В последнее время нам почти каждый день рассказывают в новостях, какие очередные вершины покорили языковые нейросетки, и почему они уже через месяц совершенно точно оставят лично вас без работы. При этом мало кто понимает — а как вообще нейросети вроде ChatGPT работают внутри? Так вот, устраивайтесь поудобнее: в этой статье мы наконец объясним всё так, чтобы понял даже шестилетний гуманитарий!
 основали в 2015 году именно вот эти двое парнишек – кто бы тогда знал, во что это в итоге выльется...")
На всякий случай сразу оговоримся: у этой статьи два автора. За всю техническую часть (и за всё хорошее в статье) отвечал Игорь Котенков — широко известный чувак в узких кругах русскоязычной тусовки специалистов по искусственному интеллекту, а также автор канала Сиолошная про машинное обучение, космос и технологии. За мольбы «вот тут непонятно, давай как‑нибудь попроще!» и за добавление кринжовых неуместных мемов был ответственен Павел Комаровский — автор канала RationalAnswer про рациональный подход к жизни и финансам.
Собственно, статья так и родилась: Павел пришел к Игорю и возмутился — дескать, «почему никто еще не написал на русском нормальную статью про ChatGPT, объясняющую понятно даже для моей бабушки, как всё вот это нейроколдунство работает?». Так что заранее приносим свои извинения всем хардкорным технарям: при подготовке этого текста мы стремились к максимальному упрощению. Нашей задачей было — дать читателям общее понимание принципов работы языковых нейросетей на уровне концепций и аналогий, а не разобрать до последнего винтика все глубокие технические нюансы процесса.
В общем, наливайте себе кружечку горячего чая и устраивайтесь поудобнее — сейчас мы вам расскажем всё про то, что там крутится под капотом у языковых моделей, каким образом эти покемоны эволюционировали до текущих (местами поразительных) способностей, и почему взрывная популярность чат‑бота ChatGPT стала полным сюрпризом даже для его создателей. Поехали!
Навигатор
Парадокс Барака, или зачем языковым моделям уметь в творчество
2019: GPT-2, или как запихнуть в языковую модель семь тысяч Шекспиров
Почему в мире языковых моделей больше ценятся именно модели «Plus Size»
Январь 2022: InstructGPT, или как научить робота не зиговать
T9: сеанс языковой магии с разоблачением
Начнем с простого. Чтобы разобраться в том, что такое ChatGPT с технической точки зрения, надо сначала понять, чем он точно не является. Это не «Бог из машины», не разумное существо, не аналог школьника (по уровню интеллекта и умению решать задачи), не джинн, и даже не обретший дар речи Тамагочи. Приготовьтесь услышать страшную правду: на самом деле, ChatGPT — это Т9 из вашего телефона, но на бычьих стероидах! Да, это так: ученые называют обе этих технологии «языковыми моделями» (Language Models); а всё, что они по сути делают, — это угадывают, какое следующее слово должно идти за уже имеющимся текстом.
Ну, точнее, в совсем олдовых телефонах из конца 90-х (вроде культовой неубиваемой Nokia 3210) оригинальная технология Т9 лишь ускоряла набор на кнопочных телефонах за счет угадывания текущего вводимого, а не следующего слова. Но технология развивалась, и к эпохе смартфонов начала 2010-х она уже могла учитывать контекст (предыдущее слово), ставить пунктуацию и предлагать на выбор слова, которые могли бы идти следующими. Вот именно об аналогии с такой «продвинутой» версией T9/автозамены и идет речь.

Итак, и Т9 на клавиатуре смартфона, и ChatGPT обучены решать до безумия простую задачу: предсказание единственного следующего слова. Это и есть языковое моделирование – когда по некоторому уже имеющемуся тексту делается вывод о том, что должно быть написано дальше. Чтобы иметь возможность делать такие предсказания, языковым моделям под капотом приходится оперировать вероятностями возникновения тех или иных слов для продолжения. Ведь, скорее всего, вы были бы недовольны, если бы автозаполнение в телефоне просто подкидывало вам абсолютно случайные слова с одинаковой вероятностью.
Представим для наглядности, что вам прилетает сообщение от приятеля: «Чё, го седня куда нить?». Вы начинаете печатать в ответ: «Да не, у меня уже дела(( я иду в...», и вот тут подключается Т9. Если он предложит вам закончить предложение полностью рандомным словом, типа «я иду в капибару» — то для такой белиберды, если честно, никакая хитрая языковая модель особо и не нужна. Реальные же модели автозаполнения в смартфонах подсказывают гораздо более уместные слова (можете сами проверить прямо сейчас).

Так, а как конкретно Т9 понимает, какие слова будут следовать за уже набранным текстом с большей вероятностью, а какие предлагать точно не стоит? Для ответа на этот вопрос нам придется погрузиться в базовые принципы работы самых простейших нейросеток.
Откуда нейросети берут вероятности слов?
Давайте начнем с еще более простого вопроса: а как вообще предсказывать зависимости одних вещей от других? Предположим, мы хотим научить компьютер предсказывать вес человека в зависимости от его роста — как подойти к этой задаче?
Здравый смысл подсказывает, что надо сначала собрать данные, на которых мы будем искать интересующие нас зависимости (для простоты ограничимся одним полом — возьмем статистику по росту/весу для нескольких тысяч мужчин), а потом попробуем «натренировать» некую математическую модель на поиск закономерности внутри этих данных.
Для наглядности сначала нарисуем весь наш массив данных на графике: по горизонтальной оси будем откладывать рост в сантиметрах, а по вертикальной оси
— вес.
")
Даже невооруженным взглядом видна определенная зависимость: высокие мужики, как правило, больше весят (спасибо, кэп!). И эту зависимость довольно просто выразить в виде обычного линейного уравнения , знакомого нам всем с пятого класса школы. На картинке нужная нам линия уже проведена с помощью модели линейной регрессии — по сути, она позволяет подобрать коэффициенты уравнения
и
таким образом, чтобы получившаяся линия оптимально описывала ключевую зависимость в нашем наборе данных (можете для интереса подставить свой рост в сантиметрах вместо
в уравнение на картинке и проверить, насколько точно наша модель угадает ваш вес).
Вы тут уже наверняка хотите воскликнуть: «Окей, с ростом/весом и так интуитивно всё было понятно, только причем тут вообще языковые нейросети?» А притом, что нейросети — это и есть набор примерно тех же самых уравнений, только куда более сложных и использующих матрицы (но не будем сейчас об этом).
Можно упрощенно сказать, что те же самые T9 или ChatGPT — это всего лишь хитрым образом подобранные уравнения, которые пытаются предсказать следующее слово (игрек) в зависимости от набора подаваемых на вход модели предыдущих слов (иксов). Основная задача при тренировке языковой модели на наборе данных — подобрать такие коэффициенты при этих иксах, чтобы они действительно отражали какую‑то зависимость (как в нашем примере с ростом/весом). А под большими моделями мы далее будем понимать такие, которые имеют очень большое количество параметров. В области ИИ их прямо так и называют — LLM, Large Language Models. Как мы увидим чуть дальше, «жирная» модель с множеством параметров — это залог успеха для генерации крутых текстов!
Кстати, если вы в этом месте уже недоумеваете, почему мы всё время говорим о «предсказании одного следующего слова», тогда как тот же ChatGPT бодро отвечает целыми портянками текста – то не ломайте зря голову. Языковые модели без всякого труда генерируют длинные тексты, но делают они это по принципу «слово за словом». По сути, после генерации каждого нового слова, модель просто заново прогоняет через себя весь предыдущий текст вместе с только что написанным дополнением – и выплевывает последующее слово уже с учетом него. В результате получается связный текст.
Парадокс Барака, или зачем языковым моделям уметь в творчество
На самом деле, в наших уравнениях в качестве «игрека» языковые модели пытаются предсказать не столько конкретное следующее слово, сколько вероятности разных слов, которыми можно продолжить заданный текст. Зачем это нужно, почему нельзя всегда искать единственное, «самое правильное» слово для продолжения? Давайте разберем на примере небольшой игры.
Правила такие: вы притворяетесь языковой моделью, а я вам предлагаю продолжить текст «44-й президент США (и первый афроамериканец на этой должности) — это Барак...». Подставьте слово, которое должно стоять вместо многоточия, и оцените вероятность, что оно там действительно окажется.

Если вы сейчас сказали, что следующим словом должно идти «Обама» с вероятностью 100%, то поздравляю — вы ошиблись! И дело тут не в том, что существует какой‑то другой мифический Барак: просто в официальных документах имя президента часто пишется в полной форме, с указанием его второго имени (middle name) — Хуссейн. Так что правильно натренированная языковая модель должна, по‑хорошему, предсказать, что в нашем предложении «Обама» будет следующим словом только с вероятностью условно в 90%, а оставшиеся 10% выделить на случай продолжения текста «Хуссейном» (после которого последует Обама уже с вероятностью, близкой к 100%).
И тут мы с вами подходим к очень интересному аспекту языковых моделей: оказывается, им не чужда творческая жилка! По сути, при генерации каждого следующего слова, такие модели выбирают его «случайным» образом, как бы кидая кубик. Но не абы как — а так, чтобы вероятности «выпадения» разных слов примерно соответствовали тем вероятностям, которые подсказывают модели зашитые внутрь нее уравнения (выведенные при обучении модели на огромном массиве разных текстов).
Получается, что одна и та же модель даже на абсолютно одинаковые запросы может давать совершенно разные варианты ответа — прямо как живой человек. Вообще, ученые когда‑то пытались заставить нейронки всегда выбирать в качестве продолжения «наиболее вероятное» следующее слово — что на первый взгляд звучит логично, но на практике такие модели почему‑то работают хуже; а вот здоровый элемент случайности идет им строго на пользу (повышает вариативность и, в итоге, качество ответов).

Вообще, наш язык — это особая структура с (иногда) четкими наборами правил и исключений. Слова в предложениях не появляются из ниоткуда, они связаны друг с другом. Эти связи неплохо выучиваются человеком «в автоматическом режиме» — во время взросления и обучения в школе, через разговоры, чтение, и так далее. При этом для описания одного и того же события или факта люди придумывают множество способов в разных стилях, тонах и полутонах. Подход к языковой коммуникации у гопников в подворотне и, к примеру, у учеников младшей школы будет, скорее всего, совсем разным.
Всю эту вариативность описательности языка и должна в себя вместить хорошая модель. Чем точнее модель оценивает вероятности слов в зависимости от нюансов контекста (предшествующей части текста, описывающей ситуацию) — тем лучше она способна генерировать ответы, которые мы хотим от нее услышать.

