Зачем это нужно?
Представьте, что вам дали размеченный набор данных, и ваша задача — предсказать новый. Что вы будете делать? Вероятно, сперва вы попробуете обучить модель машинного обучения поиску правил для разметки новых данных. А что дальше? Подробности — к старту нашего флагманского курса по науке о данных.

Модель машинного обучения удобна, но при ML сложно понять, почему модель делает именно такое предсказание. Вы также не можете использовать в такой модели знания предметной области.
Есть ли другой способ установить правила разметки данных на основе ваших знаний, кроме того, чтобы полагаться на предсказания модели машинного обучения?
Вот здесь и пригодится human-learn.
Что такое human-learn?
human-learn — это пакет Python для создания систем на основе простых в построении и совместимых со scikit-learn правил.
Чтобы установить human-learn, выполните команду:
pip install human-learnМы узнаем, как создать модель с помощью простой функции. Пробовать и форкать исходный код для этой статьи можно по этой ссылке:
Чтобы оценить эффективность модели на основе правил, начнём с предсказания набора данных с помощью модели машинного обучения.
Модель машинного обучения
В качестве примера воспользуемся набором данных Occupation Detection Dataset из репозитория UCI Machine Learning Repository.
Наша задача — спрогнозировать, занято ли помещение, помещения по температуре, влажности, освещённости и концентрации углекислого газа. Помещение свободно, если Occupancy=0, и занято, если Occupancy=1 .
После загрузки распакуйте архив и считайте данные:
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report
# Get train and test data
train = pd.read_csv("occupancy_data/datatraining.txt").drop(columns="date")
test = pd.read_csv("occupancy_data/datatest.txt").drop(columns="date")
# Get X and y
target = "Occupancy"
train_X, train_y = train.drop(columns=target), train[target]
val_X, val_y = test.drop(columns=target), test[target]Посмотрите на первые десять записей набора данных train:
train.head(10)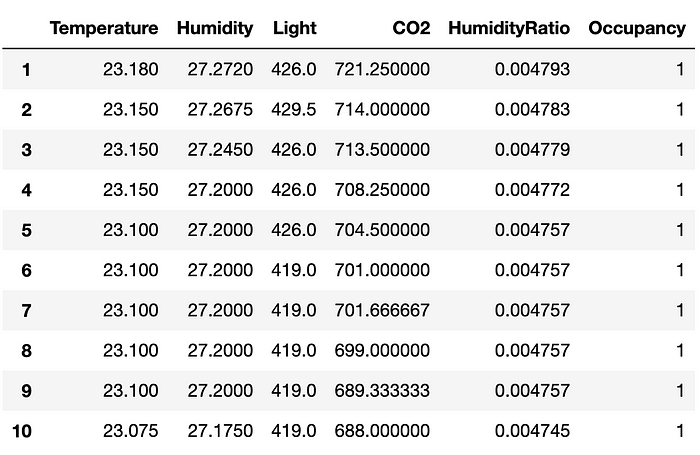
Обучите модель RandomForestClassifier [классификатор случайного леса] из scikit-learn на обучающем наборе данных и используйте эту модель для предсказания тестового набора данных:
# Train
forest_model = RandomForestClassifier(random_state=1)
# Preduct
forest_model.fit(train_X, train_y)
machine_preds = forest_model.predict(val_X)
# Evalute
print(classification_report(val_y, machine_preds))
Качество предсказания довольно хорошее. Однако неизвестно, как модель делает эти прогнозы. Давайте посмотрим, можно ли сделать разметку новых данных согласно простым правилам.
Модель на основе правил
Вот четыре шага создания правил разметки данных. Нужно:
- Выдвинуть гипотезу.
- Изучить данные для подтверждения гипотезы.
- Начать с простых правил, которые основаны на наблюдениях.
- Усовершенствовать правила.
Выдвигаем гипотезу
Свет в комнате — важный показатель того, занято ли помещение. Таким образом, можно предположить, что, чем светлее в помещении, тем больше вероятность того, что оно занято.
