Как идеально не строй цикл разработки и поиска уязвимостей, все равно будут существовать кейсы, которые приводят к security-инцидентам. Поэтому давайте соединим два ингредиента: control loop (reconciliation loop) и полную декларативную возможность Kubernetes и посмотрим, как автоматизировано реагировать на те или иные угрозы, риски, инциденты, которые происходят в Kubernetes-кластере.
Сразу предостерегаю, что после прочтения не надо бежать и воплощать то, о чем я расскажу. Всё это некоторый high level. У вас должны быть соответствующие выстроенные процессы и уровень информационной безопасности. Без базового контроля и базовых мер реализовывать SOAR очень опасно. Это может только навредить. Поэтому нужно адекватно оценивать уровень зрелости процессов и информационной безопасности в вашей компании.
Меня зовут Дмитрий Евдокимов. Я основатель и технический директор Luntry. Мы делаем security observability решение для Kubernetes и делимся опытом в данной области.

Эта статья по 3 докладу в серии. Для полного представления о концепции, полезно познакомиться с первыми двумя:
часть (DevOpsConf 2021) «Kubernetes: трансформация к SecDevSecOpsSec» про возможности Kubernetes, его control loop (reconciliation loop) и то, как он помогает улучшить безопасность на всех жизненных стадиях приложения.
часть (VK Kubernetes Conference 2021) Kubernetes Resource Model (KRM): Everything‑as‑Code о том, что всё происходящее в Kubernetes, можно выразить через тот или иной yaml.
Это 3 — заключительная часть. В ней мы совместим первые две, чтобы автоматизировано реагировать на угрозы, риски и инциденты.
Введение в Security Orchestration Automation and Response
SOAR — это специальный класс решений в информационной безопасности. В обычных сетях это выглядит так:
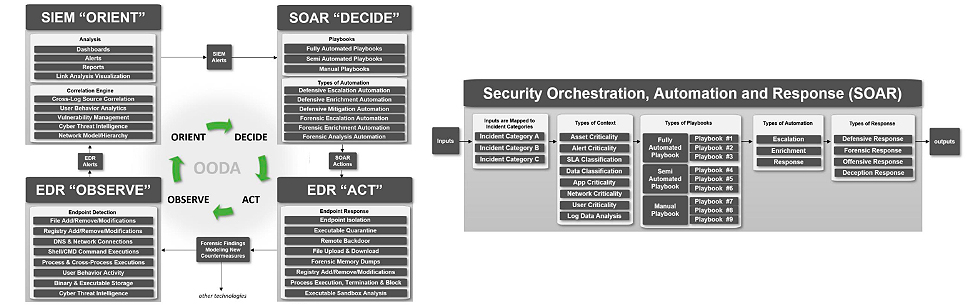
Упрощённо это выглядит следующим образом. На сервер, либо на машину пользователя ставится агент (EDR). Он собирает информацию и отправляет в SIEM. Там информация обогащается и создается контекст. В SIEM могут попадать данных с других средств защиты (межсетевых экранов, антивирусов, DLP-систем), все это аккумулируется, и позволяет прийти к выводу/обнаружению. Это приводит к генерации того или иного предупреждения (alert), который передается на SOAR решение. Оно состоит из разных playbook’ов, описывающих стандартные шаги: как и что должно быть сделано в каждом конкретном случае. Дальше принимается решение, что именно нужно сделать и передается на агент (тот же или совершенно другой, что упоминался в начале) и тот в свою очередь выполняет то или иное действие (изоляция машины, удаление файла и т.д.). Все происходит автоматически, чтобы человек занимался более интеллектуальной деятельностью, а рутинной повторяющейся деятельностью.
При этом в энтерпрайзе для обычных Windows и Linux сетей SOAR решения чрезвычайно дорогие. Часто компании, рассматривая коммерческие версии, приходят к выводу, что проще написать собственное решение. Тем более, что при составлении playbook нужно учитывать свою специфику. При этом SOAR — не какая-то мифическая штука. У DOD (Department of Defense, Министерство безопасности США), есть ряд публичных документов, в которых для организации Zero Trust архитектуры упоминаются SOAR решения. На схеме представлен один из них.

