится. Сколько тут не пишу всегда минусуют. Вот вам конкретно для чего плюсы нужны? Я вот сишку без всяких плюсов использую, потребности в плюсах не испытываю, а если надо чего подинамичнее, то lua подключаю. И на хабре плюсы бесполезны, ибо плюсуют мусор в основном. Да и во всём интернете так: то что заплюсовано банальный шлак. А норм инфу массовый потребитель не понимает, ему пропаганду подавай, там где всё разжёвано и все вопросы отвечены.
JordanCpp
09.07.2022 13:47-2Я с вами согласен. В своем сообщении я специально, поставил смайлик в конце, дабы понять, что это саркастическое предложение.
JordanCpp
09.07.2022 14:03У меня другой опыт. Писал недо движок для простой 2d игры и скрипты планировал писать на c++, как и движок. Для простоты, не городить плагины в виде so и dll, а собирать в единый исполняемый файл. Плюсы меньше зависимостей, ну и по фану.
Lex20
09.07.2022 15:27А меня выбесило когда к жирным библиотекам ffmpeg затребовался некий ссаный sjlj, или как его там. Короче c++ слишком избыточный, не уважаю такие помойки, пишу на нём только за деньги.
JordanCpp
09.07.2022 15:47+1Ещё может потребовать theards-1.dll Если собирать mingw:) Можно с ключиками поиграться и компилятор встроит в exe. У меня наоборот, пишу на С# только за деньги.:)
vassabi
09.07.2022 20:19на самом деле - самые большие тормоза в современных программах не изза алгоритмов, а изза избыточного копирования (+ маршаллинг\демаршаллинг)
amarao
210 наносекунд на вызов - вполне, неплохо, хотя всё ещё далеко от line speed. line speed - это такая произвольная, но очень красиво выглядящая цель, пришедшая из сетевой подсистемы. Если у нас сетевой интерфейс работает на 25G, то это 4.8 миллиона мелких пакетов в секунду, то есть каждый пакет надо обрабатывать за 20 нс.
Соответственно софт (даже не связанный с сетью) можно называть line speed, если он такое может. У вас получается line speed для 2х гигабит (с хвостиком).
MentalBlood
Еще можно считать поток входящих и исходящих данных. Хорошо выглядит на алгоритмах для валидации/парсинга/генерации текста. Можно сравнивать с пропускной способностью памяти, например
fougasse
А еще понимать разницу между throughput и latency.
MentalBlood
Да, метрики разные
cepera_ang
Какой лайнрейт на питоне, лол. Люди, которые на нём работают настолько привыкли порядкам производительности в 1000х меньше ("смотри, я нажимаю ctrl-enter в джупитере и функция выполняется почти мгновенно"), что для них магия первый пункт из статьи. А часто и это излишество.
MaxLK
25G (сейчас обычно 10, 40, 100. при 25 переподписка от 2:1, а в сетях Клоса такого стараются избегать) это как правило аплинки на коммутаторах или порты на ТОРах/спайнах. то есть через эти порты проходит агрегированный трафик многих клиентов. обрабатывается он не процессором, а asic`ом. так что сравнение несколько не корректно. к примеру на NGFW трафик обрабатывается именно процессором и разбор трафика с шифрованием там на уровне 200-800Мб. к чему это? если данные передаются в пределах одного ЦОДа то считать line speed есть смысл. если данные передаются на другую площадку по шифрованным каналам - надо уточнять (или замерять) скорости у хостера. может оказаться что нет смысла в глубокой оптимизации кода в стремлении достичь 25Г. например по тому, что вашему серверу доступен всего 1Г из которых реально вы можете использовать 800Мб так как 20% полосы съедает служебная информация сетевого стека. впрочем... зачем программисту разбираться в сетях? ;)
cepera_ang
Вы не поверите, но есть серверы с 100, 200 и даже 400Гбитными адаптерами, которые самостоятельно обслуживают такой трафик.