Давайте посмотрим на данные и проверим, так ли это.
Изучаем данные
Для проверки предположения воспользуемся диаграммой размаха (box plot), чтобы найти разницу между освещённостью в занятом (Occupancy=1) и пустом (Occupancy=0) помещениях.
import plotly.express as px
import plotly.graph_objects as go
feature = "Light"
px.box(data_frame=train, x=target, y=feature)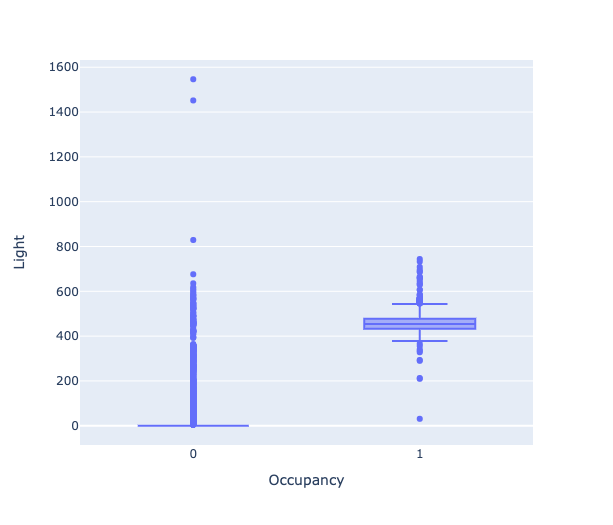
Видно значительную разницу медианы между занятым и пустым помещениями.
Начинаем с простых правил
Теперь создадим правила определения занятости помещения по его освещенности. Например, если количество света превышает определённое значение, то Occupancy=1, в противном случае Occupancy=0.

Но какое пороговое значение выбрать? Начнём со значения 100 и посмотрим, что получится:

Чтобы создать с помощью human-learn модель на основе правил, мы:
- напишем в Python простую функцию, которая задаёт правила;
- воспользуемся
FunctionClassifier, чтобы превратить эту функцию в модель scikit-learn.
import numpy as np
from hulearn.classification import FunctionClassifier
def create_rule(data: pd.DataFrame, col: str, threshold: float=100):
return np.array(data[col] > threshold).astype(int)
mod = FunctionClassifier(create_rule, col='Light')Сделаем предсказание тестового набора данных и оценим прогноз:
mod.fit(train_X, train_y)
preds = mod.predict(val_X)
print(classification_report(val_y, preds))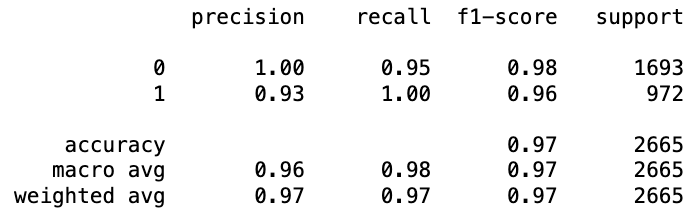
Точность модели [на основе правил] выше точности RandomForestClassifier!
Улучшаем правила
Теперь посмотрим, сможем ли мы добиться точности выше, поэкспериментировав с пороговыми значениями. Для анализа взаимосвязи между конкретным значением освещённости и занятостью помещения используем параллельные координаты.
