Увидев очередную статью об утомившем всех Chat GPT от Open AI, рука невольно тянется в пистолету минусатору. Ну, в самом деле, сколько можно? Уже, кажется, все успели поиграть с чатом во всех возможных сценариях.
Однако один аспект, почему‑то, почти не затронут как на Хабре, так и в Рунете. Почему же все‑таки Chat GPT говорит по‑русски с весьма специфическим акцентом, который условно можно назвать «нейронным говорком»?
Чтобы понять суть вопроса, обратимся к теории. Чем занимается генеративная нейронная сеть такого типа?
Говоря просто и коротко она получает на вход набор токенов, пропускает их через некий «черный ящик» и выдает другой набор токенов. Вероятность выбора конкретного токена для ответа зависит от набора входящих токенов и конкретных настроек.
Но что же такое «токен»? Интересный факт заключается в том, что для английского языка токеном обычно выступают сочетания символов, зачастую совпадающие с короткими словами или часто встречающимися частями слов.
Возьмем, например, английскую панграмму:
“The quick brown fox jumps over the lazy dog”
Напомню, что панграмма — это предложение из минимального числа слов, содержащая в себе все буквы алфавита.
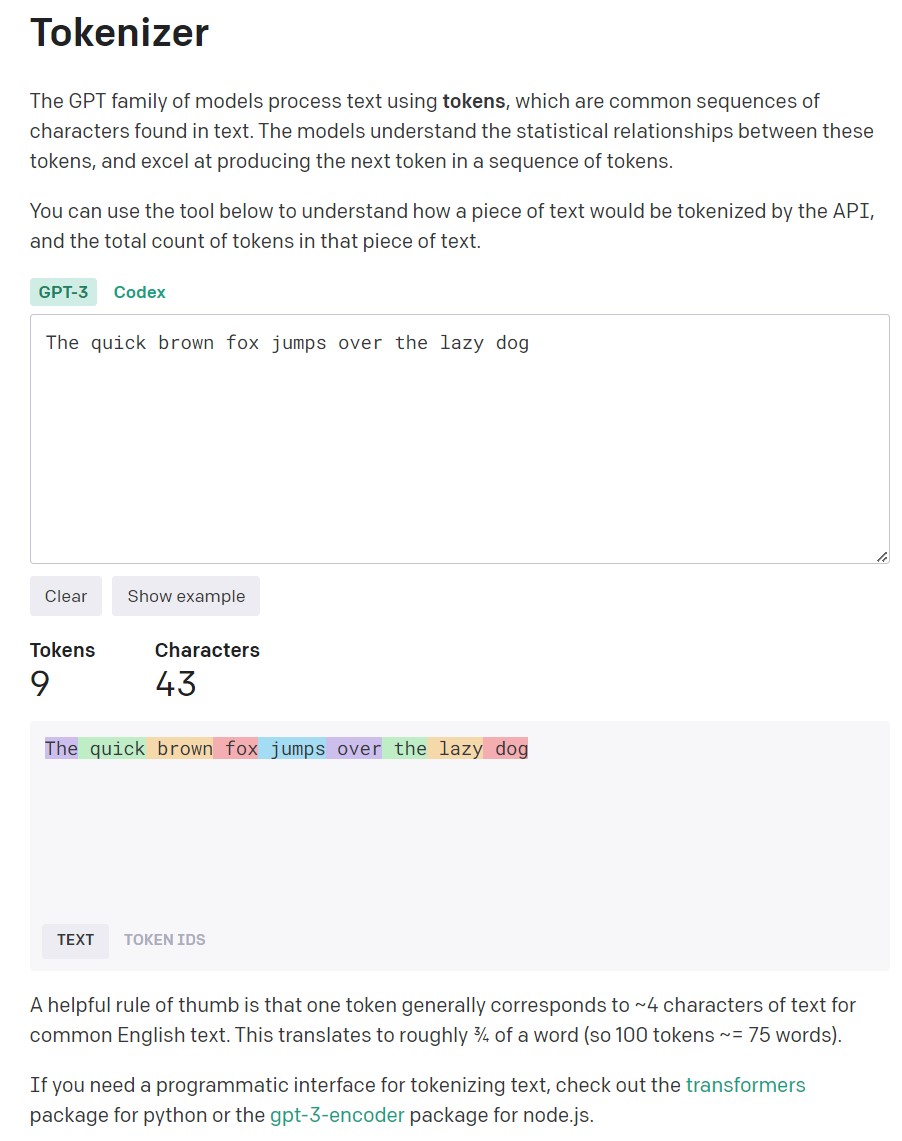
Официальный токенайзер Open AI
Показывает, что в этом предложении всего 9 токенов, содержащих 43 символа.
Однако с русским языком токенайзер Open AI работает совершенно иначе.
Популярная панграмма русского алфавита:
«Съешь ещё этих мягких французских булок, да выпей чаю»
Содержит 53 символа, однако на «упаковку» этой фразы токенизатору Open AI требуется 70 (Sic!) токенов.

