Алгоритмы в основе традиционных сетей настраиваются во время обучения, когда подается огромное количество данных для калибровки наилучших значений их весов, ликвидные («текучие») нейронные сети лучше адаптируются.
«Они способны изменять свои основные уравнения на основе входных данных, которые они наблюдают», в частности, изменяя скорость реакции нейронов, — рассказывает директор Лаборатории компьютерных наук и искусственного интеллекта Массачусетского технологического института Даниэла Рус.
Один из первых тестов для демонстрации этой способности — попытка управлять автономным автомобилем. Ведь обычная нейронная сеть анализирует визуальные данные с камеры автомобиля только через постоянные промежутки времени, а ликвидная сеть из 19 нейронов и 253 синапсов (крошечная по стандартам машинного обучения) может оказаться намного отзывчивее.
«Наша модель может делать выборки чаще, например, когда дорога извилиста», — рассказывает соавтор этой и других статей о ликвидных сетях.
Модель успешно удерживала машину на ходу, но, по словам Лехнера, у неё был один недостаток: «Она была очень медленной» из-за нелинейных уравнений, представляющих синапсы и нейроны, которые обычно невозможно решить без повторных вычислений на компьютере, который выполняет несколько итераций, прежде чем сойдется к решению. Эта работа обычно делегируется специальным программным пакетам — решателям, применять которые нужно к каждому синапсу и нейрону отдельно.
В статье 2022 года учёные показали ликвидную нейронную сеть, которая обошла это узкое место. Эта сеть основывалась на уравнениях того же типа, но ключевым достижением стало открытие Хасани, что такие уравнения не нужно решать с помощью трудоемких компьютерных вычислений. Вместо этого сеть могла бы функционировать, используя почти точное или «замкнутое» решение, которое, в принципе, можно было бы разработать на бумаге с карандашом в руках. Как правило, эти нелинейные уравнения не имеют решений в замкнутой форме, но Хасани наткнулся на достаточно хорошее приближенное решение.
«Решение в замкнутой форме — это решение при помощи уравнения, в котором можно подставить значения параметров, затем выполнить простые математические операции — и вы получите ответ, одним выстрелом».
Это ускоряет вычисления и сокращает затраты энергии.
Ликвидные нейронные сети предлагают «элегантную и компактную альтернативу», — считает Кен Голдберг, робототехник из Калифорнийского университета в Беркли. По его словам, эксперименты уже показывают, что эти сети могут работать быстрее и точнее, чем другие так называемые нейронные сети с непрерывным временем, которые моделируют системы, меняющиеся во времени.
Рамин Хасани и Матиас Лехнер, инициаторы новой архитектуры, много лет назад поняли, что C. elegans может стать идеальным организмом, который можно использовать, чтобы выяснить, как создавать устойчивые нейронные сети, способные приспосабливаться к неожиданностям. Этот червь — одно из немногих существ с полностью структурированной нервной системой, и она способна к целому ряду действий: двигаться, находить пищу, спать, спариваться и даже учиться на собственном опыте. «Он живет в реальном мире, где постоянно происходят изменения, и может хорошо работать практически в любых условиях», — сказал Лехнер.
Уважение к непритязательному червю привело Лехнера и Хасани к их новым сетям, где каждый нейрон управляется уравнением, которое предсказывает его поведение во времени. И так же, как нейроны связаны друг с другом, эти уравнения зависят друг от друга. Сеть, по сути, решает ансамбль связанных уравнений, позволяя характеризовать состояние системы в любой момент — в отличие от традиционных нейронных сетей, которые выдают результаты только в определенные моменты времени.
«[Обычные нейросети] могут рассказать вам, что происходит, только через одну, две или три секунды», — сказал Лехнер. «Но модель с непрерывным временем, подобная нашей, может описать происходящее за 0,53 секунды, 2,14 секунды или любое другое время, которое вы выберете».
Ликвидные сети также различаются тем, как они обрабатывают синапсы, связи между искусственными нейронами. Сила этих связей в стандартной нейронной сети может быть выражена одним числом — ее весом. В ликвидных сетях обмен сигналами между нейронами — вероятностный процесс, управляемый «нелинейной» функцией: ответы на входы не всегда пропорциональны. Удвоение входных данных, например, может привести к гораздо большему или меньшему сдвигу вывода. Именно из-за этой естественной изменчивости сети называют ликвидными, «жидкими». Реакция нейрона может варьироваться в зависимости от того, какие входные данные он получает.
«Их метод — победить конкурентов на несколько порядков, не жертвуя точностью», — сказал Саян Митра, ученый-компьютерщик из Университета Иллинойса, Урбана-Шампейн.
