Прим. перев.: автор данного исследования — Marc Richards, Solutions Architect и DevOps-инженер — продемонстрировал потрясающую настойчивость и тщательность в тотальной оптимизации производительности веб-приложения. Получившийся материал — кладезь полезных знаний для расширения своего кругозора в области оптимизации, особенностей сетевого стека в Linux и не только, даже вне зависимости от практической заинтересованности в конечном результате автора. Приготовьтесь к по-настоящему длинному техническому путешествию с обилием терминологии, увлекательных графиков и полезных ссылок.
В этой статье будут рассмотрены шаги, позволяющие увеличить производительность сервера до 1,2 млн JSON API-запросов в секунду на базе инстанса AWS EC2 с 4 vCPU. За рамками этого уникального квеста останется большинство спорных решений, которые мне довелось опробовать для получения нужного результата. Вместо этого мы пойдем преимущественно проторенной дорогой, неуклонно продвигаясь от 224 тыс. RPS на старте (конфигурация по умолчанию) до умопомрачительных 1,2 млн RPS на финише.

По правде говоря, превысить планку в 1 млн RPS не было изначальной целью. Все началось с написания одной статьи, совершенно не связанной с текущей темой. Именно она подстегнула мою одержимость всеобщей оптимизацией. Глобальная пандемия обеспечила некоторую передышку в работе, и я решил по-максимуму использовать свободное время. В таблице ниже перечислены девять рассматриваемых категорий оптимизации со ссылками на соответствующие Flame-графики. Отдельные столбцы показывают выигрыш от каждой оптимизации в процентах и совокупную пропускную способность в запросах в секунду. Это довольно убедительная иллюстрация того, насколько эффективно комбинирование различных подходов при работе над оптимизацией.
Оптимизация |
Flame-графики |
Прирост |
RPS |
Отправная точка |
- |
224k |
|
1. Оптимизация приложения |
55% |
347k |
|
2. Ограничение спекулятивного выполнения |
28% |
446k |
|
3. Аудит / блокировка системных вызовов |
11% |
495k |
|
4. Отключение iptables / netfilter |
22% |
603k |
|
5. Идеальная локальность |
38% |
834k |
|
6. Оптимизация обработки прерываний |
28% |
1.06M |
|
7. Любопытные соседи |
6% |
1.12M |
|
8. Борьба со спинлоками |
2% |
1.15M |
|
9. Всё близится к завершению |
4% |
1.20M |
Главная задача этой статьи — помочь вам в выборе и оценке инструментов и методов для профилирования/повышения производительность систем. При этом не стоит ожидать похожего увеличения производительности веб-приложения в 5 раз за счет бездумного изменения конфигураций. Многие из перечисленных оптимизаций принесут пользу только тем, кто уже превысил планку в 50 тыс. RPS. С другой стороны, применение методов профилирования к любому приложению позволяет разобраться в его поведении и выявить узкие места.
Была идея разбить статью на несколько частей, но она не прижилась из-за страха запутать все еще сильнее (кроме того, логично всю информацию держать в одном месте). Тем, кто желает углубиться и попробовать все самостоятельно, рекомендую воспользоваться шаблоном CloudFormation для настройки тестового окружения.
Базовая конфигурация бенчмарка
Это краткий обзор конфигурации бенчмарка на AWS. Для подробностей обратитесь к разделу «Подробное описание конфигурации бенчмарка». В качестве эталонного бенчмарка для эксперимента использовался тест JSON-сериализации Techempower. Для реализации использовался простой API-сервер на основе libreactor — event-driven-фреймворка, написанного на Си. API-сервер использует примитивы Linux, такие как epoll, send и recv, с минимальным потреблением ресурсов. За HTTP-парсинг отвечает picohttpparser, а за создание JSON — libclo. Он настолько быстр, насколько это возможно (во всяком случае, до появления io_uring), и выступает идеальной основой для эксперимента по оптимизации.
Аппаратное обеспечение
Сервер: инстанс 4 vCPU c5n.xlarge.
Клиент: инстанс 16 vCPU c5n.4xlarge (при попытке использовать более простой инстанс клиент становится узким местом).
Сеть: сервер и клиент находятся в одной зоне доступности (use2-az2) и группе размещения кластера.
Программное обеспечение
Операционная система: Amazon Linux 2 (ядро 4.14).
Сервер: реализации libreactor от Techempower (с 18 раунда по 20-й) запускались вручную в Docker-контейнере:
docker run -d --rm --network host --init libreactor.Клиент: было внесено несколько изменений в wrk (популярный инструмент для HTTP-бенчмаркинга) с последующим переименованием его в twrk. Он обеспечивает более стабильные результаты при коротких low-latency-тестах. Стандартная версия wrk должна выдавать аналогичные числа с точки зрения пропускной способности, но twrk лучше отображает задержки p99 и умеет выводить задержки p99.99.
Конфигурация бенчмарка
Бенчмарк запускался трижды; самые высокие и низкие результаты отбрасывались. Twrk запускался с клиента вручную с теми же заголовками, что и в официальном бенчмарке, и следующими параметрами:
без пайплайнов;
256 подключений;
16 потоков, каждый из которых прикреплён к vCPU (по 1 на каждый);
2 секунды на разогрев перед сбором статистики, 10 секунд на сам тест.
twrk -t 16 -c 256 -D 2 -d 10 --latency --pin-cpus "http://server.tfb:8080/json" -H 'Host: server.tfb' -H 'Accept: application/json,text/html;q=0.9,application/xhtml+xml;q=0.9,application/xml;q=0.8,/;q=0.7' -H 'Connection: keep-alive'Пользуясь случаем, хочу выразить свое восхищение современными достижениями в области инженерии и экономики, которые позволяют мне арендовать крошечный кусочек (почти) настоящего «железного» сервера в высокопроизводительной сети с минимальными задержками и платить за это посекундно. Как бы вы ни относились к AWS, возможности и доступность ее инфраструктуры просто впечатляют. Скажем, лет 15 назад было невозможно представить, что нечто подобное данному квесту можно проделать просто для развлечения.
Отправная точка
Running 10s test @ http://server.tfb:8080/json
16 threads and 256 connections
Thread Stats Avg Stdev Max Min +/- Stdev
Latency 1.14ms 58.95us 1.45ms 0.96ms 61.61%
Req/Sec 14.09k 123.75 14.46k 13.81k 66.35%
Latency Distribution
50.00% 1.14ms
90.00% 1.21ms
99.00% 1.26ms
99.99% 1.32ms
2243551 requests in 10.00s, 331.64MB read
Requests/sec: 224353.73
Transfer/sec: 33.16MBБазовая реализация libreactor способна обслуживать 224 тыс. RPS. Вполне серьезная цифра: большинству приложений такие скорости просто не требуются. Вывод twrk выше показывает статистику для базового сценария.
На гистограмме ниже — сравнение пропускной способности (RPS) базовой реализации libreactor (раунд 18) и текущих реализаций нескольких популярных серверов/фреймворков (раунд 20), работающих на сервере c5n.xlarge с конфигурацией по умолчанию.

Actix, NGINX и Netty — хорошо известные, высокопроизводительные HTTP-серверы, и libreactor ничуть им не уступает. Глядя на гистограмму, можно подумать, что возможностей для улучшения на самом деле не так много, но это заблуждение. Знание о том, какое место занимает libreactor по отношению к другим HTTP-серверам, безусловно, полезно, но останавливаться на достигнутом не стоит.
Flame-графики
Flame-графики представляют собой уникальный способ визуализировать загрузку CPU и идентифицировать наиболее часто используемые участки кода приложения. Они являются мощным инструментом оптимизации, позволяя быстро выявлять и устранять узкие места. Flame-графики широко используются в этой статье. Они служат своего рода наглядным подтверждением достигнутого прогресса и намекают, на что еще необходимо обратить внимание.
Первый Flame-график дает представление о внутреннем устройстве приложения. Flame-графики настроены таким образом, чтобы пользовательские функции выводились в оттенках синего, а функции ядра играли всеми переливами «пламени». Из графика очевидно, что основная часть процессорного времени тратится на ядро (отправку/получение сообщений по сети). То есть наше приложение уже работает довольно эффективно; основные проблемы возникают при перемещении данных ядром.
Код на стороне пользователя отвечает за парсинг входящего HTTP-запроса и подготовку ответа. Высокие и тонкие «иглы», разбросанные по графику, представляют обработку входящих запросов, связанную с прерываниями. Эти «иглы» распределены случайным образом, поскольку прерывания могут случаться когда угодно.
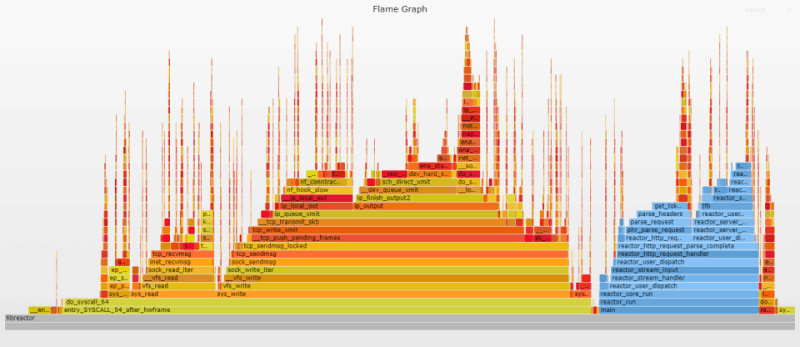
Нажмите на изображение, чтобы открыть исходный SVG-файл, созданный с помощью Flamegraph. SVG-файлы интерактивны. Можно кликнуть по сегменту, чтобы изучить его более подробно, или выполнить поиск (Ctrl + F или нажать на ссылку в правом верхнем углу) по названию функции. При поиске соответствующие участки графика выделяются фиолетовым цветом и отображается их относительная доля. Например, поиск ret_from_intr покажет, сколько времени CPU тратит на прерывания. Подробная информация о генерации Flame-графиков доступна в приложении к статье.
Предостережение
Этот квест затевался преимущественно ради развлечения. Не пытайтесь повторять его дома! Хотя дома можно, главное – не на работе (если, конечно, вы не разбираетесь досконально в том, что происходит)! Любой код на Си, написанный мной, в лучшем случае следует рассматривать как доказательство концепции. Си пришлось изучать почти с нуля — последний раз я писал на нем лет двадцать назад. Знаю, что автор libreactor’а использует его в production, но сам пока не рискую.
1. Оптимизация приложения
За базу был взят код libreactor из раунда 18* серии бенчмарков Techempower. Изменения в бенчмарке загружались непосредственно в репозиторий Techempower и сопровождались соответствующими issues в репозитории libreactor с целью внести правки на уровне фреймворка. Эти изменения были затем учтены в ветке libreactor 2.0. Реализация из раунда 20 содержит все оптимизации на уровне реализации/ фреймворка, описанные в этой статье.
* Перед бенчмаркингом код из 18 раунда получил поддержку Ubuntu 20.04, gcc 10, libdynamic 1.3.0 и libreactor 1.0.1.
Оптимизация реализации
Использование vCPU
На самую первую оптимизацию я наткнулся без какого-либо глубокого анализа. htop на сервере во время выполнения бенчмарка показал, что libreactor использует два из четырех доступных vCPU.

То есть бенчмарк в libreactor по сути использовал лишь половину своих возможностей. После правок пропускная способность возросла более чем на 25%! «А почему не в два раза?» — спросите вы. Дело в том, что:
«простаивающие» логические ядра обрабатывали часть IRQ*;
это гиперпоточные vCPU, у которых 2 физических ядра разделены на 4-х логических. Использование всех 4 логических ядер определенно увеличит скорость, но неизбежно приведет к соперничеству за ресурсы, поэтому не стоит ожидать удвоения производительности.
* Обработку IRQ на «простаивающих» vCPU можно увидеть на этом Flame-графике по итогам начального бенчмарка; он включает все процессы, а не только libreactor.
GCC
Следующая оптимизация: приложение компилировалось с GCC-флагом -O3, однако при компиляции самого фреймворка флаг оптимизации не использовался.
После создания ветки libreactor 2.0 в Makefile фреймворка был добавлен флаг GCC -march-native; его применение в приложении также благоприятно сказалось на производительности. По всей видимости, это связано с тем, что для всех компонентов используется один и тот же набор параметров при сборке с Link Time Optimizations.
Оптимизация фреймворка
send/recv
libreactor 1.0 использует функции read и write Linux для взаимодействия на основе сокетов. Использование read/write при работе с сокетами эквивалентно более специализированным функциям recv и send, при этом работа с recv/send напрямую чуть быстрее. В обычных условиях разница минимальна, но после 50 тыс. RPS она становится ощутимой. Подробности можно почерпнуть из issue на GitHub. Там же приведены Flame-графики «до» и «после». Проблема была устранена в ветке libreactor 2.0.
