Не так давно мы решили добавить в нашу Kubernetes-платформу Deckhouse поддержку Cilium. Однако в процессе разработки модуля cni-cilium неожиданно столкнулись со сложностями, для преодоления которых пришлось даже обращаться к авторам проекта. Теперь, когда модуль успешно доведен до рабочего состояния, можно перевести дух и поделиться ощущениями от полученного опыта и использования этого продукта в целом.

Предисловие
Cilium — это Open Source-проект, который обеспечивает сетевое взаимодействие, безопасность и доступность для облачных сред, таких как Kubernetes и другие платформы для оркестрации контейнеров. В основе Cilium лежит технология ядра Linux под названием eBPF, которая позволяет динамично внедрять мощную логику безопасности, видимости и сетевого управления в ядро этой ОС.
Идея Deckhouse заключается в том, чтобы предложить пользователю готовый к работе Kubernetes с минимальными трудозатратами и максимальной автоматизацией. Ранее для реализации сети в кластере мы использовали два модуля: flannel и simple-bridge. Однако у них есть существенные ограничения, такие как работа за счет iptables (медленно) и отсутствие возможности настроить политики между узлами кластера (доступно только между Pod’ами и сервисами). Поддержка Cilium была призвана избавить от этих ограничений. (Сама поддержка появилась в релизе Deckhouse v1.33, о чём мы недавно рассказывали.)
Cilium дает три основных преимущества: скорость (за счёт eBPF), наблюдаемость (за счёт Hubble) и безопасность (Network Policies). В каждой из этих технологий мы столкнулись с задачами, требующими приложения дополнительных усилий для достижения желаемого результата. Рассмотрим их подробнее, но сначала — небольшое отступление, что такое eBPF и как он работает.
Экскурс в eBPF и его связь с Cilium
eBPF — это технология, основанная на ядре Linux, которая позволяет запускать изолированные приложения в ядре операционной системы. Она используется для безопасного и эффективного расширения возможностей ядра без необходимости изменения его исходного кода или загрузки модулей. Разработчики приложений могут использовать программы eBPF для включения дополнительных возможностей в ОС во время выполнения. При этом операционная система гарантирует безопасность и эффективность их работы, как если бы она была изначально скомпилирована с помощью JIT-компилятора и механизма проверки.
Cilium активно использует эту технологию при разработке новых способов работы с сетью. Привычные инструменты, такие как iptables/netfilter, имеют за плечами долгий путь развития длиной в 25 лет, приведший их к некоторой законченной форме, которая, кажется, уже не требует доработок и усовершенствований. Они используются абсолютно везде, начиная от домашних легендарных роутеров D-Link DIR-300 и заканчивая миллионом кластеров Kubernetes с kube-proxy (iptables-бэкенд). При этом в некоторых случаях можно смело утверждать, что они неэффективны, и можно было бы сделать… по-другому.
Используя Cilium, вы завязываетесь на то, чему не 25 лет. Проект постоянно развивается и прогрессирует не только в разработке своих eBPF-программ и их LLVM-компиляторе, но и в сетевой и eBPF-части ядра Linux. Это один из аргументов в пользу того, чтобы попробовать разобраться с этой технологией и внедрить ее в свой кластер.
Для более глубокого погружения в тему советую прочитать эту статью. В ней раскрываются тонкости жизни сетевого пакета в Cilium, определение пути трафика Pod-to-Service и логики обработки BPF.
А теперь — к приключениям, с которыми нам пришлось столкнуться.
Приключения начинаются: забывчивый conntrack
Conntrack — это механизм отслеживания состояния, являющийся важной частью любого сетевого фильтра. В Cilium-агенте он похож на аналогичный в любом stateful firewall’е — например, на conntrack в netfilter. Он позволяет установить принадлежность пакетов к одному flow, что дает возможность применять дополнительную CPU-интенсивную обработку (политики, решения о NAT) только к первому пакету.
Мы столкнулись со странным поведением: таблица conntrack в map’е eBPF обнулялась при каждом рестарте Cilium-агента. Так как после этого conntrack больше ничего не знал про пакеты, которыми уже обмениваются клиент и сервер, то в соответствии с whitelist-политикой отбрасывал все пакеты, отправляемые сервером обратно клиенту.