По словам Хасани, их новейшие сети не только быстрее, но и необычно стабильнее, а это означает, что система, не выходя из строя, способна обрабатывать огромные входные данные. «Основной вклад здесь заключается в том, что стабильность и другие приятные свойства заложены в этих системах благодаря их чистой структуре», — рассказывает Шрирам Санкаранараянан, ученый-компьютерщик из Университет Колорадо, Боулдер. Ликвидные сети, кажется, работают внутри «золотого пятна: они достаточно сложны, чтобы в них происходило нечто интересное, но сложны не настолько, чтобы привести к хаотичному поведению».
Сейчас учёные из MIT тестирует свою последнюю сеть на автономном БПЛА. Хотя дрона учили ориентироваться в лесу, его переместили в городскую среду Кембриджа, чтобы посмотреть, как он справляется с новыми условиями. Предварительные результаты эксперимента Лехнер считает обнадеживающими.
Команда работает над улучшением архитектуры своей сети. Следующий шаг, по словам Лехнера, «выяснить, сколько или насколько мало нейронов нужно, чтобы решить задачу».
Учёные хотят разработать оптимальный способ соединения нейронов. Сейчас каждый нейрон связан с каждым другим нейроном, но синаптические связи C. elegans работают иначе: они более избирательны. Благодаря исследованиям нервной системы круглых червей учёные надеются определить, какие нейроны в их системе должны быть соединены.
Кроме автономного вождения и полётов, ликвидные сети хорошо подходят для анализа электрических сетей, финансовых транзакций, погоды и других явлений, которые меняются со временем. По словам Хасани, последнюю версию ликвидных сетей можно использовать «для моделирования активности мозга в масштабах, ранее невозможных».
Особенно этим заинтригован Митра. «В каком-то смысле это поэтично, показать, что это исследование может пройти полный цикл [полный, замкнутый круг], — считает он [отсылка на замкнутую форму уравнений]. — Нейронные сети развиваются до такой степени, что те самые идеи, которые мы почерпнули из природы, вскоре смогут помочь нам лучше понять природу».
Перейдём к практике. Покажем пример прямо из документации к пакету c реализацией ликвидных нейросетей. И, конечно, его работу.
Технические подробности
Политика нейронных цепей (NCP) — это повторяющиеся модели нейросетей, вдохновленные нервной системой нематоды C. elegans. По сравнению со стандартными моделями ML, NCP имеют:
- Нейроны, моделируемые обыкновенным дифференциальным уравнением;
- Разреженные и структурированные связи нейронов;
Модели нейронов
Сегодня пакет предоставляет две модели нейронов: LTC и CfC на нейронах в виде дифференциальных уравнений, связанных между собой сигмоидальными синапсами. Термин «текучая [ликвидная] постоянная времени» происходит от свойства LTC: поведение этих нейронов во времени подстраивается к входным данным (скорость реакции на некоторые стимулы может зависеть от конкретного входного сигнала). LTC — это обыкновенные дифференциальные уравнения, поэтому их поведение можно описать только во времени.
LTC являются универсальными аппроксиматорами и реализуют причинно-следственные динамические модели. У модели LTC есть один существенный недостаток: для вычисления выходных данных нужен численный решатель дифференциальных уравнений, который серьезно замедляет обучение и время вывода. Модели уравнения [замкнутой формы] с непрерывным временем (CfC) устраняют это узкое место, они содержат приближённое решение дифференциального уравнения в замкнутой форме.
Обе модели LTC и CfC — это рекуррентные нейронные сети, они обладают временным состоянием, а значит, применимы только к последовательным данным или к данным временных рядов.
Нейронные связи
Использовать можно обе вышеописанные модели, причём с полносвязной схемой соединений. Для этого просто передадим количество нейронов, как это делается в стандартных моделях, таких как LSTM, GRU, MLP или трансформеры.
from ncps.torch import CfC
# a fully connected CfC network
rnn = CfC(input_size=20, units=50)В форме объекта ncps.wirings.Wiring можно указать разреженные структурированные соединения. Политика нейронных цепей (NCP) — самая интересная парадигма нейронных связей в этом пакете, она включает в себя 4-уровневый принцип рекуррентного соединения сенсорных, промежуточных, командных и моторных нейронов.
