
В этом году мы опубликовали две статьи, связанные со сравнением функциональности маршрутизаторов и межсетевых экранов компании Cisco, а также с обзором разделения control и data plane в сетевом оборудовании. В комментариях к этим статьям был затронут вопрос производительности сетевого оборудования. А именно как зависит производительность маршрутизаторов Cisco разных поколений от включения на них тех или иных сервисов. Так же обсуждалась тема производительности межсетевых экранов Cisco ASA. В связи с этим возникло желание посмотреть на эти вопросы с практической стороны, подкрепив известные моменты цифрами. О том, что получилось и, что получилось не очень, расскажу под катом.
Под производительностью будем подразумевать пропускную способность устройства, измеряемую в Мбит/с. Стенд для тестирования представлял из себя два ноутбука, с установленной программой iPerf3. Методика испытания – достаточно проста. iPerf3 запускался в режиме передачи пакетов по протоколу TCP. Использовалось 5 потоков. Я не ставил перед собой цели определить реальную производительность устройств. Для этой задачи необходима более сложная экипировка, так как требуется воссоздавать паттерны трафика реальной сети. Да и мерить нужно было бы количество обрабатываемых пакетов. У нас же основной задачей была оценка влияния использования различных сервисов на работу устройства, а также сравнение результатов, полученных на различных устройствах. Таким образом, выбранный инструментарий на первый взгляд казался достаточно подходящим для поставленных задач.
Cisco Integrated Services Router (ISR) Generation 1 и 2
Для начала из коробки были взяты два младших маршрутизатора Cisco 871 и 881. Это маршрутизаторы разных поколений (871 более старый – G1, а 881 более новый – G2), которые обычно ставятся в небольшие офисы, например, в удалённые филиалы компании.
Исследуемые маршрутизаторы имеют сходные черты в плане программной и аппаратной архитектуры: операционная система – Cisco IOS, «мозг» устройств – SoC MPC 8272 в 871 и SoC MPC 8300 в 881.
Для каждого маршрутизатора проверялись следующие режимы работы:
- Маршрутизация с использованием технологии Cisco Express Forwarding (CEF).
- Маршрутизация без использования оптимизирующих технологий (Process Switching).
- Маршрутизация (CEF) и применённый список доступа (ACL) на одном из интерфейсов.
- Маршрутизация (CEF) и ACL на одном из интерфейсов с опцией log.
- Маршрутизация (CEF) и включённая служба трансляции адресов (NAT*).
- Маршрутизация (CEF) и включенные сервисы межсетевого экранирования (CBAC для 871 и ZPF для 881).
- Маршрутизация (CEF), МСЭ и NAT.
Тестирование затрагивало маршрутизацию трафика (L3-коммутацию) на базе CEF и Process Switching. Оба режима работы на исследуемых устройствах являются программной обработкой пакетов. Разница в том, как именно маршрутизатор принимает решение куда отправить пакет. В случае Process Switching маршрутизатор для каждого пакета определяет, куда его передать и формирует/модифицирует необходимые заголовки в рамках отдельного процесса на основании таблицы маршрутизации и L2-таблиц. Происходит так называемая процессорная обработка. В случае CEF маршрутизатор использует заранее подготовленные специальным образом таблицы FIB (таблица префиксов) и Adjacency (таблица данных по соседям), которые позволяют существенно снизить нагрузку на ЦПУ и повысить скорость обработки пакета внутри устройства.
Для более наглядного сравнения данные по разным устройствам нанесены на один график (рисунок 1).
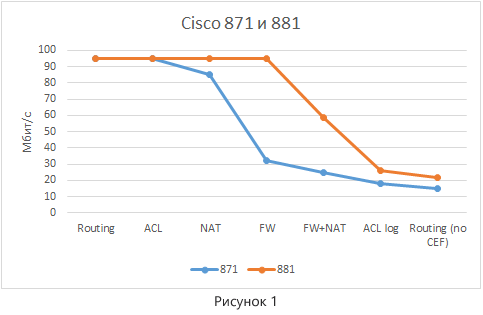
Отметим основные моменты:
- Так как интерфейсы на устройствах имеют тип FastEthernet, максимальная пропускная способность точка-точка, полученная через iPerf3, не превышала 95 Мбит/с. При этом загрузка ЦПУ для некоторых режимов тесетирования не достигала своих пиковых значений, а значит цифра 95 Мбит/с для этих маршрутизаторов не предел.
- Маршрутизатор 881 выглядит лучше, так как имеет более продвинутую аппаратную начинку (в первую очередь процессор общего назначения, далее ЦПУ).
- Как и следовало ожидать, мы видим заметную деградацию производительности при включении сервисов.
- При отключении CEF мы имеем существенное уменьшение производительности, так как маршрутизатор начинает обрабатывать каждый пакет не самым оптимальным образом.
- Включение опции log в ACL приводит к повышению нагрузки на устройство (загрузка ЦПУ в этом случае составляет 99%), что негативно сказывается на производительности. Обусловлено это тем фактом, что опция log заставляет маршрутизатор обрабатывать каждый пакет, попадающий в отмеченную строчку ACL, в режиме Process Switching, что существенно увеличивает нагрузку на процессор.