Получается, что на вопросы на английском языке Chat GPT отвечает по словам, а на вопросы на русском языке он отвечает по буквам.
По сути выходит, что при общении на русском языке чат GPT как‑бы пропускает один дополнительный слой связанности. Тем удивительнее оказывается его умение генерировать осмысленный ответ на русском языке даже по буквам.
Кстати, специфику токенизации русского языка важно учитывать при использовании API Open AI и при работе в его песочнице.
Особо осторожно следует использовать параметр «Frequency penalty» (FP) (штраф за частоту повторов токенов), который регулирует вероятность повторения уже использованных токенов.
По задумке создателей «Frequency penalty» — снижает вероятность повторного использования слова в ответе нейросети.
Однако, то, что работает с английским текстом не работает с русским, так как начинают штрафоваться просто повторы использования букв. И нейросети приходится идти на ухищрения, заменяя русские буквы латиницей, а потом и вовсе всем набором ASCII.
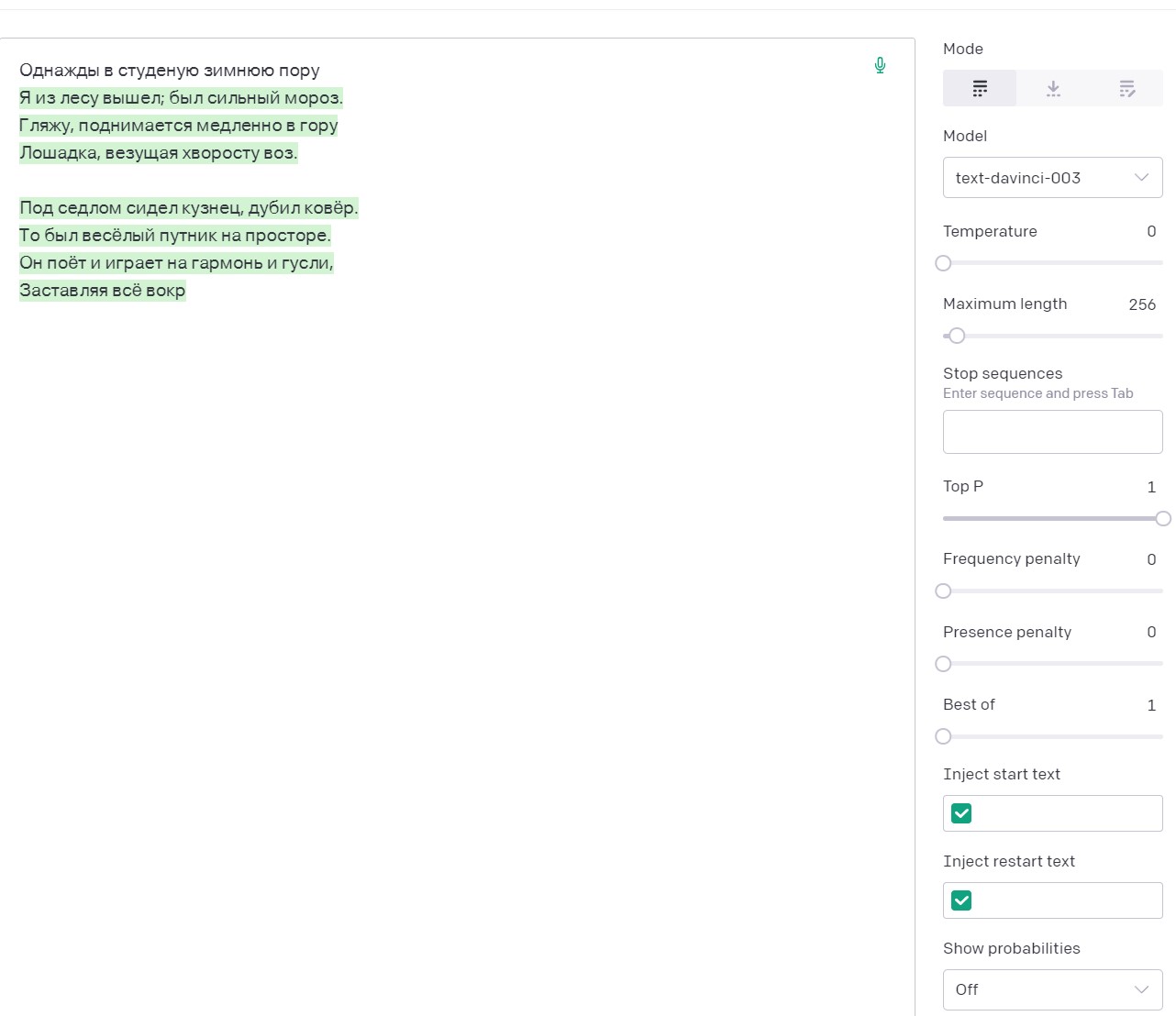
Например, затравка «Однажды в студеную зимнюю пору» в сочетанной с температурой установленной на 0, закономерно дает ожидаемое четверостишье Некрасова и лишь затем начинаются небольшие фантазии.
