
Пара слов о том, почему линии электропередач могут отключаться
Энергосистема — это довольно сложный организм, состоящий из множества узлов генерации электроэнергии и узлов потребления, соединённых между собой линиями электропередач. Когда-то на заре энергетики электростанции были маленькими и находились рядом с потребителями, а потому были соединены напрямую. Но со временем станции становились больше, возникала задача транспортировки электроэнергии на всё большие расстояния, что требовало усложнять тракт передачи.

Соответственно, чтобы снизить потери на нагрев мы можем увеличить напряжение в проводнике или его сечение, причём так как напряжение у нас в квадрате, то увеличение его оказывает гораздо больший эффект на величину потерь, чем увеличение площади сечения проводника. Более того, увеличение сечения крайне негативно сказывается на массе проводника и экономической целесообразности. Отсюда очевидный вывод: надо делать для передачи на дальние расстояния линии с большим напряжением. Но при этом чем выше напряжение – тем больше размеры оборудования и требования к безопасности, а значит, для потребителей в большинстве случаев придётся сохранять низкие значения напряжения.
Это приводит к тому, что энергосистема выстраивается по следующему принципу: есть ЛЭП высокого напряжения, которые осуществляют транзит больших мощностей на большие расстояния, есть линии меньшего напряжения, которые дублируют их и распределяют энергию между более мелкими узлами потребления, и есть линии низкого напряжения в распределительной сети, к которой подключают потребителей.
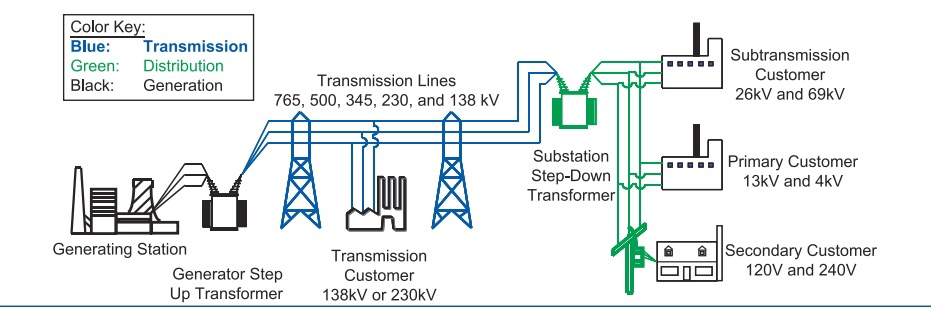
Принципиальная схема сетей США
Но у нагрева проводов есть и ещё одно следствие. Опять же, вспоминаем школьный курс физики: при нагреве проводник расширяется во все стороны, то есть и удлиняется тоже, что вызывает ещё больший рост потерь. Провод из-за удлинения провисает и может либо оборваться, либо задеть какие-то объекты внизу, например ветку дерева, что вызовет замыкание. Худший случай – это перехлёст двух или трёх проводов, что вызовет междуфазное короткое замыкание. Поэтому перегрузку линии током (термическую перегрузку) требуется жёстко ограничивать по значению и длительности.

Ключевая проблема провисания ЛЭП в одной картинке: в данном случае при провисании до 38 футов ветер в 5 узлов может привести к касанию дерева; при 36 — уже даже в отсутствии ветра может произойти касание; при 34 — критический провис по механической прочности самого провода
После отключения повреждённого элемента электрическая мощность, которую мы должны передать потребителям, распределится между оставшимися в работе элементами. Обычно отключение даже одной ЛЭП высокого напряжения не должно оказывать существенного влияния на состояния системы. Тем не менее из-за изменившихся потоков мощности становится возможна термическая перегрузка отдельных элементов энергосистемы, и для исключения их отключения требуется вмешательство оперативно-диспетчерского управления.
Этих знаний нам будет достаточно для понимания процесса развития аварии.
Предпосылки
Любая авария в энергосистеме – это сочетание множества факторов. Как бы ни была сложна система передачи электроэнергии, она обычно имеет достаточный запас надёжности по отказам, а также большую инерцию из-за чего даже в случае неблагоприятного стечения обстоятельств обычно есть время провести компенсирующие мероприятия. Но проблема в том, что для начала опасную для энергосистемы ситуацию нужно вовремя распознать, а с этим в 14 августа 2003 в Северо-Восточной энергосистеме США случились большие проблемы.
Начало аварии положило незначительное на первый взгляд происшествие: в 13:30 остановился блок №5 ТЭЦ Eastlake мощностью 680 МВт. Причина аварии крылась в неправильных действиях персонала, приведших к выходу из строя регулятора возбуждения турбины. Само по себе это происшествие было некритичным. Да, возник локальный дефицит мощности, но его компенсировало увеличение перетоков мощности по линиям из других частей энергосистемы.

Перетоки мощности между сетями энергокомпаний перед аварией
Вторым фактором стало отключение в 14:02 линии 345 кВ Stuart-Atlanta: из-за незначительной перегрузки провода провисли и произошло касание с деревьями, растущими под ЛЭП. Опять же, и этот инцидент не должен был значительно повлиять на состояние энергосистемы при внимательном наблюдении за режимом оператором диспетчерского пункта. Но именно с этим у энергообъединения First Energy Corporation (FE), в чьей зоне ответственности и происходили описанные события, в этот момент случились проблемы.
Ничего не вижу. Ничего не слышу
Для начала разберёмся с инструментарием, с помощью которого диспетчер управляет энергосистемой. Основным инструментом взаимодействия с энергосистемой у диспетчера является Supervisory control and data acquisition (диспетчерское управление и сбор данных) или попросту SCADA. SCADA служит для обеспечения работы систем сбора, обработки, отображения и архивирования информации об объекте мониторинга или управления. Условно её можно разделить на 3 крупных составных части: система сбора информации, система пользовательского интерфейса, система реализации управляющих воздействий.
- Система сбора информации осуществляет сбор данных со всех датчиков (трансформаторов тока и напряжения, датчиков мощности, направления перетока мощности и т.д), информации о срабатывании защит и автоматик, расчёт дополнительных необходимых для контроля параметров и передачу их в систему пользовательского интерфейса.
- Система пользовательского интерфейса предоставляет полученные данные в удобном для оператора формате: мнемосхемы, отображающей состояние элементов сети; графиков изменения ключевых параметров; окон данных параметров по ключевым узлам и каждому объекту сетевого хозяйства; оповещений о событиях.
- Система реализации управляющих воздействий, позволяющая либо отправлять запросы на объекты электросетевого хозяйства об изменениях режима, либо напрямую управлять отдельными её элементами.

А это уже техническая реализация
Резервирует все эти три системы обычный телефон, с помощью которого оператор может узнать о текущем положении напрямую и также напрямую отдать указания. Фактически же, в то время всё оперативно-диспетчерское управление осуществлялось с помощью звонков по телефону, а SCADA выполняла лишь функцию информирования о режиме.
Более того, из-за размеров энергообъединения FE мнемосхема на экране диспетчера при максимальном масштабе отображения была крайне малоинформативна, поэтому диспетчеры полностью полагались на подсистему генерации оповещений, которая выдавала сообщения по факту любых изменений в энергосистеме: включение/отключение объектов, выход контролируемых параметров за допустимые пределы и так далее. По факту получения оповещения диспетчер увеличивал масштаб схемы, рассматривал нужный район и решал о том, какие дальнейшие действия следует предпринять.

