Все хотят писать чистый код. Этому посвящены целые книги.
Но вам не нужно читать книги, чтобы начать писать более чистый код прямо сейчас. Есть одна «хитрость», которой может научиться любой кодер, она делает код гораздо менее запутанным.
Решение таково:
Каждая строка делает только одно действие
Одна строка, одна задача.
Но не стоит слишком перебарщивать.

«Катя, я вижу строку, которая выполняет два действия. Два действия, Катя!» Не становитесь таким.
Вот в чём заключается основной смысл: для понимания коротких строк кода требуется меньше мыслительных усилий, чем для понимания длинных. Над кодом, который легко читать, легче думать. Программы с короткими строками, в теории, проще поддерживать.
Однако компактный код может быть непонятным. (Слыхали об APL?) И возможность разбиения строки не означает, что это нужно делать обязательно.
В некоторых языках можно присвоить два значения двум переменным в одной строке:
x, y = 2, 7Можно поместить каждое из присвоений в отдельную строку:
x = 2
y = 7Но действительно ли это необходимо? Как решить, нужно ли разбивать строку?
Дело не только в длине строки
В начале своей книги The Programmer's Brain Фелиен Херманс сообщает бесспорный факт: «Неразбериха — это часть программирования».

«А-а-а, что это вообще означает?» Возможно, это означает, что пора сделать перерыв.
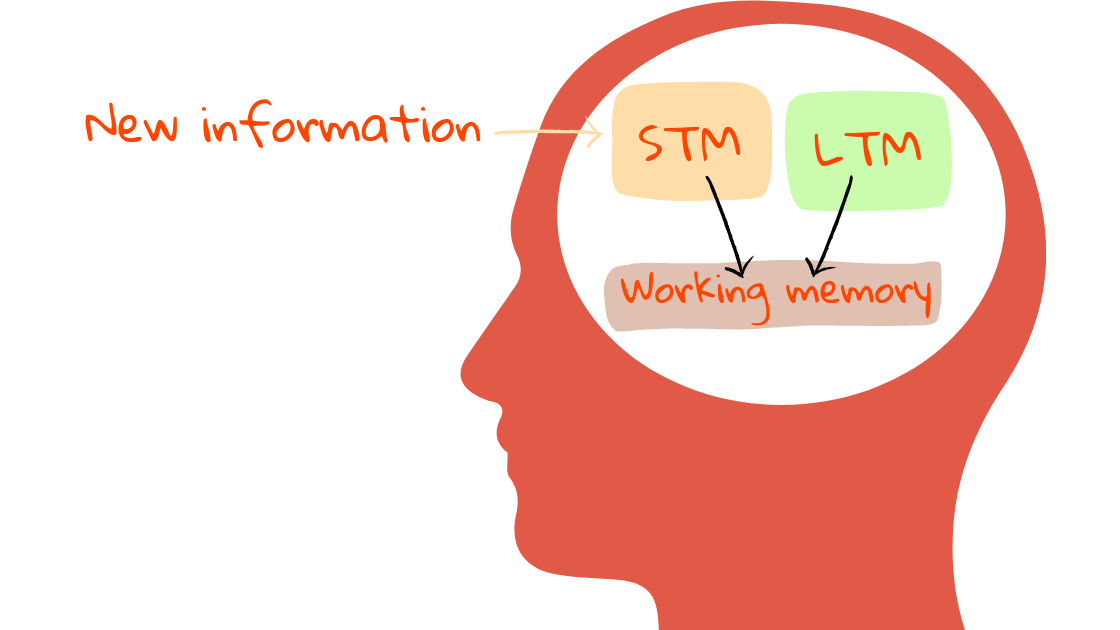
В книге Херманс (которую я крайне вам рекомендую) объясняется, как три функции памяти работают при понимании кода:
- Долговременная память (LTM): хранит информацию для долговременного поиска, например, ключевые слова, синтаксис, часто используемые идиомы и паттерны.
- Кратковременная память (STM): хранит новую информацию для кратковременного поиска (менее 30 секунд!), например, имена переменных и специальные значения.
- Рабочая память (WM): обрабатывает информацию из долговременной и кратковременной памяти, чтобы делать выводы и извлекать новое знание.
Кратковременная и рабочая память малы. И та, и другая могут хранить одновременно примерно 4-6 элементов! Если перегрузить их, то вы сразу же запутаетесь.
Как мозг обрабатывает информацию.
Это даёт нам правило определения того, не является ли строка кода слишком сложной:
Правило шести: строку кода, содержащую больше шести элементов информации, следует упростить.
Вот пример на Python:
map(lambda x: x.split('=')[1], s.split('?')[1].split('&')[-3:])Вам сложно прочитать эту строку? Мне тоже. И на то есть причина.
Вам нужно знать, что такое
map, lambda и .split(). Переменные x и s, строки '=', '?' и '&', индекс [1], и слайс [-3:] занимают место в кратковременной и рабочей памяти. Суммарно это десять элементов! Мозг этого не выдерживает.Хотя, возможно ваш может.
Если это так, то вы, должно быть, обладаете хорошим опытом.
Ваш мозг разбивает синтаксис вида
s.split('?')[1] на «часть строки справа от вопросительного знака». И вы можете воссоздать код на основе информации, хранящейся в долговременной памяти. Но вы всё равно обрабатываете за раз только небольшое количество фрагментов.Итак, мы можем определить, когда строка кода слишком сложна. Но что дальше?
Если код запутывает, разбивайте его на части
Разбейте его на меньшие части, вот и всё.
Для разбиения кода я использую две стратегии. Я назвал их SIMPLE и MORF.
Стратегия SIMPLE добавляет строки кода для снижения когнитивной нагрузки.

Разбить на несколько строк
Давайте применим SIMPLE к той строке, которую рассматривали выше. Уберём второй аргумент из
map() и вставим его в отдельную строку:query_params = s.split('?')[1].split('&')[-3:]
map(lambda x: x.split('=')[1], query_params)Возможно, код по-прежнему сложно читать. В первой строке нужно отслеживать семь элементов:
query_paramss.split()'?'[1]'&'[-3:]
Но в каждой строке теперь нужно отслеживать меньше элементов, чем раньше. Вашему мозгу будет проще их обрабатывать.
Применим SIMPLE ещё раз и переместим
s.split('?')[1] в новую строку:url_query_string = s.split('?')[1]
query_params = url_query_string.split('&')[-3:]
map(lambda x: x.split('=')[1], query_params)Сравните это с исходным однострочным кодом. Какой из них проще обработать?
В стратегии MORF используется другой подход: код группируется в функции.

