
Эта статья впервые появилась в журнале Computer и подготовлена InfoQ & IEEE Computer Society.
Теорема CAP гласит, что любая сетевая система с общими данными может иметь только два из трех желаемых свойств. Однако, работая непосредственно с разделениями, разработчики могут оптимизировать согласованность и доступность, тем самым достигая некоторого компромисса между всеми тремя.
За десятилетие, прошедшее с появления теоремы, разработчики и исследователи использовали теорему CAP (а иногда и злоупотребляли ею) как повод для изучения широкого спектра новых распределенных систем. Движение NoSQL также использовало её в качестве аргумента против традиционных баз данных.
В теореме CAP говорится, что любая сетевая система с общими данными может иметь не более двух из трех желаемых свойств:
- согласованность (С), эквивалентная наличию единственной актуальной копии данных;
- высокая доступность (A) этих данных (для обновлений); и
- устойчивость к сетевым разделениям (P).
Такое толкование CAP помогало разработчикам быть открытыми для более широкого диапазона систем и компромиссов; действительно, за последнее десятилетие возникло множество новых систем и много споров об относительных достоинствах согласованности и доступности. Формулировка «2 из 3» всегда вводила в заблуждение, поскольку имела тенденцию чрезмерно упрощать противоречия между свойствами. Но сейчас такие тонкости имеют значение. CAP запрещает лишь крошечную часть проектного пространства: идеальная доступность и согласованность при наличии разделений, которые встречаются редко.
Хотя разработчикам по-прежнему приходится выбирать между согласованностью и доступностью при наличии разделений, существует невероятная гибкость при работе с разделениями и при восстановлении после них. Современная цель CAP должна состоять в том, чтобы максимально увеличить количество комбинаций согласованности и доступности, которые имеют смысл для конкретного приложения. Такой подход включает в себя планы работы во время разделения и последующего восстановления, что помогает разработчикам думать о CAP за пределами его исторически сложившихся ограничений.
Почему «2 из 3» вводит в заблуждение
Самый простой способ понять CAP — представить себе два узла на противоположных сторонах раздела. Если разрешить хотя бы одному узлу обновлять состояние, это приведет к несогласованности узлов, что повлечет за собой потерю C. Аналогично, если выбирать сохранение согласованности, одна сторона раздела должна действовать так, как если бы она была недоступна, что ведет к потере A. И согласованность, и доступность можно сохранить только когда узлы сообщаются, что ведет к потере P. Общее мнение таково, что в глобальных системах разработчики не могут лишиться P и, следовательно, им приходится делать трудный выбор между C и A. В некотором смысле движение NoSQL связано с созданием вариантов, ориентированных в первую очередь на доступность, а затем на согласованность; базы данных, которые придерживаются свойств ACID (атомарность, согласованность, изоляция и устойчивость), делают обратное. На боковой панели «ACID, BASE и CAP» эта разница объясняется подробнее.
ACID и BASE представляют две философии разработок на противоположных концах спектра согласованности-доступности. Свойства ACID сосредоточены на согласованности и являются традиционным подходом к базам данных. Мы с коллегами создали BASE в конце 1990-х годов, чтобы охватить появляющиеся подходы к проектированию высокой доступности и четко обозначить как выбор, так и спектр. Современные крупномасштабные глобальные системы, включая облачные, используют сочетание обоих подходов.
Хотя оба термина являются скорее мнемоническими, чем точными, аббревиатура BASE (будучи второй) немного неуклюжа: в основном доступный, мягкое состояние, в конечном счете непротиворечивый (Basically Available, Soft state, Eventually consistent). Мягкое состояние и согласованность в конечном счете — это методы, которые хорошо работают при наличии разделений и, таким образом, повышают доступность.
Отношения между CAP и ACID более сложны и часто неправильно понимаются, отчасти потому, что C и A в ACID представляют разные концепции, чем те же буквы в CAP, а отчасти потому, что выбор доступности влияет только на некоторые гарантии ACID. Четыре свойства ACID:
Атомарность (А). Все системы выигрывают от атомарных операций. Когда основное внимание уделяется доступности, обе стороны разделения должны по-прежнему использовать атомарные операции. Более того, атомарные операции более высокого уровня (какие и предполагает ACID) на самом деле упрощают восстановление.
Согласованность (С). В ACID буква C означает, что транзакция сохраняет все правила базы данных, такие как уникальные ключи. А в CAP буква С относится только к согласованности единственной копии, строгому подмножеству согласованности ACID. В ACID согласованность тоже не может поддерживаться при разделении. Для восстановления раздела потребуется восстановление согласованности ACID. В более общем плане сохранение инвариантов во время разделений может оказаться невозможным, поэтому необходимо тщательно продумать, какие операции запрещать и как восстанавливать инварианты во время восстановления.
Изоляция (I). Изоляция лежит в основе теоремы CAP: если системе требуется изоляция ACID, она может работать только на одной стороне во время разделения. Упорядочиваемость в целом требует коммуникации и, следовательно, не работает при разделениях. Более слабые определения корректности применимы в условиях разделений посредством компенсации во время восстановления после разделения.