Примерно так выглядела мнемосхема на экране оператора. Упустить какое-то изменение статуса линии очень легко
В 14:14 из-за ошибки сервера SCADA подсистема генерации оповещений была потеряна без всяких сообщений об ошибке и диспетчер не узнал об этом, считая отсутствие оповещений за признак нормальной работы энергосистемы, а не отказ функции SCADA. В результате диспетчер на протяжении следующих двух часов был уверен, что у него в энергосистеме всё в порядке. Решением проблемы могло бы быть использование видеостены с большой мнемосхемой, где были бы удобно отображены все объекты и планшеты с основными параметрами сети в ключевых точках. На такой мнемосхеме диспетчер мог бы вовремя увидеть отключение сетевых элементов и изменения параметров режима. Но по неизвестной причине в FE решили сэкономить на этом, из-за чего диспетчер оказался в полной ситуационной неосведомлённости о положении в его энергосистеме.

А вот так должен выглядеть диспетчерский пункт в идеале, с большой мнемосхемой
Что же произошло с серверами FE?
Подсистема генерации отчётов SCADA GE Energy's XA/21, использовавшейся FE, исполнялась на отдельном резервированном сервере, вместе с другими вспомогательными подсистемами. Такое решение должно было увеличить надёжность работы всей системы и обеспечить большее быстродействие. Принцип работы системы был простой: она обрабатывала входящую информацию о событиях в энергосистеме и изменении параметров, как расчётных, так и измеряемых, и в случае, если один из параметров вызывал срабатывание заранее заданных триггеров, то формировалось оповещение в виде текстового сообщения и звукового сигнала.
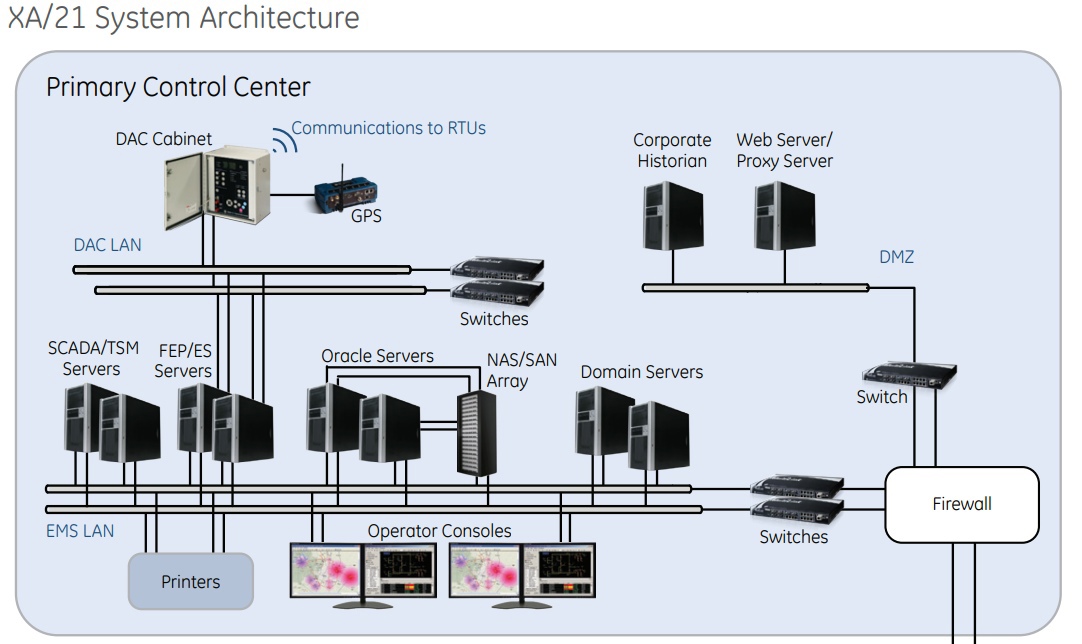
Архитектура SCADA GE XA/21

Окно отчётов о событиях
Во время расследования первоначально предположили, что сервер подсистемы генерации отчётов был поражён червём “Slammer”, бушевавшем тогда в США и уже поразившем ранее несколько ТЭЦ. Но разбор логов и кода не подтвердил эту теорию, система кибербезопасности сетей FE была признана адекватной и нескомпрометированой. Тогда начали искать причину в самом коде и после анализа миллионов строк таки нашли. Проблема заключалась в самом принципе работы генератора отчётов и крайне маловероятном стечении обстоятельств. После срабатывания триггера на вход генератора подаётся запрос на создание оповещения. Из-за кратковременной задержки обработки запросов, не более чем на пару миллисекунд, два процесса одновременно обратились к записи в одну и ту же ячейку памяти. Это привело к «состоянию гонки» (race condition) и зависанию генератора отчётов в бесконечном цикле обращения к ячейке памяти. Из-за этого уже с 14:14 оповещения не генерировались SCADA.

Так как запросы обрабатывались по очереди поступления, то из-за зависания генератора вскоре в буфере скопились необработанные запросы. К 14:41 буфер сервера переполнился и он отключился. На этот случай был резервный сервер, в котором мгновенно из бэкапа были развёрнуты все процессы, ранее запущенные на основном сервере, в том числе и зависший генератор отчётов. Этот сервер протянул гораздо меньше из-за всё большего числа данных на входе и отрубился в 14:54. При этом никаких сообщений об этом диспетчеру сгенерировано не было, автоматически был создан только тикет в службу технической поддержки FE и то только после отключения второго сервера. Из-за отсутствия в протоколе ТП требования сообщать о неисправностях оборудования диспетчерам, техподдержка, естественно, этого не сделала и отправилась чинить сервера, в то время, как диспетчер был свято уверен, что весь последний час они работают нормально.
В 15:08 были «мягко» перезапущены сервера, но при этом инженеры проверили только сам факт восстановления работы серверов, но не функциональность их ПО. А ПО подсистемы генерации отчётов после ребута серверов из-за ошибки при завершении работы оказалось нефункциональным. То есть перезапуск серверов никак не решил проблему. В 15:42 звонок из техподдержки сильно удивил диспетчеров, сообщением, что «мы восстановили работоспособность сервера генерации отчётов». При этом подсистема генерации отчётов всё ещё не работала и диспетчер пребывал в полной уверенности, что у него-то в энергосистеме всё в порядке. Хотя на самом деле к моменту этого звонка всё уже 10 минут как катилось к чёрту и точка невозврата была очень близка.
Потерянное время
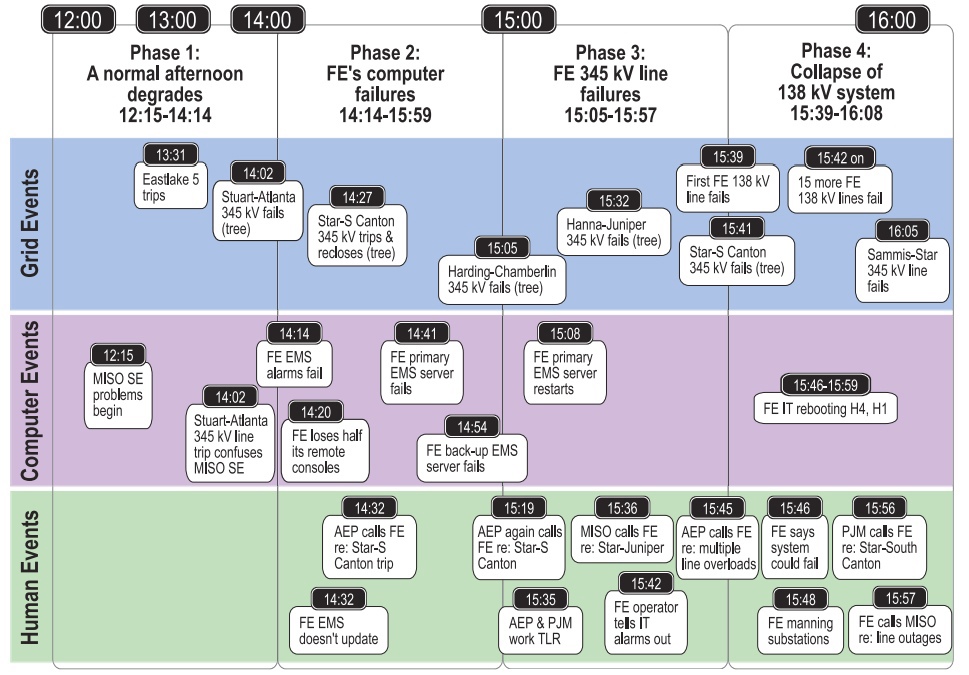
Таймлайн блэкаута
Так как диспетчер FE не знал об отказе генерации отчётов, а потому считал, что в его зоне ответственности всё в порядке, то он естественно пропустил роковое для энергосистемы событие – отключение ЛЭП 345 кВ Chamberlin-Harding. Она отключилась в 15:05 при нагрузке всего 45,5% от номинальной из-за касания фазой дерева, растущего под ЛЭП. Первой очевидной причиной такого развития событий было пренебрежение FE ухаживанием за трассами ЛЭП, так как это было уже второе за два часа, но не последнее за день, отключение линии из-за касания деревьев. Второй же причиной, непосредственно приведшей к первой, стал рост перетоков по линиям и их нагрев из-за уже случившегося ранее ослабления сети. Тот факт, что перегрузка на них так и не наступила был скорее лишь отягчающим обстоятельством, так как незначительный провис из-за термического расширения провода привёл к короткому замыканию, чего в нормальной ситуации быть не должно.
Так как в SCADA никаких уведомлений не было, то диспетчер FE был уверен, что ЛЭП 345 кВ Chamberlin-Harding находится в работе и на звонки с вопросом о её состоянии отвечал, что «всё ОК». В 15:32 из-за выросшей нагрузки коснулась деревьев и отключилась ещё одна линия — 345 кВ Hanna-Juniper. Отключение уже трёх системообразующих линий 345 кВ привело к росту нагрузки на все остальные линии. Диспетчер FE всё ещё бездействовал, так как не знал о всех этих авариях.

