Возможно, вы уже не раз встречали такие аббревиатуры как SPOD, VUCA и BANI. Я не буду уходить в дебри этой теории, скажу лишь, что мир очень быстро меняется. Когда-то мир был устойчивым, предсказуемым, линейным и простым. Можно было не обращать внимание на SPOD-мир (Steady — устойчивый, Predictable — предсказуемый, Ordinary — простой, Definite — определенный) и достаточно легко строить планы на пару лет вперед. Но наступило время VUCA (Volatility — нестабильность, Uncertainty — неопределенность, Complexity — сложность, Ambiguity — неоднозначность). Именно тут ИТ и начинает становиться неотъемлемой частью и функцией бизнеса.

«Черные лебеди» с начала второго тысячелетия всплывают один за другим, и что-то предсказать становится крайне трудно. Мы погружаемся в BANI-мир с его хрупкостью. Люди перенасыщены тревожностью, в процессах появляются нелинейность и непостижимость. Может ли что-то помочь с этим справиться? Конечно же, это старая добрая математика, которая с помощью данных может обуздать нелинейность с непредсказуемостью и сбалансировать бизнес.
А теперь давайте посмотрим на развитие компании в этих условиях с высоты птичьего полёта: на жизненный цикл, архитектуру и т.п.
Жизненные циклы компании
В жизненном цикле любой компании (тут отсылка к Ицхаку Адизесу с его трудом «Управление жизненным циклом корпораций») существуют разные стадии, где на этапе роста происходит закладка ИТ-архитектуры (в статье сделаем именно фокус на ИТ): архитектуры данных, ИТ-ландшафта (архитектуры решений) — и тут либо глобально в компании архитектура есть, либо её нет. Если у руководства не будет целевого видения архитектуры, а главное — следования данному видению, то рано или поздно система «посыпется».
Каждый отдел (структурная группа) копит данные, закупает ПО. Специалисты ИТ обеспечивают шины данных между разными продуктами, подключаются к внешним источникам, обеспечивают функционирование. Постепенно мы попадаем в ловушку, которую когда-то сами себе и заложили. А именно: у нас есть куча разношёрстных информационных систем, где хранятся данные в совершенно разном виде, администраторы пытаются помочь всем и вся, начинается дефицит ИТ-персонала для обслуживания всей физической и виртуальной инфраструктуры, и банальные вещи становятся целым кейсом и могут затянутся на длительные периоды.
Компания от момента своего создания, стадии роста, постоянно аккумулирует разные ресурсы. Но беда может быть в том, что всё это копится в хаотичном порядке, и когда настанет день Х, нужно будет разобраться со всем или срочно мигрировать на что-нибудь. Из-за этого потеряется множество данных, уйдут специалисты и т.д.
Зачем вообще понимать и разбираться в жизненных циклах?
Согласно теории жизненных циклов компаний, организации должны постоянно перерождаться. Как только появляются первые «звоночки» старения компании — это время провести адаптацию под реалии BANI-мира. Акцент делается на цифровизацию и датафикацию, когда все процессы оцифровываются и систематизируются, а в итоге остаются только оптимальные!

Но бывает и по-другому. Так, например, фирма, которая понимает, что находится максимально близко к последнему этапу своего пути, покупает себе ещё одну компанию на этапе «стабильности» и соединяется с ней. Менеджеры пытаются восстановить жизненный цикл всей группы, т.е. компания пытается обновиться за счет более «живой» компании-донора, но есть всегда одно но. Это то, что образуется при любых объединениях — целый зоопарк информационных систем и данных, и это только с точки зрения ИТ.
На каждом витке ЖЦ компаний происходит реорганизация или адаптация. Конечно, возможны и другие варианты типа интеграции или запуска нового продукта, но для того, чтобы компания жила долго, нужно постоянно отлавливать момент её «зрелости» и не давать наступать «старению», а в конечном итоге и «смерти».
")
Когда компания сама по себе растёт, тут проблемы очевидны, но когда происходит реорганизация, то наступает умножение проблем друг на друга, и они множатся постоянно, ведь ИТ-ландшафт разнообразный, а у менеджмента были разные видения его развития. А про аккумуляцию данных лучше и не говорить. Тут нужна целая экспертная группа, чтобы хоть как-то разобраться в этом хаосе.