Предлагаю рассмотреть подробнее загрузку ЦПУ в случае маршрутизации в режиме CEF и Process Switching. Маршрутизация в режиме CEF:
Router881#sh processes cpu sorted
CPU utilization for five seconds: 47%/42%; one minute: 40%; five minutes: 35%
PID Runtime(ms) Invoked uSecs 5Sec 1Min 5Min TTY Process
89 143724 8597 16717 1.51% 1.42% 1.43% 0 COLLECT STAT COU
5 25792 638 40426 1.43% 0.29% 0.20% 0 Check heaps
97 45204 180099 250 0.63% 0.57% 0.47% 0 Ethernet Msec Ti
…
Общая загрузку ЦПУ составляет 47%. Из них 42% уходит на обработку прерываний, вызванных передачей пакетов. Прерывания при передаче пакетов бывают двух типов: прерывание получения и прерывание передачи пакета. Прерывание получения пакета инициируется интерфейсным процессором, когда пакет получен через интерфейс маршрутизатора и он готов к обработке. Получив такое прерывание ЦПУ прекращает обработку текущих процессов, и начинает выполнять обработку пакета. Так как включен режим CEF, ЦПУ принимает решение, куда передать пакет на основании таблиц CEF (FIB и Adjacency) во время прерывания. Т.е. ему не требуется отправлять пакет на процессорную обработку, а значит существенно экономятся процессорные мощности. В связи с этим на процессы в маршрутизаторе тратится лишь 5% загрузки ЦПУ. Прерывание отправки пакета передаётся на ЦПУ, когда пакет был отправлен интерфейсным процессором дальше по каналам связи. ЦПУ реагирует на это прерывание обновлением счётчиков и освобождением памяти, выделенной для хранения пакета. В плане вклада в общую загрузку устройства данное прерывание менее интересно.
Маршрутизация в режиме Process Switching:
Router881#sh processes cpu sorted
CPU utilization for five seconds: 99%/27%; one minute: 82%; five minutes: 48%
PID Runtime(ms) Invoked uSecs 5Sec 1Min 5Min TTY Process
129 98988 6013 16462 69.91% 55.95% 19.35% 0 IP Input
89 145568 9248 15740 1.11% 1.11% 1.33% 0 COLLECT STAT COU
97 45480 193804 234 0.23% 0.23% 0.35% 0 Ethernet Msec Ti
…
Теперь общая загрузка ЦПУ составляет 99%. Причём только 27% уходит на прерывания. Остальные 72% тратятся на выполнение процессов. Процесс IP Input забирает практически 70% процессорного времени. Именно этот процесс отвечает за процессорную обработку пакетов, т.е. тех пакетов, которые не могут быть обработаны во время прерывания (например, отключен CEF или в его таблицах нет нужной информации для передачи, пакеты адресованы непосредственно маршрутизатору или являются широковещательным трафиком и пр.). А так как в нашем примере отключены CEF и Fast Switching (об этом методе я не упоминал в силу его неактуальности), после того как к ЦПУ пришло прерывание получения пакета, ЦПУ отправляет пакет на процессорную обработку. Прерывание завершается и ЦПУ обрабатывает пакет непосредственно в рамках одного из своих процессов. Поэтому мы и видим такую утилизацию ЦПУ процессом IP Input.
Ещё интересно будет посмотреть на загрузку ЦПУ в случае ACL с опцией log.
Router881#sh processes cpu sorted
CPU utilization for five seconds: 99%/37%; one minute: 80%; five minutes: 52%
PID Runtime(ms) Invoked uSecs 5Sec 1Min 5Min TTY Process
129 297672 15360 19379 60.83% 48.79% 29.67% 0 IP Input
89 150496 10973 13715 0.72% 0.93% 1.22% 0 COLLECT STAT COU
97 46036 232697 197 0.16% 0.17% 0.21% 0 Ethernet Msec Ti
…
Опция log в ACL заставляет маршрутизатор каждый пакеты отправлять на процессорную обработку, признаком чего, как и в предыдущем примере, является высокая утилизация ЦПУ процессом IP Input.
Cisco ASA 5500
Давайте посмотрим теперь на такое устройство как межсетевой экран Cisco ASA 5505. Можно сказать, что ASA 5505 – это аналогичное маршрутизатору Cisco 881 устройство в плане позиционирования (для небольших офисов и филиалов). Эти устройства примерно из одного ценового сегмента и обладают относительно сходными аппаратными характеристиками. В ASA 5505 используется ЦПУ AMD Geode с тактовой частотой 500 MHz. Самое главное отличие –операционная система. В ASA 5505 используется ASA OS. Про различия между маршрутизаторами и ASA в плане функциональности мы говорили в отдельной статье. Посмотрим теперь на производительность ASA и влияния на неё различных сервисов.
Так как на ASA нет чистой маршрутизации и каких-то выделенных технологий оптимизации маршрутизации трафика, проверялись лишь следующие режимы работы:
- Межсетевой экран.
- Межсетевой экран и включённая служба трансляции адресов (NAT).
- Межсетевой экран и ACL на одном из интерфейсов с опцией log.
Для более наглядного сравнения данные по таким устройствам как ASA 5505 и маршрутизатор 881 нанесены на один график (рисунок 2).
