Всем привет, меня зовут Стешенко Артем. Я работаю в Data Science и также занимаюсь небольшим проектом по разработке страниц (или мультиссылок) для самозанятых.

Бизнес-задача
Перед тем как перейти к парсингу Яндекс Карт, расскажу, какую задачу я хотел решить.
Я решил узнать, кто является целевой аудиторией для сервисов мультиссылок, например Taplink. Если зайти на сайт Taplink'a[ссылка удалена модератором], то они там показывают сценарии использования сервиса и пишут о категориях клиентов, на которые они ориентируются. Это “популярные люди”, “бизнес”, “интернет-магазин” и “каждый”. На лендинге немало примеров работ для оффлайн бизнеса, поэтому появилась идея проверить, используют ли вообще эти категории бизнеса сервисы мультиссылок. И для этого пригодится информация с Яндекс Карт.

Поделим сайты на типы:
сайты на собственном домене (или сделанные в конструкторе, или разработанные самостоятельно)
сайты на домене конструктора
страницы на домене сервиса мультиссылок
последний тип организаций без сайта, но с соцсетью
Целевой аудиторией будут те организации, где последние три категории представлены в большом количестве. Почему так? Потому что компании, имеющие соцсети, развиваются, и многим из них в скором времени может понадобиться сайт. А большое количество организаций (определенной категории бизнеса), которые пользуются конструктором, говорит о том, что этому сегменту интересны сервисы мультиссылок. Бизнес со своим доменом с большой вероятностью не перейдет в Taplink.
Парсинг Карт
Перед тем, как что-то парсить, нужно узнать, есть ли у сервиса API. У Яндекс Карт оно есть, но там есть определенные ограничения. Найти XHR запросы в консоли разработчика или json‘ы в html странице мне не удалось, поэтому пришлось писать парсер на selenium и bs4.
Я разделил работу на две части. Первая: сбор ссылок на страницы организаций. Вторая: сбор информации по этим ссылкам.
Собираем ссылки организаций
LinksCollector - это сборщик ссылок, в метод run нужно передать город, район, тип организации и последний параметр type_org - это тип организации (а также папка, куда складываются ссылки)
from selenium import webdriver
from link_parser import LinksCollector
driver = webdriver.Safari()
grabber = LinksCollector(driver)
grabber.run(city='Москва', district='район Арбат', type_org_ru='Кафе', type_org='cafe')
Внутри LinksCollector: driver открывает https://yandex.ru/maps, вводит нужный запрос, собирает все организации по запросу в регионе и сохраняет.

Parser - это сборщик информации со страницы организации. В метод parse_data нужно передать список ссылок hrefs, которые мы нашли ранее и папку для сохранения информации type_org(у меня такая же, как тип организации).
from selenium import webdriver
from info_parser import Parser
driver = webdriver.Safari()
parser = Parser(driver)
parser.parse_data(
hrefs=["https://yandex.ru/maps/org/tsentr_pravovykh_konsultatsiy/1180977373/"],
type_org='cafe'
)Внутри Parser: webdriver обходит все страницы по списку и собирает следующую информацию: название, сайт, соцсети, телефон, адрес, рейтинг, время работы. Можно собирать и товары, и услуги при желании. Для моего "исследования" нужны только соцсети и сайт.
Немного аналитики
В jupyter-ноутбуке можно посмотреть на то, какие организации какие типы сайтов используют.
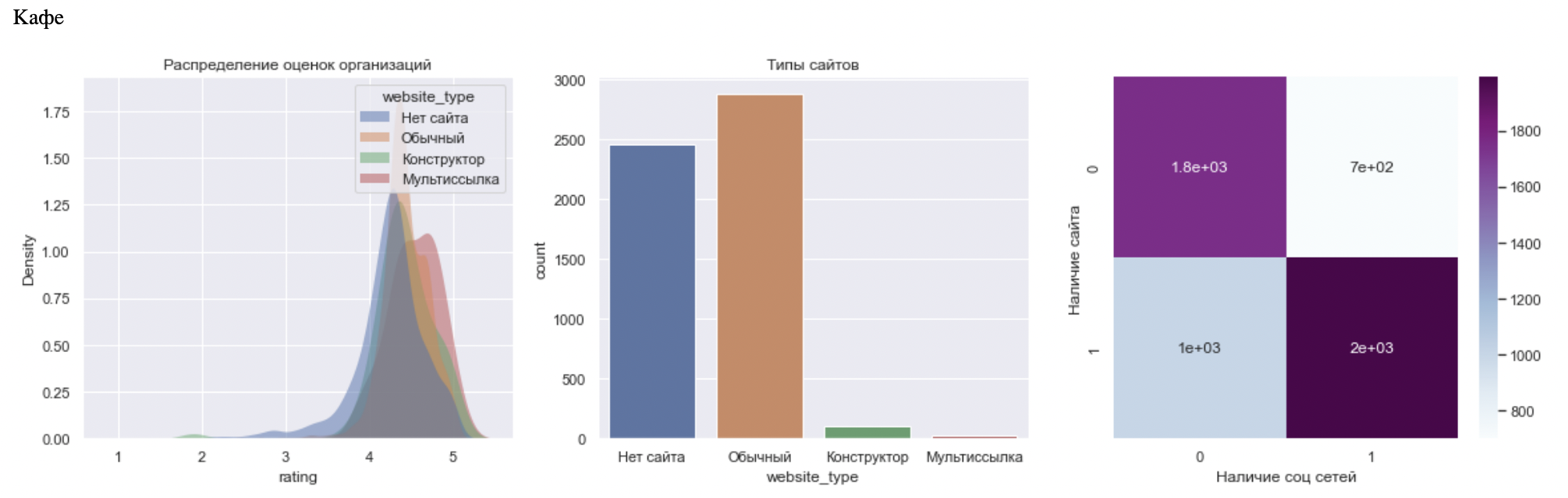
Кафе практически никогда не используют мультиссылки. Используют чаще всего сайт на своем домене или соцсети. Что логично по нескольким причинам:
Крупные сети или дорогие рестораны имеют средства на свой сайт.
Небольшим кафе проще добавлять свое меню в Яндекс Картах или постить фото в соцсети.
Поэтому сервисам мультиссылок стоит задуматься об API соцсетей и переносить посты с фото себе. Или сосредоточится на клиентах другой категории. Taplink у себя в лендинге целый раздел завел с примером кафе, хотя стоило бы сделать пример для категории, которая будет использовать сервис чаще и реально является потенциальным клиентом.

