Задача актуальна для фин. организаций и ретейла. Как мы подошли к ней и почему выбрали для обучения уменьшенную версию модели DistilBert, рассказывают наш data scientist Бондарь Андрей и владелец продукта Гриднев Владислав.

Банки и интерес к чекам
Предприниматели обязаны передавать информацию по чекам в ФНС — это требование 54-ФЗ. Посредниками в этом процессе выступают операторы фискальных данных (ОФД). Они же перепродают информацию о покупках банкам, которые собирают статистику об интересах клиентов и на её основе делают персональные предложения. Но есть нюанс — данные по чекам приходят в сыром текстовом виде. Каждый магазин описывает товары в произвольном формате (с сокращениями и собственными аббревиатурами), поскольку эта процедура не регламентирована 54-ФЗ. В итоге перед банками стоит нетривиальная задача по выделению и структурированию категорий товаров и брендов.
Именно с таким кейсом к нам обратилась крупная финансовая организация. Проблема показалась нам интересной, плюс мы увидели в этом возможность прокачать NLP-экспертизу и поработать с новыми подходами в машинном обучении. Сегодня хотим разобрать задачу подробнее и рассказать, как мы подошли к разработке системы категоризации чеков DataCheckEngine.
Последовательность действий
Мы разбили проблему на три подзадачи. Во-первых, по каждой позиции в чеке необходимо определить наименование продукта, однозначно отражающее его содержание — например, не «палочки», а «кукурузные палочки». Во-вторых, нужно определить категорию товара. В-третьих, вычленить объем (вес), единицы измерения и бренд. Например, вот так может выглядеть схема категорий для литровой бутылки кефира:

Категории товаров. Первый справочник категорий решили собрать, опираясь на интернет-каталоги магазинов, но столкнулись с проблемами. Блоки в них зачастую пересекались друг с другом и имели различное количество уровней вложенности, что в перспективе снизило бы эффективность модели машинного обучения.
Тогда мы взяли случайную выборку позиций чеков и разметили её вручную, придерживаясь двух принципов — категории должны быть уникальны и иметь всего два уровня вложенности. Разметку проводили внутренними ресурсами команды — по нашему опыту так она получается качественнее, по сравнению с результатами использования сторонних сервисов. Вообще, такой практики придерживаются многие известные компании — например, Tesla. Автопроизводитель перенес разметку данных для беспилотников в in-house формат, когда специалисты по системам ИИ работают плечом к плечу с «разметчиками».
Далее, мы начали обогащать тренировочную выборку. Возник вопрос — как добавить в неё данные по недостающим категориям, если мы еще не знаем категории позиций чеков. Проблему решили двумя способами: а) вручную искали необходимые позиции по ключевым словам, б) передавали ML-модели новые порции данных и самостоятельно категоризировали ответы с низким уровнем уверенности.
Расширяя выборку, важно не допустить переобучения модели. Иначе она просто запомнит конкретный список чеков и начнет ошибаться. Баланс точности и полноты алгоритма отражает F1-мера. Оптимальное значение метрики зависит от конкретной задачи — в нашем случае она составила 0,95.
В итоге финальная версия справочника содержит двадцать две категории первого уровня:
Авто |
Одежда, обувь, аксессуары |
Товары для животных |
Алкоголь |
Подарки и сувениры |
Товары для здоровья |
Бытовая техника |
Продукты |
Товары для красоты |
Дача, сад и огород |
Прочее |
Услуги |
Детские товары |
Спорт и отдых |
Хобби и творчество |
Досуг и развлечения |
Строительство и ремонт |
Электроника |
Канцтовары |
Табачная продукция |
|
Кафе, ресторан, доставка |
Товары для дома |
На практике они покрывают значительную часть потребительской корзины среднестатистического россиянина. Каждая категория имеет детализацию второго уровня. Она менялась по мере понимания содержимого чеков. Например, в них стали попадаться снэки, джемы и варенья — отнести эти продукты в существующие категории было проблематично. В итоге мы добавили отдельные подкатегории — «Снэки» и «Джем, мёд, варенье, сиропы и топпинги».
Похожая история произошла с чаем и кофе. Напитки можно взять навынос в кафе, найти на полке или купить в бутылке — все это разные категории. Так, чай в чайничке попадет в категорию «Кафе, рестораны, доставка», чай в бутылке — «Холодный чай и кофе», а кофе навынос — «Чай, кофе с собой». Последняя категория может быть интересна банкам с точки зрения удобства клиентов, если есть планы разместить точку кофе в отделении.
