
Привет, Хабр! На связи Рустем, IBM Senior DevOps Engineer и сегодня я хотел бы продолжить наше знакомство с инструментом в DataOps инженирии — Apache Airflow. Сегодня мы спроектируем ETL-пайплайн. Не будем томить, сразу к делу!
Что нам понадобится? СУБД MySQL, Apache Airflow и данные с Datahub. Ссылка на datahub.
Наша задача
Нашей сегодняшней задачей будет создание конвейера, который работает ежедневно и заполняет список общих доменных имен верхнего уровня в таблице MySQL. В частности, мы хотим выполнить следующие шаги:
Извлечь данные с веб-сайта Datahub.
Преобразовать данные, отфильтровав «общие» доменные имена верхнего уровня.
Загрузить данные в службу хранения данных.
Вы заметите, что мы будем очень близко следовать парадигме ETL.
На следующих шагах мы создадим ноды для извлечения, преобразования и загрузки, используя соответствующие операторы в Airflow.
Проектирование «Extract node»
Прежде чем приступить к любым другим шагам, мы должны убедиться, что можем получить данные.
Итак, теперь мы вручную запустим операцию извлечения, чтобы загрузить файл данных из Интернета на локальный компьютер. Давайте скачаем данные, выполнив следующую команду:
wget -c https://datahub.io/core/top-level-domain-names/r/top-level-domain-names.csv.csv -O /root/manual-extract-data.csv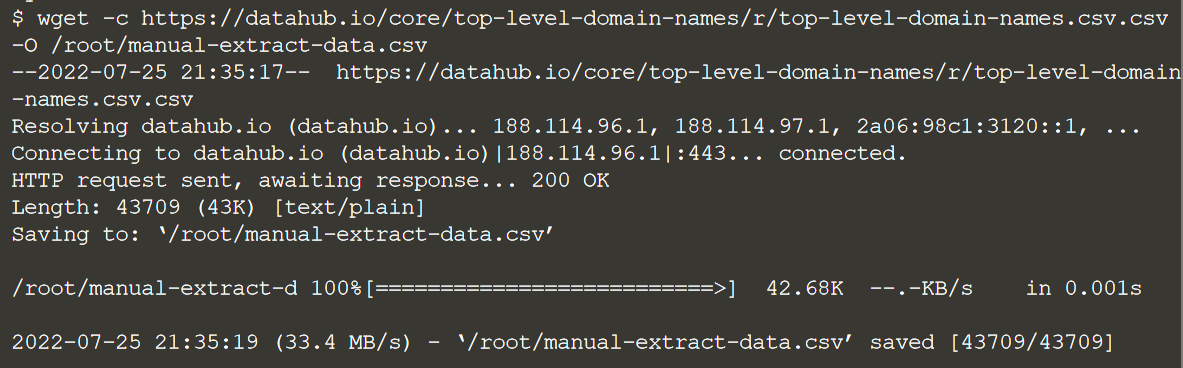
Теперь давайте удостоверимся, что это выглядит так, как ожидалось:
head /root/manual-extract-data.csv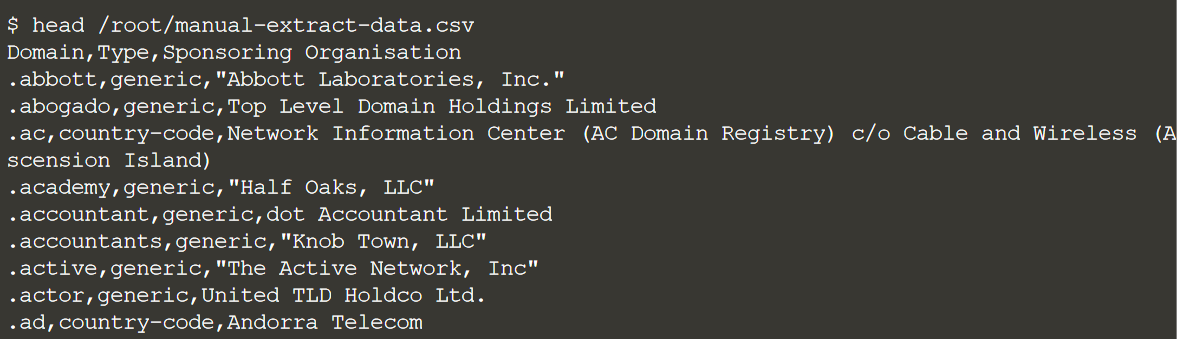
Создание “Extract node”
Теперь мы собираемся создать предыдущую функциональность в виде группы обеспечения доступности баз данных Airflow. Следующий фрагмент кода запускает команду wget и записывает данные в /root/airflow-extract-data.csv.