Так как в большинстве российских фирм данные ведутся по своим самописным правилам, то главное, чтобы вообще были хоть какие-нибудь правила. Если они есть, то вероятнее всего у менеджмента есть понимание, что данные важны. Плохо, когда специалисты делают из «плохих» данных «хорошие» специально для руководства. Любимое дело — «покрасить траву в зелёный цвет, авось не узнают». Поэтому менеджмент должен держать руку на пульсе, и не просто верхнеуровнево, а точечно.
Как же связаны ИТ-архитектура компании, данные и её жизненный цикл?
В современной реальности одного без другого не может быть. Правда, это взгляд с позиции аналитика данных, и я не могу утверждать, что только моя точка зрения единственно верная. Без заранее верно выстроенной архитектуры проблемы перерастают в очень дорогостоящий снежный ком, проблемы которого нужно будет компенсировать всё бóльшими затратами и человеческими ресурсами.
Такая же ситуация и с данными. Если нет правил и политик управления ими, то повторное использование данных становится весомой проблемой. Дополнительно возникает опасный риск утечки персональных данных и другой конфиденциальной информации, а это очень дорогостоящие потери как финансово, так и репутационно.
В век цифровизации, когда данные становятся активом, ИТ — это не просто дополнительная вспомогательная функция бизнеса, но основа большинства бизнес-процессов. Если компания не будет заботиться о своих данных и архитектуре, то её жизненный цикл неминуемо придёт к «The end», т.е. менеджмент должен всегда держать в жестком контроле данные и архитектуру. Утечки персональных данных происходят всё чаще, и чтобы ваши данные не «засветились» где-нибудь на просторах интернета, нужно их оберегать и следить за ними.
В 2020—2021 годах начал трансформацию второй банк России — ВТБ, а ранее Сбер. Крупнейшие игроки осознают возможную ценность данных и риски, которые они имеют. Другие компании подтягиваются, что видно по темам, которые поднимаются на Хабре и ИТ-конференциях, но пока очень медленно.
А что такое данные, и кто с ними работает?
Данные — это новая нефть современности. Во всех бизнес-процессах нужно применять математических аппарат: от логистики до управления кадрами.
На основе данных принимаются разного рода менеджерские и управленческие решения, и если данных мало, они недостоверные или там множество проблем, то возникает вопрос: какой вектор направления будет лежать на основе анализа таких данных? Верно, с большой вероятностью — некорректный.
Виды данных
Давайте поймём, какие же данные существуют в компаниях, чтобы понимать, за чем нужно следить. Данные в компании делятся на три основных вида: метаданные (информационные данные по данным — извиняюсь за масло масляное, но это так, а более расширенное определение можно найти, например, в Википедии), мастер-данные (ключевые бизнес-данные), справочники (НСИ или просто статическая информация, которая практически не изменяется). Эти виды держат на себе само понятие «данные». Стоит отметить, что есть ещё и другие виды данных, мы ведь из ИТ, такие как структурированные (транзакционные), полуструктурированные и неструктурированные. К транзакционным или структурированным данным относятся данные, имеющие определенные метки времени, а также формально определённую структуру. Полуструктурированные — это данные, не имеющие определенной схемы или структуры, но имеющие формальную разметку (JSON, YAML, XML). Неструктурированные — это данные, у которых отсутствует структура (текст, почта, изображение и другие). Стоит заметить, что классифицировать данные можно по-разному, и представленная классификация носит высокочастотное использование в современном подходе к управлению данными, но не исключает других подходов, где классификация может быть по альтернативным признакам: содержательному признаку, требованиям ИБ и т.п. Обеспечение всех видов данных в высоком качестве — весьма дорогостоящий и ресурсоёмкий процесс, поэтому выделяем ключевые виды и направляем наши политики на них.

Вот вам и удочка по практическому применению данной статьи здесь и сейчас: выделите у себя в проекте наиболее важные виды данных и сделайте на них упор в своей проработке.
