
В предыдущей статье (Автоматический подбор синаптических весов. Самое начало. Циклический перебор) мы простым полным последовательным циклическим перебором подобрали коэффициенты для определения значения 13-ти сегментного индикатора.
Можно ли что-то улучшить в этом самом простом алгоритме?
Оказывается, можно...
Сокращаем количество вычислений и ускоряемся в 1,8 (!) раза, получив на выходе те же коэффициенты.
Напомним результаты:
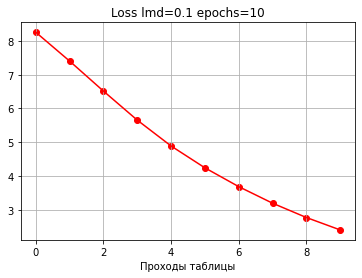
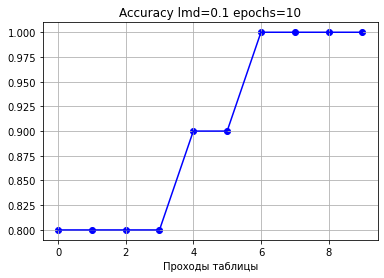
Начальная ошибка: 9.000000000000002
Начальная точность: 0.1
0: loss: 8.256888108456812 accuracy: 0.8
1: loss: 7.4035437200249845 accuracy: 0.8
2: loss: 6.515313270760133 accuracy: 0.8
3: loss: 5.655615573184693 accuracy: 0.8
4: loss: 4.889748309748125 accuracy: 0.9
5: loss: 4.243067834925036 accuracy: 0.9
6: loss: 3.6863744601447674 accuracy: 1.0
7: loss: 3.1957574183834616 accuracy: 1.0
8: loss: 2.7718738867787973 accuracy: 1.0
9: loss: 2.4043407365354073 accuracy: 1.0
Конечная ошибка: 2.4043407365354073
Конечная точность: 1.0Полученные коэффициенты (синаптические веса):
[[ 0.2 0.6 -0.9 1. 1. -0.4 -1. -0.4 1. 0.5 0.6 0.4 -0.9]
[-1. -1. 1. -1. 1. -1. -1. 0.6 -1. 0.5 -1. -1. 0.5]
[ 0.6 0.5 -0.6 -1. 1. 0.2 1. -1. 1. -1. 0.6 0.3 -0.6]
[ 0.1 0.9 -0.9 -1. 1. 0.7 0.9 -1. -1. 1. 0.6 0.4 -1. ]
[ 0.8 -1. 0.3 1. 0.6 0.6 0.8 -1. -1. -0.2 -1. -1. 0.5]
[ 0.2 0.6 -0.6 1. -1. 0.5 0.7 -0.9 -1. 0.9 0.6 0.3 -0.7]
[ 0.1 0.7 -0.7 1. -1. 0.2 1. -0.8 1. 0.3 0.2 0.2 -0.6]
[ 1. 1. -0.3 -1. 0.8 -1. -1. 0.4 -1. 0.5 -1. -1. 0.2]
[-0.6 0.8 -0.9 1. 1. -0.3 1. -1. 1. 0.7 0.3 0.2 -0.9]
[-0.6 0.7 -0.9 1. 1. 0. 0.9 -1. -1. 0.8 0.7 0.6 -0.8]]Графики:
Циклический перебор. В чем будем сокращать.
Кратко подбор коэффициентов простым полным последовательным перебором выглядит так::
1. берем значение следующего коэффициента
2. Считаем ошибку для текущего значения выбранного коэффициента
3. Считаем ошибку для значения коэффициента, увеличенного на 1 шаг
4. Считаем ошибку для значения коэффициента, уменьшенного на 1 шаг
5. Определяем минимальную ошибку
6. Фиксируем новое значение коэффициента
7. Переходим на пункт 1.
Основная часть вычислений происходит при вычислении ошибки - мы делаем 3 вычисления ошибки для каждого коэффициента, перебирая все коэффициенты последовательно, и повторяем это заданное количество эпох или до достижения заданного уровня точности.