В этой задаче будет использоваться Bash Airflow Operator.
Создадим директорию airflow_demo с подкаталогом dags. Внутри dags создадим файл airflow-extract-node.py.
Откроем файл и вставим в него следующий код:
from airflow import DAG
from airflow.operators.bash import BashOperator
from datetime import datetime
with DAG('extract_dag',
schedule_interval=None,
start_date=datetime(2022, 1, 1),
catchup=False) as dag:
extract_task = BashOperator(
task_id='extract_task',
bash_command='wget -c https://datahub.io/core/top-level-domain-names/r/top-level-domain-names.csv.csv -O /root/airflow-extract-data.csv',
)
extract_task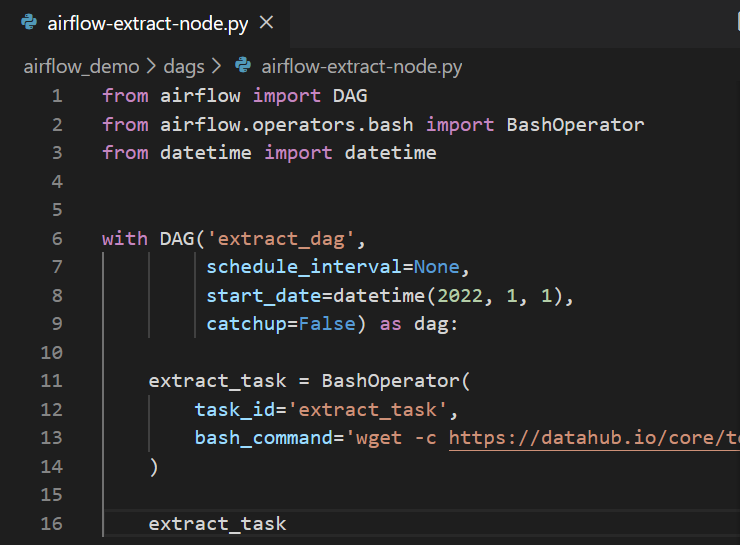
Зарегистрируем наш DAG, чтобы не ждать, пока Airflow сам подхватит его:
airflow db init
Теперь мы можем увидеть его и в нашем UI

Теперь давайте сосредоточимся на следующем шаге нашей задачи, в котором мы преобразуем данные, фильтруя их в «общие» доменные имена верхнего уровня.
Запуск операции преобразования вручную
Во-первых, мы вручную запустим операцию преобразования.
Давайте быстро поработаем над подтасовкой данных. Мы будем использовать python3 и pandas.