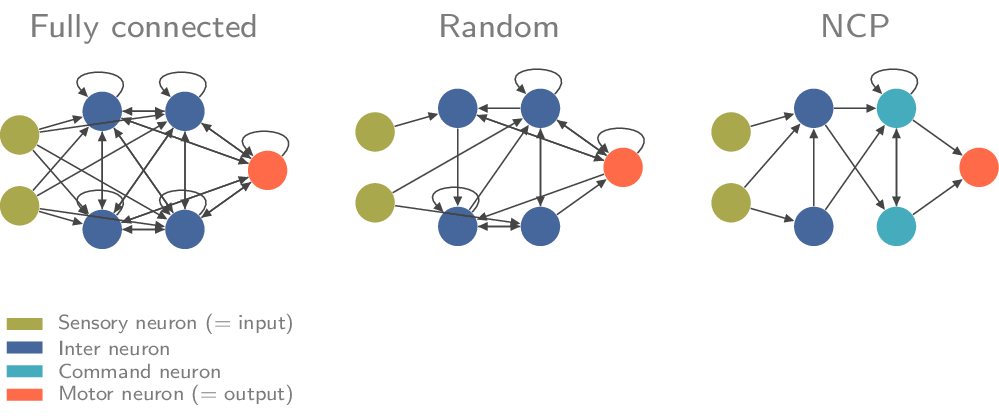
Самый простой способ создать нейронные связи NCP — использовать класс AutoNCP, требующий указать общее количество нейронов и количество двигательных нейронов, то есть размер вывода.
from ncps.torch import CfC
from ncps.wirings import AutoNCP
wiring = AutoNCP(28, 4) # 28 neurons, 4 outputs
input_size = 20
rnn = CfC(input_size, wiring)Схема

Учим текучую нейросеть играть в Atari
Ниже научим NCP играть в игру Atari с помощью обучения с подкреплением. Код написан на TensorFlow, а для обучения применяется ray[rllib]. Мы воспользуемся алгоритмом proximal policy optimization (PPO) — ближайшая оптимизация политики. Это хороший базовый алгоритм, который работает и в дискретном, и в непрерывном пространстве действий.
Установка и требования
Для начала нужно установить кое-какие пакеты:
pip3 install ncps tensorflow "ale-py==0.7.4" "ray[rllib]" "gym[atari,accept-rom-license]==0.23.1"Определяем модель
Модель состоит из блока свертки, за которым следует рекуррентная нейронная сеть типа CfC. Для совместимости модели с rllib создадим подкласс класса ray.rllib.models.tf.recurrent_net.RecurrentNetwork.
Наша сеть Conv-CfC обладает двумя выходными тензорами. Это тензоры:
- Распределения возможных действий (политика);
- Скалярной оценки функции ожидаемого возврата;
Второй тензор необходим для наших алгоритмов PPO RL. Изучение как политики, так и функции ожидаемого возврата в одной сети часто имеет некоторые преимущества обучения за счёт общих признаков.
import numpy as np
from ray.rllib.models.modelv2 import ModelV2
from ray.rllib.models.tf.recurrent_net import RecurrentNetwork
from ray.rllib.utils.annotations import override
import tensorflow as tf
from ncps.tf import CfC
class ConvCfCModel(RecurrentNetwork):
"""Example of using the Keras functional API to define a RNN model."""
def __init__(
self,
obs_space,
action_space,
num_outputs,
model_config,
name,
cell_size=64,
):
super(ConvCfCModel, self).__init__(
obs_space, action_space, num_outputs, model_config, name
)
self.cell_size = cell_size
# Define input layers
input_layer = tf.keras.layers.Input(
# rllib flattens the input
shape=(None, obs_space.shape[0] * obs_space.shape[1] * obs_space.shape[2]),
name="inputs",
)
state_in_h = tf.keras.layers.Input(shape=(cell_size,), name="h")
seq_in = tf.keras.layers.Input(shape=(), name="seq_in", dtype=tf.int32)
# Preprocess observation with a hidden layer and send to CfC
self.conv_block = tf.keras.models.Sequential([
tf.keras.Input(
(obs_space.shape[0] * obs_spac.shapee[1] * obs_space.shape[2])
), # batch dimension is implicit
tf.keras.layers.Lambda(
lambda x: tf.cast(x, tf.float32) / 255.0
), # normalize input
# unflatten the input image that has been done by rllib
tf.keras.layers.Reshape((obs_space.shape[0], obs_space.shape[1], obs_space.shape[2])),
tf.keras.layers.Conv2D(
64, 5, padding="same", activation="relu", strides=2
),
tf.keras.layers.Conv2D(
128, 5, padding="same", activation="relu", strides=2
),
tf.keras.layers.Conv2D(
128, 5, padding="same", activation="relu", strides=2
),
tf.keras.layers.Conv2D(
256, 5, padding="same", activation="relu", strides=2
),
tf.keras.layers.GlobalAveragePooling2D(),
])
self.td_conv = tf.keras.layers.TimeDistributed(self.conv_block)
