У технологии eBPF много поклонников. Она предлагает множество плюсов, но в работе с ней есть и некоторые минусы, сложности и ограничения. Давайте разберемся со всем этим.
Данный материал подготовлен на базе выступления “eBPF в production-условиях” от Дмитрия Евдокимова и Александра Трухина из компании Luntry с конференции HighLoad++ 2022. Он будет полезен как компаниям, что используют внутри себя решения на базе eBPF, так и разработчикам, которые что-то пишут или планируют писать с использованием данной технологии.

Технология eBPF в Luntry
В Luntry мы используем технологию eBPF и уже повидали достаточно много различных окружений клиентов, облачных провайдеров с их managed Kubernetes, а также используемых у них версий ядер. eBPF – очень крутая технология! В процессе прочтения вам может показаться, что мы ее критикуем, заостряем внимание на недостатках и вообще ее лучше не использовать. Но это совсем не так!
Обычно все хвалят эту технологию, говорят о ее преимуществах, из-за чего может сложиться впечатление, что она идеальна. Информации же по сложностям, недостаткам и текущим ограничениям данной технологии очень мало. В принципе, и компаний, которые сейчас делают реальные продукты на базе eBPF, еще мало. Поэтому нам бы хотелось поделиться своим опытом.
Краткое интро в eBPF
eBPF – это технология, которая позволяет запускать произвольный код пользователя в рамках ядра.
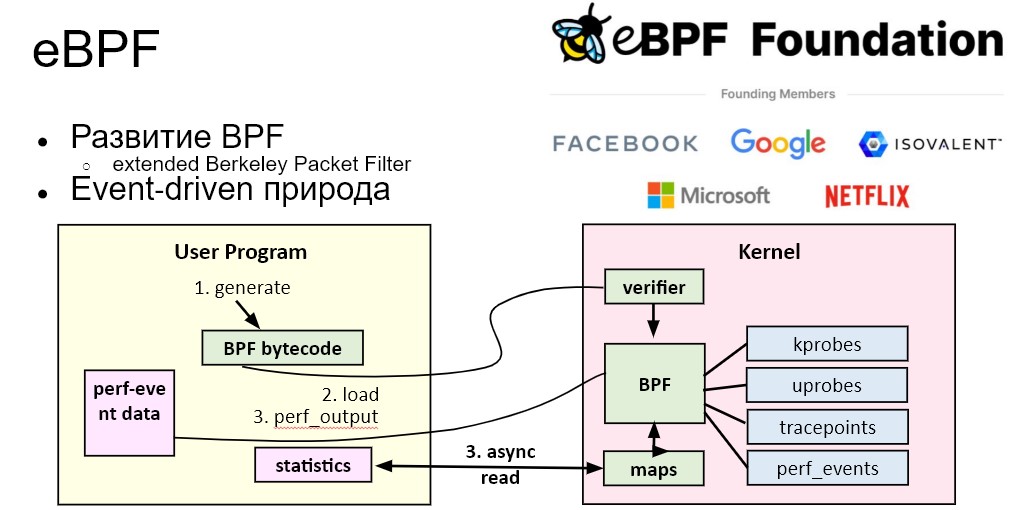
Благодаря ей можно сделать программируемое ядро операционной системы и быстро добавлять туда собственную логику и менять существующую. Раньше (сейчас это, впрочем, тоже работает) это можно было делать с помощью модулей ядра, однако сам процесс был сложен, влек за собой ряд рисков и требовал приличных усилий со стороны разработчиков.
eBPF расшифровывается как «extended Berkeley Packet Filter». Packet Filter — это лишь одна из его возможностей. Фактически технология умеет гораздо больше, но исторически развивалась она именно с фильтрации пакетов. Сегодня это настоящая event-driven система, которая начинает работать при наступлении определенных событий: когда приходит пакет, происходит какой-то системный вызов или что-то ещё. В остальное время она не работает и лишь ждет наступления того или иного события.
Сейчас eBPF активно развивается, за ним стоит уже большое сообщество. Чем он отличается от модулей ядра?