Долговечность (D). Как и в случае с атомарностью, нет причин отказываться от долговечности, хотя разработчик может предпочесть не использовать из-за ее дороговизны, выбрав мягкое состояние (в стиле BASE). Тонкость заключается в том, что во время восстановления разделения можно отменить устойчивые операции, которые по незнанию нарушили инвариант во время операции. Однако на момент восстановления, учитывая историю с обеих сторон, такие операции можно обнаружить и скорректировать. В общем, запуск транзакций ACID на каждой стороне разделения упрощает восстановление и обеспечивает структуру для компенсации транзакций, которые можно использовать для восстановления после разделения.
Фактически, именно это обсуждение привело к теореме CAP. В середине 1990-х годов мы с коллегами создавали различные территориально распределенные кластеры (по сути, ранние облачные вычисления), включая поисковые системы, прокси-кэши и системы распространения контента(1). Из-за того, что целью было получение дохода, и из-за условий контрактов доступность системы была в приоритете, поэтому мы регулярно выбирали оптимизацию доступности с помощью таких стратегий, как использование кэшей или ведение журналов обновлений для последующего согласования. Хотя эти стратегии действительно повысили доступность, выигрыш был достигнут за счет снижения согласованности.
Первая версия противостояния согласованности против доступности появилась как ACID против BASE (2), что в то время восприняли не очень хорошо, прежде всего потому, что людям нравятся свойства ACID и они не решаются отказаться от них. Цель теоремы CAP состояла в том, чтобы обосновать необходимость исследования более широкого пространства для разработок — отсюда и формулировка «2 из 3». Теорема впервые появилась осенью 1998 г. Она была опубликована в 1999 г. (3), а в 2000 г. появилась в основном докладе на Симпозиуме по принципам распределенных вычислений (4), что привело к ее доказательству.
Как поясняется на боковой панели «Недостатки CAP», точка зрения «2 из 3» вводит в заблуждение по нескольким направлениям. Во-первых, поскольку разделения встречаются редко, нет особых причин отказываться от C или A, если система не разделена. Во-вторых, выбор между С и А может происходить много раз в одной и той же системе с очень мелкой детализацией; подсистемы не только могут выбирать разные варианты, но и выбор может меняться в зависимости от операции или даже конкретных данных или вовлеченного пользователя. Наконец, все три свойства скорее непрерывны, чем бинарны. Доступность, очевидно, непрерывна от 0 до 100 процентов, но есть также много уровней согласованности, и даже у разделений есть нюансы, в том числе и разногласия внутри системы по поводу того, существует ли разделение.
Аспекты теоремы CAP часто неправильно понимаются, особенно область доступности и согласованности, что может привести к нежелательным результатам. Если пользователи вообще не могут получить доступ к обслуживанию, у них нет выбора между C и A, за исключением случаев, когда часть обслуживания выполняется на клиенте. Это исключение, широко известное как работа без подключения к сети или автономный режим (1), становится все более важным. Некоторые функции HTML5, в частности постоянное хранение на клиенте, упрощают дальнейшую работу в автономном режиме. Эти системы обычно выбирают A, а не C, и поэтому должны восстанавливаться после длительных разделений.
Область согласованности отражает идею о том, что в пределах некоторой границы состояние согласовано, но вне этой границы правила не действуют. Например, внутри основного раздела можно обеспечить полную согласованность и доступность, а вне его сервис недоступен. Paxos и атомарные многоадресные системы обычно соответствуют этому сценарию (2) В Google основной раздел обычно находится в одном центре обработки данных; однако Paxos используется на обширной территории для обеспечения глобального консенсуса, как в Chubby (3), и доступного долговременного хранилища, как в Megastore (4).
Независимые самосогласованные подмножества могут продолжать функционировать и при разделении, хотя глобальные инварианты обеспечить невозможно. Например, при шардировании, когда разработчики предварительно разделяют данные по узлам, весьма вероятно, что каждый сегмент может добиться определенного прогресса во время разделения. И наоборот, если соответствующее состояние оказалось разделенным или необходимы глобальные инварианты, то в лучшем случае только одна сторона может добиться прогресса, а в худшем случае прогресс невозможен.
Имеет ли смысл выбирать согласованность и доступность (CA) в качестве «2 из 3»? Как справедливо отмечают некоторые исследователи, неясно, что именно означает отказ от P (5, 6). Может ли разработчик отказаться от разделений? Если выбрать CA, а затем появляется разделение, то снова нужно выбирать C или A. Лучше всего думать об этом вероятностно: выбор CA должен означать, что вероятность разделения намного меньше, чем вероятность других системных сбоев, таких как аварии или множественные одновременные неисправности.
Такая точка зрения имеет смысл, потому что реальные системы при некоторых наборах ошибок теряют и С, и А, так что все три свойства являются вопросом степени. На практике большинство групп предполагает, что центр обработки данных (единственная площадка) не имеет внутренних разделений, и, таким образом, проектируют СА в пределах одной площадки; такие конструкции, в том числе традиционные базы данных, существовали по умолчанию до появления CAP. Однако несмотря на то, что разделения внутри центра обработки данных менее вероятны, они действительно возможны, отчего обеспечение CA становится проблематичным. Наконец, учитывая высокую задержку в системах с широким территориальным распределением, довольно часто в них приходится отказываться от идеальной согласованности для повышения производительности.