Вот так выглядит итоговая детализация самой многочисленной категории «Продукты» — тридцать пять подкатегорий:
Безалкогольное пиво и вино |
Мясная гастрономия |
Биойогурты и кисломолочные продукты |
Полуфабрикаты |
Блюда быстрого приготовления |
Рыбная гастрономия |
Всё для выпечки |
Снэки |
Детское питание |
Соки и нектары |
Джем, мёд, варенье, сиропы и топпинги |
Соль, специи, сахар |
Диетическое и спортивное питание |
Соусы, растительные масла |
Замороженные продукты |
Сухофрукты, семечки, орехи |
Йогурты и молочные напитки |
Сырная продукция |
Кондитерские изделия |
Торты, пирожные, суфле, десерты |
Консервация |
Фрукты, овощи и грибы |
Крупы, бобовые, макаронные изделия |
Хлеб и выпечка |
Лимонады и газированные напитки |
Хлопья, мюсли, сухие завтраки |
Минеральная и питьевая вода |
Холодный чай и кофе |
Яйца |
Чай, кофе, какао |
Молоко и молочные продукты |
Чай, кофе с собой |
Мороженое |
Энергетические напитки |
Морсы, кисели, компоты |
Наименования продуктов и бренды. Первым делом внутри позиции чека необходимо было разобраться, с каким продуктом мы имеем дело. Например, бумага может быть офисной и туалетной, а перчатки — медицинскими или кожаными. Также чеки содержали словосочетания вида «бумага для …» или «салат с …». Можно было разметить продукты в виде словосочетаний, но это трудоемкая задача. Мы применили метод n-грамм с отбросом ненужных слов.
Смысл в том, чтобы настроить множество n-грамм (мы использовали до семи слов в словосочетании), а затем отфильтровать их по окончаниям, союзам и частоте. Так мы получали почти идеальные продукты для конкретной позиции чека, которые можно было передавать моделям для обучения.
Например, для слова “батончик” мы получили вот такие n-граммы:
'шоколадный батончик', 'батончик злаковый', 'батончик протеиновый',
'мороженое батончик', 'батончик с арахисом', 'батончик молочный',
'батончик фруктово-ореховый'Для слова “сливки”:
'сливки питьевые', 'сливки для кофе', 'сливки для взбивания'Для слова “бальзам”:
'бальзам для волос', 'бальзам для губ', 'гель-бальзам', 'крем-бальзам',
'бальзам-ополаскиватель', 'бальзам для тела', 'оттеночный бальзам',
'бальзам для всех типов волос', 'бальзам для окрашенных волос'Помимо развернутого описания продукта в виде n-грамм, мы возвращаем и ключевое слово, образующее название продукта. Так, для «шоколадного батончика» мы возвратим слово «батончик». Оно может служить тегом для поиска товаров в банковском приложении. Что касается брендов, то в плане разметки мы поступили похожим образом. Написали функцию на regex, которая ищет бренды в списке из 200 тыс. наименований — так мы получили почти идеально размеченные данные. Далее, после некоторой предобработки, передали в модель для обучения. Через regex также определяем меры и объемы.
В то же время наш категоризатор товарных чеков умеет нормализовать текст — очищать от «мусора» и править некорректные написания компаний-производителей. Например, вот такой вот «крякозябр»:
Нап с/а RED DEVIL ИнаяСила7,2% ж/б0.45L
Система восстановит как:
НАПИТОК СЛАБОАЛКОГОЛЬНЫЙ RED DEVIL ИНАЯ СИЛА 7.2% ЖЕСТЯНАЯ БАНКА 0,45 ЛИТРОВ
Если говорить о точности моделей, то:
F1-мера по категориям — 95.0817 % (кол-во обучение — 225415, тест — 50357)
F1-мера по продуктам — 96.1165 % (кол-во обучение — 763348, тест — 84817)
F1-мера по брендам — 96.4335 % (кол-во обучение — 841214, тест — 93469)
Код для обучения языковой модели на выборке из 10 тыс. чеков мы выложили в открытый доступ в виде Jupyter Notebook. Там же можно найти семпл из 3 тыс. размеченных брендов для дообучения текстового категоризатора чеков в Pytorch.
Железо и алгоритмы
Предобучение модели проходило на 7,3 млн чеков. Для обучения применили уменьшенную версию DistilBert и библиотеку Transformers.