Диспетчер FE
Точкой невозврата стал отказ линии 345 кВ The Star-South Canton расположенной на стыке FE and AEP (American Electric Power). Эта линия уже дважды отключалась из-за выросшей нагрузки по ней: в 14:27 и в 15:38. Оба раза причиной были всё то же сочетание факторов перегрузка + деревья, растущие под ЛЭП. В 15:41 линия 345 кВ The Star-South Canton отключилась в третий раз и восстановить её работу на этот раз не вышло.
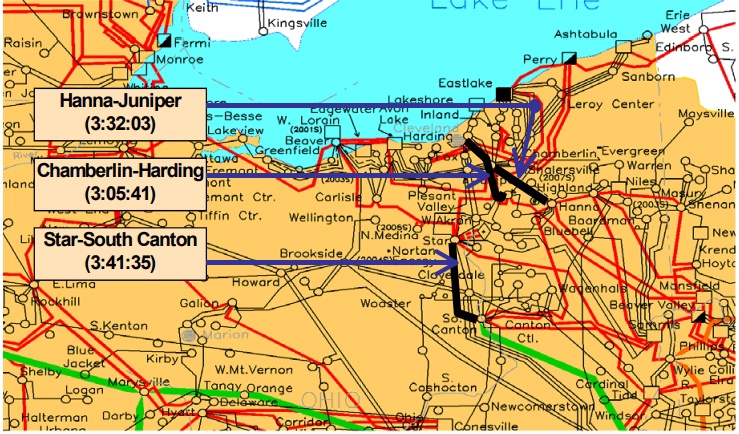
Схема сети и три первые отключившиеся линии 345 кВ
Всё, точка невозврата была пройдена – сеть потеряла 4 системообразующие ЛЭП из-за чего началась перегрузка сети меньшего напряжения 138 кВ. Первая линия 138 кВ отключилась в 15:39, то есть за две минуты до отключения 345 кВ The Star-South Canton, но после процесс принял лавинообразный характер, так как чем меньше линий оставалось в работе – тем больше была перегрузка оставшихся.
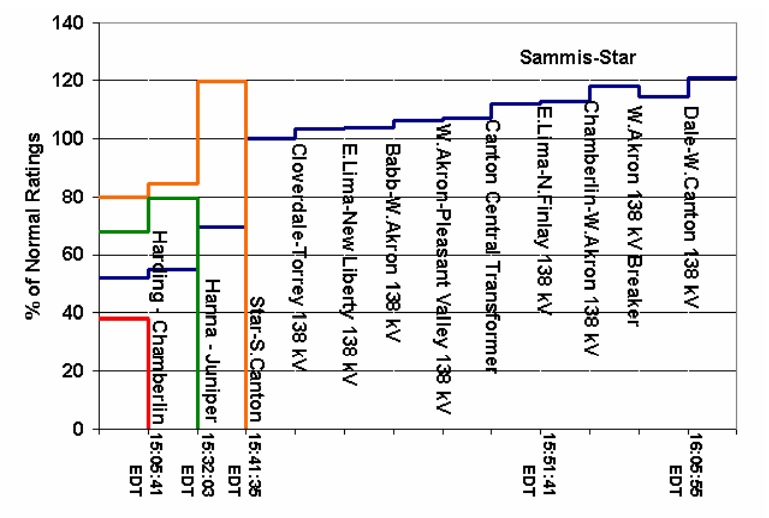
Таймлайн роста перегрузки линий
При всём при этом оператор FE не делал НИЧЕГО, так как всё ещё не знал об отказе SCADA, а на все звонки отвечал, что «проблема не в моей зоне ответственности, ищите у себя». Время на предотвращение аварии было упущено и процесс вошёл в самоподдерживающуюся стадию – впереди был только блэкаут. Но неужели система была столь плохо выстроена, что отказ одного диспетчерского пункта привёл к неминуемому коллапсу энергосистемы? Конечно нет, но в тот день США очень не повезло.
Координировали, координировали, да не выкоординировали
Естественно, что в США управлением энергетики страны занимались не дураки и понимали, что для координации деятельности разных диспетчерских центров нужен единый орган. И он на Северо-Востоке США был – координатор надёжности энергосистемы или Midcontinent Independent System Operator (MISO), объединявший значительную часть операторов энергосистем Северо-востока. К MISO в автоматическом режиме поступали все данные энергообъединений о состоянии объектов сетевого хозяйства (включены/отключены), а также результаты измерения основных параметров. По этим данным информационная система MISO должна была проводить анализ надёжности, сводящийся к расчёту режима и поиску опасных для работоспособности системы ситуаций. Выполнение таких расчётов должно было проводиться как автоматически по таймеру и при отключении/включении объектов, так и вручную в случае необходимости проверки верности предлагаемых управляющих воздействий.
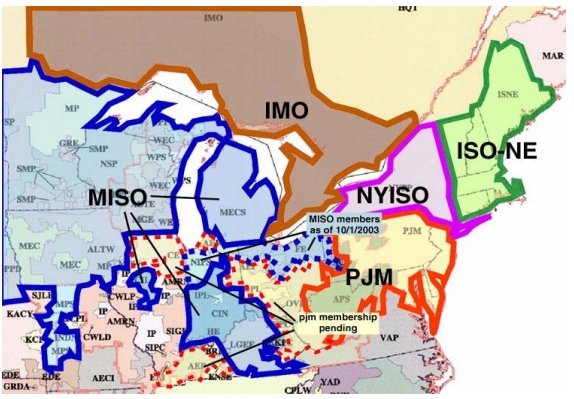
Операционная зона MISO
В идеальном мире для этого использовалась бы real-time система, как SCADA, но MISO развивало свой собственный продукт, в основном методом добавления костылей. Система в распоряжении MISO была не real-time, да она получала данные с низовых устройств, но расчёт надёжности проводился по таймеру раз в 5 минут, таким образом оператор имел срез состояния энергосистемы, который мог за следующий промежуток времени сильно устареть. Автоматический расчёт надёжности проводился по скрипту, который днём в 13:07 был отключён для проведения работ с системой. Причиной стала необходимость привязать сигналы включенного/отключенного состояния линии 230 кВ Bloomington-Denois Creek к её отображению в расчётной модели. После окончания процесса диспетчер попросту забыл активировать скрипт и ушёл на ланч, из-за чего до 14:40 автоматический расчёт надёжности не производился.