Установите pandas с помощью следующей команды:
pip3 install pandas
Далее выполните три комманды:
python3Import pandas as pdFrom datetime import dateТеперь прочитаем наши данные в датафрейме панд:
df = pd.read_csv("/root/manual-extract-data.csv")
df 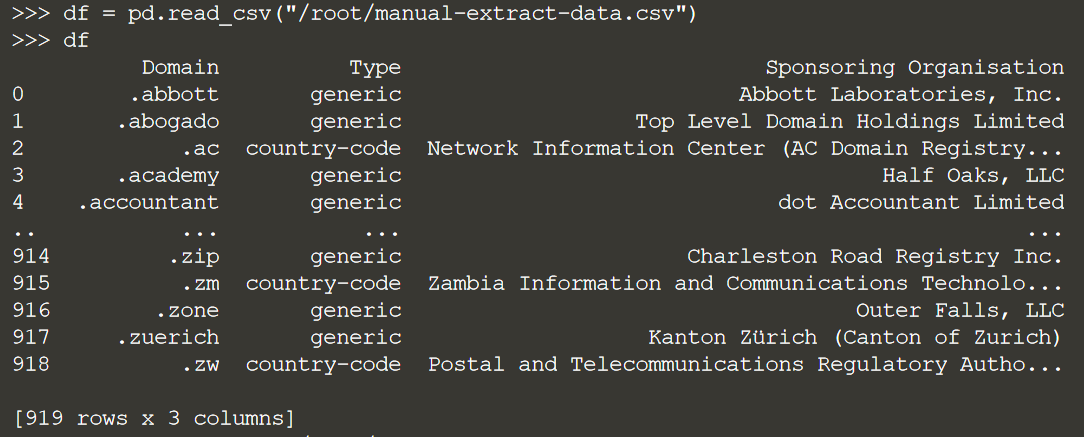
Теперь вспомните, что мы хотим отфильтровать «общие» доменные имена верхнего уровня. Давайте посмотрим, какие значения в столбце type:
df["Type"].unique()
Запустим наш фильтр:
generic_type_df = df[df["Type"] == "generic"]
Наконец, мы хотим добавить поле даты в наши данные, чтобы мы знали, в какой день они были очищены:
today = date.today()
Добавим этот столбец. (Примечание. Вы можете получить предупреждающее сообщение следующего вида: «A value is trying to be set on a copy of a slice....». Не обращайте на него внимание).
generic_type_df["Date"] = today.strftime("%Y-%m-%d")
Это данные, которые мы хотим сохранить. Давайте выпишем это:
generic_type_df.to_csv("/root/manual-transformed-data.csv", index=False)
Вернемся в наш ShellCtrl + C
Проверифицируем наши данные
head /root/manual-transformed-data.csv
Создание “Transform node”
Как и на этапе извлечения, мы собираемся создать задачу в Airflow, которая повторяет предыдущую функциональность.
В этой задаче будет использоваться оператор Python.
DAG читает из /root/airflow-extract-data.csv, применяет тот же фильтр pandas, что и выше, и записывает полученный набор данных в /root/airflow-transformed-data.csv.
Перейдите на вкладку IDE в окне Katacoda, где вы увидите папку airflow_demo с подкаталогом dags. Внутри dags вы создадим файл airflow-transform-node.py со следующим кодом:
from airflow import DAG
from airflow.operators.python import PythonOperator
import pandas as pd
from datetime import datetime, date
with DAG(
dag_id='transform_dag',
schedule_interval=None,
start_date=datetime(2022, 1, 1),
catchup=False,
) as dag:
def transform_data():
"""Read in the file, and write a transformed file out"""
today = date.today()
df = pd.read_csv("/root/airflow-extract-data.csv")
generic_type_df = df[df["Type"] == "generic"]
generic_type_df["Date"] = today.strftime("%Y-%m-%d")
generic_type_df.to_csv("/root/airflow-transformed-data.csv", index=False)
print(f'Number of rows: {len(generic_type_df)}')
transform_task = PythonOperator(
task_id='transform_task',
python_callable=transform_data,
dag=dag)
transform_task
Зарегистрируем наш DAG:
airflow db initВидим его в UI:

Проектирование «Load»
Давайте перейдем к следующему этапу, на котором полученный файл будет сохранен в локальной базе данных.
Теперь мы вручную запустим операцию загрузки. Это будет включать в себя получение недавно преобразованных данных и загрузку их в базу данных.
