В этом материале вы узнаете, как создать Telegram-канал, который будет сам обновляться, получая данные из открытых источников:
Код напишем на Python.
Запускаться он будет в AWS Lambda.
Для парсинга (т. е. получения) данных будет использоваться библиотека BeautifulSoup.
Чтобы добавить нашему софту persistance layer будем использовать базу данных AWS DynamoDB.
P. S. Все полностью бесплатно, Amazon ничего платить не нужно.
Цель статьи — объяснить работу с DynamoDB, BeautifulSoup и AWS Lambda. Если точнее — как связать все это в единый рабочий процесс для решения практической задачи.
Далее я опишу абсолютно синтетическую задачу, которая тем не менее отлично подходит в качестве простейшего примера для изучения вышеуказанных технологий.
Допустим вы фанат музыки жанра техно и хотите регулярно получать обновления о последнем поступившем музыкальном альбоме с вашего любимого сайта hardwax.com. Заходить на сайт вручную неудобно и вам бы хотелось иметь Telegram-канал, в котором каждые 15 минут публикуется последний музыкальный альбом. Задача осложняется тем, что вы не хотите видеть ни одну ссылку второй раз. Вы слушаете альбом единожды и полностью забываете про него. Таким образом, алгоритм должен запоминать, какие альбомы он уже публиковал в канале и не допускать повторной публикации.

1. Создание телеграм-канала и бота
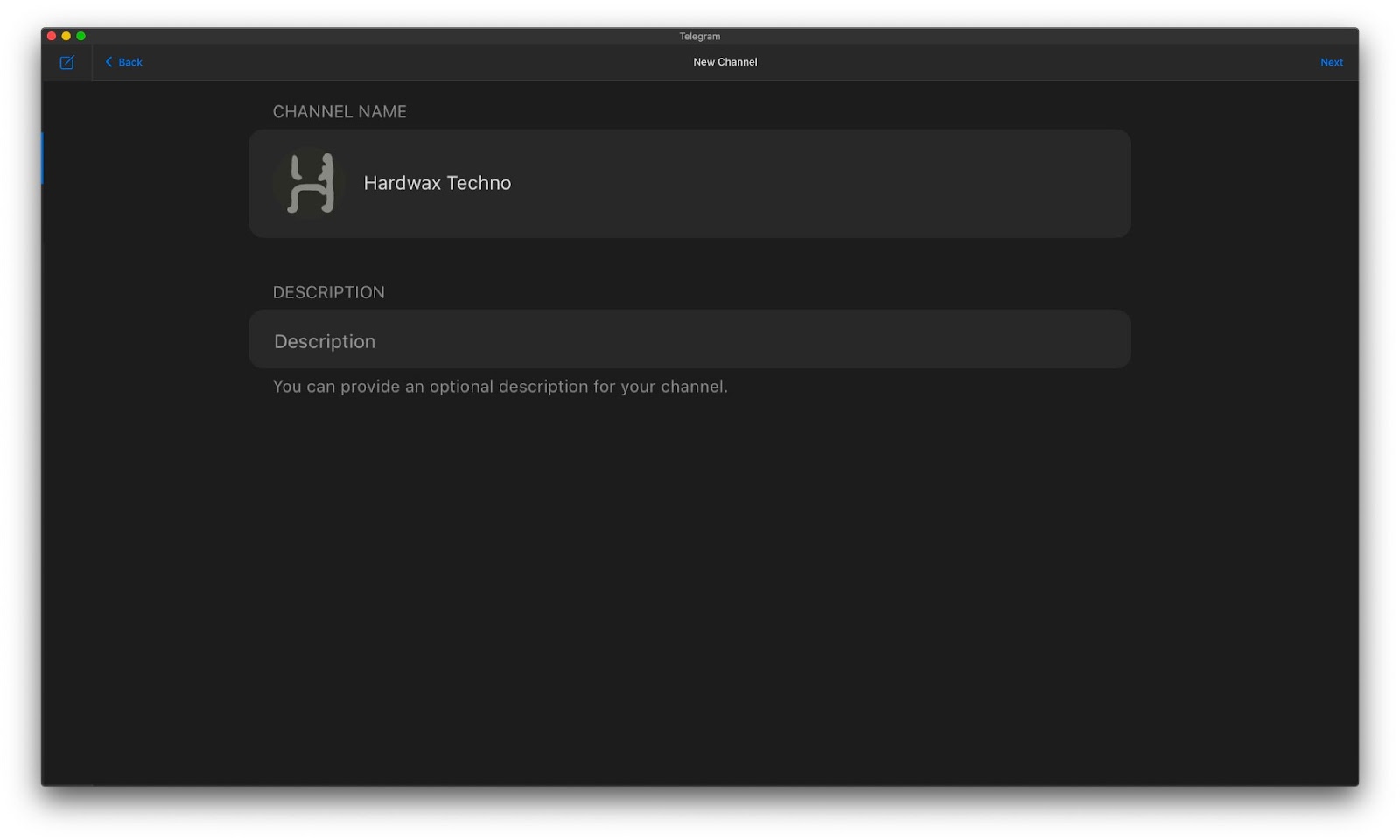
Итак, начнем. Для начала создадим Telegram-канал. Назовем его Hardwax techno:
Кто-то должен обновлять Telegram-канал, ведь сам по себе канал обновляться не может. Для этих целей создадим бота, который будет заниматься обновлением. В Telegram боты создаются через отца всех ботов — @BotFather:
Здороваемся (
/start)Создаем бота (
/newbot)Даем имя боту (
hardwax_techno_poster)Даем ему username (
hardwax_techno_poster_bot, должно заканчиваться на_bot)В конце получаем токен для управления ботом, его нужно сохранить.

Добавим созданного бота в администраторы, для этого переходим в настройки канала - > Administrators:

Далее Add Admin, выбираем нашего бота и проставляем все галочки:

2. Регистрация на AWS и создание функции
Сетап в Telegram готов, пора переходить к AWS. Очевидно, первое, что необходимо сделать это зарегистрировать аккаунт. Здесь подробно описано, как это сделать и ничего при этом не заплатить.
Сделали аккаунт AWS, переходим к созданию функции. Набираем в строке поиска ‘lambda’ и переходим в соответствующий раздел:

Нажимаем ‘Create function’, выбираем имя функции. Runtime = ‘Python 3.9’ или более поздняя версия.