На модулях ядра можно сделать всё – даже больше, чем на eBPF. Но у них есть проблемы, которые не устраивают operation- и инфраструктурные команды. Например, у нас в Luntry было две версии/реализации – в виде модуля ядра и eBPF-программы. Когда мы это говорили инфраструктурным командам, ни одна не согласилась запустить наш модуль ядра. Потому что, если в нём закралась ошибка, падает вся нода/сервер/вм и все контейнеры, которые там были. А в случае с eBPF-программой такого быть не может, и максимум завершится только данная программа, а остальная часть системы продолжит работать и дальше.
Развитие eBPF
Окунемся немного в историю – это важно для понимания развития eBPF. Сама технология появилась в 2013 году, но стала особенно популярной в последние 4-5 лет. eBPF постоянно развивается и улучшается с каждой версией ядра – это очень важный момент. В рамках данного материала мы сосредоточимся на операционной системе Linux, хотя eBPF уже начала проникать и в другие ОС. Так в 2021-м году она появилась в ОС Windows.
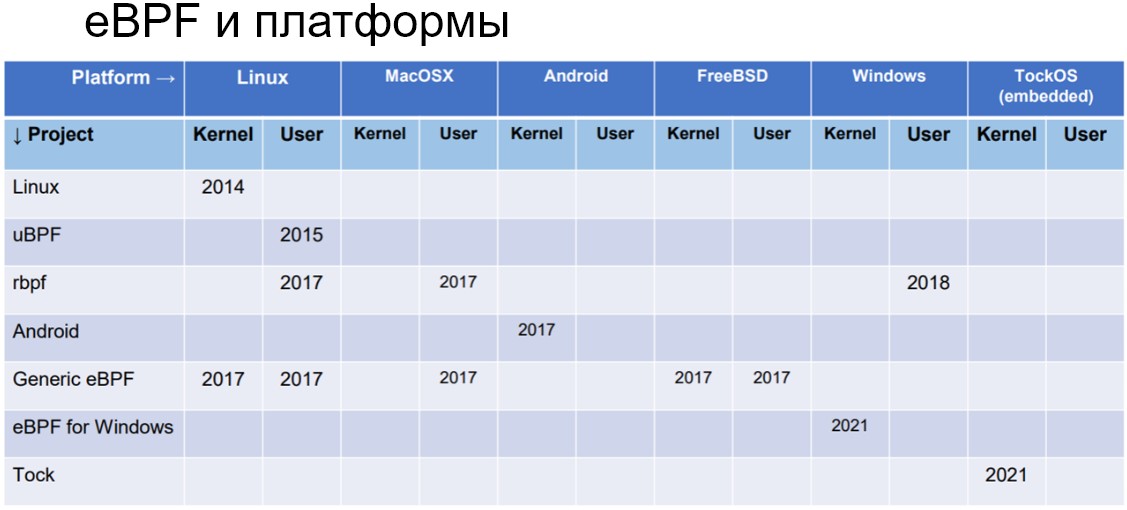
ОС Linux — родная система для eBPF. Поддержка в других операционных системах неравнозначная, то же самое и с архитектурами процессоров. Наибольшая поддержка сейчас есть у x86_64. То есть то, что можно делать в Linux на x86_64, далеко не обязательно можно делать в Windows на этой же архитектуре или на Linux на ARM.

Так, есть много поддерживаемых архитектур, но стоит внимательно смотреть, в какой версии ядра поддержка какой появилось и вообще что там можно делать.

И, естественно, чем новее ядро будет использовано, тем больше вы получите преимуществ от использования eBPF ;)
Возможности eBPF
Где вообще можно встретить использование eBPF-технологии? Как правило, в сетевых решениях, решениях, связанных с observability и security. Технология хорошо зарекомендовала себя там, где требуется глубокая, эффективная инспекция и контроль происходящего в системе.
-
Networking: Load Balancing, Kubernetes Networking, Service Mesh
-
Observability: Any metrics, logs, traces, continuous profiling,…
Pixie - observability решение для Kubernetes
Parca - continuous profiling решение
SysinternalsEBPF - Linux порт легендарного Sysmon
-
Security: Network/Runtime/Data security
Inspektor Gadget- набор программ для отладки и интроспекции Kubernetes applications
На самом деле, логику на eBPF помогают реализовать тот или иной ее тип программы. Для последних версий ядер их уже около 50, и они все еще появляются:
Смотреть bpf_prog_type/bpf_attach_type в bpf.h
Разные задачи
От узкоспециализированных до универсальных