Код "Базовый вариант"
# базовый вариант
import numpy as np
import time
lmd = 0.1
epochs = 10
def softmax(scores): # функция softmax
softmax = np.exp(scores) / np.sum(np.exp(scores))
return softmax
def E(): # функция подсчета квадратической ошибки
array = np.zeros(10) # создаем нулевой массив
Ef = np.zeros(10) # создаем нулевой массив
E_sum = 0 # обнуляем счетчик
for n in range(10): # для каждой цифры
for i in range(10): # для каждой строки
array[i] = np.dot(X[n].T, K_array[i]) # умножаем вектор X (значения индмкаторв) на коэффиценты по строке
array_soft = softmax(array) # преобразуем через softmax
for k in range (10): # для каждой строки
Ef[n] += (array_soft[k]-Y_cat[n][k])**2 # суммируем квадраты ошибок в строкам
E_sum += Ef[n] # суммируем квадратические ошибки по каждой цифре
return E_sum # врзвращаем суммарнуую квадратическую ошибку
def choice(): # функция изменения коэффициентоа
this_array = np.zeros(3) # создаем нулевой массив для трех вариантов квадратической ошибки
this_array[0] = E() # считаем квадратическую ошибка с текущими кожффициентами
K_array[n][k] = np.round(K_array[n][k] + lmd,2) # добавляем увеличиваем коффициенты на 1 шаг
this_array[1] = E() # считаем квадратическую ошибку с коэффициентами, увеличенными нв 1 шаг
K_array[n][k] = np.round(K_array[n][k] - 2*lmd,2) # уменьшаем коэффициенты на 1 шан
this_array[2] = E() # счиатем квадратическую ошибку с кожффициентами, уменьшеными на 1 шаг
min = np.argmin(this_array) # выбираем минимальное значение квадратических шошибок
if min == 0: K_array[n][k] = np.round(K_array[n][k] + lmd,2)
if min == 1: K_array[n][k] = np.round(K_array[n][k] + 2*lmd,2)
return this_array[min] # возвращает минимальное значение квадратической ошибки
def correct_count(): # функция подсчета точности
correct = 0 # обнуляем счетчик
for n in range(10): # для каждой цифры
array = np.zeros(10) # создаем нулевой массив
for k in range(10): # для каждой строки
array[k] = np.dot(X[n].T, K_array[k]) # умножаем вектор X (значчения индмкаторв) на коэффиценты по строке
array_soft = softmax(array) # преобразуем через softmax
if np.argmax(array_soft) == Y[n]: # если совпадает с правильным ответом
correct += 1 # то увеличиваем количество на 1
return correct/10 # ыозвращаем среднее значение
X = np.array([
[1,1,1,1,1,1,0,1,1,1,1,1,1],
[0,0,1,0,1,0,0,1,0,1,0,0,1],
[1,1,1,0,1,1,1,1,1,0,1,1,1],
[1,1,1,0,1,1,1,1,0,1,1,1,1],
[1,0,1,1,1,1,1,1,0,1,0,0,1],
[1,1,1,1,0,1,1,1,0,1,1,1,1],
[1,1,1,1,0,1,1,1,1,1,1,1,1],
[1,1,1,0,1,0,0,1,0,1,0,0,1],
[1,1,1,1,1,1,1,1,1,1,1,1,1],
[1,1,1,1,1,1,1,1,0,1,1,1,1]
])
Y = [0,1,2,3,4,5,6,7,8,9]
#One-Hot-Encoding
import tensorflow.keras
Y_cat = tensorflow.keras.utils.to_categorical(Y, 10)
start_time = time.time()
# маnрица начальных весов, все по 0
K_array = np.zeros([10, 13]) # Создаем начальный нулевой массив коэффициентов
print('Начальная ошибка:', E())
print('Начальная точность:', correct_count())
print()
for N_epochs in range(epochs): # для каждой эпохи
for n in range(10): # для каждой цифры
for k in range(13): # Для каждого столбца
choice() # изменяем коэффициенты
loss = E() # считаем суммарную квадратическую ошибку
accuracy = correct_count() # считаем количество правильных ответов, деленное на 10 (количество цифр
print(str(N_epochs) + ': loss: ' + str(loss) + ' accuracy: ' + str(accuracy))
print()
print('Конечная ошибка:', E())
print('Конечная точность:', accuracy)
print()
print("timing:", (time.time() - start_time), 'sec')Сокращение №1. Сохраняем минимальную ошибку.