MaxLK
хотите обсудить архитектуру НА ЦОДов? бывает много чего, речь о том, что надо исходить из возможностей имеющейся инфраструктуры, а не заниматься разгоном сферического коня в вакууме. асики на торах обрабатывают от 2Тб/сек. что эта информация Вам дает? Вы начнете оптимизировать весь ваш софт чтобы достичь таких же значений?
cepera_ang
При построении систем, решающих задачи из реальной жизни с помощью вычислений, всегда полезно понимать где находится на текущий момент аппаратная часть, потому что скорость развития отдельных аспектов и компонентов железа — разная и со временем это приводит к тому, что соотношения между скоростями и возможностями меняются, иногда радикально. Это приводит к тому, что архитектурные и программные решения, которые ещё недавно были оптимальными — перестают быть такими.
Поэтому, конечно нужно заниматься разгоном сферического коня в вакууме. А точнее хотя бы понимать пределы его скорости. Если мы пишем софт, который утилизирует датацентр на 1/10 теоретического пика — это более-менее нормально, а если на 1/1000 — то это значит, что мы можем обменять зарплату программистов на оптимизацию на уменьшение затрат на инфраструктуру. И тут уже зависит от размеров. Оптимизировать одну функцию, как в статье, может быть совершенно бесполезно (но и не слишком дорого, оптимизация из статьи занимает сколько? Столько же, сколько и написание исходной функции для специалиста?), а может иметь смысл, потому что тормоза в масштабе ЦОДа — это смерть от тысячи порезов.
Существующая инфраструктура — вторична по отношению к задаче, так же как и существующий софт. Если задачу может решить 800 серверов с гигабитными портами, а может один с 800-гигабитными, то имеет не мало смысла посмотреть, как бы эту задачу упихать в этот сервер и имеет ли смысл под него обновить/создать остальную инфраструктуру.
И да, не мало людей смотрят на 2Тб ASIC’и и думаю о том, как бы сделать такой же, но чтобы вот ещё была перепрограммируемая часть, чтобы вынести туда оверхед с серверов или что угодно. Разработка железа — это такое же программирование, только вид сбоку и миллион ограничений, о которых не думают чистые программисты, воспитанные в духе «а какое тут О большое» и пофиг на константы, доступ к памяти/сети/дискам/энергию.
MaxLK
очень похоже что Вы теоретик оторванный от жизни. вот уже лет 15 Вам никто сходу точно не скажет на каком именно железе в текущий момент Ваша задача и Ваши данные. если речь об энтерпрайзе который может себе позволить упомянутый сервер с 800Гб интерфейсом и еще 800 серверов.
любая задача имеет цену. имеет смысл исходить только из цены решения задачи. все остальное - бессмысленные фантазии.
асик это асик. никто о нем не думает, - им просто пользуются и 99,9% не знают что это, где, зачем и как оно работает. например Вы. а смотрят на его описание единицы которые понимают для чего и когда это делать.
если Вы не планируете обсуждать исходную тему, давайте прощаться. успехов.
cepera_ang
Какие-то проблемы с observability?
Иногда цена такая, что можно позволить себе даже не одного, множество теоретиков занимающихся бессмысленными фантазиями, в дополнение к практикам, решающим на чём есть.
Даже их создатели? Думаете они с неба сваливаются готовыми? А их характеристики не появляются из сочетания того, что возможно было реализовать и того, что хотели бы клиенты? Просто существует какой-то, абстрагированный от всяких теоретиков неизменный ход прогресса, который сам по себе даёт всё лучше железо и инфраструктурный софт, которым потом могут пользоваться «практики» на питоне, да?
0xd34df00d
В задачах, где это действительно важно, люди это знают с точностью до версии микрокода процессора.