Качество данных
Если присмотреться к современным архитектурам построения ИТ-ландшафта и вообще управления компаниями, то там обязательно говорится о значимости управления данными — Data Governance. Это корпоративная политика управления данными, но с позиции стратегии. Есть также Data Management — набор методов и практик для управления данными здесь и сейчас (более подробно — DMBOK).
В любой архитектуре хранилищ данных важно поддерживать еще и качество данных (Data Quality). Т.е. данные должны быть гармонизированы на всех уровнях или слоях. Data Governance — политика управления данными, должна быть принята на верхнем уровне управления и распространяться на линейных сотрудников, где обязательным правилом должно стать закрепление за каждым отделом (при матричной и линейной структуре) архитектора и Data Steward (специалиста по данным).
В случае командной работы по различным гибким методологиям (Agile или Kanban) за стримом или группой команд также нужно закрепить архитектора и Data Steward, которые, соответственно, транслируют работу с данными и отвечают за выполнение политик использования данных и их непосредственной безопасности. Любое движение по созданию витрин Data Mart должно быть одобрено архитектором при соблюдении общей политики.
Внедрение ролей и политик — это хорошо, но требуется ещё и работа c данными (Data Management) для превращения их в информацию, а именно выделение сегмента данных и принципа работы с ними. И тут вступают в дело Data Quality и Data Profiling для создания метрик качества данных и их профилирования (процесс извлечения метаданных из основных данных). И небольшой комментарий: тут лишь вводная часть в управление данными, а если захотите нырнуть с головой, то DMBOK вам в помощь.

Кто отвечает за данные?
Когда дело доходит до работы с данными — это, в основном, удел аналитиков. К сожалению, чаще всего компании не совсем корректно понимают направления, по которым работает аналитик данных. Отсюда и появляется Full-Stack Analyst. Это специалист, который работает с бизнесом, описывая его задачи в виде ТЗ и тому подобных артефактов. Он — мастер визуализации дашбордов. Он же — исследователь данных с приставкой Big Data или DWH. А еще: системный оптимизатор, интегратор, технический аналитик и еще бесконечное количество ролей. В общем, всё, что не классифицируется с разработкой, администрированием, тестированием и дизайном — это удел аналитиков.

Там, где в бизнесе заходит вопрос о работе с агрегатными состояниями данных, переводом их в информацию и в знания — именно там место аналитика (классическое разделение на системных, бизнес- и аналитиков данных не будем разбирать пока, но об этом помним).
Кейс на примере ООО «Белые Рога»
Далее я расскажу про кейс, с которым встречался, ведь он весьма показательный, и вы сможете примерить на себе эту ситуацию и подумать о том, как быть дальше. А если вы менеджер, то, возможно, сможете принять правильное решение и избежать тех проблем, через которые прошёл я.
Так, например, в работе с одной крупной продовольственной компанией премия торговой команды зависела от продаж продукции, территориальной представленности, доли рынка и т.п., т.е. разных метрик, по которым проводит оценку руководство и считает эффективность торговой команды, где KPI строится по мастер-данным. Но «дьявол в мелочах» — данные по продукции поступали некачественными: дубли разного рода, некорректные коды продукции в БД, устаревшие списки сотрудников, частично отсутствующие данные промоакций, и это не весь список.
Этими проблемами пользовались многие, но главное — данная проблема наносила фирме урон, как финансовый, так и репутационный. Раз премии были не всегда корректными, то это напрямую касалось состояния персонала, а мотивация работала только в фантазиях. Если честно, то вообще сложно говорить о правильности или корректности решений на основе данных с дефектом.
Не буду вдаваться в реальные цифры возможных финансовых издержек, которые я мог видеть своими глазами, но приведу расчёт «около» (данный расчёт будет приведён на основе средних данных рынка и не имеет прямого отношения ни к какой компании) на основании моего видения и реального опыта взаимодействия.