3. Импортируем зависимости
Чтобы парсить веб и управлять Telegram-каналом нам понадобятся зависимости — библиотеки. Чтобы использовать их в AWS Lambda предусмотрены слои — своеобразные пакеты зависимостей, подключаемые к функции. Создадим такой слой.
Для этого нужно подготовить все необходимые библиотеки в .zip-архиве. Всего нам понадобятся 3 библиотеки:
requests— вездесущая библиотека Python для запросов.bs4или BeautifulSoup — набор инструментов для парсинга веб-страниц.python-telegram-bot— библиотека, упрощающая работу с ботами в Telegram.
Чтобы подготовить архив, на машине Mac или Linux с установленным Python3 и менеджером пакетов pip выполним в командной строке следующие команды:
Создаем директорию для архива, куда положим наши зависимости.
mkdir -p ~/python
Переходим внутрь созданной директории.
cd ~/python
Устанавливаем наши зависимости в текущую директорию, указывая подходящие версии.
pip install --target=. bs4==0.0.1 python-telegram-bot==6.1.0 requests==2.24.0
Возвращаемся обратно.
cd ~
Создаем архив с зависимостями.
zip -r hardwax_poster_layer.zip python
Загрузим получившийся .zip-архив с зависимостями в AWS.
Для этого наберем в поиске Layers -> Create layer. Задаем имя слоя hardwax_poster_layer, выбираем Upload a .zip file, указываем путь до архива. Далее выбираем архитектуру x86_64 и Runtime = Python 3.9.
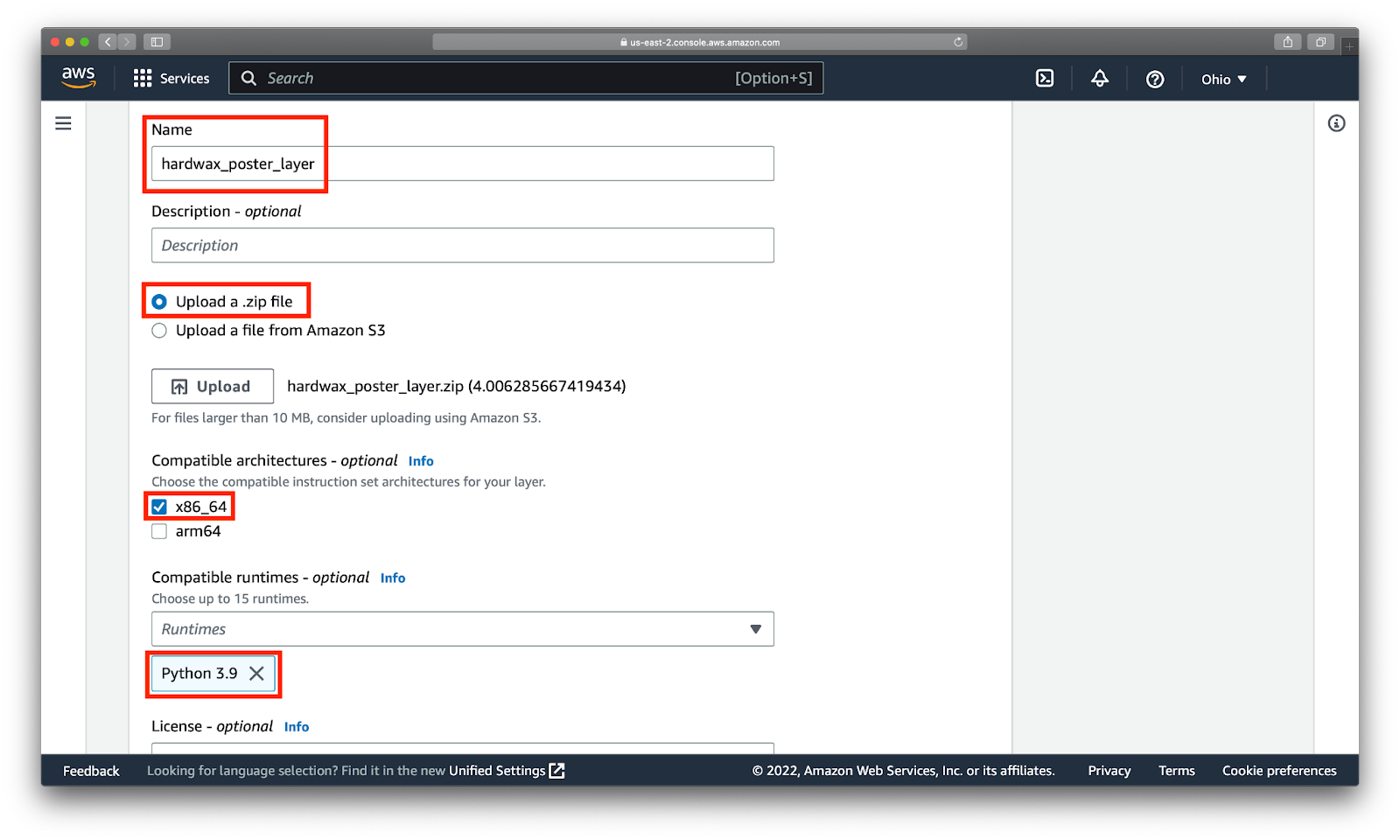
Мы успешно создали слой. Копируем и сохраняем его ARN (ID слоя или Amazon Resource Name), он пригодится нам дальше:
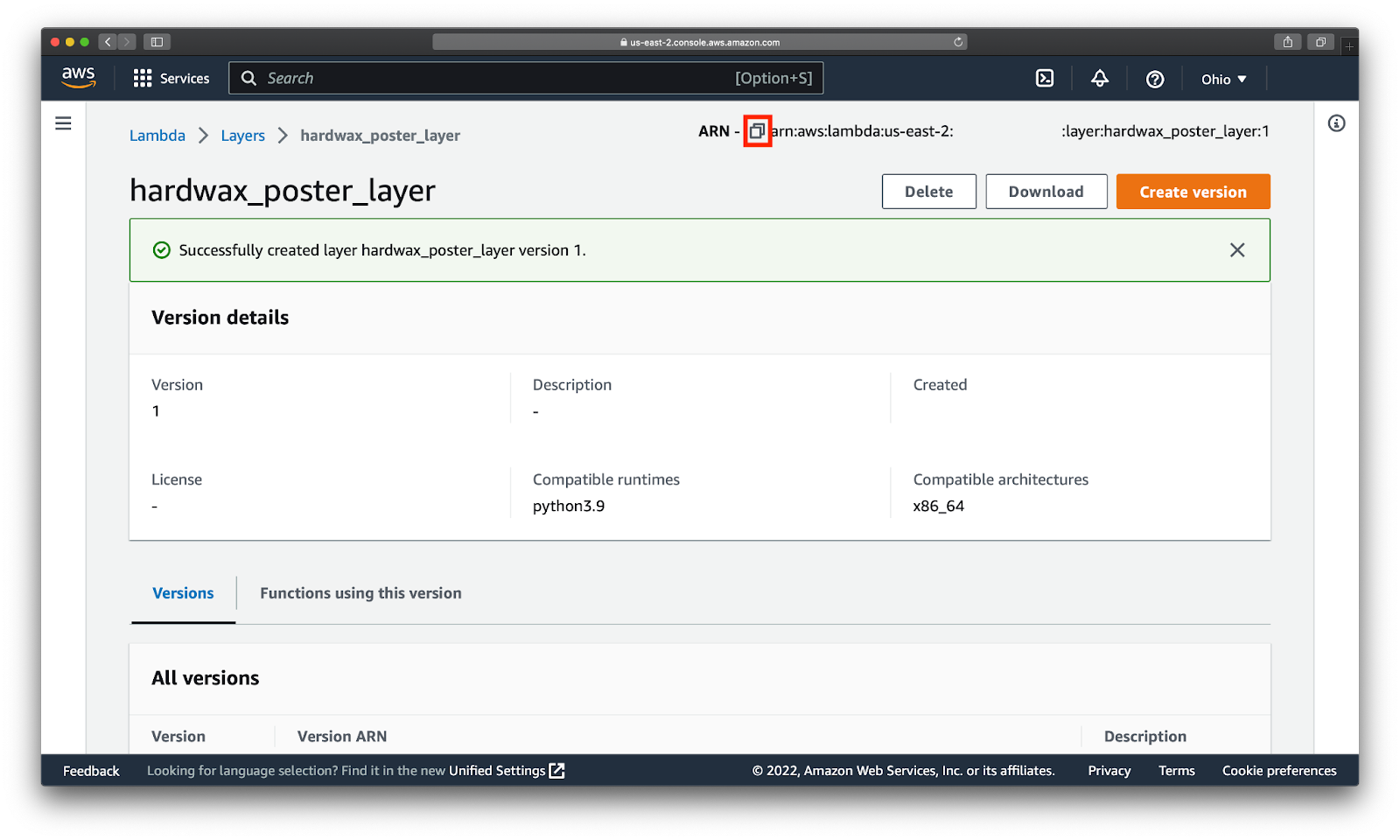
Добавим слой к нашей функции. Для этого переходим на страницу управления нашей функцией, скроллим вглубь страницы и выбираем Add layer:

Кликаем Specify an ARN, вводим в поле ранее полученный ARN слоя. Нажимаем Verify, чтобы убедиться, что все корректно. Наконец жмем Add, чтобы прикрепить слой к функции.