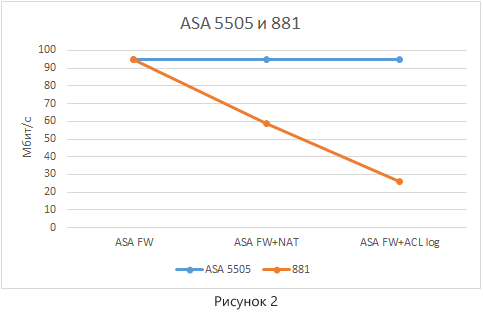
Из диаграммы видно, пропускная способность ASA 5505 во всех режимах работы ограничена лишь техническими аспектами стенда. Причём, если мы посмотрим на загрузку ЦПУ, то для всех вариантов она практически идентична:
cbs-asa-vpn# sh proc cpu-usage non-zero sorted
PC Thread 5Sec 1Min 5Min Process
0x082a2849 0xa86e0994 31.1% 25.4% 13.4% Dispatch Unit
0x09bcebdb 0xa86d094c 6.4% 5.1% 5.9% esw_stats
0x08e68295 0xa86ced10 0.2% 0.1% 0.2% ci/console
0x0919171d 0xa86c9404 0.2% 0.2% 0.2% IP SLA Mon Event Processor
0x08f0591c 0xa86ce68c 0.1% 0.1% 0.1% update_cpu_usage
Можно сделать следующие выводы:
- При относительно схожих ценовых и аппаратных параметрах ASA 5505 предоставляет большую производительность, чем маршрутизатор 881.
- Производительность ASA практически не зависит от сервисов (во всяком случае в рамках данного стенда её выявить не удалось).
- Опция логирования (log) в ACL не приводит к деградации производительности. Обусловлено этой спецификой реализаций функции маршрутизации в устройстве.
Таким образом, операционная система ASA OS кажется более сбалансированной в плане влияния сервисов на производительность устройства.
Cisco ISR 4000
Идём дальше. Предлагаю посмотреть, как обстоят дела с влиянием сервисов на производительность маршрутизаторов Cisco ISR 4000. Это самая новая линейка маршрутизаторов Cisco для небольших и средних инсталляций. Как мы помним, в этих маршрутизаторах используется операционная система Cisco IOS XE, которая умеет работать в многопоточном режиме. С точки зрения аппаратной начинки, в этих маршрутизаторах используются многоядерные процессоры.
И так достаём из коробки самый младший Cisco ISR 4000 – 4321. Активируем на нём performance license, чтобы получить заявленную максимальную производительность 100 Мбит/с, и начинаем тестировать. Важно отметить, что на маршрутизаторах ISR 4000 всегда используется шейпер, ограничивающий максимальную производительность устройства. Используется два порога: базовая (для 4321 – это 50 Мбит/с) и расширенная (для 4321 – это 100 Мбит/с; активируется лицензией performance license) производительности. Такая схема работы направлена на получение прогнозируемых значений производительности устройства, не позволяя «захлёбывать» от большого количества трафика.
Для начала проверяем производительность чистой маршрутизации в режиме CEF без дополнительных сервисов. Запускаем iPerf3 и получаем 95 Мбит/с. Ожидаемо. Смотрим в этот момент на загрузку ЦПУ:
cbs-rtr-4321#show proc cpu sorted
CPU utilization for five seconds: 1%/0%; one minute: 1%; five minutes: 1%
PID Runtime(ms) Invoked uSecs 5Sec 1Min 5Min TTY Process
658 8563421 409607083 20 0.47% 0.48% 0.48% 0 IP SLAs XOS Even
79 1123726 12408975 90 0.15% 0.06% 0.07% 0 IOSD ipc task
2 120745 326115 370 0.07% 0.00% 0.00% 0 Load Meter
667 420 1850 227 0.07% 0.03% 0.04% 2 SSH Process
…
Вот это результат! Загрузка ЦПУ 1%. Круто! Но не всё так идеально. Понимание данного феномена приходит после более детального изучения специфики работы IOS XE.
IOS XE – это операционная система, созданная на базе Linux’а, тщательно допиленного и оптимизированного вендором. Традиционная операционная система Cisco IOS запускается в виде отдельного Linux процесса (IOSd). Самое интересное заключается в том, что в IOS XE мы имеем отдельный основной процесс, выполняющий функции data plane. Т.е. мы имеем чёткое разделение control и data plane на программном уровне. Процесс, отвечающий за control plane, называется linux_iosd-imag. Это собственно и есть привычным нам IOS. Процесс, отвечающий за data plane, называется qfp-ucode-utah. QFP, знакомо? Сразу вспоминаем про сетевой процессор QuantumFlow Processor в маршрутизаторах ASR 1000. Так как изначально IOS XE появился именно на этих маршрутизаторах, процесс, отвечающий за передачу пакетов, получил аббревиатуру qfp в своём названии. В дальнейшем для ISR 4000, видимо, ничего менять не стали, с одной лишь разницей, что в ISR 4000 QFP является виртуальным (выполняется на отдельных ядрах процессора общего назначения). Кроме озвученных процессов в IOS XE присутствуют и другие вспомогательные процессы.
