Введение
В данной статье рассматривается способ использования GPU nVidia с технологией CUDA в Docker-контейнерах для распределенной тренировки моделей машинного обучения на нескольких машинах. Цель статьи - показать вариант использования Big Data Tool Apache Spark в Docker-контейнерах, совместно с акселератором GPU вычислений Rapids на устройствах nVidia CUDA, с применением библиотек DJL, Spark ML, XGBoost, в приложении Spring Boot на Java 8 (требование Rapids), на нескольких машинах под управлением ОС Windows 10 Pro для решения задачи тренировки моделей машинного обучения в распределенной системе. Те же контейнеры в дальнейшем можно использовать в Kubernetes.
Важное условие, из которого вытекают все болезненные решения - все действия выполняются в ОС Windows 10 Pro. Далее в статье будет рассмотрен рассмотрен вариант использования WSL2 (Linux Subsystem for Windows), но прежде важное требование - новейшие версии Rapids не работают с видеокартами на архитектуре Pascal, т.е. для запуска примеров в среде Windows требуется видеокарта nVidia на архитектуре Turing (серии 1600, 2000) и выше. Под OC Linux карты на архитектуре Pascal работать будут, рекомендуется запускать примеры ниже на Ubuntu 20.04 (наверняка, Debian 10 так же будет работать), но не выше - требование Rapids.
Еще одним важным условием является реализация всех примеров именно на Java. В мире Spark (вместе со Spark ML) более распространен вариант использования Scala. Scala я не знаю, и особого желания изучать нет, а вот желание изучить Spark и ML для собственного развития и решения широкого круга задач имеется. Учитывая, что Scala и Java равнозначны в среде Spark, в отличие от того же Python, и что на Java существует ряд библиотек ML, которые можно использовать совместно со Spark, и принимая во внимание уже имеющийся опыт работы с ним, решение попробовать реализовать несколько примеров не заставило себя ждать.
Код статьи проверен на Windows 10 Pro, GeForce RTX 2060 и 1080 Ti (с последней на Windows не заработало), часть скриншотов сделано во время настройки второй машины с картой GeForce 1650. Предваряя вопрос читателя, почему бы все не сделать на той же Ubuntu 20.04, отвечаю: а) так каждый сможет, вы на винде попробуйте; б) нет технической возможности (Cloud не вариант - дорогие машины с GPU).
Целевая схема запуска представлена на рисунке ниже:
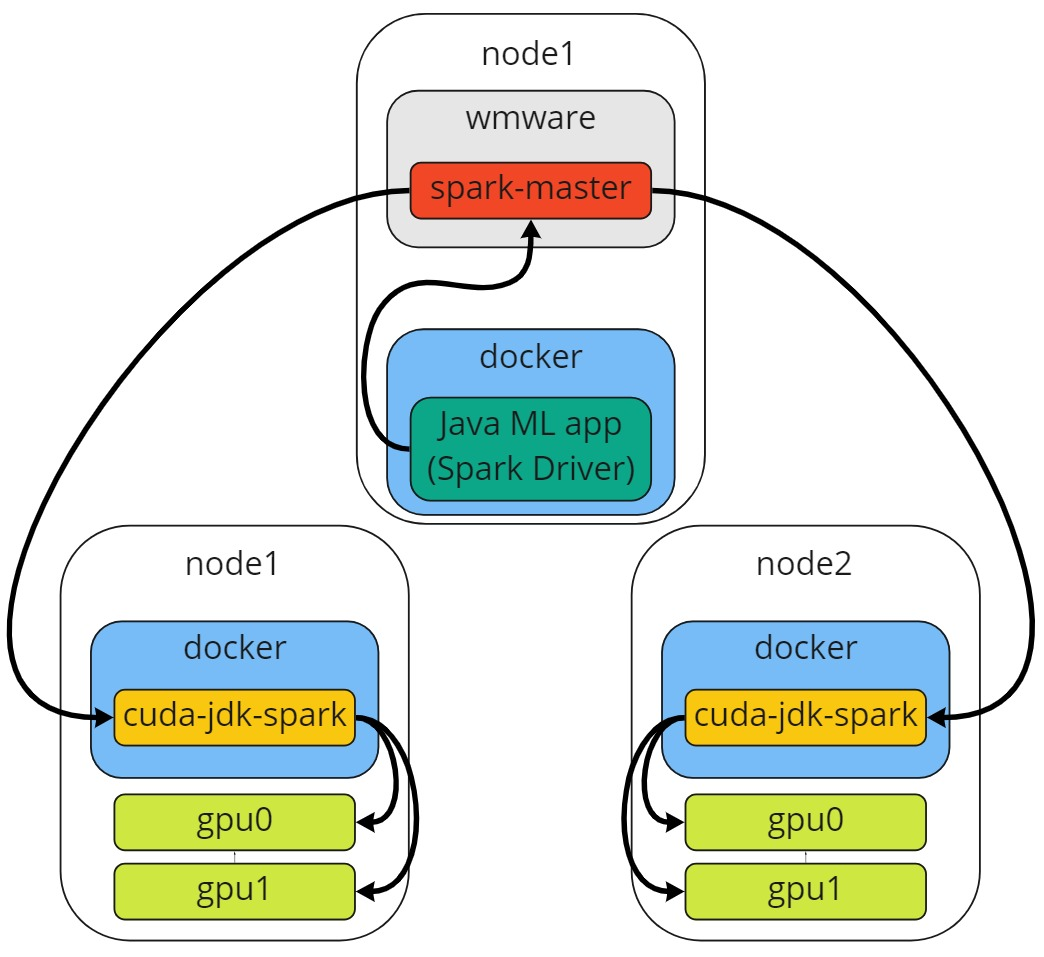
Т.е. имеется от двух до n нод, на каждой из которых от 1 до m GPU устройств, docker runtime с контейнером Spark worker, из которого доступны GPU.
Hardware и software слои описываются схемой:

Докер позволяет запускать множество контейнеров с различными приложениями:

Это подходит для задач распределенной тренировки моделей ML в инфраструктуре Apache Spark: в настоящей статье рассматривается пример запуска Standalone кластера Apache Spark с одним Master узлом, двумя Worker узлами на разных машинах, и Spring Boot Java 8 приложением с использованием библиотек DJL, Spark ML и XGBoost в отдельном контейнере (спойлер - заработало не все, и не заработает без машины с Linux).
Интересным является возможность использования Embedded устройств nVidia для IoT-устройств.

Весь нижеописанный код доступен в репозитории GitLab.
Подготовка окружения
Все нижеследующие действия выполняются на Windows 10 Pro. Важно выполнять именно на конфигурации не ниже Pro, и сборке Windows 10 Build 19043.1263 (21H1).
WSL, Docker и CUDA будут установлены в рамках данной статьи.
Рекомендуемая версия WSL 5.10.16.3+;
Docker 19.03+.
Рекомендуется установить Windows Terminal для открытия множества вкладок терминала: PowerShell, cmd, Ubuntu.
nVidia driver, CUDA
Убедитесь, что версия nVidia CUDA не ниже 11.7. Драйвер, который содержит данную версию, на момент написания статьи имеет версию 516.40.
Проверить версию драйвера и CUDA можно, открыв Powershell (лучше сразу открывать от имени администратора, но это требование для будущих действий) и выполнив команду
nvidia-smi
WSL - Windows Subsystem for Linux
Для того, чтобы использовать GPU в Docker-контейнерах, необходимо установить ПО от nVidia (см ниже), которое требует установки WSL2.
Если на ПК пользователя WSL не установлена, то можно установить командой ниже:
wsl --installЕсли WSL уже установлена, лучше обновиться до последней версии и проверить версию Ubuntu, должна быть 2.
Требуется перезагрузка. После перезапуска установится Ubuntu для Windows в отдельном окне

По окончанию установки можно проверить версию WSL в Powershell
wsl -l -v
В случае, если версия Ubuntu 1, следует ее обновить
wsl --set-version Ubuntu-20.04 2Docker Desktop
Следует установить Docker Desktop, если еще не установлен. Если установлен, рекомендуется обновить.
На момент установки на систему без Docker Desktop, моему выборы были представлены следующие настройки:

Я оставил оба чекбокса активированными. По окончанию установки требуется перезагрузка. В настройках необходимо убедиться, что чекбокс “Use WSL 2 based engine” активирован.