При этом даже после восстановления работы скрипта и получения результатов расчёта, свидетельствующих о нарастании кризиса в энергосистеме, эти расчёты оказались неадекватны ситуации. Как выяснится уже в ходе расследования, линия 345 КВт Stuart-Atlanta, отключившаяся ещё в 14:02, тоже не была подключена к автоматическому обновлению статуса по данным, получаемым от автоматик. Из-за этого расчётная модель обсчитывала более лёгкий режим и диспетчер MISO не понимал всю тяжесть ситуации.
Как результат, MISO до 14:40 вообще не понимало о существовании кризисной ситуации. После 14:40 ситуация оценивалась куда легче, чем была в реальности. Сомнения в том, что результаты расчётов адекватны, появились у диспетчера MISO лишь в начале 15 часов, когда стало ясно, что реальные замеры мощности и расчётные сильно расходятся. И только в 15:29 после телефонного звонка оператору линии 345 КВт Stuart-Atlanta (фирма PJM), была найдена ошибка в модели, устранённая к 16:04, когда каскадная авария уже охватила всю энергосистему. В результате MISO не смог выполнить свою основную функцию – сохранить надёжность работы энергосистемы. При этом, как выяснится в ходе расследования, схожая же проблема была и у SCADA оператора PJM.

У MISO кроме ПО для расчёта надёжности были и альтернативные решения, которые выступали вспомогательными средствами и могли бы помочь быстрее сориентироваться. Так, в комплексе ПО MISO была ещё и программа Flowgate Monitoring Tool (FMT), которая была альтернативным средством, рассчитывавшим перегрузки наиболее важных линий и сигнализировавшей об этом. Данное ПО работало в тот день штатно и могло бы вовремя сработать, но оно не смогло вовремя выявить аварийную ситуацию из-за особенностей сбора данных. В отличии от расчёта надёжности, FMT получала данные о состоянии линий не от их автоматик, а из базы данных NERC SDX, куда владельцы линий должны были сообщать в течении 24 часов(!) о всех выполняемых переключениях. В результате эта система обсчитывала подчас режимы, отстоящие от реальных на часы, и никто этого вообще не замечал. По какой причине FMT брало данные не из обновляющейся автоматически информации о состоянии линий, неизвестно.
Кроме того, была и система оповещений об отключении линий, похожая на имевшуюся в SCADA FE. Но и она оказалась бесполезна, так как, во-первых, диспетчер просто не заметил оповещения. А во-вторых, пользовательский интерфейс был таков, что диспетчеру после получения оповещения требовалось найти на схеме нужный выключатель и уже, кликнув по нему, проверить его состояние. Система не подсвечивала выключатели, изменившие состояние, и не имела функции перехода к объекту по щелчку на уведомление. Все эти недостатки вместе стали фатальны для работы MISO в тот день.
Коллапс
После 15:42 энергосистему Северо-востока было уже не спасти. Лавинообразный процесс нарастания перегрузок и отключений линий привёл к тому, что за следующие 25 минут отключилось из-за перегрузки 11 линий 138 кВ и 1 – 345 кВ. За следующие 5 минут отключилось 6 линий 345 кВ. Каскад перегрузок линий и их отключений привёл к ещё одному каскадному процессу – лавине напряжения, так как баланс нагрузки и генерации стал смещаться в сторону нагрузки и напряжение в сети стало проседать. А когда напряжение в сети уменьшается, то уменьшается и производительность питательных насосов электростанций, из-за чего их эффективность падает и ещё больше увеличивается дефицит генерации. В течении следующих 5 секунд с 16:10:39 по 16:10:46 отключилось 5 линий 345 кВ и 19 энергоблоков станций (в том числе 1 блок АЭС) суммарной мощностью 4700 Мвт.
При этом никто из диспетчеров так и не понимал, что и почему происходит. MISO только-только восстановили нормальную работу ПО для оценки надёжности, но всё новые отключения приводили к расхождениям их схемы и реальности. Операторы AEP и PJM, на энергосистемы которых начали накатывать перегрузки, тоже потеряли контроль за ситуацией, так как не понимали причину возникших сложностей, а оператор FE клятвенно уверял, что «проблемы не в сети FE, у нас всё в порядке». При этом в работе SCADA AEP и PJM тоже были недостатки, в частности проблемы с обновлением статуса состояния линий, но это уже мало влияло на ситуацию.
Диспетчеры FE начали понимать, что что-то, возможно, идёт не так, когда после 15:42 на них обрушилась просто лавина звонков от соседних диспетчерских пунктов и низового персонала FE о всё новых отключениях линий. Только после этого диспетчер решил таки позвонить в техподдержку и попросить проверить работу сервера ещё раз. К 16:05 был произведён полный перезапуск подсистемы генерации отчётов и она заработала. Внезапное прозрение, что проблема таки в сети FE, произошло — но было уже слишком поздно. Диспетчеры FE и других операторов, могли лишь наблюдать за разворачивающимся апокалипсисом, так как сделать что либо было уже решительно невозможно.