Таким образом, чтобы посмотреть на сколько загружены процессорные мощности, анализируем вывод следующих команд, специфичных для IOS XE:
cbs-rtr-4321#show platform software status control-processor brief
Load Average
Slot Status 1-Min 5-Min 15-Min
RP0 Healthy 1.14 1.05 1.01
Memory (kB)
Slot Status Total Used (Pct) Free (Pct) Committed (Pct)
RP0 Healthy 3950540 3888836 (98%) 61704 ( 2%) 2517892 (64%)
CPU Utilization
Slot CPU User System Nice Idle IRQ SIRQ IOwait
RP0 0 5.28 10.57 0.00 79.84 4.19 0.09 0.00
1 1.80 1.60 0.00 95.99 0.50 0.10 0.00
2 41.00 2.70 0.00 56.30 0.00 0.00 0.00
3 23.02 76.97 0.00 0.00 0.00 0.00 0.00
В нашем маршрутизаторе используется четыре ядра (CPU 0, 1, 2, и 3). Команда позволяет нам получить информацию по загрузке каждого из них.
Примечание
Увидеть аппаратную начинку маршрутизатора можно выводом стандартной для Linux информации из файла dmesg: more flash:/tracelogs/dmesg.
В маршрутизаторе ISR 4321 используется процессор:
CPU0: Intel® Atom(TM) CPU C2558 @ 2.40GHz stepping 08
Следующая команда позволяет нам увидеть утилизацию процессорных мощностей различными процессами:
cbs-rtr-4321#show platform software process slot RP active monitor cycles 1 interval 1 top - 15:03:45 up 18 days, 21:00, 0 users, load average: 1.13, 1.05, 1.01
Tasks: 316 total, 2 running, 314 sleeping, 0 stopped, 0 zombie
Cpu(s): 8.8%us, 22.3%sy, 0.0%ni, 68.8%id, 0.0%wa, 0.1%hi, 0.0%si, 0.0%st
Mem: 3950540k total, 3889372k used, 61168k free, 199752k buffers
Swap: 0k total, 0k used, 0k free, 1608388k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
3111 root 20 0 1041m 589m 333m S 150 15.3 28747:48 qfp-ucode-utah
1915 root 20 0 1957m 182m 124m S 10 4.7 2216:08 fman_fp_image
22575 root 20 0 360m 74m 30m S 2 1.9 392:16.70 bsm
23130 root 20 0 46828 25m 11m S 2 0.7 23:08.43 cmand
26108 root 20 0 2378m 896m 374m S 2 23.2 881:05.01 linux_iosd-imag
27088 root 20 0 2204 1096 728 R 2 0.0 0:00.02 top
1 root 20 0 1820 520 440 S 0 0.0 0:10.97 init
2 root 20 0 0 0 0 S 0 0.0 0:00.00 kthreadd
…
В данном примере, IOS съедает всего 2%, а QFP – 150% (что эквивалентно утилизации одно ядра полностью и ещё одного на половину).
Так, что же в итоге показывает тогда команда «show processes cpu»? Она выводит загрузку виртуального ЦПУ, который был выделен процессу IOSd. Под данный процесс на маршрутизаторах ISR 4000 выделяется одно из ядер ЦПУ.
Из всего этого можно сделать вывод, что в IOS XE архитектура обработки пакетов существенно изменилась по сравнению с обычным IOS. IOS больше не занимается обработкой абсолютно всех пакетов. Данным процессом обрабатываются лишь те пакеты, которые требуют процессорной обработки. Но даже в этом случае в IOS XE используется более новый механизм Fastpath, который реализует передачу пакетов для процессорной обработки посредствам отдельного потока внутри IOSd, а не через прерывания. Прерывания в IOSd возникают только, когда не возможна обработка через Fastpath.
Вернёмся к нашей задаче. Проверим следующие режимы работы:
- Маршрутизация с использованием технологии CEF.
- Маршрутизация и применённый список доступа (ACL) на одном из интерфейсов.
- Маршрутизация (CEF) и ACL на одном из интерфейсов с опцией log.
- Маршрутизация (CEF) и включённая служба трансляции адресов NAT.
- Маршрутизация (CEF) и включенные сервисы межсетевого экранирования (ZPF).
- Маршрутизация (CEF), МСЭ и NAT.
Необходимо отметить, что отключить CEF на 4321 (да и на всей линейке ISR 4000) нельзя. Теперь это базовая технология маршрутизации.
Результаты тестирования представлены на рисунке 3. Для большей наглядности на один график нанесены значения пропускной способности (а они у нас во всех случаях одинаковы) и загрузку ЦПУ процессом QFP. Процесс IOSd не интересен в силу того, что во всех режимах загрузка виртуального ЦПУ внутри IOSd минимальна – 1%.
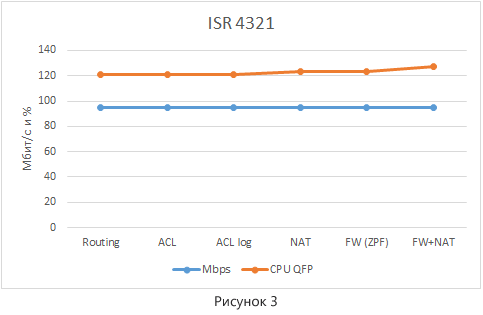
При проведении тестирования выявить зависимость производительности маршрутизатора ISR 4321 от включения сервисов не удалось. Есть небольшое повышение загрузки CPU, но совсем незначительное. Также стоит отметить, что включение опции log в ACL больше не приводит к драматическим потерям в производительности, так как пакет не отправляется на процессорную обработку.