Обратите внимание, что есть SOAR, и есть так называемые Policy Enforcement Points — это то, где применяются решения SOAR о блокировке, изоляции, запрете и тому подобных вещах.
Упоминание о SOAR в Kubernetes уже также можно встретить в документе Kubernetes DevSecOps Reference Design:

Kubernetes Policy Management
Давайте для начала посмотрим, как индустрия и CNCF сообщество подходит к этому вопросу. Достаточно недавно был выпущен документ «Kubernetes Policy Management».

Он описывает процесс применения политик в Kubernetes. При этом не рассматриваются конкретные инструменты, утилиты и тулы, а только компоненты необходимые для реализации правильного контроля политик:
PEP (Policy Enforcement Point) — точка, где получается какое‑то событие и применяем ответное действие.
PDP (Policy Decision Point) — основной мозг SOAR, который решает, что делать — паузим контейнер или убиваем.
PAP (Policy Administration Point) — этот компонент отвечает за создание политики и playbook для управления и контроля алертами/предупреждениями.
PIP (Policy Information Point) — это источники информации, обогащающие событие, которое нас триггернуло, и которое мы хотим расследовать как инцидент.
Специализированные k8s-ресурсы для отчетов
Теперь давайте обратим свое внимание на декларативную природу Kubernetes. Достаточно недавно началась и по сей день идет работа над кастомными ресурсами PolicyReport и ClusterPolicyReport. Специализированные Kubernetes-ресурсы для отчетов играют важную роль. Они выполняют модель, которую заложил Google в Kubernetes Resource Model (KRM). Эти ресурсы специально созданы для отчетов, описывающих, результаты работы сканеров, анализаторов, runtime-защита, либо Policy Engines. Это максимально приближает нас к концепциям:
Security-as-Code
Policy-as-Code
Compliance-as-Code
Detection-as-Code
Если мы хотим посмотреть, что нас не удовлетворяет, либо о чем-то предупреждает, достаточно посмотреть поле статуса данных ресурсов (или подобных). Все результаты полностью попадают в конкретный yaml.
Например, можно посмотреть в summary, сколько проверок по best practices прошло успешно.

Видим, что pass 24. Чтобы было объективнее, давайте посмотрим еще пару примеров:

Слева — в этом же отчете выполненное предупреждение от runtime защиты и запуск привилегированного контейнера. Все это попадает в PolicyReport ресурс.
Справа — фрагмент результата политики, который показывает информацию об известных уязвимостях в образах, и как это можно храниться.
Работа с PolicyReports
На сегодняшний день существует много инструментов, которые умеют складировать результаты своей работы в PolicyReport или в ClusterPolicyReport. Как runtime-решения, так и различные анализаторы:
Policy Reporter — Monitoring and Observability Tool for the PolicyReport CRD with an optional UI.
Kyverno — Kubernetes Native Policy Management
Falco adapter — Falco Policy Report adapter receives Falco events and produces one or more Policy Reports.
Tracee PolicyReport Adapter — webhook for tracee, to convert events into the unified PolicyReport and ClusterPolicyReport.
kube‑bench adapter — Building a prototype of Policy Report Generator. It aims to run a CIS benchmark check like kube‑bench and produce a policy report.
kubearmor‑adapter — This KubeArmor Policy Report adapter converts output received from KubeArmor and produces a policy report based on the Policy Report Custom Resource Definition.
Trivy Operator PolicyReport Adapter — Creates PolicyReports based on the different Trivy Operator CRDs like VulnerabilityReports
Tool: Policy Reporter
Отдельно обратим внимание на инструмент Policy Reporter. Он не генерирует отчет в формате PolicyReport, а позволяет в достаточно в удобном интерфейсе просматривать всю информацию об отчетах. Главное, чтобы ваша утилита для своего анализа складировала итоговый результат в определенном формате. А дальше Policy Reporter может либо графически, либо при поддержке других систем (Grafana Loki, Elasticsearch, Slack, Discord, MS Teams, S3, Policy Reporter UI) его отправлять или просматривать.
Недостатки Policy Reports
Мы с командой активно смотрели на PolicyReport у себя в разработке и нашли 2 проблемы:
1. Отсутствие универсальности — не все результаты хорошо ложатся на данный ресурс.
В summary всегда есть определенные поля, типа pass, fail, warn, error или skip. А, например, для отчетов об уязвимостях это не подходит. Нужна другая классификация для severity, типа critical, high, medium, low. Здесь таких понятий нет и их нельзя добавить. Поэтому, не все отчеты можно переложить в стандартные поля PolicyReport.
2. Проблема разграничения доступа к ресурсу — доступ ко всем отчетам.
Несколько утилит, которые работают с разными данными, складывают результаты своей работы в тип одного ресурса PolicyReport. RBAC Kubernetes умеет читать определенный тип ресурсов (типа PolicyReport), поэтому мы не можем разграничить, от какой утилиты тот или иной PolicyReport был сгенерирован. Конечно, можно проставить эту информацию на уровне лейблов. Например, что этот отчет об уязвимостях, второй о best practices, а третий по работе с секретами. Но на уровне RBAC Kubernetes доступ разграничить нельзя, и если вы кому-то из сотрудников дали доступ к PolicyReport типу данных, то он сможет читать все отчеты такого типа. А это неприменимо с ролями, которые выполняют сотрудники внутри компании.

