
Поиск по базе объявлений — совсем не то же самое, что поиск по интернету. Он параметрический, а не полнотекстовый: вы можете с помощью фильтров однозначно определить, что вам нужно, сузив область поиска. Поэтому и ранжирование в нём, на первый взгляд, играет не настолько большую роль — казалось бы, документов или карточек в выдаче не так много, чтобы дополнительно их ранжировать. Но это справедливо для небольшой базы и только для одного поискового сценария.
В параметрическом поиске Авто.ру действует правило: незачем строить за пользователя предположения о том, что он имел в виду. Мы в любом случае покажем все объявления, соответствующие поисковым фильтрам в запросе. Роль движка ранжирования — отсортировать карточки так, чтобы наиболее релевантные для конкретного пользователя оказались выше, не более. Я работаю над этим уже несколько месяцев, сейчас расскажу об устройстве движка и первых результатах.
На скриншоте видно: с помощью параметров можно указать марку, модель автомобиля и другие, в том числе мельчайшие характеристики. Также можно ввести запрос текстом, в этом случае он будет разбит на токены и преобразуется в набор параметров. Ещё одно важное отличие — объявления на Авто.ру могут публиковать и частные продавцы, и дилеры. Эти особенности поиска вновь ставят под сомнение возможную пользу от машинного обучения. Действительно, зачем использовать ML, когда поисковые фильтры могут дать однозначный ответ на запрос?
Как люди ищут на Авто.ру
Мы проанализировали поисковые сессии пользователей на нашем сайте и заметили, что далеко не все используют много фильтров. Самые популярные из них — марка, модель, регион, нижние и верхние границы цены. Но даже эти фильтры все вместе встречаются меньше чем в половине всех поисковых сессий. Допустим, пользователи часто указывают лишь верхнюю границу цены, оставляя остальные поля пустыми. Таким критериям поиска удовлетворяет много объявлений. Но если пользователь ввёл цену «до миллиона», это не значит, что ему одинаково интересны автомобили, которые стоят близко к миллиону и десятки тысяч рублей (да, есть и такие). Аналогично, если пользователь не указал марку или тип кузова, это не значит, что ему одинаково интересны все варианты этих параметров.
С точки зрения поисковых сценариев, одна часть пользователей приходит на Авто.ру, когда уже знает какой примерно автомобиль собирается купить, а другая — чтобы поисследовать предложения рынка, прицениться и только потом начать искать нечто конкретное.
Проблема ранжирования поисков с пустыми фильтрами
Итак, есть поисковые сценарии, где люди ещё наверняка не знают, какой автомобиль им нужен. Поэтому вопрос ранжирования выдач с большим числом пустых фильтров становится очень острым. Предположим, пользователь ввёл единственный фильтр по типу кузова седан. Что показать в топе выдачи по такому запросу? Новенький Mercedes-Benz E-класса или, например, Lada Priora с пробегом 100 тыс. км? От качества ранжирования зависит, сможет ли пользователь найти то, что ему нужно, и решить свою проблему или нет.
Одна из простых идей — ранжировать по определённому параметру, например по цене или по свежести объявления. Но такой подход к ранжированию не учитывает детали самого объявления. Поэтому мы задумались о том, что можно было бы ранжировать объявления с помощью машинного обучения. Например, по логам поисковых сессий можно обучить модель оценивать релевантность объявления на основе его контента. В самом простом виде под релевантностью понимается CTR (click-through-rate) — отношение числа кликов к числу показов объявления. На выходе для каждого объявления имеем вероятность клика по нему.
Это уже хорошо, тем не менее, у такой модели есть очевидный минус — в ней учитываются контентные факторы объявлений, но не учитываются предпочтения пользователей. Допустим, одни предпочитают японские праворульные автомобили, другим подавай немцев. Кто-то уверенно управляет ручной коробкой, другим подходит только автомат. Становится понятно — модель должна быть персональной.
Гипотеза о персональном ранжировании
Персонализация в задачах ранжирования — способность модели оценивать релевантность объявлений с учётом интересов и паттернов поведения пользователей. Рассмотрим это в контексте Авто.ру. Допустим, известно, что пользователь ранее интересовался автомобилями определённой марки. Тогда, при отсутствии строгого поискового фильтра на марку автомобиля в поисковом запросе, логично будет в поисковой выдаче в первую очередь показывать ему объявления с этой маркой и с похожими на неё. Такой подход решает проблему поиска с пустыми фильтрами. Зная предпочтения пользователей, мы можем показывать в топе выдачи наиболее релевантные для них объявления.
