Как Java разработчики, мы знакомы с концепцией сборки мусора. Наши приложения постоянно генерируют мусор, и этот мусор тщательно очищается сборщиками CMS, G1, Azul C4 и другими типами сборщиков.
Однако история не заканчивается на Java куче. На самом деле, это только начало.
В этой статье мы создадим простое Java-приложение, которое использует реляционную базу данных для пользовательских данных и твердотельные накопители (SSD) в качестве устройства хранения. Далее мы рассмотрим, как приложение генерирует мусор на уровне базы данных и SSD при выполнении логики приложения.
Примечание переводчика. В статье речь идет о Java-приложении. Поэтому название не совсем точное. Но так было в оригинале. :(
Почему меня это должно волновать?
Прежде чем мы начнем, позвольте мне ответить на вопрос в заголовке, который может возникнуть у некоторых из вас.
Во-первых, есть практическая причина. Если ваше приложение Java испытывает проблемы с производительностью, а с точки зрения приложения и JVM все выглядит хорошо, это может быть связано с вашей базой данных или циклами сборки мусора на SSD.
Во-вторых, любопытство. Инженеры-программисты обычно любят изучать, что происходит за пределами их уютной и известной области Java. Итак, приготовьтесь изучить внутреннее устройство двух компонентов, обычно присутствующих в стеке вашего приложения, — базы данных и твердотельных накопителей.
Наконец, вспомните, как Java высмеивали за использование сборки мусора?
Я слышал мнения вроде: «Почему вы используете Java, а не C++? Java-приложения медленные по своей конструкции из-за их зависимости от сборки мусора и интерпретации байт-кода во время выполнения».
Что ж, теперь мы можем возразить на это, сказав, что сборка мусора != медленная.
Другие технологии (базы данных и твердотельные накопители) эффективно используют сборку мусора, и никто обычно не называет их «медленными по дизайну».
Выбор СУБД для тестирования
Мы начнем с PostgreSQL, самой быстрорастущей реляционной базы данных согласно сайту DB Engines. Многие Java-приложения используют PostgreSQL в качестве основной базы данных, поэтому разумно начать именно с нее.