Та же затравка с FP=2, вначале также вспоминает Некрасова, но затем быстро переходит на латиницу.
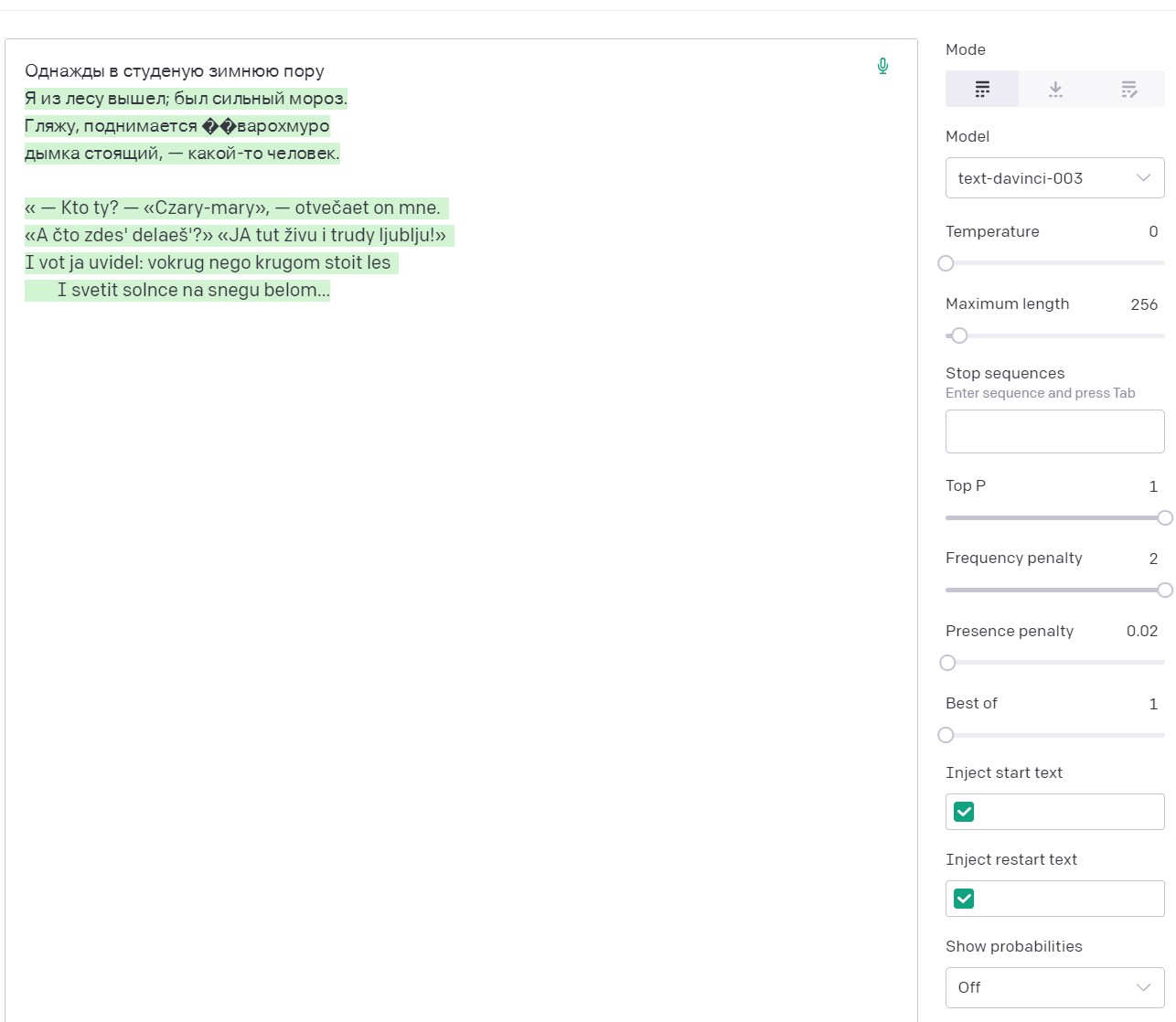
В целом, эта ситуация помогает понять нам специфику того, как нейронная сеть понимает вопросы и генерирует ответы.
Ну и, разумеется, становится понятным почему у неройсети от Open AI возникает нейронный акцент. Слова в русском языке имеют склонения, спряжения и согласования по роду, числу, времени и т. п., которые формируются в первую очередь за счет окончаний. И зачастую в пограничной ситуации вероятность той или иной буквы в окончании для нейросети колеблется примерно на одном уровне. И она делает простительные иностранцу ошибки.
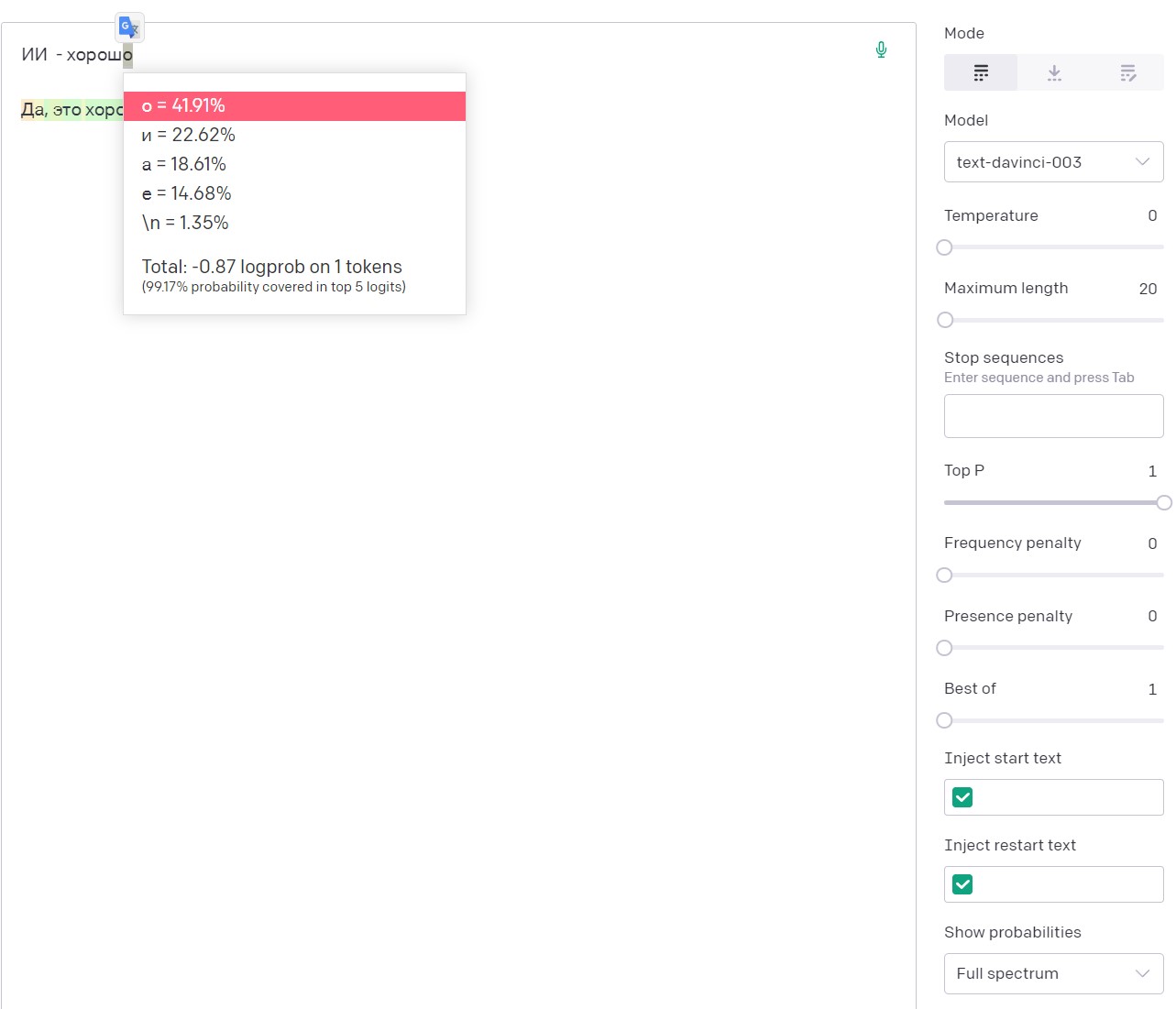
Кстати, для лучшего понимания специфики подбора очередного токена Open AI, можно в песочнице включить опцию показа вероятностей ответов Show probabilities → Full spectrum, которая покажет пять наиболее вероятных вариантов очередного токена с его конкретной вероятностью.
Видно, что с затравкой:
«ИИ — хорош»
Вероятность того, что после буквы «ш» идет токен «о» — составляет почти 42%