Чтобы сделать хорошее персональное ранжирование, нужно завести много факторов про объявления и пользователей, собрать обучающую выборку с этими факторами и обучить на них ранжирующую модель. Дальше я расскажу подробнее, как мы это делаем.
Факторы ранжирования
У нас есть разные факторы, которые мы используем для обучений моделей. Их условно можно разделить на четыре группы. Контентные — про автомобиль, конверсионные — статистики по объявлениям за время их нахождения на сайте, пользовательские — соцдем и разные real-time-счётчики на основе поведения пользователя на нашем сайте. Ещё есть факторы на стыке запроса и объявления.

Персональная модель ранжирования
Постановка задачи обучения модели:
- Обучающая выборка состоит из N поисковых запросов.
- Каждый запрос содержит набор объявлений.
- Для каждого объявления есть таргет, основанный на силе взаимодействия пользователя с данным объявлением. С точки зрения обучающей выборки, ключевые таргеты на сайте — показ объявления, клик на объявление и звонок по объявлению. Разумеется, последнее — самый сильный и желаемый сигнал.
- Цель обучения — построить модель, которая наилучшим образом будет восстанавливать порядок объявлений в соответствии с таргетами: для первых объявлений в выдаче вероятность того, что человек по ним позвонит, выше, чем для последующих.
В качестве модели мы используем градиентный бустинг из библиотеки CatBoost с ранжирующей функцией потерь YetiRank. CatBoost работает довольно быстро на всех этапах — обучает модели на GPU, параметры перебирает с помощью алгоритма Байесовской оптимизации, а для применения использует API на Java.
Персональная модель применяется в рантайме непосредственно в момент поискового запроса. Схема применения выглядит следующим образом:
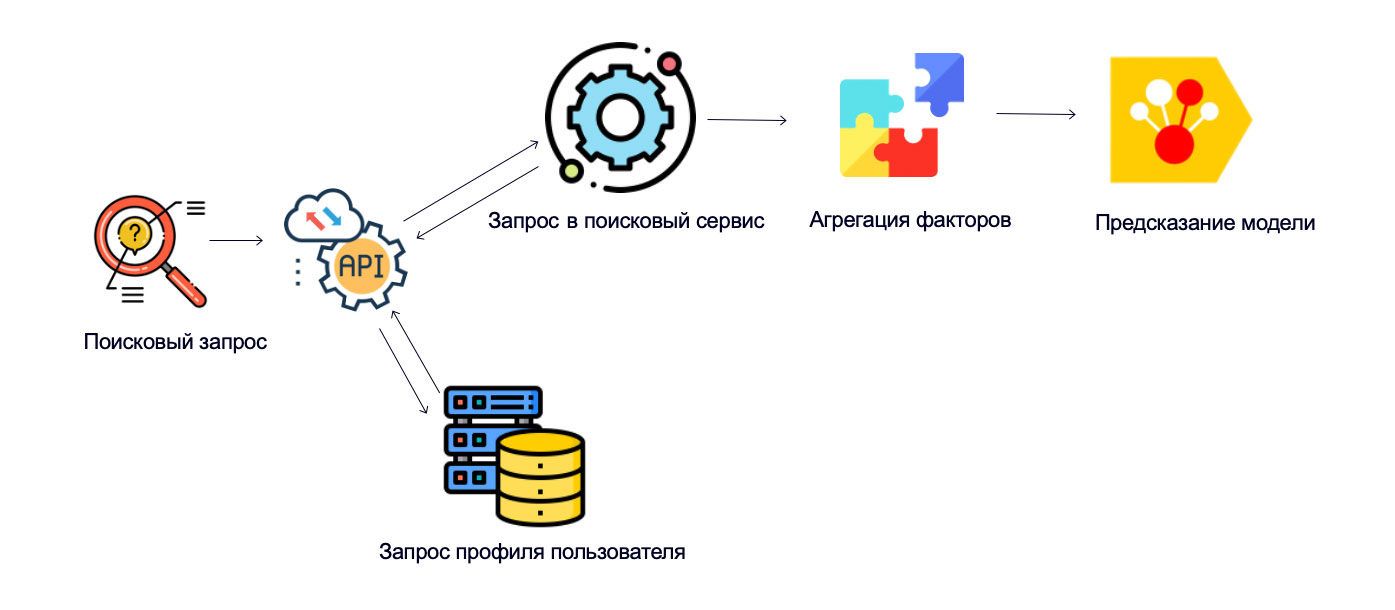
Профиль пользователя — важная инженерная компонента, которая позволяет персонализировать ранжирование. Он представляет из себя структуру, в которой лежат хэшированные идентификаторы пользователя и различные метаданные, включая счётчики пользователя по разным типам событий. Например, один из счётчиков показывает, сколько раз человек кликал по автомобилям с типом кузова седан.