Расчёты
Пусть наша компания называется ООО «Белые Рога», находится она в FCMG-секторе B2B-сегмента. Данная компания давно на рынке и постоянно старается обновиться, что видно только в верхнем уровне иерархии компании. Так как компания из FCMG, вероятнее всего, у неё есть штат торговой команды с вертикальной иерархией и разделением по крупным агломерациям. Пусть в нашей фирме трудятся порядка 5 тысяч человек в любой сезон года (в определенные периоды времени штат сотрудников увеличивается для покрытия сезонных активностей), соответственно, возьмём среднюю заработную плату (https://ru.jooble.org/salary/торговый-представитель) торгового представителя по Москве в 100 тысяч рублей, для красоты эксперимента уменьшим её в два раза, т.к. наша торговая команда разбросана по всей стране. Стоит учесть, что в торговой команде есть и руководители, поэтому - цифра будет близка к медиане, руководителей намного меньше основной массы команды продаж, поэтому это будет погрешность, которую мы принимаем. Стоит также учесть, что всё, что выше прожиточного минимума — премия.
Пусть прожиточный минимум будет 13 тысяч (на основе средних значений), соответственно, премиальная часть будет 37 тысяч рублей. Далее видим, что премиальная часть при 5 тысячах сотрудников — 185 млн рублей в месяц до налогообложения. В таблице ниже можно посмотреть, как будет меняться величина суммарной премиальной части заработной платы сотрудников при заработной плате в 50 тыс. или 25 тыс. рублей. Нужно понимать, что данные расчёты не несут в себе реальных цифр компании, но позволяют показать картину происходящего при проблемах с данными на основе данных рынка труда.
Также необходимо учесть, что исторически в России не обращали внимание на данные и их качество, и совсем недавний тренд, когда данные стали рассматриваться как актив, перешел к нам в страну (исследования проблем качества данных по отечественным компаниям я не видел, по крайней мере, таких, которые заслуживают доверия). Проценты отклонений взяты из статистики с округлением для большей наглядности, цифры отклонений в американских компаниях совершенно другие.
Ниже приведена таблица, в которой демонстрируется дельта потерь в зависимости от величины премиальной части заработной платы и процента дефектных данных, где 3% (по 1,5% с двух сторон от оси симметрии) входит в нормальное распределение по проблемам в данных, но, к сожалению, компании, у которых данные дефектные, маловероятно будут относиться к массе компаний, для которых такой низкой процент характерен.

Кроме того, за премиальными цифрами ещё стоит и вознаграждение дистрибьютеров, и это тоже немалые суммы. А теперь вопрос: был ли реально выполнен KPI? Ведь он колоссально важен для развития компании, но мы понимаем, что если данные были дефектные, то руководители, понимая это, пересчитали KPI и — вуаля — план выполнен!
Как говорится, «закрасили траву в зелёный цвет» вместо поливки и ухода за ней. С моей точки зрения, неправильные данные, т.е. некачественные или, по-другому говоря, дефектные данные, могут не просто принести финансовые и репутационные потери, но и уничтожить компанию. Если рассмотреть положение компании на кривой жизненного цикла, то компания находится на этапе «старения» (факторы оценки: прибыль генерируется только основными продуктами, уже давно находящимися на рынке, новинки не приносят особой прибыли, процессы крайне забюрократизированы и т.п.), а именно между «аристократией» и «бюрократией».
А как решить данную проблему?
Во-первых, нужно на этапе от «юности» до «рассвета» принимать общекорпоративные архитектурные решения и стандарты. Это нужно для того, чтобы данные правильно копились в хранилищах, а хранилища были корректно спроектированными. Программное обеспечение было бы зафиксировано по назначению в необходимом и достаточном количестве. По пунктам:
требуется применение Data Governance на верхнем уровне со сквозным распространением;
определение из всего спектра данных основных видов: мастер-данные, метаданные, НСИ;
выделение в структуре компании архитекторов и Data Steward во всех организационных структурах, где так или иначе производятся, аккумулируются, модифицируются данные;
требуется применение Data Management со всем набором инструментов и практик: Data Quality, Data Profiling.
Это необходимый минимум для создания ценности данных, их доступности и прозрачности. И да, небольшой спойлер: в компании, на примере которой мы проводили анализ, всё-таки начался переход к управлению данными.
Стоит ли нанять отдельного специалиста?