Потребление ресурсов pthread’ами
Аналогичным образом, хотя pthread’ы в Linux потребляют совсем мало ресурсов, их вклад станет заметным при высокой нагрузке. Оказалось, что libreactor создает пул потоков для облегчения асинхронного разрешения имен. Такой подход оправдан в случае HTTP-клиента, который подключается к множеству разных доменов, и нужно избежать блокировки DNS-запросов. Но он вряд ли подходит для HTTP-сервера, которому нужно только разрешить собственный адрес перед привязкой к сокету. Обычно эта тонкость ускользает от внимания, поскольку пул потоков создается при запуске и никогда больше не используется. Увы, управления потоками и связанной с этим траты ресурсов не избежать. Даже в экстремальных условиях этого теста overhead составляет всего около 3%, но даже 3% — слишком много, чтобы тратить их впустую.
Если сервер собран без Link Time Optimization (-flto), overhead проявляется на Flame-графиках как __pthread_enable_asynccancel и __pthread_disable_asynccancel. В этой статье он не виден, поскольку все Flame-графики генерируются на сборке со включенным -flto. Подробности доступны в соответствующем issue на GitHub; там же имеется Flame-график, на котором видны __pthread_enable_asynccancel и pthread_disable asynccancel. Проблема была устранена в ветке libreactor 2.0.
Собираем всё вместе
Вот примерный перечень всех изменений в приложении и их вклада в повышение производительности. Имейте в виду, что цифры приблизительные и призваны дать представление об их относительном вкладе.
Задействование всех vCPU — 25-27%.
Компиляция с флагом -O3 при сборке фреймворка — 5-10%.
Использование
march=nativeпри сборке приложения — 5-10%.Использование send/recv вместо
write/read— 5-10%.Устранение overhead'а pthread’ов — 2-3%.
Цифры приблизительны по следующим причинам:
Не все изменения произошли в указанном выше порядке, но были сгруппированы ради связности изложения.
Оптимизации обладают не только кумулятивным эффектом, но и дополняют друг друга. Одна оптимизация устраняет некое «узкое место», и это благоприятно сказывается на другой, повышая ее эффективность.
Например, переход от двух vCPU к четырем увеличивает пропускную способность чуть более чем на 25%, когда эта оптимизация выполняется первой, и на 40+%, когда она следует за всеми другими оптимизациями (повышается эффективность использования «простаивающих» vCPU).
Следует также отметить, что libreactor подвергся значительному рефакторингу при переходе от версии 1.0 к версии 2.0. Возможно, это также способствовало повышению производительности, однако специальных исследований на этот счет не проводилось.
Эти изменения делают нашу реализацию libreactor почти идентичной коду в 20 раунде. Единственный недостающий элемент — SO_ATTACH_REUSEPORT_CBPF (его включение будет рассмотрено позже).
Результат
Все оптимизации дают прирост производительности примерно на 55%. Пропускная способность увеличивается с 224 тыс. RPS до 347 тыс. RPS.
Running 10s test @ http://server.tfb:8080/json
16 threads and 256 connections
Thread Stats Avg Stdev Max Min +/- Stdev
Latency 735.43us 99.55us 4.26ms 449.00us 62.05%
Req/Sec 21.80k 727.56 23.42k 20.32k 62.06%
Latency Distribution
50.00% 723.00us
90.00% 0.88ms
99.00% 0.94ms
99.99% 1.08ms
3470892 requests in 10.00s, 483.27MB read
Requests/sec: 347087.15
Transfer/sec: 48.33MBАнализ Flame-графика
Наиболее очевидным изменением по сравнению с исходным Flame-графиком является уменьшение ширины и высоты фреймов, представляющих код на стороне пользователя (показаны синим цветом), благодаря флагу оптимизации gcc -O3. Также отчетливо виден результат переключения с read/write на recv/send. Наконец, повышение пропускной способности приводит к увеличению частоты прерываний (пиков ret_from intr на графике теперь гораздо больше). Поиск по ret_from_intr показывает, что его вклад вырос с 15% на исходном графике до 27% на текущем.
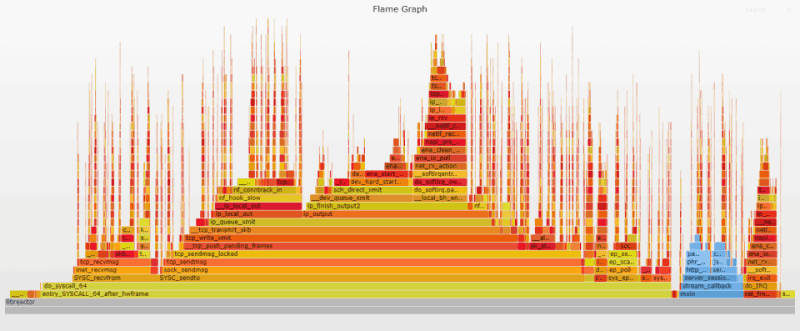
2. Отключение защиты от спекулятивного выполнения
Следующая оптимизация является одновременно существенной и спорной: отключение защиты от спекулятивного выполнения в ядре Linux. Прежде чем бежать за факелами и вилами, прошу, сделайте глубокий вдох и медленно сосчитайте до десяти. Производительность — главное в текущем эксперименте. Как оказалось, эта защита сильно на нее влияет, когда речь заходит о миллионах системных вызовов в секунду.
Но даже если оставить производительность в стороне, существуют сценарии, в которых преимущества от отключения защиты перевешивают риски (хотя в большинстве случаев она действительно имеет смысл). Например, для многопользовательской системы, которая полагается исключительно на пользовательские права и пространства имен Linux при установлении границ безопасности, стоит оставить эти ограничения в силе. С другой стороны, предположим, что API-сервер эксклюзивно занимает весь инстанс EC2. Также предположим, что ненадежный код не запускается, а инстанс использует Nitro Enclaves для дополнительной изоляции. В условиях, когда инстанс выступает естественной границей безопасности, а Nitro Enclave обеспечивает дополнительную защиту, стоит подумать об отключении защиты.
AWS, кажется, довольно уверенно применяет подход «инстансы как граница безопасности». Вот их стандартный ответ на уязвимости класса Spectre/Meltdown:
Инфраструктура AWS защищена от таких атак.
Ни один клиентский инстанс не имеет доступа к памяти инстанса другого клиента, ни один инстанс не имеет доступа к памяти гипервизора AWS.
Для разделения любых ненадежных рабочих нагрузок предлагаем использовать более жесткие меры на уровне инстансов по обеспечению безопасности и изоляции.
Естественно, не обходится без предостережения:
В качестве общей best practice в области безопасности клиентам рекомендуется вносить исправления в операционные системы или программное обеспечение по мере появления соответствующих патчей.
Полагаю, это предостережение здесь для того, чтобы клиенты не отключали бездумно средства защиты, не проанализировав должным образом особенности своего сценария.
Спекулятивное выполнение — это не единичная атака, а целый класс уязвимостей, многие из которых еще предстоит обнаружить. Возможно, если начать с предположения, что защита отключена, и изначально рассматривать инстанс/виртуальную машину как границу безопасности, в долгосрочной перспективе безопасность от этого только выиграет. Больше всего от этого выиграют те, у кого есть время и ресурсы для реализации такого подхода. Было бы крайне любопытно услышать мнения других экспертов по безопасности по этому поводу. Если вы один из них, поделитесь своим мнением на Hacker News или Reddit. Также со мной можно связаться напрямую.
Итак, для целей эксперимента выставляем performance=good, mitigations=off и переходим к подробностям о том, какие именно защитные механизмы были отключены. Вот список задействованных параметров ядра:
nospectre_v1 nospectre_v2 pti=off mds=off tsx_async_abort=offОтключенные защитные механизмы
Защиту от атак Spectre variant 1 нельзя отключить, однако защиту от SWAPGS получилось отключить с помощью параметра ядра nospectre_v1. Это привело к незначительному (1–2%) увеличению производительности.
Защиту от атак Spectre v2 можно отключить с помощью параметра ядра nospectre_v2. Это значительно повлияло на производительность, повысив ее на 15–20%.
KPTI был отключен с помощью параметра pti=off. В результате производительность выросла примерно на 6%.
MDS/Zombieload и асинхронное прерывание TSX
MDS был отключен с помощью mds=off, TAA — tsx_async_abort=off. Для обеих уязвимостей используется один защитный механизм. После его отключения производительность выросла примерно на 10%.
Защитные механизмы без изменений
Инверсия PTE включена постоянно. l1tf=flush — параметр по умолчанию, но он не релевантен, поскольку вложенная виртуализация не производится. Его отключение (l1tf=off) не оказало никакого влияния на результаты, поэтому значение по умолчанию осталось без изменений.
iTLB multihit актуален только для KVM. Он также не релевантен, поскольку AWS не поддерживает запуск KVM на инстансе EC2.
Похоже, что в ядре нет защиты от этой уязвимости; вместо этого проблема решается обновлением микрокода Intel. По утверждениям AWS, их базовая инфраструктура не подвержена этой проблеме, кроме того, была опубликована рекомендация, касающаяся этой уязвимости. spec_store_bypass по-прежнему значится в ядре как уязвимость, — возможно, ОС просто не имеет возможности проверить микрокод.
Процессоры, используемые семейством инстансов c5, не подвержены этой уязвимости.
Результат
Отключение средств защиты повышает производительность примерно на 28%. Пропускная способность возрастает с 347 тыс. до 446 тыс. RPS.
Running 10s test @ http://server.tfb:8080/json
16 threads and 256 connections
Thread Stats Avg Stdev Max Min +/- Stdev
Latency 570.37us 49.60us 0.88ms 398.00us 66.72%
Req/Sec 28.05k 546.57 29.52k 26.97k 62.63%
Latency Distribution
50.00% 562.00us
90.00% 642.00us
99.00% 693.00us
99.99% 773.00us
4466617 requests in 10.00s, 621.92MB read
Requests/sec: 446658.48
Transfer/sec: 62.19MBАнализ Flame-графика
Прирост производительности был значительным, однако изменения в Flame-графике минимальны, поскольку эти защитные механизмы практически незаметны для профилирования. Тем не менее, сравнение результатов для __entry_trampoline_start и __indirect_thunk_start на предыдущем и текущем графике показывает, что их вклад либо полностью исчез, либо сильно сократился.
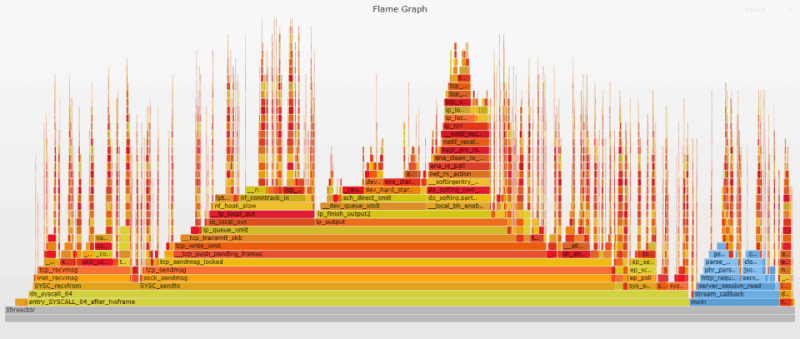
3. Аудит/блокировка системных вызовов
Overhead (излишее потребление ресурсов), связанный с аудитом/блокировкой системных вызовов по умолчанию в Linux/Docker, незаметен для большинства применений; но ситуация меняется, когда необходимо делать миллионы системных вызовов в секунду. Выполнив поиск по audit|seccomp в предыдущем Flame-графике, вы поймете, о чем речь.
Отключение аудита системных вызовов
Подсистема аудита ядра Linux предоставляет механизм для сбора и регистрации событий, связанных с безопасностью, таких как доступ к конфиденциальным файлам или системные вызовы. Это может помочь в поиске причин неожиданного поведения программы или сборе данных для последующего анализа в случае взлома. В Amazon Linux 2 подсистема аудита включена по умолчанию, но не настроена на регистрацию системных вызовов.
Хотя ведение журнала системных вызовов отключено, подсистема аудита все равно «ест» немного ресурсов при каждом системном вызове. Хорошая новость в том, что это относительно легко поправить: auditctl -a never,task. Кастомный конфиг делает именно это. Надо сказать, затея так себе, если подсистема аудита действительно занимается регистрацией системных вызовов, но я подозреваю, что в большинстве случаев это не так. Issue в Bugzilla намекает на то, что Fedora поступает аналогично.
Отключение блокировки системных вызовов
По умолчанию Docker следит за лимитами процессов, запущенных в контейнере, с помощью пространств имен, контрольных групп и ограниченного набора возможностей Linux. Кроме того, фильтр seccomp ограничивает список системных вызовов, доступных приложению.
