В этой серии статей мы пытаемся описать, как работает CDN и какие технологии делают его существование возможным.
В предыдущей статье мы обсудили иерархию Интернета, разницу между средами передачи данных и путь запроса от компьютера пользователя до сервера, расположенного на другом конце земного шара. В этой поднимемся на несколько уровней выше, чтобы разобрать каким «языком» пользуются компьютеры, чтобы общаться друг с другом.
План
Невозможно по-быстрому рассказать обо всём, что касается устройства Интернета. Потому в этой и следующих статьях мы будем рассматривать только определённое подмножество технологий – часть между физическим уровнем и уровнем приложения.
Не будем говорить о том, как компьютеры используют электричество для представления и передачи данных. Это очень интересная тема, но слишком низкоуровневая для этого цикла.
Но и рассказывать про то, как браузер загружает страницы, тоже не будем. HTTP-запросы, сжатие, языки программирования, рендеринг страниц – всё мимо.
Что нам интересно, так это то, как данные находят путь от одного компьютера до другого.
Коммутация
Если вы достаточно стары, то скорее всего застали проводные телефоны, которыми раньше активно пользовалось человечество. А может, у вас даже до сих пор есть такой! В таком случае, скорее всего вы знаете, что вот ещё лет сто назад они работали в полуавтоматическом режиме.
Сперва вам нужно было поднять трубку и сказать телефонисту (который был реальным человеком), что вы хотите, чтобы вас соединили с вашим знакомым из другого города. Телефонист выслушал бы ваш запрос, повесил бы трубку, а позже перезвонил бы уже с вашим другом «на линии» (on line – пер.).
Чего вы возможно можете не знать, так это того, что происходило за кадром. А там телефонист переключал кабели между портами, чтобы соединить вас с вашим другом:

То, что происходит на картинке – это коммутация каналов. Коммутация каналов – это способ соединения двух узлов сети, при котором между ними устанавливается выделенный канал связи. Через этот канал и происходит общение. Иными словами, когда вы звонили другу, кто-то или что-то в буквальном смысле строил путь из кабелей между вами.
Как нетрудно догадаться, подобный тип коммуникаций не очень-то подходит для Интернета, потому что мы постоянно подключаемся к огромному количеству серверов по всему миру. Строить такую высоконагруженную сеть на основе коммутации каналов было бы слишком безумно. Да и было бы слишком дорого создавать такую сеть, не говоря уже о её поддержке.
Вместо этого Интернет построен на основе коммутации пакетов. При таком способе построения сети, для создания соединения между двумя узлами не требуется физического переключения кабелей. Когда мы посылаем сообщение от одного компьютера к другому, это сообщение проходит через различные сети, каждая из которых сама решает, куда лучше его отправить.
С какой-то точки зрения это может звучать безумно, но по сути в Интернете нет какого-то главного «координатора», который бы решал, по какому пути каждый пакет должен идти. Наш компьютер просто «бросает» пакет в сеть, и все устройства, через которые он проходит, пытаются решить, какой путь для этого пакета будет наиболее оптимальным. Удивительно, но в большинстве случаев, у этих устройств получается достигнуть поставленной цели. Всё благодаря протоколам!
Протоколы
Протокол – это набор правил, определяющий, как узлы сети должны передавать данные друг другу. Вы скорее всего слышали про высокоуровневые протоколы – HTTP, SSH, IMAP, DHCP.
В сфере телекоммуникаций огромное количество протоколов, каждый из которых решает какую-то свою задачу. Из-за того, что их много, есть даже специальные модели, определяющие «уровни протоколов». Если представить, что ваше сообщение, – это конфета, то протоколы в каком-то плане играют роль обёрток для этой конфеты.
Предположим, что вы заказали в подарок своему другу большую плитку вкусного шоколада от местной шоколадной фабрики.
Первым делом плитку шоколада запакуют в обёртку. Затем всё это положат в брендированный пакет. После этого, кто-нибудь в отделе доставки увидит, что это шоколадка – подарок, а потому пакет дополнительно украсят, дабы всё выглядело подобающе. Наконец, фабрика передаст пакет с подарком почтовой компании.
Почтовая компания же, получив пакет, запакует его в коробку и напишет на ней адрес вашего друга. Наконец, они погрузят всё это в грузовик и отправят в точку выдачи.
Когда грузовик приедет в точку выдачи, процесс пойдёт в обратную сторону: сперва выгрузят, потом проверят адрес получателя, распакуют коробку и так далее.
Весь этот процесс оборачивания-разворачивания шоколадки – ровно то, как работают протоколы в Интернете:

История OSI и TCP/IP
Так сложилось, что есть две модели, описывающие уровни протоколов. Одна из них теоретическая – модель OSI, а другая практическая – TCP/IP.
В 70-80-х годах прошлого столетия в сфере телекоммуникаций было много проблем, но и много возможностей. Тогда ещё не было такого Интернета, каким мы его знаем сегодня. Была лишь куча сетей, созданных разными компаниями. И этим сетям нужен был какой-то общий «язык» для общения, или скорее стандарт. А потому многие инженеры работали над тем, чтобы этот самый стандарт создать. Если говорить грубо, то для нас важно то, что в конечном итоге эти люди разделились на две группы.
Первая верила, что подобный стандарт должен создаваться открыто, со всеобщим обсуждением, с решением всех возникающих проблем и вопросов. Чтобы всем было удобно. Эта группа назвала стандарт, который она пыталась создать, – OSI, или Open Systems Interconnection.
Другая группа пошла иным путём, и начала разрабатывать и тестировать протоколы на основе тех сетей, что у них уже были. Так они создали TCP – Transmission Control Protocol, и IP – Internet Protocol. Изначально эти два протокола были частью одного большого, но впоследствии были разбиты на два для упрощения работы с ними.
Эта группа успешно протестировала протокол и перевела сети, которые были под её руководством, на него. Это случилось первого января 1983-го года. Так что, можно сказать, что это день, когда родился Интернет.
После этого TCP/IP начал набирать популярность, потому что он «просто работал». Плюс, эта модель была бесплатной, в то время как авторы OSI хотели взимать деньги со всех, кто пользовался бы их стандартами.
И что в итоге стало с OSI? Инициатива провалилась. Из-за идеи «открытости» те, кто принимал тогда решения, потратили очень много времени на обсуждения и споры. Часть из них лоббировали идеи, которые были выгодны большим корпорациям. Из-за других же дискуссии постоянно увязали в обсуждении незначительных деталей.
Однако, несмотря на то, что OSI как сетевая модель не нашла своего применения в реальном мире, она всё ещё остаётся хорошей теоретической моделью, описывающей уровни протоколов. Но модель, которая была имплементирована и захватила мир – TCP/IP.
Вот, как выглядят уровни протоколов в этих моделях:

TCP/IP
Обычно, когда обсуждают OSI и TCP/IP, пытаются сравнить эти модели и найти соответствия между их уровнями. Хоть картинка выше и выглядит как сравнение, мы не будем этого делать, потому что то, как соотносятся их уровни, не особо важно для нашей статьи. Да и «многоуровневость» как таковая «может быть вредной», если верить RFC 3439.
Ключевые протоколы модели TCP/IP, очевидно, TCP и IP. Всё остальное в этой модели описано довольно туманно, и даже авторы учебников и справочников по сетям не могут сойтись на чётких названиях и количестве уровней в этой модели.
Есть ли физический уровень под уровнем сетевого доступа? Нужно ли вообще называть уровень сетевого доступа так, или это всё же «канальный уровень»? Вокруг TCP/IP много таких вопросов. Однако, всё это не так важно, потому что основная суть стека очень простая.
Предположим, есть два приложения в сети, которые хотят обменяться данными. Пусть один из них сгенерирует сообщение. Не важно, какое именно. Это может быть HTTP-запрос, а может и нет. Это сообщение генерируется на уровне приложения.

