Идея создать собственный веб-плеер с музыкой лоу-фай пришла мне в голову однажды воскресным днём во время изучения глубоких генеративных моделей. Я занялась этим проектом и закончила его за время каникул. Веб-плеер имеет две опции: пользователи могут выбрать трек лоу-фай на основе реальной песни, преобразованной с помощью библиотеки Tone.js, или трек, сгенерированный искусственным интеллектом. В обоих случаях поверх накладываются барабанные ритмы, атмосферные звуки и цитаты, которые пользователь сам выбрал на предыдущем шаге. В этом посте речь пойдёт в основном о том, как использовать нейросети LSTM для генерации midi-треков, а в конце я кратко расскажу о том, как с помощью Tone.js создаются песни.
Ещё со времён колледжа я увлекаюсь музыкой в жанре лоу-фай хип-хоп. Она создаёт уютную, успокаивающую атмосферу. Несколько последовательностей джазовых аккордов, ритмичные барабанные биты, атмосферные звуки, цитаты из фильмов, которые вызывают ностальгию, — и мы получаем довольно прилично звучащий трек в стиле лоу-фай хип-хоп. Важный вклад в восприятие лоу-фай вносит визуальный ряд, который создаёт соответствующую атмосферу наряду со звуками природы: воды, ветра и огня.
Попробовать веб-плеер можно здесь. Рекомендую использовать браузер Chrome для компьютера.
Архитектура нейронной сети LSTM и генерация Midi
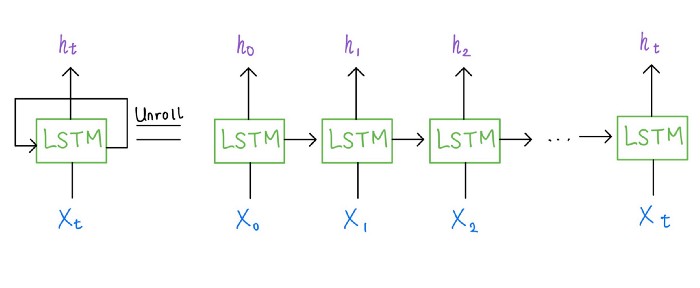
О сети LSTM я рассказала в предыдущем посте. Если кратко, то это — особая разновидность рекуррентной нейронной сети (RNN), которая лучше работает с долгосрочными зависимостями. Она также имеет рекуррентную структуру, которая на текущем временном шаге принимает выходные данные с предыдущего временного шага. Чтобы лучше понять структуру LSTM, развернём эту нейросеть и представим её ячейку в виде нескольких копий одной и той же сети, каждая из которых передаёт сообщение на следующий временной шаг, как показано на схеме.
Развёрнутая сеть LSTM
Каждая ячейка содержит четыре основных компонента, которые позволяют ей лучше справляться с долгосрочными зависимостями:
- слой фильтра забвения: определяют, какую информацию отбросить;
- входной слой: определяют, какую информацию обновлять и сохранять в состоянии ячейки;
- обновление состояния ячейки: выполняет поэлементные операции для обновления состояния ячейки;
- выходной слой: определяют, какую информацию подавать на выход.

Структура ячейки LSTM
Подготовка обучающих данных
Есть несколько вариантов формата музыкальных данных, на которых можно обучать модель:
- необработанные аудиофайлы;
- признаки (например, частотно-временные представления звука, такие как мел-спектрограмма) или символическое представление музыки (например, midi-файлы).
Наша задача — сгенерировать основной трек (т. е. последовательность нот, аккордов и пауз) для дальнейшего наложения его на другие составляющие, например, барабанные петли, поэтому для нашей цели midi-файлы — самый простой и эффективный формат. Обучение на необработанных аудиофайлах требует больших вычислительных ресурсов. Чтобы оценить их объём, достаточно отметить, что сэмплирование аудио с частотой 48000 кГц соответствует 48000 точкам данных в одной секунде аудио. Даже если мы уменьшим частоту дискретизации до 8 кГц, всё равно останется 8000 точек данных в секунду. Кроме того, чистый звук только мелодии или последовательности аккордов встречается крайне редко. Конечно, мы могли бы попытаться найти midi-файлы, которые содержат только последовательность аккордов / мелодию.
Для этих целей я использовала несколько образцов лоу-фай midi, созданных Майклом Ким-Шенгом, который великодушно разрешил мне использовать его файлы, а ещё некоторые midi-файлы из этого инструментария Cymatics lo-fi, который лицензирован для коммерческого использования. Чтобы удостовериться, что я тренирую свою модель на качественных данных (правдоподобная последовательность аккордов и размер для лоу-фай хип-хопа), я прослушала подмножество треков из каждого источника и отфильтровала обучающий набор данных. Архитектура модели создана по мотивам фортепианной музыки композиторов-классиков из этого репозитория.