Итоги
На примере нескольких устройств разных поколений и типов мы попытались рассмотреть, как зависит производительность от включения различных сервисов. В целом полученные результаты укладываются в ранее известные факты. Америки мы не открыли. Краткие выводы, полученные в результате тестирования, можно сформулировать так:
- Происходит существенная деградация производительности маршрутизаторов ISR G1 и G2 при включении сервисов.
- Производительность ASA менее подвержена влиянию сервисов. При сравнимой цене с маршрутизатором мы получаем большую производительность.
- Влияние включения сервисов на производительность ISR 4000 минимальна.
Спасибо за внимание. Надеюсь, что какая-то информация из статьи поможет в работе с оборудованием Cisco.
Комментарии (42)

Ivan_83
22.06.2016 17:18«Под производительностью будем подразумевать пропускную способность устройства, измеряемую в Мбит/с.» — это хорошо для маркетингового материала.
Для реальных применений считают в пакетах в секунду и никак иначе.
«Я не ставил перед собой цели определить реальную производительность устройств.» — Зачем тогда вообще было фигнёй страдать?
«Для этой задачи необходима более сложная экипировка, так как требуется воссоздавать паттерны трафика реальной сети.»
Любая генерилка мелких пакетов, вероятно iperf тоже умеет мелкие пакеты.
Паттерны не столь важны, дальше L4 железка всё равно не смотрит, а с таким Iperf справится.
Обе железки с рис1 не смогут дать 100 мегабит пакетами по 64 байта.
Если пересчитать данные с рисунка 1 для NAT+FW, то получится: 2,56 мегабита вместо 60 и 1,12 мегабита вместо 25.
Современные домашние мыльницы от длинка натят быстрее чем 871 за счёт аппаратного ната.
ksg222
22.06.2016 18:28+2Мне казалось, я достаточно ясно обозначил цель данной статьи. И она заключается совсем не в определении реальной производительности. Основная идея — определить, как падает производительность при включении тех или иных сервисов на разных устройствах. Поэтому за предложение измерять производительность в пакетах размером 64 байта в секунду, конечно, спасибо, но в данном контексте — это не очень важно (вроде бы, об этом я тоже постарался написать в самой статье).
Паттерны не столь важны
Если мы ставим цель получить реальную производительность, совсем не уверен, что будет достаточно её замерить на маленьких пакетах одного из сетевых протоколов. В реальной сети бегает всё-таки разный трафик.
… дальше L4 железка всё равно не смотрит...
Например, межсетевой экран смотрит иногда и выше при анализе приложений. А есть и другие функции, которые туда же заглядывают (например, NBAR)…
Современные домашние мыльницы от длинка натят быстрее чем 871 за счёт аппаратного ната.
А Вы уверены, что там реализация NAT аппаратная? Не подскажите, как именно и на чём происходит данная аппаратная обработка?Ivan_83
22.06.2016 20:25-1Производительность с пакетах отражает реальное положение вещей, а именно позволяет узнать сколько в худшем случае пролезет трафика.
Если бы вместо iperf был торрент клиент и соединений 50-100 на закачку то железки показали бы меньше.
А так вы их в тепличных условиях гоняли, когда они показывают максимум, который в реале редко бывает, это не интересно.
Для свичей и многих других железок производительность указывают именно в пакетах.
Да, я уверен что у дешман длинка есть аппаратный NAT оффлоад.
Чипы rt3050, rt3052 его имеют, они были в дир620 и ещё каких то ревизиях дир300 уже года 4 назад.
В более современных часто есть медиатеки тоже с аппаратным оффлоадом, но такие железки чуть дороже.
В ещё более дорогих Asus RT-56U которым уже лет 5 как тоже аппаратный оффлоад, и они более пол гига выжимают точно.
А для линуха на атоме 2,4ггц 100-200 мегабит роутинга+фаера это фейл, он должен больше гига легко переваривать.
2 htol:
Меня кошки вообще не интересуют, но про 871 я слышал что старьё :)
Вместо кошки я предпочитаю писюки с фрёй.
Спидтест — это для домохозяек, стыдно товарищ!
Хабы не выпускают с начала 200х, и на них не было ни шейперов ни даже полисеров, зато были коллизии.
Пророутить/натить с фаером и даже ппп больше сотки да ещё и большим пакетами сейчас может любой домашний роутер средней ценовой категории, это вообще ни разу не достижение. Это не было достижением и лет 5 назад для роутеров выше средней ценовой категории.
Микротик (оно там глючное, но вроде как есть), эджроутер.
Можно и на Asus RT-56U на альтернативной прошивке всё это поднять, хотя я не любитель таких железок — предпочитаю х86.
Про телефонию не оч понятно, но астериск/фрисвич легко поднимается даже на всяком барахле, не говоря о х86.