Создадим базу данных (как для ручных задач, так и для задач Airflow)
Сначала снова откроем оболочку MySQL:mysql
Создадим БД для “ручных” данных:
CREATE DATABASE manual_load_database;
Создадим теперь БД для данных Airflow:
CREATE DATABASE airflow_load_database;
Убедимся, что наши с нашими БД все впорядке:
SHOW DATABASES;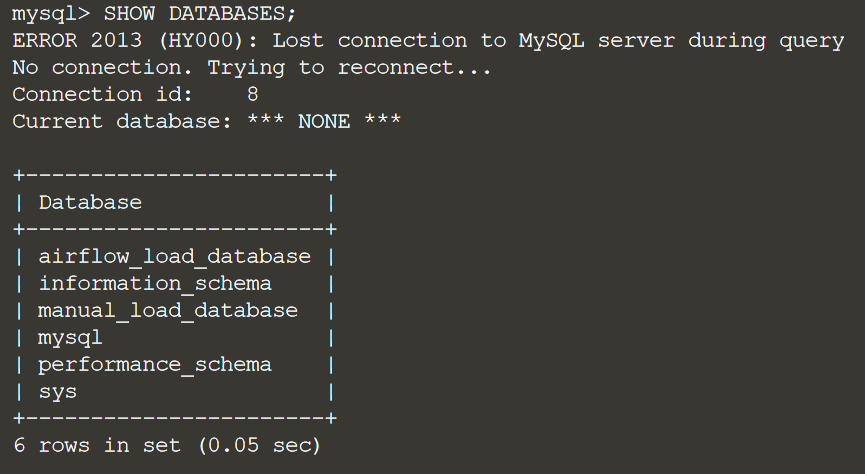
Теперь создадим таблицы для наших БД.
Сперва manual_load_database:
USE manual_load_database;
Наша схема будет выглядеть следующим образом: Domain,Type,Sponsoring Organisation
Мы собираемся архивировать «общие» данные в нашу таблицу ежедневно, поэтому нам нужно включить какой-то способ дифференциации ежедневного ввода.
Давайте создадим нашу таблицу, но добавим столбец для даты:
CREATE TABLE top_level_domains(Domain VARCHAR(30), Type VARCHAR(30), SponsoringOrganization VARCHAR(30), Date DATE);
Проверим нашу таблицу:
DESCRIBE top_level_domains;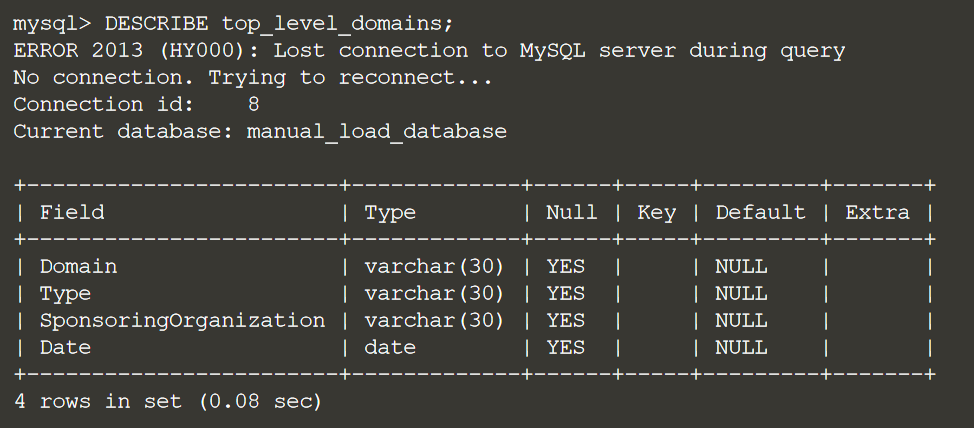
Теперь повторим тоже самое для airflow_load_database:
USE airflow_load_database; CREATE TABLE top_level_domains(Domain VARCHAR(30), Type VARCHAR(30), SponsoringOrganization VARCHAR(30), Date DATE);
Теперь загрузим данные вручную.
Сперва добавим такую настройку и выйдем:
SET GLOBAL local_infile=1;
Теперь перезайдем в mysql следующим образом:
mysql --local-infile=1
Выберем БД:
USE manual_load_database;
Загрузим данные:
LOAD DATA LOCAL INFILE '/root/manual-transformed-data.csv' INTO TABLE top_level_domains FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY '\n' IGNORE 1 ROWS;Небольшая проверочка:
select * from top_level_domains;
Если все работает до сих пор, отличная работа! Теперь мы вручную выполнили процесс ETL для нашей задачи. Давайте разберемся, как это автоматизировать.