Краткое резюме: На текущий момент мы выяснили, что несложные языковые модели применяются в функциях «T9/автозаполнения» смартфонов с начала 2010-х; а сами эти модели представляют собой набор уравнений, натренированных на больших объемах данных предсказывать следующее слово в зависимости от поданного «на вход» исходного текста.
2018: GPT-1 трансформирует языковые модели
Давайте уже переходить от всяких дремучих T9 к более современным моделям: наделавший столько шума ChatGPT является наиболее свежим представителем семейства моделей GPT. Но чтобы понять, как ему удалось обрести столь необычные способности радовать людей своими ответами, нам придется сначала вернуться к истокам.
GPT расшифровывается как Generative Pre‑trained Transformer, или «трансформер, обученный на генерацию текста». Трансформер — это название архитектуры нейросети, придуманной исследователями Google в далеком 2017 году (про «далекий» мы не оговорились: по меркам индустрии, прошедшие с тех пор шесть лет — это целая вечность).
Именно изобретение Трансформера оказалось столь значимым, что вообще все области искусственного интеллекта (ИИ) — от текстовых переводов и до обработки изображений, звука или видео — начали его активно адаптировать и применять. Индустрия ИИ буквально получила мощную встряску: перешла от так называемой «зимы ИИ» к бурному развитию, и смогла преодолеть застой.

Концептуально, Трансформер — это универсальный вычислительный механизм, который очень просто описать: он принимает на вход один набор последовательностей (данных) и выдает на выходе тоже набор последовательностей, но уже другой — преобразованный по некоему алгоритму. Так как текст, картинки и звук (да и вообще почти всё в этом мире) можно представить в виде последовательностей чисел — то с помощью Трансформера можно решать практически любые задачи.
Но главная фишка Трансформера заключается в его удобстве и гибкости: он состоит из простых модулей‑блоков, которые очень легко масштабировать. Если старые, до‑трансформерные языковые модели начинали кряхтеть и кашлять (требовать слишком много ресурсов), когда их пытались заставить «проглотить» быстро и много слов за раз, то нейросети‑трансформеры справляются с этой задачей гораздо лучше.
Более ранним подходам приходилось обрабатывать входные данные по принципу «один за другим», то есть последовательно. Поэтому, когда модель работала с текстом длиной в одну страницу, то уже к середине третьего параграфа она забывала, что было в самом начале (прямо как люди с утра, до того как они «бахнув кофейку»). А вот могучие лапища Трансформера позволяют ему смотреть на ВСЁ одновременно — и это приводит к гораздо более впечатляющим результатам.
")
Именно это позволило сделать прорыв в нейросетевой обработке текстов (в том числе их генерации). Теперь модель не забывает: она переиспользует то, что уже было написано ранее, лучше держит контекст, а самое главное — может строить связи типа «каждое слово с каждым» на весьма внушительных объемах данных.
Краткое резюме: GPT-1 появилась в 2018 году и доказала, что для генерации текстов нейросетью можно использовать архитектуру Трансформера, обладающую гораздо большей масштабируемостью и эффективностью. Это создало огромный задел на будущее по возможности наращивать объем и сложность языковых моделей.
2019: GPT-2, или как запихнуть в языковую модель семь тысяч Шекспиров
Если вы хотите научить нейросетку для распознавания изображений отличать маленьких милых чихуабелей от маффинов с черничкой, то вы не можете просто сказать ей «вот ссылка на гигантский архив со 100 500 фотографий пёсов и хлебобулочных изделий — разбирайся!». Нет, чтобы обучить модель, вам нужно обязательно сначала разметить тренировочный набор данных — то есть, подписать под каждой фоткой, является ли она пушистой или сладкой.

А знаете, чем прекрасно обучение языковых моделей? Тем, что им можно «скармливать» совершенно любые текстовые данные, и эти самые данные заблаговременно никак не надо специальным образом размечать. Это как если бы в школьника можно было просто бросать чемодан с самыми разными книгами, без какой‑либо инструкции, что там и в каком порядке ему нужно выучить — а он бы сам в процессе чтения кумекал для себя какие‑то хитрые выводы!
Если подумать, то это логично: мы же хотим научить языковую модель предсказывать следующее слово на основе информации о словах, которые идут перед ним? Ну дак совершенно любой текст, написанный человеком когда‑либо, — это и есть уже готовый кусочек тренировочных данных. Ведь он уже и так состоит из огромного количества последовательностей вида «куча каких‑то слов и предложений => следующее за ними слово».
А теперь давайте еще вспомним, что обкатанная на GPT-1 технология Трансформеров оказалась на редкость удачной в плане масштабирования: она умеет работать с большими объемами данных и «массивными» моделями (состоящими из огромного числа параметров) гораздо эффективнее своих предшественников. Вы думаете о том же, о чем и я? Ну вот и ученые из OpenAI в 2019 году сделали такой же вывод: «Пришло время пилить здоровенные языковые модели!»

В общем, было решено радикально прокачать GPT-2 по двум ключевым направлениям: набор тренировочных данных (датасет) и размер модели (количество параметров).
На тот момент не было каких‑то специальных, больших и качественных, публичных наборов текстовых данных для тренировки языковых моделей — так что каждой команде специалистов по ИИ приходилось извращаться согласно их собственной степени испорченности. Вот ребята из OpenAI и решили поступить остроумно: они пошли на самый популярный англоязычный онлайн‑форум Reddit и тупо выкачали все гиперссылки из всех сообщений, имевших более трех лайков (я сейчас не шучу — научный подход, ну!). Всего таких ссылок вышло порядка 8 миллионов, а скачанные из них тексты весили в совокупности 40 гигабайт.
Много это или мало? Давайте прикинем: собрание сочинений Уильяма Шекспира (всех его пьес, сонетов и стихов) состоит из 850'000 слов. В среднем на одной странице книги помещается около 300 английских слов — так что 2800 страниц чудесного, временами устаревшего английского текста за авторством величайшего англоязычного писателя займет в памяти компьютера примерно 5,5 мегабайт. Так вот: это в 7300 раз меньше, чем объем тренировочной выборки GPT-2... С учетом того, что люди в среднем читают по странице в минуту, даже если вы будете поглощать текст 24 часа в сутки без перерыва на еду и сон — вам потребуется почти 40 лет, чтобы догнать GPT-2 по эрудиции!
")
Но одного объема тренировочных данных для получения крутой языковой модели недостаточно: ведь даже если посадить пятилетнего ребенка перечитывать всё собрание сочинений Шекспира вместе с лекциями по квантовой физике Фейнмана впридачу, то вряд ли он от этого станет сильно умнее. Так и тут: модель еще и сама по себе должна быть достаточно сложной и объемной, чтобы полноценно «проглотить» и «переварить» такой объем информации. А как измерить эту сложность модели, в чем она выражается?
Почему в мире языковых моделей больше ценятся именно модели «Plus Size»
Помните, мы чуть раньше говорили, что внутри языковых моделей (в супер‑упрощенном приближении) живут уравнения вида , где искомый игрек — это следующее слово, вероятность которого мы пытаемся предсказать, а иксы — это слова на входе, на основе которых мы делаем это предсказание?
Так вот, как вы думаете: сколько было параметров в уравнении, описывающем самую большую модель GPT-2 в 2019 году? Может быть, сто тысяч, или пара миллионов? Ха, берите выше: таких параметров в формуле было аж полтора миллиарда (это вот столько: 1'500'000'000). Даже если просто записать такое количество чисел в файл и сохранить на компьютере, то он займет 6 гигабайт! С одной стороны, это сильно меньше, чем суммарный размер текстового массива данных, на котором мы тренировали модель (помните, который мы собирали по ссылкам с Reddit, на 40 Гб); с другой — модели ведь не нужно запоминать этот текст целиком, ей достаточно просто найти некие зависимости (паттерны, правила), которые можно вычленить из написанных людьми текстов.
Эти параметры (их еще называют «веса», или «коэффициенты») получаются во время тренировки модели, затем сохраняются, и больше не меняются. То есть, при использовании модели в это гигантское уравнение каждый раз подставляются разные иксы (слова в подаваемом на вход тексте), но сами параметры уравнения (числовые коэффициенты при иксах) при этом остаются неизменны.

Чем более сложное уравнение зашито внутрь модели (чем больше в нем параметров) — тем лучше модель предсказывает вероятности, и тем более правдоподобным будет генерируемый ей текст. И у этой самой большой на тот момент модели GPT-2 тексты внезапно стали получаться настолько хорошими, что исследователи из OpenAI даже побоялись публиковать модель в открытую из соображений безопасности. А ну как люди ринулись бы генерировать в промышленном масштабе реалистично выглядящие текстовые фейки, спам для соцсетей, и так далее?
Нет, серьезно — это был прямо существенный прорыв в качестве! Вы же помните: предыдущие модели T9/GPT-1 худо‑бедно могли подсказать — собираетесь ли вы пойти в банк или в аптеку, а также угадать, что шоссейная Саша сосет сушки, а не что‑то иное. А вот GPT-2 уже легко написала эссе от лица подростка с ответом на вопрос: «Какие фундаментальные экономические и политические изменения необходимы для эффективного реагирования на изменение климата?» (тут и иные взрослые прикурили бы от серьезности темы). Текст ответа был под псевдонимом направлен жюри соответствующего конкурса — и те не заметили никакого подвоха. Ну, окей, оценки этой работе поставили не сильно высокие и в финал она не прошла — но и «что за чушь вы нам отправили, постыдились бы!!» тоже никто не воскликнул.
«Эссе хорошо сформулировано и подкрепляет утверждения доказательствами, но идея не является оригинальной», – так один из кожаных мешков в жюри оценил работу нейросетки GPT-2.
Переход количества в качество (почти по Марксу)
Вообще, вот эта идея о том, что по мере наращивания размера модели у нее внезапно открываются качественно новые свойства (например, писать связные эссе со смыслом вместо простого подсказывания следующего слова в телефоне) — это довольно удивительная штука. Давайте поразбираем новоприобретенные скиллы GPT-2 чуть поподробнее.
Есть специальные наборы задач на разрешение двусмысленности в тексте, которые помогают оценить понимание текста (хоть человеком, хоть нейросетью). Например, сравните два утверждения:
Рыба заглотила приманку. Она была вкусной.
Рыба заглотила приманку. Она была голодной.
К какому объекту относится местоимение «она» в первом примере — к рыбе или к приманке? А во втором случае? Большинство людей легко понимают из контекста, что в одном случае «она» — это приманка, а в другом — рыба. Но для того, чтобы это осознать, нужно не просто прочитать предложение — а выстроить в голове целую картину мира! Ведь, например, рыба может быть в разных ситуациях и голодной, и вкусной (на тарелке в ресторане). Вывод о ее «голодности» в данном конкретном примере вытекает из контекста и ее, извините, кровожадных действий.