Я буду делиться простыми инструкциями для тех, кто хочет воспроизвести эти примеры дома.
Можно также просто прочитать статью. Вы можете выбрать то, что вам больше всего подходит.
Запуск PostgreSQL и приложения
Наш пример приложения — это Spring Boot RESTful сервис для пиццерии. Приложение отслеживает заказы на пиццу.
Давайте сначала запустим экземпляр PostgreSQL. Мы можем сделать это в течение минуты с помощью Docker:
Запустите базу данных в контейнере:
rm -R ~/postgresql_data/
mkdir ~/postgresql_data/
docker run --name postgresql \
-e POSTGRES_USER=postgres -e POSTGRES_PASSWORD=password \
-p 5432:5432 \
-v ~/postgresql_data/:/var/lib/postgresql/data -d postgres:13.8Подключиться к контейнеру:
docker exec -it postgresql /bin/bashПодключитесь к базе данных с помощью инструмента psql:
psql -h 127.0.0.1 -U postgresУбедитесь, что база данных пуста (пока нет таблиц):
postgres=# \d
Did not find any relations.Затем клонируйте и запустите приложение pizza:
git clone https://github.com/dmagda/java-litters-everywhere.git && cd java-litters-everywhere
mvn spring-boot:runПриложение подключается к базе данных через пул Hikari и слушает наши запросы на порту 8080:
INFO 58081 --- [main] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Starting...
INFO 58081 --- [main] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Start completed.
INFO 58081 --- [main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat started on port(s): 8080 (http) with context pathВернитесь к сеансу psql в контейнере Docker и убедитесь, что приложение создало пустую таблицу pizza_order:
postgres=# \d
List of relations
Schema | Name | Type | Owner
--------+-------------+-------+----------
public | pizza_order | table | postgres
(1 row)
postgres=# select * from pizza_order;
id | status | order_time
----+--------+------------
(0 rows)Создание мусора в базе данных
Теперь пришло время поместить первый заказ в очередь пиццерии. Для этого мы воспользуемся конечной точкой REST приложения putNewOrder:
Вызовите конечную точку с помощью curl:
curl -i -X POST http://localhost:8080/putNewOrder --data 'id=1'Приложение сохраняет заказ в базе данных с помощью следующего оператора SQL (см. вывод журнала приложения):
Hibernate:
insert
into
pizza_order
(order_time, status, id)
values
(?, ?, ?)Используйте сеанс psql, чтобы проверить, что строка попала в PostgreSQL:
postgres=# select * from pizza_order;
id | status | order_time
----+---------+-------------------------
1 | Ordered | 2022-11-21 11:14:35.103PostgreSQL хранит строки в страницах. Размер страницы по умолчанию составляет 8 КБ, что означает, что на одной странице обычно хранится несколько записей. База данных имеет расширение, которое позволяет нам просматривать необработанные данные страницы. Давайте установим расширение и изучим внутренности хранилища базы данных:
Из сеанса psql установите расширение pageinspect:
postgres=# CREATE EXTENSION pageinspect;
CREATE EXTENSIONЗапросите содержимого первой страницы таблицы
pizza_order:
postgres=# select t_ctid,t_xmin,t_xmax,t_data from heap_page_items(get_raw_page('pizza_order',0));
lp | t_xmin | t_xmax | t_data
--------+--------+--------+------------------------------------
1 | 488 | 0 | \x0100000002400000180fd8edf7900200Сейчас на странице есть одна строка, и именно ее видит ваше приложение, выполняя оператор select * from pizza_order. Давайте расшифруем столбцы pageinspect:
lp- идентификатор строки на страницеt_xmin- идентификатор транзакции, которая вставила строку в таблицу (это идентификатор, присвоенный нашему предыдущему оператору INSERT).t_xmax- идентификатор транзакции, удалившей строку, или 0, если строка видна для всех будущих запросов.t_data- это значение используется для построения указателя на фактические данные строки (полезную нагрузку).
Теперь давайте посмотрим, что произойдет, когда повар получит этот заказ и начнет выпекать пиццу. Персонал кухни меняет статус заказа на Baking:
Обновите статус с помощью curl:
curl -i -X PUT http://localhost:8080/changeStatus --data 'id=1' --data 'status=Baking'Приложение сохраняет изменение с помощью следующего оператора:
Hibernate:
update
pizza_order
set
status=?
where
id=?И PostgreSQL подтверждает, что изменение применено:
postgres=# select * from pizza_order;
id | status | order_time
----+--------+-------------------------
1 | Baking | 2022-11-21 11:14:35.103Теперь самое интересное: проверьте состояние хранилища с помощью расширения pageinspect:
postgres=# select lp,t_xmin,t_xmax,t_data from heap_page_items(get_raw_page('pizza_order',0));
lp | t_xmin | t_xmax | t_data
----+--------+--------+------------------------------------
1 | 488 | 490 | \x0100000002400000180fd8edf7900200
2 | 490 | 0 | \x0100000004400000180fd8edf7900200Несмотря на то, что оператор select * from pizza_order возвращает только одну строку, внутри PostgreSQL хранит две версии для заказа с id=1.
Первая версия (с lp=1) — это то, что приложение первоначально вставило в базу данных, когда статус заказа был Ordered. В этой версии поле t_xmax установлено в 490, что является идентификатором транзакции UPDATE, которая изменила статус на Baking. Ненулевое поле t_xmax означает, что запись помечена как удаленная и не может быть видимой для будущих запросов приложений. Вот почему select * from pizza_order больше не возвращает нам эту версию строки.
Вторая версия (с lp=2) — это последняя версия строки со status=Baking. Значение версии t_xmin установлено на 490 — идентификатор того же UPDATE, который изменил статус. Именно эту версию приложение видит через select * from pizza_order.
Оператор DELETE или UPDATE в PostgreSQL не удаляет запись немедленно и не обновляет существующую запись. Вместо этого удаленная строка помечается как «мертвая» и остается в хранилище.
Обновленная запись — это, по сути, совершенно новая запись, которую PostgreSQL вставляет, копируя предыдущую версию записи и обновляя требуемые столбцы. Предыдущая версия этой обновленной записи считается удаленной и помечается как «мертвая» версия строки.
Хотите увидеть больше мусора в хранилище PostgreSQL? Давайте изменим статус заказа пиццы:
С помощью curl измените статус на
Delivering,а затем наYummyInMyTummy(надеемся, что заказчику понравится пицца):
curl -i -X PUT http://localhost:8080/changeStatus --data 'id=1' --data 'status=Delivering'
curl -i -X PUT http://localhost:8080/changeStatus --data 'id=1' --data 'status=YummyInMyTummy'Используя сеанс psql, убедитесь, что приложение будет видеть только версию строки со
status=YummyInMyTummy:
postgres=# select * from pizza_order;
id | status | order_time
----+----------------+-------------------------
1 | YummyInMyTummy | 2022-11-21 11:14:35.103Проверьте, сколько версий строки находится в хранилище PostgreSQL:
postgres=# select lp,t_xmin,t_xmax,t_data from heap_page_items(get_raw_page('pizza_order',0));
lp | t_xmin | t_xmax | t_data
----+--------+--------+------------------------------------
1 | 488 | 490 | \x0100000002400000180fd8edf7900200
2 | 490 | 491 | \x0100000004400000180fd8edf7900200
3 | 491 | 492 | \x0100000006400000180fd8edf7900200
4 | 492 | 0 | \x0100000008400000180fd8edf7900200
(4 rows)Для нашего заказа пиццы с id=1 в хранилище существует четыре версии. Единственное различие между этими версиями — это значение столбца status!
Существует веская причина, по которой движок базы данных хранит удаленные и обновленные записи.
Ваше приложение может выполнять множество транзакций с PostgreSQL параллельно. Некоторые из этих транзакций начинаются раньше, чем другие. Но если транзакция удаляет или обновляет запись, которая все еще может представлять интерес для ранее начатых транзакций, то запись необходимо хранить в базе данных в исходном состоянии (до того момента времени, когда все ранее начатые транзакции завершатся). Именно так в PostgreSQL реализован протокол MVCC (multi-version concurrency protocol).
Сборка мусора в базе данных
Понятно, что PostgreSQL не может и не хочет хранить мертвые версии строк вечно. Вот почему в базе данных имеется собственный процесс сборки мусора, называемый vacuum.
Существует два типа VACUUM — стандартный и полный. Стандартный VACUUM работает параллельно с рабочими нагрузками вашего приложения и не блокирует ваши запросы. Этот тип очистки помечает пространство, занятое мертвыми строками, как свободное, делая его доступным для новых данных, которые ваше приложение добавит в ту же таблицу позже.
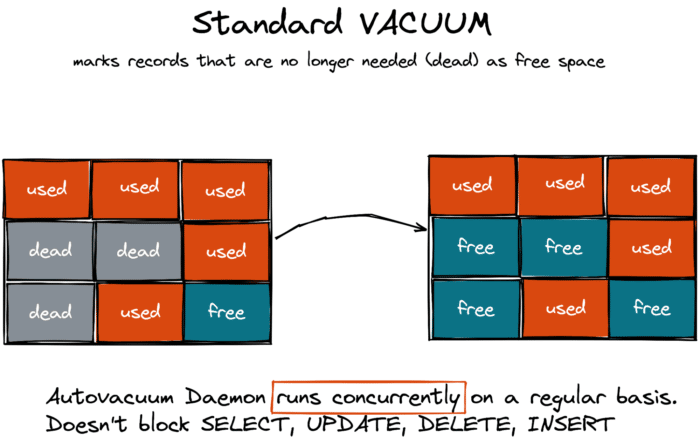
Стандартный VACUUM не возвращает пространство операционной системе для повторного использования другими таблицами или сторонними приложениями (за исключением некоторых крайних случаев, когда страница включает только мертвую версию строки, и страница находится в конце таблицы).
В отличие от этого, полный VACUUM дефрагментирует пространство хранения и может вернуть свободное пространство операционной системе, но блокирует рабочие нагрузки приложений.