Загрузка и преобразование midi-файлов
Для загрузки midi-файлов можно использовать пакет Python music21. Music21 считывает midi-файл и сохраняет каждую составляющую музыки в определённом объекте Python. То есть нота сохраняется как объект Note, аккорд — как объект Chord, а пауза — как объект Rest. Их название, продолжительность, высотный класс и другие свойства доступны в записи через точку. Music21 хранит аудио в виде иерархии, показанной ниже. Соответственно мы можем извлекать необходимую информацию. Если вас интересует, как использовать этот пакет, на веб-сайте пакета находится руководство пользователя для начинающих. Кроме того, у Валерио Велардо на канале The Sound of AI есть учебное пособие о том, как применять music21.
Как я уже упоминала, music21 хранит каждую ноту, паузу и аккорд в виде объекта Python, поэтому на следующем шаге необходимо их преобразовать и поставить в соответствие целым числам, на которых можно обучить модель. Выходные данные модели должны содержать не только ноты, но также аккорды и паузы, поэтому будем преобразовывать каждый тип отдельно и ставить в соответствие преобразованному значению целое число. Мы делаем это для всех midi-файлов и для обучения модели объединяем их в единую последовательность.
- Аккорды: получить названия нот в аккорде, преобразовать их в нормальный порядок и соединить их точкой в формате строки "#.#.#".
- Ноты: в качестве кодировки используется название ноты.
- Паузы: преобразуются в строку "r".

Загрузка и преобразование midi
Создание входящих и целевых пар
Теперь у нас есть удобная кодировка midi-данных для модели. Следующий шаг — подготовка входящих и целевых пар для модели. В простой задаче машинного обучения с учителем — задаче классификации — фигурируют входные и целевые пары. Например, модель, которая классифицирует породу собак, будет иметь в качестве входных данных цвет шерсти, рост, вес и цвет глаз собаки, а меткой/целью будет конкретная порода, к которой принадлежит собака. В нашем случае входные данные — это последовательность длины k, начинающаяся с временного шага i, а соответствующее целевое значение — точка данных на временном шаге i+k. Итак, мы организуем цикл по преобразованной последовательности нот и создаём для модели входные и целевые пары. На последнем шаге мы изменяем размерность входных данных, преобразуем их в формат, совместимый с keras, а также осуществляем прямое кодирование выходных данных.
Структура модели
Как упоминалось ранее, в качестве основной структуры модели мы воспользуемся слоями нейросети LSTM. Кроме того, в этой нейросети будут следующие составляющие:
- слои отсева: для регуляризации сети и предотвращения переобучения путём случайной установки входных единиц на 0 с частотой rate в 0,3 на каждом шаге обучения;
- плотные слои: полностью соединяют предыдущий слой и выполняют матрично-векторное умножение в каждом узле. Последний плотный слой должен иметь количество узлов, равное количеству уникальных нот/аккордов/пауз в нейросети;
- слои активации: привносят в нейросеть нелинейность, когда они есть в скрытом слое, помогают нейросети осуществить классификацию, когда они в выходном слое.
model = Sequential()
model.add(LSTM(
256,
input_shape=(network_input.shape[1], network_input.shape[2]),
return_sequences=True
))
model.add(Dropout(0.3))
model.add(LSTM(512, return_sequences=True))
model.add(Dropout(0.3))
model.add(LSTM(256))
model.add(Dense(256))
model.add(Dropout(0.3))
model.add(Dense(n_vocab))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy', optimizer='rmsprop')
model.fit(network_input, network_output, epochs=200, batch_size=128)Здесь 3 слоя LSTM с 2 слоями отсева, каждый из которых следует за первыми двумя слоями LSTM. Затем идут 2 полностью соединённых плотных слоя, за которыми следует одна функция активации softmax. Наши выходные данные категориальные, поэтому целевой функцией станет категориальная перекрёстная энтропия. Применяется довольно распространённый для RNNS оптимизатор RMSProp. Добавлены контрольные точки, для того чтобы веса регулярно сохранялись на разных эпохах и могли использоваться до окончания обучения модели. Можно изменять структуру модели и пробовать различные оптимизаторы, количество эпох и размеры пакетов.