from hulearn.experimental.interactive import parallel_coordinates
parallel_coordinates(train, label=target, height=200)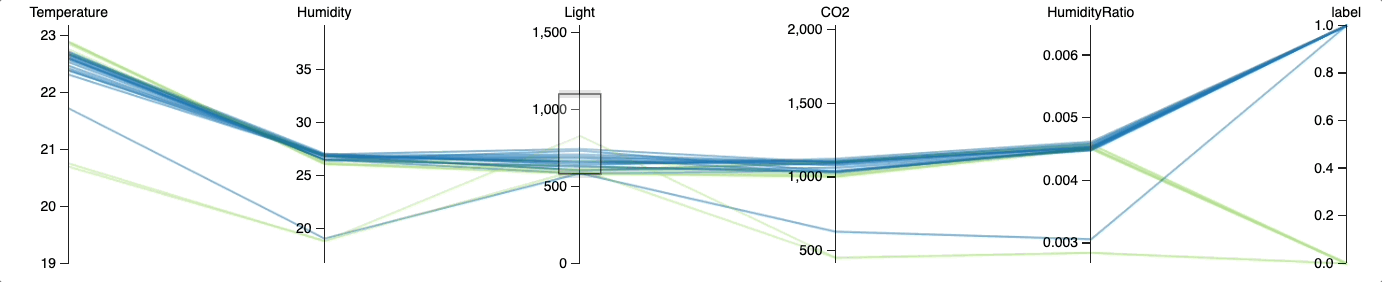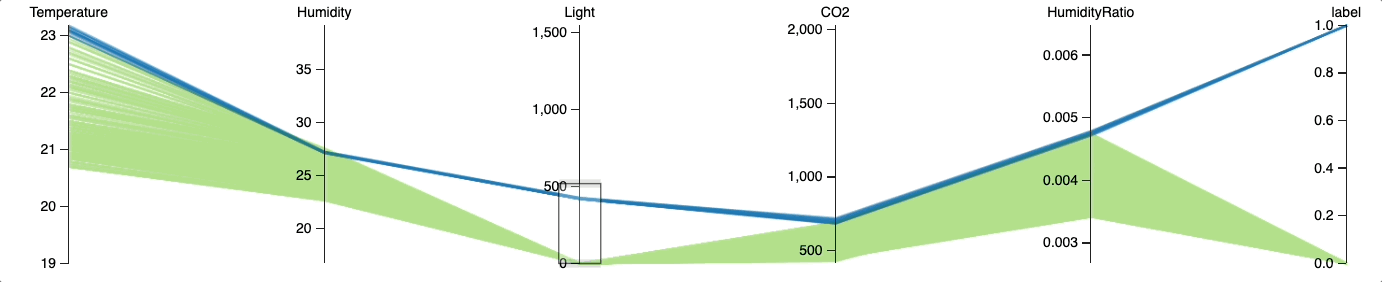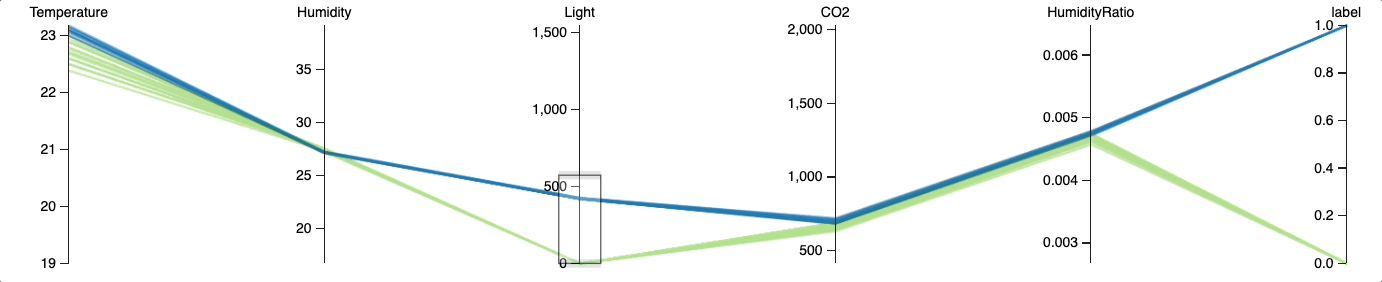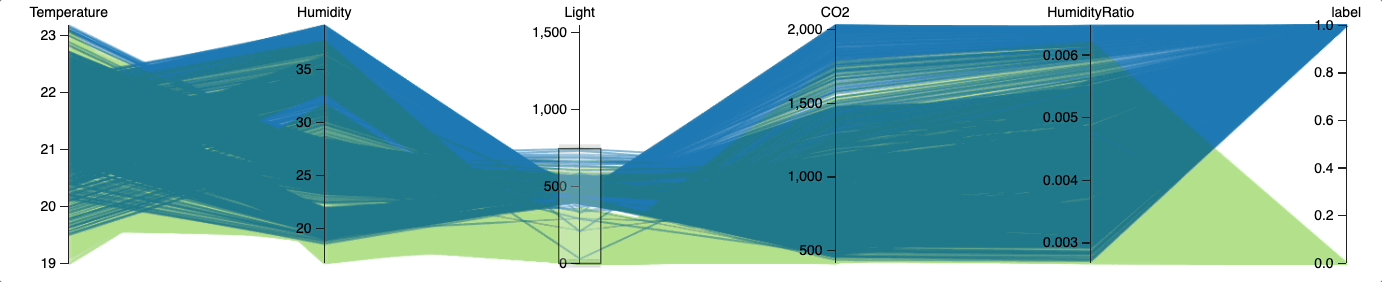
Визуализация в параллельных координатах показывает, что вероятность занятости помещения с освещённостью более 250 люксов высока. Оптимальное пороговое значение, отделяющее занятую комнату от пустой, по-видимому, находится где-то между 250 и 750 люксами.
Найдём наилучшее пороговое значение в этом диапазоне при помощи GridSearch из scikit-learn.
from sklearn.model_selection import GridSearchCV
grid = GridSearchCV(mod, cv=2, param_grid={"threshold": np.linspace(250, 750, 1000)})
grid.fit(train_X, train_y)Получаем наилучшее пороговое значение:
best_threshold = grid.best_params_["threshold"]
best_threshold