Проектирование “Load Node”
Мы собираемся использовать Airflow для выполнения той же работы, что и вручную.
В этой задаче будет использоваться оператор MySql. Чтобы это заработало, нам нужно установить некоторые параметры конфигурации.
Одной из самых мощных функций Airflow является его гибкость. Операторы фактически являются шаблонами, позволяющими выполнять различные виды операций.
Мы собираемся установить оператор MySQL:
pip3 install apache-airflow-providers-mysql
Теперь создадим файл airflow-load-node.py со следующим кодом:
from datetime import datetime
from airflow import DAG
from airflow.providers.mysql.operators.mysql import MySqlOperator
with DAG('load_dag',
start_date=datetime(2022, 1, 1),
schedule_interval=None,
default_args={'mysql_conn_id': 'demo_local_mysql'},
catchup=False) as dag:
load_task = MySqlOperator(
task_id='load_task', sql=r"""
USE airflow_load_database;
LOAD DATA LOCAL INFILE '/root/airflow-transformed-data.csv' INTO TABLE top_level_domains FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY '\n' IGNORE 1 ROWS;
""", dag=dag
)
load_task
И зарегистрируем наш DAG:
airflow db init
Собираем все вместе
На данный момент мы создали три разные DAG, каждый из которых выполняет одну задачу: извлечение, преобразование или загрузка. Давайте объединим их в один DAG Airflow.
Создаем ETL DAG
Для этого создадим файл с именем basic-etl-dag.py со следующим кодом:
from airflow import DAG
from airflow.operators.bash import BashOperator
from airflow.operators.python import PythonOperator
from airflow.providers.mysql.operators.mysql import MySqlOperator
import pandas as pd
from datetime import datetime, date
default_args = {
'mysql_conn_id': 'demo_local_mysql'
}
with DAG('basic_etl_dag',
schedule_interval=None,
default_args=default_args,
start_date=datetime(2022, 1, 1),
catchup=False) as dag:
extract_task = BashOperator(
task_id='extract_task',
bash_command='wget -c https://datahub.io/core/top-level-domain-names/r/top-level-domain-names.csv.csv -O /root/airflow-extract-data.csv',
)
extract_task
def transform_data():
"""Read in the file, and write a transformed file out"""
today = date.today()
df = pd.read_csv("/root/airflow-extract-data.csv")
generic_type_df = df[df["Type"] == "generic"]
generic_type_df["Date"] = today.strftime("%Y-%m-%d")
generic_type_df.to_csv("/root/airflow-transformed-data.csv", index=False)
print(f'Number of rows: {len(generic_type_df)}')
transform_task = PythonOperator(
task_id='transform_task',
python_callable=transform_data,
dag=dag)
transform_task
load_task = MySqlOperator(
task_id='load_task', sql=r"""
USE airflow_load_database;
LOAD DATA LOCAL INFILE '/root/airflow-transformed-data.csv' INTO TABLE top_level_domains FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY '\n' IGNORE 1 ROWS;
""", dag=dag
)
load_task
extract_task >> transform_task >> load_task
Зарегистрируем наш DAG: airflow db init.