Вынести и переписать в виде функции.
Вот как выглядит использование MORF для нашей строки:
def query_params(url):
return url.split('?')[1].split('&')[-3:]
map(lambda x: x.split('=')[1], query_params(s))Также можно сочетать MORF и SIMPLE:
def query_params(url):
query_string = url.split('?')[1]
return query_string.split('&')[-3:]
map(lambda x: x.split('=')[1], query_params(s))Чтобы почувствовать смысл, вам необязательно понимать код. Мозгу проще обрабатывать каждую строку.
Но есть и бонус!
Если вы знаете, что рабочая и кратковременная память не перегружены, то будете знать, что любое непонимание возникает вследствие отсутствия информации в долговременной памяти.
Иными словами, SIMPLE и MORF не просто помогают писать более чистый код, но и позволяют выявлять пробелы в знаниях, которые можно закрыть при помощи практики.
Комментарии (80)

oleg_shamshura
02.12.2022 17:27+46Почему принцип не распространяется дальше?
Не более 6 строк в методе.
Не более 6 методов в классе.
Не более 6 классов в приложении.
Документация -- тоже не длиннее 6 строчек.
GoogleTan
02.12.2022 17:37+31Потому что это подойдёт только для ТЗ тоже не длиннее 6 строчек.

dyadyaSerezha
04.12.2022 06:38Написать программу, которая делает все!
ТЗ в пяти словах и на одной строчке.

MaxAhmed
02.12.2022 20:20+9Нет, надо решить проблему в корне - либо сократить алфавит до 6 символов, либо запретить слова длиннее 6 символов. Можно и то и другое.

aleksandy
02.12.2022 21:06+3Вообще не проблема.
oleg_shamshura
03.12.2022 04:53+2Напомнило, как я писал плагин для Shotgun RV на его собственном языке Mu. Меня коллеги-итальянцы по утрам встречали хоровым мычанием.

YDR
02.12.2022 22:42+1"на... до... на...рили? рас...ривайте на... обратно!" - 6 слов - как раз все нормально.
Ну и "все изделия состоят из фиговины, хреновины и соединяющих их пофигени"



shasoftX
02.12.2022 18:06-1map(lambda x: x.split('=')[1], s.split('?')[1].split('&')[-3:])Вам сложно прочитать эту строку? Мне тоже. И на то есть причина.
А вот так уже гораздо проще читать и понимать эту строку
# Это строка делает такие-то действия map(lambda x: x.split('=')[1], s.split('?')[1].split('&')[-3:])
FreeNickname
02.12.2022 18:10+32Нет, так эту строку кто-нибудь поменяет, а комментарий нет. А поскольку такая угроза существует, то при поддержке этого кода Вам вначале придётся прочитать комментарий, осознать его, а потом всё равно перепроверить строку, чтобы убедиться, что она делает то же, что комментарий.
shasoftX
02.12.2022 18:15-1Если комментарий не изменился, значит функция строки не изменилась, а изменился алгоритм.
Собственно плюс такого подхода в том, что вам не нужно понимать алгоритм строки. Достаточно понимания что эта строка делает.
FreeNickname
02.12.2022 18:21+22...всё вместо того, чтобы писать читаемый код.
Если комментарий не изменился, значит функция строки не изменилась, а изменился алгоритм.
Либо это значит, что комментарий забыли поменять. Вы с таким не сталкивались? Я вот сталкивался. Комментариям верить нельзя, они не выполняются.
Также, вы не могли бы, пожалуйста, расписать строку из примера не в виде "эта строка делает такие-то действия", а в виде реального комментария (можно на русском)? Просто я могу прочитать код, и если комментарий дублирует код, то зачем мне этот комментарий? Он наверняка будет длиннее, чем код.
Таким часто грешат начинающие разработчики, которым пока трудно читать непосредственно код, но для middle / senior, описывать, что делает код в комментариях – вредно. Комментарий должен описывать, почему код это делает, причём в тех случаях, когда это неочевидно.

inkelyad
02.12.2022 18:31Либо это значит, что комментарий забыли поменять. Вы с таким не сталкивались? Я вот сталкивался. Комментариям верить нельзя, они не выполняются.
И это повод пойти разобраться, должно ли оно делать то что в комментарии написано, или то, что в коде. Еще один кусочек для проверки корректности на code review.
Потому что коду тоже верить нельзя - он регулярно выполняет не то, что должен.
FreeNickname
02.12.2022 18:38+7Для этого юнит-тесты придумали. А Вы только что увеличили трудоёмкость code review в два раза, если не больше, потому что нужно проверять не код, а код + комментарии. Причём построчно, и ещё и сравнивать. То есть, опять же, комментарии ничего не упрощают при Вашем подходе. Ведь если Вы не сверяете комментарии с кодом, то Вы не поймаете проблему на ревью.
Коду можно верить в том плане, что если он делает что-то не то, то эта проблема вылезет позже.
Если что, погуглите любые best practices по комментированию, например вот первая попавшаяся статья, прямо сходу rule 1: "Comments should not duplicate the code".
https://stackoverflow.blog/2021/12/23/best-practices-for-writing-code-comments/
inkelyad
02.12.2022 18:44+2А Вы только что увеличили трудоёмкость code review в два раза, если не больше, потому что нужно проверять не код, а код + комментарии.
Да. И юнит тест еще проверять придется. Что проверяем действительно то что надо. Повторение одного и того же -- далеко не всегда зло. Избыточность и повторы служит еще и для средством ловли ошибок и несоответствий. А то вот чего-то поправили (вместе с тестом), комментария не будет, и потом выяснится, что поправили - не так как надо.
1Comments should not duplicate the code
Проблема тут не столько в том, что комментарий есть, а в том, что он не описывает, зачем и для чего следующая строчка что-то считает.
FreeNickname
02.12.2022 18:47+2Да. И юнит тест еще проверять придется. Что проверяем действительно то что надо. Повторение одного и того же -- далеко не всегда зло. Избыточность и повторы служит еще и для средством ловли ошибок и несоответствий.
Да, моя ошибка. В четыре раза. Я проверю код и юнит-тесты, а Вы проверите код, комментарии к коду (построчно), юнит-тест и комментарии к коду юнит-теста (построчно). Очень надёжно, спору нет. Пожалуй, я это поддерживать не буду :)
Проблема тут не столько в том, что комментарий есть, а в том, что он не описывает, зачем и для чего следующая строчка что-то считает.
Верно, как я выше и писал, комментарии должны описывать, почему код делает то, что он делает. Причём в неочевидных ситуациях, иначе это, опять же, вредное дублирование. Я же не говорю запретить комментарии в коде, я за то, чтобы они снижали когнитивную нагрузку, а не увеличивали её без нужды.
inkelyad
02.12.2022 19:03+5Причём в неочевидных ситуациях, иначе это, опять же, вредное дублирование.
Проблема только в том, что то что очевидно пишущему (потому что он уже второй день над темой медитирует и ему доступны ТЗ, аналитик и еще толпа людей, имеющих отношение к тому, что пишется) -- может быть ну совсем неочевидно лет через 10, когда все все забыли, ТЗ успешно потерялись при переезде между информационными системами и разными реорганизациями. И в этот момент понять "а чего делаем-то и для чего?" - можно частенько понять только вот по таким комментариям, которые в момент написания кода казались очевидными.