Мы пробовали использовать CNN-модели c эмбеддингами GloVe. Да, они работают очень быстро — на один запрос уходит порядка 10 мс — но проигрывают по точности, что нас не устраивало. В свою очередь, Bi-LSTM дают сопоставимый результат по точности, но уступают по скорости — 40 мс на запрос. Измерения мы проводили на CPU в Pytorch. Библиотека зарекомендовала себя как более быстрая, по сравнению с TensorFlow.
Сфера NLP уходит от классических моделей LSTM и CNN в сторону attention based models. Дистилляцией и уменьшением числа параметров модели можно добиться внушительных скоростей при приемлемой точности. Также существует тренд на экстремальную дистилляцию архитектур больших моделей.
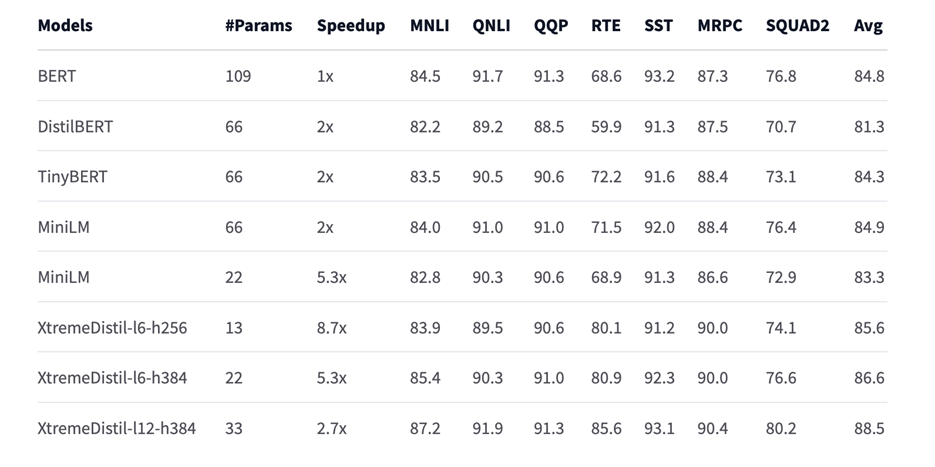
Уже есть решения вроде MiniLM и XtremeDistil-l6-h256, которые в пять-девять раз быстрее обычного BERT. К сожалению, кода для предобучения этих моделей нет в открытом доступе. Тюнинговать нашу модель на английской или мультиязычной версиях не очень хотелось, так как страдает точность. Поэтому мы и остановились на классическом, но надежном DistilBert.
Что в итоге
DataCheckEngine преобразует наименования позиций чеков в понятный формат. Получили достойные значения метрик категоризации на примере чеков среднестатистического потребителя с фиксированным списком категорий. В зависимости от задачи и вводных наше решение можно адаптировать для иного заказчика. В идеальном случае достаточно подставить в модель новый справочник категорий, и она заработает без переобучения. Для реализации более глубокой аналитики вроде анализа спроса на товар в конкретный момент времени потребуются дополнительные работы.
Возможно, у вас возник вопрос, откуда для этого брать «живые чеки»? И как финансовые организации связывают с ними покупки клиентов? У нас есть опыт реализации таких проектов, и мы поделимся им в следующих материалах.
Комментарии (7)

ALIron
21.07.2022 12:12Как с первичными данными обстоят дела?
Данные вида "Нап с/а RED DEVIL ИнаяСила7,2% ж/б0.45L " редко встречаются в чеках.
Чаще всего это невнятное неидентифицируемое даже человеком нечто, которое может трактовать только продавец и покупатель, если он еще помнит что покупал.Наиболее же интересно сравнить два товара в двух соседних магазинах разных ретейлеров.
Но на тех данных чеков что есть сейчас сделать это практически невозможно. Жаль что не передается в чеке GS1 или штрихкод или его хэш.
vladgridnev
21.07.2022 13:23Как с первичными данными обстоят дела?
Все в порядке. Кассовики их охотно продают в обезличенном виде - так, чтобы можно было понять долю уникальных клиентов или точек продаж в данном наборе переданных чеков. Но для категоризации они отдают полные наименования чеков под любые запросы - можно выбрать даже категорию из их перечня.
Данные вида "Нап с/а RED DEVIL ИнаяСила7,2% ж/б0.45L " редко встречаются в чеках.
С чего бы? Продуктовых точек в РФ очень много. Такого полно. А вот непонятного, что может трактовать только продавец - мало, это как раз таки регламентируется 54 ФЗ. А если там совсем ерунда, которую даже человек неспособен понять, то такой чек не представляет ценности в маркетинге.