Ещё один недостаток CAP — это скрытая цена утраты согласованности, которая заключается в необходимости знать инварианты системы. Тонкая красота согласованной системы заключается в том, что инварианты имеют тенденцию сохраняться, даже если разработчик не знает, что они из себя представляют. Следовательно, широкий диапазон разумных инвариантов будет прекрасно работать сам по себе. И наоборот, когда разработчики выбирают вариант доступной системы, который требует восстановления инвариантов после разделения, они должны явно указать все инварианты, что одновременно сложно и подвержено ошибкам. По сути, это та же проблема параллельных обновлений, которая делает многопоточность более сложной, чем последовательное программирование.
- J. Kistler and M. Satyanarayanan, "Disconnected Operation in the Coda File System" ACM Trans. Computer Systems, Feb. 1992, pp. 3-25.
- K. Birman, Q. Huang, and D. Freedman, "Overcoming the ‘D’ in CAP: Using Isis2 to Build Locally Responsive Cloud Services," Computer, Feb. 2011, pp. 50-58.
- M. Burrows, "The Chubby Lock Service for Loosely-Coupled Distributed Systems," Proc. Symp. Operating Systems Design and Implementation (OSDI 06), Usenix, 2006, pp. 335-350.
- J. Baker et al., "Megastore: Providing Scalable, Highly Available Storage for Interactive Services," Proc. 5th Biennial Conf. Innovative Data Systems Research (CIDR 11), ACM, 2011, pp. 223-234.
- D. Abadi, "Problems with CAP, and Yahoo’s Little Known NoSQL System," DBMS Musings, blog, 23 Apr. 2010; on-line resource.
- C. Hale, "You Can’t Sacrifice Partition Tolerance," 7 Oct. 2010; on-line resource.
Изучение этих нюансов требует развития традиционного способа работы с разделениями, что является фундаментальной проблемой. Поскольку разделения встречаются редко, CAP должна допускать идеальные C и A в большинстве случаев, но когда разделения присутствуют или воспринимаются, не помешает стратегия, которая обнаруживает разделения и явным образом учитывает их в процессе работы. Эта стратегия должна состоять из трех шагов: обнаружение разделений, вход в режим явного разделения, который может ограничить некоторые операции, и запуск процесса восстановления для восстановления согласованности и компенсации ошибок, допущенных во время разделения.
Соединение с задержками CAP
В своей классической интерпретации теорема CAP игнорирует задержку, хотя на практике задержка и разделение тесно связаны. Технически суть CAP проявляется во время тайм-аута, периода, когда программа должна принять фундаментальное решение — решение о разделении:
- отменить операцию и уменьшить доступность, или
- продолжать операцию и рисковать согласованностью.
Повторная попытка установить связь для достижения согласованности, например, через Paxos или двухэтапную фиксацию, просто откладывает решение. В какой-то момент программа должна принять решение; бесконечное повторение попыток восстановления связи, по сути, означает выбор C вместо A.
Таким образом, с практической точки зрения, разделение — это временнОе ограничение связи. Неспособность достичь согласованности в течение ограниченного времени подразумевает разделение и, следовательно, выбор между C и A для этой операции. Эти концепции охватывают основную проблему разработки в отношении задержки: могут ли две разделенные стороны продолжать функционировать?
Этот прагматичный взгляд влечет за собой несколько важных последствий. Во-первых, нет глобального понятия разделения, поскольку одни узлы могут обнаружить разделение, а другие нет. Во-вторых, узлы могут обнаруживать разделение и переходить в режим разделения — это центральная часть оптимизации C и A.
Наконец, эта точка зрения означает, что разработчики могут намеренно устанавливать временные ограничения в соответствии с целевым временем отклика; системы с более жесткими границами, скорее всего, будут чаще входить в режим разделения, и даже в те моменты, когда сеть просто медленная и на самом деле не разделена.
Иногда имеет смысл отказаться от сильной C, чтобы избежать большой задержки в поддержании согласованности на больших территориях. Система Yahoo PNUTS допускает несогласованность из-за асинхронного обслуживания удаленных копий (5). Однако она делает основную копию локальной, что снижает задержку. Эта стратегия хорошо работает на практике, потому что отдельные пользовательские данные естественным образом разделяются в соответствии с (нормальным) местоположением пользователя. В идеале основные данные каждого пользователя находятся поблизости.
Facebook использует противоположную стратегию (6): основная копия всегда находится в одном месте, поэтому у удаленного пользователя обычно есть более близкая, но потенциально устаревшая копия. Однако, когда пользователи обновляют свои страницы, обновление поступает непосредственно в мастер-копию, как и все чтения пользователя в течение короткого времени, несмотря на более высокую задержку. Через 20 секунд трафик пользователя возвращается к более близкой копии, которая к тому времени должна отражать обновление.
Управление разделениями
Здесь перед разработчиками стоит непростая задача — смягчить влияние разделения на согласованность и доступность. Идея в том, чтобы очень четко управлять разделениями, контролируя не только обнаружение, но и определенный процесс восстановления и план для всех инвариантов, которые могут быть нарушены во время разделения. Такой подход к управлению состоит из трех этапов:
- обнаружить начало разделения,
- ввести явный режим разделения, который может ограничить некоторые операции, и
- запустить восстановление раздела при восстановлении связи.
Последний шаг направлен на восстановление согласованности и компенсацию ошибок, допущенных программой за время разделения системы.