Люди решают такие задачи правильно примерно в 95% случаев, а вот ранние языковые модели справлялись только в половине случаев (то есть, пытались угадать практически рандомно «50 на 50» — как в том анекдоте про «какова вероятность встретить на улице динозавра?»).
Вы, наверное, подумали: «Ну, надо просто накопить большую базу таких задачек (на пару тысяч примеров) с ответами, прогнать через нейросеть — и натренировать ее на поиск правильного ответа». И со старыми моделями (с меньшим числом параметров) так и пытались сделать — но дотянуть их получалось только до примерно 60% успеха. А вот GPT-2 никто специально таким трюкам не учил; но она взяла, и сама неожиданно и уверенно превзошла своих «специализированных» предшественников — научилась определять голодных рыбов правильно в 70% случаев.
Это и есть тот самый переход количества в качество, про который нам когда‑то твердил старина Карл Маркс. Причем он происходит совершенно нелинейно: например, при росте количества параметров в три раза от 115 до 350 млн никаких особых изменений в точности решения моделью «рыбных» задач не происходит, а вот при увеличении размера модели еще в два раза до 700 млн параметров — происходит качественный скачок, нейросеть внезапно «прозревает» и начинает поражать всех своими успехами в решении совершенно незнакомых ей задач, которые она раньше никогда не встречала и специально их не изучала.
Краткое резюме: GPT-2 вышла в 2019 году, и она превосходила свою предшественницу и по объему тренировочных текстовых данных, и по размеру самой модели (числу параметров) в 10 раз. Такой количественный рост привел к тому, что модель неожиданно самообучилась качественно новым навыкам: от сочинения длинных эссе со связным смыслом, до решения хитрых задачек, требующих зачатков построения картины мира.
2020: GPT-3, или как сделать из модели Невероятного Халка
Поигравшись немного с располневшей (и от этого поумневшей) GPT-2, ребята из OpenAI подумали: «А почему бы не взять ту же самую модель, и не увеличить ее еще раз эдак в 100?» В общем, вышедшая в 2020 году следующая номерная версия, GPT-3, уже могла похвастаться в 116 раз большим количеством параметров — аж 175 миллиардов! Раскабаневшая нейросеть при этом сама по себе стала весить невероятные 700 гигабайт.
Набор данных для обучения GPT-3 тоже прокачали, хоть и не столь радикально: он увеличился примерно в 10 раз до 420 гигабайт — туда запихнули кучу книг, Википедию, и еще множество текстов с самых разных интернет‑сайтов. Живому человеку поглотить такой объем информации уже точно нереально — ну, разве что, если посадить с десяток Анатолиев Вассерманов, чтобы они читали буквально нон‑стоп по 50 лет подряд каждый.

Сразу бросается в глаза интересный нюанс: в отличие от GPT-2, сама модель теперь имеет размер больше (700 Гб), чем весь массив текста для ее обучения (420 Гб). Получается как будто бы парадокс: наш «нейромозг» в данном случае в процессе изучения сырых данных генерирует информацию о разных взаимозависимостях внутри них, которая превышает по объему исходную информацию.
Такое обобщение («осмысление»?) моделью позволяет еще лучше прежнего делать экстраполяцию — то есть, показывать хорошие результаты в задачах на генерацию текстов, которые при обучении встречались очень редко или не встречались вовсе. Теперь уже точно не нужно учить модель решать конкретную задачу — вместо этого достаточно описать словами проблему, дать несколько примеров, и GPT-3 схватит на лету, чего от нее хотят!
И тут в очередной раз оказалось, что «универсальный Халк» в виде GPT-3 (которую никто никаким «узким» задачам не обучал) с легкостью кладет на лопатки многие специализированные модели, которые существовали до нее: так, перевод текстов с французского или немецкого на английский сразу начал даваться GPT-3 легче и лучше, чем любым другим специально заточенным под это нейросетям. Как?! Напоминаю, что речь идет про лингвистическую модель, чье предназначение вообще‑то заключалось ровно в одном — пытаться угадать одно следующее слово к заданному тексту... Откуда здесь берутся способности к переводу?
Но это еще цветочки — еще более удивительно то, что GPT-3 смогла научить сама себя... математике! На графике ниже (источник: оригинальная статья) показана точность ответов нейросетей с разным количеством параметров на задачки, связанные со сложением/вычитанием, а также с умножением чисел вплоть до пятизначных. Как видите, при переходе от моделей с 10 миллиардами параметров к 100 миллиардам — нейросети внезапно и резко начинают «уметь» в математику.
, по вертикали – качество модели, выраженное в проценте верно решенных математических примеров")
Еще раз, вдумайтесь: языковую модель обучали продолжать тексты словами, а она при этом как‑то смогла сама разобраться в том, что если ей печатают «378 + 789 =», то на это надо отвечать именно «1167», а не каким‑то другим числом. Магия, ей‑богу, магия! (Хотя, некоторые говорят «да это нейросетка просто все варианты успела увидеть и тупо запомнить в тренировочных данных» — так что дебаты о том, магия это или всего лишь попугайство, пока продолжаются.)
На графике выше самое интересное — это то, что при увеличении размера модели (слева направо) сначала как будто бы не меняется ничего, а затем — р‑раз! Происходит качественный скачок, и GPT-3 начинает «понимать», как решать ту или иную задачу. Как, что, почему это работает — никто точно не знает. Но работает как‑то; причем, не только в математике — но и вообще в самых разнообразных других задачах!
Анимация ниже как раз наглядно показывает, как с увеличением количества параметров модели в ней «прорастают» новые способности, которые никто туда специально не закладывал:
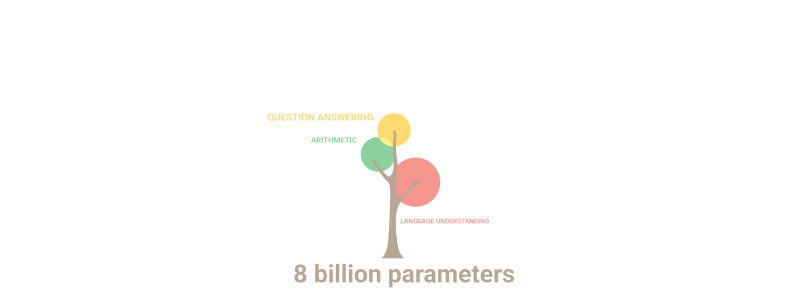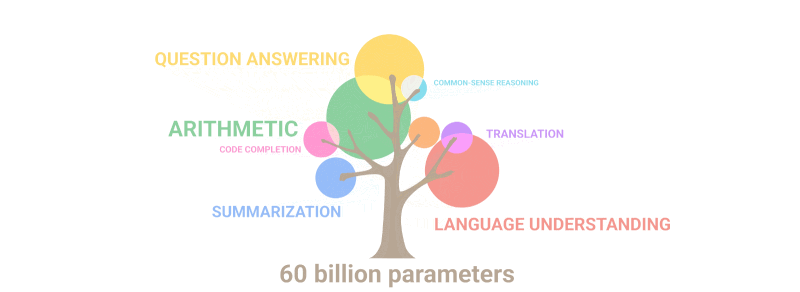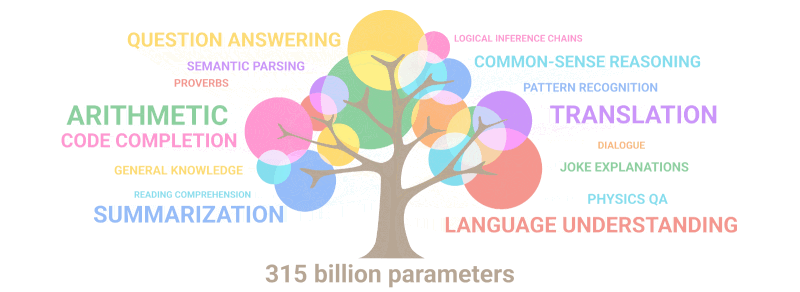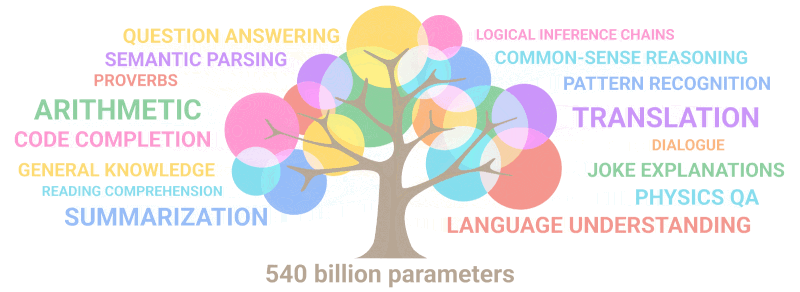
Кстати, задачу про «голодных рыбов», которой мы мучали GPT-2 в прошлом разделе, GPT-3 уже решает с точностью выше 90% — прямо как человек. Заставляет задуматься, правда: а какие новые скиллы обретет нейросеть, если увеличить ее объем еще раз в сто? Ну там, до десятков триллионов параметров, например...
Промпты, или как правильно уламывать модель
Давайте здесь сделаем небольшое отступление в сторону и обсудим, а что это вообще означает — «модель умеет решать задачи»? По сути, процесс выглядит так: мы подаем на вход модели некий текст с запросом, а она к нему дописывает свое продолжение. Если это продолжение (генерация) совпадает с нашими ожиданиями — то модель, получается, решила поставленную перед ней задачу.
Тот текст, что мы подаем на вход, называется prompt (промпт, или «запрос/затравка» по‑русски). Чем точнее он описывает, что мы хотим, тем лучше модель поймет, что ей нужно делать. А если мы ей еще и примеров отсыпем с десяток — то вообще шик!
")
Без описания цели и без примеров в промпте, модель тоже обычно понимает проблему, но предлагает не такие хорошие решения (с точки зрения их качества). Можно сказать, что детализированный промпт позволяет GPT лучше оценить вероятности слов, которые нужно генерировать в качестве ответа, направляя ее в «требуемое русло».
Но насколько сложным должен быть промпт? И насколько модель по пониманию близка к нам? Вы не поверите, но совсем недавно исследователи выяснили, что для существенного улучшения результатов генерации нужно добавить в промпт простую советскую...
Окей, кроме шуток, но добавление всего одной фразы перед ответом на вопрос существенно улучшает качество модели. И эта магическая фраза — «пожалуйста» «let»s think step by step» (давай подумаем шаг за шагом). Внезапно оказалось, что это побуждает модель рассуждать последовательно, делать выводы на основе собственных суждений, и приходить к правильному ответу гораздо чаще, чем без этой фразы.
Как это работает? Давайте на примере детской задачки:
Вопрос: В среднем боксер Иван наносит 25 ударов в минуту. Бой длится 5 раундов по 3 минуты. Сколько ударов он нанес?
Ответ: 255
Текст, выделенный жирным – это ответ, сгенерированный языковой моделью. Легко проверить, что он – ну, немного неправильный.