Протестируем, что в окружении AWS теперь действительно есть наши зависимости. Для этого прямо в браузере модифицируем код, чтобы функция в ответ печатала версию библиотеки для работы с Telegram из наших зависимостей. Нажимаем Deploy, чтобы изменения вступили в силу.
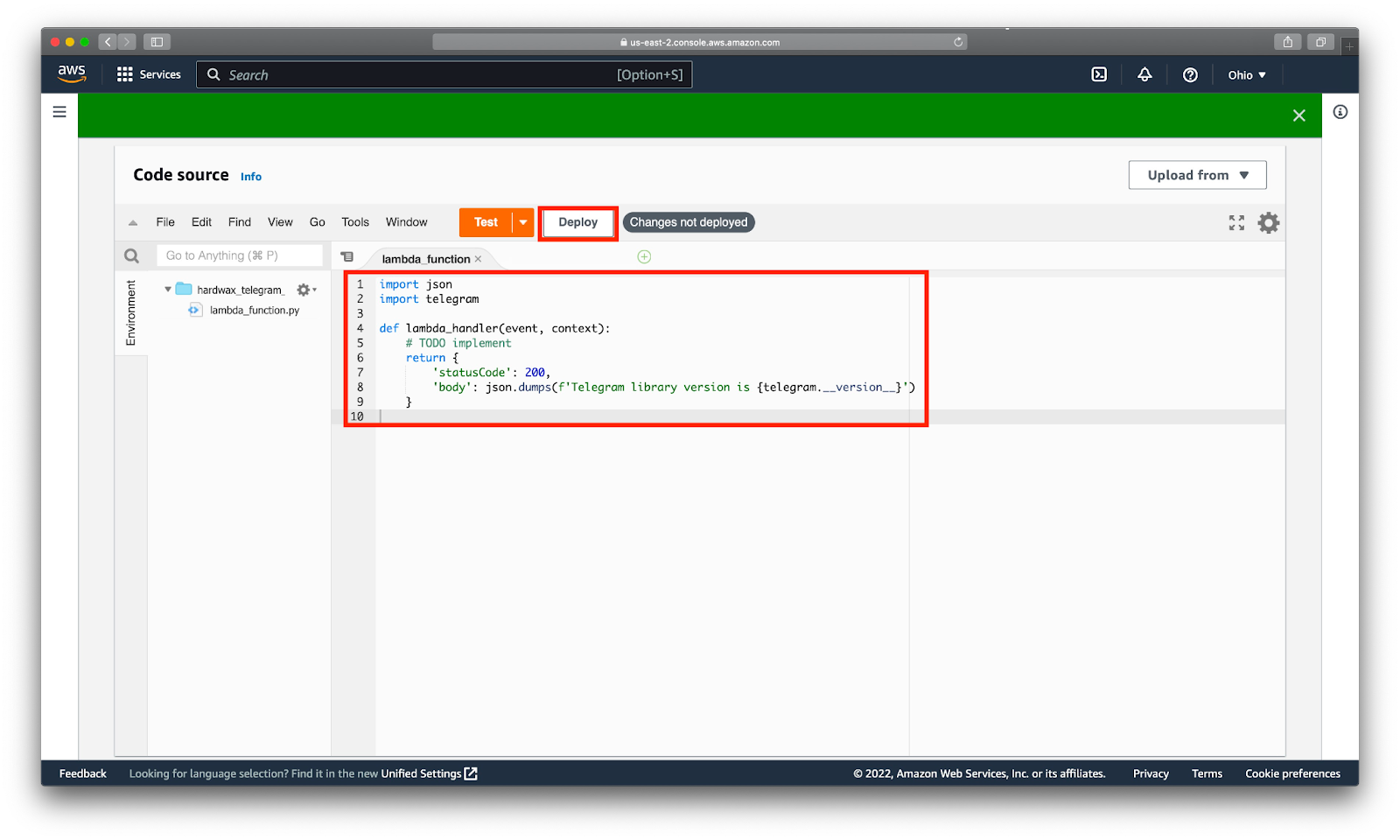
import json
import telegram
def lambda_handler(event, context):
# TODO implement
return {
'statusCode': 200,
'body': json.dumps(f'Telegram version is {telegram.__version__}')
}Прежде чем AWS даст протестировать наш код, нужно создать тестовое событие. Для этого нажимаем на большую оранжевую кнопку Test. В нашем случае нам не нужно делать ничего, кроме как дать событию имя вроде my_test_event. В других случаях в функцию можно передавать различные JSON - объекты и удобно смотреть, как она их обрабатывает.
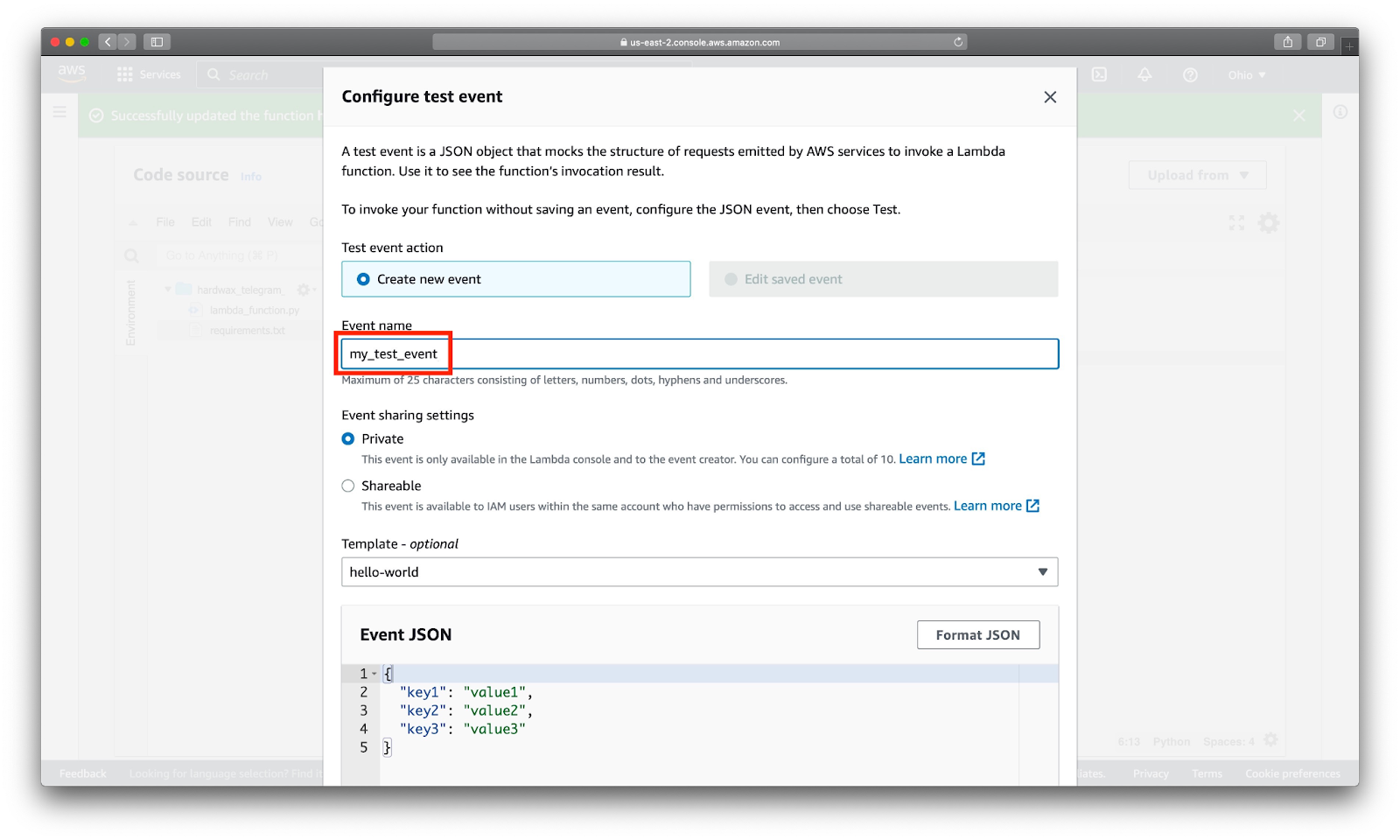