Также если информации очень много, то она просто может не поместиться в один YAML ресурс и не сохраниться... Так что смотрите сами, стоит ли вам использовать PolicyReport или лучше написать свой Custom Resource для своей задачи, в котором вы будете хранить результат работы. Так или иначе это даст возможность декларативно подходить к решению задачи.
SOAR в Kubernetes
Для реализации SOAR в Kubernetes я выделил для себя две возможных фазы применения/внедрения (при этом одна не исключает другую):
Deploy-фаза, когда ресурс выкатывается непосредственно в Kubernetes;
Runtime-фаза, когда код уже действительно запущен и работает.

Deploy-фаза
Deploy-фаза: на admission controllers, когда ресурс выкатывается непосредственно в Kubernetes. Для работы с deploy-фазой необходим Policy Engines. Самые свежие и популярные: Kyverno, OPA Gatekeeper, JSPolicy, Kubewarden. В данном аспекте подойдет любой.
Так как все, что есть в Kubernetes — это yaml-файлы, они всегда проходят цепочку:

Тут есть mutating admission controller и validating admission controller. Validating admission controller — это последняя баррикада перед выкаткой, которую задумал ваш разработчик, либо злоумышленник пытающийся что-то запустить в вашем Kubernetes-кластере.
Я сопоставил концепции, которые были заявлены в документе выше, с составными частями того, что мы используем при работе с Policy Engine. Любой ресур там можно мутировать или валидировать, и сказать, можно его дальше пропускать или нет.
Policy Administration Point (PAP)
Policy Engine
Policy Enforcement Point (PEP)
Admissions
Policy Decision Point (PDP)
Policy Engine
Policy Information Point (PIP)
Любая сторонняя система
Теперь пройдемся по playbook. В качестве Policy Engine я использую Kyverno.
Playbook 1: Запрет на exec в Pod
Ситуация: атакующий скомпрометировал учетную запись и пытается получить shell или выполнить команду в контейнере.
Далее приведен полный код, который нужен для запрета выполнения команд внутри контейнеров:
apiVersion: kyverno.io/v1
kind: ClusterPolicy
metadata:
name: deny-exec-by-pod-and-container
annotations:
policies.kyverno.io/title: Block Pod Exec by Pod and Container
policies.kyverno.io/category: Sample
policies.kyverno.io/minversion: 1.4.2
policies.kyverno.io/subject: Pod
policies.kyverno.io/description: >-
The ‘exec’ conmand may be used to gain shell access, or run other commands, in a Pod's container. While this can be useful for troubleshooting purposes, it could represent an attack vector and is discouraged.
This policy blocks Pod exec commands to containers named ‘nginx’ in Pods starting with name ‘myapp-maintenance’.
spec:
validationFailureAction: enforce
background: false
rules:
- name: deny-nginx-exec-in-myapp-maintenance
match:
resources:
kinds:
- PodExecOptions
preconditions:
all:
- key: “{{ request operation }}"
operator: Equals
value: CONNECT
- key: “{{ request.name }}"
operator: Equals
value: myapp-maintenance*
validate:
message: Nginx containers inside myapp-maintanence Pods may not be exec'd into.
deny:
conditions:
all:
- key: "{{ request object.container }}"
operator: Equals
value: nginxВ этом примере на Kyverno можно запретить exec в Pod. Следовательно, не нужно постоянно мониторить и просматривать Kubernetes Audit Log. Один раз пишем политику запрещающую выполнение интерактивного shell в определенных namespace, либо кластерах, и все. Она будет непосредственно это блокировать (естественно, там есть режим аудита).
Даже если это пользователь с ролью, например, кластер-админ, который может в кластере все, мы на этом этапе все равно запретим ему порождать shell внутри контейнеров. Естественно, он может еще через несколько манипуляций, кое-что подредактировать и обойти политику, но это потребует от него дополнительных действий.