Большинство контейнерных приложений без проблем работают с этими ограничениями, при этом контроль системных вызовов создает небольшой overhead. Одна из возможных альтернатив – запустить контейнер с параметром --privileged. Это сработает, но у контейнера окажется больше привилегий, чем необходимо. Вместо этого можно использовать параметр --security-opt, отключая только фильтр seccomp. Таким образом, команда для запуска в Docker будет выглядеть так:
docker run -d --rm --network host --security-opt seccomp=unconfined --init libreactorРезультат
В совокупности прирост производительности составил примерно 11%. Пропускная способность увеличилась с 446 тыс. до 495 тыс. RPS.
Running 10s test @ http://server.tfb:8080/json
16 threads and 256 connections
Thread Stats Avg Stdev Max Min +/- Stdev
Latency 514.02us 39.05us 1.65ms 134.00us 67.34%
Req/Sec 31.09k 433.78 32.27k 30.01k 65.97%
Latency Distribution
50.00% 513.00us
90.00% 565.00us
99.00% 604.00us
99.99% 696.00us
4950091 requests in 10.00s, 689.23MB read
Requests/sec: 495005.93
Transfer/sec: 68.92MBАнализ Flame-графика
Эти меры полностью устраняют соответствующий overhead. После их применения syscall_trace_enter и syscall_slow_exit_work исчезают с Flame-графика.
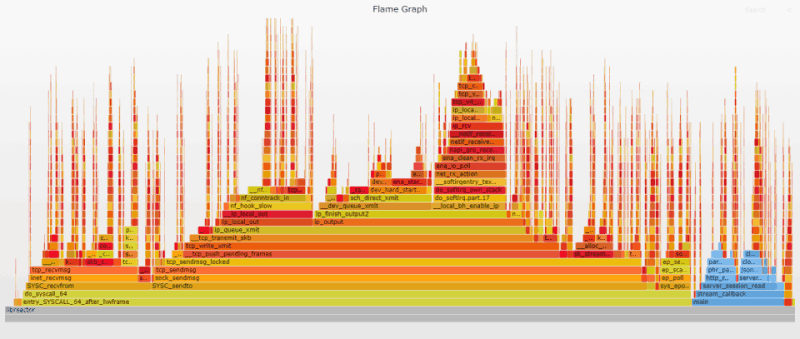
Еще одно примечание: в документации Docker говорится, что в AppArmor также есть профиль по умолчанию, однако он, похоже, отключен в Amazon Linux 2. Дело в том, что при использовании параметра --security-opt apparmor=unconfined заметных изменений в производительности (или Flame-графике) не наблюдалось.
4. Отключение iptables/netfilter
iptables/netfilter* — основной компонент, используемый традиционными брандмауэрами Linux для управления доступом к сети. Это чрезвычайно мощный и гибкий сетевой инструмент, на который полагается куча других программ, например, при преобразовании сетевых адресов (NAT). Учитывая экстремальную нагрузку теста, overhead, связанный с работой iptables, значителен, поэтому iptables становятся нашей следующей целью. На предыдущем Flame-графике overhead от iptables проявляется как на стороне отправки, так и на стороне приема в виде функции nf_hook_slow ядра; быстрый поиск по Flame-графику показывает, что на нее приходится почти 18% фреймов.
* netfilter — имя модуля ядра, который фактически выполняет всю работу. iptables — user-space-программа для изменения правил netfilter, при этом их совместный «дуэт» обычно и называют iptables.
Отключение iptables не так спорно с точки зрения безопасности, как могло бы показаться раньше. С появлением облачных вычислений задача по фильтрации пакетов сместилась с iptables на облачные примитивы (вроде AWS Security Groups). Тем не менее, во многих случаях iptables по-прежнему применяются для NAT, особенно в окружениях с большим числом Docker-контейнеров. Обратите внимание: просто отключить iptables недостаточно, необходимо также обновить/заменить все приложения, которые от него зависят.
В рамках этого теста поддержка iptables отключается в ядре и демоне Docker. Это реально, поскольку единственный контейнер напрямую подключается к хост-сети и нет необходимости в преобразовании сетевых адресов. Главное помнить, что после отключения поддержки iptables в Docker параметр --network host необходимо включать в любую команду, которая взаимодействует с сетью (в том числе в docker build).
Я предпочел отключить модуль ядра при загрузке вместо того, чтобы занести его в черный список. Теперь включить его так же просто, как добавить новое правило в iptables. Это сильно упрощает задачу, когда нужно быстро добавить динамическое правило, чтобы заблокировать недавно обнаруженную уязвимость. Увы, попутно возрастает риск случайного включения сторонним скриптом или программой. Более надежный путь — переключиться на nftables (наследника iptables) с лучшей производительностью и расширяемостью. Ограниченное тестирование с nftables показало, что загрузка этого модуля не влияет негативно на производительность, если таблица правил пуста, тогда как включение iptables существенно влияет на производительность даже без каких-либо правил.
Недостатком nftables является то, что поддержка со стороны дистрибутивов Linux появилась относительно недавно, а поддержка со стороны сторонних инструментов находится на стадии разработки. Docker — прекрасный пример этого. Что касается дистрибутивов, Debian 10, Fedora 32 и RHEL 8 перешли на nftables в качестве бэкенда по умолчанию. Слой iptables-nft используется как (преимущественно) совместимая замена iptables в user space. Разработчики Ubuntu пытались перейти на nftables в 20.04 и 20.10, но, похоже, оба раза сталкивались с проблемами совместимости. Amazon Linux 2 по-прежнему по умолчанию использует iptables. Если ваш дистрибутив поддерживает nftables, поздравляю – можно оставить модуль ядра в покое и просто внести изменения в конфиг Docker. Надеюсь, однажды в Docker появится встроенная поддержка nftables с минимальным набором правил, необходимых, чтобы сбалансировать производительность и функциональность.
Результат
Отключение iptables повысило производительность примерно на 22%. Пропускная способность возросла с 495 тыс. до 603 тыс. RPS.
Running 10s test @ http://server.tfb:8080/json
16 threads and 256 connections
Thread Stats Avg Stdev Max Min +/- Stdev
Latency 420.68us 43.25us 791.00us 224.00us 63.70%
Req/Sec 37.88k 687.33 39.54k 36.35k 62.94%
Latency Distribution
50.00% 419.00us
90.00% 479.00us
99.00% 517.00us
99.99% 575.00us
6031161 requests in 10.00s, 839.76MB read
Requests/sec: 603112.18
Transfer/sec: 83.98MBАнализ Flame-графика
Отключение iptables полностью устраняет соответствующий overhead. nf_hook_slow отсутствует на Flame-графике.

5. Идеальная локальность
Linux — крутое многоцелевое ядро, которое хорошо работает в самых разных сценариях. По умолчанию оно изо всех сил старается распределять ресурсы максимально равномерно, автоматически разбрасывая нагрузку по множеству сетевых очередей, процессов и процессоров. Такой подход отлично работает в большинстве случаев, но если нужно перейти с хорошей производительности на экстремальную, приходится жестко контролировать весь процесс.
Один из методов, возникших с появлением серверов со множеством очередей/процессоров, заключается в создании обособленных процессов (похожих на шарды баз данных), в каждом из которых сетевая очередь «прикрепляется» к CPU. В результате каждая пара работает максимально независимо от других. При этом операционная система и приложение должны быть настроены так, чтобы гарантировать, что после поступления сетевого пакета в любую очередь вся дальнейшая его обработка будет проводиться одной и той же парой vCPU/очередь как для входящих, так и для исходящих данных. Подобная привязка пакетов/данных повышает эффективность за счет актуальности кэша CPU, сокращения необходимости в переключении контекста/режимов, минимизации межпроцессорного взаимодействия и устранения конфликтов блокировок.
Привязка к процессору
Первый шаг к достижению идеальной локальности — создание отдельного серверного процесса libreactor для каждого из доступных vCPU в инстансе и привязка к этому vCPU. В нашем случае за это отвечает fork_workers(). На самом деле закрепление CPU применяется постоянно, а особое внимание, уделенное ему в текущем разделе, связано с его важностью в деле создания пары vCPU/очередь.
Receive Side Scaling (RSS)
Следующим шагом является организация фиксированных пар между сетевыми очередями и vCPU для входящих данных (исходящие обрабатываются отдельно). Receive Side Scaling — механизм с аппаратной поддержкой по равномерному распределению сетевых пакетов по нескольким очередям приема. Драйвер AWS ENA поддерживает RSS, и тот включен по умолчанию. Хеш-функция (Toeplitz) преобразует фиксированный хеш-ключ (автоматически сгенерированный при запуске) и параметры src/dst/ip/port соединения в некое хешированное значение; далее 7 наименее значимых битов этого хеша объединяются с RSS indirection table, определяя, в какую приемную очередь будет записан пакет. Такой подход гарантирует, что входящие данные от определенного соединения всегда помещаются в одну и ту же очередь. На c5n.xlarge RSS indirection table по умолчанию распределяет соединения/данные по четырем доступным приемным очередям (что и требуется), поэтому оставляем ее без изменений.
После записи пакета в область ОЗУ, зарезервированную для очереди приема, операционная система должна получить уведомление (аппаратное прерывание) о наличии данных, ожидающих обработки. Каждая сетевая очередь получает свой IRQ – по сути, выделенный канал для аппаратных прерываний. Чтобы определить, какой CPU будет обрабатывать прерывание, каждый IRQ сопоставляется с CPU с помощью /proc/irq/$IRQ/smp_affinity_list. По умолчанию сервис irqbalance обновляет значения в списке smp_affinity_list для динамического распределения нагрузки. Чтобы сохранить привязку очередей к процессорам, необходимо отключить irqbalance и вручную прописать значения в списке smp_affinity_list так, чтобы queue 0 соответствовала CPU 0, queue 1 соответствовала CPU 1, и т. д.
systemctl stop irqbalance.service
export IRQS=($(grep eth0 /proc/interrupts | awk '{print $1}' | tr -d :))
for i in ${!IRQS[@]}; do echo $i > /proc/irq/${IRQS[i]}/smp_affinity_list; done;Аппаратные прерывания и программные прерывания (softirq) автоматически обрабатываются на одном и том же процессоре, поэтому привязка сохраняется и для softirq. Это важно, поскольку аппаратные обработчики прерываний крайне минималистичны, а вся реальная работа по процессингу входящего пакета выполняется softirq-обработчиком. После завершения работы softirq данные готовы для передачи в приложение через сокет.
SO_ATTACH_REUSEPORT_CBPF
Реализация libreactor использует параметр сокета SO_REUSEPORT, позволяющий нескольким серверным процессам ожидать соединений на одном и том же порту. Это отличный вариант для распределения соединений по нескольким процессам. По умолчанию используется простая хеш-функция. Она также использует параметры src/dst/ip/port, но никак не связана с функцией, которая используется для RSS. К сожалению, случайность этого распределения нарушает привязку. Входящий пакет может быть направлен на CPU 2 для softirq-обработки, а затем передан процессу приложения, работающему на CPU 0. К счастью, начиная с версии 4.6 ядра появилась возможность более контролируемым образом управлять этими соединениями. Параметр сокета SO_ATTACH_REUSEPORT CBPF позволяет указать собственный BPF-алгоритм и с его помощью распределять соединения. Допустим, имеется четыре серверных процесса с сокетами, «слушающими» один и тот же порт; алгоритм BPF, приведенный ниже, использует идентификатор (ID) CPU, отвечавшего за softirq-обработку пакета, для определения того, какая именно комбинация из четырех «слушающих» сокетов/процессов получит входящее соединение.
{{BPF_LD | BPF_W | BPF_ABS, 0, 0, SKF_AD_OFF + SKF_AD_CPU}, {BPF_RET | BPF_A, 0, 0, 0}}* Cтрого говоря, алгоритм написан в формате Classic BPF, но автоматически переводится в представление eBPF.
Например, если softirq работал на CPU 0, то данные для этого соединения направляются в сокет 0. В этом месте стоит упомянуть об особенностях работы с параметром SO_ATTACH_REUSEPORT_CBPF. Сокет 0 не обязательно является сокетом, подключенным к процессу, который выполняется на CPU 0. На самом деле это первый сокет, который начал «слушать» комбинацию ip/port для группы SO_REUSEPORT.
Сначала я не особо задумывался об этом, так как считал, что запускаю серверные процессы (и открываю сокеты) в том же порядке, в котором я прикреплял (pin) их к соответствующим процессорам. Для fork() нового рабочего процесса, закрепления его на процессоре и запуска сервера libreactor использовался простой цикл for. Увы, если вызывать fork() в цикле for, порядок создания нового процесса/сокета будет недетерминированным, нарушая соответствие между сокетами и процессорами. Короче говоря, при использовании SO_ATTACH_REUSEPORT_CBPF нужно особое внимание уделять порядку, в котором создаются сокеты. Подробнее см. коммит на GitHub с исправлениями.