Генерация выходных данных и обратное преобразование в midi-ноты
Генерация выходных данных аналогичен процессу обучения — мы подаём модели последовательность длиной m (для упрощения обозначения обозначим её последовательностью m) и просим её предсказать следующую точку данных. Эта последовательность m имеет начальный индекс, случайно выбранный из входной последовательности, но при желании можно указать конкретный начальный индекс. Выходные данные модели представляют собой список вероятностей из softmax, которые сообщают нам, насколько каждый класс подходит в качестве следующей точки данных. Выберем класс с наибольшей вероятностью. Чтобы сгенерировать последовательность длины j, мы повторим этот процесс, удалив первый элемент последовательности m и добавив недавно сгенерированную точку данных к этой последовательности m. И так до тех пор, пока модель не сгенерирует j новых точек данных.
Данные, сгенерированные по алгоритму из последнего абзаца, по-прежнему являются целым числом, поэтому мы преобразуем их обратно в ноту/аккорд/паузу через те же соответствия, что и при кодировании. Если это формат строки аккорда, прочитаем целочисленное обозначение из строки "#.#.#.#" и создадим объект music21.chord. Если это нота или пауза, мы создадим соответствующий объект note или rest. В то же время на каждом временном шаге мы добавляем к выходной последовательности прогноза новую сгенерированную точку данных. Для иллюстрации ниже приведён пример потока, где мы генерируем последовательность из 4 точек данных на основе входной последовательности из 3 точек данных.
Теперь у нас есть последовательность нот, аккордов и пауз. Мы могли бы поместить их в поток music21 и записать midi-файл, и в этом случае все ноты будут четвертными. Чтобы сделать вывод немного интереснее, я добавила фрагмент кода, который случайным образом выбирает длительность для каждой ноты или аккорда (распределение вероятностей по умолчанию составляет 0,65 для восьмых нот, 0,25 — для 16-х нот, 0,05 — для четвертных и половинных нот). Паузы по умолчанию равны 16-м <1----> паузам, чтобы избежать слишком долгих промежутков между нотами.
NOTE_TYPE = {
"eighth": 0.5,
"quarter": 1,
"half": 2,
"16th": 0.25
}
offset = 0
output_notes = []
for pattern in prediction_output:
curr_type = numpy.random.choice(list(NOTE_TYPE.keys()), p=[0.65,0.05,0.05, 0.25])
# pattern is a chord
if ('.' in pattern) or pattern.isdigit():
notes_in_chord = pattern.split('.')
notes = []
for current_note in notes_in_chord:
new_note = note.Note(int(current_note))
new_note.storedInstrument = instrument.Piano()
notes.append(new_note)
new_chord = chord.Chord(notes, type=curr_type)
new_chord.offset = offset
output_notes.append(new_chord)
elif str(pattern).upper() == "R":
curr_type = '16th'
new_rest = note.Rest(type=curr_type)
new_rest.offset = offset
output_notes.append(new_rest)
# pattern is a note
else:
new_note = note.Note(pattern, type=curr_type)
new_note.offset = offset
new_note.storedInstrument = instrument.Piano()
output_notes.append(new_note)
# increase offset each iteration so that notes do not stack
offset += NOTE_TYPE[curr_type]
midi_stream = stream.Stream(output_notes)
midi_stream.write('midi', fp='test_output.mid')Для того чтобы сгенерированные треки по звучанию были ближе к настоящей музыке, после запуска модели несколько раз с разными параметрами и подбора треков, которые нам нравятся, применим инструментальный эффект в стиле лоу-фай из любой цифровой звуковой рабочей станции (DAW). Затем создадим веб-плеер с помощью JavaScript.
Создание веб-плеера с Tone.js
Tone.js — это веб-фреймворк, предназначенный для создания интерактивной музыки в браузере. Вы можете использовать его для создания различных интерактивных веб-сайтов (см. демоверсии здесь). Но здесь он применяется для окончательного наложения аудио, чтобы обеспечить одновременное воспроизведение барабанных ритмов, атмосферных звуков, цитат и мелодии. Он также позволяет записывать музыкальное сопровождение, сэмплировать определённый инструмент, добавлять звуковые эффекты (реверберацию, усиление и т. д.) и создавать циклы прямо в JavaScript. Скелет программы разработала Kathryn. Если вы хотите быстро и эффективно освоить Tone.js, я настоятельно рекомендую примеры использования этой библиотеки на веб-сайте. Вот самый важный вывод: если мы хотим добавить звуковые эффекты к каждому звуковому событию, которое создаём, нужно подключить его к AudioDestinationNode (т. е. к нашим динамикам) через toDestination() или через samplePlayer.chain(effect1, Tone.Tone.Destination). Затем через Tone.Transport мы сможем запускать, приостанавливать и планировать события на выходе устройства.