dense1 = self.td_conv(input_layer)
cfc_out, state_h = CfC(
cell_size, return_sequences=True, return_state=True, name="cfc"
)(
inputs=dense1,
mask=tf.sequence_mask(seq_in),
initial_state=[state_in_h],
)
# Postprocess CfC output with another hidden layer and compute values
logits = tf.keras.layers.Dense(
self.num_outputs, activation=tf.keras.activations.linear, name="logits"
)(cfc_out)
values = tf.keras.layers.Dense(1, activation=None, name="values")(cfc_out)
# Create the RNN model
self.rnn_model = tf.keras.Model(
inputs=[input_layer, seq_in, state_in_h],
outputs=[logits, values, state_h],
)
self.rnn_model.summary()
@override(RecurrentNetwork)
def forward_rnn(self, inputs, state, seq_lens):
model_out, self._value_out, h = self.rnn_model([inputs, seq_lens] + state)
return model_out, [h]
@override(ModelV2)
def get_initial_state(self):
return [
np.zeros(self.cell_size, np.float32),
]
@override(ModelV2)
def value_function(self):
return tf.reshape(self._value_out, [-1])После определения модели её можно зарегистрировать в rllib:
from ray.rllib.models import ModelCatalog
ModelCatalog.register_custom_model("cfc", ConvCfCModel)Определяем алгоритм обучения с подкреплением и его гиперпараметры
Каждый алгоритм RL опирается на дюжину гиперпараметров, которые способны оказать огромное влияние на эффективность обучения, и PPO здесь не исключение. К счастью, авторы rllib предоставили конфигурацию, которая прилично работает с PPO и средами Atari. Этой конфигурацией мы и воспользуемся:
import argparse
import os
import gym
from ray.tune.registry import register_env
from ray.rllib.algorithms.ppo import PPO
import time
import ale_py
from ray.rllib.env.wrappers.atari_wrappers import wrap_deepmind
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--env", type=str, default="ALE/Breakout-v5")
parser.add_argument("--cont", default="")
parser.add_argument("--render", action="store_true")
parser.add_argument("--hours", default=4, type=int)
args = parser.parse_args()
register_env("atari_env", lambda env_config: wrap_deepmind(gym.make(args.env)))
config = {
"env": "atari_env",
"preprocessor_pref": None,
"gamma": 0.99,
"num_gpus": 1,
"num_workers": 16,
"num_envs_per_worker": 4,
"create_env_on_driver": True,
"lambda": 0.95,
"kl_coeff": 0.5,
"clip_rewards": True,
"clip_param": 0.1,
"vf_clip_param": 10.0,
"entropy_coeff": 0.01,
"rollout_fragment_length": 100,
"sgd_minibatch_size": 500,
"num_sgd_iter": 10,
"batch_mode": "truncate_episodes",
"observation_filter": "NoFilter",
"model": {
"vf_share_layers": True,
"custom_model": "cfc",
"max_seq_len": 20,
"custom_model_config": {
"cell_size": 64,
},
},
"framework": "tf2",
}
algo = PPO(config=config)При запуске алгоритма создаются контрольные точки, которые мы сможем восстановить позже. Эти точки сохраним в папке rl_ckpt и добавим восстановление по идентификатору контрольной точки, переданному с аргументом --cont:
os.makedirs(f"rl_ckpt/{args.env}", exist_ok=True)
if args.cont != "":
algo.load_checkpoint(f"rl_ckpt/{args.env}/checkpoint-{args.cont}")Визуализация взаимодействия политики и среды
Чтобы показать, как именно обученная политика играет в игру Atari, нужно написать функцию, которая включает режим среды render_mode и выполняет политику в замкнутом цикле.