XPS: Transmit Packet Steering
Transmit Packet Steering по существу делает для исходящих пакетов то же самое, что RSS делает для входящих; этот механизм позволяет использовать одну и ту же пару vCPU/queue при отправке ответа. Для этого надо установить значение /sys/class/net/eth0/queues/tx-<n>/xps_cpus (где n — идентификатор очереди) в шестнадцатеричный битовый массив, содержащий соответствующий CPU.
export TXQUEUES=($(ls -1qdv /sys/class/net/eth0/queues/tx-))
for i in ${!TXQUEUES[@]}; do printf '%x' $((2**i)) > ${TXQUEUES[i]}/xps_cpus; done;Результат
Благодаря этим изменениям мы достигли идеальной привязки и значительного повышения производительности — примерно на 38%. Пропускная способность выросла с 603 тыс. до 834 тыс. RPS.
Running 10s test @ http://server.tfb:8080/json
16 threads and 256 connections
Thread Stats Avg Stdev Max Min +/- Stdev
Latency 301.65us 23.43us 692.00us 115.00us 68.96%
Req/Sec 52.41k 640.10 54.25k 50.52k 68.75%
Latency Distribution
50.00% 301.00us
90.00% 332.00us
99.00% 361.00us
99.99% 407.00us
8343567 requests in 10.00s, 1.13GB read
Requests/sec: 834350.86
Transfer/sec: 116.17MBАнализ Flame-графика
Изменения в нашем Flame-графике довольно интересны. По сравнению с предыдущим графиком пользовательский блок (синий) стал заметно шире. Его ширина на графике возросла с 12% до 17%. Профилирование на основе Flame-графика не является точной наукой, т.к. возможны отклонения в 1-2%, но разница вполне заметна и ощутима. Сначала была идея, что это связано с неравномерным распределением прерываний, но дальнейший анализ показал, что на самом деле это корреляция. Больше процессорного времени в пространстве пользователя означает и большее число прерываний в нем.
Моя теория состоит в том, что полная привязка позволила ядру выполнять свою работу более эффективно. Теперь обрабатывается больше пакетов, а процессорного времени используется меньше. Дело не в том, что пользовательский код стал медленнее, а в том, что код ядра стал намного быстрее. В частности, доля recv-стека (SYSC_recvfrom на графике) упала с 17% до 13%. Это логично, поскольку в условиях постоянной привязки recv всегда выполняется на том же процессоре, который обрабатывал прерывание, что значительно ускоряет работу.
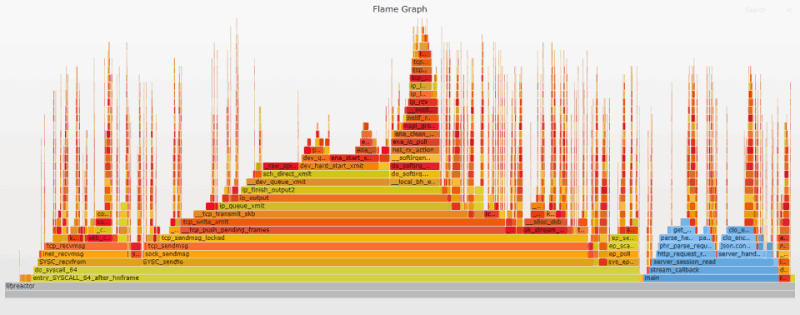
Преимущества постоянной привязки очевидны, но этот подход имеет и некоторые ограничения; его самый большой плюс — одновременно и самая большая слабость. Например, у вас небольшое число подключений, и распределение этих подключений неоптимально: непропорционально большая нагрузка приходится на CPU/queue 0. В нашем случае никакой другой CPU не сможет обрабатывать IRQ, никакой другой процесс не сможет обрабатывать соединения из очереди 0, и никакую другую очередь не будет возможно использовать для исходящих пакетов. Другими словами, каждая связка vCPU/queue в нашем случае предоставлена сама себе, и помощи ей ждать неоткуда.
Также имейте в виду, что нужно быть очень осторожным при работе на ограниченном количестве процессоров с использованием taskset или параметра Docker --cpuset-cpus. Он будет отлично работать с существующей виртуальной машиной BPF, если используется непрерывный диапазон процессоров, но чтобы проявить фантазию, вам придется написать более специфическую программу. В зависимости от конкретной архитектуры и рабочей нагрузки эти ограничения могут быть неактуальны, но их все равно необходимо держать в уме, поскольку архитектуры и рабочие нагрузки имеют тенденцию со временем меняться.
Даже с такими оговорками SO_ATTACH_REUSEPORT_CBPF – мощная оптимизация при эффективном использовании, и я надеюсь, что ее популярность будет расти. Думаю, что одна из причин, по которой она так долго оставалась незамеченной, заключается в том, что трудно найти хорошие практические примеры ее применения. Надеюсь, эта статья послужит приближенным к реальности примером по обеспечению привязки пакетов с ее помощью. В рассылке NGINX были намеки на добавление поддержки SO_ATTACH_REUSEPORT_CBPF, поэтому скоро популярность этого подхода может возрасти. Как и у реализации libreactor, использованной в этом тесте, у NGINX архитектура «процесс на ядро» с поддержкой привязки CPU, поэтому добавление SO_ATTACH_REUSEPORT_CBPF — отличная идея (если, конечно, ОС соответствует).
6. Оптимизация обработки прерываний
Модерация прерываний
Когда поступает пакет данных, сетевая карта сигнализирует операционной системе о входящих данных, которые необходимо обработать. Она делает это с помощью аппаратного прерывания, (как следует из названия) прерывая текущие «занятия» ОС. Это предотвращает переполнение буферов данных сетевой карты и позволяет избежать потери данных. Однако когда ежесекундно приходят тысячи пакетов, постоянные прерывания начинают серьезно тормозить работу.
Чтобы смягчить негативные последствия от обилия прерываний, современные сетевые карты поддерживают их модерацию/объединение. Можно сделать так, чтобы прерывание вызывалось через некоторый период времени сразу для всех пакетов, прибывших за этот период. Более продвинутые драйверы (вроде AWS ENA) поддерживают адаптивную модерацию, которая использует алгоритм динамической модерации прерываний ядра для динамической настройки задержек прерываний. Если сетевой трафик невелик, период ожидания уменьшаются до нуля, и прерывания вызываются сразу после получения пакета (т.е. с минимально возможной задержкой). С ростом сетевого трафика увеличивается и период ожидания, помогая избежать перегрузки ресурсов системы; подобный подход увеличивает пропускную способность, сохраняя задержку на адекватном уровне.
Драйвер ENA поддерживает фиксированные значения задержки прерывания (в микросекундах) для входящих и исходящих данных (tx-usecs, rx-usecs) и динамическую модерацию прерываний для входящих данных (adaptive-rx on / off). По умолчанию adaptive-rx выключен, rx-usecs — 0, а tx-usecs — 64. По итогам тестирования оказалось, что наилучший баланс пропускной способности и низкой задержки для ряда рабочих нагрузок обеспечивают следующие значения: adaptive-rx включен (on), tx-usecs — 256.
В нашем случае включение adaptive-rx увеличивает пропускную способность с 834k RPS до 955k RPS (+14%). Включение adaptive-rx — один из немногих механизмов, обсуждаемых в этой статье, у которого много потенциальных преимуществ и мало недостатков для любой системы, обрабатывающей более 10 тыс. RPS. Впрочем, обязательно протестируйте любые изменения на своей рабочей нагрузке, чтобы убедиться в отсутствии неожиданных побочных эффектов.
Busy polling
Busy polling — это относительно малоизвестная (и не очень хорошо документированная) сетевая функция, которая существует с 2013 года (ядро 3.11). Она разработана для случаев, когда крайне важна низкая задержка. По умолчанию функция позволяет заблокированному сокету опрашивать драйвер на предмет наличия входящих данных. Расплачиваться за это приходится дополнительными циклами процессора и повышенным энергопотреблением. функцию можно включить несколькими способами:
Команда
sysctl net.core.busy_readустанавливает значение по умолчанию для busy polling при использованииrecv/read, но только для блокирующих чтений. Нам это не подходит, так как у нас неблокирующие чтения.Значение
net.core.busy_readможно переопределить для каждого сокета с помощью параметраSO_BUSY_POLL, но этот способ тоже не подходит для неблокирующих чтений.Команда
sysctl net.core.busy_poll— еще один способ установить нужный параметр, подходящий для нашего случая. Если судить по документации, этот параметр актуален только дляpollиselect(но не для epoll libreactor’а). В ней явно говорится, что «только сокеты с установленным SO_BUSY_POLL будут опрашиваться». Возможно, что оба эти утверждения были справедливы тогда, но сегодня все изменилось. Поддержка busy polling была добавлена в epoll в 2017 году (ядро 4.12), и, судя по коду и тестам, устанавливатьSO_BUSY_POLLв сокете не нужно.
При использовании с epoll, busy polling больше не работает на уровне отдельного сокета, а вызывается через epoll_wait. Если включен busy polling и нет доступных событий при вызове epoll_wait, то подсистема NAPI собирает все необработанные пакеты из очереди приема сетевой карты и обрабатывает их с помощью программных прерываний (softIRQ). В идеальном сценарии обработанные пакеты затем попадут в те же сокеты, которые отслеживал epoll-инстанс, и заставят epoll вернуть доступные события. Все это может происходить без участия аппаратных прерываний или переключений контекста.
Самым большим недостатком busy polling является дополнительное потребление ресурсов CPU из-за постоянного опроса на предмет поступления новых данных. Рекомендуемое значение net.core.busy_poll варьируется от 50μs до 100μs, однако тестирование показало, что все преимущества (с минимумом недостатков) busy polling сохраняются при значении всего в 1μs. При net.core.busy_poll=50 использование CPU при тестировании всего с 8 подключениями подскакивает на 45%, в то время как в случае net.core.busy_poll=1 потребление ресурсов CPU увеличивается всего 1-2%.
Важно подчеркнуть степень взаимного благоприятного влияния модерации прерываний, busy polling’а и SO_ATTACH_REUSEPORT_CBPF. Уберите хотя бы один компонент из трех, и получите гораздо менее выраженный эффект в плане пропускной способности, задержки и соответствующего Flame-графика. Без модерации прерываний busy polling вряд ли получится запустить, а без SO_ATTACH_REUSEPORT_CBPF (и других соответствующих настроек) эффект от busy polling’а оказывается минимальным. Обратите внимание, что в сообщении к коммиту git, добавившему busy polling в epoll, особое внимание уделяется использованию SO_ATTACH_REUSEPORT_CBPF совместно с busy polling ради повышения эффективности. Из этого доклада на конференции netdev 2.1 можно почерпнуть дополнительную информацию.
Результат
Управление прерываниями и busy polling дают прирост производительности примерно на 28%. Пропускная способность увеличивается с 834 тыс. до 1,06 млн RPS, а 99-й процентиль (p99) задержки снижается с 361μs до 292μs.
Running 10s test @ http://server.tfb:8080/json
16 threads and 256 connections
Thread Stats Avg Stdev Max Min +/- Stdev
Latency 233.13us 24.41us 636.00us 73.00us 70.59%
Req/Sec 66.96k 675.18 68.80k 64.95k 68.37%
Latency Distribution
50.00% 233.00us
90.00% 263.00us
99.00% 292.00us
99.99% 348.00us
10660410 requests in 10.00s, 1.45GB read
Requests/sec: 1066034.60
Transfer/sec: 148.43MBАнализ Flame-графика
На Flame-графике заметны довольно разительные перемены по сравнению с предыдущим, но в основном они связаны с обработкой IRQ. Управление прерываниями и busy polling приводят к тому, что обработка softirq происходит проактивно, а не вызывается прерываниями.

Если поискать ena_io_poll, ret_from_intr и napi_busy_loop на соответствующих Flame-графиках, видно, что общая доля softirq (на что указывает ena_io_poll) остается примерно такой же, но доля прерываний (все тонкие «шипы») падает с 25% до чуть более 6%, а доля, связанная busy_poll, подскакивает почти до 22%.