Apply & Restart.
Можно проверить, что в wsl появились новые записи в списке

Проверить работу Docker можно командой
docker run -d -p 5000:5000 --restart=always --name registry registry:2Установится локальный docker registry, который будет полезен в последующей работе.
docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
745b50d66906 registry:2 "/entrypoint.sh /etc…" 2 minutes ago Up 2 minutes 0.0.0.0:5000->5000/tcp registryCUDA Support for WSL 2
Ключевым моментом является поддержка работы CUDA в докер-контейнерах, для этого у nVidia есть решение.
Выполнить следующие шаги в PowerShell под именем администратора:
wsl
sudo -i
apt-key del 7fa2af80
wget https://developer.download.nvidia.com/compute/cuda/repos/wsl-ubuntu/x86_64/cuda-wsl-ubuntu.pin
mv cuda-wsl-ubuntu.pin /etc/apt/preferences.d/cuda-repository-pin-600
wget https://developer.download.nvidia.com/compute/cuda/11.7.0/local_installers/cuda-repo-wsl-ubuntu-11-7-local_11.7.0-1_amd64.deb
# see the output of the previosly command
cp /var/cuda-repo-wsl-ubuntu-11-7-local/cuda-B81839D3-keyring.gpg /usr/share/keyrings/
apt-get update
apt-get -y install cudaТеперь нужно проверить в отдельном окне PowerShell работу тестового контейнера nVidia с флагом benchmark:
docker run --gpus all nvcr.io/nvidia/k8s/cuda-sample:nbody nbody -gpu -benchmarkЕсли вывод содержит нечто подобное, все шаги выполнены корректно и можно продолжать работу.

Если имели место ошибки, рекомендуется обратиться к страницам документации nVidia здесь и здесь для их решения.
Подготовка образов и запуск контейнеров
Учитывая, что для работы Rapids необходимо использовать Java 8, следующие шаги по подготовке всех необходимых Docker образов, а в последующем и самих приложений, будут выполнены исходя из данного требования.
Базовый образ для приложений и Spark Workers
Первоначально необходим самый базовый образ. Ниже листинг Dockerfile.
Используется базовый образ Ubuntu 20.04 с CUDA 11.7.0 из репозитория образов nVidia. Доступный образ с Ubuntu версии 22.04 не подошел по причине совместимости всех компонентов системного ПО, необходимого для запуска прикладного ПО.
FROM nvcr.io/nvidia/cuda:11.7.0-devel-ubuntu20.04
ENV LANG='en_US.UTF-8' LANGUAGE='en_US:en' LC_ALL='en_US.UTF-8'
ARG DEBIAN_FRONTEND=noninteractive
RUN apt-get update && apt install -y bash tini libc6 libpam-modules libnss3 procps nano iputils-ping net-tools
RUN apt-get update && \
apt-get install -y openjdk-8-jdk && \
apt-get install -y ant && \
apt-get clean && \
rm -rf /var/lib/apt/lists/* && \
rm -rf /var/cache/oracle-jdk8-installer;
# Fix certificate issues
RUN apt-get update && \
apt-get install -y ca-certificates-java && \
apt-get clean && \
update-ca-certificates -f && \
rm -rf /var/lib/apt/lists/* && \
rm -rf /var/cache/oracle-jdk8-installer;
# Setup JAVA_HOME, this is useful for docker commandline
ENV JAVA_HOME /usr/lib/jvm/java-8-openjdk-amd64/
RUN export JAVA_HOME
CMD ["tail", "-f", "/dev/null"]
Используемым в образе JDK является openjdk8, что соответствует требованиям Rapids и не испытывает проблем с лицензионным соглашением Oracle JDK. Также в образ устанавливается набор приложений для дебага.
Инструкция CMD не обязательна, но удобна для отладки.
Стоит заметить, что первоначально используется базовый образ nVidia с пометкой “devel” - тестирование происходило именно на нем, чтобы исключить возможные ошибки, связанные с недостаточностью компонентов.

При этом, имеется образ:

отличие от devel - отсутствие “nvcc”.
Собирается образ командой:
docker build -f Dockerfile-cuda-java8 -t localhost:5000/cuda-jdk8:v1 .Обращаю внимание, что на моей локальной машине имеется контейнер с репозиторием образов Docker, мне удобно при работе с локальным кластером Kubernetes указывать в манифесте свои образа из localhost:5000, и загружать их, не используя внешние репозитории.
Запускается контейнер командой:
docker run --gpus all --name=cuda-jdk8 -it -d localhost:5000/cuda-jdk8:v1Примечание: важным флагом является “--gpus”, которому передается значение “all” - благодаря данному флагу контейнеру доступны все ресурсы gpu локальной машины.
Проверить работоспособность базового образа можно путем выполнения в контейнере двух команд:
$ nvidia-smi
Sun Jul 10 13:58:20 2022
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 515.48.07 Driver Version: 516.40 CUDA Version: 11.7 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... On | 00000000:0B:00.0 On | N/A |
| 0% 42C P8 20W / 250W | 1241MiB / 11264MiB | 4% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
$ nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2022 NVIDIA Corporation
Built on Tue_May__3_18:49:52_PDT_2022
Cuda compilation tools, release 11.7, V11.7.64
Build cuda_11.7.r11.7/compiler.31294372_0При использовании базового образа “runtime” nvcc --version выведет ошибку, так как nvcc отсутствует в данном образе.
Если нет похожего вывода какой-либо из команд, следует вернуться к предыдущим разделам и проверить корректность выполнения всех шагов.
Образ Spark Worker
Следующий шаг - подготовка образа Spark Worker.
Здесь следует отметить, что в данной статье рассматривается запуск кластера Spark как Standalone кластера, без менеджера ресурсов. Spark Master запускается на локальной виртуальной машине (у меня уже имелся настроенный мастер на виртуальной машине для тестирования работы Spark с Cassandra в рамках другой задачи, которая в настоящей статье не рассматривается), и к ней подключается Spark Worker в Docker контейнере. Полезность данного теста состоит в том, что:
а) тестируется работоспособность GPU-нагрузки в контейнерах;
б) для последующей работы остается пример Standalone кластера и Docker-образ для Kubernetes кластера.
Следует так же отметить, что образ Spark может быть использован и для запуска контейнера с Spark Master.
Кратко обо всех способах запуска Spark, как в локальном и standalone режимах, так с использованием Kubernetes, можно прочесть здесь, а о различиях менеджеров Yarn и Mesos можно прочесть здесь, или изучить вопрос самостоятельно.
Подготовка
Необходимо загрузить архив со Spark с официального сайта. Ввиду проблем с совместимостью именно в моей программно-аппаратной конфигурации, мне пришлось использовать версию 3.2.1, хотя, на момент тестирования (и написания данной статьи) уже доступна версия 3.3.0.
Распаковать содержимое в директорию spark (или воспользоваться подготовленными примерами из репозитория).
После распаковки архива директория spark должна иметь следующий вид:

Rapids resources
За исключением директории rapids. Ее нужно создать и загрузить в нее файлы *.jar с сайта Rapids. На момент написания статьи доступен релиз 22.06.0, который совмещает в себе два представленных на скриншоте файла. Но на момент тестирования свежей версией была 22.04.0.
Сначала я хотел написать, что оставляю этот момент без изменений, однако, когда я тестировал Spring сервис перед публикацией статьи на 1080 Ti, я все же попробовал использовать 22.06.0. На 1080 Ti все равно не заработало, однако последняя версия вывела сообщение для дебага, благодаря которому я узнал, что новая версия Rapids в связке с Pascal и WSL2 работать не будет. Читатель может использовать любую версию из упомянутых, а в репозитории с примером остается 22.06.0.
Скрипт getGpusResources.sh нужен для обнаружения GPU ресурсов:
#!/usr/bin/env bash
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
# This script is a basic example script to get resource information about NVIDIA GPUs.
# It assumes the drivers are properly installed and the nvidia-smi command is available.
# It is not guaranteed to work on all setups so please test and customize as needed
# for your environment. It can be passed into SPARK via the config
# spark.{driver/executor}.resource.gpu.discoveryScript to allow the driver or executor to discover
# the GPUs it was allocated. It assumes you are running within an isolated container where the
# GPUs are allocated exclusively to that driver or executor.
# It outputs a JSON formatted string that is expected by the
# spark.{driver/executor}.resource.gpu.discoveryScript config.
#
# Example output: {"name": "gpu", "addresses":["0","1","2","3","4","5","6","7"]}
ADDRS=`nvidia-smi --query-gpu=index --format=csv,noheader | sed -e ':a' -e 'N' -e'$!ba' -e 's/\n/","/g'`
echo {\"name\": \"gpu\", \"addresses\":[\"$ADDRS\"]}Datasets
Еще одна директория - datasets. В ней хранятся файлы *.csv и *.parquet, которые в последующем будут использованы в приложениях как обучающие и валидирующие датасеты. Взять можно здесь.
Spark config files
Пройдемся по всем директориям, в которых нужно внести изменения.
Все рабочие конфиги представлены в репозитории примера.
Директория conf
Директория содержит шаблоны конфигов. Задействовать каждый можно путем копирования шаблона в ту же директорию и удаления “.template” в имени файла:
Таким образом, редактируется файл spark-defaults.conf:
spark.master spark://192.168.5.129:7077
spark.executor.memory 2g
spark.executor.cores 4
spark.worker.resource.gpu.amount 1
spark.worker.resource.gpu.discoveryScript /opt/sparkRapidsPlugin/getGpusResources.sh
spark.executorEnv.NCCL_DEBUG INFOspark-env.sh:
#!/usr/bin/env bash
# Options for the daemons used in the standalone deploy mode
SPARK_MASTER_HOST="192.168.5.129"
SPARK_MASTER_PORT="7077"
SPARK_WORKER_OPTS="-Dspark.worker.resource.gpu.amount=1 -Dspark.worker.resource.gpu.discoveryScript=/opt/sparkRapidsPlugin/getGpusResources.sh -Dspark.rapids.memory.pinnedPool.size=2G -Dspark.executor.resource.gpu.amount=1 -Dspark.executorEnv.NCCL_DEBUG=INFO""
Docker
Следуя документации Spark, следующим шагом должен быть запуск скрипта для создания Docker-образов:
$ ./bin/docker-image-tool.sh -r <repo> -t my-tag buildПодготовленный Dockerfile необходимо изменить до вида:
ARG java_image_tag=11-jre-slim
# проставляется в команде docker-build
FROM ${java_image_tag}
ARG spark_uid=1001
ARG UID_GID=1001
ENV UID=${UID_GID}
ENV GID=${UID_GID}
ENV SPARK_RAPIDS_DIR=/opt/sparkRapidsPlugin
ENV SPARK_RAPIDS_PLUGIN_JAR=${SPARK_RAPIDS_DIR}/rapids-4-spark_2.12-22.06.0.jar
# old
#ENV SPARK_CUDF_JAR=${SPARK_RAPIDS_DIR}/cudf-22.04.0-cuda11.jar
#ENV SPARK_RAPIDS_PLUGIN_JAR=${SPARK_RAPIDS_DIR}/rapids-4-spark_2.12-22.04.0.jar
RUN set -ex && \
sed -i 's/http:\/\/deb.\(.*\)/https:\/\/deb.\1/g' /etc/apt/sources.list && \
apt-get update && \
ln -s /lib /lib64 && \
apt install -y bash tini libc6 libpam-modules libnss3 procps nano iputils-ping net-tools iptables sudo \
wget software-properties-common build-essential libnss3-dev zlib1g-dev libgdbm-dev libncurses5-dev \
libssl-dev libffi-dev libreadline-dev libsqlite3-dev libbz2-dev python3 && \
mkdir -p /opt/spark && \
mkdir -p /opt/spark/examples && \
mkdir -p /opt/spark/conf && \
mkdir -p /opt/spark/work-dir && \
mkdir -p /opt/sparkRapidsPlugin && \
touch /opt/spark/RELEASE && \
rm /bin/sh && \
ln -sv /bin/bash /bin/sh && \
echo "auth required pam_wheel.so use_uid" >> /etc/pam.d/su && \
chgrp root /etc/passwd && chmod ug+rw /etc/passwd
RUN apt-get install libnccl2 libnccl-dev -y --allow-change-held-packages && rm -rf /var/cache/apt/*
COPY jars /opt/spark/jars
COPY rapidsNew /opt/sparkRapidsPlugin
# old
#COPY rapids /opt/sparkRapidsPlugin
COPY bin /opt/spark/bin
COPY sbin /opt/spark/sbin
COPY conf /opt/spark/conf
COPY kubernetes/dockerfiles/spark/entrypoint.sh /opt/
COPY kubernetes/dockerfiles/spark/decom.sh /opt/
COPY kubernetes/tests /opt/spark/tests
COPY data /opt/spark/data
COPY datasets /opt/spark/
ENV SPARK_HOME /opt/spark
WORKDIR /opt/spark/work-dir
RUN chmod g+w /opt/spark/work-dir
RUN chmod a+x /opt/decom.sh
# USER
RUN groupadd --gid $UID appuser && useradd --uid $UID --gid appuser --shell /bin/bash --create-home appuser
RUN mkdir /var/logs && chown -R appuser:appuser /var/logs
RUN mkdir /opt/spark/logs && chown -R appuser:appuser /opt/spark/
RUN chown -R appuser:appuser /tmp
RUN ls -lah /home/appuser
RUN touch /home/appuser/.bashrc
RUN echo -e '\
export SPARK_HOME=/opt/spark\n\
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin\
' > /home/appuser/.bashrc
RUN chown -R appuser:appuser /home/appuser
# Specify the User that the actual main process will run as
USER ${spark_uid}
EXPOSE 4040
EXPOSE 8081
ENTRYPOINT [ "/opt/entrypoint.sh" ]
entrypoint.sh:
#!/bin/bash
SPARK_DRIVER_BIND_ADDRESS=192.168.5.129:7077 # spark master address
NCCL_DEBUG=INFO
source ~/.bashrc
start-worker.sh spark://$SPARK_DRIVER_BIND_ADDRESS
tail -f /dev/nullSPARK_DRIVER_BIND_ADDRESS - адрес Spark Master, в моем случае - это адрес локальной виртуальной машины. Для дебага возможных неисправностей в ходе работы с библиотекой nccl следует выставить уровень дебага INFO. Командой start-worker.sh spark://$SPARK_DRIVER_BIND_ADDRESS запускается воркер, подключаясь к мастеру.
Исходники kubernetes/dockerfiles/Dockerfile и содержимое той же директории можно найти в репозитории примера.
Сборка образа и запуск контейнера:
cd spark
docker build -f kubernetes/dockerfiles/spark/Dockerfile --build-arg java_image_tag=localhost:5000/cuda-jdk8:v1 -t localhost:5000/cuda-jdk8-spark:v1 .
docker run --memory="6g" --cpus="4" --gpus all --name=cuda-jdk8-spark -p 8081:8081 -it -d localhost:5000/cuda-jdk8-spark:v1Следует убедиться, что в образ установилась библиотека nccl корректной версии, для чего нужно экзекнуться в созданный контейнер Spark Worker и выполнить:
$ dpkg -l | grep nccl
ii libnccl-dev 2.12.12-1+cuda11.7 amd64 NVIDIA Collective Communication Library (NCCL) Development Files
ii libnccl2 2.12.12-1+cuda11.7 amd64 NVIDIA Collective Communication Library (NCCL) Runtimeна момент написания статьи и тестирования корректной версией является 2.12.12-1+cuda11.7. В версиях ниже может встречаться проблема с запуском задач XGBoost, т.к. nccl не может найти сетевое устройство по причине того, что в докер-контейнере оно является виртуальным.
Проверяем доступность воркера, путем открытия его WEB GUI по адресу localhost:8081 (в соответствии с командой docker run выше):

Видим, что помимо Cores и Memory, доступен ресурс Resources: gpu. На моей локальной машине одно устройство, и его id обозначен в массиве как “0”.
Проверяем WEB GUI мастера (адрес моей локальной виртуальной машины http://192.168.5.129:8080/):

Spark Worker, запущенный в контейнере, появился в списке Workers. Можно переходить к приложению.
Разработка и запуск приложения
В текущем разделе рассматривается пример работы простого веб-сервиса, являющимся так же Spark Driver. Приложение будет иметь 3 HTTP Endpoint’a, на каждом будет доступен пример одной из библиотек: DJL, Spark ML, XGBoost.
Каркас приложения
В виде каркаса приложения используется Spring Boot с зависимость spring-boot-starter-web, используемый JDK - OpenJDK 8 (держим в уме требование Rapids). Я создаю новый проект в тот момент, когда пишу эту статью, поэтому финальный результат также должен заработать у читателя при условии выполнения предварительных шагов, описанных выше.