Playbook 2: Добавление securityContext
Ситуация: разработчик в обход установленных pipeline пытается выкатить небезопасное приложение.
Далее приведен полный код, который принудительно выствит для микросервиса требуемый настройки безопасности.
apiVersion: kyverno.io/v1
kind: ClusterPolicy
metadata:
name: apply-pss-restricted-profile
annotations:
policies.kyverno.io/title: Apply PSS Restricted Profile
policies. kyverno.io/category: Other
kyverno.ie/kyverno-version: 1.6.2
kyverno.io/kubernetes-version: "1.23"
policies.kyverno.io/subject: Pod
policies.kyverno. io/deseription: >-
Pod Security Standards define the fields and their options which
are allowable for Pods to achieve certain security best practices. While
these are typically validation policies, workloads will either be accepted or
rejected based upon what has already been defined. It is also possible to mutate
Incoming Pods to achieve the desired PSS level rather than reject. This policy
sets all the fields necessary to pass the PSS Restricted profile.
spec:
rules:
- none: add-pss-fields
match:
any:
- resources:
kinds:
- Pod
mutate:
patchStrategicMerge:
spec:
securityContext:
seccompProfile:
type: RuntimeDefault
runAsNonRoot: true
runAsUser: 1000
runAsGroup: 3000
fsGroup: 2000
containers:
- (name): "?*"
securityContext:
privileged: false
capabilities:
drop:
- ALL
allowPrivilegeEscalation: falseKyverno умеет мутировать Kubernetes ресурсы. И если в ресурсе не хватает security-контекста, можно принудительно применить security context, который по политике компании должен применяться ко всем микросервисам, выкатывающимся в прод. Таким образом, забывчивый разработчик или разработчик с вредоносными намерениями не сможет достичь своей цели.
Playbook 3: Создание запрещающей NetworkPolicy
Ситуация: атакующий пытается создать новый namespace без ограничений и через него развивать атаку.
Далее приведен полный код, который при создании namespace, автоматически создал и NetworPolicy.
apiVersion: kyverno.io/v1
kind: ClusterPolicy
metadata:
name: default
spec:
rules:
- name: deny-all-traffic
match:
any:
- resources:
kinds:
- Namespace
exclude:
any:
- resources:
namespaces:
- kube-system
- default
- kube-public
- kyverno
generate:
kind: NetworkPolicy
apiVersion: networking.k8s.io/v1
name: deny-all-traffic
namespace: "{{request.object.metadata.name}}"
data:
spec:
# select all pods in the namespace
podSelector: {}
policyTypes:
- Ingress
- EgressКогда происходит создание нового ресурса, то можно сразу создать и дополнительный yaml-ресурс. Для этого у Kyverno есть функциональность generate. Здесь это видно в самой политике. Каждый раз, когда Kyverno видит создание нового namespace, он создает запрещающую политику NetworkPolicy. Если атакующий пытается в namespace создать какие-то поды, он не сможет нормально в них общаться с другой частью вашей системы, потому что для этого нужен NetworkPolicy, разрешающий такие действия конкретным системам. Таким образом, атака значительно усложняется в плане распространения на другие системы.
Это примеры только на deploy. Такие playbook можно делать в зависимости от инцидента. Теперь перейдем к другой фазе.
Runtime-фаза
Runtime-фаза, когда код уже действительно работает, он запущен. В Runtime-фазе необходим агент, который видит, что происходит непосредственно на Node, внутри контейнера. Самые известные: Luntry, Falco, Tracee, Tetragon, KubeArmor. Еще должен быть Response Engine. Его задача провести реакцию на то или иное полученное предупреждение/событие, которые прислал агент. Рассмотрим два: Argo Events + Argo Workflow, Falcosidekick.
Здесь все интереснее:

Например, через Kubernetes Audit Log можно получать информацию о том, какой пользователь и какую операцию сейчас производит. Если в системе появился какой-то Kubernetes Resource, для нас это может быть триггером по запуску цепочки дальнейших действий.
Также информацию можно получить непосредственно с агента, который стоит на ноде и отправляет информацию, что за процессы в контейнерах порождают, как они между собой взаимодействуют, как процесс взаимодействует с файловой системой и с сетью. Дальше эта информация должна попасть на Response Engine, который в соответствии с тем или иным playbook её принимает и решает, что дальше делать с этим.
Это также хорошо накладывается на сущности, которые мы рассматривали раньше:

Эту точку применения можно использовать, например, для отправки команды на Agent, чтобы сказать ему:
Останови контейнер;
Сними дамп памяти, чтобы потом использовать ее для расследований инцидентов;
Удали Pod;
Создай что-то еще.
А можно, не отходя от принципов GitOps, создать отдельный файл или реакцию в Git. И уже человек придет и проверит, к какому выводу пришла система, что она хочет произвести и решит не нанесет ли она вред.
Tool: falcosidekick
Что касается Response Engine, есть опенсорсное решение falcosidekick. Оно умеет получать информацию только от двух решений: Falco, Tracee. То есть, если поддерживать определенный формат сообщений, тогда отправлять информацию в falcosidekick в принципе может любое средство. В дальнейшем в качестве триггеров можно использовать гигантский набор решений:
Chat: Slack, Rocketchat, Mattermost, Teams, Discord, Google Chat, Zoho Cliq;
Metrics/Observability: Datadog, Influxdb, Prometheus, Wavefrontм
Alerting: AlertManager, Opsgenie, PagerDuty;
Logs: Elasticsearch, Loki, AWS CloudWatchLogs, Grafana, Syslog;
Object Storage: AWS S3, GCP Storage, Yandex S3 Storage;
FaaS/Serverless: AWS Lambda, Kubeless, OpenFaaS, Knative, GCP Cloud Run, GCP Cloud Functions, Fission;
Message queue/Streaming: NATS, STAN (NATS Streaming), AWS SQS, AWS SNS, AWS Kinesis, GCP PubSub, Apache Kafka, Kafka, Rest Proxy, RabbitMQ, Azure Event Hubs;
Email: SMTP;
Web: Webhook, WebUI;
Other: Tekton, Flux v2, Argo Events + Argo Workflow, Policy Report.
Можно дергать Function-as-Code и даже Tekton. Например, прилетает событие, а он его конвертирует в Policy Report отчет. Получается полная декларативная система и работа как Detection-as-Code.
В блоге Falco есть серия постов Kubernetes Response Engine, где они на разных кейсах показывают, как может работать Falcosidekick. Например, сценарий с Argo.