До |
После |
|
ena_io_poll |
29.6% |
30.2% |
ret_from_intr |
24.6% |
6.3% |
napi_busy_loop |
0.0% |
21.9% |
Разница видна ещё лучше, если посмотреть на подробную статистику прерываний, генерируемую dstat:
dstat -y -i -I 27,28,29,30 --net-packetsДо
---system-- -------interrupts------ -pkt/total-
int csw | 27 28 29 30 |#recv #send
183k 6063 | 47k 48k 49k 37k| 834k 834k
183k 6084 | 48k 48k 48k 37k| 833k 833k
183k 6101 | 47k 49k 48k 37k| 834k 834kПосле
---system-- -------interrupts------ -pkt/total-
int csw | 27 28 29 30 |#recv #send
16k 967 |3843 3848 3849 3830 |1061k 1061k
16k 953 |3842 3847 3851 3826 |1061k 1061k
16k 999 |3842 3852 3852 3827 |1061k 1061kОбщее число аппаратных прерываний в секунду снизилось с 183 тыс. до 16 тыс. Также обратите внимание, что общее количество переключений контекста упало с 6000 до менее 1000 — впечатляюще низкое число, учитывая, что обрабатывается более 1 миллиона запросов в секунду.
7. Любопытный сосед
Преодоление одного миллиона RPS стало важной вехой. Я даже открыл виртуальное шампанское в чате и немного станцевал. Однако чувство, что можно добиться большего, не покидало, и, честно говоря, я стал немного одержим оптимизацией. Теперь я тщательно изучал Flame-график, пытаясь найти что-нибудь, что можно было бы устранить. Сначала тучи сгустились над _raw_spin_lock — функцией в верхней части стека системных вызовов sendto. Увы, попытки устранить ее оказались безрезультатны. Разочаровавшись, я двинулся дальше (впрочем, как видно из следующего раздела, судьба этой функции все же была предрешена).
Следующей целью стала dev_queue_xmit_nit (3,5% на Flame-графике). Исходный код dev_queue_xmit_nit говорит о том, что функция вызывается только если !list_empty(&ptype_all) || !list_empty(&dev->ptype_all), что на человеческий язык можно перевести так: «что-то ожидает и перехватывает копию каждого исходящего пакета». Аналогичная проверка происходит и для входящих пакетов внутри __netif_receive_skb_core. Поиск на Flame-графике по dev_queue_xmit_nit|packet_rcv, дает packet_rcv во входящих стеках softirq, а их совокупная доля вырастает до 4,5%.
Подобную нагрузку можно было бы ожидать, если бы программа перехватывала пакеты низкого уровня (как, например, tcpdump), но она этого не делала. Вызов packet_rcv означал, что кто-то где-то открыл raw-сокет с помощью AF_PACKET, и это тормозило работу. К счастью, виновника в конце концов удалось установить с помощью ss. Сначала я попробовал сделать ss --raw, но оказалось, что этот параметр применим только к сокетам AF_INET/SOCK_RAW, а мы ищем AF_PACKET/SOCK_RAW (не спрашивайте, я особо не копался в этом). Команда sudo ss --packet --processes находит raw-сокет AF_PACKET, а также показывает имя слушающего процесса. Итак, наш виновник найден: (("dhclient",pid=3191,fd=5)). Это DHCP-клиент с raw-сокетом.
Конечно, установить причину проблемы — только половина дела, теперь надо ее устранить. Первый вопрос: зачем DHCP-клиенту вообще «висеть» на raw-сокете? Ответ из базы знаний ISC приведен ниже. Повествование там ведется с точки зрения сервера, но та же логика, уверен, применима и к клиенту:
[Сокет] Посылает направленные одноадресные (без ARP) и специальные широковещательные сообщения, соответствующие RFC 2131. Они необходимы на этапе начальной настройки (когда у клиента еще не настроен адрес).
Это имеет смысл, поскольку клиент DHCP должен иметь возможность отправлять и получать сообщения до того, как инстансу будет присвоен IP-адрес. В той же статье из базы знаний упоминается, что стандартный сокет UDP используется для передачи маршрутизируемых одноадресных сообщений для обновлений DHCP. Я надеялся, что есть способ заставить dhclient закрыть raw-сокет после получения начального адреса и просто использовать сокет UDP для обновлений, но похоже, что это невозможно.
Следует отметить, что эти пакеты никогда не достигают dhclient, так как на сокете скорее всего стоит фильтр BPF, который отбрасывает пакеты, не относящиеся к DHCP, прежде чем те покинут ядро. Тем не менее, такая «пустая» работа ядра все равно отнимает ресурсы, а мы не можем себе этого позволить.
Согласно документации, после назначения первичного приватного IP-адреса инстансу тот привязывается к нему на все время работы (даже при перезагрузках и длительных остановках). Поскольку обновления DHCP не критичны для предотвращения переназначения IP-адреса, я решил отключить dhclient после загрузки. Помимо остановки dhclient’а также необходимо обновить время жизни частного адреса на уровне сетевого устройства (eth0), используя ip address. По умолчанию время жизни составляет 1 час (а обновления IPv4 происходят каждые 30 минут), поэтому я вручную установил время жизни на forever.
sudo dhclient -x -pf /var/run/dhclient-eth0.pid
sudo ip addr change $( ip -4 addr show dev eth0 | grep 'inet' | awk '{ print $2 " brd " $4 " scope global"}') dev eth0 valid_lft forever preferred_lft foreverРезультат
Отключение dhclient увеличило производительность почти на 6%. Пропускная способность возросла с 1,06 млн до 1,12 млн RPS.
Running 10s test @ http://server.tfb:8080/json
16 threads and 256 connections
Thread Stats Avg Stdev Max Min +/- Stdev
Latency 219.38us 26.49us 598.00us 56.00us 68.29%
Req/Sec 70.84k 535.35 72.42k 69.38k 67.55%
Latency Distribution
50.00% 218.00us
90.00% 254.00us
99.00% 285.00us
99.99% 341.00us
11279049 requests in 10.00s, 1.53GB read
Requests/sec: 1127894.86
Transfer/sec: 157.04MBАнализ Flame-графика
Функции dev_queue_xmit_nit и packet_rcv были полностью удалены. «Любопытного соседа» выселили.
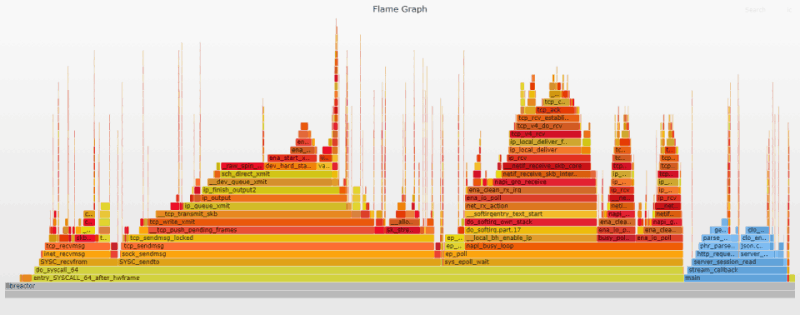
ПРИМЕЧАНИЕ. Хочу прояснить, что не тестировал эту конфигурацию на production-нагрузках или в течение длительного периода времени. Отключение dhclient может привести к непредвиденным последствиям. В данном случае это просто обходной маневр «на коленке»; если вы знаете более корректный способ выселить dhclient с raw-сокета, дайте мне знать: Hacker News | Reddit | Direct.
8. Борьба со Spin Lock
Я потратил довольно много времени, пытаясь что-то сделать с фреймом _raw_spin_lock в верхней части стека sendto (см. предыдущий Flame-график). Ядро использует несколько спинлоков для управления исходящими пакетами, проходящими через механизм qdiscs (или в обход его) по пути к сетевой карте. Учитывая, что я уже обеспечил идеальную привязку, логично предположить, что блокировка должна минимально влиять на производительность, однако, как показывает график, это не так. Я решил разобраться в происходящем.
Проблема оказалась замысловатой, и на ее решение ушли дни (если не недели). Я пытался найти ответ с помощью трейсинга. Я вручную перекомпилировал bpftrace, чтобы небезопасно трассировать _raw_spin_lock с помощью kretprobe. Я шел спать, думая о ней. Я спал, думая о ней. Я просыпался с очередной «светлой» идеей, которая оказывалась тупиковой. Поиск ответа стал моей идеей фикс. В ход шли разные параметры, разные qdisc’и, разные ядра (даже хаки для полного отключения qdisc). В итоге все старания закончились недоступностью инстанса.
В конце концов, с тяжелым сердцем, пришлось признать поражение и сдаться. Технически ядро вело себя так, как и ожидалось. Спинлоки, связанные с qdisc, — известная проблема, и попытки разработчиков ядра решить ее до сих пор не увенчались успехом. Поддержка lockless qdisc была добавлена в ядро 4.16, но заплатить за это пришлось невозможностью обхода пустого qdisc (TCQ_F_CAN_BYPASS). Это означает, что для моего сценария (неконкурентная отправка/идеальная привязка) проблемный участок просто сместится с _raw_spin_lock на __qdisc_run даже при всегда пустом qdisc.
Я был в восторге, узнав, что поддержка одновременного использования TCQ_F_CAN_BYPASS и lockless qdiscs была добавлена в более поздние ядра. Увы, радость была недолгой. Патч привел к регрессиям, и пришлось все откатить.
Noqueue спешит на помощь
Забросив борьбу со спинлоками, я перешел к другим оптимизациям, но через некоторое время вернулся, чтобы пополнить раздел «Оптимизации, которые не сработали» (см. ниже). Идея была в том, чтобы рассказать об идеях и находках — вдруг кто-то другой уловит то, что я пропустил. В поисках всевозможных хаков (в том числе и того, который «убил» инстанс), я наткнулся на то, на что раньше не обращал внимания: noqueue qdisc.
Документация по noqueue qdisc довольно скудна, но мне посчастливилось обнаружить неофициальные tc-заметки с толковым описанием. Как следует из названия, это механизм организации очередей, который на самом деле действует в обход очередей. Он разработан для использования с программными устройствами, такими как loopback-интерфейс (localhost) или виртуальные интерфейсы на основе контейнеров.
В то время как аппаратные устройства могут время от времени прекращать прием новых пакетов, чтобы очистить очередь, программные устройства принимают все, что им отправлено, и никогда не применяют back-pressure (противодавление). Пакет помещается в очередь qdisc обычно именно из-за back-pressure, поэтому нет противодавления = нет очереди. Обоснование для использования noqueue с программными устройствами простое: если qdisc все равно не будет использоваться, то можно вообще избежать расходования ресурсов. Идея казалась отличной, особенно если удастся избавиться от всех спинлоков! Вопрос был в том, получится ли заставить его работать с аппаратным устройством?
* Несмотря на то, что инстанс EC2 является виртуальной машиной, сетевое устройство Nitro выглядит как сетевая карта, подключенная к PCIe.
Короткий ответ — да, можно заменить pfifo_fast на noqueue в качестве qdisc по умолчанию.
sudo sysctl net.core.default_qdisc=noqueue
sudo tc qdisc replace dev eth0 root mqЕсли сделать sudo tc qdisc show dev eth0 после выполнения приведенных выше команд, вот как будет выглядеть вывод для c5n.xlarge. Имейте в виду, что используется несколько очередей (multi-queue), поэтому для каждой очереди передачи сетевой карты есть отдельный qdisc.
qdisc mq 8001: root
qdisc noqueue 0: parent 8001:4
qdisc noqueue 0: parent 8001:3
qdisc noqueue 0: parent 8001:2
qdisc noqueue 0: parent 8001:1Итак, мы убедились, что это возможно, но также помним, что этот механизм был разработан для другого. Осталось понять: эта идея просто не очень удачная или совсем-совсем плохая?
Для начала надо было взглянуть на код, чтобы понять, что на самом деле происходит при использовании noqueue. В функции noqueue_init значение функции enqueue установлено в NULL. По сути, так noqueue идентифицирует себя; оно вступает в игру позже, когда enqueue проверяется в __dev_queue_xmit. Если значение enqueue отлично от NULL, используется стандартный qdisc-путь (со спинлоками). Если enqueue равен NULL, используется путь noqueue: перед вызовом dev_hard_start_xmit для отправки пакета на устройство используется всего одна блокировка.
Следует иметь в виду, что даже без qdisc у сетевого интерфейса есть собственная очередь передачи (обычно кольцевой буфер). В ней исходящие данные дожидаются, пока сетевая карта их отправит. Простые реализации qdiscs, такие как pfifo_fast, служат дополнительным буфером, который используется, если устройство занято. Более навороченные реализации qdiscs, такие как sfq, планируют передачу пакетов, базируясь на т.н. потоках. Цель — обеспечить справедливость, чтобы каждый поток имел возможность отправлять данные по очереди. В данном случае удаление qdisc означает, что придется полагаться только на очередь сетевой карты. Возникают два вопроса: (1) Есть ли риск переполнения очереди передачи? (2) Каковы последствия этого?