Изначально мы делаем три подсчета ошибки для каждого коэффициента.
Заметим, что, полученное минимальное значение ошибки для текущего коэффициента будет значением начальной ошибки для следующего коэффициента. Если это значение сохранять, то высчитывать это значение для следующего коэффициента уже не понадобится. Таким образом количество вычислений ошибок для каждого коэффициента сократится с 3 до 2 - это 1,5 раза (!), а заменить нужно всего одну строку.
Код функции изменения коэффициентов. Базовый вариант.
# базовый вариант
def choice(): # функция изменения коэффициентоа
this_array = np.zeros(3) # создаем нулевой массив для трех вариантов квадратической ошибки
this_array[0] = E() # считаем квадратическую ошибка с текущими кожффициентами
K_array[n][k] = np.round(K_array[n][k] + lmd,2) # добавляем увеличиваем коффициенты на 1 шаг
this_array[1] = E() # считаем квадратическую ошибку с коэффициентами, увеличенными нв 1 шаг
K_array[n][k] = np.round(K_array[n][k] - 2*lmd,2) # уменьшаем коэффициенты на 1 шан
this_array[2] = E() # счиатаем квадратическую ошибку с кожффициентами, уменьшеными на 1 шаг
min = np.argmin(this_array) # выбираем минимальное значение квадратических шошибок
if min == 0: K_array[n][k] = np.round(K_array[n][k] + lmd,2)
if min == 1: K_array[n][k] = np.round(K_array[n][k] + 2*lmd,2)
return this_array[min] Код функции изменения коэффициентов "Сокращение №1"
# Сокращение 1
def choice1(): # функция изменения коэффициентоа
this_array = np.zeros(3) # создаем нулевой массив для трех вариантов квадратической ошибки
#this_array[0] = E() # считаем квадратическую ошибка с текущими кожффициентами
this_array[0] = last_E if N_epochs else E() # присваиваем значение прошлых вычислений
K_array[n][k] = np.round(K_array[n][k] + lmd,2) # добавляем увеличиваем коффициенты на 1 шаг
this_array[1] = E() # считаем квадратическую ошибку с коэффициентами, увеличенными нв 1 шаг
K_array[n][k] = np.round(K_array[n][k] - 2*lmd,2) # уменьшаем коэффициенты на 1 шан
this_array[2] = E() # счиатем квадратическую ошибку с кожффициентами, уменьшеными на 1 шаг
min = np.argmin(this_array) # выбираем минимальное значение квадратических шошибок
if min == 0: K_array[n][k] = np.round(K_array[n][k] + lmd,2)
if min == 1: K_array[n][k] = np.round(K_array[n][k] + 2*lmd,2)
return this_array[min] При запуске 100 раз на каждый вариант видим, что соотношение среднего времени действительно составляет 1.42, при том что итоговые коэффициенты, точность и ошибка остались теми же.
mean_choice: 1.326184549331665
mean_choice1: 0.9316199898719788
1.4235252181674487Сокращение №2. Сохраняем направление.