И увидим его в нашем UI:
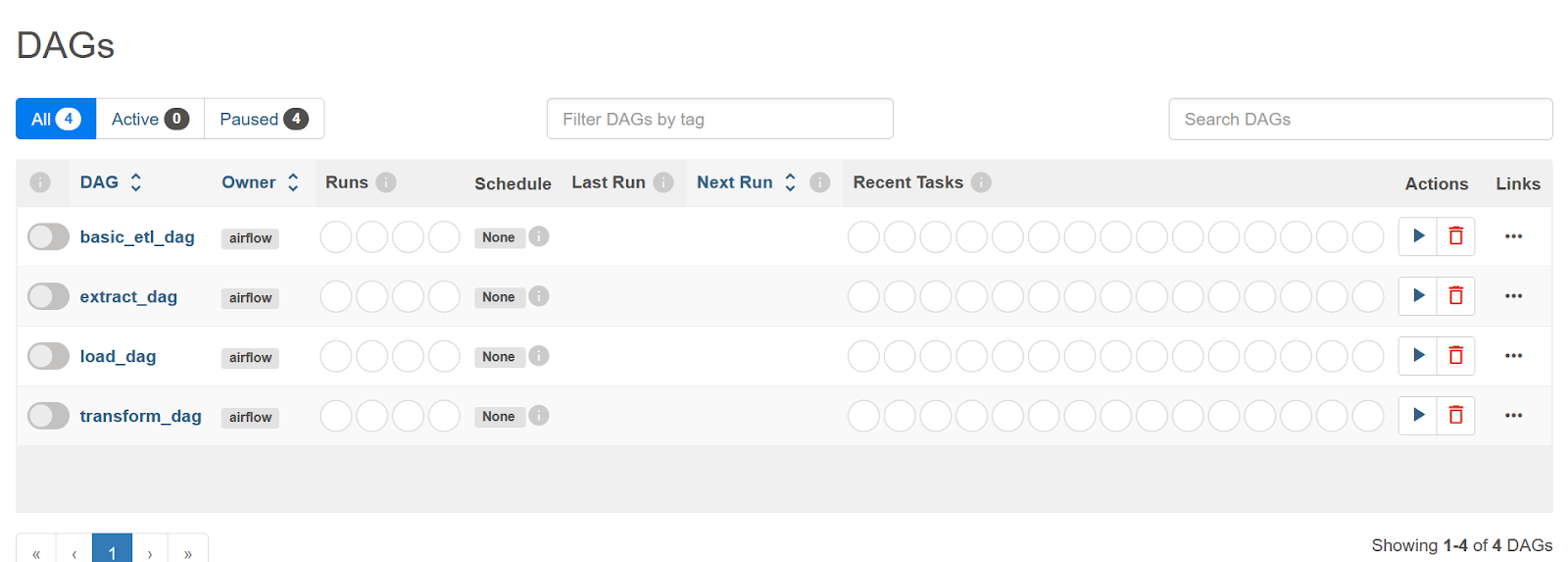
Теперь давайте запустим наш DAG.
После запуска DAG давайте быстро проверим работоспособность, чтобы убедиться, что он делает то, что нам нужно.
Всегда полезно убедиться, что все работает должным образом, даже если вы получаете три зеленых поля в Airflow.
Первым шагом задачи извлечения в DAG является извлечение данных из Datahub в /root/airflow-extract-data.csv. Давайте удостоверимся, что данные действительно есть:
head /root/airflow-extract-data.csv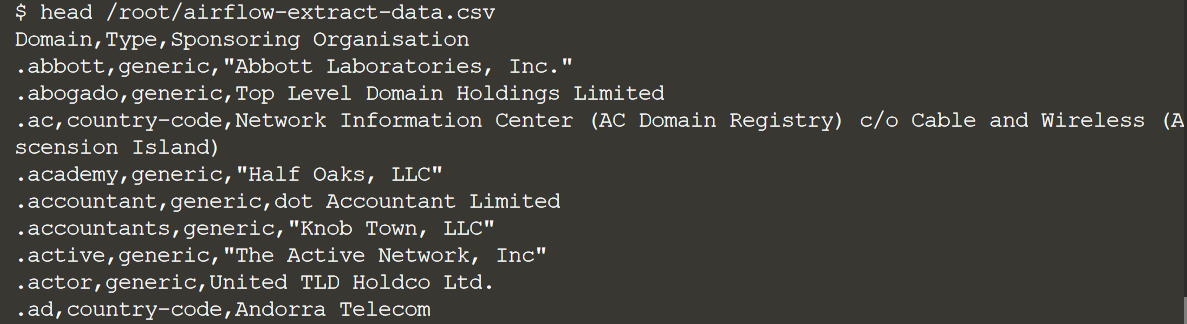
Если вы видите, что данные возвращаются, это означает, что ваша задача успешно смогла получить и сохранить данные на диске.
Шаг преобразования считывает файл /root/airflow-extract-data.csv, выполняет в нем некоторые преобразования и записывает его в /root/airflow-transformed-data.csv.