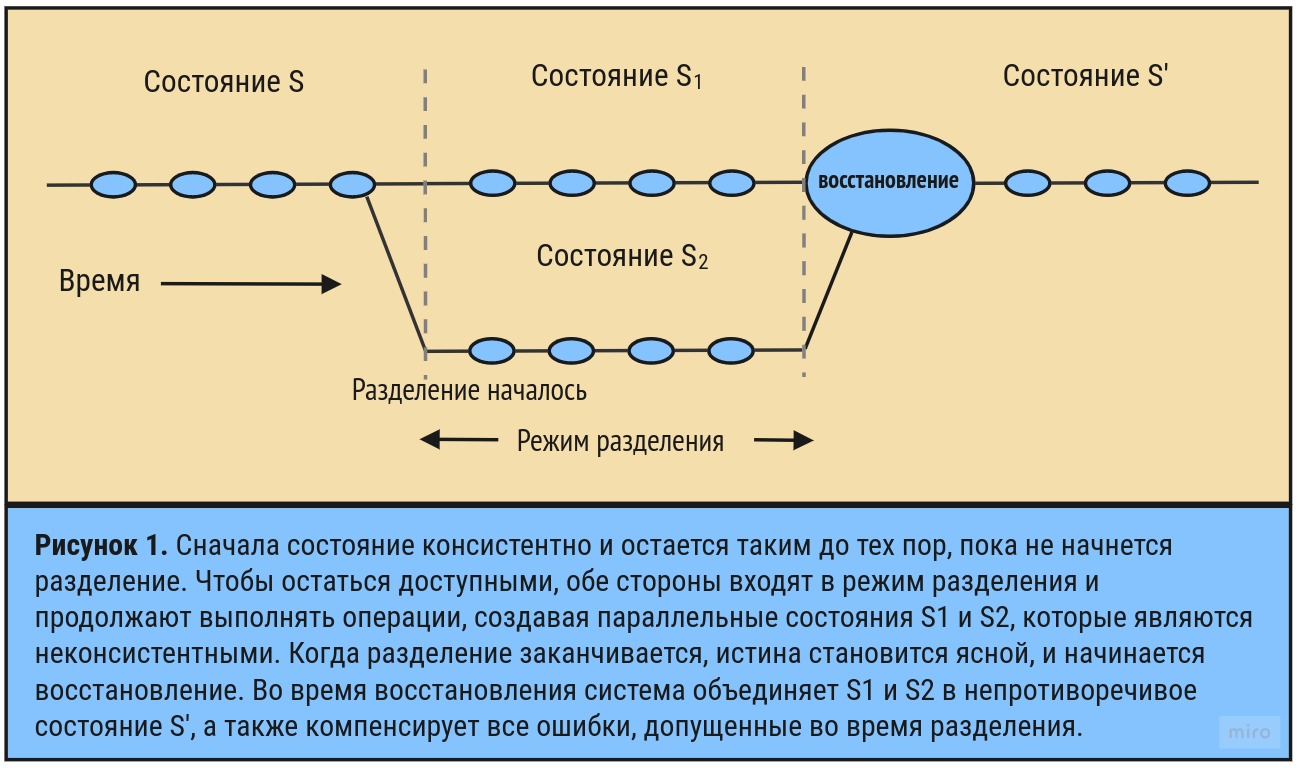
На рис. 1 показано развитие разделения. Обычная работа представляет собой последовательность атомарных операций, поэтому разделения всегда начинаются между операциями. По истечении времени ожидания система обнаруживает разделение, и обнаруживающая сторона переходит в режим разделения. Если разделение действительно существует, в этот режим входят обе стороны, но возможны и односторонние разделения. В таких случаях другая сторона поддерживает связь как положено, и либо эта сторона получает правильные ответы, либо связь не требуется; в обоих случаях операции остаются согласованными. Однако, поскольку обнаруживающая сторона могла выполнять несогласованные операции, она должна войти в режим разделения. Системы, использующие кворум, являются примером такого одностороннего разделения. Одна сторона будет иметь кворум и сможет продолжить, а другая – нет. Системы, поддерживающие автономную работу, явно имеют понятие режима разделения, как и некоторые атомарные многоадресные системы, такие как JGroups в Java.
Когда система переходит в режим разделения, возможны две стратегии. Первая — ограничить некоторые операции, тем самым снизив доступность. Вторая — записать дополнительную информацию об операциях, которая будет полезна при восстановлении после разделения. Продолжение попыток установить связь позволит системе определить, когда разделение заканчивается.
Какие операции следует продолжать?
Решение о том, какие операции ограничить, зависит прежде всего от инвариантов, которые должна поддерживать система. Учитывая набор инвариантов, разработчик должен решить, поддерживать ли конкретный инвариант в режиме разделения или рискнуть нарушить его с намерением возобновить его во время восстановления. Например, в случае с инвариантом, когда ключи в таблице уникальны, разработчики обычно решают рискнуть этим инвариантом и разрешить дублирование ключей во время разделения. Дублирующиеся ключи легко обнаружить при восстановлении, и с учетом того, что их можно объединить, разработчик легко восстановит инвариант.