Итак, можно подвести итог. Специфика ответов на русском языке, сгенерированных нейронной сетью GPT-3.5 от Open AI, в первую очередь обусловлена не объемом выборки, а подходом к токенизации текста на кириллице. При работе с сетью, и в частности с ее API нужно учитывать, что при токенизации русского языка один символ <= 1 токену. Это приводит к быстрому исчерпанию лимита токенов и делает некоторые настройки (в частности FP) чрезвычайно чувствительными.
Самым актуальным остается вопрос: насколько особенности токенизации русского языка влияет на работу со смыслом текста?
А именно:
На каком уровне у нейросети возникает осмысленный ответ? (Конечно, не в том смысле, что она его понимает, а в том, что внутри сети возникает адекватная вопросу смысловая конструкция)
То‑есть формирует ли сначала нейросеть смысл ответа, а лишь затем переводит его в язык ответа (Английский или Русский)?
Или смысл проявляется непосредственно в процессе ответа?
Очевидно, что в первом случае глубина и осмысленность ответов на разных языках отличаться не будет. А во‑втором случае можно ожидать изменение качества смыслового наполнения ответа в зависимости от языка на котором отвечает модель.
Пока что я не пришел к определенному выводу. Понятно лишь, что на английском языке чат отвечает быстрее и корректнее с точки зрения грамматики. Но это полностью объяснимо спецификой токенизации в Open AI.
Буду благодарен за ваши мнения по этому вопросу.
Комментарии (25)