Программы образно можно поделить на три категории: сетевые, observability и security. Образно, потому что те же задачи, связанные с сетью в зависимости от задачи, можно решать и с помощью тех же tracepoints.
С eBPF возможно дотянуться до любой части как файловой, так и сетевой подсистемы и решать с помощью этих программ (еще их можно представить как точки внедрения) те или иные задачи. Так, например, у нас в Luntry мы не используем такие типы программ, как TC (traffic control) и XDP, которые работают с сетевыми пакетами, а задачи с сетью решаем на уровне raw_tracepoints. А тот же CNI Cilium наоборот все делает с использованием первых двух.
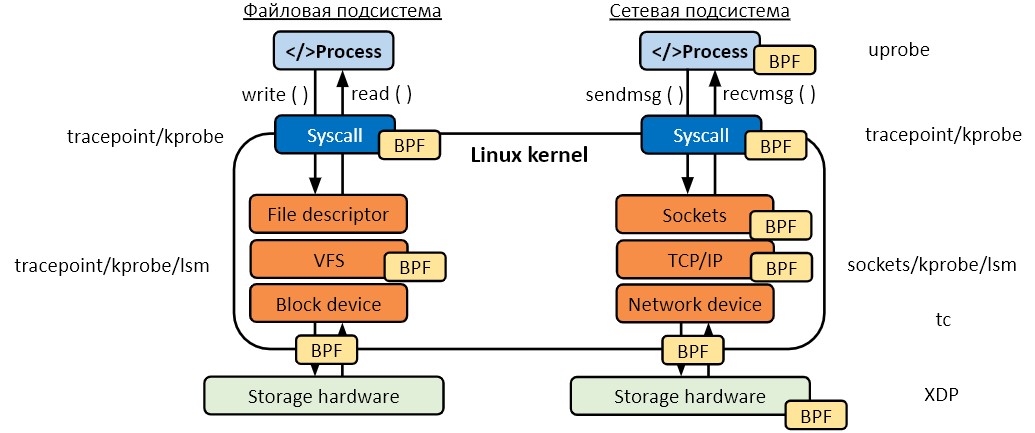
При этом мы способны строить сетевую карту взаимодействия, собирая информацию о системных вызовах, не влезая в сам трафик и не завися от его объема.
Таким образом, eBPF предоставляет разработчикам огромное поле возможностей. Есть такой устоявшийся миф, что eBPF предназначен только для сетевых задач. Нет с ним можно делать много и за пределами работы с сетью.
Компании с большими нагрузками, активно используют различные системы контейнеризации, оркестраторы типа Kubernetes и так далее. Тут возникает вопрос, а как у eBPF с контейнерами? Сразу скажем, что технология отлично дружит со всеми нативными подсистемами Linux ядра.
eBPF и containers/sandbox/VM/microVM
-
При работе с классическими контейнерами можно определить контекст
runc
-
При работе с sandbox/VM/microVM нельзя определить контекст
Wasmer Runtime и подобные
Sandbox gVisor
Kata Runtime
MicroVM Fargate
[Fargate] [request]: Provide the ability to use ebpf on fargate instances. #1027
Классические контейнеры построены на базе cgroups, namespaces. eBPF прекрасно видит и понимает их контекст. Технология может сказать, какой процесс работает в каком контейнере, какой трафик туда ходит или какие события внутри происходят. Что касается различных sandbox, micro VМ и просто VМ, то технология, запущенная на хосте, не понимает (не видит) происходящее в них. Потому что эти сущности работают под своими отдельными ядрами, а не на хостовом ядре. И она не понимает контекст ...
В том же micro VM в Fargate в реквестах есть запрос, чтобы сделали поддержку eBPF. Так, в рамках этой micro VM можно было бы запускать и eBPF-программу (на ее гостевом ядре). Тогда можно будет понять, что там происходит. Иначе — нет.