doctorw
02.12.2022 20:37+5А для этого уже существует code review, на котором другой разработчик, который не медитировал над темой два дня, задаст вопрос в неочевидных ему ситуациях.

maeris
02.12.2022 22:57+6Ага, и будем читать комментарии к ПРу трёхлетней давности вместо комментариев в коде. Отличный подход, чудесный совет.
Code review существует для проверки и кода, и консистентности комментариев к нему, и никоим образом не освобождает от обязанности комментировать код. Желательно, конечно, чтобы код и без комментариев читался, но на типичной работе вам столько времени на разработку никто не даст.

Kanut
02.12.2022 23:12+3Если я на code review не понимаю что должен делать код или меня просто почему-то не устраивают комментарии, то код не пройдёт пока не будут написаны нормальные комментарии. Причём именно в коде, а не "к ПРу" .
doctorw
03.12.2022 10:36+1На типичной работе я так и работаю, и пока ко мне никаких претензий от руководства нет. Комментарии использую по возможности только там, где может быть неочевидно, почему выбрано именно такое решение. Писать удобочитаемый и достаточно самодокументированный код в целом отнимает не сильно больше времени, чем писать код, к которому нужны комментарии.
За годы работы помню не один случай, когда чисто случайно в ходе разработке обнаруживался legacy-код, в котором были комментарии, отставшие от кода. Хорошо, когда из конфликта комментария с кодом очевидно, что следует поправить, а если нет? А если и людей, которые могли бы ответить на этот вопрос, в компании уже нет?
shasoftX
02.12.2022 18:37+1Тут ещё всё зависит от того, для чего именно вы разбираетесь.
Если вам нужна общая идея, то комментарий нужен. А если вы хотите понять как этот алгоритм работает, то тут вам нужно понимание что делает функция map, lambda и split. А раз автор дальше пишет что "вы можете этого не знать", значит вам всё-таки нужен общий алгоритм. А для понимания общего алгоритма как раз комментарий, по моему мнению, будет больше полезен , чем этот алгоритм разбитый по строкам.
FreeNickname
02.12.2022 18:41+9Если Вы пишете комментарий, потому что кто-то может не знать, что делают map, lambda и split, то Вы просто дублируете документацию по lambda, map и split в ущербном урезанном виде. Если человек не знает, что делают эти функции, то ему нужно пойти и разобраться.
Проблема примера не в том, что там есть страшные функции, а в том, что они нагромождены в однострочник, который может быть сложно воспринимать. Если у Вас получился длинный страшный однострочник, то его имеет смысл разбить, при этом можно промежуточные значения сохранять во временные переменные с адекватными именами, и вот у нас уже самодокументирующийся код.
shasoftX
02.12.2022 18:55+3В комментарии нужно писать ОБЩИЙ алгоритм из этих функций, а не копировать документацию по каждой из них.
Если нужно разбивать однострочник с применением временных переменных, то тут уже имеет смысл сделать отдельную функцию. Назвать её так, чтобы само имя говорило что она делает и будет самодокументирование.