Диспетчер FE в 16:00
Диспетчер FE в 16:05
История сохранила записи телефонных звонков операторов, в которых сквозит полное непонимание происходящего:
Оператор AEP: “У нас большие проблемы… много линий отключается. East Lima и New Liberty отключились. Посмотри на это.”
Оператор AEP: “О боже, я в глубокой …”
Оператор PJM: “Ты и я, мы оба, брат. Что мы собираемся делать? Если тебе что-нибудь нужно, дай мне знать.”
Оператор AEP: “Только что еще что-то отключилось. Много чего происходит.”
Оператор PJM: “И когда это произошло? Это могло бы...”
Оператор MISO: “Я еще не знаю. У меня все еще есть… У меня не было пока возможности изучить этот вопрос. Сейчас слишком много всего происходит”.
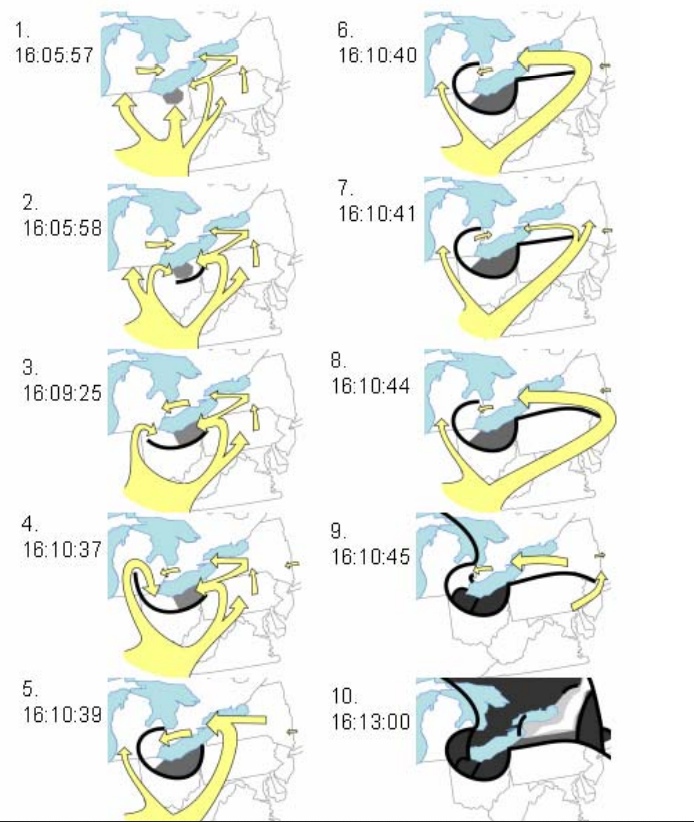
Последние минуты перед коллапсом. Жёлтым отмечены перетоки мощности
К 16:13 коллапс энергосистемы завершился, приведя к отключению сотен линий электропередач и 508 энергоблоков на 265 электростанциях, из которых 10 – это АЭС(!). В зоне отключения оказались: северная часть Огайо, восточная часть Мичигана, северная часть Пенсильвании и Нью-Джерси, большая часть Нью-Йорка, Массачусетс, Коннектикут, Вермонт, а также канадские провинции Онтарио и Квебек. Всего без света остались 40 миллионов человек в США и 15 миллионов в Канаде. Рухнула сотовая и телефонная связь, остановилась торговля на Нью-Йоркской фондовой бирже, возникли проблемы с посадкой самолётов и многочасовые задержки рейсов. Единственным плюсом было то, что авария произошла днём и власти успели наладить подобие порядка на улицах городов. На полное возвращение энергоснабжения ушло несколько дней из-за того, что многие станции вынуждены были проводить ремонтные работы из-за аварийного останова.
Эпилог
Как несложно заметить, авария развивалась 2 часа, из которых первые полтора часа было достаточно возможностей для предотвращения коллапса, но из-за бездействия диспетчеров ситуация развилась в каскадную аварию, остановить которую было уже нереально. При этом причиной «веерного отключения» стала череда из множества совершенно неожиданных отказов. Фактически только отсутствие оперативного диспетчерского управления и сделало блэкаут неизбежным, хотя если бы линии ЛЭП оператор FE вовремя очищал от деревьев, то может ничего вообще бы и не случилось. После аварии было проведено расследование, которое выявило все описанные и многие другие проблемы. Среди предложений мер реакции были, как организационные меры, в частности пересмотры внутренних регламентов и аудиты, так и технические меры: совершенствование систем SCADA, более жесткие требования к контролю состояния линий, установка автоматик отключения нагрузки при снижении напряжения и так далее. Более крупных блэкаутов в США не было, но как и в любой сложной системе, сколько бы дыр в ней не закрывали, всегда может найтись новая.
- NERC «Technical Analysis of the August 14, 2003, Blackout: What Happened, Why, and What Did We Learn?»
- U.S.-Canada Power System Outage Task Force «Final Report on the August 14, 2003 Blackout in the United States and Canada: Causes and Recommendations»
- The Availability Digest «The Great 2003 Northeast Blackout and the $6 Billion Software Bug»

Комментарии (62)

Sun-ami
30.07.2022 15:55+4Думаю, главной причиной аварии было то, что в ответ на звонки о проблемах диспетчер предпочел "клятвенно уверять, что у них всё в порядке" вместо того, чтобы проверить всю доступную ему в SCADA информацию.

vassabi
30.07.2022 16:26+17вот скажите - когда вам grep пишет, что в файле логов ничего не нашел - вы ему доверяете, или после него идете и глазами еще раз просматриваете весь лог?
Вы себе представляете - где сидит диспетчер, а где реальные провода на сотни км ? Или вы думаете, что он программист а не электрик и может легко посмотреть "всю доступную ему в SCADA информацию" (и для начала - найти ее и перевести в человекочитаемый формат...) ?
DrPass
30.07.2022 18:01+6вот скажите — когда вам grep пишет, что в файле логов ничего не нашел — вы ему доверяете,
да, до момента, когда мне позвонят несколько юзеров и скажут, что что-то упало. Тогда я всё-таки перепроверю :)
Диспетчер не может легко посмотреть всю доступную ему информацию, но он в общем-то в состоянии позвонить на подстанцию и спросить, что у них там происходит.

Tangeman
30.07.2022 18:10+30Когда меня первый раз спрашивают — я доверяю grep.
Когда второй — я проверяю не ошибся ли я с grep (бывает), и на всякий случай проверю изменялся ли лог вообще в последнее время, т.е. есть ли там хоть что-нибудь.
Когда третий (за последние полчаса) — я уже разбираю всю цепочку по винтику и вручную проверяю все компоненты, работают ли они вообще. Да, бесит, но зато надёжно.
Такой подход не раз спасал ситуацию когда казалось бы всё совершенно нормально и проблема явно где-то ещё. Да, иногда действительно проблема оказывается где-то ещё — но лучше перебдеть, это займёт всего несколько минут но они могут спасти от многочасового аврала.
Если бы диспетчер руководствовался похожим принципом, то на третий вопрос он бы уже позвонил в техотдел и спросил всё ли работает как должно, а судя по рассказу он получил кучу вопросов, сам факт их возникновения за короткий временной интервал уже должен был его насторожить.
PS: В далекой молодости (ещё при союзе) я проходил практику в чём-то типа центра управления энергосистемой крупного города, и там было похожее правило — на третий звонок, неважно что показывают лампочки на пульте и даже если они все зелёные — давай проверяй ручками или ножками, звони на участки и вообще поднимай кипеш до выяснения ситуации.

stalinets
30.07.2022 22:51+3Кстати, это открывает вектор атаки на систему через социальную инженерию. Пранкеры звонят сразу с сотен номеров на кучу подстанций и жалуются, что пропал свет. И на более крупные узлы мониторинга тоже. И начинается неслабый кипиш, техники начинают перезагружать сервера, звонить друг другу ещё больше усиловая хаос, и в итоге кто-то что-то реально ломает. А так, если система отлажена нормально, оператор посмотрит, что всё ОК, поймёт, что его разыгрывают, и пошлёт звонящих лесом.

sanalex76
01.08.2022 00:46+1Юзеры звонят своему поставщику энергии, а не на подстанцию. А поставщик энергии уже может перепроверить и позвонить на подстанцию, если нужно. Так что фильтр сработает, заддосить не получится.

LeToan
30.07.2022 19:34+7Диспетчеру было достаточно посмотреть состояние линии, статья утверждает, что это было легко доступно, но обычно делается при появлении аварийного сообщения. Что мешало посмотреть при многочисленных звонках, на которые отвечали клятвенными заверениями?

funca
30.07.2022 19:52+4Один из основных принципов расследования инцидентов состоит в том, что у него всегда больше одной причины. Даже если там был человеческий фактор, то он был не единственный.
Диспетчерская это не один человек (и в статье пару раз упоминают во множественном числе). То есть, были причины из-за которых продолбали все, кто был на дежурстве.
LeToan
30.07.2022 21:15+4Это ж не ответ. Просто перекладывание ответственности на всю смену. Диспетчеры отвечая не знали состояние сети, они могли уверенно сказать, что не было аварийных сообщений, а не то, что всё в норме. Почему никто из целой смены не посмотрел?
funca
30.07.2022 21:40+2Я просто хотел сказать, что причин было больше. Свалить все на одного диспетчера (или смену) это просто, но по факту не практично, так как даёт лишь временный эффект, как латание дыр. Заменят одних другими и потом снова все повторится.
Цель таких расследований не в том, чтобы указать на виноватого, а чтобы найти и потом усилить все узкие места в системе. Инструкции по расследованиям предлагают сразу отбрасывать причину, которая кажется всем очевидной, и начинать копать дальше.
В статье это хорошо показано - они обнаружили там кучу интересных и по-отдельности не очевидных проблем в разных местах. Начиная с банально за годы разросшейся флоры, больших организационных проблем и заканчивая гонками где-то в софте на микросекунды.
LeToan
30.07.2022 22:08Я что, предлагаю свалить только на диспетчеров? Вина остальных в статье раскрывается. Тут даже копать не надо, техподдержка скады, не проверившая работоспособность, диспетчер MISO забывший запустить скрипт, кто-то, ответственный за неполноту данных в MISO (когда там целая линия исчезла из модели). Если б они не лажали, то все другие недостатки были бы не критичны.