Однако та же самая модель может ответить вот так:
Вопрос: В среднем боксер Иван наносит 25 ударов в минуту. Бой длится 5 раундов по 3 минуты. Сколько ударов он нанес?
Ответ: Давай подумаем шаг за шагом. За одну минуту Иван наносит 25 ударов. За три минуты Иван наносит 3 * 25 = 75 ударов. За пять раундов Иван наносит 5 * 75 = 375 ударов.
И снова текст выделенный жирным — это ответ модели. Видно, что он стал длиннее, решение задачи получилось прямо как у школьника — в три действия. Четко, последовательно — ровно так, как мы и попросили. И финальная цифра 375 является корректным ответом на исходный вопрос. Отдельно отмечу: мы никак не дообучали модель после того, как она ответила неправильно — это абсолютно та же самая модель. Мы просто дописали пять дополнительных слов в конец нашего промпта, и произошло чудо!
Причем вот этот «режим рассуждения» — это одна из качественно новых фишек, которые появились в «большой» модели GPT-3 после преодоления планки в сотню миллиардов параметров. Старые модели с меньшим количеством параметров такие фокусы показывать не умели, как их ни упрашивай специальными подсказками «ну подумой, братишка!».
Вообще, составление грамотных промптов для модели — это отдельная наука. Под эту задачу компании уже начали нанимать отдельных людей с должностью «промпт‑инженер» (то есть человек, сочиняющий запросы для языковых моделей) — вангую, что до появления онлайн‑курсов «????????????Научись промпт‑инжинирингу за 6 недель и вкатись в перспективную индустрию с зарплатой 300к в месяц!????????????» осталось всего ничего.
Краткое резюме: GPT-3 образца 2020 года была в 100 раз больше своей предшественницы по количеству параметров, и в 10 раз – по объему тренировочных текстовых данных. И снова рост количества привел к внезапному скачку в качестве: модель научилась переводу с других языков, арифметике, базовому программированию, пошаговым рассуждениям, и многому другому.
Январь 2022: InstructGPT, или как научить робота не зиговать
На самом деле, увеличение размеров языковых моделей само по себе еще не означает, что они будут отвечать на запросы именно так, как хочет их пользователь. Ведь часто мы, когда формулируем какой‑то запрос, подразумеваем очень много скрытых условий — которые в коммуникации между людьми считаются сами собой разумеющимися, что ли. Например, когда Маша просит своего мужа: «Вась, сходи выбрось мусор» — то вряд ли ей придет в голову прибавить к этому промпту «(только не из окна, плз!)». Ведь Вася это понимает и без уточнений — а всё потому, что их намерения и установки неплохо выравнены между собой.

А вот языковые модели, если честно, не очень похожи на людей — поэтому им часто приходится подсказывать и разжевывать те вещи, которые людям кажутся очевидными. Слова «давай подумаем шаг за шагом» из прошлого раздела — это как раз и есть один из примеров такой подсказки (хотя среднестатистические взрослые люди, учившиеся в школе, догадались бы сами: если речь идет про задачку — значит, надо решать по действиям). Но было бы здорово, если бы модели, во‑первых, сами для себя понимали/генерировали более развернутые и релевантные инструкции из запроса (не заставляя людей напрягаться), а во‑вторых, точнее следовали бы им — как бы предугадывая, как в похожей ситуации поступил бы человек.
Отчасти отсутствие таких способностей «по умолчанию» связано с тем, что GPT-3 обучена просто предсказывать следующее слово в гигантском наборе текстов из Интернета — а в Интернете, как и на заборе, много всякого разного написано (и не всегда полезного). При этом люди хотели бы, чтобы рожденный таким образом искусственный интеллект подтаскивал по запросу точные и полезные ответы; но одновременно эти ответы должны быть еще и безобидные и нетоксичные. Иначе саму модель быстренько закэнселят (с этим сейчас строго), а ее создателям предъявят судебные иски на много миллионов долларов за оскорбление достоинства кожаных мешков.
Когда исследователи думали над этой проблемой, довольно быстро выяснилось, что свойства модели «точность/полезность» и «безобидность/нетоксичность» весьма часто как бы противоречат друг другу. Ведь точная модель должна честно выдать инструкцию на запрос «окей, Гугл, как сделать коктейль Молотова, без регистрации и смс», а заточенная на максимальную безобидность модель в пределе будет отвечать на совершенно любой промпт «извините, я боюсь, что мой ответ может кого‑то оскорбить в Интернете».

Вокруг этой проблемы «выравнивания ИИ» (AI alignment – OpenAI последнее время только про это и пишут) есть много сложных этических вопросов, и разбирать мы их все сейчас не будем (возможно, в следующей статье). Основная загвоздка здесь в том, что подобных спорных ситуаций – огромная куча, и как-то четко формализовать их просто не представляется возможным. Да что там, люди и сами между собой не могут толком последние несколько тысяч лет договориться – что хорошо, а что плохо. Не говоря уже о том, чтобы понятные для робота правила сформулировать (Айзек, к тебе вопросов нет)...
В итоге исследователи не придумали ничего лучше, чем просто дать модели очень много обратной связи. В каком-то смысле, человеческие детеныши ведь именно так и обучаются морали: делают много всякого разного с самого детства, и при этом внимательно следят за реакцией взрослых – что можно делать, а что есть «кака, фу!».
Короче, InstructGPT (также известная как GPT-3.5) – это как раз и есть GPT-3, которую дообучили с помощью фидбека на максимизацию оценки живого человека. Буквально – куча людей сидели и оценивали кучу ответов нейросетки на предмет того, насколько они соответствуют их ожиданиям с учетом выданного ей запроса. Ну, на самом деле, всё было не совсем так просто (инструкции для членов такого «мясного жюри» занимали 26 страниц убористым почерком) – но суть именно такая. А языковая модель, получается, училась решать еще одну дополнительную задачу – «как мне поменять свой сгенерированный ответ таким образом, чтобы он получил наибольшую оценку от человека?» (подробнее процесс обучения по обратной связи разбирается в этом материале).
Причем с точки зрения общего процесса обучения модели, этот финальный этап «дообучения на живых людях» занимает не более 1%. Но именно этот финальный штрих и стал тем самым секретным соусом, который сделал последние модели из серии GPT настолько удивительными! Получается, GPT-3 до этого уже обладала всеми необходимыми знаниями: понимала разные языки, помнила исторические события, знала отличия стилей разных авторов, и так далее. Но только с помощью обратной связи от других людей модель научилась пользоваться этими знаниями именно таким образом, который мы (люди) считаем «правильным». В каком-то смысле, GPT-3.5 – это модель, «воспитанная обществом».
Краткое резюме: GPT-3.5 (также известная как InstructGPT) появилась в начале 2022 года, и главной ее фишкой стало дополнительное дообучение на основе обратной связи от живых людей. Получается, что эта модель формально вроде как больше и умнее не стала – но зато научилась подгонять свои ответы таким образом, чтобы люди от них дичайше кайфовали.
Ноябрь 2022: ChatGPT, или маленькие секреты большого хайпа
ChatGPT вышла в ноябре 2022 года — примерно через 10 месяцев после своей предшественницы, InstructGPT/GPT-3.5 — и мгновенно прогремела на весь мир. Кажется, что последние несколько месяцев даже бабушки на лавочке у подъезда обсуждают только одно — что там нового сказала эта ваша «ЧатЖПТ», и кого она по самым свежим прогнозам вот‑вот оставит без работы.
При этом с технической точки зрения, кажется, у нее нет каких‑то особо мощных отличий от InstructGPT (к сожалению, научной статьи с детальным описанием ChatGPT команда OpenAI пока так и не опубликовала — так что мы тут можем только гадать). Ну окей, про некоторые менее значимые отличия мы всё же знаем: например, про то, что модель дотренировали на дополнительном диалоговом наборе данных. Ведь есть вещи, которые специфичны именно для работы «ИИ‑ассистента» в формате диалога: например, если запрос пользователя неясен — то можно (и нужно!) задать уточняющий вопрос, и так далее.

Но это уже детали — нам здесь важно, что основные технические характеристики (архитектура, количество параметров...) нейросетки не поменялись кардинально по сравнению с прошлым релизом. Отсюда возникает вопрос — как так? Почему мы не слышали никакого хайпа про GPT-3.5 еще в начале 2022-го? При том, что Сэм Альтман (исполнительный директор OpenAI) честно признался, что исследователи сами удивились такому бурному успеху ChatGPT — ведь сравнимая с ней по способностям модель к тому моменту тихо‑мирно лежала на их сайте уже более десяти месяцев, и никому не было до этого дела.
Это удивительно, но похоже, что главный секрет успеха новой ChatGPT — это всего лишь удобный интерфейс! К той же InstructGPT обращаться можно было лишь через специальный API‑интерфейс — то есть, сделать это заведомо могли только нёрды‑айтишники, а не обычные люди. А ChatGPT усадили в привычный интерфейс «диалогового окна», прямо как в знакомых всем мессенджерах. Да еще и открыли публичный доступ вообще для всех подряд — и люди массово ринулись вести диалоги с нейросетью, скринить их и делиться в соцсетях. Choo‑choo, all aboard the hype train!

Как и в любом технологическом стартапе, здесь оказалась важна не только сама технология — но и обертка, в которую она была завернута. У вас может быть самая лучшая модель или самый умный чат‑бот — но они будут никому не интересны, если к ним не прилагается простой и понятный интерфейс. И ChatGPT в этом смысле совершил прорыв, выведя технологию в массы за счет обычного диалогового окна, в котором дружелюбный робот «печатает» ответ прямо на глазах, слово за словом.
Неудивительно, что ChatGPT установил абсолютные рекорды по скорости привлечения новых пользователей: отметку в 1 миллион юзеров он достиг в первые пять дней после релиза, а за 100 миллионов перевалил всего за два месяца.

Ну а там, где есть рекордно быстрый приток сотен миллионов пользователей — конечно, тут же появятся и большие деньги. Microsoft оперативно заключила с OpenAI сделку по инвестированию в них десятка миллиардов долларов, инженеры Google забили тревогу и сели думать, как им спасти свой поисковый сервис от конкуренции с нейросетью, а китайцы в срочном порядке анонсировали скорый релиз своего собственного чат‑бота. Но это всё, если честно, уже совсем другая история — следить за которой вы можете сейчас сами «в прямом эфире»...
Краткое резюме: Модель ChatGPT вышла в ноябре 2022-го и с технической точки зрения там не было никаких особых нововведений. Но зато у нее был удобный интерфейс взаимодействия и открытый публичный доступ — что немедленно породило огромную волну хайпа. А в нынешнем мире это главнее всего — так что языковыми моделями одномоментно начали заниматься вообще все вокруг!
Подведем итоги
Статья получилась не очень короткой — но надеемся, что вам было интересно, и просле прочтения вы чуть лучше стали понимать, что же конкретно творится под капотом этих самых нейросетей. Кстати, у Игоря Котенкова (одного из авторов этой статьи) есть еще один лонгрид на Хабре под названием «ChatGPT как инструмент для поиска: решаем основную проблему», в котором нюансы машинного обучения разбираются еще более подробно.
Для вашего удобства мы сделали небольшой сводный постер, который наглядно иллюстрирует основные вехи истории эволюции языковых моделей. Если какой‑то этап кажется вам не очень понятным — можете просто вернуться чуть назад к соответствующему разделу в тексте и перечитать его заново (ну или задать нам уточняющие вопросы в комментариях).

