
В данной статье (будет состоять из двух частей) хотел бы кратко пройтись по основным технологиям стекирования коммутаторов Cisco. Попробуем разобраться с общей архитектурой передачи пакетов в рамках каждого типа стека, реакцией на отказы, а также с цифрами пропускной способности. В первой части мы рассмотрим технологии StackWise и StackWise Plus. Во второй части — StackWise-160, StackWise-480, FlexStack и FlexStack Plus.
Сейчас функционалом стекирования никого не удивишь. Он есть во многих моделях коммутаторов различных производителей, в том числе и у Cisco. Но так было не всегда. На заре моей карьеры (где-то середина двухтысячных) в области сетевых технологий в портфеле компании Cisco был всего один коммутатор с поддержкой полноценного стека. Это была модель коммутатора Cisco 3750. Псевдо стеки на базе 2950 и 3550 в ту пору уже практически умерли. На тот момент меня, как молодого специалиста, очень удивлял факт того, что вопросу стекирования коммутаторов компанией Cisco уделялось так мало внимания. При этом, например, у коммутаторов 3com (прим. куплен компанией HP), которые в то время были достаточно популярны, стекирование поддерживалось достаточно на большом перечне моделей. Также обстояли дела и у Allied Telesis. Я даже помню, как приверженцы продукции Cisco мне объясняли, что стекирование – это плохо, и в продакшене данную технологию не стоит использовать. Жаль, уже не помню точных формулировок, но речь шла вроде о стабильности работы. Стоит заметить, что в то время основными доводами в пользу стекирование было упрощение управления (во всяком случае, на тот момент мне казалось именно так). Т.е. вместо того, чтобы настраивать отдельно два или более устройства, стек даёт нам возможность получить один большой коммутатор.
Шло время. Многие осознали плюсы стекирования. И сейчас большая часть коммутаторов Cisco поддерживет данную технологию. В настоящее время, говоря о стекировании, стоит разделять стек на уровне доступа (там, где подключаем обычных пользователей) и стек во всех остальных случаях.
В первом случае основной причиной объединения коммутаторов в стек является упрощение администрирования. В какой-то момент времени мне даже стало казаться, что это уже совсем не актуально и является больше маркетинговым моментом. Но не так давно в общении с заказчиком, у которого большой парк
Во всех остальных случаях, на мой взгляд, основным «за» в пользу стека стала возможность организации относительно недорогой схемы отказоустойчивости в сети (как на уровне ядра сети, так и при подключении серверного оборудования). Стек позволяет нам агрегировать физические каналы, заведённые на разные коммутаторы, в один логический. Это обеспечивает нас не только большей пропускной способностью (за счёт утилизации одновременно нескольких каналов) и отказоустойчивостью (выход из строя одного из коммутаторов стека не приведёт к остановке сети), но и в ряде случаев даёт возможность полностью отказаться от петель. А значит от использования протоколов семейства STP. Т.е. упрощает жизнь, делая топологию сети достаточно простой.
На оборудовании Cisco в зависимости от платформы используются несколько технологий стекирования. Небольшое замечание. Рассматривать будем классические схемы стекирования. Технология VSS останется за кадром.
| Технология | Платформа | Кол-во коммутаторов в стеке | Общая пропускная способность стековой шины | Необходимость стекового комплекта |
|---|---|---|---|---|
| StackWise | 3750, 3750G | 9 | 32 Гбит/с | Нет |
| StackWise Plus | 3750-E, 3750-X | 9 | 64 Гбит/с | Нет |
| StackWise-160 | 3650 | 9 | 160 Гбит/с | Да |
| StackWise-480 | 3850 | 9 | 480 Гбит/с | Нет |
| FlexStack | 2960-S, 2960-SF | 4 | 40 Гбит/с | Да |
| FlexStack Plus | 2960-X, 2960-XR | 8 | 80 Гбит/с | Да |
StackWise
Рассмотрим технологию StackWise. Она является самой пожилой среди остальных. Для соединения коммутаторов в стек по технологии StackWise используется специализированный стековый кабель. При этом отдельного стекового модуля нет, стековые порты сразу встроены в коммутатор (по два порта).

Пропускная способность стекового кабеля 16 Гбит/с (в каждую сторону). Так как на каждом коммутаторе два стековых порта, пропускная способность стековой шины должна равняться:
16 Гбит/с * 2 (в каждую сторону) * 2 (количество портов) = 64 Гбит/с
Смотрим в спецификацию, а там 32 Гбит/с. Куда делась половина пропускной способности?