Снова нажимаем большую оранжевую кнопку Test и AWS запускает наш код. Переходим во вкладку Execution result и видим, что функция вернула корректную строку Telegram library version is 6.1.0. Это значит, что наши зависимости в окружении и можно идти дальше.
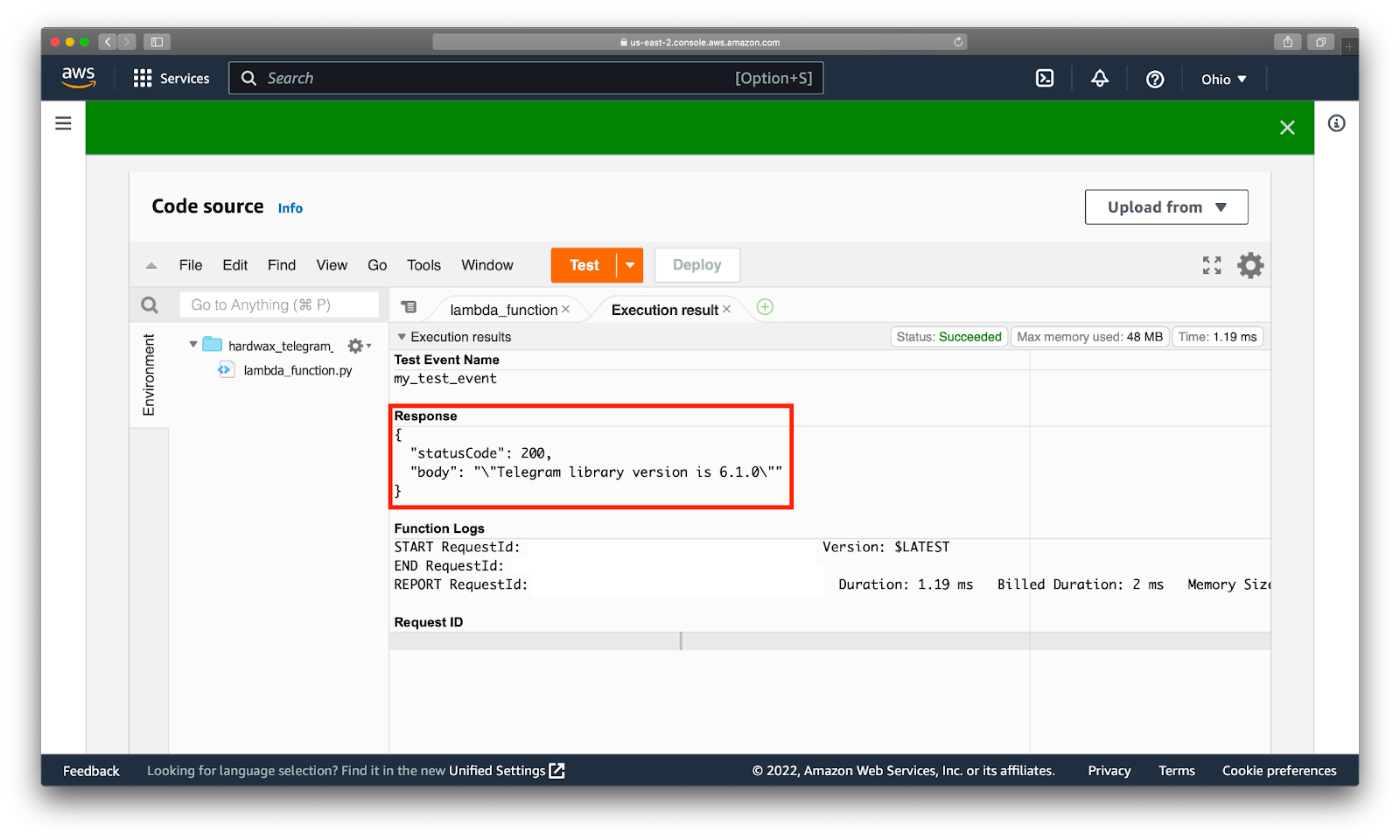
4. Задаем переменные среды
Мы собираемся обновлять Telegram-канал с помощью нашей функции. Для этого в код необходимо передать токен для бота, который будет публиковать новые посты в канале в качестве администратора. Лучший способ сделать это — создать Environment variable или переменную среды для токена. Просто вписать токен в тело кода небезопасно. Чтобы создать переменную среды переходим в Configuration -> Environment variables -> Edit.
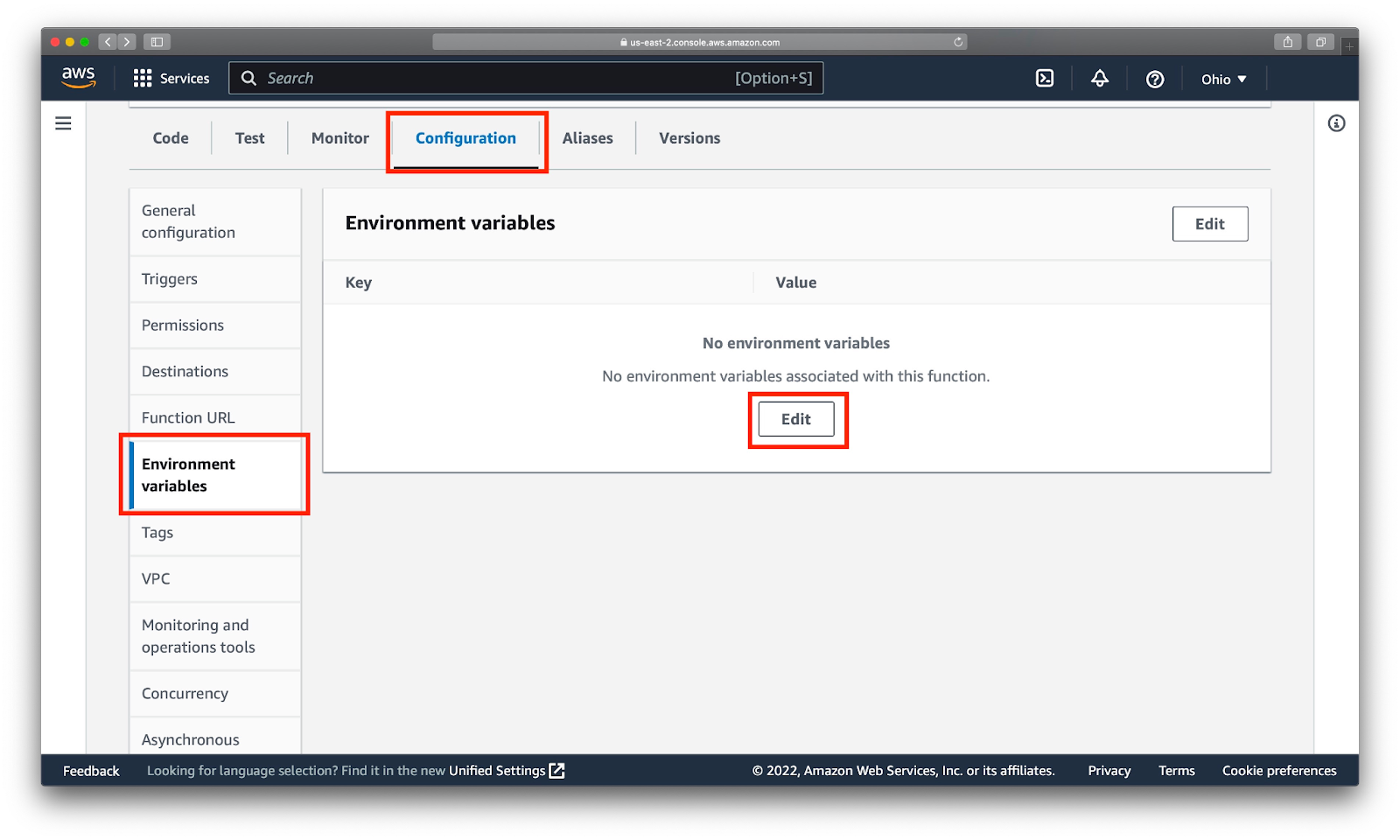
Добавляем переменную с названием telegram_token и значением токена, который мы ранее получили от бота:

5. Выставляем таймаут
Также поменяем таймаут функции или максимальное время ее работы. По умолчанию у AWS Lambda функций он выставлен на 3 секунды, что слишком мало для нашего случая. Для этого перейдем General configuration -> Edit.

Для нас больше подходит таймаут в 15 минут:

6. Настраиваем роли
По умолчанию AWS не разрешает использовать DynamoDB из AWS Lambda. Это сделано из соображений безопасности, поэтому сперва нам нужно настроить права. Для этого наберем в строке поиска Roles. Здесь мы видим список всех ролей, которые есть в нашем аккаунте AWS. Отдельная роль автоматически создается под каждую Lambda-функцию. Мы можем найти роль, которая была создана для нашей ф-и с помощью поиска, как показано на скриншоте:
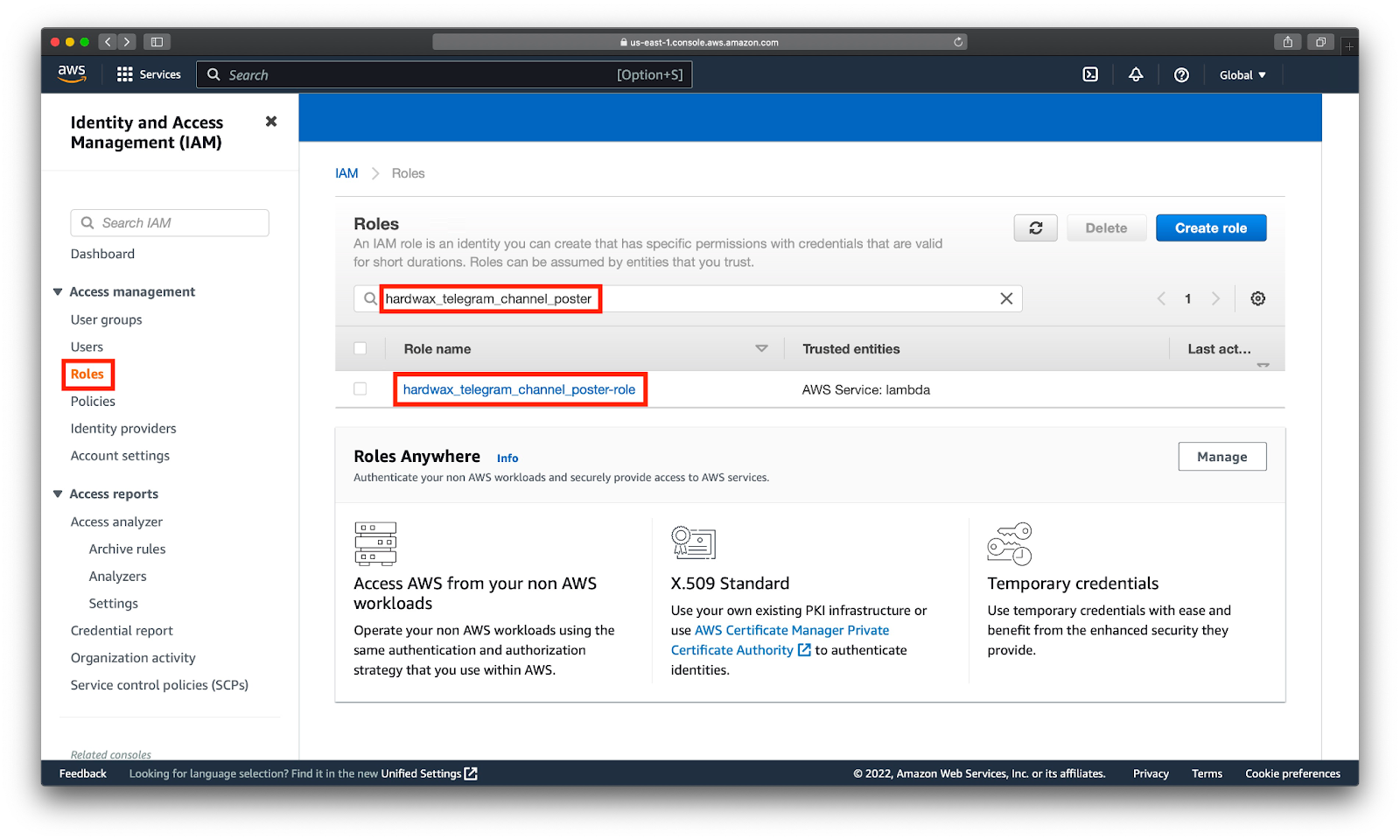
Прикрепим к роли ф-и права для управления DynamoDB. Для этого нажимаем Attach policies:

Находим с помощью поиска нужные нам права AmazonDynamoDBFullAccess, выбираем Attach policies:
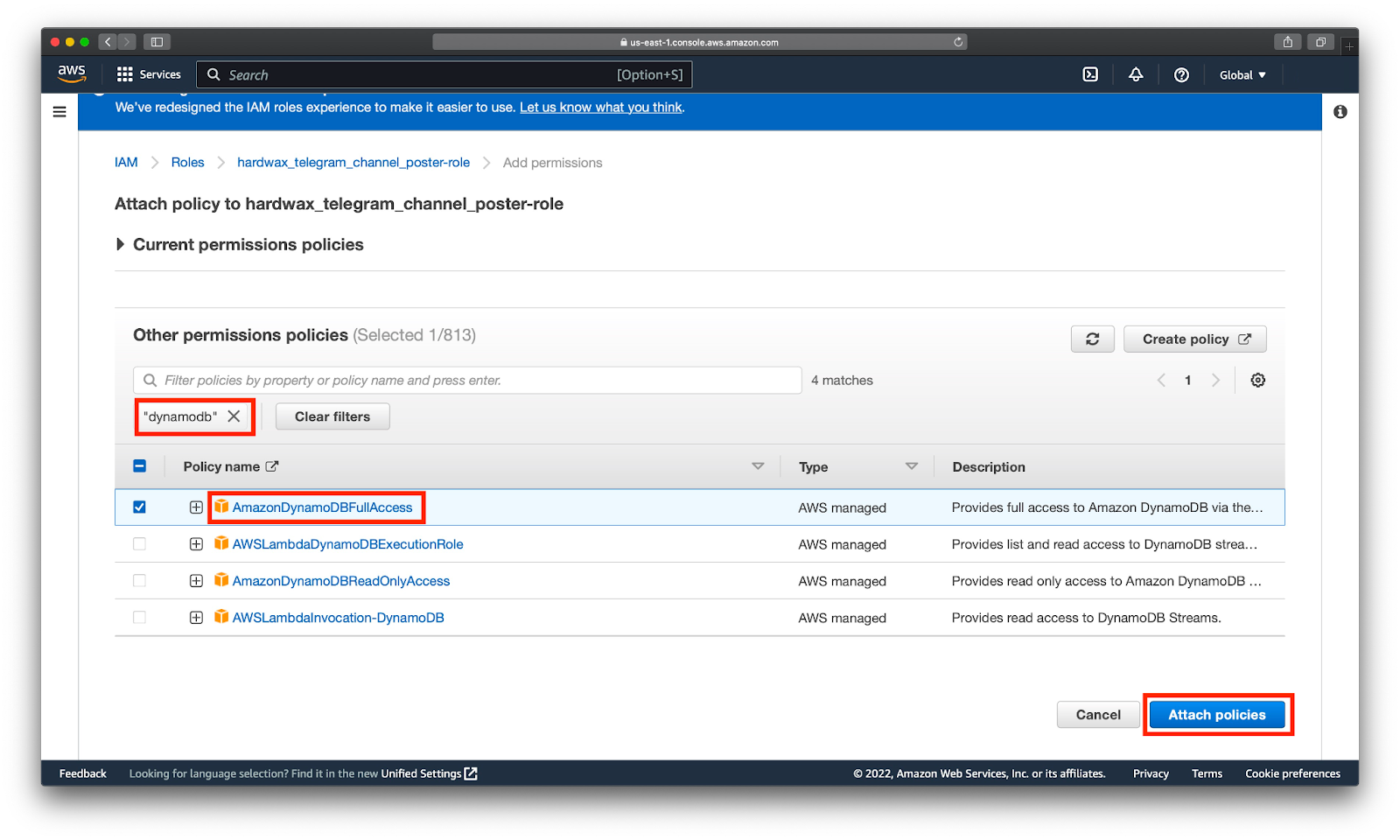
Перед запуском скрипта посмотрим, что в DynamoDB нет таблиц. Для этого наберем в поиске DynamoDB:
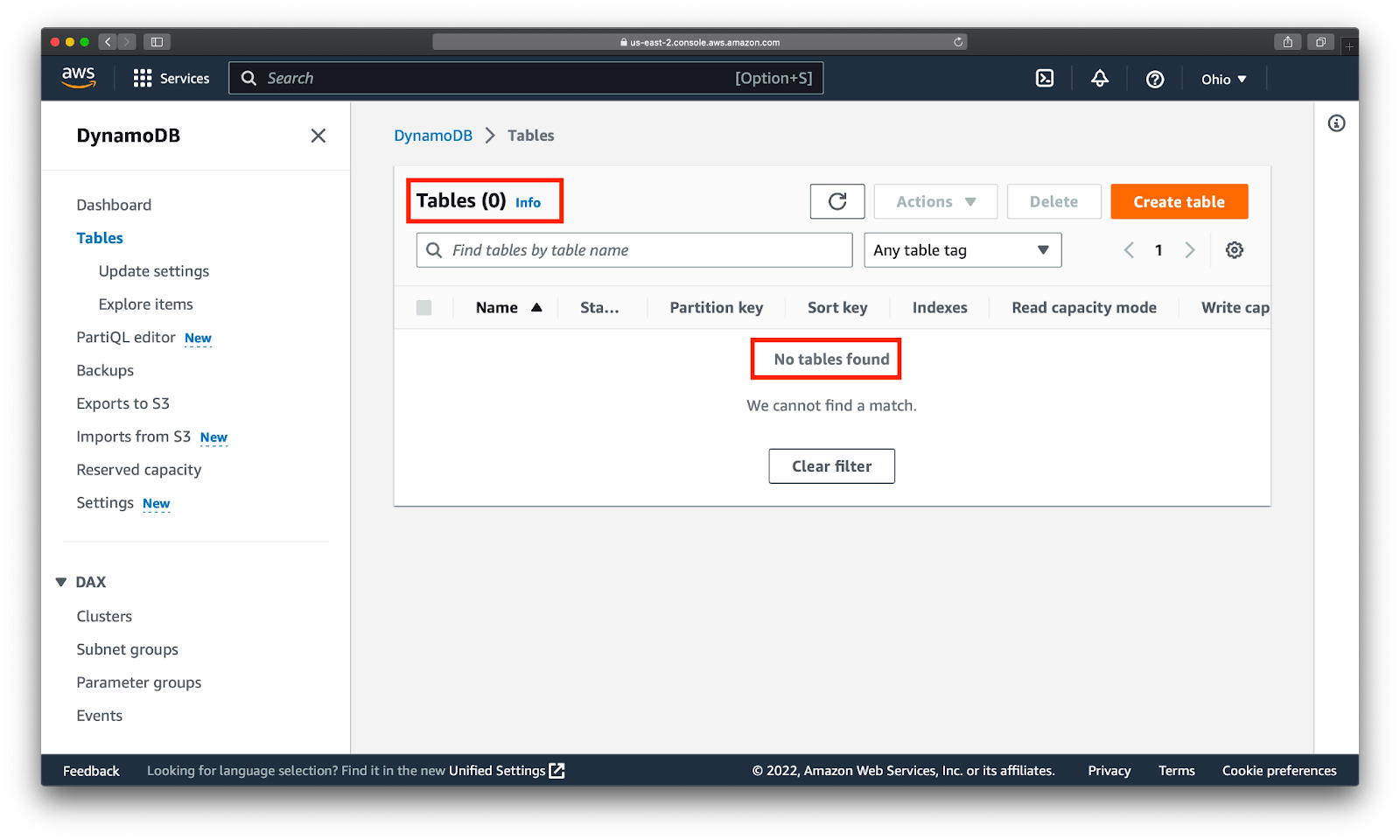
7. Код
Права настроены, переменные среды инициализированы, зависимости подтянуты. Теперь можно перейти к коду. Используем следующий код:
import requests
import boto3
from boto3.dynamodb.conditions import Key
from bs4 import BeautifulSoup
from botocore.exceptions import ClientError
import telegram
import os
def lambda_handler(event, context):
# Create table if necessary
dynamodb = boto3.resource('dynamodb', region_name='us-east-2')
table_name = 'HardwaxLinks'
try:
params = {
'TableName': table_name,
'KeySchema': [
{'AttributeName': 'Link', 'KeyType': 'HASH'},
],
'AttributeDefinitions': [
{'AttributeName': 'Link', 'AttributeType': 'S'}
],
'ProvisionedThroughput': {
'ReadCapacityUnits': 10,
'WriteCapacityUnits': 10
}
}
table = dynamodb.create_table(**params)
table.wait_until_exists()
except ClientError:
table = dynamodb.Table(table_name)
page_number = 1
keep_going = True
while keep_going:
page_url = f'https://hardwax.com/techno/?page={page_number}'
print(f'Getting albums from {page_url}')
# Get all album links from page
response = requests.get(page_url).content
soup = BeautifulSoup(response, "html.parser")
page_album_links = ['https://hardwax.com' + x.get('href')\
for x in soup.findAll('a', {'class': 'an'})]
n_albums = len(page_album_links)
if n_albums > 0:
page_number += 1
print(f'Got {n_albums} albums...')
for link in page_album_links:
already_processed =\
len(table.query(KeyConditionExpression=Key('Link').eq(link))\
['Items']) > 0 # check if a link is in the table
if not already_processed:
bot = telegram.Bot(token=os.environ['telegram_token'])
bot.send_message(chat_id="@hardwax_techno",\
text=f'{link}', parse_mode=telegram.ParseMode.HTML)
table.put_item(Item={'Link': link}) # update table
print(f'Posted {link}')
return
else:
print(f'Already processed {link}')
else:
keep_going = FalseЧто делает код?
Создаем таблицу на DynamoDB с одним полем Link. В таблице будет храниться все опубликованные в канале ссылки. Если таблица уже создана, то пропускаем этот шаг. Для этого добавляем try/except блок.
-
Переходим по ссылке https://hardwax.com/techno и листаем страницы. На каждой новой странице делаем следующее:
Получаем список ссылок на альбомы с этой страницы, используя библиотеку BeautifulSoup. Перестаем листать, если количество таких альбомов 0, т. е. мы дошли до конца.
Для каждой ссылки проверяем, есть ли она в таблице DynamoDB. Это можно делать за константное время, в этом прелесть этой базы данных. Таблица представляет из себя нечто вроде огромного словаря и по хэшу получает значения для ключа (нашей ссылки). В данном случае значением является простое наличие ссылки в таблице.
Если ссылка есть в таблице, то пропускаем ее. Это значит, что мы уже публиковали ее в канале.
Если ссылки нет в таблице, то публикуем ее в канал и добавляем в таблицу новую запись. В следующий раз она будет присутствовать в таблице и мы сможем пропустить ее. Как только ссылка опубликована и запись в таблицу добавлена, завершаем выполнение функции. В противном случае продолжаем, пока не найдем ссылку для публикации.
Обновляем файл lambda_function.py из браузера. Не забываем нажать на Deploy, чтобы изменения вступили в силу. Код обновлен, давайте протестируем, нажав Test:
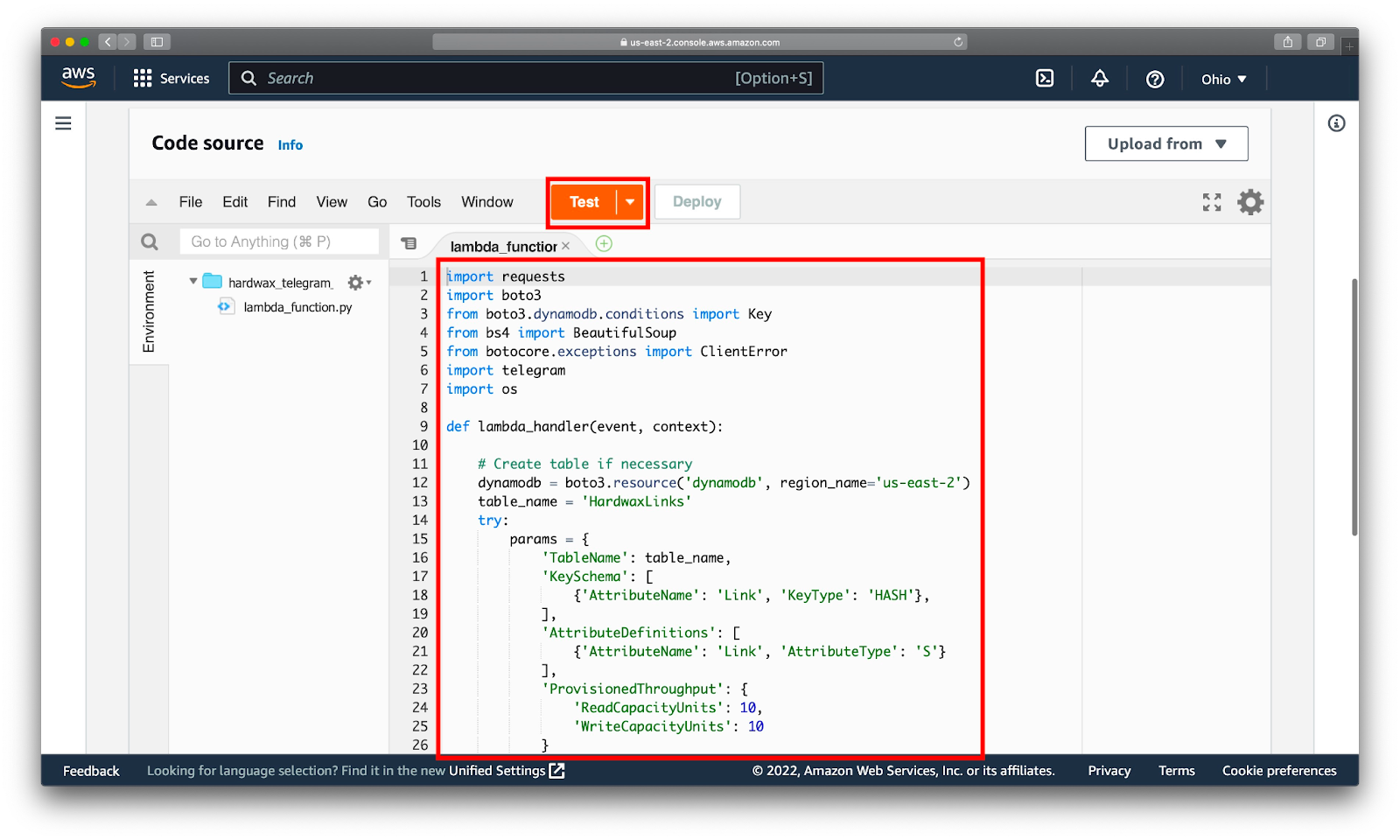
Выполнение завершилось, посмотрим результаты. Из логов видно, что ф-я получила 45 альбомов на первой странице и запостила первый же из них.