Давайте рассмотрим следующую ситуацию. Сколько своего времени тратит специалист, который работает с данными, на приведение этих данных в порядок? Не могу сказать за всех, но по моему опыту (после проведения исследования в компании), аналитики (системные и Data), работающие с DWH или BigData тратят 1/5 рабочего времени. Специалисты, работающие с отчётностью – 2/5.
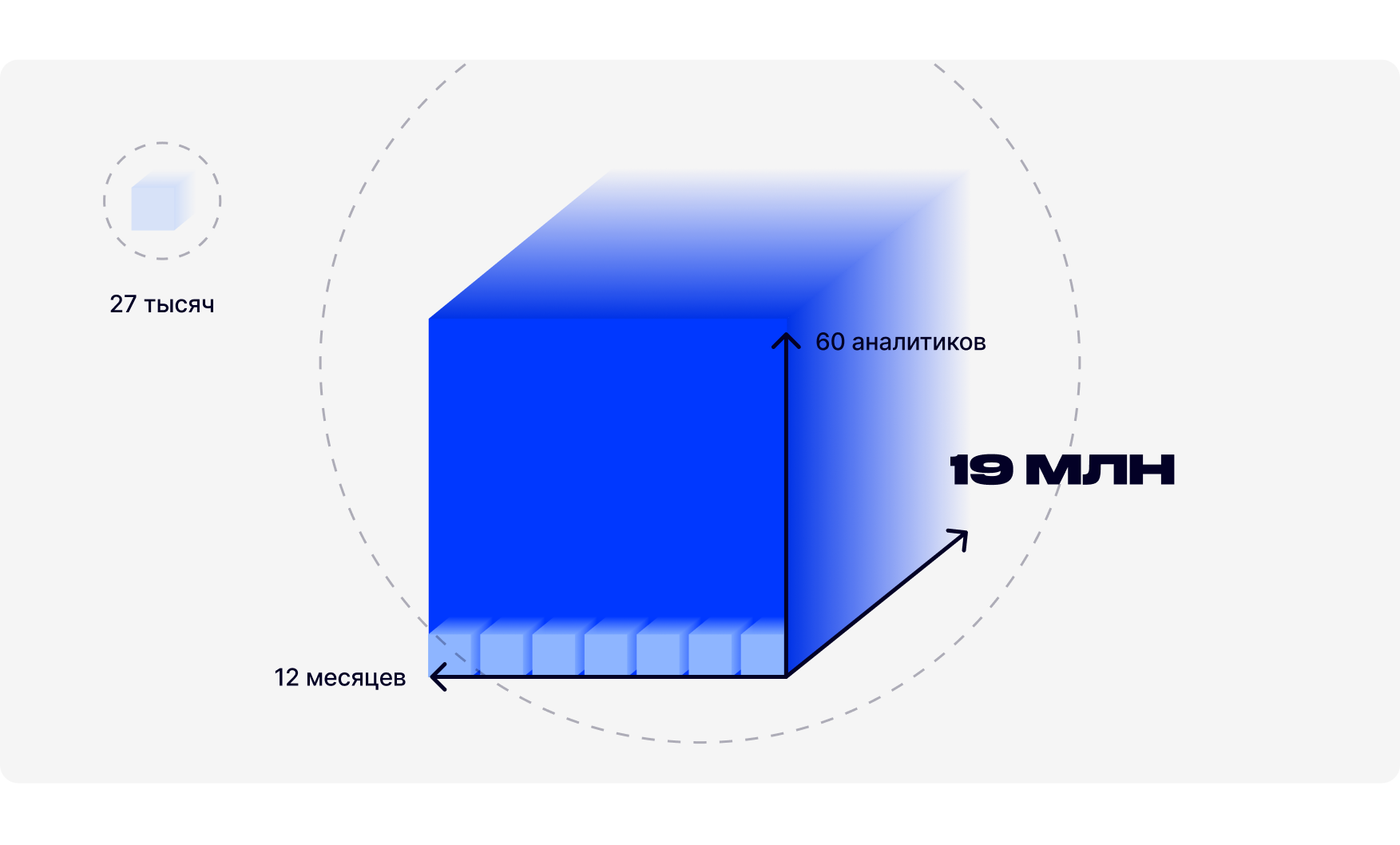
Давайте исследуем цену вопроса. Цена аналитика уровня Middle на московском рынке труда находится на уровне 134 000 рублей согласно исследованию Skillfactory. 1/5 — это около 27 000 рублей, соответственно, в год только один сотрудник тратит порядка 324 000 рублей на правку данных, Data Quality. Но нужно понимать, что во второй половине 2021 года произошел скачок заработных плат, похожий скачок был и в 2022 году, и сумма в 324 000 вырастет как минимум на процент инфляции, а что на эти деньги можно сделать?