Я был вполне уверен, что не смогу переполнить очередь своим тестом. Несмотря на то, что каждую секунду отправляется более миллиона ответов, (а) имеется только 256 подключений, (б) каждый ответ помещается в один пакет и (в) это бенчмарк на основе синхронного запроса/ответа. Другими словами, в каждый момент времени есть не более 256 исходящих пакетов, ожидающих отправки. Кроме того, все наши пары CPU/queue работают независимо, поэтому в каждой очереди собирается не более 64 пакетов, ожидающих отправки. Емкость очереди передачи драйвера ENA составляет 1024 элемента, так что запас у нас предостаточный.
Теперь надо было подтвердить, что ожидания совпадают с реальностью. Увы, размер очереди передачи не отслеживается ОС или драйвером ENA. Для этого был создан скрипт bpftrace, который сохранял для длину очереди передачи устройства при каждом вызове ena_com_prepare_tx. Далее, скрипт bpftrace поработал с qdisc, установленным на pfifo_fast, а затем — с noqueue. Результаты оказались почти одинаковыми; в обоих случаях длина очереди редко превышает 64. Вот они:
pfifo_fast
@txq[4593, 1]:
[0, 8) 313971 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[8, 16) 558405 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
[16, 24) 516077 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[24, 32) 382012 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[32, 40) 301520 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[40, 48) 281715 |@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[48, 56) 137744 |@@@@@@@@@@@@ |
[56, 64) 9669 | |
[65, ...) 37 | |noqueue
@txq[4593, 1]:
[0, 8) 338451 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[8, 16) 564032 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
[16, 24) 514819 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[24, 32) 380872 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[32, 40) 300524 |@@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[40, 48) 281562 |@@@@@@@@@@@@@@@@@@@@@@@@@ |
[48, 56) 141918 |@@@@@@@@@@@@@ |
[56, 64) 11999 |@ |
[65, ...) 112 | |Итак, в моем случае нет риска переполнения очереди передачи. Естественно, меня интересовало, что произойдет, если переполнение все же случится. Согласно этому документу, реализация метода ndo_start_xmit в сетевом драйвере должна возвращать NETDEV_TX_OK в случае успеха и NETDEV_TX_BUSY в случае неудачи. В частности, ответ NETDEV_TX_BUSY может вызвать переполнение очереди передачи. В случае простого qdisc (вроде pfifo_fast) подобный ответ приводит к повторной постановке исходящих данных в очередь qdisc. В случае же noqueue возникает ошибка, и пакет отбрасывается.
Подтвердить теорию фактами должен был исходный код драйвера ENA. Увы, все оказалось совсем не так, как ожидалось. ena_start_xmit() на самом деле обрабатывает ошибки передачи, отбрасывая пакет и возвращая NETDEV_TX_OK вместо NETDEV_TX_BUSY. В функции ena_com_prepare_tx есть проверка на заполнение очереди передачи. Если она заполнена, ненулевой код ответа передается вверх по цепочке, в результате чего драйвер снимает (unmap) DMA, отбрасывает пакет и возвращает NETDEV_TX_OK. В таком сценарии NETDEV_TX_BUSY никогда не возвращается, что означает, что ни pfifo_fast, ни noqueue не будут заниматься обработкой back-pressure. Таким образом, забота о пакете возложена на протоколы более высокого уровня вроде TCP. Они должны будут заметить, что пакет не достиг пункта назначения, и повторно отправить его.
Что ж, подтвердим ожидаемое поведение с помощью теста. Воспользуемся iPerf для передачи как можно большего количества пакетов с тестового сервера на другой инстанс: iperf3 -c 10.XXX.XXX.XXX -P 10 -t 5 -M 88 -p 5200. iPerf отправляет пакеты асинхронно, что резко увеличивает вероятность заполнения очереди передачи. Модифицированный скрипт bpftrace помог мне убедиться, что во время тестового прогона очередь передачи сетевой карты была загружена полностью (1024 записи) по крайней мере несколько раз. Запустив dmesg, чтобы убедиться в отсутствии неожиданных ошибок или предупреждений от ядра, я с удивлением обнаружил это: Virtual device eth0 asks to queue packet! .
Оказалось, что код драйвера ENA не так прост, как считалось. Сразу после того, как новый пакет успешно добавлен в очередь передачи, выполняется второй тест, чтобы увидеть, заполнена ли очередь в этот момент. Если это так, очередь останавливается, чтобы отправить все накопившиеся сообщения. Таким образом, следующий исходящий пакет может наткнуться на остановленную очередь. Когда нет qdisc, ядро просто регистрирует предупреждение и отбрасывает его, возлагая задачу по повторной отсылке на протоколы более высокого уровня.
К слову, смоделировать сценарий переполнения очереди получилось только с помощью довольно экстремального синтетического теста, и даже в нем было бы потеряно всего 500-1000 пакетов из 9 миллионов, переданных в ходе теста. Впрочем, могут быть другие побочки, связанные с noqueue. Просто помните, что этот инструмент был разработан совершенно для другого. Еще раз подчеркну: не делайте этого в production!
Результат
Переход на noqueue дал чуть более 2%. Пропускная способность увеличилась с 1.12M RPS до 1.15M RPS.
Running 10s test @ http://server.tfb:8080/json
16 threads and 256 connections
Thread Stats Avg Stdev Max Min +/- Stdev
Latency 213.19us 25.10us 801.00us 77.00us 68.52%
Req/Sec 72.56k 744.45 74.36k 70.37k 65.09%
Latency Distribution
50.00% 212.00us
90.00% 246.00us
99.00% 276.00us
99.99% 338.00us
11551707 requests in 10.00s, 1.57GB read
Requests/sec: 1155162.15
Transfer/sec: 160.84MBАнализ Flame-графика
Функция _raw_spin_lock стека системных вызовов sendto, наконец, побеждена. Небольшой вызов _raw_spin_lock происходит в __dev_queue_xmit, но он весит всего 0,3% по сравнению с чудовищными 5,4% в случае его предшественника.
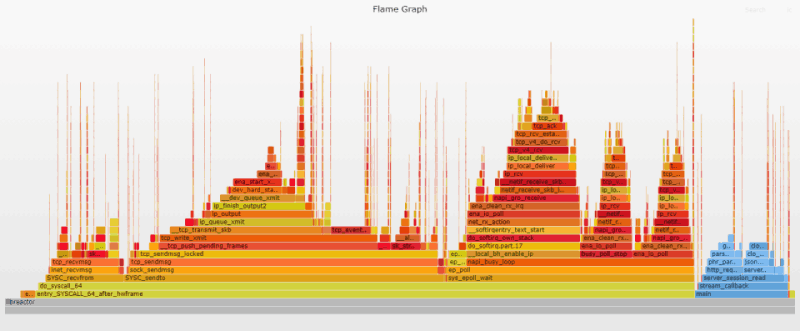
Навязчивая идея обретает новую форму
Я был рад избавиться от _raw_spin_lock, но ликовать было рано. Кое-что по-прежнему не давало мне покоя. Изменение процентов на Flame-графике не означает такого же прироста производительности, но столь значительная оптимизация все же должна была увеличить пропускную способность больше, чем на 2%. Пристальное изучение Flame-графика таило в себе сюрприз: оказалось, что вклад функции tcp_event_new_data_sent внезапно вырос с 1,1% до 5,1%. Как только я подумал, что победил, «враг» проявился в новом виде.
Преодолев первоначальное разочарование и отрицание очевидного, я с удвоенной энергией начал атаковать tcp_event_new_data_sent. Был досконально изучен исходный код (увы, безрезультатно). Был проведен анализ с помощью bpftrace: функция вызывалась одинаковое количество раз и при одинаковых условиях. Попытки проанализировать тайминги не увенчались успехом, поскольку анализ занимал значительно больше времени, чем работа самой функции. В какой-то момент меня посетила идея: вдруг это аномальный артефакт от выборки данных perf’ом? Сэмплирование велось на рекомендованной частоте (99 Гц), но я решил на всякий случай попробовать и другие. 49 Гц, 173 Гц, 263 Гц – никаких изменений.
Далее возникла идея: возможно, проблема связана с гиперпоточностью? Окей, меняем таблицу косвенной адресации, чтобы отправлять данные только в связки очередь/CPU 0 и очередь/CPU 1 (в этом инстансе процессор 0 и 1 соответствуют разным физическим ядрам), и пробуем. К моему удивлению, это сработало, доля tcp_event_new_data_sent упала почти до 1%. К моему ужасу, ее место занял новый зверь: release_sock подскочил с 1% до почти 7%. Отбросив все страхи и сомнения, я продолжил. Теперь было нужно провести тесты с гиперпоточностью, отключенной на физическом уровне. Сказано – сделано: запускаем инстанс с 1 потоком на ядро с помощью параметров CPU, проводим тесты, рисуем Flame-график. tcp_event_new_data_sent и release_sock вернулись в норму, но по какой-то причине tcp_schedule_loss_probe теперь подскочил до 11%. Что за…?!
К каждой минутой ситуация все больше напоминала причудливую греческую трагедию, в которой главный герой обречен вечно сражаться с гидрой, головы которой заново отрастают после отсечения. В этот момент я решил, что вселенная пытается преподать мне урок. Иногда нужно остановиться и оценить то, что уже удалось достичь, вместо того, чтобы зацикливаться на эфемерных и постоянно ускользающих «5 дополнительных процентах». Пора было вернуться к своей статье, а борьбу с гидрой оставить на потом.
Если вы знаете, в чем проблема и как ее победить, пожалуйста, дайте мне знать: Hacker News | Reddit | Direct.
9. Всё близится к завершению
Я классифицирую это последнее трио как мелкие оптимизации, помогающие «выжать последнюю каплю» из производительности, несмотря на то, что они негативно влияют на некоторые сценарии применения (и это известно).
Отключение Generic Receive Offload (GRO)
GRO — это сетевая функция, способная гибко объединять входящие пакеты на уровне ядра. Собранные сегменты поставляются userland-приложению как единый блок данных. Идея состоит в том, что сборка более эффективно проходит на уровне ядра, повышая производительность. Как правило этот параметр лучше оставить включенным (и он включен по умолчанию в Amazon Linux 2). Однако в случае нашего теста все запросы и ответы, как известно, легко помещаются в один пакет, поэтому необходимости в такой сборке нет. Отключение GRO высвобождает ресурсы, потребляемые функцией проверки необходимости сборки dev_gro_receive.
sudo ethtool -K eth0 gro offОтслеживание перегрузок TCP
Linux поддерживает несколько подключаемых алгоритмов для контроля за загруженностью TCP. Каждый из них использует свою стратегию для оптимизации потока данных в сети. Если не вдаваться в подробности, каждый из алгоритмов замедляет работу при обнаружении перегрузки во внешней сети и ускоряет ее, когда перегрузка исчезнет. Это особенно важно для беспроводных сетей (Wi-Fi, мобильные, спутниковые), отличающихся значительной нестабильностью. В сети с низкими задержками и без перегрузок (вроде сети в AWS cluster placement group, используемой в этом бенчмарке) их ценность сомнительна.
Сперва я не рассматривал контроль перегрузок как кандидата на оптимизацию, но потом мне в голову пришла идея: даже если перегрузка в сети отсутствует, алгоритм все равно должен следить за тем, что происходит. Вместо того, чтобы искать лучший алгоритм для управления перегрузками, возможно, мне стоит поискать тот, что потребляет минимум ресурсов в условии окружения без перегрузок?
Amazon Linux 2 поставляется с двумя механизмами управления перегрузкой: reno и cubic. Reno (он же NewReno) встроен в ядро; он используется, если другие алгоритмы недоступны. Reno использует простейший подход, а другие алгоритмы часто просто прикручивают дополнительные функции к Reno. Cubic задействует более навороченный и универсальный алгоритм. В Amazon Linux 2 он используется по умолчанию.
Если посмотреть на список опций tcp_congestion_ops для reno и cubic, становится понятно, насколько reno проще. Переход с cubic на reno приводит к небольшому, но стабильному увеличению производительности.
sudo sysctl net.ipv4.tcp_congestion_control=renoТакже были протестированы другие алгоритмы управления перегрузкой, в том числе vegas, highspeed и bbr. Для этого сначала потребовалось вручную загрузить соответствующие модули ядра, например, modprobe tcp_bbr. Ни один из них не смог опередить Reno.
Статическая модерация прерываний
Алгоритм модерации прерываний adaptive-rx чрезвычайно эффективен и универсален, но добавляет незначительный overhead при большой нагрузке. Кроме того, его максимальное значение — всего 256 usecs. Отключение adaptive-rx и использование сравнительно высокого статического значения немного улучшает пропускную способность и снижает задержки. Методом проб и ошибок я нашел оптимальный интервал — 300 usecs (для этого конкретного теста).