Когда в Pod что-то происходит, он обнаруживает нежелательное событие по сигнатурам и пушит его в falcosidekick. Дальше смотрит, куда можно это переслать и кого уведомить. На схеме это Argo Events. Falcosidekick пишет в Events bus. Argo workflow достает это событие и принимает решение в соответствии с playbook, например, удалить Pod. Так мы можем автоматически реагировать на инциденты безопасности без участия человека.
Tool: Argo Events
Он позволяет обойтись вообще без falcosidekick, не привязываться к его протоколу и типу событий, а брать информацию с того же Kubernetes Audit Log, либо кастомных агентов. В качестве источников сообщений можно принимать гигантское количество типов Event Sources: AMQP, AWS SNS, AWS SQS, Azure Events Hub, Bitbucket, Bitbucket Server, Calendar, Emitter, File Based Events, GCP PubSub, Generic EventSource, GitHub, GitLab, HDFS, K8s Resources, Kafka, Minio, NATS, NetApp StorageGrid, MQTT, NSQ, Pulsar, Redis, Slack, Stripe, Webhooks.
В качестве триггеров тоже можно выполнять все что угодно: Argo Workflows, Standard K8s Objects, HTTP Requests / Serverless Workloads (OpenFaaS, Kubeless, KNative etc.), AWS Lambda, NATS Messages, Kafka Messages, Slack Notifications, Azure Event Hubs Messages, Argo Rollouts, Custom Trigger / Build Your Own Trigger, Apache OpenWhisk, Log Trigger.
Argo сам по себе Event-Based система.
Argo Tool: Argo Workflow
Argo Events обычно участвует в сочетании с Argo Workflow. первый создает какое-то событие, а второй запускает тот или иной Workflow.

В Argo Workflow можно описать шаги или целый алгоритм. Причем каждый из шагов — это отдельный образ контейнера. Вы можете передавать какие-то результаты между ними, сообщения, аргументы, имя контейнера, имя пода, имя namespace, имя кластера. Все будет проходить по этой цепочке.
У Argo Workflow достаточно богатый, выразительный язык. Там есть циклы, рекурсия, условия. При желании можно написать playbook, и в зависимости от окружения, namespace и команды применять те или иные действия. Если это произошло на dev или test, можно просто отправить предупреждение в Slack. Если на stage или prod, то можно заблокировать или запретить.
Например, у любимого ML-щиками Kubeflow, который позволяет параллельно вычислять и запускать свои собственные задачи, под капотом тот же Argo Workflow.
Общий алгоритм
В итоге, общий алгоритм при работе с Argo и Argo Workflow выглядит так:

Мы создаем специализированный ресурс Event Source, и говорим, что будем собирать события с определенного webhook. Например, информацию об определенном Kubernetes ресурсе. Дальше Event Source забирает эту информацию и кладет ее в Event Bus. Далее создается Sensor, который забирает уже определенные события из этой шины. У него есть матчер, который предлагает на определенное событие запускать следующий Workflow. Для этого в ресурсе создается Workflow Template. Чтобы у данного контейнера были возможности создать ресурсы типа Workflow, создается Service Account. В самом WorkflowTemplate описываем какие параметры, аргументы и по какой логике в какие образы переходят. Каждый маленький образ будет определенным шагом Workflow — маленьким playbook. Их может быть много или мало, но для каждого нужно создавать маленький контейнер.
Посмотрим, как это использовать на примере playbook.
Playbook 4: Сетевая изоляция Pod
Ситуация: внутри Pod обнаружена вредоносная, аномальная активность:

Сценарий: вы хотите, чтобы служба безопасности провела расследование инцидента, посмотрела, что за вредоносный код, либо атакующая «полезная» нагрузка там используется. Поэтому мы изолируем ее по сети, чтобы она не могла атаковать соседние микросервисы. У нас есть несколько вариантов.
Вариант 1. Если в компании не применяются NetworkPolicy.
Мы можем применить классическую нативную NetworkPolicy, которая запрещает любые Ingress и Egress соединения. Они применяются к подам по лейблам со статусом compromised, и ее можно заранее заготовить (isolate-compromised-pod). Если атакующий туда попал, его вредоносный код не посканит сеть и никуда ничего не отправит — он изолирован. NetworkPolicy может быть воссоздана в каждом namespace, но если у вас нет ни одного пода с соответствующим лейблом, она не будет никого ограничивать.
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: isolate-compromised-pod
spec:
podSelector:
matchLabels:
status: compromised
policyTypes:
- Ingress
- EgressВариант 2. Если в компании есть NetworkPolicy.
Если есть кастомная реализация NetworkPolicy от CNI (Calico и Cilium), вы можете делать полностью запрещающие политики. Идея такая же — запрещающая политика делается в зависимости от того, какой CNI используется в сети. isolate-compromised-pod по селектору также применяется к подам, у которых есть лейбл status: compromised. А когда происходит инцидент, нам достаточно повесить на него лейбл status: compromised — всё, он будет изолирован. Следующим шагом в workflow можем, например, отправить сообщение в чат команде безопасности. Они придут на ту ноду и на живой системе посмотрят, что за вредоносный код, что он делает, дампнуть память и произвести подобные вещи.