В коммутаторах 3750 (3750v2) и 3750G отсутствует как таковая выделенная внутренняя коммутационная фабрика (используется старая архитектура shared-ring switch fabric). Стековые порты подключаются напрямую к внутренней шине коммутатора, становясь её продолжением. Таким образом, коммутаторы одного стека имеют одну большую шину в виде кольца. Данная шина на логическом уровне представляет собой два пути в виде кольца каждый.
Пропускная способность каждого из них — 16 Гбит/с. Эти пути разнонаправленные: пакеты по ним передаются в противоположные стороны. Так как мы имеем общую шину на весь стек, пакет, попав на порт любого коммутатора стека, обязательно пройдёт не только через все внутренние ASIC’и, но и через всё кольцо стека, даже если исходящий порт находится на том же коммутаторе, что и входящий. Причём пакет будет убран с шины, только когда он пройдёт весь круг и вернётся обратно. Это позволяет ASIC’у, который «захватил» один из путей, узнать о том, что пакет дошёл и путь можно освобождать. Такой алгоритм работы можно называть «удаление отправителем» (в терминах Cisco — Source stripped). Выбор пути, по которому отправить пакет, определяется исходя из доступности каждого из них (используется механизм токенов: тот ASIC, который обладает токеном, передаёт данные).
Давайте рассмотрим это на примере (Рис. 2). В нашем случае пакет, попав на порт коммутатора (1), попадает на ASIC, который в свою очередь выбирает синий путь (2) (допустим, он был свободен в этот момент). Далее пакет по синему пути проходит через все коммутаторы (3), попадая в итоге на тот коммутатор, где находится порт назначения (4). Коммутатор отправляет копию пакета (5) через свой локальный порт. Но сам пакет продолжает своё путешествие по стековому кольцу (6), пока не достигнет ASIC’а, который его изначально отправил (7). Только там он будет удалён со стековой шины.
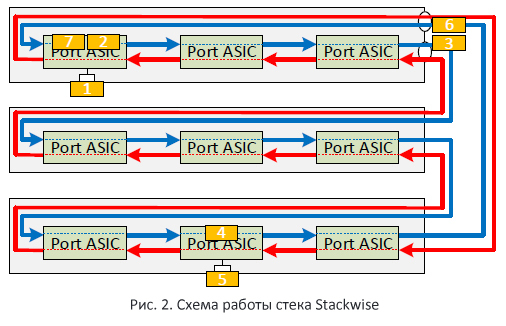
Таким образом, один и тот же пакет проходит 2 раза через стековые порты коммутатора (сначала через один (3), потом через второй (6) порты). А значит наша общая полезная пропускная способность стековой шины равна 32 Гбит/с (ровно в два раза меньше физической).
А, что будет если один из коммутаторов стека откажет? В этом случае пути замкнутся друг на друга, тем самым образуя одно большое кольцо (Рис. 3). Ровным счётом также поведут себя коммутаторы в случае, если будет отключён один из стековых кабелей.
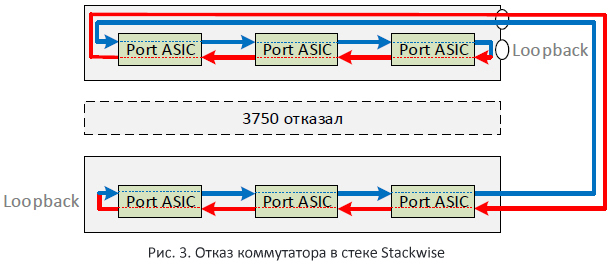
Стоит отметить ещё два момента. Два пути «крутятся» в разные стороны. Предполагаю, что это сделано для усреднения задержки передачи пакетов внутри стека. Второй момент заключается в том, что для Stackwise пропускная способность стековой шины равна общей производительности стека, в силу того, что все коммутаторы в стеке используют одну общую шину.
StackWise Plus
Перейдём к технологии StackWise Plus. В коммутаторах 3750E и 3750X была добавлена выделенная коммутационная фабрика (switch fabric). Это позволяет делать локальную коммутацию пакетов без их появления в стековом кольце. Стековые порты заводятся непосредственно на коммутационную фабрику. Теперь за логику работы со стековой шиной отвечает непосредственно коммутационная фабрика. В случае технологии StackWise со стековой шиной работал каждый ASIC отдельно.