Фиксированное значение rx-usecs окажет довольно большое негативное влияние на время отклика при более легких рабочих нагрузках (например, ping-тестах). Также оно отрицательно скажется на производительности при отключении BPF или busy polling’а (помните об этом, если решите поиграться с бенчмарком). Обратите внимание: эта оптимизация не включена в шаблон CloudFormation.
sudo ethtool -C eth0 adaptive-rx off
sudo ethtool -C eth0 rx-usecs 300
sudo ethtool -C eth0 tx-usecs 300Результат
Заключительные оптимизации увеличили производительность более чем на 4%. Пропускная способность возросла с 1,15 млн до 1,2 млн RPS.
Running 10s test @ http://server.tfb:8080/json
16 threads and 256 connections
Thread Stats Avg Stdev Max Min +/- Stdev
Latency 204.24us 23.94us 626.00us 70.00us 68.70%
Req/Sec 75.56k 587.59 77.05k 73.92k 66.22%
Latency Distribution
50.00% 203.00us
90.00% 236.00us
99.00% 265.00us
99.99% 317.00us
12031718 requests in 10.00s, 1.64GB read
Requests/sec: 1203164.22
Transfer/sec: 167.52MBАнализ Flame-графика
На нем вы не увидите больших изменений. dev_gro_receive просела с 1,4% до 0,1%. bictcp_acked (одна из функций, используемых алгоритмом cubic) раньше «съедала» 0,3%, но теперь полностью исчезла с графика.
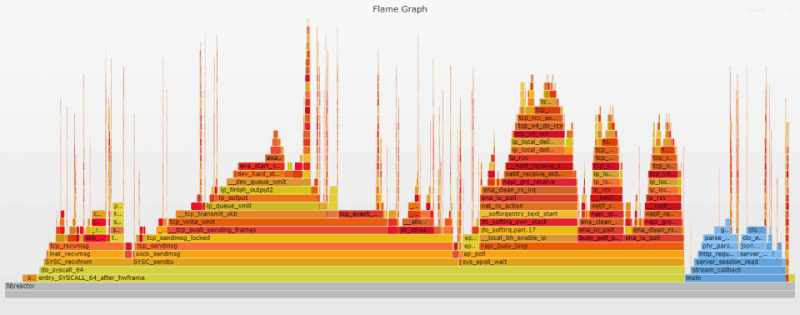
Заключение
Итак, дорогие читатели, мы прибыли в конечный пункт нашего назначения. Это было долгое, запутанное и не всегда приятное путешествие, но оно того стоило. По пути я многому научился и невероятно доволен конечным результатом. Число запросов в секунду выросло на 436%, задержка p99 снизилась на 79% — отличные результаты, особенно для сервера, который и так был быстрым.
С чего все начиналось:
Running 10s test @ http://server.tfb:8080/json
16 threads and 256 connections
Thread Stats Avg Stdev Max Min +/- Stdev
Latency 1.14ms 58.95us 1.45ms 0.96ms 61.61%
Req/Sec 14.09k 123.75 14.46k 13.81k 66.35%
Latency Distribution
50.00% 1.14ms
90.00% 1.21ms
99.00% 1.26ms
99.99% 1.32ms
2243551 requests in 10.00s, 331.64MB read
Requests/sec: 224353.73
Transfer/sec: 33.16MBК чему я пришел:
Running 10s test @ http://server.tfb:8080/json
16 threads and 256 connections
Thread Stats Avg Stdev Max Min +/- Stdev
Latency 204.24us 23.94us 626.00us 70.00us 68.70%
Req/Sec 75.56k 587.59 77.05k 73.92k 66.22%
Latency Distribution
50.00% 203.00us
90.00% 236.00us
99.00% 265.00us
99.99% 317.00us
12031718 requests in 10.00s, 1.64GB read
Requests/sec: 1203164.22
Transfer/sec: 167.52MBlibreactor vs остальной мир
На гистограммах ниже сравниваются начальная (раунд 18) и конечная (раунд 20) реализации libreactor с некоторыми из наиболее популярных (или производительных) реализаций бенчмарка Techempower JSON по состоянию на раунд 20.
На первой диаграмме показаны результаты запуска всех 11 реализаций на c5n.xlarge с использованием стандартного AMI Amazon Linux 2 без каких-либо оптимизаций ОС/сети. Как видно, оптимизаций на уровне приложения, добавленных между 18 и 20 раундами, оказалось достаточно, чтобы вывести libreactor в лидеры.

Вторая диаграмма показывает, как оптимизации ОС/сети повлияли на все реализации. Также видно, насколько хорошо эти оптимизации сочетаются с libreactor'ом 20 раунда, еще сильнее увеличивая его отрыв от остальных участников. Нижний (темный) сегмент каждого столбца соответствует производительности, продемонстрированной до оптимизации ОС/сети (т.е. на предыдущем пункте).

Обратите внимание, что эти результаты будут отличаться от официальных результатов 20-го раунда Techempower JSON из-за известной проблемы. В их тестовом стенде клиентский инстанс такой же, что и сервер, и для JSON-теста он становится узким местом. Все десять топ-реализаций «срезаются» примерно на 1,6 млн RPS. Примерное представление о потенциальной производительности можно получить, взглянув на столбец загрузки CPU сервера в 20-м раунде. Libreactor «съел» всего 47% ресурсов процессора, в то время как ulib-json_fit задействовал 75%, а pico.v — 90%.
Techempower пробует устранить это ограничение, используя сервер базы данных для создания нагрузки во время JSON-тестов. Кроме того, Фредрик Видлунд (Fredrik Widlund) недавно выпустил похожий на wrk инструмент тестирования производительности под названием pounce на фреймворке libreactor. Мои грубые предварительные тесты показали, что он на 20-30% быстрее, чем wrk, и вполне может пригодиться команде Techempower.
Совет от усталого путешественника
Это приключение поддерживалось моим любопытством, желанием учиться и неутомимой настойчивостью; но я добился успеха только после того, как отбросил в сторону все предположения и воспользовался доступными инструментами для измерения, анализа и понимания приложения. Я последовательно профилировал рабочую нагрузку с помощью Flame-графиков в поисках потенциальных оптимизаций (и чтобы подтвердить их эффективность). Когда что-то не срасталось, bpftrace помогал проверять различных гипотезы и подтверждать ожидания.
Тем, кто читает эту статью в поисках идей по оптимизации производительности, рекомендую придерживаться аналогичного подхода. Прежде чем подумать об отключении аудита системных вызовов или seccomp, создайте Flame-график и посмотрите, каков вклад этих функций в вашем конкретном случае. Скорее всего, он минимален. При этом Flame-график может выявить другое узкое место или даст более глубокое представление о том, что происходит с ОС и приложением.
Что дальше?
Как бы я ни был доволен конечным результатом, меня терзают сомнения: вдруг я что-то пропустил? Пожалуйста, сообщите о существенных оптимизациях (если таковые имеются), которые я не рассмотрел. Но сперва ознакомьтесь со списком оптимизаций, которые я пробовал и которые не сработали (см. ниже).
Забегая вперед, скажу, что у меня уже есть планы сравнить производительность ARM и Intel, «столкнув лбами» c6gn на базе Graviton2 и c5n (и новый m5zn). Скорее всего это произойдет после того, как будет решена проблема с сетью c6gn. Также есть мысль присмотреться к io_uring как к альтернативе epoll. Дайте мне знать, если у вас есть идеи о том, чем мне еще заняться.
Мы живем в уникальное время!
Как упоминалось ранее, 15 лет назад было невозможно даже представить проект подобного размаха. Более того, даже если бы у меня был доступ к необходимому оборудованию, повторить мой опыт было бы гораздо сложнее. Все изменилось благодаря облачным вычислениям.
Какими бы фантастическими ни казались результаты, это не просто теория, проверяемая на экзотическом, недоступном оборудовании. Практически любой, у кого есть немного времени и денег, может воспользоваться этим шаблоном и повторить мои результаты на том же оборудовании. При наличии опыта работы с AWS/CloudFormation это займет не более часа и будет стоит около доллара. Возможности для исследований и экспериментов, которые открывает облачная модель, поистине впечатляют.
Особая благодарность
Я хочу выразить признательность авторам многочисленных публикаций в блогах, статей, презентаций и инструментов, которые я изучил в процессе эксперимента. Ниже есть полный перечень, но в этом разделе я хотел бы особо упомянуть несколько жемчужин:
Сердечная благодарность парням из packagecloud.io, чей исключительно подробный разбор сетевого стека Linux оказался невероятно полезен. Сперва он показался мне китайской грамотой, но потом, вчитавшись, я оценил его по достоинству. Хотя разбор был написан для ядра 3.13, он до сих пор актуален и очень полезен (и ориентирован на UDP вместо TCP, но это не страшно).
В процессе работы я наткнулся на потрясающую презентацию Boost UDP Transaction Performance от Тошиаки Макиты (Toshiaki Makita). Она не только выступила практической и эффективной демонстрацией применения Flame-графиков для поиска узких мест в производительности, но и стала стимулом в моем стремлении достичь отметки в 1 млн RPS, когда перспективы казались туманными.
Инструмент Flamegraph Брендана Грегга (Brendan Gregg) и его книга BPF Performance Tools сыграли важную роль. Я использовал FlameGraph и
bcc/bpftraceна протяжении всего проекта. Интересующимся рекомендую недавно вышедшее второе издание книги Брендана Systems Performance: Enterprise and the Cloud.Спасибо Fredrik Widlund и Will Glozer за создание libreactor и wrk.
Спасибо разработчикам ядра Linux, чья работа является фундаментом, на котором всё держится. Если бы кто-то сказал мне год назад, что я буду часами копаться в исходном коде ядра, я бы, честно говоря, не поверил ему.
И последнее, но не менее важное: особая благодарность моим рецензентам Kenia, Nesta, Andre, Crafton, Kaiton, Dionne, Kwaku и Monique.
Оптимизации, которые не сработали
Вот неполный список оптимизаций, которые я попробовал, но они не принесли результата:
-
libreactor:
запуск libreactor без Docker'а (как самостоятельный исполняемый файл);
использование
writevвместоsend(замедляет);большее значение для
maxeventsсepoll_wait;различные версии
gcc;различные опции
march/mtune;флаги gcc;
-
Ядро:
обновление до 4.19 (Amazon Linux 2);
обновление до 5.4 (Amazon Linux 2 и Ubuntu 20.04);
планировщики
SCHED_FIFOиSCHED_RR;kernel.sched_min_granularity_ns;kernel.sched_wakeup_granularity_ns;transparent_hugepages=never;skew_tick=1;clocksource=tsc;
-
Сеть:
-
драйвер ENA:
отключение функций (сегментация, разброс-сбор (scatter-gather), контрольная сумма rx/tx);
рекомпиляция
enaс-O3;-
параметры ENA:
ena.rx_queue_size;ena.force_large_llq_header;
отключение IPv6:
ipv6.disable=1;отключение VLAN:
sudo modprobe -rv 8021q;-
отключить проверку источника:
net.ipv4.conf.all.rp_filter=0;net.ipv4.conf.eth0.rp_filter=0;net.ipv4.conf.all.accept_local=1(ухудшил работу perf);
net.ipv4.tcp_sack=0;net.ipv4.tcp_dsack=0;net.ipv4.tcp_mem/tcp_wmem/tcp_rmem(значений по умолчанию достаточно);net.core.netdev_budget;net.core.dev_weight(не актуально, если вы не используете RPS);net.core.netdev_max_backlog(не актуально, если вы не используете RPS);net.ipv4.tcp_slow_start_after_idle=0(не актуально);net.ipv4.tcp_moderate_rcvbuf=0;net.ipv4.tcp_timestamps=0;net.ipv4.tcp_low_latency=1(legacy-опция);SO_PRIORITY;TCP_NODELAY.
-
Подробное описание конфигурации бенчмарка
Дополнительная информация
Приведенная ниже информация дополняет сведения из раздела «Базовая конфигурация бенчмарка».
Программное обеспечение
-
Операционная система (клиент и сервер):
EC2 AMI:
amzn2-ami-hvm-2.0.20210126.0-x86_64-gp2;-
Linux sysctls:
vm.swappiness=0;vm.dirty_ratio=80;net.core.somaxconn=2048;net.ipv4.tcp_max_syn_backlog=10000;
amazon-ssm-agent был отключен, чтобы избежать потенциального влияния.
Сеть
Аппаратное обеспечение/драйвер: и клиент, и сервер подключались к сети через карту Amazon Nitro для VPC и работали под управлением версии 2.4.0 драйвера Elastic Network Adapter (ENA). Сетевой интерфейс поддерживает несколько сетевых очередей (по одной на каждый vCPU), масштабирование на стороне приема (Receive side scaling, RSS) и рабочий режим, называемый очередью с низкой задержкой (Low-latency Queue, LLQ).