Анализ истории изменений коэффициентов показал, что в большинстве случаев направление движения сохраняется несколько шагов подряд, то есть вероятность того, что направление изменения на данном шаге будет такое же, как и на предыдущем, больше, чем вероятность того, что направление изменится. В данном примере направление сохранялось в 86,24% случаев.
history
1000000100 1111110000 2222220222 1111111111 1111111111 1000022222 2222222222 2222000000 1111111111 1111010000 1111100100 1111000000 2222222202
2222222222 2222222222 1111111111 2222222222 1111111111 2222222222 2222222222 1111110000 2222222222 1111100000 2222222222 2222222222 1111100000
1111110000 1111100000 2222200002 2222222222 1111111111 1111000220 1111111111 2222222222 1111111111 2222222222 1111100100 1110000000 0222220200
1201000000 1111111011 2222222022 2222222222 1111111111 1111111000 1111110111 2222222222 2222222222 1111111111 1111101000 1111000000 2222222222
1111110101 2222222222 1011000000 1111111111 1111110000 1111101000 1111110110 2222222222 2222222222 1002220000 2222222222 2222222222 1101010001
1010000000 1111101000 2222202000 1111111111 2222222222 1111100000 1111111000 2222222022 2222222222 1111111011 1111100100 1110000000 2222220200
1201000000 1111111000 2222222000 1111111111 2222222222 1111100222 1111111111 2222222002 1111111111 1110010020 1101000200 1100000000 2222220000
1111111111 1111111111 2100002220 2222222222 1111101110 2222222222 2222222222 1110010000 2222222222 1111100000 2222222222 2222222222 1100000000
2222220000 1101111110 2222222220 1111111111 1111111111 1000002222 1111111111 2222222222 1111111111 0011111110 1111000020 1100000000 2222222202
2222220000 1111110010 2222222220 1111111111 1111111111 1101020022 1111111110 2222222222 2222222222 0011111111 1111111000 1111110000 2222222200
repeat: 1009 1170 86.24%
norepeat: 161 1170 13.76%Исходя из представленного, каждый раз при оценке нужного изменения коэффициента мы можем предполагать, что, скорее всего, направление движения будем таким же, как и при предыдущем изменении этого коэффициента. Теперь будем брать из памяти направление движения и сразу считать ошибку именно для этого направления.
Если новая ошибка будет меньше сохраненной входящей, значит изменение сделано корректно, сохраняем и переходим к следующему коэффициенту. Если же новая ошибка не будет меньше сохраненной входящей, то в этом случае вернем все обратно и сработаем по версии "Сокращение №1". Таким образом, в большинстве случаев мы считаем лишь 1 ошибку и идем дальше. При этом итоговые коэффициенты, точность и ошибка остаются теми же, так как сами изменения делаются те же.
Код функции смены коэффициентов "Сокращение №2"
def choice2(): # функция изменения коэффициентоа
if not N_epochs: # здесь прошлого изменения еще нет, только начали
this_array = np.zeros(3) # создаем нулевой массив для трех вариантов квадратической ошибки
this_array[0] = last_E if N_epochs else E() # считаем или скачиваем квадратическую ошибка с текущими кожффициентами
K_array[n][k] = np.round(K_array[n][k] + lmd,2) # добавляем увеличиваем коффициенты на 1 шаг
this_array[1] = E() # считаем квадратическую ошибку с коэффициентами, увеличенными нв 1 шаг
K_array[n][k] = np.round(K_array[n][k] - 2*lmd,2) # уменьшаем коэффициенты на 1 шан
this_array[2] = E() # счиатем квадратическую ошибку с кожффициентами, уменьшеными на 1 шаг
min = np.argmin(this_array) # выбираем минимальное значение квадратических шошибок