onyxmaster
31.07.2022 10:35+2Вы предлагаете искать виноватых, а не причины. Это неконструктивно при работе на перспективу.
LeToan
31.07.2022 11:37А в этом расследовании определены причины лажи этих субъектов? Вижу только дополнительные факторы, которые всегда есть, но которые не критичны, если все хорошо выполняют свою работу.
onyxmaster
31.07.2022 14:17+1Вам надо чтобы все хорошо выполняли работу и наказывать тех кто плохо это делает, или чтобы аварий не было?
Sun-ami
31.07.2022 15:31+2С grep я не работаю. Когда система мониторинга диспетчерской связи метро определяет по логам, что всё нормально, а мне звонит механик связи, что не прошел вызов или нет голоса - я сразу вручную смотрю логи соединения DSS1.
По тексту статьи, у диспетчера была возможность просто увеличить нужный фрагмент схемы, чтобы увидеть, что линия отключена. Он должен был сделать это после первого же звонка. После второго звонка он, кроме того, должен был позвонить на подстанции, чтобы проверить правильность работы SCADA, и посмотреть в SCADA нагрузку на дублирующих линиях. Я одно время совмещал обслуживание SCADA энергосистемы предприятия с работой оператора SCADA и некоторыми функциями диспетчера, и поступал именно так. После третьего звонка диспетчер должен был позвонить в техподдержку.

geher
30.07.2022 16:51+4Тут свою роль сыграло доверие диспетчера к оповещениям в его системе. Оповещений нет - значит, все нормально.
Вот если бы такого абсолютного доверия не было, то был бы и шанс на обнаружение проблемы. Конечно, диспетчер бы не сорвался и не поехал смотреть линию (хотя у него вроде должен быть вариант по телефону послать разбираться на месте дежурную бригаду). Он просто поглядел бы на конкретное место на карте, увеличив масштаб.
vassabi
30.07.2022 17:24+1Тут свою роль сыграло доверие диспетчера к оповещениям в его системе. Оповещений нет - значит, все нормально.
чтож, вот поэтому в систему аварийного оповещения здорового человека ставят две лампочки:
первая - красная, для оповещений, а вторая - зеленая, чтобы видеть что первая лампочка таки сработает, когда надо (а не "замерла в состоянии не горит").

mayorovp
30.07.2022 18:48+1Вот у них весь экран и был в зелёных лампочках, а что толку? Информации просто слишком много, волей-неволей приходится на систему оповещений смотреть.
funca
30.07.2022 19:28+4В SRE для мониторинга есть 4 золотых сигнала: latency, traffic, errors и saturation. Здесь контроль трафика и насыщенния по нижнему пределу должны по идее выявлять ситуации, когда от системы перестают приходить метрики вообще. Проще говоря, кроме grep, нужен ещё wc -l

defiaNtBY
01.08.2022 09:47ну очевидно жеж что SRE появилось после этого блэкаута. Т.е. лбди уже знали про эти ошибки когда составляли его.
блекаутже в 2003 был, когда и SRE появилось.
много того чтотмы сейчас делаем для доп проверок, как раз добавилось после случаев когда эти проверки не сделали - RCA во плоти.
Sun-ami
31.07.2022 16:19Доверие людей к технике должно быть основано на сертификации по безопасности, а не на опыте безаварийной работы техники. Думаю, в этом случае генератор оповещений не мог быть сертифицирован для обеспечения безопасности энергосистемы - ведь он даже никак не индицировал свой отказ.


DaneSoul
30.07.2022 17:53Начало аварии положило незначительное на первый взгляд происшествие: в 13:30 остановился блок №5 ТЭЦ Eastlake мощностью 680 МВт.
ИМХО, в подобный ситуациях в протоколе действий электростанции должно быть дополнительное информирование центрального диспечерского центра энергосистемы по телефону. Тогда диспечер был бы в состоянии повышенного внимания и увидел бы, что в логе у него нет этого события и начал бы предпринимать какие-то действия.
Woolfen
30.07.2022 23:06Так это случилось до файла скады. Собсно накинуть возбуждения для поднятия напряжения попросил сам диспетчер FE. Когда генератор отключился он не стал вводить еомпенсиркющих мер, так как посчитал некритичным.

OlegZH
30.07.2022 18:59+2В идеальном мире для этого использовалась бы real-time система, как SCADA, но MISO развивало свой собственный продукт, в основном методом добавления костылей. Система в распоряжении MISO была не real-time, да она получала данные с низовых устройств, но расчёт надёжности проводился по таймеру раз в 5 минут, таким образом оператор имел срез состояния энергосистемы, который мог за следующий промежуток времени сильно устареть. Автоматический расчёт надёжности проводился по скрипту, который днём в 13:07 был отключён для проведения работ с системой. Причиной стала необходимость привязать сигналы включенного/отключенного состояния линии 230 кВ Bloomington-Denois Creek к её отображению в расчётной модели. После окончания процесса диспетчер попросту забыл активировать скрипт и ушёл на ланч, из-за чего до 14:40 автоматический расчёт надёжности не производился.
Паразительно читать такое!
То, есть можно для критически важной отрасли разрабатывать свой собственный продукт (его кто-нибудь сертифицировал?), не real-time, и где можно что-то отключить и "забыть включить" обратно! И никаких протоколов на случай технических работ!
А во-вторых, пользовательский интерфейс был таков, что диспетчеру после получения оповещения требовалось найти на схеме нужный выключатель и уже, кликнув по нему, проверить его состояние. Система не подсвечивала выключатели, изменившие состояние, и не имела функции перехода к объекту по щелчку на уведомление.
С этого же нужно начинать разработку, с вопроса: а как должен выглядеть пользовательский интерфейс? Сделанные ошибки выглядят просто детскими. Но они оказались фатальными!
Более крупных блэкаутов в США не было, но как и в любой сложной системе, сколько бы дыр в ней не закрывали, всегда может найтись новая.
А как быть имитационным моделированием? С поиском оптимальных систем управления? И что было, если бы было бы несколько независимых энергетических сетей?
funca
30.07.2022 19:38+15В этом и суть нормального incident management: выявить проблемы, определить пути для их устранения, чтобы больше не повторялось. Это интересная область, где работают классные инженеры.
Отечественные подходы, продвинающие принципы негодования и устрашения, в этом смысле контрпродуктивны.

runapa
02.08.2022 09:00То, есть можно для критически важной отрасли разрабатывать свой собственный продукт (его кто-нибудь сертифицировал?), не real-time, и где можно что-то отключить и "забыть включить" обратно! И никаких протоколов на случай технических работ!
А было ли это так очевидно в 2003 году? Сейчас всем понятно, что компоненты электрической сети должны быть надёжно изолированы во избежание несчастных случаев, но в начале 20-го века этого практически не делали, хотя, казалось бы, очевиднейшая вещь.
funca
30.07.2022 19:17+14Расследование инцидентов это не поиск виноватых. Это крутая инженерная практика. Тот факт, что происшествие в сложной географически распределенной технической системе удалось описать языком, понятным для широкой публики, говорит о высоком уровне проведенной работы.
В АйТи часто бывает так, что ни система ни персонал не способны решать проблемы, когда от инцидента до катастрофы в распоряжении всего час.