IP-адреса: для инстансов использовались исключительно адреса IPv4.
Пределы пропускной способности: AWS гарантирует пропускную способность только для инстансов круче 4xlarge. c5n.xlarge может кратковременно выдавать до 25 Гбит/с с 1,8 млн пакетов в секунду, но обычные его параметры гораздо ниже. Испытания были намеренно сокращены, чтобы избежать превышения допуска по пакетам. В последней версии драйвера ENA можно проверить, было ли превышено ли ограничение, используя недавно добавленные метрики (их можно посмотреть с помощью ethtool, например,
ethtool -S eth0 | grep exceeded).
Генерация Flame-графиков
Flame-графики в этом материале были созданы путем ручного запуска perf record во время выполнения бенчмарка. Чтобы выделить детали и обеспечить визуальную согласованность по всем направлениям, при их создании использовалась версия libreactor чуть отличающаяся от той, на которой выполнялись реальны бенчмарки. Версии libreactor для Flame-графиков были собраны с опциями GCC -fno-inline, -fomit-frame-pointer и -flto. Flame-графики генерировались с помощью следующих команд (вместе с этой кастомной палитрой):
sudo perf record -F 99 --call-graph dwarf --pid $(pgrep -d ',' 'libreactor')
sudo perf script | ./stackcollapse-perf.pl --kernel | ./flamegraph.pl --width 1600 --bgcolors grey --cp > output.svgПродвинутый стенд
Я использовал описанный выше стенд для поиска оптимизаций и оценки их влияния, но для финального прогона хотелось использовать стенд, способный минимизировать любые факторы, которые могут отрицательно повлиять на результаты. Основная цель состояла в том, чтобы свести к минимуму несоответствия на уровне платформы/ОС/сети, чтобы гарантировать, что изменения являются результатом оптимизаций и не связаны с каким-то внешним фактором.
Скорее всего, вы сможете достичь заветных 1.2M RPS и без приведенных ниже шагов, заплатив за это гораздо большей изменчивостью пропускной способности и вариабельностью задержек в верхних процентилях (p99 и p99.99).
Избегайте вредных соседей и непостоянства Intel Turbo Boost
Заключительный бенчмарк проводился на c5n.9xlarge, число виртуальных процессоров которого было снижено до 4 с помощью оптимизации параметров процессора EC2. Это означало две вещи:
Тестовый сервер был единственной виртуальной машиной на узле NUMA.
Intel Turbo Boost был всегда включен.
В процессе тестирования я заметил, что Turbo Boost увеличивал производительность процессора при stress-ng-тестировании (stress-ng --matrix 0 --metrics-brief -t 7) примерно на 2%. Гарантируя, что Turbo Boost всегда включен, я защищался от возможной просадки на те самые 2%, которая могла произойти, если бы соседние виртуальные машины внезапно оказались бы исключительно нетребовательными к ресурсам CPU при тестировании.
Была идея провести тест с клиентом и сервером на одном выделенном хосте, чтобы избежать вредных соседей и вариабельности сетевых задержек, но помешала эта проблема. По какой-то причине производительность падала при запуске на выделенном хосте.
Проверьте задержки
Средняя задержка между двумя серверами в группе размещения кластера обычно гуляет в диапазоне от 40μs до 60μs в зависимости от того, как ее измерять:
ICMP (
ping -U): 35–60μs;TCP (
sockperf ping-pong): 40–65μs.
Однако время от времени она может сильно выходить за пределы этого интервала, поэтому я останавливал/запускал свои инстансы до тех пор, пока задержка между клиентом и сервером не оказывалась ниже средней. Результаты для инстансов в тесте ниже оказались довольно высокими (нормальные значения – около 50μs):
Команда: sudo ping -U -q -i 0 -s 18 -w 10 10.XXX.XXX.XXX
Результат: 39μs
249138 packets transmitted, 249137 received, 0% packet loss, time 10000ms
rtt min/avg/max/mdev = 0.035/0.039/0.155/0.008 ms, ipg/ewma 0.040/0.040 msКоманда: sockperf ping-pong --tcp --full-rtt -m 14 -i 10.XXX.XXX.XXX -t 10
Результат: 44μs
sockperf: Summary: Round trip is 44.804 usec
sockperf: Total 212861 observations; each percentile contains 2128.61 observations
sockperf: ---> <MAX> observation = 143.388
sockperf: ---> percentile 99.999 = 67.481
sockperf: ---> percentile 99.990 = 65.303
sockperf: ---> percentile 99.900 = 60.829
sockperf: ---> percentile 99.000 = 50.901
sockperf: ---> percentile 90.000 = 46.082
sockperf: ---> percentile 75.000 = 45.163
sockperf: ---> percentile 50.000 = 44.556
sockperf: ---> percentile 25.000 = 44.014
sockperf: ---> <MIN> observation = 38.849Остановка некритичных сервисов
После загрузки были остановлены все некритичные сервисы на инстансе, чтобы они не портили задержку. Вы удивитесь, узнав, что в их число вошли dockerd и containerd. Процессы libreactor продолжают работать даже после остановки dockerd/containerd благодаря функции live restore Docker’а (еще одно напоминание о том, что контейнер — это всего лишь один или несколько процессов Linux, работающих в кастомном пространстве имен).
Вот команды для остановки некритичных служб:
sudo systemctl stop containerd
sudo systemctl stop docker
sudo systemctl stop rsyslog
sudo systemctl stop postfix
sudo systemctl stop crond
sudo systemctl stop chronyd
sudo systemctl stop libstoragemgmt
sudo systemctl stop systemd-journald.socket
sudo systemctl stop systemd-journald
sudo systemctl stop rpcbind.socket
sudo systemctl stop rpcbind
sudo service auditd stopОтключение этих сервисов может привести к неожиданным побочным эффектам, поэтому они не включены в шаблон CloudFormation. Разумеется, никакие интерактивные программы (например, htop) не запускались во время бенчмарка.
Кэширование записей ARP
С помощью sysctl также были изменены некоторые параметры. Это позволило кэшировать записи ARP и уменьшить частоту обновлений кэша.
sudo sysctl -w net.ipv4.neigh.default.gc_thresh1=128
sudo sysctl -w net.ipv4.neigh.default.gc_interval=300
sudo sysctl -w net.ipv4.neigh.eth0.gc_stale_time=300Эта оптимизация также была исключена из шаблона CloudFormation.
Странности EC2
Даже после выполнения всех вышеперечисленных шагов разница в производительности между двумя, казалось бы, идентичными инстансами EC2 могла достигать 5–10%. Были исключены следующие возможные причины:
различия в задержках TCP (
sockperf);различия в производительности процессоров (
stress-ng);«вредные соседи» / кража процессорного времени (9xlarge +
sar);Intel Turbo Boost (
turbostat);модель CPU (
lscpu).
Похоже, есть какая-то существенная разница в прошивке или железе, которую мне не удалось обнаружить. Если у вас есть идеи по этому поводу, дайте мне знать: Hacker News | Reddit | Direct.
Чтобы обойти разброс результатов, я старался использовать один и тот же инстанс во всех прогонах. Если приходилось повторять тест, я кропотливо останавливал/запускал инстанс сервера в поисках того, который соответствовал бы производительности при предыдущих запусках.
Шаблон CloudFormation
Шаблон AWS CloudFormation создаст готовое тестовое окружение со всеми примененными оптимизациями, кроме статической модерации прерываний (см. раздел выше). В разделе небезопасных настроек, приведённом ниже, есть команды для включения статической модерации прерываний; помните, что сначала нужно провести ping-тесты, иначе их результаты будут искажены.
Единственные параметры шаблона, которые нужно задать:
Пара ключей инстанса EC2.
Подсеть VPC (подойдет любая подсеть в VPC по умолчанию).
Группа безопасности VPC (подойдет стандартная группа безопасности для VPC по умолчанию).
ВНИМАНИЕ!
Если вы новичок в AWS, всегда, всегда — повторяю, всегда! — включайте биллинг-оповещения, прежде чем приступить к экспериментам.
Не забывайте останавливать инстансы, когда они не используются; не забудьте удалить стек CloudFormation, когда закончите. Конфигурация по умолчанию обходится примерно в 1 доллар в час в регионе us-east-2. Дешево, если запустить инстанс на час, но если забыть и оставить его на целый месяц, то придется выложить круглую сумму.
Имейте в виду, что за остановленные инстансы взимается плата за EBS. Приблизительно 0,05 доллара в день для конфигурации по умолчанию.
На заметку
Инстансы настроены на автоматическую сборку twrk и libreactor при первом запуске. Они автоматически перезагрузятся, чтобы применить изменения параметров ядра. Поэтому перед первым входом в систему придется подождать 3-4 минуты.
Шаблон CloudFormation автоматически использует последнюю доступную версию Amazon Linux 2. На момент написания это
amzn2-ami-hvm-2.0.20210427.0-x86_64-gp2, но после выпуска новой версии она сразу станет версией по умолчанию. Новые версии могут отрицательно (или положительно) повлиять на бенчмарк.При слишком частом запуске бенчмарка (или его долгой работе), есть риск превысить лимиты инстанса по пиковой производительности (burst). Используйте эту команду для проверки:
ethtool -S eth0 | grep exceeded.Результаты будут варьироваться от 1,1M RPS до 1,2M RPS из-за различий в производительности между инстансами EC2 (см. «Странности EC2»).
Запуск бенчмарка
Добавьте правило в группу безопасности, которое разрешает подключение по SSH только с вашего IP-адреса.
Войдите по SSH на клиент и сервер, используя их публичные IP-адреса.
Пропингуйте приватный IP-адрес сервера с клиента, чтобы убедиться, что задержка находится в ожидаемом диапазоне (40–60μs):
sudo ping -U -q -i 0 -s 18 -w 10 172.31.XX.XXЗапустите twrk на клиенте, подставив в URL приватный IP-адрес сервера:
docker run -d --rm --security-opt seccomp=unconfined --network host --init libreactorЗапустите twrk на клиенте, подставив в URL приватный IP-адрес сервера:
twrk -t 16 -c 256 -D 2 -d 10 --latency --pin-cpus "http://172.31.XX.XX:8080/json" -H 'Host: server.tfb' -H 'Accept: application/json,text/html;q=0.9,application/xhtml+xml;q=0.9,application/xml;q=0.8,/;q=0.7' -H 'Connection: keep-alive'Небезопасные настройки
Здесь обитают драконы. Прежде чем запускать любую из этих команд, обязательно прочитайте раздел «Продвинутый стенд». Убедитесь, что осознаете последствия.
Включение статической модерации прерываний:
sudo ethtool -C eth0 adaptive-rx off
sudo ethtool -C eth0 rx-usecs 300
sudo ethtool -C eth0 tx-usecs 300Остановка некритичных служб:
sudo systemctl stop containerd
sudo systemctl stop docker
sudo systemctl stop rsyslog
sudo systemctl stop postfix
sudo systemctl stop crond
sudo systemctl stop chronyd
sudo systemctl stop libstoragemgmt
sudo systemctl stop systemd-journald.socket
sudo systemctl stop systemd-journald
sudo systemctl stop rpcbind.socket
sudo systemctl stop rpcbind
sudo service auditd stopВключение кэширования ARP-записей:
sudo sysctl -w net.ipv4.neigh.default.gc_thresh1=128
sudo sysctl -w net.ipv4.neigh.default.gc_interval=300
sudo sysctl -w net.ipv4.neigh.eth0.gc_stale_time=300Полезные ссылки
Ресурсы о сетевых технологиях ядра Linux
Linux Network Receive Stack: Monitoring and Tuning Deep Dive;
-
Подробная серия статей о сетевых технологиях ядра от packagecloud:
-
Busy polling:
Toshiaki Makita's LinuxCon presentation: Boost UDP Transaction Performance;
Tuned: Daemon for monitoring and adaptive tuning of system devices;
Инструментарий и программное обеспечение
-
Flame-графики:
Linux kernel driver for Elastic Network Adapter (ENA) family.
Уязвимости спекулятивного выполнения
Бюллетень AWS Bulletin об уязвимостях класса Spectre/Meltdown.
-
AWS re:Invent 2019: Speculation & leakage: Timing side channels & multi-tenant computing (SEC355):
P.S.
Читайте также в нашем блоге:
Комментарии (5)

Worky
22.04.2022 18:28+1Хорошая статья, многое можно применить в жизни. Еще добавил бы увеличить txqueuelen на сетевке: увеличивает пропускную способность. Вроде у автора не было.

karabanov
23.04.2022 10:35Еще добавил бы увеличить txqueuelen на сетевке: увеличивает пропускную способность
И, в месте с ней, задержки.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
godzie
Очень сильно, огромное спасибо за перевод!