Дальше оно передаётся на транспортный уровень, где к нему добавляется TCP или UDP-заголовок. Этот заголовок содержит информацию о портах, которые используются приложениями, и некоторую другую информацию (но о ней чуть позже). В результате получается то, что обычно называется датаграммой или сегментом.

Затем, сегмент передаётся на межсетевой уровень. Там к нему добавляется IP-заголовок, содержащий адреса компьютеров, на которых запущены приложения, участвующие в этом обмене данными. Результат объединения сегмента и IP-заголовка обычно называется пакетом.
Справедливости ради, нет чёткой разницы между датаграммами, сегментами и пакетами. В большинстве случаев для простоты они все называются «пакетами». Термины «датаграмма» и «сегмент» используются, только когда нужно явно указать тип протокола, с которым мы имеем дело.

Наконец, пакет передаётся на канальный уровень, где кодируется и уходит по проводам в сторону точки назначения. Протоколы на этом уровне так же добавляют свой заголовок в каждый пакет, и в результате получается кадр (или «фрейм» – пер.).
Кадры обычно содержат не только заголовок, но и окончание. Например, Ethernet-кадр для нашего сообщения может выглядеть примерно так:

Когда кадр передаётся от одного промежуточного узла сети к другому, эти узлы разбирают кадр на части, проверяют IP-заголовок пакета, определяют что с ним делать, а затем создают новый кадр для этого пакета и передают его следующему узлу.
Иными словами, когда путь сообщения выглядит как-то так:

То работа протоколов на пути этого сообщения выглядит так:

Окей, теперь мы знаем, что модель TCP/IP определяет протоколы транспортного и межсетевого уровней, но не особо тщательно описывает протоколы прикладного и канального уровней. Давайте теперь посмотрим на транспортный уровень чуть поближе.
TCP и UDP
Транспортный уровень модели TCP/IP основан на двух китах: Transmission Control Protocol и User Datagram Protocol. Есть и другие протоколы на этом уровне (например, QUICK), но они не так часто используются.
Протоколы транспортного уровня используется для адресации пакетов с порта приложения отправителя на порт приложения получателя. Более того, протоколы этого уровня не знают ничего про различия в узлах сетей. Всё, что им требуется знать про адресацию, это то, что есть приложение, отсылающее сообщение, и оно для отправки использует какой-то порт. И приложение, которое получает сообщение, тоже использует какой-то порт. Основная «адресация внутри Интернета» же реализована на межсетевом уровне, и будет описана в следующей статье.
UDP куда «легче» и проще, чем TCP, но в то же время UDP не такой надёжный, как TCP. Чтобы посмотреть на разницу между ними поподробнее, давайте начнём с User Datagram Protocol.
User Datagram Protocol
Этот протокол используется для «связи без установки соединения» (connectionless communication – пер.). Один узел сети просто отсылает пакеты, адресуя их другому узлу. Отправитель не знает ничего о том, готов ли получатель к приёму пакетов, и вообще, существует ли этот получатель. Отправитель также не ждёт какого-либо подтверждения о том, что получатель принял предыдущие пакеты.
Пакеты, передаваемые с помощью UDP, иногда называются датаграммами. Этот термин обычно используется тогда, когда важно подчеркнуть, что пакет передаётся без установки соединения.
Заголовок UDP-пакета состоит из 8 байт, которые включают в себя:
порт отправителя;
порт получателя;
длину датаграммы;
контрольную сумму.
Вот так просто. Типичная UDP-датаграмма выглядит так:

Пробуем
UDP-сервер очень просто поднять самому. Вот, например, такой сервер, написанный на Node.js ровно так, как об этом сказано в официальной документации:
const dgram = require('dgram');
const server = dgram.createSocket('udp4');
server.on('error', (err) => {
console.log(`error:\n${err.stack}`);
server.close();
});
server.on('message', (msg, rinfo) => {
console.log(`got a message from ${rinfo.address}:${rinfo.port}: ${msg}`);
});
server.on('listening', () => {
const address = server.address();
console.log(`listening ${address.address}:${address.port}`);
});
server.bind(8082);Давайте ж запустим его:
$ node udp.js
server listening 0.0.0.0:8082Теперь мы можем использовать netcat для отправки датаграмм из соседнего окна терминала:
$ nc -u 127.0.0.1 8082
Hello, server!
Do you have a minute to talk about UDP?Наш сервер успешно логирует отправленные нами датаграммы после их получения:
$ node udp.js
server listening 0.0.0.0:8082
server got a message from 127.0.0.1:55823: Hello, server!
server got a message from 127.0.0.1:55823: Do you have a minute to talk about UDP?Как видите из логов выше, netcat решил использовать порт 55823 для отправки пакетов. Если мы возьмём Wireshark и перехватим эти пакеты, то увидим следующее:

Если не хотите поднимать Node.js-сервер и перехватывать трафик самостоятельно, но хочется потыкать в Wireshark, качайте дамп-файл.
Итак, что у нас тут? Порт отправителя – 55823, тот, что выбрал netcat. Порт получателя – 8082, тот, что указан у нас в настройках сервера. Длина пакета 48 байт, потому что 8 из них – это заголовок, а ещё 40 – наше сообщение. И в конце контрольная сумма, указанная netcat.
Как видите, в логе Wireshark нет никаких ответов от сервера, а потому клиент не может быть уверен, что сервер действительно получил его датаграммы. По этой причине UDP используется там, где не страшно потерять часть сообщений. Например, при видео- или аудио-стриминге. Да, можно использовать для этого и TCP, но, как вы увидите чуть через минуту, использование TCP замедлило бы в таком случае передачу данных.
Справедливости ради, хоть UDP и не предполагает наличия подтверждений о получении сообщений, мы всё ещё можем узнать о том, что получатель недоступен. С помощью ICMP. Попробуйте отправить сообщения используя netcat, не включив перед этим UDP-сервер, и посмотрите, что будет в логах Wireshark. Вот, что вы там увидите; а вот дамп-файл.
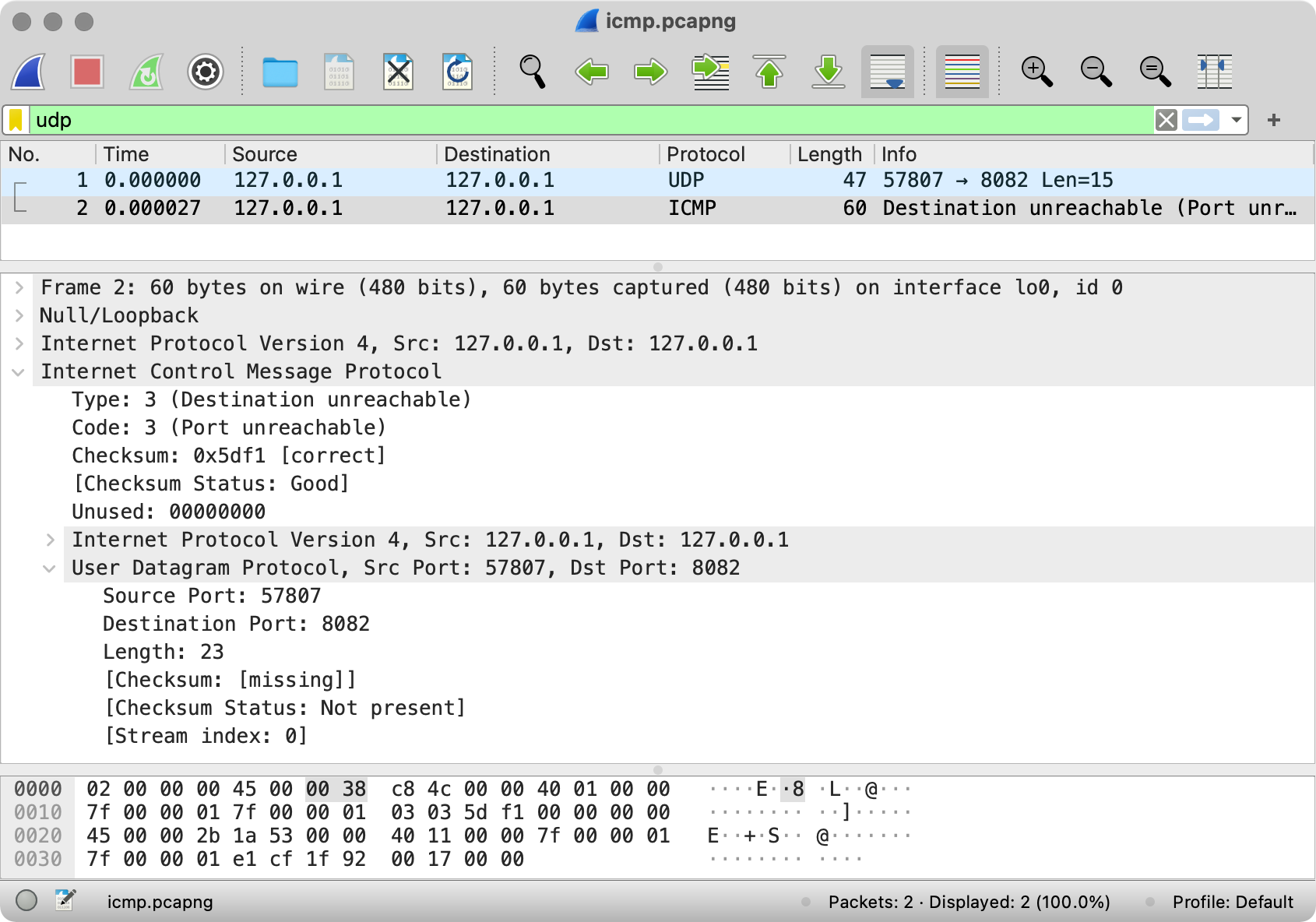{kind=link}
Transmission Control Protocol
Если UDP простой и не требующий установки соединения, то TCP – сложный и требующий. Перед тем, как начать передачу данных, клиент и сервер должны подключиться друг к другу и договориться о том, как они будут осуществлять эту самую передачу.
В отличие от датаграмм в UDP, пакеты, создаваемые TCP, называются сегментами.
А вот, некоторые из тех задач, что решает TCP во время передачи данных:
Убеждается в том, что сегменты доставлены в нужном порядке.
Убеждается в том, что они вообще доставлены.
Контролирует поток пакетов, чтобы не перегружать им узлы сети.
Работы много, а потому и заголовок у TCP как минимум 20 байт, а то и больше. Он включает в себя:
порт отправителя;
порт получателя;
порядковый номер;
номер подтверждения;
длину заголовка;
флаги;
размер окна;
контрольную сумму;
указатель важности;
дополнительные опции.
Схема пакета выглядит так:

Порт отправителя, порт получателя и контрольная сумма – такие же поля, как и в UDP. А чтобы объяснить оставшиеся, давайте перейдём к тестам.
Пробуем
Поднимем простой TCP-сервер с помощью Node.js (опять же, используя код из официальной документации).
const net = require('net');
const server = net.createServer(connection => {
console.log('client connected');
connection.on('end', () => {
console.log('client disconnected');
});
connection.write('Hello, client!\n');
// 'connection' – это поток, который мы можем перенаправить
// сперва перенаправляем его в stdout, чтобы логировать сообщения от клиента
connection.pipe(process.stdout);
// затем перенаправляем в самого себя,
// тем самым отправляя в ответ то, сообщение, что получили
connection.pipe(connection);
});
server.on('error', (err) => {
console.log(`server error:\n${err.stack}`);
server.close();
});
server.listen(8082, () => {
const address = server.address();
console.log(`server listening ${address.address}:${address.port}`);
});Этот код похож на тот, что мы использовали для UDP-сервера, но вместо простой работы со входящими сообщениями как со строками, мы теперь оперируем объектом соединения. Этот объект позволяет нам не только выводить сообщения, когда мы их получаем, но и отправлять что-нибудь в ответ, и определять подключение-отключение клиента. Если вы когда-либо поднимали самостоятельно HTTP-сервера, то многое тут будет вам знакомо.
Запустим сервер:
$ node tcp.js
server listening :::8082Два двоеточия вместо привычного IP означают, что сервер забиндился на localhost с помощью IPv6, но это не принципиально сейчас
Теперь используем netcat в соседнем окне терминала, чтобы соединиться с нашим сервером по TCP:
$ nc 127.0.0.1 8082
Hello, client!Строка, что вы видите в логе, пришла к нам с сервера как только соединение было установлено. Вот, как выглядят логи сервера:
$ node tcp.js
server listening :::8082
client connectedКак видите, сервер получил уведомление от клиента и знает, что этот клиент существует, и что он собирается что-то прислать. Давайте пошлём, раз так:
$ nc 127.0.0.1 8082
Hello, client! # сообщение от сервера
Hello, server! # наше сообщение
Hello, server! # ответ от сервера
Hey, stop it! # наше сообщение
Hey, stop it! # ответ от сервераМы написали простейший эхо-сервер, который присылает нам в ответ всё то, что получает от нас.
Закроем netcat нажатием Ctrl+C и посмотрим на логи сервера:
$ node tcp.js
server listening :::8082
client connected
Hello, server!
Hey, stop it!
client disconnectedТам появились два сообщения, что мы присылали, и уведомление о том, что клиент отключился.
Окей, и как же это возможно, что сервер знает о том, что появилось какое-то «соединение», если мы ещё не послали никаких данных? Чтобы разобраться, обратимся снова к Wireshark.
Вот, как наш обмен сообщениями выглядел там:

И снова, если не хочется поднимать сервер самостоятельно, но хочется потыкать в логи, держите дамп.
Как много всего! Давайте посмотрим на это в деталях.
Рукопожатие
Прежде, чем клиент начнёт посылать данные серверу, они оба, как мы уже говорили, должны установить соединение. Эта «установка» обычно называется рукопожатием.
В нашем случае рукопожатие происходит в три этапа:
Клиент посылает серверу пакет, который называется SYN.
Сервер отвечает пакетом SYN-ACK.
Клиент отвечает серверу пакетом ACK.
Названия пакетов взяты из названий флагов, которые установлены в TCP-заголовках этих пакетов. Вот как первый из пакетов рукопожатия выглядит в Wireshark:

Как видите, один из битовых флагов установлен в 1. Флаг называется «Syn», что есть сокращение от «Синхронизация».
TCP – надёжный протокол, что означает, что отправитель всегда в курсе, дошёл ли пакет до получателя или нет. Чтобы сделать такое уведомление возможным, TCP использует специальные типы пакетов (SYN, ACK и пр.), а также каждый TCP-заголовок содержит два числа: порядковый номер и номер подтверждения.
Порядковый номер (Sequence number – пер.) показывает, сколько данных отправитель уже послал в сторону получателя. Этот номер увеличивается на 1 каждый раз, когда отправитель посылает пакеты с флагами SYN или FIN, а также увеличивается на размер полезных данных, если они были переданы. Число, указанное в номере, не учитывает текущий пакет. А потому порядковый номер первого пакета, посылаемого клиентом, всегда равен 0.
Номер подтверждения (Acknowledgement number – пер.) же показывает сколько данных отправитель этого пакета получил на текущий момент. Это число как бы отзеркаливает порядковый номер «собеседника», но опережает его на один шаг. А потому первый пакет, отправленный сервером, имеет номер подтверждения равный 1.
Вообще, начальные значения для этих номеров выбираются случайным образом. Но для простоты обычно оперируют их относительными значениями, как, например, вы можете видеть на скриншоте Wireshark выше.
Эти числа важны, потому что позволяют обеим сторонам понимать статус передачи данных. И клиент, и сервер, оба ожидают получить определённые значения порядкового номера и номера подтверждения от противоположной стороны. А если вдруг действительно полученные значения расходятся с ожидаемыми, значит где-то произошла ошибка, и возможно кто-то из них должен переотправить какие-то пакеты.
Так вот. Как выглядит рукопожатие в нашем случае:

И когда рукопожатие закончено, наш сервер как раз и понимает, что клиент готов передавать данные, и начинает их от него ожидать.
Передача данных
Когда рукопожатие закончено, начинается передача данных.

Как видно в логе выше, каждый кусок данных отправленный одной стороной, подтверждён (ACK-ed – пер.) отдельным сегментом, отправленным другой стороной.
Выглядит легко и просто, но это так лишь потому, что наш пример совсем уж учебный. В реальном же мире полно проблем: пакеты могут потеряться, канал может быть забит, может возникнуть какая-нибудь ошибка, и так далее. TCP обрабатывает все эти ситуации. Как? Это история для отдельной серии статей. Дайте нам знать, если вам интересно было бы про это почитать.
А, кстати. У каждого пакета в логе выше выставлен флаг PSH. Это необычно, и в реальной жизни этот флаг не так часто используется. Вероятно, это особенность netcat.
Завершение соединения
Когда один из «собеседников» решает прекратить общение, он инициирует завершение соединения. Этот процесс похож на рукопожатие, но вместо флага SYN используется флаг FIN.
Вот как выглядит завершение соединения в нашем логе:

Как вы можете заметить, для завершения соединения потребовалось четыре сегмента, а не три, как в случае с рукопожатием. Схема выглядит чуть иначе, потому что при завершении соединения, собеседник (в нашем случае сервер) должен сперва уведомить приложение, использующее TCP, о том, что соединение вот-вот завершится. И когда это приложение будет готово к завершению, тогда TCP собеседника отправит свой FIN-пакет.
И поскольку участники обмена пакетами должны подобным образом «договориться» о завершении, мы можем подписаться на соответствующее событие у себя в приложении. Что мы выше в коде и сделали.
Кстати, иногда завершение соединения вызывается не сегментом с флагом FIN, а сегментом с флагом RST. Это не совсем обычная практика, то такое возможно. Также RST-флаг может быть использован для атаки, которая может прервать существующее соединение между TCP-узлами. См. статью Роберта Хитона, если вдруг интересно.
Подытожим
Интернет работает за счёт коммутации пакетов. Основной его стек – TCP/IP. Два главных протокола транспортного уровня этого стека – TCP и UDP, на каждый из которых мы по-быстрому посмотрели в этой статье.
В следующей же посмотрим на то, как устроен Internet Protocol, и разберём, как благодаря ему все компьютеры мира могут общаться друг с другом.
От переводчика: в этой статье было много сетевых терминов – названий уровней, моделей, протоколов. Сложно было понять, в каких местах правильнее переводить, в каких нет. Я руководствовался тем, что протоколы и модели в рунете всё же чаще называют латиницей, не переводя, в то время как уровни всё же переводят. Изображения оставил без перевода. Если вам кажется, что получилась мешанина, и вы что-то не поняли – напишите мне, пожалуйста, где именно возникло недопонимание, я что-нибудь придумаю и обновлю статью.
Следующая статья уже доступна на английском. Переведу её, если эта не потонет в минусах.
vesper-bot
Справедливости ради, автор неправ в части TCP/IP соответствия L1 OSI, на физическом уровне устройства и среды передачи имеют также свои протоколы, которые зачем-то упрятаны в Network Access. Ethernet-протокол это всего лишь один из оберток над физикой, являющийся L2-протоколом, ниже него может быть много что, от V12 до протоколов спутникового канала.
victor_1212
> Справедливости ради
какая там справедливость, когда понадобилось лет >30 назад с нуля сделал до 5-го уровня, но нет желания комментировать :)