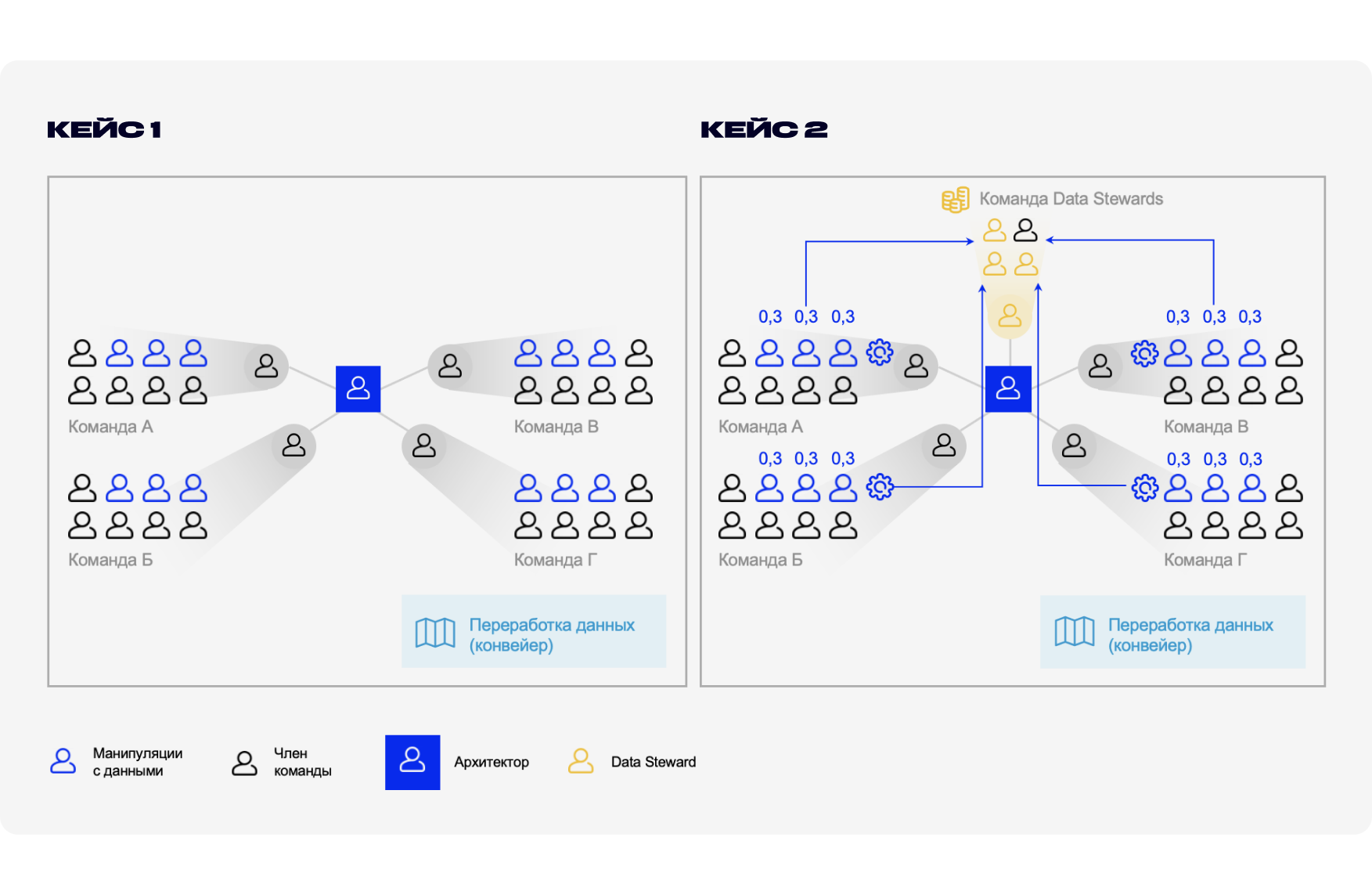
Как минимум — взять специалиста, который будет реализовывать стратегию работы с данным. Но то, что 324 тысяч нам не хватит — это неправда, т.к. данный специалист должен обслуживать не один отдел (структурную группу), а несколько, в зависимости от объёма людей, баз данных и других факторов. Стоит отметить, что чем больше компания, тем больше в ней аналитиков, которые работают с данными, и если есть 100 аналитиков, и из них порядка 60 — среднего уровня, то потенциальные затраты приближаются к 60 * 324 = 19,4 млн рублей. Этой суммы хватит на целый отдел и, соответственно, чем больше людей трудится в компании, тем больше потенциальных денег мы можем сохранить и направить на закупку специалистов, профильное обучение, ПО и т.п.
Данный подход с организацией центра экспертности с закреплением определенных ролей за структурными группами в любом случае даёт большую финансовую и бизнесовую отдачу, т.к., во-первых, за данными начинают следить, и данные профилируются, во-вторых, появляется дополнительный центр компетенций, который распространяет единые правила для компании и стандарты. Стоит заметить, что создание такого центра на первоначальном этапе — это инвестиция, сотрудникам вы не будете платить меньше, но у них высвобождается время, которое они должны перенаправить на свои основные рабочие процессы, а без хороших управленцев никуда не уйти.
Что еще может пойти не так?
Бывает и так, что наверху приняли стратегию по управлению данными, даже людей взяли, но вот не отработал Data Management, хотя закупили ПО для ведения МДМ или НСИ, а может быть, и того, и другого вместе, но на рабочих местах линейные специалисты как очищали адреса от дублей, так и продолжают это делать. Или, например, пытаются тем или иным способом нормализовать адреса, и таких проблем с данными множество: битые ИНН, несоответствие контрольной суммы ИНН, разноформатная запись телефона, кривые почтовые адреса, даты начала действия договоров, начинающиеся почти в Советском Союзе, а то и в царские времена, и этих проблем множество.