Medeyko
00.00.0000 00:00+3Да уж, для такой токенизации даже как-то и неплохо тексты на русском генерируются.
Но вообще, по-моему, это выглядит как позорный ляп создателей ChatGPT...

MAXH0
00.00.0000 00:00+5"Позорный ляп" - это слишком громко. НО я думаю если бы делал Яндекс, который собаку и пуд соли съел на русской грамматике, то результат был бы более вменяемым. Поживём - оценим.
Medeyko
00.00.0000 00:00+5Вопрос не в грамматике. Вопрос в том, что они UTF-8 не разбирают, а прямо как есть, так и пихают, как я понял. Создаётся ощущение, что они вообще не запаривались тем, что существуют символы за пределами ASCII.

thevlad
00.00.0000 00:00+3UTF-8 вряд ли, а вот то что токены связаны с энтропией вполне возможно. (часто встречающиеся входные последовательности отображаются более "плотно" в токены, а менее наоборот)
Medeyko
00.00.0000 00:00+1Одно другому не мешает. Точнее, как раз типа и мешает: имеено то, что UTF-8 прямо байтами и пихается и парсинга, мешает эффективно работать с энтропией. По поводу UTF-8 - посмотрите на пример выше, там видно, что для букв "с" и "ъ", например, показаны отдельные токены на каждый из двух байтов UTF-8 кода.
thevlad
00.00.0000 00:00Да, вы в общем правы. Но к кодированию байтами пришли как раз из этих соображений, минимизации базового словаря(и энтропии).
а вот и пэйпер с которого началось Neural Machine Translation with Byte-Level Subwords

exwill
00.00.0000 00:00В рамках своих исследований, я задаю вопрос "Сколько чая на основном складе" и прошу дать текст запроса SQL. Что интересно, я всегда получаю совершенно правильную конструкцию
WHERE Товар.Наименование='чай' AND Склад.Наименование='основной'
Я экспериментировал с разными словами. Пока не заметил никакой путаницы в падежах. Видимо, побуквенная токенизация работает хорошо.