BotCoder
02.12.2022 19:05+4Я затрудняюсь как давно программистам уже известно понятие "Self-documenting code", но точно могу сказать, что с тех самых пор без любителей доказывать полезность комментариев не обходится ни одна тема касающаяся документирования и прозрачности проекта. Рад, что кто-то еще не устал развенчивать полезность комментариев, написанных в стиле: "Я не смог тебе объяснить свою логику, написанным кодом, поэтому сейчас запутаю еще и своим комментарием"
inkelyad
02.12.2022 19:12+4Мы такие не из воздуха беремся. А после того, как приходится много поработать с кодом, где авторы сильно переоценили степень того, насколько оно self-documented.
FreeNickname
02.12.2022 19:31+4А Вы правда верите в способности людей, не способных написать адекватный код, написать адекватные комментарии к этому коду?
inkelyad
02.12.2022 19:35+1Я верю в то, что пользуюсь "не очень адекватный код+не очень адекватный комментарий" вероятность в конце концов установить, что на самом деле хотели/нужно было сделать -- несколько больше, чем просто по "не очень адекватный код".
doctorw
02.12.2022 20:44+3Эта вероятность больше только в моменте, когда комментарий и код не разъехались по своей сути. В какой-то момент код и комментарий разъедутся и вероятность сильно снизится, потому что придётся разбираться - а что тут правильное, код или комментарий? И время последнего изменения не может однозначно показать, что правильно, потому что изменение могло быть ошибочным.
inkelyad
02.12.2022 22:07+3потому что изменение могло быть ошибочным.
И оно не отловилось ни код-ревью, ни юнит-тестами (либо просто забыли какой-то случай, либо что-то не так поняли и просто в соответстветствии с новой логикой тест поправили)
Теперь имеем два случая.
1) У нас нет комментариев и мы просто не замечаем, что тут что-то не так и думаем, что так и надо.
2) У нас есть комментарии, мы замечаем различие и идем разбираться, чтобы потом поправить либо комментарий, либо код.
Вот именно факт того, что можно заметить различие между тем и тем -- и добавляет дополнительный слой избыточности, дающий и указывающий на то, где и почему копать, чтобы разбираться. А на этапе Code Review -- спросить "у тебя же комментарий с кодом не сходится, ты точно хотел написать то что написал?"
Вообще, аргументы против комментариев очень похожи на аргументы против тестов -- их же тоже понимать, поддерживать и ревьювить надо, тратя на это время. Почему бы не проигнорировать и не поверить в то, что ревьювер просто код почитает и примет решение, что все правильно?
Но если с необходимостью тестов вроде все согласились, то против того, чтобы нужное поведение описывать еще и просто человеческим языком (чтобы можно было сравнить желаемое с написанным кодом) -- почему-то споры вызывает.
Туда же вдогонку - вообще все документирование чего бы то ни было. Оно же тоже может разъезжается с кодом, может, не надо его делать? А то еще сравнивать, что документация коду и поведению софта соответствует. Так что ли?
doctorw
02.12.2022 22:52В юнит-тестах, лично я, вообще не вижу особого смысла, лучше использовать систему типов языка настолько насколько это возможно, чтобы исключить пространство для багов, и это, очевидно, касается языков со статической типизацией.
Код-ревью тоже не даёт стопроцентной гарантии, что все проблемы будут отловлены, хотя и позволяет ловить нетривиальные проблемы ещё до тестирования.
Как по мне, вместо избыточности лучше уделить внимание выразительности и лаконичности.
Тесты в моём понимании нужны - интеграционные и end-to-end. Что касается документации, то если она прямо детальная, то чтобы она не отставала от кодовой базы, нужно держать соразмерный штат техписов, с которыми должна быть хорошо налажена коммуникация.
Мне хорошее решение в отношении документации неизвестно.

vkni
03.12.2022 17:46+1лучше использовать систему типов языка настолько насколько это возможно, чтобы исключить пространство для багов
Ну да, но система типов не всегда достаточно мощна. Возьмите, скажем, какой-нибудь вычислительный код, ну там Рунге-Кутта. Да, часть вещей можно представить в виде матриц и векторов; если типы зависимые, то даже с размерностями. Но подавляющая часть объектов алгоритма — это IEEE754 двойной точности.
Даже физические размерности "обычные языки" при компиляции не проверяют, т.к. физические размерности требуют поддержки функции "возведение в степень", посмотрите на совершенно корректную:
1 м — ((2 м)**(0.25))**4