Пример разбора одного пакета (появляется в cilium monitor -D -vv после включения опции debug-verbose: datapath):
Ethernet {Contents=[..14..] Payload=[..118..] SrcMAC=00:00:5e:00:01:00 DstMAC=d0:0d:ba:34:90:bc EthernetType=IPv4 Length=0}
IPv4 {Contents=[..20..] Payload=[..98..] Version=4 IHL=5 TOS=0 Length=2519 Id=54017 Flags=DF FragOffset=0 TTL=63 Protocol=TCP Checksum=18846 SrcIP=10.160.128.31 DstIP=10.160.128.34 Options=[] Padding=[]}
TCP {Contents=[..32..] Payload=[..66..] SrcPort=2379(etcd-client) DstPort=24824 Seq=2205186449 Ack=1078895699 DataOffset=8 FIN=false SYN=false RST=false PSH=true ACK=true URG=false ECE=false CWR=false NS=false Window=368 Checksum=8011
Urgent=0 Options=[TCPOption(NOP:), TCPOption(NOP:), TCPOption(Timestamps:388221802/215800007 0x1723cb6a0cdcd8c7)] Padding=[]}
Packet has been truncated
Failed to decode layer: No decoder for layer type Payload
CPU 01: MARK 0x0 FROM 137 from-network: 2533 bytes (128 captured), state new, interface eth0, orig-ip 0.0.0.0
CPU 01: MARK 0x0 FROM 137 DEBUG: Successfully mapped addr=10.160.128.31 to identity=7
CPU 01: MARK 0x0 FROM 137 DEBUG: Successfully mapped addr=10.160.128.34 to identity=1
CPU 01: MARK 0x0 FROM 137 DEBUG: Conntrack lookup 1/2: src=10.160.128.31:2379 dst=10.160.128.34:24824
CPU 01: MARK 0x0 FROM 137 DEBUG: Conntrack lookup 2/2: nexthdr=6 flags=0
CPU 01: MARK 0x0 FROM 137 DEBUG: CT verdict: New, revnat=0
CPU 01: MARK 0x0 FROM 137 DEBUG: Successfully mapped addr=10.160.128.31 to identity=7
CPU 01: MARK 0x0 FROM 137 DEBUG: Policy evaluation would deny packet from 7 to 1Из лога видно, что etcd отправляет TCP ACK в сторону эфемерного порта kube-apiserver. Conntrack-таблица пуста, поэтому eBPF-программа пытается создать в ней новую запись. Модуль политик при этом видит новое подключение со стороны etcd, что не разрешено политиками. И не может быть разрешено, потому что порт со стороны apiserver эфемерен (kube-apiserver инициирует TCP-подключение к etcd).
Нами был инициирован разбор этой проблемы в issue на GitHub, который в конечном счете привел к необходимому исправлению. Взаимодействие с разработчиками напрямую в Slack проекта Cilium значительно ускорило этот процесс и оставило крайне положительные впечатления от работы с сообществом:
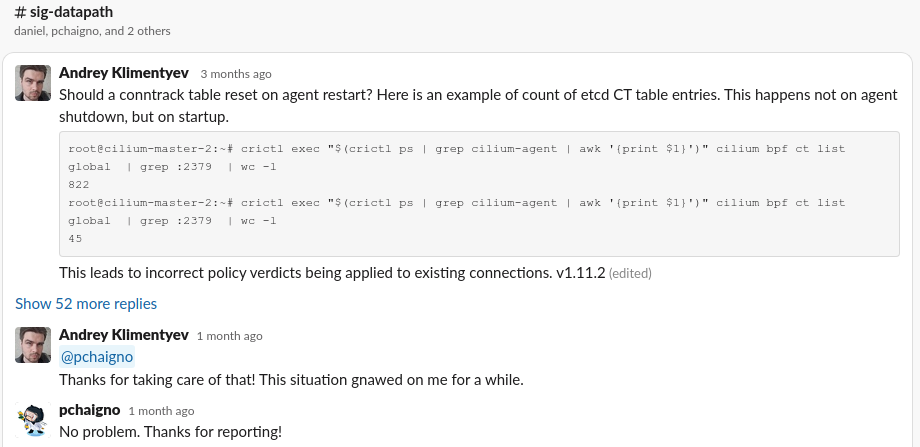
Но на этом наши вызовы при внедрении Cilium не закончились…
Сетевые политики, которые сложно победить
Cilium предоставляет довольно гибкие политики безопасности для сети — например:
возможность поиска соответствий по L3/L4 (даже L7), а также по
entity ID(Cilium позволяет уникально идентифицировать субъекты обмена трафиком);политики не только для трафика между Pod’ами, но и для всего трафика, который присутствует на хосте, будь то трафик до Pod’ов
hostNetworkили системных демонов, запущенных через systemd.
Но, несмотря на это, они иногда создают проблемы, когда вступают в конфликт с особенностями конкретных реализаций объектов Kubernetes.
Вот и мы столкнулись с подобной проблемой: Cilium не позволяет разрешить трафик к healthCheckNodePorts, который генерируется исключительно для сервисов type: LoadBalancer. Это вынудило нас предоставлять эти порты вручную и так же добавлять их в CiliumClusterwideNetworkPolicies.
DSR или сохранение клиентского IP-адреса
DSR (Direct Server Return) — крутая штука при использовании externalTrafficPolicy: Cluster, так как позволяет сохранить клиентский IP-адрес, а также предотвратить лишний hop на обратном пути пакета. Включается она через параметр --set loadBalancer.mode=dsr.