kryvichh
00.00.0000 00:00Хорошее замечание. Поскольку токен - это единица информации для нейросети, как бит для компьютера, мелкие токены несомненно влияют на качество работы ChatGPT c неанглийскими текстами.


m0rg0t
00.00.0000 00:00+1Я когда почитал решил проверить еще одну странную теорию.
А что будет если мы русский текст транслитерируем, что будет с генерацией и количеством токенов?
Про количество токенов: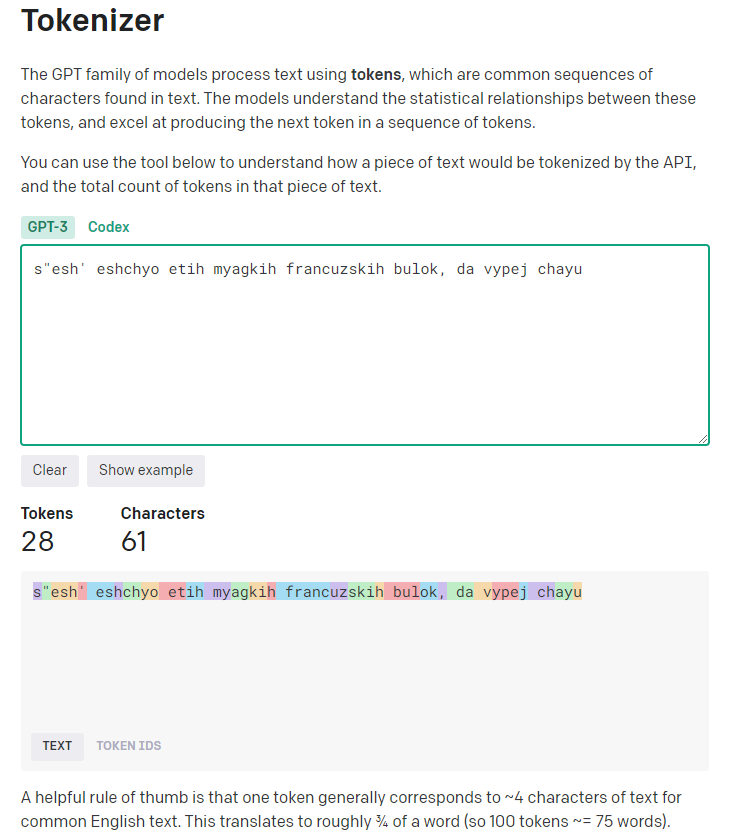
При транслитерированном тексте мы экономим количество токенов (70 против 28)
А что с основной функцией дополнения текста?
Она вполне нормально отрабатывает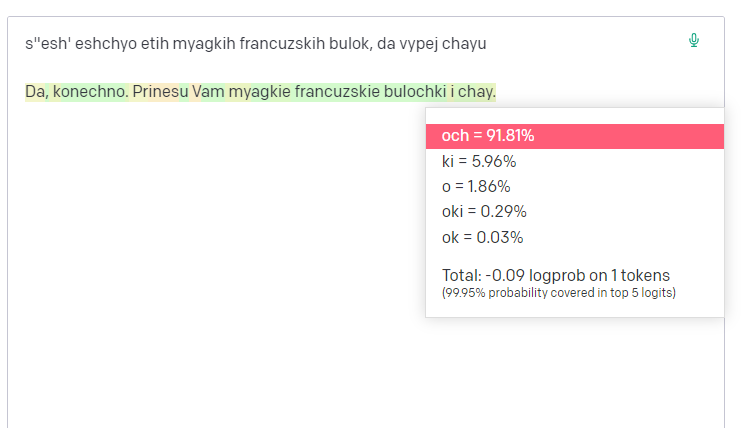
Поэтому если покопаться и делать транслитерацию и детранслитерацию текста потенциально можно половину бюджета экономить, если гипотеза и мой единичный тест на больших объемах будет работать