adeshere
03.12.2022 19:31Но подавляющая часть объектов алгоритма — это IEEE754 двойной точности.
Спрашиваю без подтекста: а Вы на каком языке пишете? У меня в очень древнем Intel Fortran-е 2013 года и 64-битные, и 128-битные REAL(8) и REAL(16) - это базовые типы, построенные на floating-point-модели IEEE 754, с которыми штатно работают все встроенные операторы и методы, включая функции из Math Kernel Library. Не уверен, что там есть все нужные Вам алгоритмы (я далек от этих задач), но даже если нет, то их наверняка можно сконструировать из базовых процедур. Эта библиотека в равной степени доступна и из фортана, и из Си-языков. (Но код на фортране, наверное, будет чуть проще благодаря массивным операторам, которые автоматически оптимизируются компилятором и избавляют программиста от этих забот). Может, стоит в эту сторону посмотреть?
vkni
04.12.2022 19:56Речь не о том, а об ограниченности возможностей строгой статической типизации. То есть не об оптимизациях, а о проверках корректности.
vkni
03.12.2022 17:41Не обязательно разъедутся. Код достаточно постоянный в массе своей.
И если этак в 90% коммент будет помогать понять код (чисто суть описывать), а в 9% будет понятно, что он не имеет никакого отношения к коду, то уже хорошо.
doctorw
04.12.2022 00:04+1Это также может быть и код, который меняется нерегулярно, но достаточно часто, а иногда и наскоро, в силу часто меняющихся требований. И ситуация может быть такой, что повлиять на частоту изменения требований нельзя.
В такой ситуации, имхо, надёжнее, если код уж больно запутанный и не удаётся его описать проще - сделать страницу в системе документации с подробным описанием механизма, реализованного в коде. В самом коде разместить комментарий в специальном формате со ссылкой на страницу и с указанием времени реализации и комментария, а в git-репозитории реализовать git-hook проверяющий, что вместе с файлом кода был изменён и комментарий.
Иными словами, нельзя ни при каких обстоятельствах допускать изменение кода без изменения комментариев к нему, если не хочешь потом разгребать абсурдные комбинации оных.
vkni
04.12.2022 19:54+2Комментарий может быть достаточно общим, чтобы не меняться с кодом. Например, вы вбили в код какое-то расписание, тогда комментарий сверху говорит об этом и не меняется никогда, а история git вам прекрасно скажет какое же расписание.
Иными словами, нельзя ни при каких обстоятельствах допускать изменение кода без изменения комментариев к нему, если не хочешь потом разгребать абсурдные комбинации оных.
Мой опыт работы в кровавом ынтерпрайзе подсказывает, что лучше противоречивая информация, чем отстутствие информации вообще. Поэтому любой PullRequest лучше связать с рабочей заявкой (в Jira, к примеру), историю git лучше никогда не тереть, заявки не протирать.
Противоречия можно разрешить, а вот то, что вы не знаете — вы ведь не знаете, что вы этого не знаете.
adeshere
03.12.2022 02:31+3Никто не спорит, что self-documented код - это правильно. И что дублировать код комментарием - это неправильно. Но у меня вот сейчас в одном окне открыто это обсуждение, а в соседнем - мой код. С которым работаю почти только я один, т.е. я пишу комментарии для себя. Причем с одной стороны, эти комментарии мне реально помогают в работе, особенно когда надо вернуться к коду многолетней давности, чтобы быстро найти нужное место и что-то подправить. А с другой - эти комментарии в половине случаев как раз таки именно дублируют код. В результате чего у меня назревает когнитивный диссонанс: получается, что я сам нарушаю тот принцип, который считаю правильным, и при этом я считаю правильным его нарушать.
Единственный нюанс, который слегка успокаивает мое душевное равновесие, состоит в том, что одна строка комментария у меня обычно приходится на несколько строк кода. Дело в том, что я использую довольно многословный язык, и многие функции с линейной логикой (вообще без ветвлений или с короткими select case) растягиваются на несколько экранов. Бывают функции размером под сотню строк, а иногда даже больше. И вот как раз при чтении таких функций комментарии помогают мне как-то структурировать код.
Если кто-то готов посмотреть на конкретный пример такого оксюморона и высказать свое мнение - прошу под спойлер. Буду благодарен как за ободряющую поддержку (что писать такой код нормально, и переживать об этом не стоит), так и за советы - что именно можно подправить в стиле, чтобы упомянутое противоречие перестало быть таким острым.
оксюморон
Вот этот фрагмент кода нужен, чтобы юзер выбрал один из нескольких вариантов формата данных, нажав клавишу из предопределенного списка. Сначала тут читается файл с сохраненными ответами, чтобы в качестве умолчания подсунуть опцию, выбранную в прошлый раз. Потом проверяется, что прочитанное из этого файла значение входит в список разрешенных альтернатив (мало ли, может юзер последний раз открывал этот диалог лет 10 назад, и с тех пор неизвестно что поменялось). Потом я вызываю свою обертку к функции GETKEY(), которая позволяет выбрать нужную опцию не только с клавиатуры, но и кликом мышки в нужном месте строки-подсказки, либо щелчком по предварительно распечатанному подробному списку альтернатив. Ну и под конец сделанный выбор запоминается в том же файле конфигурации:
c c 2.3. Выбрать тип файла для записи данных = установить export_format: call save_conf($SC_Read,$SC_AbdMdExport) ! ABDEXPORT_DATA export_format=win_ltl(saveconf.c1) if (.not.inset(export_format,'xtcsa')) export_format='x' ansyer_default=export_format dos_line='Нажмите X, T, C, S или A'; charset='teXt, csv-Tab, csv-Comma, csv-Semicolon, Ana+anP' call screen_char_in(LFA-ii+$Max_formats+2,$Hue_In1,AllowF2=$AllowF2,Forbidden_symbols=', _-+') c select case(ansyer) case('X'); export_format='x' case('T'); export_format='t' case('C'); export_format='c' case('S'); export_format='s' case('A','P'); export_format='a' case default; goto 900 ! аварийный выход, возможен в случае ansyer=$charEsc,$charF10 end select saveconf.c1=win_ltl(export_format) call save_conf($SC_Write,$SC_AbdMdExport) ! ABDEXPORT_DATAВ этом коде ansyer_default, ansyer, dos_line, charset, saveconf и др. - это публичные члены модулей (фактически классов), в которых реализованы вызываемые здесь функции. Поэтому они не перечислены в списке фактических параметров в явном виде.
В результате функция длиной 110 строк оказывается визуально разбита на несколько вполне обозримых блоков строками-разделителями (=комментариями). Получается вот такая структура процедуры (ее полный текст ниже отдельно):