При этом, к сожалению, стоит учитывать, что у eBPF очень плохая документация. Большинство информации приходится получать из исходников ядра, рассылок, каких-то уже готовых примеров больших решений. Все это делает разработку на базе данной технологии не такой простой как хотелось бы.
Разработка с eBPF
Начнём с того, что любое eBPF-решение состоит из двух частей: пользовательской и ядерной. eBPF-код выполняется в контексте ядра, поэтому он составляет ядерную часть.
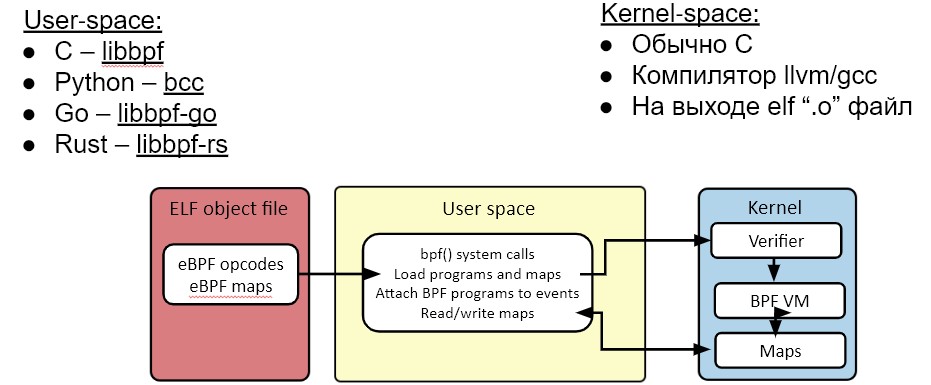
Что же включается в пользовательскую часть? Нам нужно загрузить eBPF код в ядро и осуществлять взаимодействие между пользовательской и ядерной частями для какой-нибудь динамической смены настроек или для передачи из ядерной части события в пользовательскую, для их последующей обработки.
Обычно для загрузки eBPF кода в ядро используется специальная библиотека. Сделать это вручную можно, но это непросто и требует множества мелких низкоуровневых операций. Кроме загрузки, еще нужно провести релокацию кода, загрузить настройки, инициализировать кучу вспомогательных структур. Не стоит это делать вручную, общаясь с ядром через системные вызовы, лучше использовать специальную библиотеку. Например, libbpf. Она разрабатывается синхронно с ядром и содержится в том же репозитории.
Вернемся к ядерной части, её обычно пишут на С. Ядерная часть – это eBPF код, сам код ядра тоже написан на С. Так, можно легко перенести готовые конструкции и структуры из ядерной практики в eBPF. Обычно для компиляции используется LLVM. Как это выглядит у нас? Сначала наш С код с помощью Clang превращается в промежуточное представление LLVM, а дальше с помощью eBPF-бэкенда промежуточное представление уже превращается в eBPF байт-код, который непосредственно можно загружать в ядро.
Используют и другие языки программирования, не С. Если есть соответствующий фронтэнд для LLVM, можно разрабатывать на С++, на Rust. Вариантов может быть много, даже Fortran или Delphi.
Особенностей в userspace нет, там можно использовать практически любой язык программирования, какой больше нравится. Но самые популярные — С++ и Go, на них сделано много крупных проектов. Мы в своей практике пришли к использованию Rust.
Ограничения
Вернёмся к ядерной части eBPF-кода. Для данной части есть целый список ограничений.

Не будем подробно на всём этом останавливаться. Так, например, возьмём невозможность использования циклов. В итоге, при обработке структуры связанных списков или деревьев возникают трудности. Или еще можно обрабатывать структуры только фиксированного размера.
Такие ограничения есть у eBPF из-за его заявленных особенностей. Технология выполняется за конечное время, и код не может где-то зависнуть в ядре или в циклах. Также eBPF код ограниченным образом может влиять на систему. На пример, он не может переписать произвольную память в ядре по какому-нибудь указателю.
Кем осуществляются эти ограничения? При загрузке срабатывает verifier. Он проверяет на корректность eBPF-программу, а также её соответствие всем требованиям. Можно долго писать код, он скомпилируется, будет показано, что всё нормально, но при загрузке возникнут проблемы. Он не загрузится, и ядро выдаст какую-то ошибку. Из этой ошибки не всегда понятно, в чем дело и какое из этих ограничений было нарушено.
Бороться с этим довольно сложно, но можно найти общий язык с verifier.

Про портируемость
К сожалению, с портируемостью не все так гладко. Рассмотрим две проблемы, которые возникали у нас. Они довольно распространённые. Первая — нестабильность ядерных интерфейсов.