if min == 0: K_array[n][k] = np.round(K_array[n][k] + lmd,2)
if min == 1: K_array[n][k] = np.round(K_array[n][k] + 2*lmd,2)
if min == 2: pass
if min == 0 : K_array_history[n][k] = K_array_history[n][k] + '0'
if min == 1 : K_array_history[n][k] = K_array_history[n][k] + '1'
if min == 2 : K_array_history[n][k] = K_array_history[n][k] + '2'
# Вносим K_array_history_last[n][k]. Это добавление по сравнения с Сокращеие №1
if min == 0 : K_array_history_last[n][k] = '0'
if min == 1 : K_array_history_last[n][k] = '1'
if min == 2 : K_array_history_last[n][k] = '2'
return this_array[min] # возвращает минимальное значение квадратической ошибки#
else:
this_array = np.zeros(3) # создаем нулевой массив для трех вариантов квадратической ошибки
# начинаем менять коэффициенты по прошлым изменениям
if K_array_history_last[n][k] == '0': pass
if K_array_history_last[n][k] == '1': K_array[n][k] = np.round(K_array[n][k] + lmd,2)
if K_array_history_last[n][k] == '2': K_array[n][k] = np.round(K_array[n][k] - lmd,2)
this_E = E()
if this_E < last_E: # если новое значение меньше, то идем дальше
K_array_history[n][k] = K_array_history[n][k] + K_array_history_last[n][k]
return this_E # возвращает минимальное значение квадратической ошибки
else: # если нет, то все возвращаем и пересчитываем
# вернули все обратно
if K_array_history_last[n][k] == '0': pass
if K_array_history_last[n][k] == '1': K_array[n][k] = np.round(K_array[n][k] - lmd,2)
if K_array_history_last[n][k] == '2': K_array[n][k] = np.round(K_array[n][k] + lmd,2)
this_array[0] = last_E # вместо вычислений берем уже сосчитанное знаяение ошибки значение ошибки
K_array[n][k] = np.round(K_array[n][k] + lmd,2) # добавляем увеличиваем коффициенты на 1 шаг
this_array[1] = E() # считаем квадратическую ошибку с коэффициентами, увеличенными нв 1 шаг
K_array[n][k] = np.round(K_array[n][k] - 2*lmd,2) # уменьшаем коэффициенты на 1 шан
this_array[2] = E() # счиатем квадратическую ошибку с кожффициентами, уменьшеными на 1 шаг
min = np.argmin(this_array) # выбираем минимальное значение квадратических шошибок
#if n == 0 and k == 0: print(this_array, min)
if min == 0: K_array[n][k] = np.round(K_array[n][k] + lmd,2)
if min == 1: K_array[n][k] = np.round(K_array[n][k] + 2*lmd,2)
if min == 2: pass
if min == 0 : K_array_history[n][k] = K_array_history[n][k] + '0'
if min == 1 : K_array_history[n][k] = K_array_history[n][k] + '1'
if min == 2 : K_array_history[n][k] = K_array_history[n][k] + '2'
# Вносим K_array_history_last[n][k]. Это добавление по сравнения с Сокращеие №1
if min == 0 : K_array_history_last[n][k] = '0'
if min == 1 : K_array_history_last[n][k] = '1'
if min == 2 : K_array_history_last[n][k] = '2'
return this_array[min] 100 запусков показывают, что соотношение с предыдущей версией составляет 1,2.
mean_choice2: 0.7761234068870544
1.2003503329562035Сокращение №3.
И теперь понимаем, что даже если новая ошибка не меньше входящей, то ошибка для коэффициентов без изменений у нас уже есть как входящая, ошибка для одного из направлений у нас только что посчитана, и нам остается посчитать только оставшуюся ошибку для оставшегося направления, что еще сокращает количество вычислений по сравнению с предыдущей версией.
В итоге в большинстве случае мы считаем всего 1 ошибку и идем дальше, а если направление оказалось неправильным, то считаем всего еще 1 ошибку и идем дальше.