Структура проекта:
Файл pom.xml можно посмотреть в репозитории, я остановлюсь на важном моменте. Для работы XGBoost на Windows с WSL2 в Docker контейнере проведено детальное обследование проблемы в GitHub Issue.
На данный момент версия библиотеки XGBoost, используемая в данном примере, не имеет релизной версии, поэтому в Maven central она отсутствует. Для загрузки библиотеки нужно добавить в pom.xml репозиторий с версиями SNAPSHOT:
<distributionManagement>
<repository>
<id>XGBoost4J Snapshot Repo</id>
<name>XGBoost4J Snapshot Repo</name>
<url>https://s3-us-west-2.amazonaws.com/xgboost-maven-repo/snapshot/</url>
</repository>
</distributionManagement>Однако, есть нюанс. Доступа с Российских и Казахстанских IP (с других не проверялось) к данному репо с недавнего времени нет. Варианты: либо VPN, либо воспользоваться репозиторием проекта и загрузить джарники xgboost4j-gpu_2.12-2.0.0-SNAPSHOT.jar и xgboost4j-spark-gpu_2.12-2.0.0-SNAPSHOT.jar в локальный m2 репозиторий:



Также эти джарники необходимо загрузить в директорию jars проекта (см. скрин выше). Данные *.jar файлы будут переданы в Spark Executor как зависимости для запуска кода драйвера. Список таких файлов описывается в SparkConfiguration:
package com.mlwebservice.config;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.sql.SparkSession;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.net.InetAddress;
import java.net.UnknownHostException;
@Configuration
public class SparkConfiguration {
@Value("${spring.application.name}")
private String appName;
@Value("${spark.masterHost}")
private String masterHost;
@Bean
public JavaSparkContext javaSparkContext() throws UnknownHostException {
String host = InetAddress.getLocalHost().getHostAddress();
SparkConf sparkConf = new SparkConf(true)
.setAppName(appName)
.setMaster("spark://" + masterHost)
.setJars(new String[]{
"service.jar",
"jars/config-1.4.1.jar",
"jars/rapids-4-spark_2.12-22.06.0.jar",
"jars/spark-nlp_2.12-3.4.1.jar",
"jars/xgboost4j-gpu_2.12-2.0.0-SNAPSHOT.jar",
"jars/xgboost4j-spark-gpu_2.12-2.0.0-SNAPSHOT.jar"})
// Spark settings
.set("spark.worker.cleanup.enabled", "true")
// executors
.set("spark.executor.cores", "4")
.set("spark.executor.memory", "2g")
.set("spark.executor.resource.gpu.amount", "1")
.set("spark.executorEnv.NCCL_DEBUG", "INFO")
.set("spark.task.resource.gpu.amount", "1")
// driver
.set("spark.ui.enabled", "true")
.set("spark.ui.port", "4040")
.set("spark.driver.host", host)
.set("spark.driver.bindAddress", host)
.set("spark.driver.blockManager.port", "45029")
.set("spark.driver.port", "33139")
.set("spark.port.maxRetries", "16")
.set("spark.driver.maxResultSize", "2g")
.set("spark.executor.heartbeatInterval", "200000")
.set("spark.network.timeout", "300000")
// rapids
.set("spark.rapids.memory.gpu.pooling.enabled", "false")
.set("spark.rapids.memory.gpu.minAllocFraction", "0.0001")
.set("spark.rapids.memory.gpu.reserve", "2")
.set("spark.rapids.sql.enabled", "true")
.set("spark.sql.adaptive.enabled", "false")
.set("spark.rapids.sql.explain", "ALL")
.set("spark.rapids.sql.hasNans", "false")
.set("spark.rapids.sql.csv.read.float.enabled", "true")
.set("spark.rapids.sql.castFloatToString.enabled", "true")
.set("spark.rapids.sql.csv.read.double.enabled", "true")
.set("spark.rapids.sql.castDoubleToString.enabled", "true")
.set("spark.rapids.sql.exec.CollectLimitExec", "true")
.set("spark.locality.wait", "0s")
.set("spark.sql.files.maxPartitionBytes", "512m")
.set("spark.plugins", "com.nvidia.spark.SQLPlugin")
.set("spark.driver.extraClassPath", "/opt/sparkRapidsPlugin/rapids-4-spark_2.12-22.06.0.jar");
return new JavaSparkContext(sparkConf);
}
@Bean
public SparkSession sparkSession(JavaSparkContext context) {
return SparkSession.builder()
.master("spark://" + masterHost)
.appName(appName)
.config(context.getConf())
.config("spark.executorEnv.NCCL_DEBUG", "INFO")
.getOrCreate();
}
}
Параметров конфигурации Spark очень много, подробнее с ними можно ознакомиться на странице Configuration - Spark 3.3.0 Documentation .
Контроллер максимально простой, он содержит три сервиса, каждый сервис реализует по 1-2 метода каждой библиотеки. Обращаю внимание, что данный контроллер является инструментом запуска соответствующего примера, сделанный в угоду скорости и самому факту, что несколько технологий можно объединить в приложении Spring, и никак не претендует на использование приложения в продуктивной среде. Для реального приложения здесь должны быть как минимум другие HTTP глаголы, обработчики сообщений, информативные DTO, асинхронные операции, брокеры сообщений для потоков данных, реактивщины, вебсокеты и вот это вот все.
package com.mlwebservice.controller;
import ai.djl.translate.TranslateException;
import com.mlwebservice.service.DJLService;
import com.mlwebservice.service.RapidsService;
import com.mlwebservice.service.SparkMLService;
import lombok.RequiredArgsConstructor;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.io.IOException;
@RestController
@RequestMapping("/")
@RequiredArgsConstructor
public class MLController {
private final DJLService djlService;
private final SparkMLService sparkMLService;
private final RapidsService rapidsService;
@GetMapping("/djl")
public ResponseEntity<?> djl() {
try {
djlService.mlWork();
} catch (TranslateException | IOException e) {
return ResponseEntity.status(500).body(e.getMessage());
}
return ResponseEntity.ok().build();
}
@GetMapping("/forest")
public ResponseEntity<?> sparkML() {
sparkMLService.randomForestTest();
return ResponseEntity.ok().build();
}
@GetMapping("/gpu_test")
public ResponseEntity<?> rapidsGpuTest() {
rapidsService.testRapids();
return ResponseEntity.ok().build();
}
@GetMapping("/xgboost")
public ResponseEntity<?> rapidsXGBoost() {
rapidsService.xgBoost();
return ResponseEntity.ok().build();
}
}
Deep Java Library - DJL
Первая библиотека на очереди - DJL. Это удобная библиотека машинного обучения для языка Java, особенностью которой является зоопарк моделей (Model Zoo), позволяющий получить готовую модель по описываемым параметрам из списка доступных моделей. Также имеется возможность создать свою модель, сохранить на диск и загрузить для дальнейшего использования.
В данном примере рассматривается реализация модели линейной регрессии. К сожалению, в виду архитектурной особенности данной модели, распараллелить процесс ее обучения довольно сложно, и, вероятно, решается в определенных случаях определенными движками, такими как PyTorch. По крайней мере, распараллеливание обучения с помощью Spark модели линейной регрессии мне не попалось, и быстро сам придумать реализацию также не смог. Однако, есть распространенный пример применения Spark в паре с DJL для классификации изображений с использованием модели из Model Zoo, например данная статья.
Реализация модели линейной регрессии сделана на основе статей 3.2. Linear Regression Implementation from Scratch — Dive into Deep Learning 0.1.0 documentation и 3.3. Concise Implementation of Linear Regression — Dive into Deep Learning 0.1.0 documentation и отображена в сервисе DJLService.
В целях отладки в main методе приложения логируется вызов нескольких методов, с помощью которых легко опознать некорректность конфигурации приложения. При корректной конфигурации должен вывестись лог вида:
2022-07-18 19:38:45.346 INFO 1 --- [ main] c.mlwebservice.MLWebServiceApplication : Initializing DJL lib...
2022-07-18 19:38:45.349 INFO 1 --- [ main] c.mlwebservice.MLWebServiceApplication : CPU: cpu()
2022-07-18 19:38:45.349 INFO 1 --- [ main] c.mlwebservice.MLWebServiceApplication : GPU: gpu(0)
2022-07-18 19:38:45.439 INFO 1 --- [ main] c.mlwebservice.MLWebServiceApplication : CUDA available: true
2022-07-18 19:38:45.440 INFO 1 --- [ main] c.mlwebservice.MLWebServiceApplication : CUDA GPU count: 1
OpenJDK 64-Bit Server VM warning: You have loaded library /root/.djl.ai/pytorch/1.11.0-20220510-cu113-linux-x86_64/libtorch_cpu.so which might have disabled stack guard. The VM will try to fix the stack guard now.
It's highly recommended that you fix the library with 'execstack -c <libfile>', or link it with '-z noexecstack'.
2022-07-18 19:38:45.739 INFO 1 --- [ main] ai.djl.pytorch.engine.PtEngine : Number of inter-op threads is 8
2022-07-18 19:38:45.740 INFO 1 --- [ main] ai.djl.pytorch.engine.PtEngine : Number of intra-op threads is 8
2022-07-18 19:38:45.740 INFO 1 --- [ main] c.mlwebservice.MLWebServiceApplication : GPU count: 1
2022-07-18 19:38:45.741 INFO 1 --- [ main] c.mlwebservice.MLWebServiceApplication : Engine: PyTorch:1.11.0, capabilities: [
CUDA,
CUDNN,
OPENMP,
MKL,
MKLDNN,
]
PyTorch Library: /root/.djl.ai/pytorch/1.11.0-20220510-cu113-linux-x86_64Код примера:
package com.mlwebservice.service;
import ai.djl.Model;
import ai.djl.metric.Metrics;
import ai.djl.ndarray.NDArray;
import ai.djl.ndarray.NDManager;
import ai.djl.ndarray.types.Shape;
import ai.djl.nn.Block;
import ai.djl.nn.ParameterList;
import ai.djl.nn.SequentialBlock;
import ai.djl.nn.core.Linear;
import ai.djl.training.DefaultTrainingConfig;
import ai.djl.training.EasyTrain;
import ai.djl.training.Trainer;
import ai.djl.training.dataset.ArrayDataset;
import ai.djl.training.dataset.Batch;
import ai.djl.training.listener.TrainingListener;
import ai.djl.training.loss.Loss;
import ai.djl.training.optimizer.Optimizer;
import ai.djl.training.tracker.Tracker;
import ai.djl.translate.TranslateException;
import com.mlwebservice.model.DataPoints;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Service;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.util.Arrays;
@Slf4j
@Service
public class DJLService {
public void mlWork() throws TranslateException, IOException {
// Generating the Dataset
NDManager manager = NDManager.newBaseManager();
NDArray trueW = manager.create(new float[]{2, -3.4f});
float trueB = 4.2f;
DataPoints dp = DataPoints.syntheticData(manager, trueW, trueB, 1000);
NDArray features = dp.getX();
NDArray labels = dp.getY();
// Reading dataset
int batchSize = 10;
ArrayDataset dataset = loadArray(features, labels, batchSize, false);
// mini test
Batch testBatch = dataset.getData(manager).iterator().next();
NDArray X = testBatch.getData().head();
NDArray y = testBatch.getLabels().head();
log.info("X = {}", X);
log.info("y = {}", y);
testBatch.close();
// Defining the model
Model model = Model.newInstance("lin-reg");