Однако в случае с инвариантом, который должен поддерживаться во время разделения, разработчик должен запретить или изменить операции, которые могут его нарушить. (В общем, невозможно предсказать, нарушит ли операция инвариант, поскольку состояние другой стороны неизвестно.) Внешние события, такие как снятие средств с кредитной карты, часто работают таким образом. В этом случае стратегия состоит в том, чтобы записать намерение и выполнить его после восстановления. Такие транзакции обычно являются частью более крупного рабочего процесса, в котором есть явное состояние обработки заказа, и отсрочка операции до завершения разделения не особо страшна. Разработчик жертвует А так, что пользователи этого не видят. Пользователи знают только, что они разместили заказ и что система выполнит его позже.
В более общем плане режим разделения ставит сложную задачу пользовательскому интерфейсу – сообщить, что задачи выполняются, но не завершены. Исследователи довольно подробно изучили эту проблему в режиме автономной работы, которая представляет собой просто длинное разделение. Программа-календарь Bayou, например, показывает потенциально несогласованные (предварительные) записи другим цветом. (7) Такие уведомления регулярно видны как в приложениях для выполнения рабочих процессов, скажем, коммерция с уведомлениями по электронной почте, так и в облачных службах с автономным режимом, таких как Гугл документы.
Одна из причин сосредоточиться на явных атомарных операциях, а не просто на чтении и записи, заключается в том, что гораздо проще анализировать влияние более высокоуровневых операций на инварианты. По сути, разработчик должен построить таблицу, которая рассматривает перекрестное произведение всех операций и всех инвариантов и решает для каждой записи, может ли эта операция нарушить инвариант. Если да, то разработчик должен решить, следует ли запретить, отложить или изменить операцию. На практике эти решения также могут зависеть от известного состояния, от аргументов или от того и другого. Например, в системах с домашним узлом для определенных данных (5) операции обычно выполняются на домашнем узле, а не на других узлах.
Лучший способ отслеживать историю операций с обеих сторон — использовать векторы версий, которые фиксируют причинно-следственные зависимости между операциями. Элементы вектора представляют собой пару (узел, логическое время) с одной записью для каждого узла, обновившего объект, и временем его последнего обновления. Учитывая две версии объекта, A и B, A новее, чем B, если для каждого общего узла в их векторах время A больше или равно времени B, и по крайней мере одно из значений времени A больше.
Если упорядочить векторы невозможно, значит, обновления были одновременными и, возможно, несогласованными. Таким образом, учитывая историю векторов версий обеих сторон, система может легко определить, какие операции уже выполняются в известном порядке, а какие выполняются одновременно. Недавняя работа(8) доказала, что такого рода причинно-следственная связь является наилучшим возможным результатом в целом, если разработчик решает сосредоточиться на доступности.
Восстановление после разделения
В какой-то момент связь возобновляется и разделение заканчивается. Во время разделения каждая сторона была доступна и продолжала функционировать, но разделение задержало некоторые операции и нарушило некоторые инварианты. На этом этапе системе известно состояние и история обеих сторон, поскольку в режиме разделения всё подробно записывалось в журнал. Состояние не так полезно, как история, благодаря которой система может вычислить, какие операции на самом деле нарушили инварианты и какие результаты были вынесены вовне, в том числе ответы, отправленные пользователю. При восстановлении разработчик должен решить две сложные задачи:
- состояние с обеих сторон должно стать согласованным, и
- должна быть предусмотрена компенсация ошибок, допущенных в режиме разделений.
Как правило, проще исправить текущее состояние, начиная с состояния на момент разделения и воспроизводя оба набора операций, поддерживая при этом согласованное состояние. Bayou для этого откатывал назад базу данных до нужного времени и воспроизводил полный набор операций в четко определенном, детерминированном порядке, чтобы все узлы достигли одного и того же состояния (9). Похожим образом система контроля исходного кода, такая как Concurrent Versioning System (CVS) запускается из общей согласованной точки и последовательно выполняет обновления для объединения ветвей.
Большинство систем не всегда могут разрешить конфликты. Например, в CVS иногда возникают конфликты, которые пользователь должен разрешать вручную, а вики-системы с автономным режимом обычно оставляют конфликты в итоговом документе, требующем ручного редактирования. (10)
И наоборот, некоторые системы всегда решают конфликты, выбрав определенные операции. В качестве примера можно привести редактирование текста в Google Docs (11), которое ограничивает операции применением стиля и добавлением или удалением текста. Таким образом, хотя общая проблема разрешения конфликтов неразрешима, на практике разработчики могут ограничивать использование определенных операций во время разделения, чтобы система могла автоматически объединять состояния во время восстановления. Отсрочка рискованных операций — одна из относительно простых реализаций этой стратегии.
Использование коммутативных операций — это наиболее близкий подход к общей структуре автоматической конвергентности состояний. Система объединяет журналы, сортирует их в определенном порядке, а затем выполняет. Коммутативность подразумевает способность перестраивать операции в предпочтительный непротиворечивый глобальный порядок. К сожалению, использовать только коммутативные операции сложнее, чем кажется; например, сложение коммутативно, а сложение с проверкой границ — нет (например, нулевой баланс).
Недавняя работа Марка Шапиро и его коллег из INRIA (12,13) значительно улучшила использование коммутативных операций для конвергентности состояний. Команда разработала коммутативные реплицированные типы данных (commutative replicated data types — CRDT), класс структур данных, которые доказуемо сходятся после разделения, и описывает, как использовать эти структуры для того, чтобы
- гарантировать, что все операции во время разделения коммутативны, или
- представлять значения на сетке и гарантировать, что все операции во время разделения монотонно возрастают по отношению к этой сетке значений.