Код функции смены коэффициентов "Сокращение №3"
def choice3(): # функция изменения коэффициентоа
global repeat, norepeat
if not N_epochs: # здесь прошлого изменения еще нет, только начали
this_array = np.zeros(3) # создаем нулевой массив для трех вариантов квадратической ошибки
this_array[0] = last_E if N_epochs else E() # считаем или скачиваем квадратическую ошибка с текущими кожффициентами
K_array[n][k] = np.round(K_array[n][k] + lmd,2) # добавляем увеличиваем коффициенты на 1 шаг
this_array[1] = E() # считаем квадратическую ошибку с коэффициентами, увеличенными нв 1 шаг
K_array[n][k] = np.round(K_array[n][k] - 2*lmd,2) # уменьшаем коэффициенты на 1 шан
this_array[2] = E() # счиатем квадратическую ошибку с кожффициентами, уменьшеными на 1 шаг
min = np.argmin(this_array) # выбираем минимальное значение квадратических шошибок
#if n == 7 and k == 7: print(N_epochs,n,k,this_array, min)
#if test and test[1] and test[2]:
# if n == test[1] and k == test[2]: print(N_epochs,n,k,this_array, min)
if min == 0: K_array[n][k] = np.round(K_array[n][k] + lmd,2)
if min == 1: K_array[n][k] = np.round(K_array[n][k] + 2*lmd,2)
if min == 2: pass
if min == 0 : K_array_history[n][k] = K_array_history[n][k] + '0'
if min == 1 : K_array_history[n][k] = K_array_history[n][k] + '1'
if min == 2 : K_array_history[n][k] = K_array_history[n][k] + '2'
# Вносим K_array_history_last[n][k]. Это добавление по сравнения с Сокращеие №1
if min == 0 : K_array_history_last[n][k] = '0'
if min == 1 : K_array_history_last[n][k] = '1'
if min == 2 : K_array_history_last[n][k] = '2'
return this_array[min] # возвращает минимальное значение квадратической ошибки#
else:
this_array = np.zeros(3) # создаем нулевой массив для трех вариантов квадратической ошибки
#this_array[0] = last_E if N_epochs else E() # считаем или скачиваем квадратическую ошибка с текущими кожффициентами
# начинаем менять коэффициенты по прошлым изменениям
if K_array_history_last[n][k] == '0': pass
if K_array_history_last[n][k] == '1': K_array[n][k] = np.round(K_array[n][k] + lmd,2)
if K_array_history_last[n][k] == '2': K_array[n][k] = np.round(K_array[n][k] - lmd,2)
this_E = E()
# новое меньше вхолящего. все ок. идем дальше
if this_E < last_E: # если новое значение меньше, то идем дальше
#if n == 7 and k == 7: print(N_epochs,n,k,'идем также',last_E,this_E, 'this_E < last_E', K_array_history_last[n][k] )
#if test and test[1] and test[2]:
# if n == test[1] and k == test[2]: print(N_epochs,n,k,'идем также',last_E,this_E, 'this_E < last_E', K_array_history_last[n][k] )
K_array_history[n][k] = K_array_history[n][k] + K_array_history_last[n][k]
repeat = repeat + 1
return this_E # возвращает минимальное значение квадратической ошибки
# нкжно проверить противоподожное и выбрать меньшее
if this_E >= last_E: # если нет, то все возвращаем и пересчитываем
#if n == 7 and k == 7: print(N_epochs,n,k,'идем как-то по-другому',last_E_last,this_E)
#if test and test[1] and test[2]:
# if n == test[1] and k == test[2]: print(N_epochs,n,k,'идем как-то по-другому',last_E,this_E)
# при этом 2 ошибки уже посчитаны, осталась только 1
# вернули все обратно
if K_array_history_last[n][k] == '0': pass
if K_array_history_last[n][k] == '1': K_array[n][k] = np.round(K_array[n][k] - lmd,2)
if K_array_history_last[n][k] == '2': K_array[n][k] = np.round(K_array[n][k] + lmd,2)
this_array[0] = last_E # вместо вычислений берем уже сосчитанное знаяение ошибки значение ошибки
# Сокращение 3 - это коррекция отсюда
if K_array_history_last[n][k] != '0':
#if n == 7 and k == 7: print(N_epochs,n,k,'идем как-то по-другому',last_E,this_E, 'прошлое не 0')