На самом деле, в первоначальном плане статьи у нас было гораздо больше пунктов: мы хотели подробнее обсудить и проблемы контроля за искусственным интеллектом, и жадность корпораций, которые в высококонкурентной погоне за прибылью могут случайно родить ИИ‑Франкенштейна, и сложные философские вопросы вроде «можно ли считать, что нейросеть умеет мыслить, или всё же нет?».
Если на эту статью будет много положительных отзывов, то все эти (на наш взгляд — супер‑захватывающие!) темы мы разберем в следующем материале. Если вы не хотите его пропустить — то приглашаем вас подписаться на ТГ‑каналы авторов: Сиолошная Игоря Котенкова (для тех, кто хочет шарить за технологии) и RationalAnswer Павла Комаровского (для тех, кто за рациональный подход к жизни, но предпочитает чуть попроще). Всё, всем спасибо за внимание — с нетерпением ждем ваших комментариев!
Комментарии (261)

tagir_analyzes
00.00.0000 00:00+4Статью пока не читал, но за одни только мемы можно ставить лайк. Положил в закладки, вернусь вечером. Спасибо за труд, коллеги!

Fedarod
00.00.0000 00:00-19А ее нет смысла читать, всё это было предсказано еще лет 20 назад, тут был такой Редозубов, который обещал ИИ через три года, но не было его ни через три, ни через тридцать не будет. Вот вкратце планы на ближайшие 50 лет в псевдоразвитии ИИ, не поленитесь зайти через 50 лет:
Авторские права. Это уже тут было упомянуто, но криво, и потому заминусовано; но суть от этого не изменилась - ИИ не будет создан, пока его ждут капиталисты, чтобы украсть. Никто им его не подарит, зря только сыпят деньгами.
Строка диалога - это то, что было создано для сохранения авторских прав. Это еще с Юникса пошло, когда не смогли создать Андроидов. Потом это Гугл применил, когда не смог создать помощника. Теперь это применил ЧатГПТ, когда не смог создать ИИ.
Всё это ведёт к эксплуатации первоначальной провальной идеи, к наихудшему сценарию из возможных - к прятанию за строкой диалога человека. Сисадмина Юникса, маркетингового отдела Гугла, галеру подрядчика ЧатГПТ.
Да-да, украинская галера на подряде Амазона как ИИ по распознаванию образов - это верхушка айсберга новой пирамиды, которую пытаются надуть под видом ИИ. Курсы датасайентологов, миллиарды человеко-часов и изображение человека, которому художник должен подправить пальцы до нужного числа.
Всегда нужен художник, админ или архитектор, который будет полировать мусор для продажи. В этом суть продаж, а не плохого ИИ. Хороший ИИ нельзя продать, поэтому он принципиально не будет создан.

rPman
00.00.0000 00:00+7умудрились ошибиться максимально в каждом утверждении ;)
* все будет украдено вне зависимости от того кто и что, это было есть и будет, но совершенное не мешает все это создавать, ИИ как технология ничем тут не отличается от любого другого продукта, будь то соцсеть/месседженер/условный тикток (все что было создано успешное, было украдено, многократно переделано)
* строка диалога это не способ что то спрятать, это способ решить задачу создания ИИ, при этом статья буквально показывает почему выбран этот путь (если что чат боты и чат игры на основе продолжения фразы уже были, рост тут не скачкообразный а постепенный)
вот вам аналогия — не понимая как зайти в дом, залезли через канализационную трубу, сейчас у нас рука торчит из унитаза, пролезть дальше не можем но формально мы уже в доме.
* мир создал нечто странное, сейчас этот мир пытается понять как этим пользоваться, зачем это ему и что из этого получится хз, но не беспокойтесь, пользоваться будут
даже если будут франкенштейны вида — в промпт уходят все что видим (текущее состояние) и запрос на буквально управление мышцами (типа у вас три числа, угол первого сочленения, второго и третьего, соединенных друг с другом, какое должно быть последовательное изменение чтобы поднять предмет A и перенести на площадку B с координатами...)
Хороший ИИ, чем бы это не являлось, создан будет… не сможем создать, подправим понятие 'хороший' под то что сможем. Текущая задача была решена буквально брутфорсом, завалив ее большими деньгами. Упрутся в железный предел, будут оптимизироватьэ.
вон помню человек открыл исходники stable diffusion, ужаснулся и запилил одну из его частей под nvidia тензор, ускорив в 4 раза (меньше секунды на генерацию)… кто-нибудь другой оптимизирует задачу под специфическое железо (если что в мире куча стартапов занялись разработкой специализированных чипов под нейронки, которые могут дать ускорение на порядок, мне к примеру нравится стартап, которые для вычислений используют аналоговую электронику (к сожалению не всю, иначе ну очень плохая точность)

nasos
00.00.0000 00:00+3Интересно увидеть график, как умнеет человек от количества прочитанных книг, сделанных проектов и чего-то ещё эквивалентного количеству набора переменных.

gagarinas
00.00.0000 00:00+2А как измерить "умность" человека?

voted
00.00.0000 00:00-2Для этого изобрели тест на "коэффициент умности" (от англ. intelligence quotient или IQ)

Spaceoddity
00.00.0000 00:00+4который с количеством прочтенных книг никак не коррелирует в принципе.
а завязан на анализ и поиск закономерностей
UPD: вру. на примере обсуждаемого сабжа - можно пройти тест "100500 раз" и если уж не вызубрить все ответы, то по крайней мере понять логику создателей теста.

yatanai
00.00.0000 00:00Там же много факторов есть, вот у тебя высокий IQ, но плохая память. И толку то? Гениально решаю задачи по математике но не могу вспомнить что решал, приходится зубрить пока наизусть не выучу?

WASD1
00.00.0000 00:00Ну самая большая неожиданность IQ (когда его только ввели) - оказалось что результаты тестов по разным его разделам очень неплохо скоррелированы.
Т.е. вас сценарий не исключён, но весьма маловероятен.yatanai
00.00.0000 00:00Ну в итоге умные дяди решили что "одного IQ" нет и разделили тесты на несколько категорий.
Грубо говоря мне говорили тип, у тебя может быть очень сильный вербальный интеллект, в словесном споре ты буквально уничтожаешь людей интеллектом, но какой же ты тупой боже ты даже намёков не понимаешь надо по несколько раз объяснять.

user5000
00.00.0000 00:00+4мне говорили тип, у тебя может быть очень сильный вербальный интеллект, в словесном споре ты буквально уничтожаешь людей интеллектом
Читал ваши комментарии, наличие какого-то супер-интеллекта у вас не заметил. Много орфографических ошибок. Употребление в речи слова "координально" тоже кое о чём говорит. В общем, вам просто-напросто льстят насчёт интеллекта.

saboteur_kiev
00.00.0000 00:00+2Если человек прочитает тысячу книг, можно утверждать, что он.. научился читать книги. Хорошо, быстро, качественно.
А поумнеть - ну смотря что читать, смотря как читать, смотря зачем читать. Опытнее станет точно.

vconst
00.00.0000 00:00+2Ха! Зависит от того — какие книги он будет читать ))
Как-то наткнулся в жж на забавный пост, как человек «пообещал себе читать по новой книге каждый день». Он почти выполнил свое обещание, но читал при этом ТАКУЮ позорнейшую графоманию, всяких альтернативных попаданцев с промежуточными патронами и прочей хренью — что ни уму, ни сердцу, ни желудку.saboteur_kiev
00.00.0000 00:00тем не менее, графомания тоже дает эмоции, какой-то опыт, сопереживание и так далее. Я не считаю чтение попаданцев совершенно бесполезным занятием, если человек имеет свой кусок хлеба, а свободное время пусть тратит как хочет. Жизнь - одна.
vconst
00.00.0000 00:00+1Ой нет, не тот случай
Оно утомительное тупое, картонное, шаблонное, всякие мери сью на марсе и даша сью на луне, корявый и неприятный слог, пишут лозунгами и штампами. Это и пару страниц читать нельзя. К примеру — как такой оборот: «взгляд выглядывал»? ))
Нет и нет
Я пробовал — больше «ноги моей не будет»saboteur_kiev
00.00.0000 00:00Не каждый попаданец - графомания.
Объективно - есть множество шикарных произведений.
Ваше личное мнение - не стоит путать с объективным =)vconst
00.00.0000 00:00Личное мнение — это вкус. А его можно и нужно — развивать. Надо отличать книги не только по жанру — но и по уровню. Например: Аберкромби или Уоттс — это вопрос вкуса. Но Гибсон или Поселягин — это вопрос уровня произведения. У последнего он настолько низок, что можно считать «некнигой»
Впрочем — можете потренироваться. Вот примерный уровень моего чтива: Фантастика и фентези за два с половиной года, почти сто хороших книг. Найдете попаданцев схожего уровня? Причем — много попаданцев, а не 1-2, чтобы зачитаться как следует, как Экспансией или Пространством откровения и перечитать хотелосьsaboteur_kiev
00.00.0000 00:00А его можно и нужно — развивать
Кому нужно?
Почему вы командуете как людям тратить свое свободное время и свою единственную жизнь?
Или вы реально считаете, что после смерти кому-то будет дело до того что вы читали, зачем и почему?vconst
00.00.0000 00:00+1Командую? Я?
Такой примитивный передерг, что даже скучно
ЧСХ, ваше личное мнение — «обьективно», а мое — нет?
Примеров попаданцев-неграфоманий вы привести не смогли, перевели все на нелепую тему «что там читал после смерти». Значит я оказался прав. Ок, принятоsaboteur_kiev
00.00.0000 00:00Мое мнение - можно читать. Оно не говорит нужно или нельзя, оно предоставляет выбор
Ваше мнение - нельзя читать, при этом еще и фраза в уничижающих интонациях.
"Примеров попаданцев-неграфоманий вы привести не смогли"
Не не смог, а не хотел. Я как бы не подписывался составлять отчет, готовой статьи, чтобы надергать - у меня нет.vconst
00.00.0000 00:00Таки мне интересно, почему свое мнение вы назвали — обьективным, а мое — нет?
И да — читать невозможно
Сюжеты тупые и шаблонные, независимо от автора — там будет уныние и однообразие. О качестве слога вообще говорить не приходится, ибо предложения строятся коряво — будто Пропмт из 90-х на инглиш и обратно переводил. Герои даже не картонные, я не знаю какой материал не оскорбится сравнением с ними. Диалоги вымученные и неестественные.Я пробовал. Не раз и не два. Оно в принципе несьедобно, это даже не макдак с резиновыми котлетами — это что-то вроде самого дешевого дожирака.
Мне много раз и под самыми нелепыми предлогами отказывались назвать альтернативных попаданцев, по уровню сравнимых с чем-то типа моего списка. Никто ВООБЩЕ не осмелился сказать что-то типа: "Вот этот альтернативны попаданец — не хуже Станислава Лема и даже лучше". НИКТО
Ведь все просто.
Открываешь книгу, которую читаешь прямо сейчас и говоришь — вот она, хорошая. Но так никто не сделает, потому что оно несравнимо ниже уровнем любого нормального фантаста, просто гарантированно. А никто не хочет признаться, что, в данный и конкретный момент, он читает — дерьмо
saboteur_kiev
00.00.0000 00:00-2Очень печально, что в своей нетерпимости, вы не пытались найти что-то интересное, а просто забрызгали слюной первые попавшиеся графомании. Нужно же понимать, что среди попаданцев и литрпг в топе будут не лучшие произведения, а именно те, которые востребованы основными потребителями такого жанра.
Хорошие и сложные произведения будут среднестатистического массового потребителя примерно там же, где и Лэм или Азимов.
vconst
00.00.0000 00:00Я достаточно почитал самиздата, в поисках "новой русской фантастики" — 1 (одна) книга была нормальная: Роза и червь
И ВСЁ!Ну так где они, хорошие и сложные, уровня Лема и Азимова?
Одно я нашел, еще десяток, хотя бы — наберется? Пока никто мне не зазвал альтернативных льтропыгышных попаданцев уровня Азимова.