> 364.61461461461465Теперь отразим это значение на диаграмме размаха:
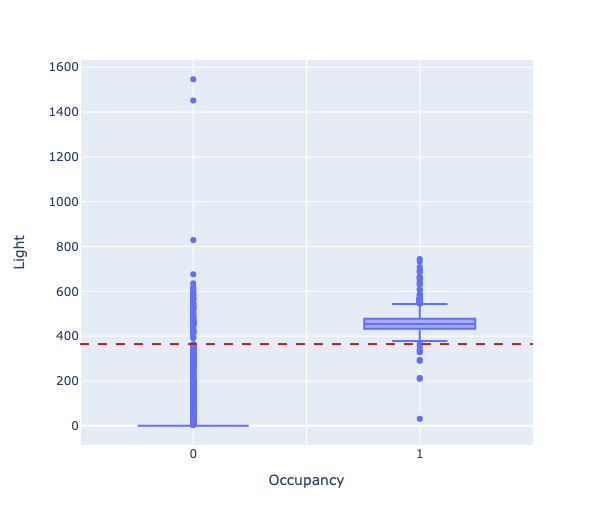
Используем модель с наилучшим пороговым значением для прогнозирования тестового набора данных:
human_preds = grid.predict(val_X)
print(classification_report(val_y, human_preds))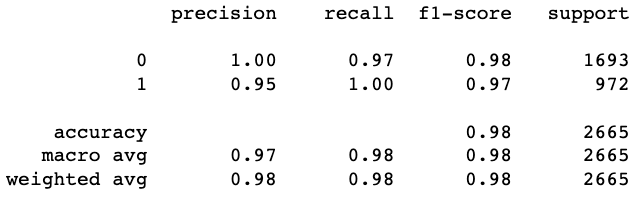
Пороговое значение 365 даёт точность выше, чем пороговое значение 100.
Объединение модели машинного обучения и модели на основе правил
Для создания модели на основе правил обратиться к знаниям предметной области неплохо, однако у подхода есть недостатки:
- сложно обобщать модель на недоступные данные;
- трудно придумать правила для сложных данных;
- нет обратной связи для улучшения модели.
Поэтому комбинация модели на основе правил и модели машинного обучения поможет дата-сайентистам масштабировать и улучшать модель, сохраняя при этом возможность использовать экспертные знания предметной области.