LordDarklight
00.00.0000 00:00Ну, только лишь русским и английскими языками же вся мировая лингвистика не ограничивается же. Что там с другими языками?
Можно предположить, что всякие латинские языки всё-таки будут более коррелировать с токенизацией слов. А вот, "условно" килилические (славянская группа). Вообще я в группах языков не особо разбираюсь, и мне трудно привести примеры кроме русского, украинского и беларусского языков. Возможно болгарский, польский, сербский языки сюда тоже относятчя.
Азиатские же языки - это явно другая группа - там разбор должен быть строго по отдельным иероглифам.
Арабские и тюркские языки тоже стоят особняком.
Короче - тут ещё столько разным лингвистических особенностей - мама не горюй. Но вот как с ними обстоят дела у ChatGPT - ждём продолжения анализа, короче...
thevlad
00.00.0000 00:00Токенизатор там как раз более-менее стандартный, по крайней мере в gpt-3 был такой. https://arxiv.org/pdf/1909.03341.pdf
В лучших традициях современного DS/NLP. Насколько я понимаю, сплит делается только по границе слов. Все остальное просто байтики в utf-8 с забавными статистическими свойствами.

MishaRash
00.00.0000 00:00Можно предположить, что у токенайзера будет больше проблем с синтетическими языками с родами, падежами и разнообразным спряжением, где слова сильнее изменяются при образовании связей между ними. В английском такого значительно меньше, чем в русском или украинском (а также, вероятно, латыни, испанском, немецком и греческом). В китайском вроде ещё чаще слова составляются из частей совсем без изменений, как в более аналитическом языке.
Кстати, есть ещё такая проблема, что в арабском алфавите буквы выглядят по-разному в начале, середине и конце слова, а также если в слове только одна буква. Точно не знаю, как это кодируется там, но в иврите, где только у 5 букв из 22 сейчас есть вторая отдельная конечная форма, коды разных форм разные (хоть и соседние). Может быть нетривиально их соотнести, если специально не учесть.

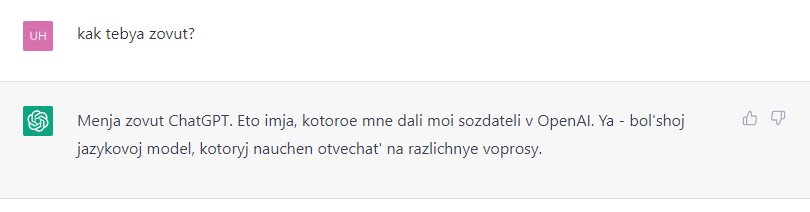
uhf
00.00.0000 00:00+1Я уверен, что в чате переводчик на входе и выходе стоит, а токенайзер натренирован только на английский.

AlexKimen Автор
00.00.0000 00:00Да. Сейчас дорвался до нового Бинга. И судя по всему так и есть. Переводчик на входе и выходе. Для сохранения смысла это хорошо, а вот для грамматики - не очень.

Simpre_falta_algo
00.00.0000 00:00Именно так. Вот цитата:
Когда я задаю вопрос на русском ты сначала переводишь на англ, потом генерируешь ответ тоже на англ и далее переводишь, если я прошу на русский. Так?
Да, вы правы. Как я являюсь моделью, обученной на английском языке, я принимаю запросы на английском языке. Поэтому, когда вы задаете вопрос на русском языке, я сначала перевожу его на английский язык, генерирую ответ на английском языке и затем перевожу его обратно на русский язык, если вы запросили ответ на русском языке.



Lerax116
00.00.0000 00:00Автор, скорее всего не совсем знаком с концепцией Byte-level BPE. В исследованиях наглядно показывалось, что для ряда языков токены данного типа не декодируемы по отдельности. При этом определенное сочетание токенов может сразу декдироваться как слово. Так что само по себе большое число токенов не говорит об character-level токенищации, в данном случае.
Ну и, кроме того, словарь ChatGPT оптимизмровался по обучающей выборке GPT-3, в которой, судя по всему, было только 0.11% русского текста. Естественно BPE под такие токены не обобщился.
Discivery
00.00.0000 00:00Тут без вариантов - сначала перевод, потом токенизация и обработка, затем обратный перевод.
rafuck
<offtop> Вообще говоря, известная фраза про булки и чай содержит не все буквы алфавита. Мой вариант: Съешь ещё этих мягких французских булок, да выпей же чаю. </offtop>
garryq
И без запятой, конечно.