SadOcean
00.00.0000 00:00Скорее набору переменных эквивалентны биологические особенности мозга человека.
Количество нейронов, к примеру.
nasos
00.00.0000 00:00И еще. Что такое миллион параметров модели для человека? Миллион нейронов?

stalkermustang Автор
00.00.0000 00:00+6Я предпочитаю избегать такой аналогии. Да, отдельные концепты в нейросетях переняты от человека, мы как бы свои "удачные" механизмы внедряем как априорные знания. Но эти похожие вещи очень условно можно называть одинаковыми. То есть концепция нейрона из головы слабо переносится на концепцию нейрона в нейросети. Поэтому сравнивать сложно.

iBljad
00.00.0000 00:00Хотелось бы ещё понять, как формируются "параметры", сотни миллионов уже явно не вручную заводятся.
Второе, не про параметры, интересно, как оно понимает что вот сейчас в ответе будет/должен быть, например, код (и оформляет это отдельными сниппетом)
stalkermustang Автор
00.00.0000 00:00+2Они получаются во время обучения путем оптимизации некоторой функции ошибки (предсказание следующего слова) с помощью градиентных методов. https://youtu.be/PaFPbb66DxQ + https://youtu.be/sDv4f4s2SB8 - вот два видео с объяснением подхода для линейного уравнения, приведенного в статье.
(и оформляет это отдельными сниппетом)
тот сниппет, который мы сами видим - это просто UI Элемент, который получается парсингом выходов модели. Как только условная регулярка находит, что модель сгенерировала токен <code> или что-то такое - так сразу сайт рисует бокс для кода. То же и с латехом.

Roman_Kor
00.00.0000 00:00+6Скорее миллион синапсов. Синапс - это место соединения нейронов (аксона от нейрона посылающего сигнал к принимающему дендриту).
На счёт количества синапсов в мозге человека точно сказать не могу, но кол-во нейронов оценивается в районе 80 - 100 миллиардов. Кол-во синапсов на нейрон варьируется от типа нейронов, но насколько помню оно не более 1000.
UPD: Нашёл, что количество синапсов в человеческом мозге оценивается в 0.15 x 10^15.Devise1612
00.00.0000 00:00+6вы слишком много для человека насчитали - в коре всего 16 миллиардов, тем более это на два полушария. У 3 летнего ребенка грубо говоря можно "синапсов" всего 8-30 триллионов насчитать. Если GPT на 170 миллиардов - 700 ГБ то модельку наверное можно оценить 70-250 ТБ, не так уж много
сравнивать прямо нельзя в первую очередь потому, что биологические нейроны гораздо сложнее максимально примитивной весовой функции. На работу мозга гормональная и гуморальная системы влияют, вы их устанете в модель вносить

goodok
00.00.0000 00:00+1В коре 16 млрд. нейронов. Всего - 100 млрд. Так что Roman_Kor правильно для человека посчитал.
Наверное, Вы имеете ввиду, что весь "человечески интеллект" только в коре головного мозга находится, но это (скорее всего) не так.
Devise1612
00.00.0000 00:00а зачем вы считаете нейроны отвечающие за всякие там частоту сердечных сокращений, уровень сатурации крови и прочие "поднять шерсть дыбом" и перестальтике кишечника????
вы кстати учтите что к 16 миллиардам коры у человека - прилагаются все органы чувств и вся моторика. Сомнительно что нейросетевой модели какая бы она ни была требуется различать отдельные кванты света, чувствовать нанометровые неровности, жевать и поднимать хвост и прочее что отличает человека от медузы
goodok
00.00.0000 00:00+4Потому что я допускаю, что человеческий интеллект реализован не только в коре головного мозга.
Например, Гиппока́мп "Участвует в механизмах формирования эмоций, консолидации памяти (то есть перехода кратковременной памяти в долговременную), пространственной памяти, необходимой для навигации. Генерирует тета-ритм при удержании внимания[1]."
Если интересно, кое-какие идеи на этот счёт изложены в прошлогодней статье Яна Лекунна "A Path Towards Autonomous Machine Intelligence" https://openreview.net/pdf?id=BZ5a1r-kVsf
КДПВ от туда:
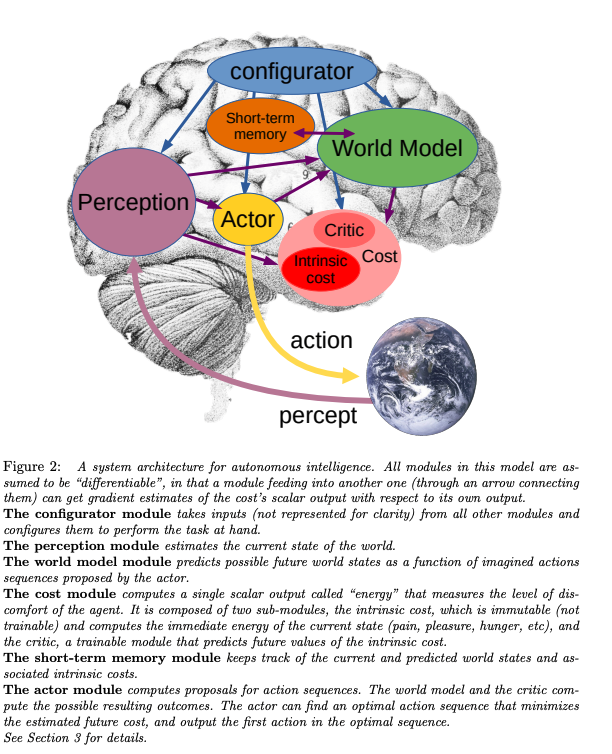
Devise1612
00.00.0000 00:00+2я не исключаю, что весь человеческий интеллект реализован в коре головного мозга.
наоборот наверное?
статью посмотрю, спасибо, тем более это к моим темам близко если собственно матмоделирование затрагивает.
но вот это вот:
иппока́мп "Участвует в механизмах формирования эмоций,
мизинец на ноге тоже участвует в формировании эмоций. И давление на стенки желудка - тоже. Ну, вики такая вики
Картинка кстати к человеческой НС вообще не относится, что собственно даже в подписи прямо написано.
Я не спорю что в функционировании человеческого сознания в полной мере все тело участвует, еще и социальное окружение - это как бы факт. Но зачем тащить в сравнение с "языковой моделью" то что явно в этом не участвует? Вы мозг слона сравните лучше, они тоже говорить умеют, еще порядок чисел добавится
goodok
00.00.0000 00:00+2Спасибо за ответы. Да, сорри - описался в первом абзаце (отвлекали), подправил. Но вы правильно поняли.
Тем не менее получается оценка 16..100 млрд нейронов которые обеспечивают уровень человеческого ИИ.
Дальше можно пофилософствовать, и вспомнить про спинной мозг и ганглии, животных и пр.. Но давайте как нибудь найдём время после прочтения статья (читал летом)
Ну и с интересом ждём мультимодальных больших моделей (типа недавней MLLM multimodal large language model https://arxiv.org/pdf/2302.14045.pdf), а не только текстовых. Будет весело, когда нейронка обсмотрится фильмов, видео новостей, экшнкамер и пр.
Devise1612
00.00.0000 00:00получается оценка 16..100 млрд нейронов которые обеспечивают уровень человеческого ИИ
мы не говорим про "человеческий ИИ" - мы пытаемся сопоставить мощность языковой модели и человека на основании числа параметров/синапсов.
100 млрд - плохая оценка, очевидно.
16 млрд /2 - гораздо лучше, на самом деле еще меньше
прочтения статья (читал летом)
ну по первому впечатлению это все-таки не статья а скорее презентация. И совершенно точно - никакого отношения к GPT не имеет.
Hidden text
несколько настораживает уровень гетерогенности - он ничем не объясняется. Да, те же проблемы переобучения это снимет - но только частично, их все равно придется решать. Зачем АИ на нейросетях - специализированная память? Почему в гетерогенной по сути системе нет внешних модулей?
Много еще вопросов, на самом деле их можно к одному свести - зачем использовать модель оптимизированную из текущих представлений если мы ээ переходим на более мощный уровень реализации, причем на порядки? Исследований очевидно нет, соответственно нет и обоснований
с интересом ждём мультимодальных больших моделей
ну у меня на этот счет то мнение, что без сверточных классификаторов любая модель такой мощности сразу в переобучение свалится вообще без вариантов. А с их использованием как-то особой разницы нету в каком виде информация на вход поступает - то же зрение у человека нифига не матрица видеокамеры.
Я бы все-таки больше посмотрел на модели с активным deeplearning. Понятно что безумно дорого и на текущий момент вряд ли что-то даст - но это хоть какое-то отличие от уже известного. Ну или реккурентные сети в том или ином виде - 3000 токенов для GPT это все-таки несерьезно
saboteur_kiev
00.00.0000 00:00Плюс мозг помнит не буквы и не цифры. Там вообще огромная часть данных это может быть сигналы от почесывания, и вообще мозг человека сильно заточен на аггрегацию и обобщение кучи точечных сигналов. сигналов
yatanai
00.00.0000 00:00+3Добавлю, там всё настолько мудрёно, что даже один "параметр"(синапс), на самом деле, производит минимальные вычисления и это можно модулировать ферментами, а ещё он может "активироваться" от ферментов, а ещё нейрон может объединять сигналы от других синапсов до того как они дойдут до тела нейрона, и это тоже можно модулировать, а ещё активность нейрона зависит от соседей и соседи могут модулировать активность, а ещё нейрону может что-то мешать он может недополучать кислорода или никто не убирает продукты его жизнедеятельности и он "отравляется" и меняет свои характеристики.
В то время ИНС это просто сумма(много_весов*много_данных) = ответ. Так что даже если представить что синапс это и есть "параметр", то он играет далеко не ключевую роль в вычислениях.

h0tkey
00.00.0000 00:00Есть теоремы об аппроксимации функций перцептронами. Как считаете, все процессы, которые вы упомянули, поддаются описанию в виде функций, которые можно аппроксимировать, если добавить больше искусственных нейронов? И нужно ли аппроксимировать именно их, или достаточно попытаться получить результаты работы, как с ними, но не повторяя в точности их механизмы?

phenik
00.00.0000 00:00+1Свойства биологических нейронов, например, пирамидальных лучше моделируются целыми сетями ИНС, а не как обычно, просто взвешенным по входам сумматором с некоторой функцией активации, см. 1, 2, 3. Возможно, что куски сетей в современных архитектурах могут моделировать отдельные биологические нейроны, т.е. такие архитектуры можно рассматривать, как состоящие из "виртуальных" приближенно биологических нейронов, а не слоев формальных.
yatanai
00.00.0000 00:00+1Нужно понимать что способы кодирования информации у биологических нейронов и классических ИНС координально разные. ИНС оперируют числами а БНС сигналами, а сигналы можно кодировать по времени по частоте по интенсивности по фазе и вообще они не работают по одиночке и сигналы идут "волнами по коре". (А ещё эти сигналы модулируются на всех уровнях передачи)
Как сопоставить их в теме "кто лучше апроксимирует функции" я даже не представляю.
Могу лишь сказать что классические ИНС популярны больше из-за своей простоты и предметной ориентированности. Можно просто декодировать картинку и подавать данные как есть, в то время как биологическим надо кучу раз конвертировать, определится какой паттерн будет означать что сеть нашла котика на картинке, писать отдельный софт который бы находил эти самые паттерны и тд и тп.