У активного пользователя профиль может быть большим и тяжелым — важно уметь обрабатывать такие сценарии. Необходимо следить, чтобы профиль сильно не разрастался, иначе пострадает скорость работы сервиса. Для этого можно удалять самые старые события, накладывать ограничения на размер профиля и на число событий, которые можно хранить. В рантайме профиль передаётся строкой в формате Base64.
Факторы ранжирования доставляются в модель из разных источников. Персональные факторы достаются из профиля пользователя, контентные факторы про объявления (тип кузова, марка, модель) — из поискового индекса. Статистические факторы тоже хранятся в поисковом индексе и обновляются отдельным регулярным процессом. Каждые 30 минут запускается процесс, чтобы на основе свежих данных пересчитать все ключевые статистики для каждого объявления. Подсчитанные результаты складываются в таблицу, которая и доставляется в поисковый индекс.
Схема доставки персональной модели в продакшен
Персональная модель — ключевая компонента в ранжировании. Больше всего мы экспериментируем именно с ней, поэтому важно, чтобы процесс выкатки модели в эксперимент занимал мало времени и работал стабильно.
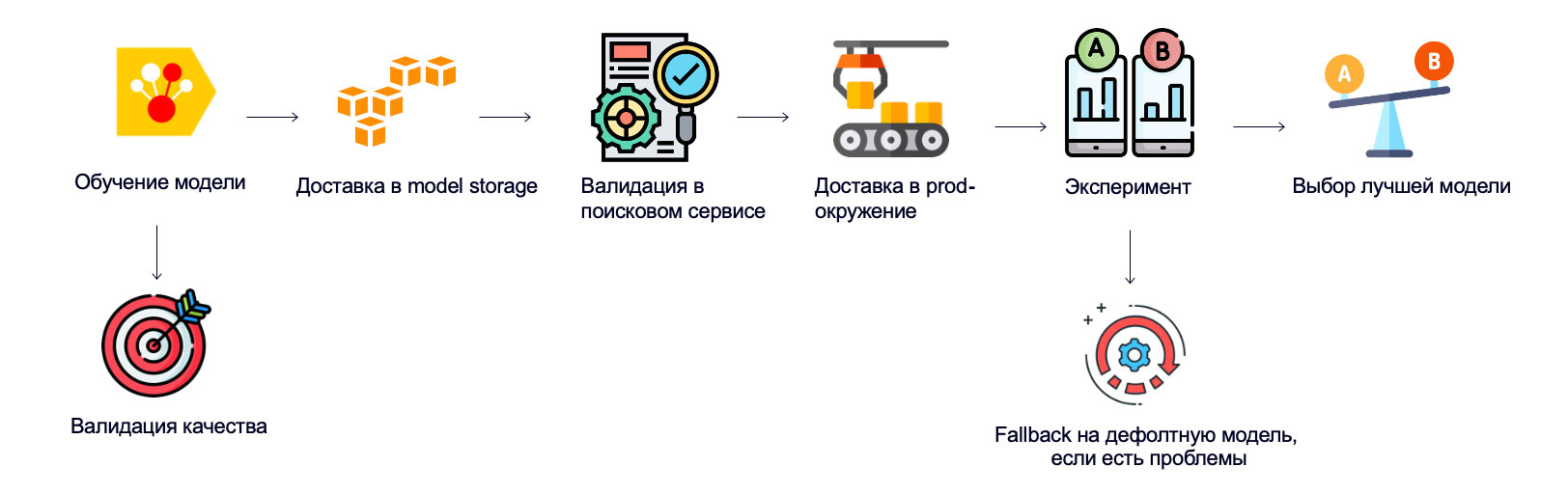
После обучения модель загружается в объектное хранилище S3, затем поисковый сервис с помощью автоматизированной регулярной задачи обнаруживает, что появилась новая модель, подбирает её и запускает процесс валидации модели, который включает в себя проверку наличия необходимых факторов для применения модели в продакшен-окружении и делает прочие health checks. Если проверка прошла успешно, то модель доставляется в продакшен-окружение, после чего можно завести эксперимент с моделью на платформе А/Б-тестирования и наблюдать за результатами. Если же что-то пойдёт не так, у нас есть механизм отката на стабильную версию модели.