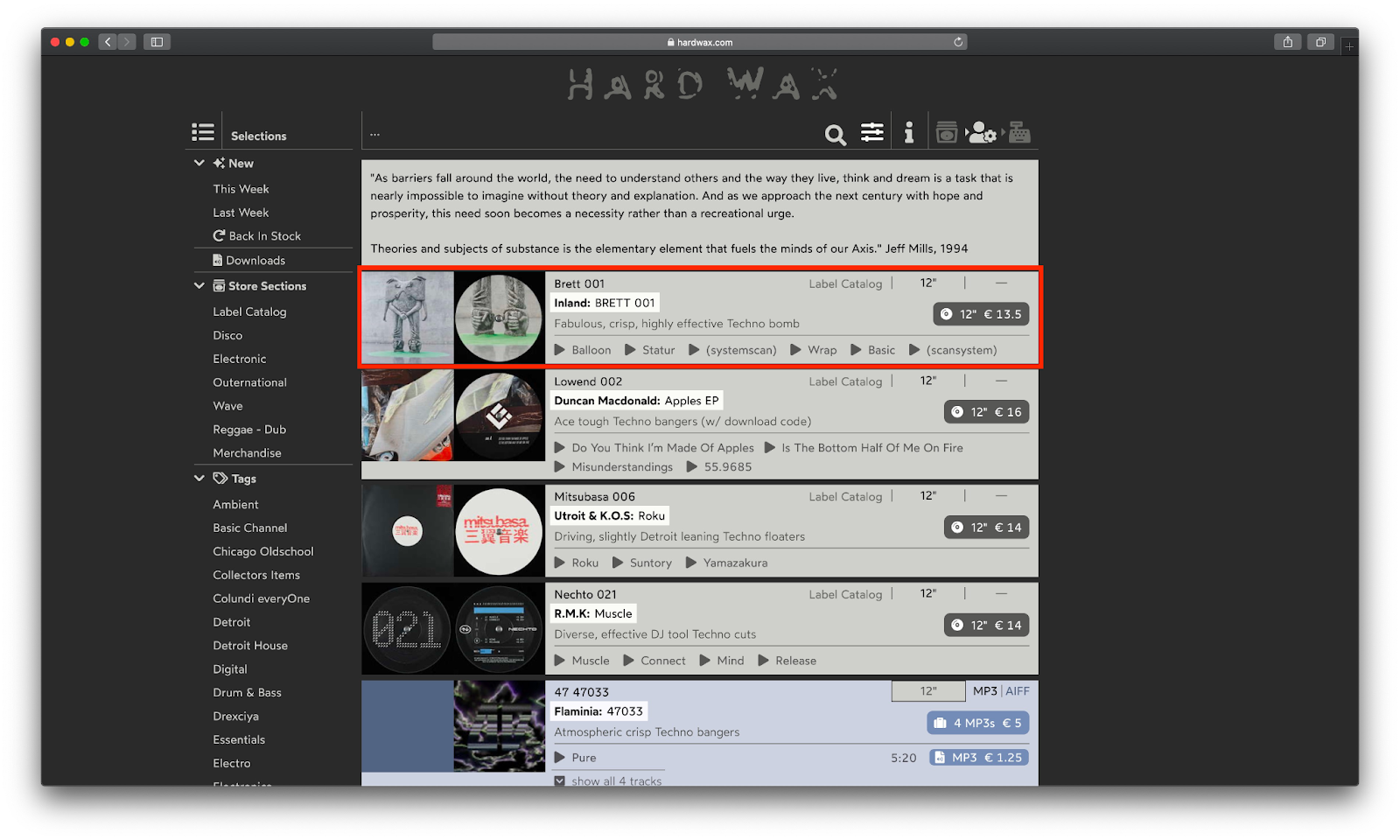
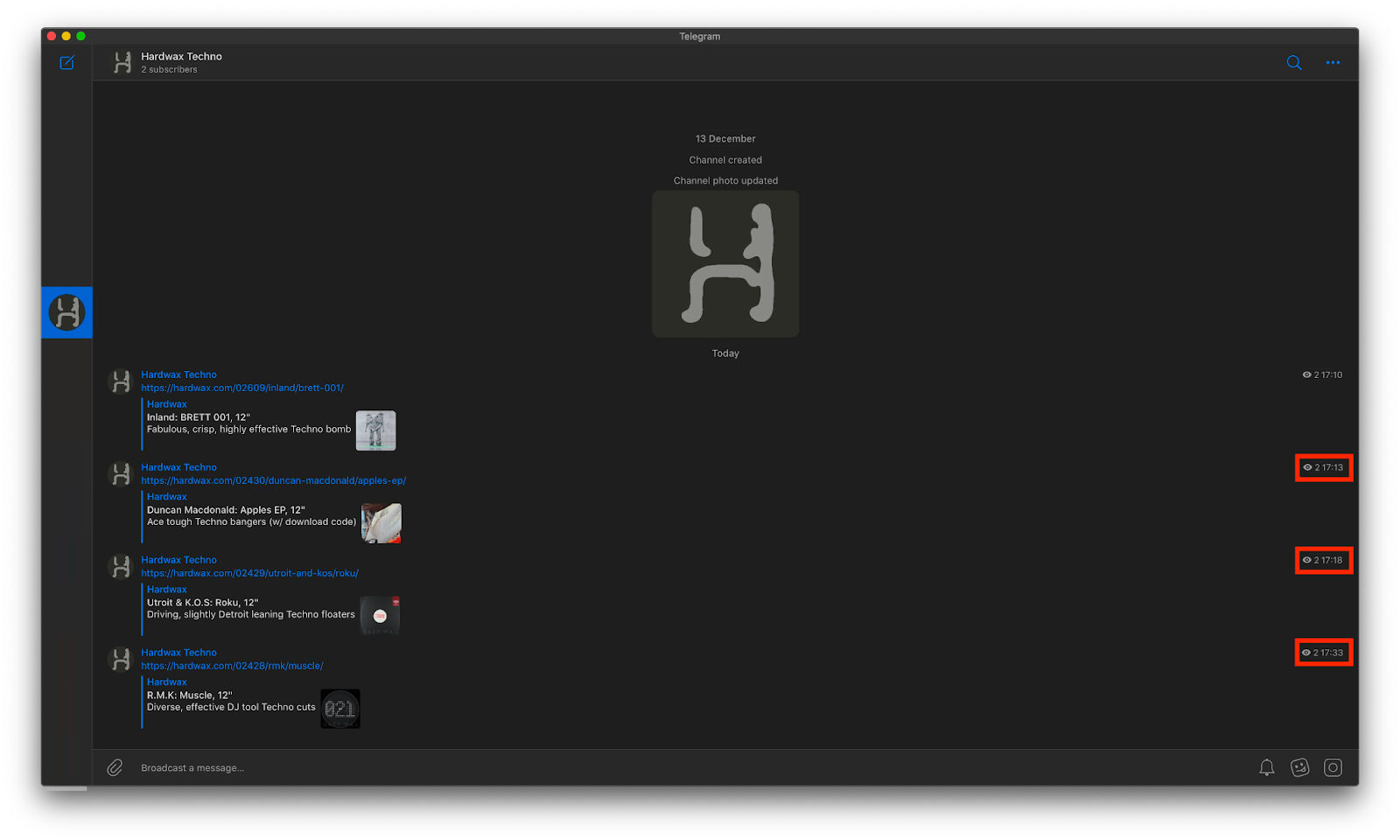
В канале видим опубликованную ссылку на альбом:

Переходим на web-страницу и видим, что это первый альбом в категории.
Проверим, как изменилась таблица в DynamoDB. Для этого переходим DynamoDB -> Tables -> HardwaxLinks -> Explore table items. Видим, что в таблице появилась наша ссылка.

Проверим, что функция не постит одну и ту же ссылку повторно. Для этого снова запустим ее и посмотрим на логи. Видим, что ф-я пропустила предыдущую ссылку, потому что она уже была опубликована и находится в таблице.