Playbook 5: Временное усиление изоляции микросервиса
Ситуация: в Police Report/Vulnerability Report/… содержится High critical RCE уязвимость:
Здесь мы будем привязываться не к событию, которое нам присылает агент с ноды, а, например, к появлению того или иного ресурса. Если работает сканер на уязвимости, то результаты своей работы он складывает в какой-нибудь PolicyReport или в VulnerabilityReport. Мы там видим high critical RCE-уязвимость и допустим через нее возможен побег из контейнера.
Что делать? Быстро обновиться не получится. На то, чтобы дампнуть версию микросервиса и библиотеки нужно время: надо поставить задачу разработчику, разработчик должен ее исправить, версия с исправлением должна пройти все pipelin’ы, новая версия раскатится на весь прод. И все это время система уязвима! Поэтому необходимо выиграть время.
Уязвимый микросервис нужно изолировать, чтобы пока мы ждем исправления, оставаться уверенными, что даже если атакующий реализует угрозу, он не сможет нанести какой-либо значимый ущерб.
Для временного усиления изоляции микросервиса можно:
Вариант 1: Заранее создать и расположить в инфраструктуре Nodes с label: example.com.node-restriction.kubernetes.io/type=isolator. Скачать ресурс и добавить в него:
nodeSelector:
type: isolator
Он перевыкатится и весь запускается на нодах с лейблом isolator. Команда безопасности сможет его смотреть на данной ноде более детализировано просматривать, а также на данных нодах другие микросервисы не запустятся. А после того, как разработчики выпустят патч, мы просто убираем две строчки и все раскатывается, как обычно.
Вариант 2: В качестве альтернативного runtime ставим gVisor или Kata и регистрируем RuntimeClass. В уязвимый микросервис добавляем свойство runtimeClassName, где используется sandbox или microVM.
Для этого мы заранее регистрируем в системе ресурс runtimeClass и на все ноды ставим тот или иной дополнительный runtime. Тогда в playbook для того микросервиса, который мы хотим временно изолировать, достаточно добавить одну строку runtimeClassName: gVisor (или Kata). Он перевыкатится и будет работать с изоляцией уровня microVM или sandbox. Даже если атакующий проэксплуатирует уязвимость, сбежать из данного контейнера ему будет чрезвычайно сложно. А у нас будет время, чтобы выкатить патчи и обновления причем без участия человека. Достаточно просто в одном yaml добавить строку и все это запустить.
Playbook 6: Временное усиление изоляции микросервиса
Ситуация: появилось обращение к SelfSubjectAccessReview или SelfSubjectRulesReview APIs от service accounts или nodes. Это значит, что атакующий пытается понять, какими правами он обладает. То есть, у вас скомпрометировали Service Account token.
Сценарий: с ресурсами SelfSubjectAccessReview и SelfSubjectRulesReview APIs, думаю, немногие работали, потому что они чисто системные. Но когда вы делаете в команде kubectl auth can-i (какими возможностями я обладаю), как раз идет обращение к двум этим API, и они возвращают, какими правами обладает данный сервисный аккаунт.
Идея в том, что сами микросервисы не ходят и не спрашивают, какие у них права. Иначе это было бы восстание машин, и ваш микросервис задумался о том, что может в этой жизни. Естественно, он этого не делает, если ваши разработчики такую логику не заложили, но обычно не закладывают.
Следовательно, это человек получил доступ к Service Account token и теперь хочет понять, что может делать в вашей системе. На основании этого признака начинается процедура отзыва Service Account token. Для этого мы создаем новый Service Account token. Потом скачиваем ресурс, где он раньше использовался и меняем его на новый. Он перевыкатывается, а старый удаляется.
В документации есть пометка, что должен быть обязательно выставлен флаг (на схеме выделен красным). Таким образом, даже если у атакующего на руках находится Service Account token, после того, как вы удалили сервисный аккаунт, благодаря которому он был создан, этот токен становится на Kubernetes API недействительным.