На рисунках далее представлены схемы работы с DSR и без него:


Несмотря на предоставляемые ей плюсы, мы столкнулись и с несколькими минусами:
При использовании DSR перестаёт работать
nodePort-трафик в сторону Pod’ов. Проблема уже известна и описана в соответствующем PR’е.DSR совсем не работает для
hostNetwork-Pod’ов. Эта проблема также уже известна.
Первый случай мы исправили включением указанного PR’а в поставку Сilium в Deckhouse, а вторая не имеет простого решения, т.к. требует значительной доработки eBPF-программы bpf_host.c.
Поэтому на текущий момент hostNetwork-Pod’ы в Deckhouse будут работать с DSR только при использовании externalTrafficPolicy: Local.
Производительность Hubble
Hubble — инструмент, обеспечивающий наблюдаемость (observability) ваших сервисов. Он позволяет полностью прозрачно отслеживать их взаимодействие и поведение, а также мониторить сетевую инфраструктуру. Hubble предоставляет видимость на уровне узла, кластера или даже между кластерами в мультикластерном сценарии (cluster mesh). Подробнее о его возможностях и взаимодействии с Cilium можно прочитать в официальной документации.
Помимо Hubble Relay, позволяющего агрегировать, и Hubble UI, позволяющего красиво отобразить пакеты и решения политик по ним, Hubble также содержится в каждом cilium-agent. Именно он экспортирует информацию обо всех пакетах по отдельности для дальнейшей обработки и визуализации.
В одном кластере, где был запущен Istio и количество пакетов и одновременных TCP-соединений зашкаливало, мы столкнулись с сильно завышенным потреблением CPU cilium-agent’ом. (Хотя документация обещает накладные расходы в объеме не более 1–15%.)
На графике показано влияние отключения Hubble в cilium-agent’е в этом кластере из ~30 узлов:

Мы не стали активно заниматься этой проблемой, посчитав на данном этапе достаточным дать настройку, позволяющую отключить Hubble в cilium-agent.
Барахлящий мониторинг
При первичном размещении было выбрано несколько ключевых метрик, по которым предполагалось судить о состоянии Cilium agent’а и делать алертинг. В один момент на нескольких кластерах загорелась метрика cilium_controllers_failing, а cilium status --verbose показывал наличие проблемы с обновлением eBPF-map’ы cilium_throttle. Логов не было. Понять что-то, используя CLI cilium, тоже не удалось.
При подробном разборе выяснилось, что ошибка, возникающая при удалении элементов eBPF-map’ы bandwidth controller’а, никак не обрабатывалась, а сообщение в лог не писалось. При этом метрика генерировалась и создавала смуту.
Мы предложили исправление в Cilium, и оно было принято с внесением в upstream.
Выводы
Стоит предостеречь новичков от бездумного использования Cilium на старте без достаточного опыта работы с Kubernetes, Linux и сетями. К сожалению, навыки работы с сетевыми подсистемами Linux помогут разобраться лишь с симптомами потенциальных проблем, но никак не помогут их решению. Если раньше можно было поправить правило в iptables, то теперь придётся дебажить eBPF-программы, прикреплённые к различным хукам в ядре (XDP, tc, cgroup), и разбирать, правильные ли значения помещает (или удаляет) в eBPF-map’ы cilium-agent, написанный на Go. Также не стоит забывать и про возможные баги в ядре и LLVM, о которых мы здесь не говорили, чтобы чрезмерно не нагнетать. Поэтому новичкам лучше все же остановиться на более простом способе реализации сети (Kube-router).
Хотя Cilium имеет довольно высокий порог вхождения, это мощный и однозначно полезный инструмент, который добавляет в управление кластером много полезных возможностей. Благодаря eBPF, используемому под капотом, доступны новые политики безопасности, подробный мониторинг сетевых взаимодействий между сервисами кластера, а также более быстрые способы маршрутизации пакетов. Все это делает Cilium очень интересным проектом, на который стоит обратить внимание.
При этом и в Cilium, и в eBPF встречаются нюансы, которые требуют глубокой диагностики и впоследствие доработок. Несмотря на возможные неудобства при внедрении этих технологий, мы в компании «Флант» верим в их будущее, и появление модуля Cilium в Deckhouse — логичный шаг навстречу этому будущему.
P.S.
Читайте также в нашем блоге:


identw
Спасибо за статью!
Я тоже с этим сталкивался. Но это еще было в версии 1.8, надеялся что исправили уже. Но я также заметил нюанс: что прям много CPU потребляется именно в туннельном режиме с включенным hubble. Если использовать native routing, то потребление CPU агентами падает (также с включенным hubble). Вы аналогичное наблюдали?
zuzzas Автор
Благодарю.
Ситуация была с native routing'ом. Хотел бы дать больше информации, но, к сожалению, не углублялись ещё в это.