8. Расписание
Чтобы завершить автоматизацию Telegram-канала настроим расписание. Для этого наберем в поиске Amazon EventBridge -> Schedules:

Выбираем Recurring schedule -> Rate-based schedule. Rate expression = 15 minutes.
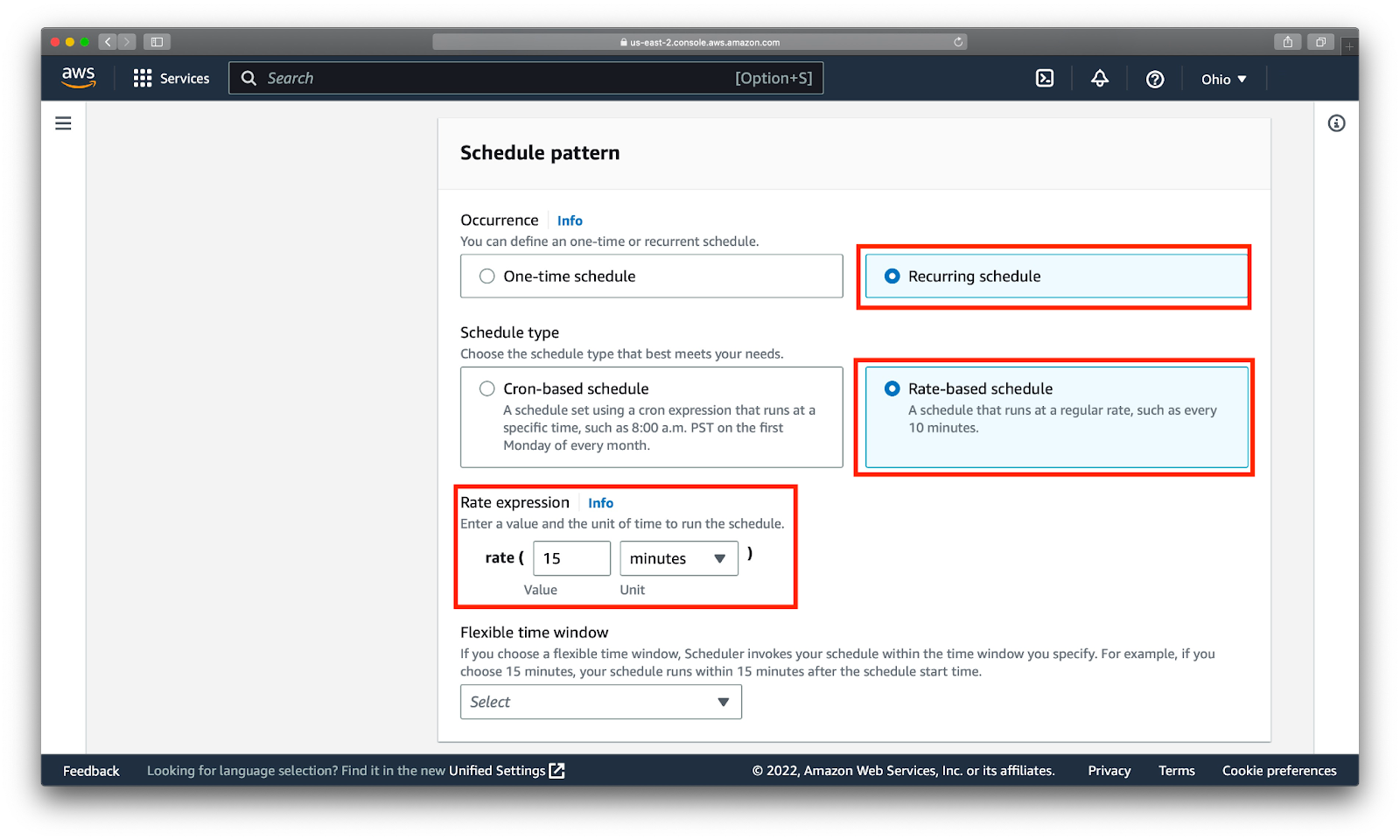
Target = AWS Lambda:

Выбираем нашу функцию:
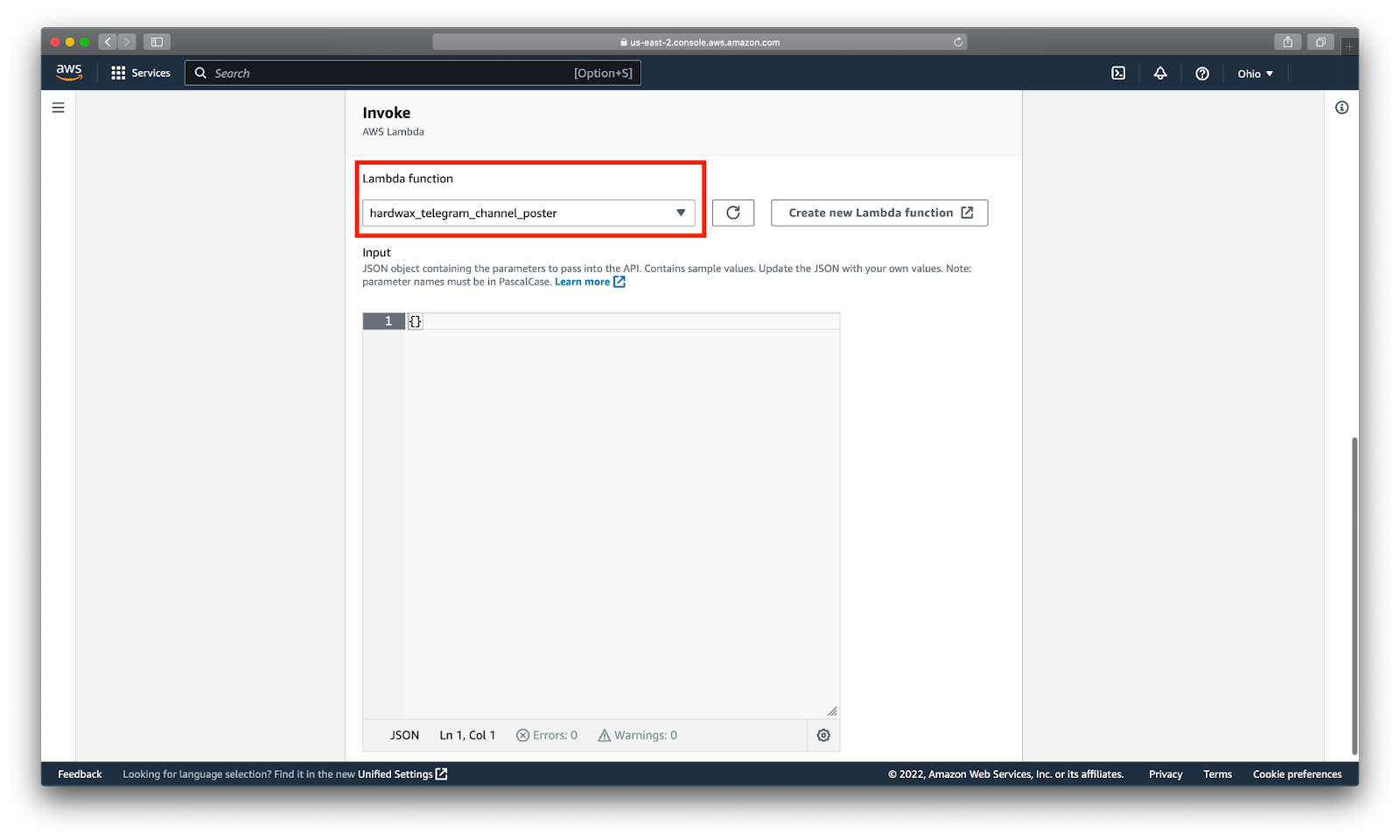
Готово! Посты в канале публикуются с интервалом в 15 минут, без повторений.
9. Что можно улучшить?
В этом туториале мы многое делали руками. Например, вручную обновляли код в браузере, формировали архив с зависимости и загружали его в AWS. Гораздо удобнее использовать CI/CD пайплайн для кода и зависимостей. Идея такая: вы обновляете репозиторий на GitHub, а функция и слой обновляются автоматически. Подробная инструкция описана в моем предыдущем материале — CI/CD для AWS Lambda через GitHub Actions.
Комментарии (2)

Stas911
19.12.2022 04:39Коннект к DynamoDB, чтение переменных окружения и другие тяжелые инициализации имеет смысл вынести из кода хендлера, тогда они будут переиспользованы между вызовами того же контейнера и сама инициализация будет быстрее, тк при инициализации не используются лимиты CPU.
Boti4ello
Спасибо! Познавательно!