MaxLK
что важно? в стойках с дисковыми полками на всех дисках версия микрокода одинакова как и версия микрокода на полках. на каком диске ваши данные никто не скажет. на хостах в серверных шасси версия микрокода одинакова, как и на шасси в кластере. на каком хосте ваше ПО в текущий момент - надо смотреть по тому что НА и балансировщик гоняют его между хостами постоянно. для высокой доступности версии микрокода выравниваются автоматически ПО управляющим оборудованием. версии микрокода точно известны и доступны к просмотру в интерфейсе управления. рекомендуемы производителем оборудования версии мирокодов указаны в документации. какое отношение фантазии про микрокод имеют к обсуждаемой теме оптимизации прикладного ПО? зачем вообще пытаться выдумывать мифическую задачу (которая, кстати решена десятки лет назад) в области, в которой не работаешь и про которую имеешь крайне отдаленное представление?
0xd34df00d
Так мы обсуждаем прикладное ПО, крутящееся у людей на их машинах, или что-то в ЦОДах?
Не знаю, я могу только за себя отвечать.
Вы пишете, что никто не скажет, а я пишу, что минимум две из трёх компаний, где что-то надо было оптимизировать, которые не были недостартапами, и где я работал, вполне себе сказали бы.
MaxLK
началось все с этого: " Если у нас сетевой интерфейс работает на 25G, то это 4.8 миллиона мелких пакетов в секунду, то есть каждый пакет надо обрабатывать за 20 нс. "
я вот не знаю людей у которых дома реальная потребность в таком оборудовании и оно же в наличии и купленное за свои. поэтому у меня не возникал вопрос о том где работает ПО. опять же автор обсуждаемой статьи изначально говорил о приложении которое планируется использовать в ЦОДе.
ну да, если у вас оборудование домашнего или сохо уровня, то сказать где что в общем-то не сложно. но изначально речь вроде как шла об энтерпайзе? ну вот эта фраза автора "Нужно учесть, что вывод этой функции должен быть вычислен менее чем за 500 мс, чтобы она хотя бы попала в продакшен (где нам нужно менее чем за 500 мс выполнить 400-800 вызовов этой функции)." как бы однозначно намекает что используется оборудование и объемы не домашнего уровня.
хотя может быть я ошибаюсь и люди массово используют подобные задачи дома или в организациях 10-20 человек на своем оборудовании из пары серверов с дисками без рейдов уровня отличного от 1/10 или более современных технологий.
fougasse
При чем здесь «дома»?
MaxLK
при уровне технологий используемых в оборудовании и ПО. я говорил что в НА кластере с включенными DRS и SDRS сказать на каком хосте выполняется ПО в данный момент затруднительно, нужно зайти в консоль управления и посмотреть (и в данном случае микрокод на всем оборудовании будет либо одинаков либо достаточно совместим для работы данных технологий и ваше ПО не увидит разницы). мне ответили что такое возможно. да, такое возможно. но только если у вас нет данных технологий. а это значит что использует что-то более примитивное, рассчитанное на сегмент малого офиса или домашнего использования ("дома"). то же самое относится к системам хранения: если Вы можете точно указать на каком диске ваши данные у вас СХД или рейдов (кроме 1 и 10) просто нет.
я вижу что обсуждение зашло в тупик. уже никто не помнит с чего все началось и все пытаются обсудить что-то совершенно иное, что не все понимают. давайте закругляться - выхлоп от этой беседы какой-то нулевой для всех участников. если кому-то принципиально - считайте что я ничего не понимаю и несу чушь. займемся чем-то более полезным и интересным! ;)
cepera_ang
Лично я вообще перестал понимать, о чём вы говорите. Микрокод только у дисков бывает (и что за микрокод дисков вообще?)? Оптимизацию только прикладному ПО делают? Что за мифическая задача, решённая десятки лет назад?
amarao
Уже давно нет. Сервер с парочкой 25G стоит 2 бакса в час. Если напрячься, то будет и 4x25.
100G уже более экзотика, но 25G вполне на рынке уже присутствует.
cepera_ang
4*100Гбит в AWS стоит 13 баксов в час (или 5, если на три года резервировать).