Последний подход конвергирует состояние, передвигая к максимуму значения каждой стороны. Это оформление и усовершенствование того, что Amazon делает со своей корзиной (14): после разделения конвергентное значение представляет собой объединение двух корзин, причем объединение представляет собой операцию с монотонным множеством. При выборе такого подхода удаленные элементы могут появиться снова.
Однако CRDT также могут выполнять устойчивые к разделениям наборы инструкций, которые добавляют и удаляют элементы. Суть этого подхода заключается в введении двух множеств: по одному для добавленных и удаленных элементов, причем элементами этих множеств являются изменения. Каждый упрощенный набор сходится, а значит, сходятся и изменения. В какой-то момент система может навести порядок, просто убрав удаленные элементы из обоих наборов. Однако такая очистка, как правило, возможна только в том случае, если система не разделена. Другими словами, разработчик должен запретить или отложить некоторые операции во время разделения, но это операции очистки, которые не ограничивают воспринимаемую доступность.
Таким образом, реализуя состояние через CRDT, разработчик может выбрать A и по-прежнему гарантировать, что состояние автоматически сходится после разделения.
Компенсация ошибок
В дополнение к вычислению состояния после разделения существует более сложная проблема исправления ошибок, допущенных во время разделения. Отслеживание и ограничение операций в режиме разделения обеспечивает знание того, какие инварианты могли быть нарушены, что, в свою очередь, позволяет разработчику создать стратегию восстановления для каждого такого инварианта. Как правило, система обнаруживает нарушение во время восстановления и в это же время должна выполнить нужное исправление.
Существуют различные способы исправить инварианты, в том числе такие банальные как «выигрывает последний автор» (которые игнорируют некоторые обновления), более разумные подходы, объединяющие операции, и эскалация до человека. Примером последнего является избыточное бронирование самолетов: посадка в самолет в некотором смысле является восстановлением после разделения с инвариантом, согласно которому мест должно быть не меньше, чем пассажиров. Если пассажиров слишком много, некоторые из них потеряют свои места, и в идеале служба поддержки клиентов каким-то образом возместит ущерб этим пассажирам.
Пример с самолетом также демонстрирует экспортированную ошибку: если бы авиакомпания не сообщила, что у пассажира есть место, решить проблему было бы намного проще. Это еще одна причина откладывать рискованные операции: на момент восстановления правда известна. В основе исправления таких ошибок действительно лежит идея компенсации; разработчики должны создавать компенсирующие операции, которые одновременно восстанавливают инвариант и, в более широком смысле, исправляют экспортированную ошибку.
Технически CRDT допускают только локально подтвержденные инварианты — ограничение, которое делает компенсацию ненужной, но несколько снижает мощность подхода. Однако решение, использующее CRDT для конвергенции состояний, может допустить временное нарушение глобального инварианта, конвергировать состояние после разделения, а затем выполнить все необходимые компенсации.
Для восстановления после экспортированных ошибок обычно требуется некоторая история внешних выходных данных. Рассмотрим сценарий «набора номера» в состоянии алкогольного опьянения, когда человек не помнит, как делал различные телефонные звонки в состоянии алкогольного опьянения предыдущей ночью. Состояние этого человека на другой день может быть нормальным, но журнал по-прежнему показывает список звонков, некоторые из которых могли быть ошибочными. Звонки являются внешним последствием состояния человека (опьянения). Поскольку человек не помнит звонки, может быть трудно компенсировать возникшие из-за них проблемы.
В контексте механизма компьютер во время разделения может выполнять заказы дважды. Если система может отличить два преднамеренных заказа от двух повторяющихся заказов, она может отменить один из дубликатов. В случае экспортирования ошибки, одна из компенсационных стратегий будет состоять в том, чтобы автоматически сгенерировать электронное письмо для клиента, объясняющее, что система случайно выполнила заказ дважды, но ошибка была исправлена, и прикрепить купон на скидку на следующий заказ. Однако без надлежащей истории ошибку искать придется самому покупателю.
Некоторые исследователи формально рассматривают компенсационные транзакции как способ работы с долгоживущими транзакциями. (15,16) Долгосрочные транзакции сталкиваются с вариантами решений о разделении: что лучше – удерживать блокировки в течение длительного времени для обеспечения согласованности или отпускать их раньше и предоставлять незафиксированные данные другим транзакциям, но обеспечивать более высокий уровень параллелизма? Типичным примером является попытка обновить все записи о сотрудниках за одну транзакцию. Сериализация этой транзакции обычным способом блокирует все записи и предотвращает параллелизм. Компенсационные транзакции используют другой подход, разбивая большую транзакцию на сагу, состоящую из нескольких субтранзакций, каждая из которых фиксируется по пути. Таким образом, чтобы прервать более крупную транзакцию, система должна отменить каждую уже совершенную субтранзакцию, создавая новую транзакцию, которая корректирует ее последствия — компенсирующую транзакцию.