SequentialBlock net = new SequentialBlock();
Linear linearBlock = Linear.builder().optBias(true).setUnits(1).build();
net.add(linearBlock);
model.setBlock(net);
// Defining the Loss function
Loss l2loss = Loss.l2Loss();
// Defining the Optimization Algorithm
Tracker lrt = Tracker.fixed(0.03f);
Optimizer sgd = Optimizer.sgd().setLearningRateTracker(lrt).build();
// Instantiate Configuration and Trainer
DefaultTrainingConfig config = new DefaultTrainingConfig(l2loss)
.optOptimizer(sgd) // Optimizer (loss function)
.optDevices(manager.getEngine().getDevices(1)) // single GPU
// .addTrainingListeners(TrainingListener.Defaults.logging()); // Logging
.addTrainingListeners(TrainingListener.Defaults.basic()); // Without logging for increase speed
Trainer trainer = model.newTrainer(config);
log.info("Trainer devices: {}", Arrays.toString(trainer.getDevices()));
// Initializing Model Parameters
// First axis is batch size - won't impact parameter initialization
// Second axis is the input size
trainer.initialize(new Shape(batchSize, 2));
// Metrics
Metrics metrics = new Metrics();
trainer.setMetrics(metrics);
// Training
int numEpochs = 30;
long startTime = System.currentTimeMillis();
for (int epoch = 1; epoch <= numEpochs; epoch++) {
// Iterate over dataset
for (Batch batch : trainer.iterateDataset(dataset)) {
// Update loss and evaulator
EasyTrain.trainBatch(trainer, batch);
// Update parameters
trainer.step();
batch.close();
}
// reset training and validation evaluators at end of epoch
trainer.notifyListeners(listener -> listener.onEpoch(trainer));
}
Block layer = model.getBlock();
ParameterList params = layer.getParameters();
NDArray wParam = params.valueAt(0).getArray();
NDArray bParam = params.valueAt(1).getArray();
long endTime = System.currentTimeMillis();
float[] w = trueW.sub(wParam.reshape(trueW.getShape())).toFloatArray();
log.info("Error in estimating w: [{} {}]", w[0], w[1]);
log.info("Error in estimating b: {}", trueB - bParam.getFloat());
log.info("Training time: " + (endTime - startTime) + " ms");
// Save the model
Path modelDir = Paths.get("models/lin-reg");
Path savedDir = Files.createDirectories(modelDir);
model.setProperty("Epoch", Integer.toString(numEpochs)); // save epochs trained as metadata
model.save(modelDir, "lin-reg");
log.info("Model saved in " + savedDir.toAbsolutePath());
}
// Save in the file for later use
public ArrayDataset loadArray(NDArray features, NDArray labels, int batchSize, boolean shuffle) {
return new ArrayDataset.Builder()
.setData(features) // set the features
.optLabels(labels) // set the labels
.setSampling(batchSize, shuffle) // set the batch size and random sampling
.build();
}
}
Модель DataPoints:
package com.mlwebservice.model;
import ai.djl.ndarray.NDArray;
import ai.djl.ndarray.NDManager;
import ai.djl.ndarray.types.DataType;
import ai.djl.ndarray.types.Shape;
public class DataPoints {
private final NDArray x;
private final NDArray y;
public DataPoints(NDArray x, NDArray y) {
this.x = x;
this.y = y;
}
public NDArray getX() {
return x;
}
public NDArray getY() {
return y;
}
// Generate y = X w + b + noise
public static DataPoints syntheticData(NDManager manager, NDArray w, float b, int numExamples) {
NDArray x = manager.randomNormal(new Shape(numExamples, w.size()));
NDArray y = x.matMul(w).add(b);
// Add noise
y = y.add(manager.randomNormal(0, 0.01f, y.getShape(), DataType.FLOAT32));
return new DataPoints(x, y);
}
}
Результат выполнения:
2022-07-18 20:29:27.461 INFO 1 --- [nio-9090-exec-1] com.mlwebservice.service.DJLService : X = ND: (10, 2) gpu(0) float32
[[ 0.7017, -0.7652],
[ 2.495 , -0.3341],
[-2.175 , -0.452 ],
[ 1.1075, 0.8347],
[-1.8369, -0.7469],
[ 0.5647, 2.1323],
[-0.2754, 0.3807],
[ 0.2902, 1.5136],
[-0.5902, 0.6777],
[ 0.4059, -1.0304],
]
2022-07-18 20:29:27.473 INFO 1 --- [nio-9090-exec-1] com.mlwebservice.service.DJLService : y = ND: (10) gpu(0) float32
[ 8.1976, 10.324 , 1.3922, 3.5564, 3.0556, -1.9248, 2.3501, -0.361 , 0.7023, 8.4904]
2022-07-18 20:29:27.491 INFO 1 --- [nio-9090-exec-1] com.mlwebservice.service.DJLService : Trainer devices: [gpu(0)]
2022-07-18 20:29:34.665 INFO 1 --- [nio-9090-exec-1] com.mlwebservice.service.DJLService : Error in estimating w: [-4.7445297E-5 -1.2493134E-4]
2022-07-18 20:29:34.670 INFO 1 --- [nio-9090-exec-1] com.mlwebservice.service.DJLService : Error in estimating b: 1.9073486E-4
2022-07-18 20:29:34.670 INFO 1 --- [nio-9090-exec-1] com.mlwebservice.service.DJLService : Training time: 7112 ms
2022-07-18 20:29:34.676 INFO 1 --- [nio-9090-exec-1] com.mlwebservice.service.DJLService : Model saved in /usr/src/app/models/lin-regSpark ML
Существует замечательная документация для начинающих от nVidia по работе со Spark ML на примере модели Random Forest. Учитывая специфику данной модели, процесс обучения можно распараллелить на несколько исполнителей, а затем пользоваться либо средним значением в случае решения задач регрессии, либо голосованием по большинству в случае решения задач классификации. Подробнее можно почитать на хабре, в документации Spark, примеры кода Spark ML также можно посмотреть в документации.
В данном примере понадобятся датасеты для тренировки и валидации, можно взять отсюда, либо воспользоваться кодом репозитория. Отмечу, в данном разделе не полностью переписан пример из статьи nVidia по Spark ML, а скорее является реализацией задачи из статьи nVidia по XGBoost, но с применением Random Forest из Spark ML. Датасеты копируются в сценарии Dockerfile, а в сервисе пути к ним хардкодятся (пример же, можно себе позволить).
Обращаю внимание: в статье по Spark ML говорится, что только XGBoost поддерживает GPU-ускорение в Spark ML. Вполне может быть, что документация устарела (как писали в одном из Issue на GitHub) и в данный момент, так как в документации Rapids указывается репозиторий с еще как минимум одним примером для алгоритма Principal component analysis (PCA).
Код сервиса:
package com.mlwebservice.service;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.apache.spark.ml.Pipeline;
import org.apache.spark.ml.PipelineStage;
import org.apache.spark.ml.evaluation.RegressionEvaluator;
import org.apache.spark.ml.feature.StandardScaler;
import org.apache.spark.ml.feature.VectorAssembler;
import org.apache.spark.ml.param.ParamMap;
import org.apache.spark.ml.regression.RandomForestRegressor;
import org.apache.spark.ml.tuning.CrossValidator;
import org.apache.spark.ml.tuning.CrossValidatorModel;
import org.apache.spark.ml.tuning.ParamGridBuilder;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import org.springframework.stereotype.Service;
import static org.apache.spark.sql.functions.col;
@Slf4j
@Service
@RequiredArgsConstructor
public class SparkMLService {
private final SparkSession session;
public void randomForestTest() {
String trainPath = "/opt/spark/train/train.parquet";
//test
String evalPath = "/opt/spark/eval/eval.parquet";
Dataset<Row> tdf = session.read().parquet(trainPath);
Dataset<Row> edf = session.read().parquet(evalPath);
String labelName = "fare_amount";
String[] featureColumns = {"passenger_count", "trip_distance", "pickup_longitude", "pickup_latitude", "rate_code",
"dropoff_longitude", "dropoff_latitude", "hour", "day_of_week", "is_weekend", "h_distance"};
VectorAssembler assembler = new VectorAssembler()
.setInputCols(featureColumns)
.setOutputCol("rawfeatures");
StandardScaler standardScaler = new StandardScaler()
.setInputCol("rawfeatures")
.setOutputCol("features")
.setWithStd(true);
RandomForestRegressor regressor = new RandomForestRegressor()
.setLabelCol(labelName)
.setFeaturesCol("features");
Pipeline pipeline = new Pipeline().setStages(new PipelineStage[]{assembler, standardScaler, regressor});
ParamMap[] paramGrid = new ParamGridBuilder()
.addGrid(regressor.maxBins(), new int[]{100, 200})
.addGrid(regressor.maxDepth(), new int[]{2, 7, 10})
.addGrid(regressor.numTrees(), new int[]{5, 20})
.build();
RegressionEvaluator evaluator = new RegressionEvaluator()
.setLabelCol(labelName)
.setPredictionCol("prediction")
.setMetricName("rmse");
CrossValidator crossvalidator = new CrossValidator()
.setEstimator(pipeline)
.setEvaluator(evaluator)
.setEstimatorParamMaps(paramGrid)
.setNumFolds(3);
CrossValidatorModel pipelineModel = crossvalidator.fit(tdf);
ParamMap[] bestEstimatorParamMap = pipelineModel.getEstimatorParamMaps();
log.info("best params map {}", bestEstimatorParamMap);
Dataset<Row> predictions = pipelineModel.transform(edf);
Dataset<Row> result = predictions.withColumn("error", col("prediction").minus(col(labelName)));
result.select(labelName, "prediction", "error").show();
result.describe(labelName, "prediction", "error").show();
RegressionEvaluator maevaluator = new RegressionEvaluator()
.setLabelCol(labelName)
.setMetricName("mae");
log.info("mae evaluation: {}", maevaluator.evaluate(predictions));
RegressionEvaluator rmsevaluator = new RegressionEvaluator()
.setLabelCol(labelName)
.setMetricName("rmse");
log.info("rmse evaluation: {}", rmsevaluator.evaluate(predictions));
}
}
Rapids и XGBoost
Последним примером является реализация примера из статьи nVidia по XGBoost, который использует и Spark, и Rapids вместе. Данный пример является самым интересным, так как обеспечивает действительно лучшую скорость вычислений по сравнению со Spark ML Random Forest.
Кроме того, в документации Rapids первым примером рассматривается операция Join двух датафреймов из 10 млн чисел. Данный пример также реализован в тестовом методе сервиса RapidsService:
@Slf4j
@Service
@RequiredArgsConstructor
public class RapidsService {
private final SparkSession session;
public void testRapids() {
int capacity = 1000000;
List<LongValue> list = new ArrayList<>(capacity);
for (long i = 1; i < (capacity + 1); i++) {
list.add(new LongValue(i));
}
Dataset<Row> df = session.createDataFrame(list, LongValue.class);
Dataset<Row> df2 = session.createDataFrame(list, LongValue.class);
long result = df.select(col("value").as("a"))
.join(df2.select(col("value").as("b")), col("a").equalTo(col("b"))).count();
log.info("count result {}", result);
}
}
@Data
@AllArgsConstructor
public class LongValue implements Serializable {
private static final long serialVersionUID = 1L;
private Long value;
}
Пример несколько отличается от своего исходника на Scala, но также обеспечивает вычисления на GPU. DAG представлен на скрине ниже:

Что касается XGBoost, то пример взят из статьи nVidia, датасеты те же, что и для Random Forest Spark ML, про сам XGBoost можно почитать здесь и здесь.
Реализация XGBoost regressor:
package com.mlwebservice.service;
import com.mlwebservice.model.LongValue;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import ml.dmlc.xgboost4j.scala.spark.XGBoostRegressionModel;
import ml.dmlc.xgboost4j.scala.spark.XGBoostRegressor;
import org.apache.spark.ml.PredictionModel;
import org.apache.spark.ml.linalg.Vector;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import org.springframework.stereotype.Service;
import scala.collection.immutable.HashMap;
import scala.collection.immutable.Map;
import java.util.ArrayList;
import java.util.List;
import static org.apache.spark.sql.functions.col;
@Slf4j
@Service
@RequiredArgsConstructor
public class RapidsService {
private final SparkSession session;
public void xgBoost() {
String trainPath = "/opt/spark/train/train.parquet";
//test
String evalPath = "/opt/spark/eval/eval.parquet";
Dataset<Row> tdf = session.read().parquet(trainPath);
Dataset<Row> edf = session.read().parquet(evalPath);
String labelName = "fare_amount";
String[] featureColumns = {"passenger_count", "trip_distance", "pickup_longitude", "pickup_latitude", "rate_code",
"dropoff_longitude", "dropoff_latitude", "hour", "day_of_week", "is_weekend", "h_distance"};
Map<String, Object> map = new HashMap<>();
map = map.updated("learning_rate", 0.05);
map = map.updated("max_depth", 8);
map = map.updated("subsample", 0.8);
map = map.updated("gamma", 1);
map = map.updated("num_round", 500);
map = map.updated("tree_method", "gpu_hist");
map = map.updated("num_workers", 1);
XGBoostRegressor regressor = new XGBoostRegressor(map);
regressor.setLabelCol(labelName);
regressor.setFeaturesCol(featureColumns);
PredictionModel<Vector, XGBoostRegressionModel> model = regressor.fit(tdf);
Dataset<Row> predictions = model.transform(edf);
Dataset<Row> result = predictions.withColumn("error", col("prediction").minus(col(labelName)));
result.select(labelName, "prediction", "error").show();
result.describe(labelName, "prediction", "error").show();
}
}
Запуск
Пора запустить приложение. Для этого необходимо собрать Docker-образ, воспользовавшись Dockerfile:
#FROM adoptopenjdk/openjdk8:ubuntu-jre-nightly
FROM localhost:5000/cuda-jdk8:v1
WORKDIR /usr/src/app
ARG JAR_FILE
ARG UID_GID=1001
ENV UID=${UID_GID}
ENV GID=${UID_GID}
RUN mkdir -p jars
COPY jars jars
ENV PYTHONUNBUFFERED=1
RUN apt-get update && apt install -y python-is-python3 wget curl ca-certificates bash libgomp1 && \
rm -rf /var/cache/apt/*
RUN mkdir -p /opt/spark/
COPY spark /opt/spark
COPY ${JAR_FILE} service.jar
RUN groupadd --gid $UID appuser && useradd --uid $UID --gid appuser --shell /bin/bash --create-home appuser
RUN chown -R appuser:appuser /home/appuser && chown -R appuser:appuser /usr/src/app
EXPOSE 4040
EXPOSE 9090
USER $UID
CMD ["java", "-jar", "service.jar"]
Обращаю внимание на первую и вторую строки. Если нужно запускать приложение с логикой библиотеки DJL, нужно воспользоваться базовым образом, созданным ранее для Spark. Он содержит необходимое системное ПО для работы с видеокартами nVidia. Учитывая, что при запуске скачивается указанный в зависимостях движок (PyTorch, MXNet, etc), нужно соединение с интернетом и немного больше времени на запуск сервиса. Есть вариант один раз подключить volume к контейнеру и добавить несколько директив COPY в Dockerfile после первого запуска, чтобы не загружать необходимые файлы из интернета, а сразу скопировать в образ.
В случае, если DJL не используется в сервисе, смысла в использовании “тяжелого” базового образа, и можно воспользоваться более “легким” образом, который содержит JRE8, например, тот, что закомментирован в первой строке.
Команды запуска вынесены в скрипт build.sh:
#!/bin/bash
mvn clean install -DskipTests=true
docker rmi localhost:5000/ml:1
docker build -f Dockerfile --build-arg JAR_FILE=target/service.jar -t localhost:5000/ml:1 .
docker run --gpus all -p 9090:9090 -p 4040:4040 -p 33139-33155:33139-33155 -p 45029-45045:45029-45045 --name=ML -it -d localhost:5000/ml:1
Через некоторое время контейнер должен запуститься, движки и все необходимое для DJL инициализироваться, а в Web UI Spark Master должен появиться сервис в списке запущенных приложений:

В Web UI Spark Worker должен появиться Executor для указанного приложения:

Web UI сервиса также должен стать доступным:

Согласно контроллеру, имеется 4 доступных GET-метода, которые запускают необходимый пример:
http://localhost:9090/gpu_test
Лог результата выполнения DJL представлен в соответствующем разделе выше, он не очень интересен, нежели Spark Jobs.
При первом запуске логики, которая должна выполняться на Spark, метод выполняется несколько дольше, чем при последующих запусках - есть необходимость некоторого “прогрева” executor'а. Для этого можно запустить метод gpu_test.

В деталях джобы видим, что она выполнялась чуть более 8и секунд, что, действительно, довольно долго. Последующие вызовы данного метода выполнялись в два раза быстрее (кроме второго - именно в данный момент подвел vmmem, выделив под WSL 25Гб ОЗУ):

Результат выполнения:
2022-07-19 14:05:13.856 INFO 1 --- [nio-9090-exec-4] o.a.spark.ml.tree.impl.RandomForest : init: 1.62514E-4
total: 3.192210057
findBestSplits: 3.17661902
chooseSplits: 3.166410779
2022-07-19 14:05:13.864 INFO 1 --- [nio-9090-exec-4] com.mlwebservice.service.SparkMLService : best params map {
rfr_dc03cc8c5712-maxBins: 100,
rfr_dc03cc8c5712-maxDepth: 2,
rfr_dc03cc8c5712-numTrees: 5
}
+------------------+------------------+--------------------+
| fare_amount| prediction| error|
+------------------+------------------+--------------------+
| 11.4|12.422369509009028| 1.0223695090090281|
| 7.4| 7.289954038707909|-0.11004596129209165|
| 5.0| 4.601351052403492| -0.3986489475965076|
| 8.5| 8.773609129887804| 0.27360912988780406|
| 7.4| 7.351427584678662|-0.04857241532133827|
| 3.8| 4.509977888929194| 0.7099778889291946|
| 5.4|6.1300686499042305| 0.7300686499042301|
| 7.4| 5.310782694363023| -2.0892173056369776|
| 5.3| 6.281121521712063| 0.9811215217120628|
| 4.1| 4.320442646467865| 0.22044264646786527|
| 4.2| 4.358399833924078| 0.15839983392407753|
| 23.0| 21.84539235607258| -1.1546076439274202|
| 6.2| 4.800643228448342| -1.3993567715516582|
| 12.6|13.513431604134931| 0.9134316041349315|
| 7.8| 7.289324492912175| -0.510675507087825|
| 11.0| 12.14859211003076| 1.1485921100307603|
| 24.2| 19.82343367802233| -4.37656632197767|
| 10.6| 9.87204611828728| -0.72795388171272|
| 18.6|19.290663393934967| 0.6906633939349653|
|11.800000000000002|12.322340133504676| 0.5223401335046738|
+------------------+------------------+--------------------+
only showing top 20 rows
+-------+-----------------+------------------+--------------------+
|summary| fare_amount| prediction| error|
+-------+-----------------+------------------+--------------------+
| count| 3000| 3000| 3000|
| mean|9.536166666666665| 9.535967764479922|-1.98902186749770...|
| stddev|6.952558857268078|6.4554477337337675| 1.9208959387344227|
| min| 2.5|3.9593080769885773| -69.80275612138105|
| max| 110.0|53.803333333333356| 12.055956289978678|
+-------+-----------------+------------------+--------------------+
mae evaluation: 0.8626064049871519
rmse evaluation: 1.9205757730272761Random forest сделал очень много Spark Jobs, которые выполнялись с 14:04:02 до 14:05:15 (73 секунды).

XGBoost на том же датасете выполнялся в рамках 433-436 Spark Jobs, которые заняли ~16 секунд.