Pavel1114
31.07.2022 06:31+1Работал с подобной scada системой на крупной ТЭС машинистом энергоблока. БЩУ (блочный щит управления) выглядел примерно как на картинке с множеством мониторов и панелей, только людей у нас поменьше. Одной из практик, уменьшающей вероятность того что машинист не заметит какие то критические изменения, это ведение бумажной ведомости основных показателей, которую необходимо заполнять вручную каждые 2 часа. Также регламентируется постоянная связь с людьми на местах, которые глазами видят оборудование. Но конечно всё это не 100 процентная гарантия, да и легко обходится — ведомости заполняются методом копирования предыдущих записей, люди на местах тоже ненадёжны.


edo1h
31.07.2022 11:10приведя к отключению сотен линий электропередач и 508 энергоблоков на 265 электростанциях, из которых 10 – это АЭС(!)
а почему такое внимание к отключению энергоблоков на АЭС?

Kitsok
31.07.2022 11:19+1Потому что их потом долго включать. Потому что обесточенная АЭС - серьезная авария. Потому что работающий штатно блок АЭС - безопасно, а аварийно отключенный - опасно.
mayorovp
31.07.2022 11:21+3Потому что им три дня остывать перед повторным включением. Кроме того, остывающему реактору требуется питание для охлаждения, а внешнее питание-то пропало. Если бы ещё и у них оказался бардак и, к примеру, не запустились дизели...
Sun-ami
31.07.2022 16:13Если рассматривать причины этого инцидента с технической стороны, то тут можно выделить отсутствие системы предупреждения о возможности касания проводов ветвей деревьев, и системы, предотвращающей саму возможность лавинообразного отключения ЛЭП по перегрузке при потере существенного количества нагруженных ЛЭП.
Думаю, приближение касания проводов ветвей деревьев можно распознать по характеру увеличения утечки через коронный разряд. Это должно позволить увидеть вероятность такого отключения сильно заранее, и выслать бригаду для рубки или обрезки деревьев.
Система, предотвращающая возможность лавинообразного отключения ЛЭП должна действовать в ситуации, когда человек уже не успевает среагировать, отключая часть потребителей, чтобы избежать отключения магистральных ЛЭП по перегрузке (надеюсь, не все они отключились от касания деревьев на мощности сильно ниже максимальной). Странно, что в США в то время не было такой системы. Интересно, есть ли сейчас?
mayorovp
31.07.2022 18:16Если рассматривать причины этого инцидента с технической стороны, то тут можно выделить отсутствие системы предупреждения о возможности касания проводов ветвей деревьев
Такой системе нужны актуальные данные о растущих рядом с ЛЭП деревьях — а в обсуждаемой истории даже с подключенных к SCADA устройств — и с тех актуальные данные снять не всегда могли.
Думаю, приближение касания проводов ветвей деревьев можно распознать по характеру увеличения утечки через коронный разряд. Это должно позволить увидеть вероятность такого отключения сильно заранее, и выслать бригаду для рубки или обрезки деревьев.
Такая система, скорее всего, обнаружила бы приближение за час-два до блэкаута. Бригада для обрезки деревьев так быстро работать не может. А ещё им могло понадобиться отключение линии на время работы, что лишь спровоцировало бы блэкаут ещё раньше.

Tarakanator
01.08.2022 10:06+1Такая система, скорее всего, обнаружила бы приближение за час-два до блэкаута.
Такая система скорее всего обнаружила бы приближение ещё в предыдущие циклы провисания. Если только это провисание было не аномально сильным.
mayorovp
01.08.2022 10:51Разумеется, оно было аномально сильным, в том-то и проблема! Провисание зависит от температуры, температура зависит от протекающего тока.
Tarakanator
01.08.2022 11:12Т.е. вы уверены в том, что РАНЕЕ НЕБЫЛО ПИКОВ провисания не сильно слабее? Я вот не уверен

Bedal
01.08.2022 12:21Энергосистема выстраивается по следующему принципу: есть ЛЭП высокого напряжения, которые осуществляют транзит больших мощностей на большие расстояния, есть линии меньшего напряжения, которые дублируют их и распределяют энергию между более мелкими узлами потребления, и есть линии низкого напряжения в распределительной сети, к которой подключают потребителей.
Это описание энергосистем типа ГОЭЛРО. Американские энергосистемы устроены не совсем так (и даже совсем не так).Худший случай – это перехлёст двух или трёх проводов, что вызовет междуфазное короткое замыкание.
это, конечно, неприятность — но далеко не худший случай. Даже можно сказать, бытовая подробность в работе сети. Бывает не так уж редко, парируется релейными защитами и повторным пуском.edo1h
01.08.2022 12:32Это описание энергосистем типа ГОЭЛРО. Американские энергосистемы устроены не совсем так (и даже совсем не так).
не разовьёте тему?
Bedal
01.08.2022 13:32+1Ну, вот это «есть высоковольтный хребет, куда отдают мощность крупные электростанции, а потом от него с постепенным снижением класса напряжения энергия раздаётся» — как раз ГОЭЛРО и как раз так устроена единая энергосистема России (на самом деле есть и автономно работающие сети Дальнего Востока, Магадана, Сахалина — но и они «внутри» устроены так же).
В США производство и потребление электроэнергии росло от компаний. Есть компания, она владеет электростанцией, раздаёт энергию потребителям. Выросла, пристроила себе ещё электростанцию, больше охват потребителей… Выросши, энергокомпании обзавелись некоторым количеством ЛЭП, соединяющих их с соседними зонами. Цельной сети ЛЭП высоких напряжений нет.
Зато есть ЛЭП высоких и сверхвысоких напряжений и даже на постоянном токе для далёких станций. Скажем, у какой-то энергокомпании потребление растёт, а новые генерирующие мощности ставить негде, да и топливо возить неудобно. Строится электростанция где-то за пределами своей зоны, там, где удобнее логистика энергоресурса (это не обязательно уголь или газ). И от этой станции к себе, в свою зону, тянется та самая мощная ЛЭП. Не в общую сеть снабжения страны, а к себе.
Для компании (или группы компаний) практически нет «общего режима страны». Есть режим своей системы и сальдо-переток обмена с соседними системами с учётом частоты. Где и сколько через границу отдавать, где получать — определяется, ессно, договорами. Все отклонения от этого, «ошибка управления зоной», Area Control Error, ACE. Диспетчер, заступая на смену, в первую очередь загоняет АСЕ в ноль, и только после этого занимается всякими событиями внутри своей системы.
Чтобы всё это вместе работало, компании собираются в группы и назначают «регионального координатора надёжности», как та же MISO. Общий на всю страну координатор — NERC. Но указания координаторов не обязательны к исполнению.
Необходимо учесть, что, какое бы мнение первично не создалось при прочтении, на самом деле это не означает «плохо» или «хорошо». Просто особенность. Скажем, по числу и масштабности аварий у нас с америкой примерный паритет (учитывая, что мощности у них во многие разы больше).
Европейские сети тоже устроены по-своему, в Индии — по-своему (там совсем недавно вообще без координаторов обходились), и так далее.Woolfen
01.08.2022 15:34+1Так если сейчас этот хребет из высоуовольтных лэп есть, то в чем проблема? То что генезис систем разный ок, но в итоге от все равно пришли к схожему построению сети. И межсистемные перевозки насколько я понимаю идут в основном именно через высокрвольтные линии, так что и роль в энергосистеме у них одинаковая
Bedal
01.08.2022 15:52если есть — хорошо. Но — есть не везде. Поверьте, межсистемные связи в американской сети — это не хребет. Как по топологии, так и по характеру использования.
Поймите, в ГОЭЛРО электростанции обязаны отдавать энергию в «хребет». В американской реальности — они должны обеспечивать тот регион, к которому привязаны. В наших аналогиях — они почти все в ТГК, и крупные тоже.
Это играет свою роль.Woolfen
01.08.2022 16:15+1Так, падажжите. При чем тут это вообще? Речь про то, что чем выше напряжение лэп - тем больше у нее пропускная способность и тем важнее ее роль в энергосистеме. Я понимаю, что в США баланс в значительной мере смещён в сторону низкого напряжения, но блин, все аварии в сша про которые я читал были связаны именно с потерей лэп высокого напряжения по которым шёл транзит мощности. Т.е. вот на вскидку что помню. НЙ 1977, отказ 4 лэп 345кВ по которым энергосистема города получала 3ГВт мощности. И как бы если это не "хребет", то я хз
Bedal
01.08.2022 17:00«Хребет» — это когда высоковольтные ЛЭП объединены в систему. В США они часто одиноки, с одного конца станция, с другого — потребление.
Если продолжать скелетные ассоциации: одно дело — позвоночник, а другое — берцовые кости. Даже мощные — они всё же не позвоночник.
Bedal
01.08.2022 12:31остановился блок №5 ТЭЦ Eastlake мощностью 680 МВт.
Ну да, вот уж мелочь… Вы вообще представляете что-то в области, про которую пишете? Там нет ГОЭЛРО, и потеря полугига для ЭС весьма критична.Причина аварии крылась в неправильных действиях персонала, приведших к выходу из строя регулятора возбуждения турбины.
Ах, регулятор возбуждения турбины? Всё ясно.Решением проблемы могло бы быть использование видеостены с большой мнемосхемой
Вот нифига. Это традиционное — и устаревшее решение. оно мало помогает. Хотя, конечно, щит какой-нибудь CAISO в размере стадиона, поставленного вертикально, впечатляет на бытовом уровне.Можете убедиться, на щит никто не смотрит, толку мало
Ну и да, для энергокомпаний в штатах указания MISO и даже NERC не являются обязательными, это не российская ЕЭС. Упомянутые координаторы надёжности выдают не приказы, а рекомендации — за неисполнение которых могут как-то наказать позже при обновлении лицензии на работу.
Дополню тем, что американский диспетчер крайне ограничен в наборе воздействий. Отключить «по списку» он практически никого и никогда не может. В своё время, в 2005 году, московское обесточивание произошло по очень похожей схеме, потому что в то время диспетчеры были почти в том же, «американском», положении.