А WiFi 2/5 Ггц AC в ваших кошках есть? :)
navion
22.06.2016 22:29+1У SOHO есть проблема с количеством одновременных соединений, так что в офисе им всё равно не место.
А настоящие тесты делала сама Киска, плюс Fedia с товарищами вроде гонял какой-то навороченный стенд.Ivan_83
22.06.2016 23:55-1Припоминаю в моём первом АДСЛ мопеде было ограничение в 100 одновременных соединений, он был 2006 года если не раньше.
В RT-56U 16384 соединения держит аппаратный нат, программный походу больше.
Всякие микротыки скорее всего ограничены памятью доступной, те никак не меньше 10-20к, думаю они раньше на лукапе в контрак таблице загнутся чем память кончится :)
Притом по ссылке кошки 8хх держат от 300 до 1100 соединений.
На практике в офисе средний комп вряд ли держит более 10 соединений в инет постоянно, те 1000 соединений хватит на 100 включённых компов. Это уже не маленький такой офис.
Думаю мой домашний экономный роутер на дешман проце амд ам1 легко потягается с 2951, и вероятно 3945 при наличии 1гбх4 или 10г адаптера. :)
По IPSec точно порвёт: AES-NI сильно больше 1 гигабита выдаёт, даже в один поток.
Вот настоящая киска и написала там kpps в самой первой таблике, дальше там только таблица с соединениями фаера и конектами впн интересны.

INSTE
23.06.2016 14:16ZyXEL Keenetic Ultra II мало того, что поддерживает 16384 сессий в аппаратном NAT (который работает на уровне гигабитного свича, то есть сетевые карты устройства даже не видят обрабатываемых им пакетов кроме keep-alive и некоторых специфичных навроде TCP SYN/RST), так и имеет два уровня программного ускорения обработки трафика: на одном из них пакеты обрабатываются и отправляются сразу в контексте NAPI сетевой карты, полностью минуя весь сетевой стек, в другом минуют весь путь через netfilter, проходя от цепочки PREROUTING сразу в POSTROUTING.
В последних двух режимах полностью поддерживается шейпер и приоритезация, а также ускорение PPPoE/PPTP/L2TP-туннелей.
Плюс ко всему он имеет 256 Мбайт DDR2 и два ядра по 880 МГц, и в теории размер conntrack-таблицы неограничен.
Ну и напоследок: компонент IPsec в сочетании с аппаратным обработчиком ESP пакетов позволяет прокачивать до 350 Мбит/сек в режиме ESP AES/SHA1.
На фоне этого предложенные здесь Cisco с точки зрения именно скорости являются странным выбором.
dukzcry
27.06.2016 12:40Линейка Keenetic вообще могучий оплот русско-китайской дружбы. Прошивку, говорят, наши писали. Есть ли у зукселя что-нибудь эквивалентное для рынков других стран?
INSTE
27.06.2016 15:43Почему говорят, пишем и продолжаем писать. :)
Пока неизвестно, подобные решения о выпуске устройств для других стран принимает руководство в Тайване, но они еще думают.

htol
23.06.2016 00:12+1VPN hub же, или Вы все же не в теме совсем? Больше 100 мбит/с на ipsec это повод для гордости, а не стыда. Даже если спидтест.
В свое время заменил большущий кластер на фре из 20 машин делавших нат, на два маршрутизатора, которые заняли в разы меньше места и по потрблению электричества сильно выигрывали. Так что это всего лишь вопрос денег, задач и квалификации.
А на счет ISR, до сих пор нет конкуретнов по количеству фич в одной коробке. У cisco один из самых лучших радиотрактов для wifi в мире. AC есть уже очень давно. Почитайте например про CleanAir. Или про то, что делает Мираки. Ну тут я сильно спорить не буду, знаю как минимум еще двух хороших производителей. Да и я больше про датацентры, чем про радио.
click0
23.06.2016 00:21-1Не рассказывайте сказки.
Dell PowerEdge r710 с 10Г сетевыми под FreeBSD 10.3 тащит 10Г ната в среднестатистической домашней сети на просторах РФ.
Пара таких железок (для резервирования) дешевле раз в 10 Cisco аналоги :)
А wifi каким вы боком к статье приплели?htol
23.06.2016 00:42+1Про wifi отвечал Ивану.
Интересно сколько сессий на сервер, вдруг придется вспоминать молодость? Я несколькими сессиями с сервера и 80гигабит выжимал. Сейчас конечно многое поменялось. Но тогда 10-гб серваки не умели, либо стоили как круизные лайнеры. А в 2006 уже далеко не одну 10-ку утилизировал. Сервера в лучшем случае 800 мбит прокачивали и умириали от прерываний даже при настроенном пулинге, т.е. один сервер на одну задачу. Про остальные задачи я уже молчу.