Как не просадить тайминги рантайма поиска
Применение персональной модели на каждый поисковый запрос — дело затратное. Если применять её на десятки тысяч объявлений, удовлетворяющих критерию поискового запроса, то пока пользователь будет ждать ответ от поиска, он успеет забыть, что хотел, и уйдёт.
Для решения этой проблемы мы используем двухэтапный процесс ранжирования. На первом этапе применяется легковесная неперсональная CatBoost-модель, которая предсказывает вероятность звонка по объявлению с учётом его контентных факторов. Такой модели не нужны факторы пользователя (которые можно получить только в рантайме), поэтому предсказания для неё можно рассчитать заранее и закэшировать в поисковом индексе. В момент поискового запроса объявления сортируются сперва по предсказанию неперсональной модели — вероятность звонка.
На втором этапе мы возьмём топ-800 объявлений по этим вероятностям и переранжируем их персональной моделью. Таким образом неперсональная модель имитирует отбор кандидатов, для которых мы применим персональную модель.
Пользователи нечасто скроллят до конца выдачи, поэтому нам важно, чтобы именно в топе были наиболее релевантные объявления. Применить персональную модель для топ-800 объявлений оказывается вполне достаточно. Объявления, не попавшие в топ-800, останутся в хвосте выдачи как есть. В результате качество ранжирования не страдает, а время ответа поиска для большинства запросов не превышает 100 мс.
Дизайн экспериментов
Правильный дизайн экспериментов не менее важен, чем хорошая модель. Как только мы обучили модель, мы оцениваем её качество на тестовой выборке. Если по метрикам качества ранжирования (NDCG, MAP, MRR) модель выглядит перспективно, то мы запускаем А/Б-тест — так мы оцениваем модель на реальных пользователях и измеряем финальный продуктовый эффект от внедрения. Несколько ключевых правил, которыми мы руководствуемся при проведении экспериментов:
- Формулируем чёткие ожидания от гипотезы: какие метрики должны вырасти, а какие нет, и почему.
- Фиксируем время эксперимента и не принимаем решения до его окончания.
- Следим, чтобы наша модель не ухудшала общие критически важные метрики сервиса.
- Заводим отдельные эксперименты на разных платформах.
- При принятии решений руководствуемся статистическими критериями.
- Документируем лог релизов и экспериментов с ключевыми выводами.
Несмотря на следование этим правилам, при проверке гипотез мы периодически получали результаты, которые тяжело проинтерпретировать. Допустим, наша цель — улучшить качество ранжирования в срезе по автодилерам. Для этого объявления дилеров сильнее взвешиваются в обучающей выборке и строится отдельная модель с учётом желаемого эффекта, но по результатам А/Б-теста метрики в срезе по дилерам, наоборот, падают. Приведу ещё один пример. Допустим, мы строим модель ранжирования в срезе по новым автомобилям, раскатываем в А/Б-тест, видим, что кликать по объявлениям с новыми автомобилями начали больше, однако наблюдаем нежелательный эффект — падают метрики в срезе по подержанным автомобилям. Получается, мы сделали настолько хорошее ранжирование в новых авто, что подержанные теперь никому не нужны? :) Искать причинно-следственные связи в таких гипотезах бывает сложно.
Итак, одна из особенностей и ключевая сложность экспериментов с ранжированием в Авто.ру — это необходимость работать над улучшением метрик, которые могут противоречить друг другу. С точки зрения математики мы имеем дело с задачей мультикритериальной оптимизации, которую не всегда удаётся решить оптимально — и это нормально. Ранжирование — сложный инструмент, любое изменение может отразиться на разных метриках. Поэтому нужно следить за многими метриками — не только за теми, на которые эксперимент, как ожидается, повлияет в первую очередь.