Сам eBPF-код прекрасно портируем, проблема возникает, только когда вы работаете со структурами или объектами ядра. Вот пример произвольной структуры. Вас интересует определенное поле, но в новой версии ядра, допустим, эта структура была расширена. В неё добавилось новое поле. То, что конкретно интересует, сместилось и будет доступно по другому offset’у. Это важно при компиляции, потому что компилятор должен знать, к чему обращаться, то есть какой offset у этого поля.
Как решить эту проблему? Развитие ее решения такое:
Cтабильные интерфейсы
-
Использование Kernel headers
CONFIG_IKHEADERS
Отгадывание offsets
-
BTF и CO-RE
Бывают проблемы с нестабильностью интерфейса. Например, вы привязываетесь к каким-то функциям в ядре и функциональности, доступным в определённой версии. Уже в новых версиях они могут видоизмениться или вообще отсутствовать. Тут нет одного решения. Нужно с каждой ситуацией разбираться отдельно, искать альтернативные варианты, в общем должен быть план Б.
Что касается проблем с нестабильностью структур и обращения по полям, поговорим про различные решения. Всё это уже много обсуждается сообществом, мы тут не открываем Америку. Первое — это стабильный интерфейс.
Это не результат, а просто любопытный момент. Например, для сетевого решения не обязательно обращаться к структурам ядра. Там будут только стабильные интерфейсы. Большая часть кода Cilium так устроена – там нет работы с внутренними структурами ядра.
Дальше наиболее надежный метод, который всегда работает, это заголовки ядра.
Linux headers
-
Собирать при запуске
Нужен компилятор (llvm/gcc) на целевой системе
-
Нужны заголовки ядра на целевой системе
обычно доступны по пути (из системного пакета): /lib/modules/$(uname -r)/build/
при наличии опции CONFIG_IKHEADERS: /sys/kernel/kheaders.tar.xz
-
могут быть доступны для загрузки из сети
известная система (например, Google COS)
Предсобранный вариант
С ними знакомы те, кто собирал драйвер для видеокарты под какой-нибудь дистрибутив. Заголовки ядра используются для сборки модулей и подходят для eBPF-программ. Их доставляют на целевую систему различными способами. Используя их, нужно каждый раз для каждой системы, дистрибутива, версии ядра, отдельно собирать eBPF-программу. Можно делать это при запуске или заранее, то есть иметь предсобранные варианты программ.
Есть ещё один эзотерический метод. Он используется, например, в порте известного Windows инструмента Sysmon на Linux от Sysinternals. Мы назвали его условно «отгадывание офсетов».
Тут с помощью каких-то эвристик определяются эмпирическим методом offset-полей. Метод не очень надёжный и далеко не всегда применим, но просто любопытный.
Альтернативой заголовкам ядра является концепция Compile Once – Run Everywhere.
CO-RE (BTF)
Концепция CO-RE: Compile Once – Run Everywhere
На 90% состоит из BTF: BPF Type Format
Проблема разных оффсетов полей структур решается на этапе загрузки с помощью релокаций
-
BTF встроено в ядро с 5.2
CONFIG_DEBUG_INFO_BTF=y
bpftool btf dump file /sys/kernel/btf/vmlinux format c
Она сводится к BTF — формату данных. Он напоминает формат для отладочных символов, как DWARF, но гораздо компактнее.
Как он упрощает задачу сборки? На этапе компиляции компилятор генерирует таблицу релокации для вашего кода. При загрузке eBPF смотрит на таблицу и релоцирует код так, чтобы он смог запуститься на конкретной системе, то есть Compile Once – Run Everywhere. Основная проблема здесь — доступность этой информации BTF-данных.
В определенных версиях ядра BTF-информация может содержаться в самом ядре, т.е. быть туда встроенной, и её оттуда можно легко забрать. На слайде ниже можно наблюдать, как выглядит процесс при использовании заголовков ядра и BTF. Без и с CO-RE
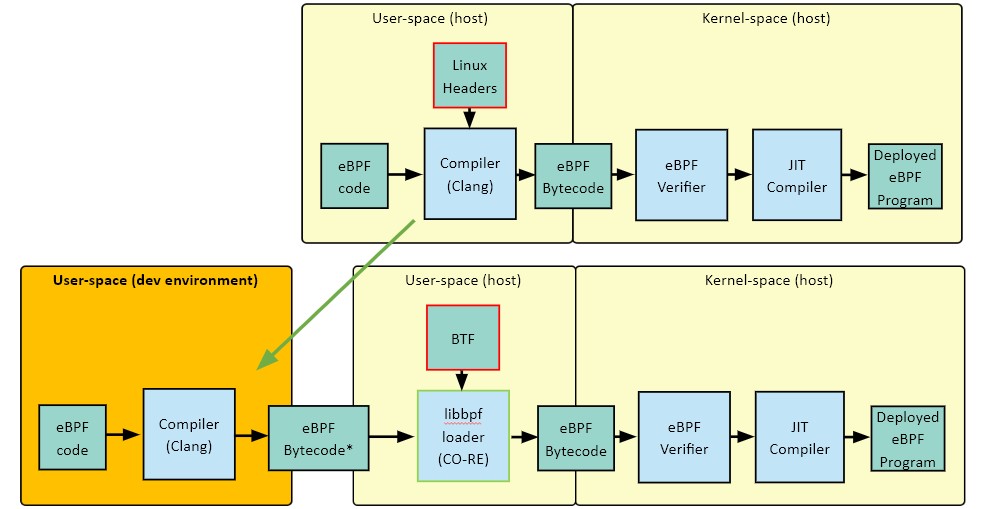
Разница тут в том, что в левой части сверху у нас сборка проходит при запуске, на целевой машине. При использовании BTF она происходит на машине разработчика, то есть один раз. Если в ядре выключена опция или же оно старое и BTF недоступен, то в таком случае можно обратиться к проекту BTFHub. В нем содержится BTF-информация для большого количества ядер.