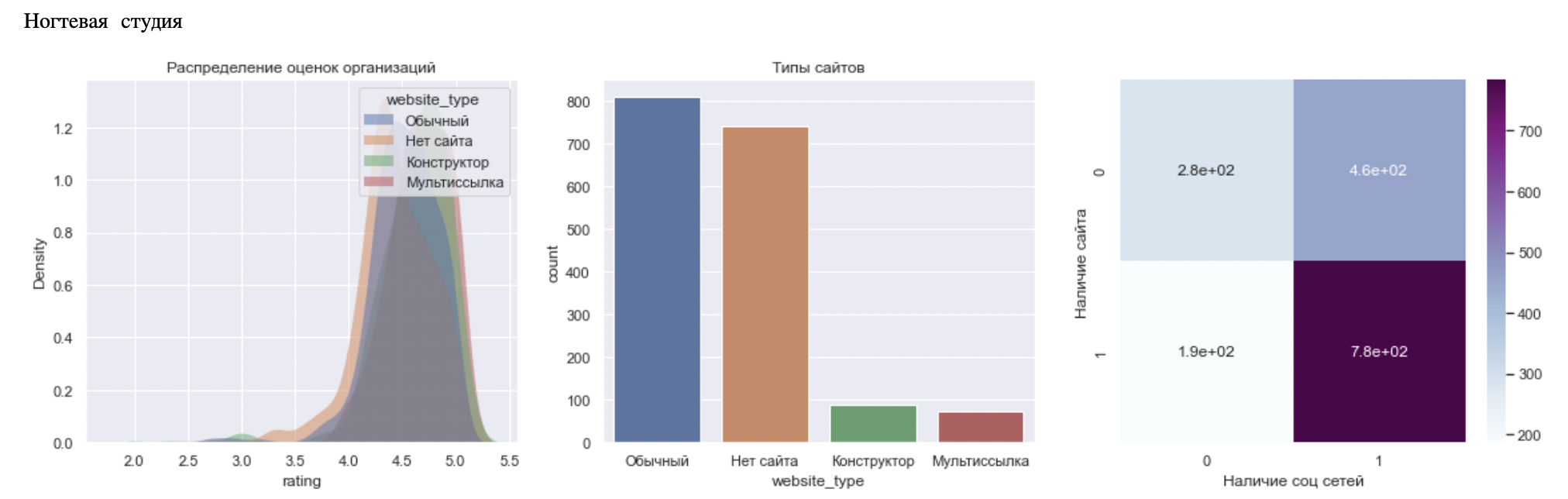
Следущая категория - это "Ногтевая студия". Почти все организации этого типа имеют соцсети, ведь нужно выкладывать фото красивых ноготочков. Но в отличие от "Кафе" некоторые имеют мультиссылки и используют их для записи в салон. Я думаю, если подумать над идеей переноса фото и постов из соцсетей, то пользователей будет больше, ведь тогда на красивые ноготочки можно будет смотреть на странице (мультиссылке).
Такие организации как "Отель", "Фитнес" делают свои сайты. "Шоурумы", как ни странно, тоже: для них важен модный дизайнерский сайт. Подробнее про то, как определялись типы сайтов, и больше аналитики можно посмотреть в ноутбуке.
Выводы
Во-первых, сбор небольшого количества данных на коленке может помочь понять: какая ваша целевая аудитория и как себя лучше позиционировать.
Просмотр их сайтов или соцсетей поможет понять, что нужно ЦА и какие фичи следует добавить, чтобы улучшить сервис.
Я надеюсь, вам понравилась статья.
Также надеюсь, что вам поможет парсер для ваших задач. Также не сомневаюсь, что многие могут написать его лучше. Тогда прошу делиться мыслями и идеями
Комментарии (12)