https://kubernetes.io/docs/reference/access-authn-authz/authentication/#service-account-tokens
Такую же идею можно найти в документации Google при описании GKE. Просто создаем новый сервисный аккаунт, подменяем строку для нашего микросервиса, а старый удаляем. И на руках у атакующего находится недействительный, нерабочий Service Account token.

Вопрос согласованности данных
Мы все за GitOps, чтобы у нас был единый источник правды. Но если мы напрямую начинаем коммуницировать с Kubernetes API или с агентом, это обходит стандартные pipeline и ломает согласованность, консистентность данных. На своем канале я как-то проводил дискуссию по этому вопросу. Наилучший сценарий, чтобы мы это не сломали:
Писать в Git;
Использовать GitOps;
Использовать для безопасности специальный быстрый security pipeline без кучи проверок и прогона через все стейджи, чтобы можно было максимально быстро выкатить и применить в кластере.
Так как это Git, можно делать это не полностью автоматизировано. Я обсуждал данные SOAR с реальными финансовыми организациями. Они не всегда доверяют полной автоматизации и говорят, что хотя бы на последнем уровне нужно иметь человеческий апрув. Поэтому мы создаем в Git, все проверяется человеком и только после этого данный pipeline запускается. При этом вся команда DevOps всегда понимает, в каком состоянии находится система. Они могут посмотреть, а что за последнее время в этом security pipeline вообще выкатывалось, откатывалось, запрещалось и разрешалось.
Заключение
Kubernetes — очень классная система. Благодаря control loop, возможностям admission controller и декларативной природе он упрощает не только возможность самовосстановления, но и самообороны. С помощью нехитрых манипуляций мы можем отрабатывать с yaml-файлами те или иные сценарии с безопасностью. Argo Events и Argo Workflow — действительно крутые решения. Я их показывал на примере реакции на security-инциденты, но при желании можно писать более хитрые автоматизированные сценарии на инциденты не только ИБ, но и на инциденты своих IT-задач.
Идеология Kubernetes упрощает создание SOAR для него;
Argo Events + Argo Workflow отлично подходят для реагирования;
От self-healing до self-defence совсем близко.
Kubernetes — это реально новый мир. Обидно, когда к нему пытаются применить те же контроли и практики безопасности, которые применяют к классическим Linux и Windows сетям. У него свои особенности. Некоторые безопасники, побаиваются Kubernetes, но если его понять и использовать по делу, можно получить такой прирост безопасности, который не даст ни одна другая система. Я уж не говорю про использование различных иммутабельных ОС, distroless образов, где атакующему сбежать либо невозможно, либо нереально вообще.
Инструменты автоматизации не только находят уязвимости и экономят средства на разработку. Они выполняют множество функций про которые мы скоро поговорим на DevOps Conf 2023. 13 и 14 марта вас ждут новые кейсы, инструменты и боли со своими решениями. Уже подготовлена программа:
Александр Токарев «Все, что надо знать о рейтлимитах, и даже больше.»
Александр Титов «DevOps умер. Да здравствует, DevOps!»
Виктор Попов «Горшочек не вари. Когда алертов слишком много.»
Тимофей Нецветаев «DevOps трансформация. Как раздать инженеров по командам и не погибнуть.»
Евгений Харченко «Хочешь расти в DevOps, но не знаешь как? Приходи, расскажу!»
Ещё больше информации смотри на официальном сайте конференции.