Результаты:
+------------------+------------------+--------------------+
| fare_amount| prediction| error|
+------------------+------------------+--------------------+
| 11.4|11.298457145690918|-0.10154285430908239|
| 7.4| 7.516303539276123| 0.11630353927612269|
| 5.0| 5.16908597946167| 0.16908597946166992|
| 8.5| 9.045893669128418| 0.545893669128418|
| 7.4| 7.355461597442627| -0.0445384025573734|
| 3.8| 4.012299060821533| 0.21229906082153338|
| 5.4| 5.95053768157959| 0.5505376815795895|
| 7.4| 5.841796875| -1.5582031250000004|
| 5.3| 6.106812000274658| 0.8068120002746584|
| 4.1| 4.191019058227539| 0.09101905822753942|
| 4.2|3.9211881160736084| -0.2788118839263918|
| 23.0| 22.72040557861328|-0.27959442138671875|
| 6.2| 4.528580665588379| -1.6714193344116213|
| 12.6| 13.0178804397583| 0.41788043975830114|
| 7.8| 7.767493724822998|-0.03250627517700...|
| 11.0|11.349909782409668| 0.34990978240966797|
| 24.2| 23.78424072265625| -0.4157592773437493|
| 10.6|10.418869972229004|-0.18113002777099574|
| 18.6| 19.02918243408203| 0.42918243408202983|
|11.800000000000002|11.934724807739258| 0.13472480773925533|
+------------------+------------------+--------------------+
+-------+-----------------+------------------+-------------------+
|summary| fare_amount| prediction| error|
+-------+-----------------+------------------+-------------------+
| count| 3000| 3000| 3000|
| mean|9.536166666666665| 9.538236152251562|0.00206948558489451|
| stddev|6.952558857268078|6.8646934667359885| 0.6205967386209823|
| min| 2.5|1.9244213104248047| -4.911700439453128|
| max| 110.0|106.85425567626953| 2.949781894683838|
+-------+-----------------+------------------+-------------------+Именно в данном примере видим, что XGBoost справился быстрее и лучше, судя по значениям ошибок.
Гладко было на бумаге…
Разворачивая спойлер из первой части статьи, заработало действительно не все. На двух машинах с Docker Desktop завести целевую схему не удалось по причине невозможности синхронизации двух контейнеров разных машин друг с другом. Network=host не дает нужного результата, роуты и nginx proxy тоже, также настраивал iptables в контейнерах - безуспешно.
Проблему можно решить воспользовавшись Docker Swarm, но все дело в том, что для корректной работы кластера все равно нужна хотя бы одна машина с ОС Linux, выступающей мастером. Естественно, я попробовал сделать схему с запуском мастера на виртуалке, прописывал роуты и направлял трафик со второй физической ноды на определенный порт первой, а на первой ноде прописывал роут с данного порта на виртуалку, но столкнулся с проблемой получения ответных пакетов от мастера, и несколькими другими проблемами.
Также можно было попробовать раскатать Kubernetes, но на этом я решил остановиться, так как:
а) Standalone кластер Spark в контейнерах - по сути бред и априори overhead, так как суть Standalone кластера заключается в том, что его можно использовать на малом количестве нод и для постоянной нагрузки. В таком случае Docker не нужен, и лучше поставить на чистую ОС;
б) Если Kubernetes, то нужно понимать, что он нужен для плавающих нагрузок, для оптимизации использования вычислительных ресурсов, и лучше использовать Kubernetes Operator - вот в этом опыта пока еще нет, и, вероятно, это тема будущей статьи;
в) “Все, стоп, осталось только кубер на винде раскатать, хватит страдать фигней” - раздалось в голове, и я остановился :)
Однако, результат меня все равно обрадовал - работа XGBoost встала на шаге синхронизации датасетов для последующей выдачи результата, что успел запечатлеть на скриншоте.

Итог
Цель данной статьи считаю достигнутой. Все три библиотеки оказались работоспособными, сервис написан на Java, запущен как Spring Web Service, в Docker-контейнерах задачи на GPU исполняются.
Что дальше и можно ли что-то улучшить? Естественно, направлений работы несколько:
Тюнинг Spark. Как минимум, неплохо бы подключить Kryo serializer. Во время работы с Rapids 22.06.0 у меня он так и не заработал. Кроме Kryo есть множество параметров конфигурации самого Spark, которые все вместе в целом довольно сильно влияют на производительность.
Запуск Spark Standalone кластера на bare metal и нативном Ubuntu 20.04.
Запуск сервиса в Kubernetes в паре с Spark Kubernetes Operator. Вероятно, гайд по запуску и результаты будут темой отдельной статьи.
Дальнейшее R&D в ML и Spark.
Список ресурсов и литературы
ссылки
Common interesting articles
Accelerating Spark 3.0 and XGBoost End-to-End Training and Hyperparameter Tuning
Accelerating Deep Learning on the JVM with Apache Spark and NVIDIA GPUs
How Amazon retail systems run machine learning predictions with Apache Spark using Deep Java Library
How Netflix uses Deep Java Library (DJL) for distributed deep learning inference in real-time
Adopting machine learning in your microservices with DJL (Deep Java Library) and Spring Boot
Getting Started with RAPIDS Accelerator with on premise cluster or local mode
Accelerating Apache Spark 3.0 with GPUs and RAPIDS
Leverage deep learning in Scala with GPU on Spark 3.0
Accelerating Deep Learning on the JVM with Apache Spark and NVIDIA GPUs
nVidia documentation
nVidia docker containers documentation
How to install CUDA Toolkit on Ubuntu 18.04 LTS — Performatune
WSL 2 GPU Support for Docker Desktop on NVIDIA GPUs — Docker
nVidia Rapids documentation
On-Prem — Example Join Operation
nVidia ML documentation
Predictive Analytics Tutorial with Spark ML | NVIDIA
What’s New in Deep Learning & Artificial Intelligence from NVIDIA
Spark ML library documentation:
Classification and regression — Spark 3.3.0 Documentation
Ensembles — RDD-based API — Spark 3.3.0 Documentation
DJL
Troubleshooting — Deep Java Library
Deep Learning with Spark in Deep Java Library in 10 minutes
Deep Java Library(DJL) — a Deep Learning Toolkit for Java Developers
5.5. GPUs — Dive into Deep Learning 0.1.0 documentation
DJL dependency management — Deep Java Library
3.2. Linear Regression Implementation from Scratch — Dive into Deep Learning 0.1.0 documentation
3.3. Concise Implementation of Linear Regression
XGBoost Java library
xgboost/jvm-packages/xgboost4j-example at master · dmlc/xgboost
xgboost/SparkMLlibPipeline.scala at master · dmlc/xgboost
A Full Integration of XGBoost and Apache Spark
XGBoost4J-Spark-GPU Tutorial (version 1.6.1+) — xgboost 2.0.0-dev documentation
XGBoost4J-Spark-GPU Tutorial (version 1.6.1+) — xgboost 1.6.1 documentation
spark-rapids-examples/kubernetes-scala.md at branch-22.06 · NVIDIA/spark-rapids-examples
spark-rapids-examples/Taxi.scala at branch-22.06 · NVIDIA/spark-rapids-examples
For debugging
Комментарии (8)

sshikov
28.07.2022 09:11>Big Data Tool Apache Spark в Docker-контейнерах,
Знаете, что мне осталось сразу не очень понятным? Spark хорош в ситуации легкого масштабирования, например при наличии ярн кластера, ну и хотя бы сотни-тысячи ядер. У вас, как я понимаю, два узла (ядер соответственно скорее всего штук 20?), а сколько в наличии GPU вообще как-то не уловилось. В чем был смысл смешивать спарк и докер? Чтобы запуститься под windows (потому что драйверы для нужных GPU не работают в линуксе?
Dartya Автор
28.07.2022 09:40Драйверы для всех GPU имеются для линукса. У меня есть доступ только к виндовым машинам, линукс накатить нет возможности, а VMWare и VirtualBox не позволяют проводить такие манипуляции с GPU, остался вариант только с WSL.GPU в наличии по одному на каждой машине: 2060, 1650; с возможностью добавить на одну из машин 1080 Ti.
Вторая причина кроется в варианте использования той же DJL без Spark, но на GPU.
Третья причина (сейчас будет дилетантское суждение, так как изучил вопрос лишь поверхностно) - образ воркера для Kubernetes Operator должен содержать необходимый JVM, либы и скрипт обнаружения ресурсов, то есть все равно пришлось бы делать образ.
А так - да, Standalone кластер в докере - оверхэд и не нужно, для Yarn-Mesos слишком мало машин и ресурсов, а до кубера на винде я пока еще не дошел, и вряд ли дойду :)
sshikov
28.07.2022 09:49Понятно. Ну тогда да, такое решение хоть и странное немного, на первый взгляд, но под эти условия наверное логичное. Главное — работает)
sshikov
28.07.2022 09:57>неплохо бы подключить Kryo serializer. Во время работы с Rapids 22.06.0 у меня он так и не заработал.
Не очень представляю, как вам такое удалось :) Там конечно есть (с десяток наверное) параметров настройки, но мы как в начале их настроили, так только размеры буфера иногда крутим, когда очень широкие таблицы попадаются под руку. А вот настройка производительности, это да, это тема неисчерпаемая.
Почти все руководства, какие имеются в сети, рассчитаны исходя из того, что вы на кластере один, и можете распоряжаться ресурсами как хотите — в то время как в жизни у нас на кластере сотни и тысячи контейнеров, мы даже упирались в пределы масштабирования ярна, когда в его очереди было порядка тысяч задач, он перестает справляться. И выбор настроек в таком случае — это вообще задача без простых решений.Dartya Автор
28.07.2022 10:02Обязательно вернусь с подробностями в эту ветку, как будет время, прямо сейчас не готов развернуто ответить.
alexdoublesmile
Спасибо за статью!
"Немножко" над clean code поработать, чтобы этим кодом можно было пользоваться больше одного раза.
Dartya Автор
Учту, спасибо.