Проект активно развивается, пополняется новыми ядрами, его можно реально применять.
Мы тут много говорим про разные версии ядер, и что в одной что-то работает, а что-то нет. В реальности никто не запускает ничего на голых ядрах. И мы имеем дело с дистрибутивами и облачными решениями.
Облачные провайдеры стараются быть более eBPF дружелюбными
-
Появляются Cloud/Kubernetes-oriented OS с целенаправленной поддержкой eBPF
Пример: Flatcar Container Linux
-
RHEL
Много чего бэкпортят на старые ядра
Мы запускали решение у многих облачных провайдеров: Яндекс, Мейл.ру, Амазон, Гугл. Везде мы это делали достаточно успешно. Иногда требовалась некоторая дополнительная работа, но в целом у них у всех с этим сегодня уже всё нормально.
Вторая проблема — прохождение kernel verifier.

Kernel verifier может выдавать false positive. Это значит, что ваш код реально соответствует каким-то требованиям, но тем не менее не проходит проверку. Например, реально не происходит разыменование нулевых указателей, потому что вы где-то в коде всё это проверяете. Но, verifier основан на эвристиках, поэтому он может не принять данный нормальный код.
И, к сожалению, логика verifier меняется от одной версии ядра к другой, поэтому могут возникать проблемы. Ещё они усугубляются тем, что при обновлении компилятора (на разных версиях разные оптимизации), они могут вмешиваться в этот процесс и создавать дополнительные сложности.
Эта проблема не решается при помощи заголовков ядра или BTF. Это параллельная тема. Нужно каждый случай решать отдельно, добавлять свои safe guards в код при необходимости и тестировать всё на всех ядрах.

Производительность
Производительность для eBPF-кода – это довольно сложная штука. У вас две компоненты: пользовательский код и eBPF ядерный код. Для первого всё более-менее понятно. Для ядерной же части нагрузка распределяется по системе. То есть eBPF-программа работает в контексте ядра и всех приложений.
-
Оверхед грубо складывается из:
Работа eBPF-программ (kernel space)
Обработка данных (user space)
-
eBPF – event-driven
Производительность сильно зависит от нагрузки, количества событий
Оверхед точек входа (https://lwn.net/Articles/748352/):