Для вычисления действий воспользуемся функцией в объекте алгоритма — это compute_single_action, но об инициализации скрытого состояния RNN нужно позаботиться самостоятельно:
def run_closed_loop(algo, config):
env = gym.make(args.env, render_mode="human")
env = wrap_deepmind(env)
rnn_cell_size = config["model"]["custom_model_config"]["cell_size"]
obs = env.reset()
state = init_state = [np.zeros(rnn_cell_size, np.float32)]
while True:
action, state, _ = algo.compute_single_action(
obs, state=state, explore=False, policy_id="default_policy"
)
obs, reward, done, _ = env.step(action)
if done:
obs = env.reset()
state = init_stateЗапускаем PPO
А теперь запускаем алгоритм обучения с подкреплением. Игру сети программа показывает, если прописан аргумент --render:
if args.render:
run_closed_loop(
algo,
config,
)
else:
start_time = time.time()
last_eval = 0
while True:
info = algo.train()
if time.time() - last_eval > 60 * 5: # every 5 minutes print some stats
print(f"Ran {(time.time()-start_time)/60/60:0.1f} hours")
print(
f" sampled {info['info']['num_env_steps_sampled']/1000:0.0f}k steps"
)
print(f" policy reward: {info['episode_reward_mean']:0.1f}")
last_eval = time.time()
ckpt = algo.save_checkpoint(f"rl_ckpt/{args.env}")
print(f" saved checkpoint '{ckpt}'")
elapsed = (time.time() - start_time) / 60 # in minutes
if elapsed > args.hours * 60:
breakВесь исходный код вы найдёте здесь.
На современном настольном компьютере требуется около часа, чтобы получить возврат 20, и около 4 часов, чтобы достичь возврата 50.
Для сред Atari rllib различает два возврата: эпизодический (то есть с 1 жизнью в игре) и игровой (с тремя жизнями), поэтому возврат, сообщаемый rllib, может отличаться о полученного при оценке модели с обратной связью.
Вывод скрипта выглядит примерно так:
> Ran 0.0 hours
> sampled 4k steps
> policy reward: nan
> saved checkpoint 'rl_ckpt/ALE/Breakout-v5/checkpoint-1'
> Ran 0.1 hours
> sampled 52k steps
> policy reward: 1.9
> saved checkpoint 'rl_ckpt/ALE/Breakout-v5/checkpoint-13'
> Ran 0.2 hours
> sampled 105k steps
> policy reward: 2.6
> saved checkpoint 'rl_ckpt/ALE/Breakout-v5/checkpoint-26'
> Ran 0.3 hours
> sampled 157k steps
> policy reward: 3.4
> saved checkpoint 'rl_ckpt/ALE/Breakout-v5/checkpoint-39'
> Ran 0.4 hours
> sampled 210k steps
> policy reward: 6.7
> saved checkpoint 'rl_ckpt/ALE/Breakout-v5/checkpoint-52'
> Ran 0.4 hours
> sampled 266k steps
> policy reward: 8.7
> saved checkpoint 'rl_ckpt/ALE/Breakout-v5/checkpoint-66'
> Ran 0.5 hours
> sampled 323k steps
> policy reward: 10.5
> saved checkpoint 'rl_ckpt/ALE/Breakout-v5/checkpoint-80'
> Ran 0.6 hours
> sampled 379k steps
> policy reward: 10.7
> saved checkpoint 'rl_ckpt/ALE/Breakout-v5/checkpoint-94'
...А полезная теория и ещё больше практики с погружением в среду IT ждут вас на наших курсах:

Data Science и Machine Learning
- Профессия Data Scientist
- Профессия Data Analyst
- Курс «Математика для Data Science»
- Курс «Математика и Machine Learning для Data Science»
- Курс по Data Engineering
- Курс «Machine Learning и Deep Learning»
- Курс по Machine Learning
Python, веб-разработка
- Профессия Fullstack-разработчик на Python
- Курс «Python для веб-разработки»
- Профессия Frontend-разработчик
- Профессия Веб-разработчик
Мобильная разработка
Java и C#
- Профессия Java-разработчик
- Профессия QA-инженер на JAVA
- Профессия C#-разработчик
- Профессия Разработчик игр на Unity
От основ — в глубину
А также
Комментарии (5)

netricks
00.00.0000 00:00+1Расскажите кто-нибудь простыми словами, в чем суть изобретения?

Celsius
00.00.0000 00:00+1Судя по оригинальной статье сеть на исходных данных не учится напрямую, а вычленяет из них векторное пространство и на основе найденных закономерностей строится уравнение аппроксимирующее некоторый набор функций, эта аппроксимация и служит преобразователем данных. Эффективность выше чем у LSTM, но точность ниже.
Идея очень интересная, но подход пока не очень понятный. Это похоже на резервуарные вычисления, только без резервуаров.

iskateli
00.00.0000 00:00Еле нашёл статью. А почему статься не в разделе "Машинное обучение"? Это же чистой воды машинное обучение.

konstando
00.00.0000 00:00"Жидкая", "ликвидная" и "текучая" - это же такой перевод слова liquid. Да? ;-)
TiesP
Крутейшая идея! Давно хотел с такой архитектурой поиграться. Понятно же, что соединение "каждый с каждым" как в FC - это тупик.