Зацикливание аудиоклипов
Барабанные ритмы, атмосферные звуки, цитаты и треки, предварительно сгенерированные искусственным интеллектом, представляют собой аудиофайлы (.mp3 или .wav), загруженные в наш веб-плеер через класс Player. После загрузки пользователем с веб-сайта входящих событий они передаются в класс Tone.js для создания циклов.
Барабанные ритмы повторяются каждые 8 тактов, атмосферные звуки — каждые 12 тактов, а сами сгенерированные треки — каждые 30 тактов. Цитаты не зацикливаются и начинаются с 5-го такта.
Создание мелодии и последовательности аккордов с помощью сэмплов инструментов
Tone.js не предоставляет нам инструментальных опций, подобно программам DAW, только сэмплеры, которые позволяют нам сэмплировать наши собственные инструменты, загружая пару нот. Затем сэмплер автоматически повторно загрузит сэмплы и создаст ноты, которых в явном виде не было.
Теперь мы можем записать мелодию и последовательность аккордов, указав ноты и время, в течение которого должна звучать та или иная нота. Для нужного нам преобразования ритма я рекомендую использовать TransportTime. TransportTime представлено в виде "такты: четвертные: шестнадцатые", нумерация начинается с нуля. Например, "0:0:2" означает, что нота будет воспроизведена после двух шестнадцатых нот в первом такте. "2:1:0" означает, что нота будет воспроизведена в третьем такте после одной четвертной ноты. Таким образом я записала мелодию и последовательности аккордов для 3 существующих песен: Ylang Ylang (автор FKJ), La Festin (автор Camille) и See You Again (автор Tyler, the Creator).
Дизайн веб-плеера
Я добавила опции для изменения фона веб-плеера в зависимости от атмосферных звуков. Таким образом, для каждого контекста отображается более соответствующая анимация. Также есть визуализатор, выполненный с помощью p5.js и связанный с нотами песни.
Дальнейшие действия
Нейронная сеть LSTM
- Добавление маркеров начала и конца последовательности. Так модель сможет запоминать конец музыкального паттерна.
- Включение кодировки длительности ноты для отслеживания ритма.
Веб-плеер
- Было бы здорово подключить к веб-плееру модель искусственного интеллекта на базе сервера, чтобы выходные данные можно было генерировать в реальном времени. В настоящее время недостатком является то, что модели для генерации выходных данных требуется несколько минут. Однако, возможно, мы могли бы использовать API с предварительно обученной моделью.
- Степень интерактивности можно значительно увеличить, если веб-плеер позволит пользователям:
- вводить последовательность аккордов по своему выбору;
- вводить текст, по которому веб-плеер проведёт анализ тональности и выведет соответствующую последовательность аккордов.
Заключение
Получить код и обучающие наборы данных можно в репозитории GitHub. Это всего лишь простой лоу-фай веб-плеер, но мне доставила удовольствие работа с моделью LSTM и Tone.js. Возможность использовать технологии для работы с музыкой удивляет меня каждый раз.

Data Science и Machine Learning
- Профессия Data Scientist
- Профессия Data Analyst
- Курс «Математика для Data Science»
- Курс «Математика и Machine Learning для Data Science»
- Курс по Data Engineering
- Курс «Machine Learning и Deep Learning»
- Курс по Machine Learning
Python, веб-разработка
- Профессия Fullstack-разработчик на Python
- Курс «Python для веб-разработки»
- Профессия Frontend-разработчик
- Профессия Веб-разработчик
Мобильная разработка
Java и C#
- Профессия Java-разработчик
- Профессия QA-инженер на JAVA
- Профессия C#-разработчик
- Профессия Разработчик игр на Unity
От основ — в глубину
А также
Комментарии (4)

Dynasaur
06.02.2023 10:22вы не указали на какой библиотеке это создано, или я пропустил? Это tensorflow?

stranger777
06.02.2023 12:07+2Кроме tone.js, использовалась Keras. Автор пишет о ней вскользь, такое несложно упустить. Код здесь.
numark
>Я занялась этим проектом
>О сети LSTM я рассказал в предыдущем посте.
Неплохо было бы к одному роду привести.
stranger777
Спасибо, поправили. Перепроверили окончания глаголов. Ошибкам такого рода — и контролю качества в целом — у нас посвящён целый чек-лист, но из-за форс-мажора пострадали связанные с ним процессы, гарантирующие, в частности, отсутствие этой ошибки. Сейчас всё это потихоньку налаживаем и заново закручиваем гайки. Добавлю также, что на Хабре есть стандартный механизм сообщения об опечатках, срабатывает он по выделению опечатки и нажатию Ctrl+Enter, а замечание попадает автору поста в личные сообщения.