Код может срабатывать в контексте всех приложений, которые запущены на системе. Нагрузка бывает разная, в зависимости от решения. Если это сетевое решение, то ситуация относительно простая. Можно замерять как вы справляетесь с ddos-атаками, дропая пакеты и классифицируя их в eBPF-коде. Это замеряется на уровне количества обработанных пакетов или задержки какой-то обработки.
С observability-решениями всё значительно сложнее, так как вы не знаете, какая будет нагрузка. Тут могут быть сюрпризы. В нашей практике был такой. Мы добавляли поддержку системы OpenShift и наблюдали, что в контексте системного контейнера периодически запускалось lsof.
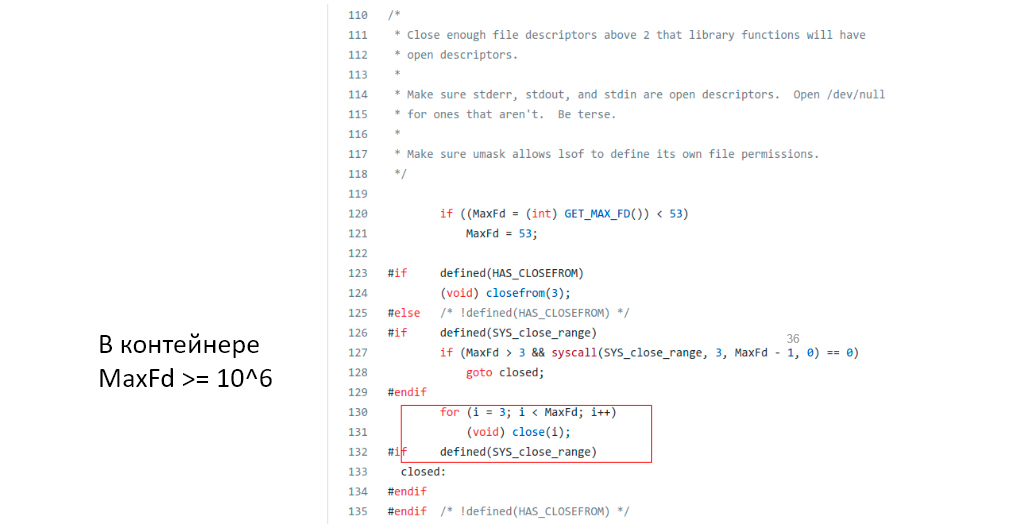
Она позволяет определить, какие процессы использует тот или иной файл в системе. Это довольно старый код. Мы не знаем почему было выбрано такое решение, но перед каждым запуском lsof он пытается закрыть сколько-то файловых дескрипторов. Максимальное их количество. Если раньше их было около 1 000, то в контейнерах используются повышенные лимиты, то есть от миллиона и выше.
Получается, что этот lsof при запуске генерирует нагрузку – где-то миллион сисколов. Причём запускается он с достаточно большой периодичностью на многих Kubernetes Nodes, если мы говорим про какой-то кластер. В нашем случае это вызывало большую нагрузку, потому что у нас была нетривиальная обработка файловых дескрипторов. Впоследствии мы от неё отказались. Можно даже не знать и не представлять, где у вас возникнут проблемы с производительностью.
Когда мы с кем-то работаем, у нас часто спрашивают про производительность. Она сильно зависит от того, что и на чём запускать.

Про безопасность
Тема безопасности eBPF очень актуальная. Раскроем её, чтобы стало понятно, может ли она навредить вашей системе или дать преимущества при использовании данных технологий в вопросах безопасности.
Во-первых, разделим всю эту безопасность на два раздела, а именно safety и security.
Safety — надёжность. Обеспечивается verifier и определёнными ограничениями, которые накладываются на eBPF-код (рассматривали выше). Благодаря Safety свойству eBPF она не сломает систему. Operation-команды любят ее за то, что он не способен в какой-то момент затушить всю Node, машину, виртуалку, в отличие от того же модуля ядра.
Второй аспект — безопасность самой технологии, которая зависит от качества кода и архитектуры. C версией ядра 5.7 появился тип программы eBPF LSM. Решения типа AppArmor, SELinux выполнены как модуль ядра и как раз базируются на хуках Linux Security Modules и в определённых моментах смотрят, разрешена та или иная операция или нет.
Только с версией 5.7 eBPF позволяет запрещать тот или иной системный вызов. До этой версии этого сделать нельзя, то есть можно реализовать только detection подход. С версией 5.7, используя BPF LSM, можно уже реализовывать prevention-подход.
Этот патч в ядро сделала команда Google. На этом типе программы BPF LSM они делают свой HIPS – host intrusion prevention system. Так они на каждой машине, в инфраструктуре, могут гибко подгружать и динамически менять эти политики. Например, они могут раскатать eBPF-программу, которая запретит запуск всех bash или запуск какой-то версии java. Если там будут системные вызовы, которые они порождают, это будет запрещено. До версии 5.7 никаких запретов eBPF делать не может.
Что касается безопасности самой технологии eBPF, здесь, как и в любом коде, содержатся уязвимости.