В технологии StackWise Plus был использован новый алгоритм обработки пакетов в стеке – «удаление получателем» (в терминах Cisco — Destination stripped, ещё одно наименование Spatial reuse). В данном алгоритме пакет удаляется со стековой шины сразу же, как только он достиг коммутатора, на котором находится исходящий порт (Рис. 4). Теперь для сигнализации о том, что путь можно освобождать используется маленький Ack пакет (8 бит).

Как и в технологии Stackwise, логически у нас остаётся два пути. Но так как теперь за работу со стековым кольцом отвечает коммутационная фабрика, механизм работы с этими путями усложнился. Как и раньше доступ к тому или иному пути осуществляет с помощью механизма токенов. Получив токен, коммутационная фабрика может передавать пакеты по стековому кольцу. А так как непосредственно пакеты забираются с каждого ASIC’а, за порядок обслуживания каждого ASIC’a отвечает механизм кредитов. Их раздаёт коммутационная фабрика.
Эти новшества позволили увеличить пропускную способность стековой шины до маркетинговых 64 Гбит/с, прировняв полезную пропускную способность к физической. Теперь пакет проходит только один раз через стековый порт коммутатора. Хотел бы обратить внимание, что в обоих технологиях (Stackwise и StackWise Plus) используются одни и те же типы стековых кабелей.
Тут стоит подчеркнуть, что пропускная способность стековой шины не стала равна 64 Гбит/с, она стала стремиться к этой цифре. Почему? Причина в том, что весь трафик broadcast, multicast и unknown unicast продолжает обрабатываться по алгоритму Source stripped. Т.е. эти типы трафика проходят всё кольцо, прежде чем будут удалены со стековой шины. А значит на данные типы трафика расходуется двойная пропускная способность.
В одном стеке допускается использование любых коммутаторов серии 3750. Если в один стек добавить, например, коммутаторы 3750v2 (поддерживают StackWise) и 3750X (StackWise Plus), стек будет работать по технологии StackWise (алгоритм Source stripped). При этом для 3750X коммутация пакетов между локальными портами будет осуществляться только внутри коммутатора без появления на стековой шине. Для коммутаторов 3750v2 пакеты между локальными портами по старинке будут проходить через всю стековую шину.
Давайте кратко коснёмся схемы работы стека на программном уровне. В рамках стека StackWise или StackWise Plus один из коммутаторов выбирается в качестве мастера (stack master). Он выполняет логические операции (control-plane) для всего стека. При его отказе передача unicast трафика продолжается. Это достигается благодаря синхронизации аппаратных таблиц. Между коммутаторами стека синхронизируются MAC-таблица, а также таблицы Cisco Express Forwarding (CEF), а именно FIB и Adjacency table. А вот остальные таблицы, в том числе таблица маршрутизации, таблица передачи multicast трафика, на новом мастере заполняются заново. При этом возможно использование функционала NSF — Nonstop Forwarding. Т.е. control-plane на новом мастере запускается с нуля.
На этом предлагаю прерваться. Продолжение появится в ближайшие дни.?
Комментарии (5)
JDima
28.10.2015 18:27+1>Я даже помню, как приверженцы продукции Cisco мне объясняли, что стекирование – это плохо, и в продакшене данную технологию не стоит использовать. Жаль, уже не помню точных формулировок, но речь шла вроде о стабильности работы.
Ну еще бы. Проблема-то как была, так и осталась, и да, в большинстве реалистичных сценариев стекирование решительно невозможно использовать в продакшне (исключения — либо нулевая критичность сервиса, либо наличие рядом второго стека для резервирования).
А заключается проблема в том, что вы создаете громадную единую точку отказа там, где ее раньше не было. Вы взяли два резервирующих друг друга свитча и превратили их в один свитч с одним control plane. А в control plane в любой момент времени найдется много интереснейших багов. В результате тот несчастный, кто решил объединить важные железки в стек, будет бояться даже смотреть в их сторону, чтобы не попадали разом.
Ходят слухи, что кто-то когда-то слышал о существовании человека, работавшего со стеками и не разу не обжигавшегося на них, но я в такие мифы не верю. Лично меня уже подводили и стеки на 3750, и VSS на 6500. Под «подводили» подразумеваю «без стека сбой либо не произошел бы, либо не оказал бы заметного влияния на сервис».