В общем, цель – избежать отмены других транзакций, которые использовали неправильно зафиксированные данные (без каскадных прерываний). Корректность этого подхода зависит не от сериализуемости или изоляции, а скорее от чистого влияния последовательности транзакций на состояние и выходные данные. Вопрос в том, оказывается ли база данных после компенсации в месте, эквивалентном тому, где она была бы, если бы субтранзакции никогда не выполнялись? Эквивалентность должна включать внешние действия; например, возврат денег за дублирующую покупку не то же самое, что и не взимать плату с этого клиента сразу, но, возможно, это эквивалентно. Та же идея сохраняется и при восстановлении после разделения. Поставщик услуг или продуктов не всегда может исправить ошибки напрямую, но стремится признать их и предпринять новые компенсирующие действия. Вопрос о том, как лучше всего применить эти идеи для восстановления после разделений, остается открытым. На боковой панели «Вопросы компенсации в банкомате» описаны некоторые проблемы только в одной прикладной области.
При проектировании банкомата (ATM) логичным выбором кажется строгая согласованность, но на практике А превосходит С. Причина достаточно проста: более высокая доступность означает более высокий доход. Так или иначе, конструкция банкомата служит хорошим контекстом для рассмотрения некоторых проблем, связанных с компенсацией инвариантных нарушений во время разделения.
Основными операциями банкомата являются внесение средств, снятие средств и проверка баланса. Ключевым инвариантом является то, что баланс должен быть равен нулю или выше. Поскольку инвариант может нарушить только снятие средств, для него потребуется специальная обработка, но две другие операции всегда могут быть выполнены.
Разработчик системы банкоматов может запретить снятие средств во время разделения, поскольку в это время невозможно узнать истинный баланс, но это поставит под угрозу доступность. Вместо этого, используя режим ожидания (режим разделения), современные банкоматы ограничивают чистое снятие не более чем до k, где k может составлять $200. Ниже этого лимита вывод работает полностью; когда баланс достигает лимита, система отказывает в снятии средств. Таким образом, банкомат выбирает сложный лимит доступности, который разрешает снятие средств, но ограничивает риск.
Когда разделение заканчивается, должен быть какой-то способ как восстановить согласованность, так и компенсировать ошибки, допущенные при разделении системы. Восстановить состояние легко, потому что операции коммутативны, но компенсация может принимать несколько форм. Окончательный баланс ниже нуля нарушает инвариант. В обычном случае банкомат выдал деньги, из-за чего ошибка стала внешней. Банк компенсирует это, взимая комиссию и ожидая погашения. Учитывая, что риск ограничен, проблема не столь серьезная. Однако предположим, что баланс был ниже нуля в какой-то момент во время разделения (неизвестный банкомату), но более поздний депозит восстановил его. В этом случае банк может по-прежнему взимать комиссию за овердрафт задним числом или игнорировать нарушение, так как клиент уже произвел необходимый платеж.
В целом, из-за задержек связи правильная работа банковской системы зависит не от согласованности, а скорее от аудита и компенсации. Ещё один пример — «чековый кайт», когда клиент снимает деньги в нескольких отделениях до того, как они смогут связаться, а затем убегает. Овердрафт будет взыскан позже, что, возможно, приведет к компенсации в виде судебного иска.
Разработчики систем не должны слепо жертвовать согласованностью или доступностью при наличии разделений. Используя предложенный подход, они могут оптимизировать оба свойства за счет тщательного управления инвариантами во время разделения. По мере того, как новые методы, такие как векторы версий и CRDT, внедряются во фреймворки, упрощающие их использование, этот вид оптимизации должен получить более широкое распространение. Однако, в отличие от транзакций ACID, этот подход требует более продуманного развертывания по сравнению с прошлыми стратегиями, и лучшие решения будут в значительной степени зависеть от конкретных инвариантов и операций сервиса.
Благодарности
Я благодарю Mike Dahlin, Hank Korth, Marc Shapiro, Justin Sheehy, Amin Vahdat, Ben Zhao и волонтеров IEEE Computer Society за их полезные отзывы об этой работе.
- E. Brewer, "Lessons from Giant-Scale Services," IEEE Internet Computing, July/Aug. 2001, pp. 46-55.
- A. Fox et al., "Cluster-Based Scalable Network Services," Proc. 16th ACM Symp. Operating Systems Principles (SOSP 97), ACM, 1997, pp. 78-91.
- A. Fox and E.A. Brewer, "Harvest, Yield and Scalable Tolerant Systems," Proc. 7th Workshop Hot Topics in Operating Systems (HotOS 99), IEEE CS, 1999, pp. 174-178.
- E. Brewer, "Towards Robust Distributed Systems," Proc. 19th Ann. ACM Symp.Principles of Distributed Computing (PODC 00), ACM, 2000, pp. 7-10; on-line resource.
- B. Cooper et al., "PNUTS: Yahoo!’s Hosted Data Serving Platform," Proc. VLDB Endowment (VLDB 08), ACM, 2008, pp. 1277-1288.
- J. Sobel, "Scaling Out," Facebook Engineering Notes, 20 Aug. 2008; on-line resource.
- W. K. Edwards et al., "Designing and Implementing Asynchronous Collaborative Applications with Bayou," Proc. 10th Ann. ACM Symp. User Interface Software and Technology (UIST 97), ACM, 1999, pp. 119-128.
- P. Mahajan, L. Alvisi, and M. Dahlin, Consistency, Availability, and Convergence, tech. report UTCS TR-11-22, Univ. of Texas at Austin, 2011.