Результаты
Активное развитие проекта пришлось на последние полгода. Мы провели более двадцати экспериментов и улучшили ряд ключевых продуктовых метрик — сначала в срезе поиска по подержанным автомобилям, а затем и в срезе по новым. Внедрение машинного обучения позволило на 5% увеличить число переходов в карточки объявлений. Выросли метрики поискового сценария: на 4% выросла средняя позиция первого клика, на 5% выросла доля кликов в топ-5 по выдачам (с поправкой на то, что на разных платформах результаты были немного разными). При этом сократилось число поисковых сессий — это значит, что новые алгоритмы ранжирования позволяют пользователям быстрее находить то, что им нужно, и реже возникает необходимость переформулировать поисковый запрос.
Рост метрик на условные 5%, на первый взгляд, сложно назвать большим — но только не в нашем случае. Ещё до внедрения машинного обучения мы проверяли много гипотез, внедряли разные эвристики, которые заметно улучшили качество ранжирования. Как только стало невозможно расти дальше с помощью простых правил и эвристик, мы перешли к персонализации с помощью ML. На наших объёмах польза от таких внедрений очень ощутима.
Заключение
Когда речь заходит о внедрении машинного обучения, часто бывает сложно оценить потенциальный эффект от ML и определиться, стоит ли игра свеч. Существует немало историй, когда машинное обучение внедряли туда, где можно было обойтись простыми эвристиками и получить результат не хуже, а порой и лучше. При обсуждении плана проекта у нас тоже были опасения, что мы потратим кучу ресурсов в никуда. Мнения коллег сперва разделились, но совместными усилиями с помощью аналитики и обсуждения продуктовых сценариев поиска Авто.ру мы решили, что верим в гипотезу о персонализации поиска и, как оказалось, не прогадали. Сегодня мы внедряем ML-ранжирование во все контуры поиска Авто.ру.
По пути мы, конечно, много раз ошибались и выучили несколько уроков. Во-первых, как бы банально это ни звучало, важно не опускать руки после неудачных экспериментов. Первые два месяца мы проверяли гипотезы как будто вслепую. Результаты нас не устраивали, и было непонятно, куда двигаться дальше. Мы пробовали разные подходы, анализировали результаты, и со временем ситуация прояснилась.
Во-вторых, важно следить за тем, чтобы с инженерной точки зрения инфраструктура проекта была на хорошем уровне. Например, логирование и мониторинг качества моделей, процессы доставки моделей в продакшен, версионирование моделей и процессы с данными. Последнее особенно важно — мы потратили много ресурсов на построение качественного типизированного лога с данными событий пользователей. Это упростило процессы сбора обучающих выборок для ML-моделей, а также стало проще анализировать результаты экспериментов. Если вы начинаете делать новый ML-проект, сперва надо подготовить для него инфраструктуру, иначе есть риск, что эксперименты будут срываться в неожиданных местах, а решать проблемы на ходу станет тяжелее.
Комментарии (4)

s37
17.08.2022 14:55Основная проблема поиска на Авто.ру заключается в том, что большинство продавцов, вероятно, не продают машины, а только показывают, как рыбов из мема. Очень часто при подборах для выставления фильтра приходится делать его заведомо менее точным, т.е. брать более широкую выборку, в расчете на ошибочное описание со стороны продавца (двигатель, привод, кпп, количество мест и т.п.), и чем дальше транспортное средство от категории легковых тем печальнее ситуация.
Было бы замечательно, если бы ваша команда бросила силы на улучшение качества самих объявлений, например, сопоставление введенной информации с VIN или аналогичными объявлениями. По моему мнению это сделало бы поиск намного более точным.
P.S.: а если бы для коммерческой техники был введен такой критерий как модель двигателя то было бы вообще замечательно!

ieBoytsov Автор
17.08.2022 15:59Спасибо большое за обратную связь! Подумаем над улучшением качества поиска в контуре нелегковой и коммерческой техники! И про фильтр по модели двигателя тоже интересное предложение!
TiesP
Можно же раньше заканчивать… в соответствии с критерием Вальда. Чего сидеть и ждать-то?
ieBoytsov Автор
Действительно, есть статистические критерии и подходы к a/b тестированию, когда не нужно фиксировать диапазон и можно динамически принимать решение. Такие подходы хороши, но иногда они требуют более тонких настроек и бОльших знаний о природе и распределении данных, чтобы с достаточной надежностью оценивать результаты экспериментов. Исходя из особенностей наших экспериментов нам удобно использовать фиксированный горизонт, который берется из расчета примерного объема наблюдений, необходимых для получения статистически-значимых результатов.