А сколько надо парится чтобы получить полноценный BRAS на таком решении? На сколько все сильно станет хуже, если добавить фаервол, инспецию трафика, шейперы/полисеры/маркирование? Решение уже не кажется таким уж дешевым. Сейчас и с отказоусточивостью получше конечно на серверах, а тогда в лучшем случае кривой CARP с кучей ограничений. Так что тут не до сказок. В статье восновном старье кроме ISR4k. Вот я и сравниваю с тем что было тогда.click0
23.06.2016 01:08В 2006 году, в типовой домовой сети/ISP РФ, а их тогда было за 85%, траффика в ЧНН было в лучшем случае — 400-600Mbps.
htol
23.06.2016 01:30Ну что же, значит я был не просто в топе, а в элите. Кстати проникновением в 45% мог тоже не каждый похвастаться, а в 8 году примерно продались акаде :(
Ivan_83
23.06.2016 02:04-1Надо писать понятнее, я же не кошковод и сленга не знаю.
Я тут видел производителей софта, которые 100+ гигабит натят на х86 под линухом, но линух там чисто для запуска их софтины и общих задач.
Так что может пора менять кошек на отечественного производителя софта?)
Может и хороший и но сильно у кошак всё дорого, и искусственные лимиты-лицензии мягко говоря расстраивают жабу.
Да и конкуренты есть в лице жунипера и хуавея, с низу ещё эджроутер с длинками бизнес серии, а в самом низу микротики.
Вафля меня интересует пока исключительно как хомяка.
И оно было в контексте того что описанное в тестах легко заменяется роутером среднего — выше среднего ценового диапазона + там ещё и вафля приличная.
2 click0:
Про вафлю это я написал.
А вот пакетики в ядре фри и юзерспейсе я молотил своим софтом, потому производительность в мегабитах меня возмутила.
JackMonterey
23.06.2016 09:51Я бы еще предложил бы посмотреть на производительность NAT в плане количества соединений, устанавливаемых в единицу времени. в программной реализации ната почти наверняка используется хэш табличка, которая хранит информацию о соединениях, было бы интересно посмотреть, как много поточный программный QFP справляется с добавлением в нее записей на лету, а не только в начале тестирования.
Вообще, когда мы тестировали производительность разных программных реализаций маршрутизаторов, наблюдали, что у некоторых есть некий интервал (минимальное количество потоков; максимальное количество потоков), при котором наблюдается максимальная производительность, а выход за границы приводит к скачкообразному падению производительности.
dukzcry
27.06.2016 09:28> Да, я уверен что у дешман длинка есть аппаратный NAT оффлоад.
Источник не укажете? Как-то удивительно, чтоб длинк стал морочиться с добавлением поддержки аппаратных обработчиков в прошивку для устройств низшего сегмента.INSTE
27.06.2016 12:04Обязательно стал бы.
Сейчас все провайдеры поголовно используют spirent для тестирования, а пройти его без аппаратного ната практически невозможно.
А провайдерский кастомный рынок — основной для dlink.dukzcry
27.06.2016 12:39Ivan_83 рассказывает про SOHO, мой вопрос ему также был про пользовательское оборудование.
dukzcry
27.06.2016 12:44+1Нагуглил сам. В том же упомянутом им DIR-620 офлоада в родной прошивке нет. Нужно шить стороннюю.
INSTE
27.06.2016 15:46Сочетание символов «DIR-620» не говорит вообще ни о чем, кроме того, что это устройство с 2 MIMO WiFi антеннами и USB-портом.
Ревизия-то какая? Русская прошивка или нет?
htol
22.06.2016 19:36Обе железки с рис1 не смогут дать 100 мегабит пакетами по 64 байта.
Если пересчитать данные с рисунка 1 для NAT+FW, то получится: 2,56 мегабита вместо 60 и 1,12 мегабита вместо 25.
Современные домашние мыльницы от длинка натят быстрее чем 871 за счёт аппаратного ната.
Обе представленные 800-е совсем древние. 871 — умерла больше года назад. Была актуальна на конец 2000-x. 881 доживает последние денечки. Разработчиками уже года два не поддерживается. И говорить про эти две модели практически прошлого века нет ни какого смысла. Посмотрите на NITRO, будете приятно удивлены. VPN до амса спидтест показал больше 100Мбит/с. Показал бы еще больше, но на хабе шейпер.
Ну и если пошло сравнение. Покажите мне домашнюю мыльницу с ospf/bgp/mpls/sip/h323/snmp/trunk/sub interfaces и прочим.
beerchaser
22.06.2016 23:37Mikrotik hap lite. Цена-2 круб.
Если менее бюджетно — Microtik hap ac lite — 3.8 круб., но 2.4+5htol
22.06.2016 23:54В нем точно нет fxo/fxs. Я это к чему. Такой концентрации фич больше нет ни где, и это факт.
beerchaser
23.06.2016 00:37Cisco 881/871 — мы точно про домашние мыльницы говорим?
Каждая фича-бюджет. Если учесть, что для юриков 2 Мбит/с ~6 круб/мес с НДС, то встает вопрос — какая целевая аудитория у этих устройств?
«Для Атоса это слишком много, для графа де лаФер — слишком мало» (С)htol
23.06.2016 00:44Мне сказали что любая мыльница уделает ISR. Я считаю, что сравнение вообще не уместно, т.к. аналогов в мире нет. Наверное надо было сразу так написать.