- D.B. Terry et al., "Managing Update Conflicts in Bayou, a Weakly Connected Replicated Storage System," Proc. 15th ACM Symp. Operating Systems Principles (SOSP 95), ACM, 1995, pp. 172-182.
- B. Du and E.A. Brewer, "DTWiki: A Disconnection and Intermittency Tolerant Wiki," Proc. 17th Int’l Conf. World Wide Web (WWW 08), ACM, 2008, pp. 945-952.
- "What’s Different about the New Google Docs: Conflict Resolution" blog.
- M. Shapiro et al., "Conflict-Free Replicated Data Types," Proc. 13th Int’l Conf. Stabilization, Safety, and Security of Distributed Systems (SSS 11), ACM, 2011, pp. 386-400.
- M. Shapiro et al., "Convergent and Commutative Replicated Data Types," Bulletin of the EATCS, no. 104, June 2011, pp. 67-88.
- G. DeCandia et al., "Dynamo: Amazon’s Highly Available Key-Value Store," Proc. 21st ACM SIGOPS Symp. Operating Systems Principles (SOSP 07), ACM, 2007, pp. 205-220.
- H. Garcia-Molina and K. Salem, "SAGAS," Proc. ACM SIGMOD Int’l Conf. Management of Data (SIGMOD 87), ACM, 1987, pp. 249-259.
- H. Korth, E. Levy, and A. Silberschatz, "A Formal Approach to Recovery by Compensating Transactions," Proc. VLDB Endowment (VLDB 90), ACM, 1990, pp. 95-106
Об авторе
Эрик Брюэр — профессор компьютерных наук Калифорнийского университета в Беркли и вице-президент по инфраструктуре Google. В его исследовательские интересы входят облачные вычисления, масштабируемые серверы, сенсорные сети и технологии для развивающихся регионов. Он также помог создать USA.gov, официальный портал федерального правительства. Брюэр получил докторскую степень в области электротехники и компьютерных наук в Массачусетском технологическом институте. Он является членом Национальной инженерной академии. Связаться с ним можно по адресу brewer@cs.berkeley.edu

Комментарии (9)

DinoZavr2
25.11.2022 21:47Читаю спокойно.. В один момент понимаю, что-то знакомо. И вспоминаю статью точь в точь, символ в символ, которую я читал в 2013.

devalio Автор
25.11.2022 22:55А можете ссылку дать? А то я гуглю плохо - так и не нашел перевода.
DinoZavr2
26.11.2022 15:36Здравствуйте. Извините, но это было в 2013. Если что не обращайте внимание на какого-то @DinoZavr3
DinoZavr3
26.11.2022 22:08Я тоже плохо гуглю. Извините, но я читал это в 2013,на каком-то форуме
devalio Автор
26.11.2022 22:09Так а кто спорит то? Статья от 2012 года.
Вот только ее нигде не нагуглишь в русском переводе. И это было грустно
Меня беспокоит только это ваше "символ в символ" - вот это вы уже не докажете, если все-таки не нагуглите свою статью.
DinoZavr2
27.11.2022 19:35-1Нагуглить так и не смог. Отличалось только названи статьи. Вы, наверное, использовали гугл или Яндекс переводчик. Если нет, незнаю.
devalio Автор
28.11.2022 06:13Так, давайте вы сначала попробуете перевести исходную статью в гугл- или яндекс-переводчике, а потом ужу будете утверждать что-то подобное.
А еще лучше, вы просто скажете, что конкретно в нашем тексте вам не понравилось. Возможно мы ошиблись где-то (ведь люди ошибаются), так давайте вместе исправим ошибку.
domage
Начал читать статью, и почувствовал некоторый подвох...
И действительно, статья февраля 2012 года, плохо переведенная гуглом.
Десять лет прошло, а мы всё еще обсуждаем, что же такое CAP.
devalio Автор
Извините, что вам не угодил. Хотел первым делом написать, почему я опубликовал перевод такой старой статьи, но вы опередили меня
Итак. Я не нашел ни одной хорошей статьи, которая бы объясняла, откуда взялся такой интересный мейнстрим - навязывать кап-ярлыки базам данных. Особенно страдают реляционные, которым всегда дают CA. Хорошо, но что такое "распределенная система, которая forfeit P?". Решительно никто не может объяснить в RU сегменте, что же это значит Partition Tolerance. А некоторые онлайн IT-школы вообще говорят, что P дано нам от рождения, потому что TCP-IP нам это гарантирует!
Я нашел эту статью чисто случайно, и в ней автор раскрывает все, что так долго путают технические специалисты среднего уровня. Так вот, чтобы прекратить всю эту околесицу, я и взялся за этот перевод. Конечно делал я его не сам. Над переводом работали два человека - мой хороший друг и учитель английского языка - Екатерина Харченко и я (ваш покорный Игорь Меньшенин), как технический специалист.
Мы работали над каждой фразой и выверяли все понятия. Адаптировали в некоторых местах так, чтобы было понятно не только прожженному разработчику. Уверяю вас, что в этом переводе нет ни одного слова, которое бы мы скопировали из гугл- или другого онлайн переводчика, так что я просто думаю, что ваш комментарий проплачен.
Спасибо, нам очень важно ваше мнение =)