emaxx
25.11.2022 06:11+1И такой парсинг легален?
https://yandex.ru/legal/maps_api/ говорит:
2.3.11. ОГРАНИЧЕНИЯ. Используя Сервис, Пользователь не имеет права:
2.3.11.4. Сохранять, обрабатывать и видоизменять полученные через Сервис
Данные (включая результаты ответа на запросы Геокодирования и
Построения маршрута), за исключением случаев временного хранения
(кэширования) результатов ответа на запросы Геокодирования и Построения
маршрута исключительно для целей улучшения функциональности и
работоспособности Сервиса и только для использования в рамках
возможностей, предоставляемых Сервисом, на срок не более 30 дней.https://yandex.ru/legal/maps_termsofuse/:
4.5. Любая информация, используемая в Сервисе, предназначена
исключительно для личного некоммерческого использования. При этом любое
копирование Данных, их воспроизведение, переработка, распространение,
доведение до всеобщего сведения (опубликование) в сети Интернет, любое
использование в средствах массовой информации и/или в коммерческих целях
без предварительного письменного разрешения правообладателя
запрещается, за исключением случаев, прямо предусмотренных
функциональными возможностями сервиса, настоящими Условиями, условиями
использования других сервисов Яндекса или документами, указанными в п.
1.2. настоящих Условий.
Mirzapch
25.11.2022 06:27+4Граждане (физические лица) и организации (юридические лица) (далее - организации) вправе осуществлять поиск и получение любой информации в любых формах и из любых источников при условии соблюдения требований, установленных настоящим Федеральным законом и другими федеральными законами.
Мне кажется, этот 2.3.11.4. не имеет приоритета перед федеральным законом.
emaxx
25.11.2022 15:44Не юрист - вопрос мне самому интересный. Уточните, какой закон вы имеете в виду? И точно ли он имеет силу в случае, когда, как здесь, авторские права на данные принадлежат Яндексу (или были предоставлены ему сторонними организациями из https://yandex.ru/legal/right_holders/)?
Mirzapch
26.11.2022 02:48Авторских прав у Яндекса никто не отбирает. Но если информация доступна к просмотру, то автоматически пользователю доступно и сохранение информации. И не важно, запомнит пользователь эту информацию, или запишет. Если Яндекс не хочет чтобы информацией пользовались, пусть не распространяет её "неограниченному кругу лиц".
Сам не юрист, потому и написал, что "кажется".

alexeydg
25.11.2022 08:07+2долго такой парсер не отработает, словит каптчу, а что дальше?

Hidadmin
25.11.2022 09:47+1Видимо ничего. Дальше автор полезет в интернеты читать что такое капча и методы борьбы с ними, а потом напишет продолжение статьи)
Mirzapch
26.11.2022 02:36Года три назад парсил один из проектов Яндекса - auto.ru.
Взял Gecko, реализовал обход каталога в естественном порядке, добавил случайных таймаутов между загрузками страниц. В итоге, капчи при парсинге замечено не было. Только на этапе разработки.
Mirzapch
26.11.2022 03:52Вообще, с российскими компаниями творятся странные вещи. Лазаешь по сайту вручную - сайт подозревает, что запросы автоматические. Автоматизируешь обход сайта, и капча больше не появляется.

cry_san
25.11.2022 10:12-
driverоткрывает https://yandex.ru/maps, вводит нужный запрос, собирает все организации по запросу в регионе и сохраняет.А где пагинация результатов? Или только собирается с первой страницы выдачи?
Ну такое себе...

R_N6
25.11.2022 10:18Что то не понял по соцсети)) какой салон красоты имеет СВОЮ соцсеть и не имеет сайта??? Можно на примере что подразумевает автор говоря про соцсеть?)

tenderbender
25.11.2022 10:27Интересное исследование, спасибо.
Вы пишете, что «Бизнес со своим доменом с большой вероятностью не перейдет в Taplink», но это не так. Многие бьютики спокойно сидят на таплинк с привязанным собственным доменом. Да и на Тильду они же домен привязывают легко и непринуждённо. Есть целый пласт недорогих спецов, которые это для малого и микро-бизнеса регистрируют, оформляют и подключают.
Так что тут нужно открывать каждый линк, лезть в разметку и там смотреть, на чём написано. Вот только есть ли смысл так глубоко копать...
tempick
Спасибо за репозиторий. Но было бы интересно почитать про проблемы парсинга, нюансы и прочее. А так вся статья заключается просто в ссылке на гитхаб.