Robastik
00.00.0000 00:00+20Применительно к
прорыв в нейросетевой обработке текстов
, несколько за рамками темы, но стоит упомянуть, что
связи типа «каждое слово с каждым»
в переводе на человеческий означает, что правила языка, т.е. грамматика (и пунктуация), не используются в принципе.
50 лет долбления всем миром в грамматику не научили языку ни одну железяку.
100 лет обучения грамматике умеющих говорить на своем языке никому не помогли лучше владеть своим языком для коммуникации (а не для сдачи экзаменов на знание грамматики).
Абсолютное незнание грамматики не мешает нейтивам с успехом пользоваться языком как средством коммуникации.В результате отказа от правил языка железяка сразу заговорила на всех языках.
Совпадение?
stalkermustang Автор
00.00.0000 00:00+8Интересная точка зрения :) Но это правда - раньше в модель зашивали как можно больше "понимания" того, как люди видят язык: синтаксические деревья, грамматику, прочее. А оказалось, что всё это не нужно, работает и без него (правда мы не можем определить, что внутри находится).

gatoazul
00.00.0000 00:00+13Разумеется, модель знает грамматику. Как и нейтивы. Просто это знание не в той форме, как написано в учебниках.

Nulliusinverba
00.00.0000 00:00+2есть два способа знать родной язык: читать учебники, и читать книги — МНОГО книг.
Devise1612
00.00.0000 00:00В результате отказа от правил языка железяка сразу заговорила на всех языках.
как-то Гугл статью писал что их Переводчик вроде как свой собственный язык использует и переводит "через него". если правда то получается что правила для языков не сильно-то и нужны
stalkermustang Автор
00.00.0000 00:00+6Там не совсем так, если я верно понял, о чем речь. Такие модели переводят текст в вектор (в набор чисел, очень большой набор, сотни и тысячи float'ов для каждого слова), а затем другая модель "читает" эти вектора и "переводит" их на иностранный язык. Но это не язык в прямом смысле - это просто метод сжатия информации из текста в числа, он же и в GPT, разбираемой в статье, применяется.
Devise1612
00.00.0000 00:00Но это не язык в прямом смысле
ну человек тоже не совсем слова и предложения воспринимает, не говоря про картинку. Тем более кто сказал что "язык" нейросети должен быть тем же что и для человека? Если убрать ээ фонетику то иероглифическая письменность ничем от такого отличаться не будет, так? А если это письмо читает с рождения глухой - как он это воспринимать будет?
Такие модели переводят текст в вектор
вы имеете в виду сверточную "подсеть"-классификатор на входе? Это еще не стало стандартом для всех более-менее серьезных моделей?
это просто метод сжатия информации из текста в числа
а чем текст в цифровом виде от числа отличается? А сжатие по определению подразумевает обработку.
нет, я не настаиваю тем более мои знания по нейросетям несколько устаревшие и со скажем так математической точки зрения но статья выглядела достаточно убедительной.
Скажите, а такие модели как GPT - что у них с переобучением? И как это будет выглядеть если допустим Гугл выкатит такую модель но с активным DeepLearning в своем поисковике?
stalkermustang Автор
00.00.0000 00:00+2вы имеете в виду сверточную "подсеть"-классификатор на входе?
я не понял, что значит классификатор, но нет. На входе стоит эмбеддинг слой, который по словарю переводит слово в вектор. Этот словарь дифференцируемый, то есть он обучается вместе с моделью, меняет чиселки в векторах.
а чем текст в цифровом виде от числа отличается?
модель не умеет работать с текстом, только с числами. На вход числа, внутри числа, на выходе числа. В этом смысле "текст в цифровом виде" модель вообще никогда не видит.
GPT - что у них с переобучением?
in general переобучить их очень сложно, потому что модели огромны. Но они легко переобучатся на одну маленькую конкретную задачу. Если будет активное обучение в онлайне, то всё должно быть ок, покуда есть очень большой набор тестов / метрик для отслеживания
Devise1612
00.00.0000 00:00что значит классификатор
вот такое если правильно статью понял
https://habr.com/ru/post/539312/
по словарю переводит слово в вектор
именно это я и имел ввиду. А поскольку вектор - уникален, то это эквивалентно внутреннему "языку" и непосредственно генеративная часть с этим внутренним языком и работает. А с использованием свертки этот вектор и контекст с собой несет автоматически
модель не умеет работать с текстом, только с числами
я так понимаю "чтение" с картинки это все-таки фича, а изначально - это ASCII-строка. Нет?
in general переобучить их очень сложно, потому что модели огромны. Но они легко переобучатся на одну маленькую конкретную задачу
я больше имел ввиду начинают ли такие модели "глючить" при переобучении? Можно ли этим объяснить ээ "вранье" и выдуманные тексты?
stalkermustang Автор
00.00.0000 00:00+1А поскольку вектор - уникален
я не согласен с этой точкой зрения, так как вектор для одного и того же слова разный в разных контекстах -> они как бы всегда уникальные, но по этой логике и рандомные вектора тоже уникальны, и это тоже "язык", хотя структуры и связей у них нет.
я больше имел ввиду начинают ли такие модели "глючить" при переобучении? Можно ли этим объяснить ээ "вранье" и выдуманные тексты?
Да, могут начать глючить, особенно если переобучены на конкретный фидбек. Про это можно почитать по прилагаемой в конце статьи ссылке на мою другую статью про ChatGPT - тоже очень увлекательно.
Но вранье это не должно объяснять.
Devise1612
00.00.0000 00:00я не согласен с этой точкой зрения, так как вектор для одного и того же слова разный в разных контекстах -> они как бы всегда уникальные
не совсем, если вы достаточно "грубо" метрику определяете то при достаточно большом числе параметров у вас будет более чем похожие вектора для одного слова в разных контекстах. Ну это в смысле математически - они, эти вектора, будут "примерно" в одном направлении, а следующий слой их по модулю отсортирует. Ну и при использовании свертки само собой что бы классификация появилась
где-то даже у Гугла такую статью тоже читал, года 2 назад
Про это можно почитать по прилагаемой в конце статьи ссылке на мою другую статью про ChatGPT
спасибо, почитаю
вранье это не должно объяснять
Hidden text
в порядке бреда - свертка снижает риск переобучения для классификатора(как вы написали embedde слой) но вектора подаваемые на выход после генеративной части заведомо менее мощные чем слой для вывода что вызывает его переобучение(количество слов в векторной форме которое модель может выдать сильно меньше числа параметров поскольку контекст/разные языки). То есть получится контекст запроса сохранен а выдает данные как при переобучении. Такое может быть?
Devise1612
00.00.0000 00:00так как вектор для одного и того же слова разный в разных контекстах -> они как бы всегда уникальные, но по этой логике и рандомные вектора тоже уникальны, и это тоже "язык"
еще один момент вспомнил против вашего мнения - гугл отлично переводит многоязыковые фразы. Контекст для отдельного слова очевидно разный - а промежуточный вектор так же очевидно один и тот же. Это легко управляется метрикой, и судя по всему - не очень сложно и дорого технически раз общедоступно
D1m1tr4dz3
00.00.0000 00:00Хм...
--
Можете глянуть в сторону Language tool. Там ИИ (как заверяют разработчики) как раз помогает с правкой грамматики (и т.п.).
--
Нейтивам плевать. Им "ехать, а не шашечки". Там правило 3.14 П: прагматизм, примитивизм, пофигизм.
--
Железяка заговорила на понятном нейтивам сленге. Языком ту жижу потока сознания - назвать сложно... Но - от оной и не требовалось)

PsyHaSTe
00.00.0000 00:00Как показала практика, запихивание "экспертных знаний" в систему только портит её, потому что люди сами ошибаются. В итоге нейронка "сама по себе" куда лучше учится, чем с такой "помощью". Это выглядит как если бы у семьи гепардов был подкидыш-орёл и они орла заставляли бегать на лапках чтобы добраться из точки А в точку Б. А что, поколениями гепарды выясняли, что именно бег является наиболее эффективным способом перемещения.
Robastik
00.00.0000 00:00поколениями гепарды выясняли
Даже в парадигме предложенной аналогии концы с концами не сходятся: при выяснениях все гепарды известны наперечет → закон Ньютона, преобразования Фурье, точка Кюри, шкала Фаренгейта и т.п.
А кто выяснил деепричастный оборот? Кто открыл падежи? Почему скрываются авторы трех склонений? (Я бы спросил → почему их на самом деле пять?)На мой взгляд, ситуация ближе к представлениям о плоской Земле. Никто ничего не выяснял. Наука заключалась в описании наблюдаемых явлений. "На трех грудных сегментах есть крылья и ноги. Этими сегментами являются переднегрудь, среднегрудь и заднегрудь." Образованный человек отличался от необразованного заучиванием этого бреда.
Поэтому "законы" и "правила" пестрели исключениями: "У паука и жука шесть ног? Но они не относятся к классу шестиногих!" Сравните → "Буква «ы» пишется только после твёрдых согласных, а после мягких и в начале слова идет «и». И неважно, что все говорят жЫр и жЫраф, писать надо жиши!".
Представляете себе исключения из закона Архимеда или из правила буравчика?)Поэтому грамматика → чистой воды плоскоземельщина.
vconst
00.00.0000 00:00Грамматика — это инструмент, с помощью которого определяется семантика предложения и сохраняется его смысл. Банальное "казнить нельзя помиловать" — семантика предложения диаметрально меняется с помощью грамматики
Сказать "грамматика — это бессмысленная плоскоземельщина" — это все равно что сказать "терминология — это бессмысленная плоскоземельщина". Потому что это понятия примерного одного порядка и назначения: формализация, ради однозначности понимания
Знаю я одного забавного чела, он искренне не понимает необходимости терминологии считает — что ее можно произвольно менять, когда надо "выиграть спор". Например, он считает — что Сайдуиндер первого поколения, это чисто механическая ракета, без всякой электроники. Когда его ткнули в определение термина "электроника", он сказал "А я считаю, что электроника это совсем другое, потому — я прав. В этой ракете нет элекетроники". Ну и о чем с таким говорить?
Грамматика — это тоже самое, но уровнем выше
PsyHaSTe
00.00.0000 00:00Так это касается не только грамматики. То же самое с переводом языков. То же со скажем игрой в шахматы. Попытки закодить "хорошие"/"плохие" дебюты, правила что конь стоит 3 пешки и т.п. закончились провалом, машины нашли более хорошие паттерны просто методом перебора.