CCCCCCCCCCCCCCCCC ABDEXPORT_DATA CCCCCCCCCCCCCCCCC C Экспорт помеченных рядов данных из рабочего пространства в файл. C C Формат файла выбирается в диалоге. С экспортированных рядов пометка снимается. C C...................................................................................C SUBROUTINE ABDEXPORT_DATA() c c.....1. Пометить текущий ряд, если ничего не помечено: c c.....2.Выбрать режим экспорта: c 2.1. Открыть окно для вопроса: c 2.2. Напечатать меню, установить регионы мышки - синонимы: c 2.3. Выбрать тип файла для записи данных = установить export_format: c c.....3. Экспорт в anp-формате: c c.....4. Экспорт в текстовом виде и в CSV: c c.....5. Завершающие операции: очистить и закрыть окно: endПолный текст функции
CCCCCCCCCCCCCCCCC ABDEXPORT_DATA CCCCCCCCCCCCCCCCC C Экспорт помеченных рядов данных из рабочего пространства в файл. C C Формат файла выбирается в диалоге. С экспортированных рядов пометка снимается. C C...................................................................................C SUBROUTINE ABDEXPORT_DATA() USE HEADERS; USE ABD_INC logical*4 write_header, full_date_format ! Писать ли в вых-файл шапку и подробную дату character*1 export_format ! Формат экспорта integer*4, parameter :: $Max_formats=5 integer*4 i,ii,iline TYPE (KEY_CODE):: HotKey($Max_formats)= (/ 1 KEY_CODE($X,ichar('X')), 2 KEY_CODE($T,ichar('T')), 3 KEY_CODE($C,ichar('C')), 4 KEY_CODE($S,ichar('S')), 5 KEY_CODE($A,ichar('A')) /) c character*72 :: ASK_Text($Max_formats)= (/ 1 '"x"- записать ряды в простой текстовый файл с выравниванием столбцов', 2 '"t"- записать ряды в CSV-файл (ASCII-текст), разделитель "табуляция"', 3 '"c"- записать ряды в CSV-файл (ASCII-текст), разделитель "запятая"', 4 '"s"- записать ряды в CSV-файл (ASCII-текст), разд. "точка с запятой"', 5 '"a"- экспортировать данные в ana+anp-формат'/) c character*156 :: TTH_Text($Max_formats)= (/ 1 'Значения данных будут записаны в виде выровненных столбцов.'//$EOL// + ' Для выравнивания столбцов между ними добавляются пробелы.', 2 'Каждое значение данных отделяется от предыдущего значения табуляцией.'//$EOL// + ' Этот формат удобен для импорта в Excell и некоторые другие программы', 3 'Каждое значение данных отделяется от предыдущего значения запятой.'//$EOL// + ' Некоторые версии Excell требуют точку с запятой, а не запятую.', 4 'Каждое значение данных отделяется от предыдущего значения точкой с запятой.'//$EOL// + ' Некоторые версии Excell требуют вместо точки с запятой запятую', 5 'Данные будут экспортированы в бинарные файлы стандарта Zetlab.'//$EOL// + ' Каждый ряд записывается в два файла: ana-файл с данными и anp-заголовок.'/) c c c.....1. Пометить текущий ряд, если ничего не помечено: call mark_current_if_none() c c.....2.Выбрать режим экспорта: c c 2.1. Открыть окно для вопроса: call abdmain_ask_open(SCols-8,ask_window_shift(ecursor),16) call window_label('Экспорт отмеченных рядов') c c 2.2. Напечатать меню, установить регионы мышки - синонимы: call mouse_unreg() call TTHelp_unreg() ii=$Max_formats/2+1 call screen_putl(LFA-ii-1,c_col-32,'В каком формате экспортировать данные? Выберите один из вариантов:') do i=1,$Max_formats iline=LFA-ii+i call screen_putl(iline,c_col-32,ASK_Text(i),TTH_text(i),HotKey(i)) end do call mouse_reg() call TTHelp_reg($TTHELP_Normal) c c 2.3. Выбрать тип файла для записи данных = установить export_format: call save_conf($SC_Read,$SC_AbdMdExport) ! ABDEXPORT_DATA export_format=win_ltl(saveconf.c1) if (.not.inset(export_format,'xtcsa')) export_format='x' ansyer_default=export_format dos_line='Нажмите X, T, C, S или A'; charset='teXt, csv-Tab, csv-Comma, csv-Semicolon, Ana+anP' call screen_char_in(LFA-ii+$Max_formats+2,$Hue_In1,AllowF2=$AllowF2,Forbidden_symbols=', _-+') c select case(ansyer) case('X'); export_format='x' case('T'); export_format='t' case('C'); export_format='c' case('S'); export_format='s' case('A','P'); export_format='a' case default; goto 900 ! аварийный выход, возможен в случае ansyer=$charEsc,$charF10 end select saveconf.c1=win_ltl(export_format) call save_conf($SC_Write,$SC_AbdMdExport) ! ABDEXPORT_DATA c c.....3. Экспорт в anp-формате: SELECT CASE(export_format) CASE('a') call abdexport_anp_data() c c.......4. Экспорт в текстовом виде и в CSV: CASE('x','t','c','s') call inbox_clear() if (export_format == 'x') then; dos_line='Экспорт отмеченных рядов в текстовом формате' else; dos_line='Экспорт отмеченных рядов в CSV-формате'; end if call window_label(dos_line) write_header=saveconf.l1 ansyer_default='n'; if (write_header) ansyer_default='y' dos_line='Записывать ли в экспорт-файл названия рядов'; call set_ynh_charset() call screen_char_in(LFA-2,$Hue_In) if ((ansyer == $charF10).or.(ansyer == $charEsc)) goto 900 write_header=(ansyer == 'Y'); saveconf.l1=write_header c full_date_format=saveconf.l2 ansyer_default='n'; if (full_date_format) ansyer_default='y' dos_line='Записывать ли в экспорт-файл календарную дату'; call set_ynh_charset() call screen_char_in(LFA-1,$Hue_In) if ((ansyer == $charF10).or.(ansyer == $charEsc)) goto 900 full_date_format=(ansyer == 'Y'); saveconf.l2=full_date_format call save_conf($SC_Write,$SC_AbdMdExport) ! ABDEXPORT_DATA c c Собственно экспорт. Если он прерван, считаем, что так и надо (что записалось - то записалось): call ABDEXPORT_TEXT_CSV_DATA(export_format,write_header, full_date_format) END SELECT c c.....5. Завершающие операции: очистить и закрыть окно: 900 call close_window(1) endИ - да, я в курсе, что в современных языках пользовательский интерфейс пишется по другому. Но у меня основная задача программы - перемалывание чисел, поэтому интерфейс организован as is. Точнее, в современном фортране есть стандартный интерфейс к виндовым окошкам и диалоговым боксам. Но когда мы переписывали пакет под винду, то оказалось, что для простого сохранения функциональности DOS-версии этих стандартных средств недостаточно; нужны определенные танцы с бубном. Поэтому в подобных диалогах до сих пор остался legacy-код из DOS-версии. Я выбрал эту функцию для иллюстрации вопроса про стиль комментариев не для того, чтобы получить советы по рефакторингу диалогов (это тоже интересно, но уместнее сделать отдельно), а потому, что она дает хороший пример огромной функции с понятной линейной логикой.
YDR
02.12.2022 22:44я вот стал примеры данных приводить в комментариях. Не знаю, насколько так общепринято, но мне удобно. (так я и до тестов дойду, буду эти данные из комментариев скармливать тестам)

