В первой части было сделано несколько запусков обучения с различными количествами нейронов в скрытом слое и различными размерами батчей. Запускали 128-256-512-1024 нейронов в скрытом слое с размером батча 16-32-64-128, а также различные значения Dropout.
Сравниваем уменьшение шага
По первой части был ясно, что увеличение количества нейронов в 2 раза не дает существенной разницы в точности, поэтому увеличиваем сразу в 4 раза.
Количество нейронов 128-512-2048-8192.
Батч 128.
Уменьшаем в 2 раза, если 3 эпохи не будет улучшения
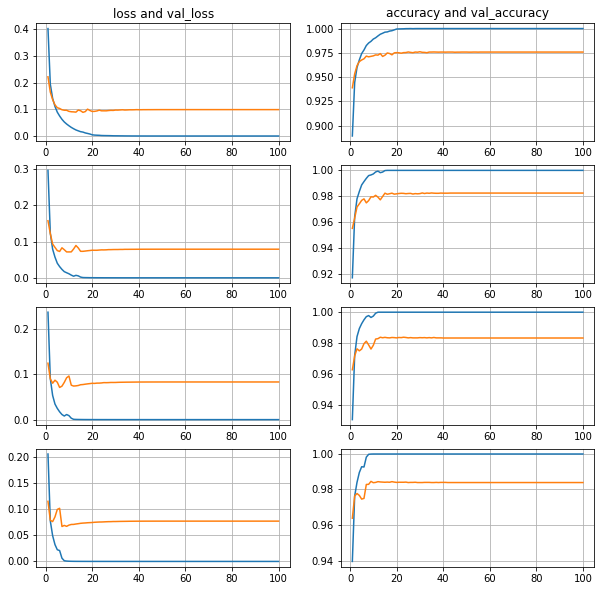


Видно, что чем больше нейронов в скрытом слое, тем ошибка валидационной выборки меньше, а точность валидационной выборки больше, и во всех случаях примерно к 40 эпохам все стабилизируется.
Уменьшаем в 2 раза, если 10 эпох не будет улучшения



Видно, что ошибку валидационной выборки сильно разносит по мере увеличения количества нейронов скрытого слоя. Примерно к 40 эпохам точность также стабилизируется, хотя ошибка продолжает расти. То есть явное переобучение, нужно выбирать момент для остановки или сохранять лучший результат .
Интересно, что при уменьшении шага через 3 эпохи, а не через 10, мы не видим такого разноса и роста ошибки, то есть к этому моменту шаг уже стал настолько маленький, что движение происходило вокруг найденного к тому моменту локального минимума и уже никуда не скакало.
Конечные результаты схожи: чем больше нейронов в скрытом слое, тем точность валидационной выборки больше, и во всех случаях примерно к 40 эпохам стабилизируется.
Dropout
Помимо выбора момента остановки и сохранения лучшего результата, пробуем уменьшать переобучение засчет Dropout.
100 эпох, 1024 нейрона, batch128, без уменьшения шага
Dropout 0.1-0.2-0.3-0.4-0.5



Видно, что ошибка катастрофически резко летит вверх, то есть пока переобучение не уменьшили.
100 эпох, 1024 нейрона, batch512, без уменьшения шага
Dropout 0.1-0.2-0.3-0.4-0.5



Ожидаемо, увеличение размера батча улучшило стабильность ситуации, ошибка взлетает не так резко, хотя точность примерно в том же интервале.