Petr0vich
22.06.2016 21:51-1Всё ещё 100Mbit/s :(
Я вот ищу SOHO маршрутизатор на 10 Gbit/s. NAT+FW+VPN, Ну, раз SOHO, то ему вполне позволительно 5-8 держать вместо заявленных 10.kvant21
22.06.2016 23:08+210Gpbs пока еще не SOHO сегмент, но варианты «подешевле» уже есть — от mikrotik и ubiquiti до vyatta и pfsense. Тестов внятных нет (чтобы с сервисами и маленькими пакетами), поддержки тоже нет, ну зато и $30K не стоят :)
Если не секрет, сколько и где вы платите за подключение, что при этом приличный маршрутизатор в бюджет не вписывается?Petr0vich
22.06.2016 23:37Где — Киев. Сколько: $500 за предоплаченный гигабит зарубежа, и до 10Gbit/s внутриукраинского трафика. Как раз Mikrotik это все это сейчас и принимает. Но там много нюансов. Начиная от того, что ipsec на Mikrotik, в самом лучшем случае, выдаст 200Mbit/s.
Да, ситуация, пока больше напоминает сферический конь в вакууме. Столько интернета пока не нужно в реальности. Но, одного гигабитпа маловато, а следующий интерфейс по скорости — 10.
А вариант подключить, скажем, филиал транспортом, без интернета, на скорости 10Gbit/s еще дешевле, стоит в пределах $100-$200 в месяц. Бюджет понятие растяжимое, можно поставить железку и стоимостью $10K, но зачем она нужна для простенького фаервола и одного VPN подключения.kvant21
22.06.2016 23:55+1Хорошие цены :) Это всё на колокациях?
Я бы наверное в такой ситуации попробовал запустить pfsense на каком-нибудь из верхних Xeon E3. Лично не использовал, но отзывов слышал хороших много, и под задачу идеально вписывается, мне кажется. IPsec там работает с AES-NI, так что тоже проблем не должно быть.
kvant21
22.06.2016 22:15Спасибо, познавательно. А у вас был старый Cisco 881 или новый C881? Железо разное, насколько мне известно.
Вот всё хорошо с ASAми, но за routed порты в 5506 руки бы оторвать причастным :)ksg222
22.06.2016 22:36Тестировался старый cisco881-k9. Оперативной памяти точно больше в c881-k9. А вот информацию по процессору получить из sh ver не удалось. По идее, должен быть более свежим.
kvant21
22.06.2016 23:17Помнится, на какой-то из сессий Cisco Live по ISRам выступающий недвусмысленно намекал, что вы, мол, не на номер по старшинству модели смотрите, а на год выпуска, т.к. процессор там будет совсем другой. И даже что, мол, если свежие 800е с 1900ми сравните, можете удивиться. На слайдах этого не было, но вслух было сказано именно так.
Хотя, конкретно по процессору в C881 у меня информации тоже нет. Будет на руках несколько штук через месяц, попробую померять интереса ради. У вас в iperf какие ключи были выставлены, помимо tcp и пяти потоков?

tom_alex
23.06.2016 09:51Много 881-х, и судя по регулярному обновлению (возможно развитию) софта вроде не умирает пока модель. Да и в наличии они всегда есть, следовательно производят.
Description: UNIVERSAL DATA
Release: 15.5.3M2
Release Date: 10/Feb/2016
File Name: c880data-universalk9-mz.155-3.M2.bin
Min Memory: DRAM 256 MB Flash 128 MBksg222
23.06.2016 11:25Окончание продаж 881 на данный момент не объявлено. Модель актуальна. Правда, совсем недавно вендор сообщил, что планируется к выпуску новый маршрутизатор ISR 960. Видимо, уже на базе IOS XE.
navion
23.06.2016 14:06В следующий раз хотелось бы прочитать про маршрутизацию на ASA, там ведь сделали роут-мапы и BGP. Как оно влияет на производительность?
htol
27.06.2016 14:08+1Олег Типисов про это рассказывал на Cisco Connect. Не думаю что где-то полнее найдете, да еще и на русском.
pdf
Учитывая архитектуру форвардинга ASA, pbr не долже ни как повлиять на производительность. Но можнно спросить у того же Олега на русском cisco support community. https://supportforums.cisco.com/ru/community/5686/bezopasnost-security
Darka
Странно, что IPSec не тестировали…
ksg222
IPSec тестировался. Но отсутствие лицензии HSEC для маршрутизатора 4321 наложило ограничение в виде 85 Мбит/с в одну сторону. Поэтому из итоговых данных IPSec я решил исключить. В целом IPSec ничего нового выявить не позволил. Его включение приводило к получению аналогичных результатов, как и при включении других сервисов. Росла загрузка ЦПУ. Там, где загрузка и так была большой, падала производительность.
sergrok
И все же, пожалуйста, укажите полученные вами цифры по IPSec для Cisco 871/881/ASA
ksg222
При включении IPSec на 871/881 маршрутизаторы сразу просели по ЦПУ и выдали пропускную способность в 60 Мбит/с. В ASA используется отдельный crypto engine, поэтому включение IPSec картину не изменило по сравнению с другими режимами работы. ISR 4321, как я написал, выдал около 85 Мбит/с, отсигнализировав в логах, что сработало лицензионное ограничение. При этом загрузка одного ядра ЦПУ повысилась где-то на 10% по сравнению с режимом обычной маршрутизации.