Один из простых способов объединить эти две модели — решить, нужно ли нам уменьшить ложно отрицательные прогнозы (False Negative — FN), или ложно положительные прогнозы (False Positive — FP).
Уменьшение числа ложно отрицательных прогнозов
Вероятно, вам стоит уменьшить FN в таком случае, как прогнозирование наличия у пациента рака (лучше ошибиться, сообщив пациентам, что у них рак, чем не обнаружить его, [чем наоборот: сообщить, что рака нет, когда он есть]).
Чтобы уменьшить FN, выберите положительные прогнозы, где две модели дают разные ответы:
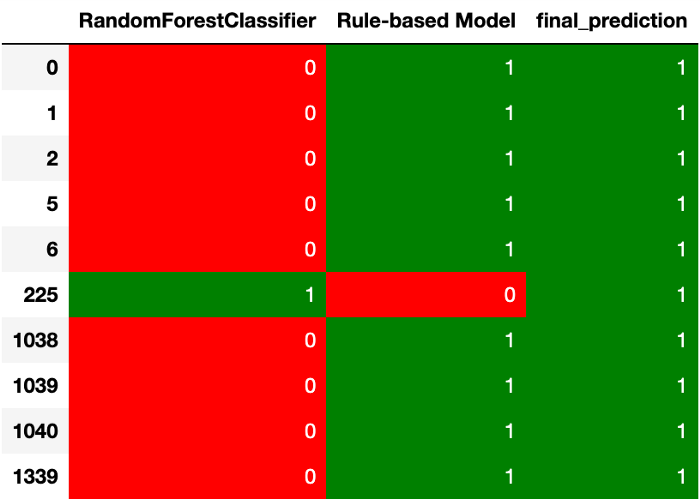
Уменьшение числа ложно положительных прогнозов
Вероятно, вам стоит уменьшить количество FP в таких случаях, как рекомендация детям видео со сценами жестокости (лучше ошибиться, не рекомендуя детям видео для детей, чем рекомендовать детям видео для взрослых).
Чтобы уменьшить количество FP, выберите отрицательные прогнозы, где две модели дают разные ответы.
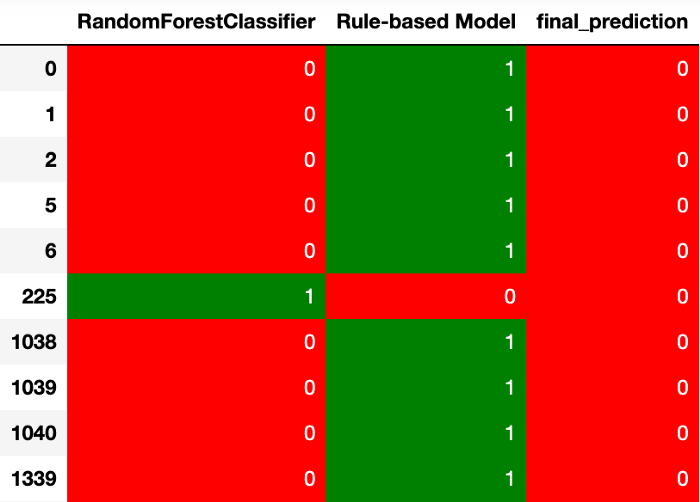
Для принятия решения о выборе прогноза можно использовать и другие, более сложные стратегии
Чтобы узнать подробности о том, как объединять модель машинного обучения с моделями на основе правил, рекомендую посмотреть отличное видео Джереми Джордана:
Заключение
Поздравляю! Вы только что узнали, что такое модель на основе правил и как объединить её с моделью машинного обучения. Надеюсь, что эта статья даст вам знания, необходимые для разработки вашей собственной модели на основе правил.
Добавляйте в избранное этот репозиторий, если хотите попробовать код к моим статьям.