doomguy49
03.12.2022 04:08-1Поддерживаю. В определенный момент поймал себя на мысли, что комментарии только усложняют чтение кода. Если без них не очевидно, что делает код – нужен рефактор. Даже сложные вещи состоят из простых составляющих
И код, и комментарий может вводить в заблуждение, но код хотя бы выполняется согласно своду формальных правил, и его результат все равно предсказуем, а вот комментарий может быть совсем не связан с реальностью

rombell
03.12.2022 21:30Комментарий тут должен быть не вида «если пройден чек, то делаем то-то», а вида «так как возможна ситуация… необходимо проверить...», если уж он необходим, по мнению автора кода или ревьюера.
if(someCheck()){ ... }else{ ... }
Собственно, у меня принцип при работе с новичками в проекте (неважно, какого уровня новичками, хоть джунами, хоть сеньорами помидорами) — если написанное в коде вызывает вопросы вида «для чего это?», необходим комментарий. Если вопросы вида «почему реализовано именно так?», тоже почти всегда необходим.

IronKaput
03.12.2022 10:02+2Комментариям верить нельзя, они не выполняются.
Тестам верить нельзя, и ревьюверам тоже нельзя верить. Вы с таким не сталкивались, когда тесты ничего не тестируют, а проверяющие ничего не проверяют?

panteleymonov
02.12.2022 18:26+4Комментарии в основном используются для комментирования идеи и обобщения в помощь самому разработчику или для doxygen-а, в остальном, поддержке и разбору кода они слабо способствуют какие бы вы условия их использования не ставили.
А тот пример что вы привели проще обернуть отдельной функцией и по ее названию будет понятно что делает это строчка.

TheTryProgrammerName
02.12.2022 18:27+6Есть мнение, что хороший код должен обходиться вообще без комментариев и при этом не терять в понятности. На реальных проектах такое возможно невозможно, но пытаться двигаться в эту сторону, а не писать комментарий на каждую непонятную фичу, думаю, стоит.
rombell
03.12.2022 21:36+2Код может быть прекрасно понятен, однако совершенно непонятно его назначение, либо же непонятно, почему именно такая реализация выбрана. Зачем в этом месте мы используем ручную реализацию аля красно-чёрное дерево? И почему именно красно-чёрное?
И в этом случае без комментария не обойтись.

Siddthartha
02.12.2022 20:49только если то, что она делает можно просто сформулировать на естесственном языке. ) что далеко не всегда возможно. это могут быть какие-то манипуляции с данными и проще чем кодом их никак не опишешь..

General_Failure
02.12.2022 21:20+1Знаете, с комментарием лучше
Выглядит правда как-то так:# Вот так рисуется сова
drawEyes()
drawOwl()

Layan
03.12.2022 01:10Гораздо проще понять эту строку, если есть рядом функция, которая ее тестирует, и в которое есть выходные и входные данные, которые ей обычно будут переданы.
MaryRabinovich
02.12.2022 18:19+6На втором повторении парсинга квери стринги задумалась, правда ли на питоне делают вот так вот. Я питон знаю плохо, так что вопрос логичный - чего я такого не знаю, что уже есть, видимо. Это же очень частая ситуация, парсинг строки с параметрами. Вопросик и амперсанд, потом ещё квери-параметры - какие ещё сомнения могут быть.
Очевидно, прослеживается стремление выцепить какой-то параметр... хотя нет: странно просить после парсинга по амперсанду что-то с конца да в три символа по длине. Было бы как-то понятнее, если бы мы ключ пропускали. Будучи, скажем, уверены, что ключ там только один, длиной на три символа. Только было бы не -3, а просто 3. Но кто же так делает - вдруг там однажды добавят туда же ещё один ключ, и новый придёт как раз первым.
Беглый загугл по теме показывает, что уже несколько лет есть, как минимум, библиотечка urllib.parse . Про ту же библиотечку в официальной доке .
Собственно, если вы пишете что-то, по всей видимости, часто употребимое, видимо, под это дело есть уже либо либа сторонняя, либо, как тут, встроенное в языке что-нибудь.

sshikov
02.12.2022 20:27+3>На втором повторении парсинга квери стринги
Ну, на мой взгляд проблема в том, что изначально не было написано, что мы парсим. Если бы сразу было написано, что это URL, практически все было бы очевидно, и я бы тоже взял библиотечку (хотя см. ниже).
>Вам сложно прочитать эту строку? Мне тоже.
Мне нет.Вам нужно знать, что такое map, lambda и .split().
Это очевидно. Первые два есть во многих языках, split вообще практически везде.Переменные x и s, строки '=', '?' и '&', индекс [1], и слайс [-3:] занимают место в
кратковременной и рабочей памяти.
Нет, не занимают. Потому что люди даже не сильно опытные не держат в памяти такую фигню. Вот я работаю с питоном хорошо если раз в пять лет (а всего где-то с 2010), и единственное что мне тут было непонятно сразу — это [-3:]. Причем скорее по тем же причинам, что и вам — непонятна цель, то что это слайс — тоже в общем очевидно, и тоже для питона не уникально.Суммарно это десять элементов!
Десять элементов, хи-хи. А ничего, что есть множество людей, способных запомнить книгу типа «Евгения Онегина»? Нет, я вот не такой — но страниц 10 стихов я спокойно запоминал, особенно тех что нравятся. И ничего в этом нет необычного — просто надо понимать, что никто и никогда не помнит все буквы книги, а помнят на более высоком уровне, а мелкие детали вспоминаются по ассоциации. Точно так же и тут — для понимания как это работает, не нужно удерживать все десять деталей одновременно. map это одна сущность, причем вместе с лямбдой. И две сущности внутри — два раза split. Когда понимаешь, зачем это — тут вообще ничего сложного нет.

un1t
02.12.2022 20:51+1Конечно так не пишет никто, для этого есть специальные функции, это просто искусственный пример.
un1t
02.12.2022 20:56+4Как раз сегодня обсуждали, что я функцию map в питоне не использовал лет 6, Т.к. для этого есть генераторы списков и выражения генераторы.

v1000
02.12.2022 22:26+1Напоминает историю с клавиатурами - сколько придумали различных "удобных", которые решают различные недостатки стандартной клавиатуры, но все равно все сводится к стандартной, пусть и не такой удобной, но понятной большинству людей.

rtemchenko
02.12.2022 22:56+4Зачастую запутанный код - длинные файлы и функции с огромными уровнями вложенности и явными несоответствиями. А не вот это вот "как распарсить строку" написанное слишком заумно.

d-stream
03.12.2022 10:45+2Хм... 6?
Раньше звучала усредненное число - 7
Применительно к мгновенной памяти/охвату. Точнее звучало как "от 5 до 9".
И предлагался простой метод измерения своего размера этого буфера: высыпаем на ладонь несколько спичек, сжимаем в кулак, потом кратковременно открываем и пытаемся сказать сколько их.
Дальше измерения можно модифицировать. Например применив разные предметы.