Наиболее же интересно сравнить два товара в двух соседних магазинах разных ретейлеров.Но на тех данных чеков что есть сейчас сделать это практически невозможно. Жаль что не передается в чеке GS1 или штрихкод или его хэш.
А в чем вы видите задачу сравнения с точки зрения бизнеса? Сравнить имеющиеся чеки нашим решением как раз возможно и провести достаточно глубокую аналитику. Другой вопрос, что мы не можем покупать чеки конкретного юр. лица, не имея на то их согласия. Т.е. кассовики вам никогда не назовут наименование или ИНН юр. лица, продавая семпл чеков. Отсюда сравнить условную "Пятёрочку" с "Дикси" не выйдет.
ALIron
21.07.2022 14:09может у нас разные пятерки / дикси / перекрестки и рыбные/мясные лавки и фруктовые / овощные магазинчики. у меня чеки мало пригодные для чтения .
по реглементирование 54 ФЗ, удивили, посмотрю. Спасибо.
про кассовиков не совсем понял в чеке же есть ИНН.
ИНН-> ЕГРЮЛ->ОКВЭДvladgridnev
21.07.2022 18:09может у нас разные пятерки / дикси / перекрестки и рыбные/мясные лавки и фруктовые / овощные магазинчики. у меня чеки мало пригодные для чтения .
В рамках более глобальной задачи по матчингу транзакций на чеки в ОФД мы имели доступ к большому массиву данных по РФ, чеки разнятся, бывают магазины с четкими написаниями, бывают такие сокращения. И те и те закупали для обучения нашего категоризатора.
по реглементирование 54 ФЗ, удивили, посмотрю. Спасибо.
Если не дословно, ФЗ регламентирует, что покупатель должен понять, какой вид товара он купил вплоть до единицы. Условно, нельзя написать в чеке "товар 1" или "футболка 1", "футболка 2" - если футболка 1 - это, допустим детская футболка, а футболка 2 - мужская. Однако, можно написать наименование буквенно-цифровое, если по какой-то причине это однозначный товар. Например, коды запчастей автомобилей концерна VAG. Но сокращать и коверкать слова продавцы могут как угодно, это не регламентировано.
про кассовиков не совсем понял в чеке же есть ИНН.ИНН-> ЕГРЮЛ->ОКВЭД
Вы, имея какой-то объем чеков, оперируете тем, что вы его уже получили и он у вас есть законно вместе со всей персональной информацией - ИНН продавца, возможно, e-mail физ. лица, владеющий этим чеком. Т.е. у вас получены согласия этих юр. лиц и физ. лиц соответственно (это тоже, кстати из 54 ФЗ). Однако, в жизни, вы можете так получить максимум свои чеки. Тогда там будет персональная информация точки продажи - чек ведь ваш. Но глобально, в рамках решения задачи под финансовую организацию или ритейл (который хочет получить чеки конкурентов, к примеру), чтобы получить, а уж тем более, работать с такими чеками, нужно согласие этих самых владельцев персональной информации и владельца чека.
Пример, если банк хочет работать с чеками своих клиентов, он сначала получает с них согласия, потом только закупает их чеки у ОФД вместе со всей информацией по юр. лицу точки продажу, а уже потом обрабатывает их в своих целях для маркетинга. Вопрос, как понять, что данная транзакция клиента равна данному чеку - за рамками, это наш отдельный опыт, о котором с удовольствием расскажем в следующей статье.

andreybondar
21.07.2022 18:12Первичные данные имеют самую разнообразную структуру. Данный пример был взят как один из самых сложных. Что касается сравнения товарных позиций разных магазинов - да, это интересная задача, которая могла бы решаться нашим продуктом.
ZloyVampir
С одной стороны, цель понятна. С другой - а зачем кусать кактус со сложной стороны?
В каждом чеке есть обязательно ИНН организации. Через ИНН можно сделать две полезные вещи:
1) Узнать ОКВЭД
2) Завести словарь Организация - род деятельности.
И по каждому чеку вы теперь примерно понимаете категорию.
vladgridnev
ОКВЭД не дает вам детальной категории товара. К примеру, вы можете узнать, что какое-то юр. лицо магазина "Ашан" занимается продуктами, но какую это даст картину о клиенте, если он покупал там велосипед, чайник или что-то не из продуктов? Мы же говорим о более детальных категориях и работе с такими сущностями как продукт и бренд.