Источник данных:
Точное определение занятости офисного помещения по данным освещённости, температуры, влажности и концентрации углекислого газа с помощью статистических моделей обучения. Luis M. Candanedo, Véronique Feldheim. Energy and Buildings. Том 112, 15 января 2016 г., стр. 28-39.
А мы научим вас аккуратно работать с данными, чтобы вы прокачали карьеру и стали востребованным IT-специалистом.

Data Science и Machine Learning
- Профессия Data Scientist
- Профессия Data Analyst
- Курс «Математика для Data Science»
- Курс «Математика и Machine Learning для Data Science»
- Курс по Data Engineering
- Курс «Machine Learning и Deep Learning»
- Курс по Machine Learning
Python, веб-разработка
- Профессия Fullstack-разработчик на Python
- Курс «Python для веб-разработки»
- Профессия Frontend-разработчик
- Профессия Веб-разработчик
Мобильная разработка
Java и C#
- Профессия Java-разработчик
- Профессия QA-инженер на JAVA
- Профессия C#-разработчик
- Профессия Разработчик игр на Unity
От основ — в глубину
А также
Комментарии (7)

Kotovoz
10.01.2023 01:22-1Где данные модели на основе правил могут пригодиться, для каких реальных задач? Есть ли у вас примеры из практики?!


KirovDoc
10.01.2023 20:13Спасибо за статью, есть над чем подумать, в частности над методологией. По сути это разновидность бэгинга. Вопрос: можно ли представленный вами способ поиска порога заменить на поиск через ROC-анализ? Комментарий: независимо от метода, порог не будет являться стабильной величиной. Можно высчитать порог, который идеально будет делить данные, но в реальности он будет иметь интервал неопределенности (это можно показать через бутстрэп), что приведет к невозможности его использования. Если порог зафиксировать, метрики модели (чувствительность, специфичность..) будут тоже меняться от выборки к выборке. Возможно порог, как правило для принятия решения следует находить не через статистику (потому что ML делает практически тоже самое), а через эмпирический подход и знания предметной области, если это возможно.
OBIEESupport
А не проще ли узнать номер офисного помещения и просто позвонить по телефону? Аукнуть под дверью? Постучаться? Или посмотреть по внутренним камерам? 7 лет назад материал статьи написан - неужели у вас материалы с тех пор не поменялись?
stranger777
Статья написана 1 января 2023 года. В оригинале указано, что время чтения — 7 минут, возможно, вы перепутали эту 7 со сроком написания статьи. Когда речь идёт об уже прошедших годах, Medium указывает год рядом с месяцем и днём.
Возможно, прогнозирование такого рода используется для целей статистики. Когда обзванивать или смотреть камерами каждый офис просто неудобно, проще прикинуть цифру моделью.
И ещё нашлось отслеживание занятости переговорных комнат для оптимизации использования помещений: https://support.google.com/a/answer/9025587?hl=ru. Представьте, что вы разрабатываете информационную панель для задачи такого рода. Конечно, теоретически, можно поставить фотоэлементы во всех помещениях, считать открытие и закрытие двери, но это может подойти не всегда. Здесь пойдут в ход самые разнообразные данные, только бы они были доступны.
OBIEESupport
Извините, я еще и автор medium.com немного. Туда попала выдержка из исследования сделанного 7 лет назад. Ранее мне это исследование было известно на английском языке, года 4 я его рассказывал в средней школе как пример простого применения ИИ.
В реальности - наличие такого количества датчиков уже давным-давно компенсировано встроенным в потолки видеонаблюдением. Мой товарищ заказывал такую систему, проще поставить камеру в каждую комнату с CV на движение, чем калибровать режимы камер раз в месяц, учитывать режим отопления по году, или неправильно сработавшие сигнализации. Это - условия России.
Я - практик, преподаватель, но с большим сдвигом к постоянному применению знаний. За перевод с medium.com - спасибо, но оригинал исследования на английском заметно более информативен.
stranger777
Статья ведь не совсем о полезности набора данных или модели. Она пример того, как включать в модель знания предметной области.