#if test and test[1] and test[2]:
#if n == test[1] and k == test[2]: print(N_epochs,n,k,'идем как-то по-другому',last_E,this_E, 'прошлое не 0')
#if N_epochs == (test[0]-1) and n == test[1] and k == test[2]: print('здесь должен быть приежним | ', K_array_3[test[1]][test[2]])
if K_array_history_last[n][k] == '1':
this_array[1] = this_E
K_array[n][k] = K_array[n][k] = np.round(K_array[n][k] - lmd,2)
this_E_alt = E()
this_array[2] = this_E_alt
K_array[n][k] = K_array[n][k] = np.round(K_array[n][k] + lmd,2)
if K_array_history_last[n][k] == '2':
this_array[2] = this_E
K_array[n][k] = np.round(K_array[n][k] + lmd,2)
this_E_alt = E()
this_array[1] = this_E_alt
K_array[n][k] = K_array[n][k] = np.round(K_array[n][k] - lmd,2)
if K_array_history_last[n][k] == '0':
#if n == 7 and k == 7: print(N_epochs,n,k,'идем как-то по-другому',last_E,this_E, 'прошлое 0')
#if test and test[1] and test[2]:
#if n == test[1] and k == test[2]: print(N_epochs,n,k,'идем как-то по-другому',last_E,this_E, 'прошлое 0')
K_array[n][k] = np.round(K_array[n][k] + lmd,2) # добавляем увеличиваем коффициенты на 1 шаг
this_array[1] = E() # считаем квадратическую ошибку с коэффициентами, увеличенными нв 1 шаг
K_array[n][k] = np.round(K_array[n][k] - 2*lmd,2) # уменьшаем коэффициенты на 1 шаг
this_array[2] = E() # счиатем квадратическую ошибку с кожффициентами, уменьшеными на 1 шаг
K_array[n][k] = np.round(K_array[n][k] + lmd,2)
min = np.argmin(this_array) # выбираем минимальное значение квадратических шошибок
#if n == 7 and k == 7: print(N_epochs,n,k,this_array, min)
#if test and test[1] and test[2]:
#if n == test[1] and k == test[2]: print(N_epochs,n,k,this_array, min)
# вот здесь при не равно 0 вытаскивается лишний шаг, так как он тянет из минуса
#if min == 0: K_array[n][k] = np.round(K_array[n][k] + lmd,2)
#if min == 1: K_array[n][k] = np.round(K_array[n][k] + 2*lmd,2)
#if min == 2: pass
# вот так работает при том, что чуть выше добавлена строка на возврат к предыдущему значению
if min == 0: pass
if min == 1: K_array[n][k] = np.round(K_array[n][k] + lmd,2)
if min == 2: K_array[n][k] = np.round(K_array[n][k] - lmd,2)
if K_array_history[n][k]:
if str(K_array_history[n][k])[-1] == str(min): repeat = repeat + 1
else: norepeat = norepeat + 1
if min == 0 : K_array_history[n][k] = K_array_history[n][k] + '0'
if min == 1 : K_array_history[n][k] = K_array_history[n][k] + '1'
if min == 2 : K_array_history[n][k] = K_array_history[n][k] + '2'
# Вносим K_array_history_last[n][k]. Это добавление по сравнения с Сокращеие №1
if min == 0 : K_array_history_last[n][k] = '0'
if min == 1 : K_array_history_last[n][k] = '1'
if min == 2 : K_array_history_last[n][k] = '2'
#if n == 7 and k == 7: print('возвращаем:', this_array[min])
#if test and test[1] and test[2]:
#if n == test[1] and k == test[2]: print('возвращаем:', this_array[min])
return this_array[min] 100 запусков показывают, что ускорились в 1,05.
mean_choice3: 0.7382487916946411
1.0513033216152954Итог
В итоге 1.326184549331665 секунд превратились в 0.7382487916946411 секунд
Коэффициент 1.8.
В данном примере это 0,59 секунды, а при больших датасетах разница может составить уже часы и даже дни.

Предыдущие статьи:
Синаптические веса в нейронных сетях – просто и доступно. Часть 1.
Синаптические веса в нейронных сетях – просто и доступно. Часть 2.
Автоматический подбор синаптических весов. Самое начало. Циклический перебор
В следующих статьях предполагается протестировать простой полный последовательный циклический перебор с представленными вариантами на каком-либо публично известном датасете.

ErnestMazurin
Судя по формулам, робот с картинки учится с 7-м классе =)