hecatonchires
01.08.2022 13:04Получается противоаварийной автоматики в нашем понимании у них вообще нет?
Хорошо, что хотя бы КЗ отключает не диспетчер по сигналу из АСУ "ток выше уставки".
Bedal
01.08.2022 13:36да, противоаварийной автоматики у нас намного, намного больше, чем у них. Но есть.
КЗ отключается автоматически, но включения (АПВ) не обязательно автоматичны. Скажем, в Калифорнии обнаружили, что значительная доля степных пожаров возникает от пробоев на землю при АПВ. Потому там есть отдельны оператор, контролирующий спутниковые снимки (обновляемые каждые полтора часа, пролётом спутника) на цвет степи. Зелёный — АПВ в положении «разрешено». Жёлтый — АПВ запрещено, только вручную, только под контролем.hecatonchires
01.08.2022 16:42У нас в середине века диспетчера сидели перед амперметром и отключали линию при превышении. Ничего, когда-нибудь они и АЧР изобретут.
А почему при АПВ, а не при первом КЗ? Может наоборот, при пожарах выше вероятность неуспешного АПВ из-за ионизации воздуха над огнем?Bedal
01.08.2022 17:03когда-нибудь они и АЧР изобретут.
Наоборот, когда-нибудь и у нас оно исчезнет. У нас тоже число потребителей, которых можно «рубануть», всё время сокращается.А почему при АПВ, а не при первом КЗ?
«Мопед не мой». Что мне в PGnE рассказывали — то и написал.hecatonchires
01.08.2022 18:39+1Ну а какие варианты? Если, как в большинстве случаев, ввести резерв генерации невозможно, остается только кого-то отключить.
Лучше кого-то, чем всех)Bedal
02.08.2022 07:57+1А вот и нет :-)
Лет семь назад, вполне в России.По памяти, и место называть не буду:
Компания подаёт в суд на энергетиков за отключение. Родная энергетическая контора, ессно,подставляетвыставляет диспетчера. Примерно такой диалог:
— Зачем Вы нас отключили?
— Ситуация была предаварийная, перегружено сечение, температура трансформатора…
— Вы хотите сказать, что была авария?
— Нет. (гордо) Я её предотвратил!
— Значит, аварии не было.
— Да, благодаря моей и коллег квалифицированной работе.
— Прошу зафиксировать, аварии не было. Итак, зачем Вы нас отключили?
Можете себе представить, как выглядит подобное там, где всякие там негосударственные компании имеют всякие там права.
Варианты, по рассказам знакомых американских диспетчеров, просты: играть генерацией, ждать, когда всё ляжет — этот форс-мажор исключает иски. И тогда уже быстро поднимать сеть.
Практически все тренировки персонала, какие я видел / для которых готовил модель / прорабатывал сценарии, начинаются одинаково: погасло всё.hecatonchires
02.08.2022 09:24Мне кажется наша энергетика сейчас уже не в эту сторону двигается. Активно развивается НТД, новые полномочия СО ЕЭС - курс скорее на усиление регулирования. Действия автоматики или диспетчеров должны соответствовать НТД, а пострадавшим можно и компенсацию выплатить.
Если за системную аварию тоже платить компенсации всем пострадавшим - сразу мотивация предотвращать появится.

amberovsky
01.08.2022 13:14Какой штатный алгоритм действий в таких ситуациях? Ручное перенаправление потоков по менее загруженным сетям (если так, то почему нельзя автоматически так делать?) и/или отключение наименее критических потребителей?
Bedal
01.08.2022 13:39+2Штатный алгоритм — разный в разных местах. Самое лучшее для энергосистемы — это отрубить потребителей в сумме потерянной генерации :-)
А дальше всё зависит от того, сколько каких потребителей разрешено отключать. Бывает, что и нисколько не разрешено.
Второе решение, увеличивать генерацию, конечно, тоже применяется — но оно хуже, так как создаёт те самые перекосы, что описаны в посте.
Третье решение — пройтись по списку ведущихся ремонтов и оставшемуся времени до ввода в работу и попробовать срочно задействовать это оборудование.amberovsky
02.08.2022 00:47Самое лучшее для энергосистемы — это отрубить потребителей в сумме потерянной генерации
Это происходит на стороне потребителя?
Bedal
02.08.2022 08:03+1В смысле — глубокосознательный потребитель сам себе
отрезает яотключает электричество? Нет :-)
Есть подробно проработанные списки потребителей, по категориям. Этих совсем нельзя отключать, этих только вручную после предупреждения, этих можно завести под автоматику, так что отключение произойдёт неожиданно и, возможно, вскоре так же неожиданно будет восстановление питания (АЧР/ЧАПВ) и т.п.
Komrus
02.08.2022 09:42Это привязано к первой/второй/третьей категории энергоснабжения?
Или какими-то другими терминами описывается?
vlad49
Во времена фидо ходила устойчивая байка, как энергетикам было лень ездить в другой район перезагружать часто виснущий сервер, и они делали это обесточиванием половины города.
Gregalex84
У меня был похожий случай. Как-то раз, 31 декабря, в 10 часов вечера - то есть за 2 часа до Нового года у нас моргнул свет и вырубился интернет. Я дозвонился до техподдержки, и сотрудник подтвердил, что наш подъездный роутер завис. "Но вы же понимаете, что сейчас никто не пойдёт его перезагружать?" Я вздохнул, сказал, что всё понимаю и пожелал счастливого Нового года. Через полчаса на пять минут вырубился свет. После включения - интернет заработал. До сих пор думаю - совпадение, или сотрудник провайдера как-то договорился с электриками?