arheops
04.12.2022 04:07Как считающий мгновенно по 12-15 могу сказать, что метод неочень.
Поскольку мгновенный счет обьектов тренируется, а временная память — не сильно. Она у меня меньше, в районе 7 была, сейчас скорее всего еще меньше.
Мгновенный счет тренируют для математических олимпиад некоторые. Тренируется он обычно «обучая» мозг воспринимать, к примеру, тройку обьектов как одну ячейку. Соответсвенно 3х5=15, и еще 2 ячейки на охват разницы в последней тройке.d-stream
04.12.2022 12:37Ну не знаю. Это же речь не о счёте как таковом, а мгновенном охвате. Хотя похоже это где-то рядом. А тренировки скорее не отращивают размер кэша, вырабатывают практики опознания как объекта чего-либо крупного.
Как образчик - код, написанный по заветам например той же "банды четырех" иногда читается не строками и символами, а целыми узнанными паттернами и охват восприятия резко расширяется с 5-7-9 переменных/выражений до 5-7-9 огромных знакомых кусков.

vvbob
03.12.2022 10:47+4Читаешь все эти правильные статьи про красивый код.. а потом открываешь свою любимую IDE и пытаешься вкрячить какую-то логику по текущей задаче, в метод, размером в 4000+ строк (не шучу, реальный случай из недавней практики).
Конечно, такой говнокод надо рефакторить, кто-бы спорил-то. Но, объективно говоря, один только его нормальный рефакторинг займет не один месяц, а на задачу у тебя отпущено не больше недели. Так ведь, по хорошему, отрефаченный метод придется еще и тестировщикам проверять потому что поломаться там может все что угодно Бизнес на такое не согласен.. Вот и ковыряешься в этом всем, пытаясь по максимуму все вынести в отдельные сервисы, но это не всегда оказывается возможным сделать, без нормального рефакторинга. И как итог работы над задачей - Метод4000+ получает в себя еще пару десятков строк..
Какое счастье что я там уже не работаю, и мне больше не придется в этом всем ковыряться.

ainoneko
03.12.2022 12:37+3> Ваш мозг разбивает синтаксис вида
s.split('?')[1]на «часть строки справа от вопросительного знака».
А ничего, что справа от первого вопросительного знака могут быть ещё?
Я бы написал_, query_string = s.split('?', 1)
(или
_, query_string = s.split(sep='?', maxsplit=1)
(если код-стайл у нас такой))
, чтобы
(1) явно показать, что самый первый (нулевой) элемент нам не нужен (а не ошибочно написал [1] вместо [0] после другого языка программирования) и
(2) вquery_string попала бы вся остальная строка.
dyadyaSerezha
04.12.2022 06:43+1По обилию длиннющих комментов вижу, что разгорелась нешуточная холивар (или как теперь разрешено говорить, холисво).
Однако, не могу не заметить, что
Ваш мозг разбивает синтаксис вида
s.split('?')[1]на «часть строки справа от вопросительного знака».справа от первого вопросительного знака. От первого, Карл)
orion_tvv
04.12.2022 14:44Кошелек Миллера(или правило 5±2) чуть более общее империческое наблюдение чем ультимативное 6

DeepFakescovery
04.12.2022 16:40+1Каждая строка делает только одно действие
нет, спасибо. Есть комментарий в одну строку перед длинной строкой, который поясняет что делается. Это в разы лучше, чем строка разбитая на 10 более простых строк, которая забьёт вертикальный скролл и ухудшит читаемость.
строку кода, содержащую больше шести элементов информации, следует упростить.
не следует. Это пережиток консольного программирования, где больше 80 символов не умещалось. Сейчас же с широкоформатными мониторами и удобными IDE, читать и скролить горизонтально не составляет труда. Если длинная строка логически составляет одно действие, например что-то парсит, пусть она будет бесконечно длинной, комментарий перед ней всё расскажет.
Если код запутывает, разбивайте его на части
Разбейте его на меньшие части, вот и всё.
Если код запутывает, значит архитектура вашей программы - мусорка. Разбивать нужно на логические части, а не тупо проставить ентеров где попало.
Kanut
04.12.2022 16:42Сейчас же с широкоформатными мониторами и удобными IDE, читать и скролить горизонтально не составляет труда.
Особенно когда потом делаешь code review в гите....
DeepFakescovery
04.12.2022 18:21втыкать палки себе в колёса из-за несовершенства гита?
Kanut
04.12.2022 18:22Нет. Писать код с оглядкой на других.

orcy
05.12.2022 04:14не следует. Это пережиток консольного программирования, где больше 80 символов не умещалось.
Я считаю что лимит какой-то должен быть, потому как мониторы и размеры шрифтов у всех разные, кроме того есть 2-side diff, 3 way merge и случаи когда нужно делать code review.
Когда я помогал с преподаванием один студент штук десять строк сворачивал в одну строчку и говорил что ему вот так норм, он видит структуру программы.

vassabi
05.12.2022 15:39120 в ширину.
И это не для того чтобы лепить несколько строк в одну (за это мы больно бьем стажеров. шутка), а чтобы у функции и всех ее параметров были длинные хорошие имена
sfi0zy
Тут, наверное, стоит добавить, что в нашем распоряжении есть анализаторы кода (тот же Sonar), которые за всем этим могут следить, и в реальном времени подсказывать, если код становится сложным для восприятия.
Kenya-West
Sonar же локально не запускается? Только в CI. У нас почему-то такая ситуация была. Как минимум, я не нашёл npm-пакет, чтобы запустить его в Deno. Или это не так работает?
dolfinus
У Sonar есть локальный клиент sonar-scanner, который получает у сервера проверки и проверяет по ним код, отправляя обратно на сервер результаты. Так что технически он хоть и работает локально, все равно ему нужен сервер для работы.
Рекомендую использовать линтеры, они гораздо проще монструозного сонара и запускаются локально с локальным же конфигом. И не важно, где их запускать - в консоли, IDE или CI, поведение одно и тоже.
vassabi
у него есть плагины к ИДЕЕ, которые делают анализ кода
dyadyaSerezha
Именно делают? То есть, работают без сервера?
skozharinov
У них на сайте написано, что есть SonarLint, SonarQube и SonarCloud. SonarQube надо поднимать, за SonarCloud платить.
Ну и быстрая проверка показала, что плагин к CLion работает без интернета.
vassabi
сонарлинт работает без интернета. Возможно он поймает меньше багов, чем сонаркуб, но тем не менее - все на что он реагирует, сонаркуб тоже отреагирует, так что мы его используем как ориентир