>Между коммутаторами стека синхронизируются MAC-таблица, а также таблицы Cisco Express Forwarding (CEF), а именно FIB и Adjacency table.
И синхронизации тоже зло, потому что где синхронизации, там и разные любопытные рассинхронизации. Самое надежное решение — самое простое. Например, банальный ECMP роутинг между тупейшими свитчами с централизованным форвардингом. Или что-то вроде TRILL (блин, циска, дай уже FP на каталистах!). Даже STP кольцо лучше стека в плане надежности.
ksg222
28.10.2015 21:09Позволю себе чуточку не согласится. На данный момент технологии стекирования достаточно хорошо отработаны. Конечно же, они тоже могут сбоить. Но что не сбоит? У меня как-то четырёхпортовый неуправляемый коммутатор решил, что он «звезда сети», и стал отвечать на все подряд ARP запросы. Поэтому даже если мы разнесём control-plane по разным железкам (например, будем использовать vPC или vPC+), мы всё равно не получаем пилюлю от всех проблем. Тут стоит смотреть больше на то, как часто происходят такие сбои. Лично из своего опыта чаще всего такие стеки (Stackwise и др.) вредничали в основном в моменты обслуживания (например, замены IOS и пр.). При этом большую часть времени никаких претензий к их работе не было.
Безусловно, использовать стекирование в сетях, где требуется минимальное время простоя, не стоит. Для построения таких сетей есть специальные гайды (предлагающие использовать всякие там Nexus’ы, полностью маршрутизируемые сети и пр.), которые выливаются в немаленькие суммы. Но для большинства самых обычных сетей, таких требований нет. При этом цена вопроса является определяющей. И вот тут-то стек, например, на базе 3750X вполне подойдёт.
Что касается вопроса, что лучше: использовать STP или использовать стек. Тут я придерживаюсь второго варианта. Скажем так, дело вкуса. Думаю, обсуждать плюсы/минусы каждого варианта не стоит. Они хорошо известны. Скажу только, что появление технологий стекирования на большинстве коммутаторов наводит на мысль, что второй подход предпочтителен не только для меня.JDima
28.10.2015 22:06+1>На данный момент технологии стекирования достаточно хорошо отработаны.
Это не имеет значения. Софт модульных свитчей тоже хорошо обкатан. И модульный свитч всегда остается единой точкой отказа, даже с двумя супами в SSO, и в нем очень много чего периодически ломается. Стек мало чем принципиально отличается от модульного свитча.
>даже если мы разнесём control-plane по разным железкам (например, будем использовать vPC или vPC+), мы всё равно не получаем пилюлю от всех проблем.
Именно так. vPC жутко уязвим к одинаковым багам одинаковых устройств с одинаковым софтом и одинаковым конфигом. Но это уже шаг в правильную сторону, при правильной топологии одно устройство легко и без влияния на сервис изолируется. Ну и в целом софт NX-OS куда стабильнее IOS.
>Лично из своего опыта чаще всего такие стеки (Stackwise и др.) вредничали в основном в моменты обслуживания
Именно поэтому я и говорю, что администратор будет откладывать кирпичи при одной мысли о каких-то махинациях со стеком. Поведение STP намного предсказуемее — протокол проще, его код по большей части давно отлажен, ничего нового там не происходит. А главное — риски меньше.
Да и вообще говоря большинство багов выстреливает в момент внесения изменения или вскоре после него, остальное — в основном утечки памяти.
> Скажу только, что появление технологий стекирования на большинстве коммутаторов наводит на мысль, что второй подход предпочтителен не только для меня.
Фичи появляются благодаря спросу, циска очень часто реализует хотелки крупных заказчиков. Раньше вы делали обзор OTV. Это — монстр, которого не должно существовать, потому что не должно существовать задачи, которую он решает (L2 между несколькими локациями с большим числом нод на каждой — фу-фу-фу). Но он есть. Кто-то даже пользуется. Зуб даю, что из этих «кто-то» 90% забыли сначала подумать, надо ли оно им вообще, а после внедрения периодически ругаются матом.
gotch
Спасибо, познавательная статья. Было бы удобно, если бы вы добавили в конец пару ссылок на вендорские материалы, если захочется почитать чего-то еще на эту тему.
ksg222
Есть неплохая статья на сайте Cisco. Но более глубокая информация была взята из различных презентаций компании Cisco с таких мероприятий, как Cisco Live, Networkers и пр.