Если проблемы с данными однотипны, то почему отдел «А», не может использовать наработки отдела «Б» или их данные, а, возможно, и их код? Всё просто: отдел «А» затачивает данные под свои бизнес-задачи и со своими оговорками, аналогично делают и другие отделы, где под отделом надо подразумевать структурную группу, состоящую из единиц — сотрудников.
Выводы
Поднимать вопросы качества данных и двигать их в рамках среднестатистической компании — затратно. Если внимания и времени работе с данными не уделяется должным образом, то о каком Data Management или Data Governance можно говорить?
В необходимых данных для реализации структурными группами в рамках задач содержится множество ошибок. А перед дедлайнами исправления проводятся только для причёсывания данных, чтобы выполнить поставленную задачу. Всё как обычно: красим траву, зачем её высаживать и поливать? Об обращении к создателю данных или ответственному (-ым) не идёт и речи кроме редких случаев, когда невозможно сдвинуть задачу с места или проблемы настолько масштабны, что закрыть задачу не получится.
Как я и сказал ранее, круг замкнулся, в большинстве отечественных компаний работа с данными — новые реалии, под которые они ещё не подстроились. Техногиганты активно пытаются трансформироваться, так как данные — это актив и риски одновременно, и какая чаша весов перевесит — это зависит от руководства. Нужно прекратить красить траву в зелёный цвет и начать тотальную практику по внедрению сквозных политик по управлению данными.
У ИТ не вспомогательная функция бизнеса, а его неотъемлемая часть. 21 век — новый мир. Если компания хочет жить, нужно использовать ресурсы по назначению, и задуматься о том, какие данные вы используете — это важно.