Давайте удостоверимся, что данные действительно есть:
head /root/airflow-transformed-data.csv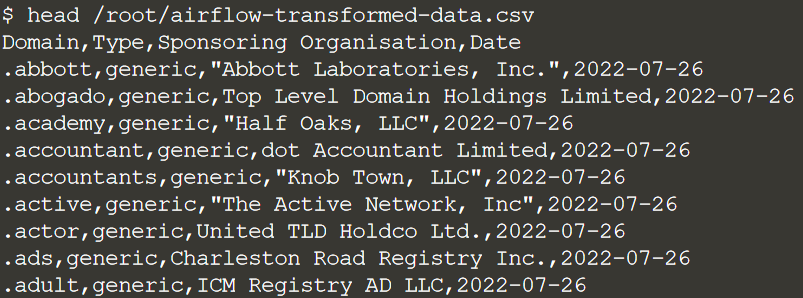
Если вы видите выходные данные, это означает, что вашей задаче удалось успешно прочитать, преобразовать и сохранить эти новые данные на диске.
На этапе выгрузки данные считываются из /root/airflow-transformed-data.csv и сохраняются в таблице MySQL.
Давайте откроем оболочку MySQL, чтобы увидеть, есть ли там наши результаты:
mysql
Используйте базу данных, которую мы создали для нашей DAG Airflow:
USE airflow_load_database;И, наконец, давайте запустим SELECT для таблицы:
SELECT * FROM top_level_domains;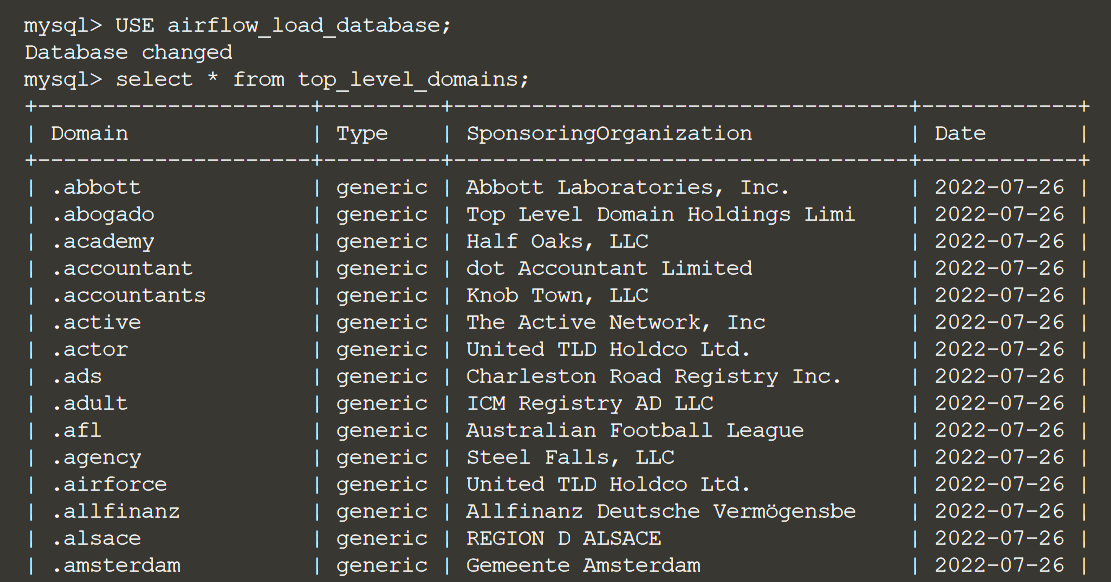
Если вы видите результаты, это означает, что ваша DAG прошла успешно!
Приглашаем всех желающих на открытое занятие «MapReduce: алгоритм обработки больших данных». На нем подробно разберем универсальный алгоритм, с помощью которого обрабатываются большие данные на распределённых системах без общего хранилища (Hadoop, Spark). Поговорим об «узких местах» и потенциальных операционных проблемах. Посмотрим, как это выглядит на практике в Яндекс.Облаке. Регистрация здесь.
Также регистрируйтесь на занятие по теме «Архитектуры систем обработки данных».