Считайте, что полный вакуум — это пауза в сборке мусора Java, которая «остановит мир». Только в PostgreSQL эта пауза может длиться часами (зависит от размера базы). Поэтому администраторы базы данных делают все возможное, чтобы вообще предотвратить полный VACUUM, и обеспечить своевременную очистку мусора демоном autovacuum, который выполняет стандартную очистку.
Подведение итогов
В следующий раз, когда кто-то попросит вас объяснить внутреннюю работу сборки мусора в Java, сделайте шаг вперед и удивите его, расширив тему и включив в нее реляционные базы данных.
Если говорить серьезно, сборка мусора — это широко распространенная техника, используемая далеко за пределами экосистемы Java. При правильной реализации сборка мусора может упростить архитектуру программного и аппаратного обеспечения без ущерба для производительности. Java и PostgreSQL являются хорошими примерами продуктов, которые успешно используют преимущества сборки мусора и входят в число лучших продуктов в своих категориях.
Эта история еще не закончена. В следующей статье я расскажу, что произойдет, если Java-приложение будет работать с распределенной базой данных и использовать твердотельные накопители (SSD).
Если вы хотите узнать больше о распределенных базах данных SQL, ознакомьтесь с этой статьей!
Комментарии (8)

LuggerFormas
23.12.2022 15:52Java ни при чем, мусор в памяти и мусор на диске - не эквивалентны. сборка мусора = медленная


oxff
24.12.2022 21:55Какая-то несусветная чушь. При чём тут Java вообще? Возьмите СУБД с другой реализацией мультиверсионности, или совсем без неё, блокировочник, и затем повторите тест.
И кстати, наличие этого "мусора" в Postgres имеет и свои преимущества. Например, не нужно иметь дополнительное место для хранения версий строк или undo data; отмена транзакции происходит мгновенно потому что оригинальные версии строк всё ещё присутствуют; транзакционное изменение схемы данных (DDL) и хранимых процедур с возможностью отмены; нет проблемы переполнения для транзакций изменяющих много данных и т.д. Мусором это становится если автовакуум не поспевает, как правило по причине того что его не настрили как следует под конкретное приложение.

DenisPantushev
26.12.2022 13:50Во-первых, да, при чем тут джава. Во-вторых, при чем тут мусор? Записи в бд - не мусор, а версии строки. Это всё нужная информация, в отличии от настоящего мусора в джаве. Версии - один из возможных механизмов транзакционности. Так мы договоримся до того, что лог в Ms sql - мусор.
Kopilov
Таки причём тут Java?
val6852 Автор
Добавил примечание:
В статье речь идет о Java-приложении. Поэтому название не совсем точное. Но так было в оригинале. :(
dbubb
Ну Java-приложение тут тоже не при чем - приложение можно на любом языке написать, либо вообще напрямую через SQL данные менять, тут описано поведение именно самого PostgreSQL.