Данные уязвимости можно использовать для повышения привилегий (privilege escalation). В контейнерных средах эти уязвимости подойдут для побега из контейнеров. То же самое можно делать и через модуль ядра. Здесь особых отличий нет.
Что касается использования eBPF во вредоносных целях, здесь есть преимущества, связанные с портированием, надёжностью и так далее по сравнению с модулями ядра.
-
Исследования:
-
Проекты:
-
Вредоносный код ITW:
The Bvp47 - Backdoor от US NSA Equation Group
BPFDoor- passive network implant для Linux

На это смотрят security-исследователи и различные злоумышленники. Они могут писать backdoors, rootkits для Linux, которые на текущий момент не так-то и распространены из-за этих проблем.
Здесь eBPF открывает новые возможности как раз благодаря своим свойствам. Уже несколько лет исследователи смотрят на то, как с eBPF удобно делать различные атакующие вещи.
Как можно улучшить ситуацию? C версии 5.8 появилась отдельная capability для работы с eBPF-программами.

До версии 5.8 необходима чрезвычайно мощная capability под названием CAP_SYS_ADMIN, которая по сути сродни root. Правда для большинства логики и программ, всё равно понадобится CAP_SYS_ADMIN и работа под root. Любые решения, которые есть сегодня на базе eBPF, будут требовать root и работать под ним. Нужны очень широкие привилегии, полномочия.
Чтобы ответить вредоносному коду, для модулей ядра есть возможность их подписывать и при загрузке проверять, доверяем мы этому модулю ядро или нет.
-
Сообщество обсуждает возможность подписи eBPF программ
Статья “Toward signed BPF programs”
Сложность из-за структуры программы и JIT компиляции
Требует перенос user-space BPF loader в kernel или специального формата файла или специализированный loader.
Для eBPF-программ нет возможности их подписи ввиду специфики байт-кода, JIT-компиляции. Но сообщество в это направление активно смотрит. Возможно, когда-то это появится. Но сейчас любой пользователь с возможностью загрузки eBPF-программ сможет загрузить туда что угодно (даже с вредоносной функциональностью).
Если вы не заточены и eBPF вам не нужен, вы видите от него только вред вашей системе, то можете его полностью отключить. При сборке ядра достаточно отключить соответствующий флаг, и он будет полностью исключать возможность поддержки eBPF. Но это так себе решение.
Что мы имеем в итоге? Нужно следовать принципу наименьших привилегий, чтобы с eBPF-кодом у вас могли работать только те, кто должен, и никто более. Следует контролировать, что eBPF-код делает.

Есть некоторые статистические анализаторы, которые при подаче исполняемых файлов с eBPF кодом могут сказать, какие eBPF программы, maps они используют. Может сложиться впечатление, на что завязана та или иная eBPF программа. Но, к сожалению, с подписью сейчас дела обстоят никак, и когда она появится, неизвестно.
Таким образом, eBPF — определённо очень крутая технология. С каждым днём в том же CNCF Cloudnet Foundation появляется всё больше проектов, базирующихся на этой технологии.
Выводы

Но само её использование ещё не настолько идеальное. Есть много сложностей, проблем, которые обычно решаются желанием поставить более свежее ядро. Но на практике есть клиенты на RHEL7 с ядром 3.10. Хорошо, что хоть что-то бэкпортнули на 3.10, но у нас, например сейчас, разрыв клиентов в поддержке от 3.10 до 5.10, и это накладывает море ограничений.
Компании не так быстро обновляются. Не получается гибко использовать более новые версии ядер, где меньше ограничений и больше возможностей. Иногда очень везёт, если клиент живёт где-нибудь в облачном провайдере, и он следит за активным обновлением ядер, вот тогда хорошо. Там можно использовать какие-нибудь передовые для этого подходы.
Что вы будете использовать, варьируется от задачи к задаче. Нужно ориентироваться в этом всём. Честно скажем, в рамках этого материала мы не смогли раскрыть все тонкости, нюансы и проблемы, с которыми вы можете встретиться при использовании, разработки eBPF-программ. Есть и проблемы, связанные с так называемым TOCTOU (Time-of-check to time-of-use), с различными page faults и так далее.
Окунувшись в удивительный мир eBPF, можно много чего открыть для себя. Мы подсветили основные моменты, с которыми вы 100% встретитесь.
В материале использованы и сторонние работы. Рекомендую почитать тем, кто только начинает в эту сферу погружаться.