zohraserhenova
00.00.0000 00:00+16Наконец-то появилась познавательная и увлекательная статья на русском языке, которую с радостью можно переслать друзьям не из айти) Большое спасибо за проделанную работу!


phenik
00.00.0000 00:00+7Думаю, если вам для каждого слова в разговоре пришлось бы решать по уравнению на полтора миллиарда параметров, то вы бы тоже стояли с примерно таким же лицом лица
Так у человека еще больше параметров в мозге, и слова также предсказываются, механизм даже сложнее, как показывают исследования, и обычно таких лиц не наблюдается)Это и есть тот самый переход количества в качество, про который нам когда‑то твердил старина Карл Маркс.
Вообще-то началось с диалектики Гегеля.Сразу бросается в глаза интересный нюанс: в отличие от GPT-2, сама модель теперь имеет размер больше (700 Гб), чем весь массив текста для ее обучения (420 Гб). Получается как будто бы парадокс: наш «нейромозг» в данном случае в процессе изучения сырых данных генерирует информацию о разных взаимозависимостях внутри них, которая превышает по объему исходную информацию.
Никакого парадокса нет, эти параметры моделей выбираются самими разработчиками — число параметров модели и объем обучающей выборки, в зависимости от аппаратных возможностей и имеющегося бюджета.Но это еще цветочки — еще более удивительно то, что GPT-3 смогла научить сама себя… математике! На графике ниже (источник: оригинальная статья) показана точность ответов нейросетей с разным количеством параметров на задачки, связанные со сложением/вычитанием, а также с умножением чисел вплоть до пятизначных. Как видите, при переходе от моделей с 10 миллиардами параметров к 100 миллиардам — нейросети внезапно и резко начинают «уметь» в математику.
Никакой магии, зависит от объема и содержания обучающей выборки, и соотношения с числом параметров модели, которое определяет величину сжатия информации. Всегда можно привести числа и операции с ними на которые модели ответят не верно. Для целых чисел это множество бесконечно, хотя и счетно, не говоря о вещественных, для которых еще и несчетно. Все примеры в обучающей выборке привести нельзя. Обобщения как у детей, после изучения таблицы сложения и умножения, и решения несколько сот примеров в школе и домашних заданиях, не происходит. Выход состоит в вызове внешнего калькулятора, как это предлагают некоторые разработчики. Аналогично со многими другими навыками.
Еще раз, вдумайтесь: языковую модель обучали продолжать тексты словами, а она при этом как‑то смогла сама разобраться в том, что если ей печатают «378 + 789 =», то на это надо отвечать именно «1167», а не каким‑то другим числом. Магия, ей‑богу, магия! (Хотя, некоторые говорят «да это нейросетка просто все варианты успела увидеть и тупо запомнить в тренировочных данных» — так что дебаты о том, магия это или всего лишь попугайство, пока продолжаются.)
И что-то не слова о фантазиях сетей) Хотя это не является их недостатком, а основой для творчества. Вот!
В остальном статья интересная. Спасибо! Пишите еще.stalkermustang Автор
00.00.0000 00:00+1Никакого парадокса нет, эти параметры моделей выбираются самими разработчиками — число параметров модели и объем обучающей выборки.
парадокс для читателя, мол, как так - текста меньше, чем сама нейронка, она ж его просто выучит, даже сжимать не надо.
Про внешние тулы типа калькулятора на 100% согласен. Более сложные примеры в статью кидать не хотелось, хотя они, безусловно, есть.
Обобщения как у детей не происходит после изучения таблицы сложения и умножения,
спорный тезис, даже вот на умножении - сетка решает больше 90% примеров для 3-значных чисел. Таких вариантов 900*900, 90% от этого это 729'000 примеров. я готов биться об заклад, что точно не все из них были в трейне, а значит модель ответила верно на такие примеры, которых не видела - смогла обобщить.

usego
00.00.0000 00:00+2Потестил
4325345.32423 / 345345.654
The result of dividing 4325345.32423 by 345345.654 is approximately 12.511207280582545. Правильный результат - 12.52468439701285 .
Интересно, как так получилось.
eptr
00.00.0000 00:00+1Попробовал "вытрясти душу" из него.
Кажется, получилось

Можно попробовать получить тот же результат без подсказки.
Умеет ли ChatGPT сам жульничать?
Вычислял ли он на самом деле или воспользовался подсказкой из моей информации?
sasha_semen
00.00.0000 00:00Логарифм ста посчитает?
eptr
00.00.0000 00:00Логарифм ста посчитает?
Посчитает:

Результат совпадает с полученным в Python'е. В принципе, ещё и подсказывает, как можно самому посчитать.
sasha_semen
00.00.0000 00:00Логарифм ста равен двум ) Естественно десятичный, натуральный в уме не считается.
vconst
00.00.0000 00:00В вопросе был задан — натуральный ))
Прикинуть, чему равен натуральный — можно и в уме, ессно весьма приблизительноsasha_semen
00.00.0000 00:00В моем вопросе основания не было, в этом и заключается подвох вопроса. Приблизительно 2.7 я не в 4 ни в 5 степень в уме не возведу.
eptr
00.00.0000 00:00+2Естественно десятичный
Совершенно неестественно.
Видите, и другие люди так же думают.Я сначала хотел уточнить, что раз не указан, значит, — натуральный, но не стал. Оказывается, надо было уточнить.
Что интересно, второй раз на вопрос по вычислению логарифмов пустой ответ пришёл, раньше с таким вообще не сталкивался:

По моим ощущениям, ChatGPT за последнее время "поумнел".
Уже не такой болван, как раньше, ответы явно адекватнее стали.Но они и писали несколько раз при login'е, что обновили и улучшили.
sasha_semen
00.00.0000 00:00Правильный ответ (по версии автора вопроса) - по какому основанию. И да, с явным указанием основания логарифма вопрос заметно упрощается.
Натуральный логарифм если не указано это хорошая, правильная логика. Но в контексте задачи на устный счет основание 10.
eptr
00.00.0000 00:00+1Ну, если даже я не догадался, что имелось ввиду, то грех требовать этого от ChatGPT.
ChatGPT обычно отвечает несколько в другом стиле: вместо того, чтобы переспрашивать, накидывает возможные варианты.
Так случилось и в этот раз (специально в новом чате спросил, чтобы старый контекст не повлиял):
В этот раз обошлось без пустых ответов.
phenik
00.00.0000 00:00The result of dividing 4325345.32423 by 345345.654 is approximately 12.511207280582545. Правильный результат — 12.52468439701285
ИНС универсальные аппроксиматоры. Удивляться нечему;)
Интересно, как так получилось.
eptr
00.00.0000 00:00+3ChatGPT "эволюционирует":
Или здесь ChatGPT врёт?
phenik
00.00.0000 00:00Или здесь ChatGPT врёт?
Приведенные вами примеры расчетов чата навеяли такие мыслиПоскольку документа с деталями, как работает чат от OpenAI пока нет, можно только догадываться какие средства они используют, кроме известных. Это вопрос приоритетов и больших денег, поэтому любые эффективные решения хороши, включая за пределами нейросетевых. Некоторые пользователи с опытом работы и тестирования продуктов в связанных с ИИ высказывают сомнение, что используются только средства базовой модели GPT-3, напр, в этой ветке обсуждений. Известно о модерации политкоректности модели известной, как версия 3.5, MS в чате поиска Бинга использует обращения к инету для генерации ответа. Что еще может использоваться пока можно только догадываться.
Что касается любых вычислений в любом контексте, то они требуют понимания смысла чисел, их обобщений, включая операций с ними, и выработки процедур работы с ними. По роду проф. деятельности знаком с некоторыми подробностями, включая нейрофизиологическими, функционирования этих механизмов в мозге, см. этот комент с пояснениями. Можно ли эти механизмы воспроизвести полностью исключительно в языковых моделях, не прибегая к аналогам этих механизмов в мозге? В этой ветке с автором статьи обсуждали эти моменты, но не пришли к пониманию, и пока без ответа остался последний комент. Автор статьи видит решение проблемы вычислений в использовании внешнего калькулятора. Обосновывается это тем, что модель еще не обладает достаточным количеством параметров и объемом обучения, и в перспективе может самостоятельно производить любые вычисления. Об этом свидетельствует динамика тестов для разных моделей. Однако эту динамику можно объяснить ростом числа и разнообразия примеров вычислений в растущей по объему обучающей выборке, включая использования математических ресурсов, и ограниченностью самих тестов.
Человек также прибегает при вычислениях к использованию калькуляторов и других средств, особенно в сложных вычислениях. Но принципиально люди способны их производить самостоятельно, устно (есть с феноменальными способностями), т.к. обобщили обучающие примеры, и развили соответствующие процедурные навыки. Однако это имеет предел, из-за ограничений вычислительных ресурсов мозга, первую очередь рабочей памяти. Для вычислений с любыми числами потребуются, как минимум бумага и карандаш, для расширения этих возможностей, и они будут происходить медленно. Системы общего ИИ также могут использовать внешние средства вычислений, но не потому что им не хватает собственных вычислительных ресурсов, а по причине, что они пока не способны на такое обобщение и выработку внутренних процедур вычислений на ограниченной выборке примеров, как это может делать человек. Для этого необходимо выйти за пределы только языковой модели, и дополнительно использовать другие типы архитектур сетей, которые адекватно моделируют не только ассоциативные мышление, объясняющее, в том числе, фантазии чатов, но также логическое, концептуальное и приемы критического мышления. А также образного мышления, связанного с восприятием, воображением, интуицией, инсайтом, см. формы мышления.
Интересно было бы протестировать чат на примерах которые требуют приближения к неформальному (нативному) пониманию смысла чисел, в которых они заданы не явно. Это неформальное понимание у человека состоит в том, что, например, при быстром взгляде на две совокупности предметов, при котором он не успеет произвести их точный подсчет, он может сказать в какой совокупности сколько предметов, и какая совокупность больше. Человек и животные обладают такой, эволюционно выработанной, способностью, и могут статистически достоверно оценивать численность в пределах некоторой дисперсии оценки, отношение которой к численности предметов постоянно, что описывается законом Вебера. При этом количество в 3-4 предмета оценивается, как правило, точно. Как не странно на этом нативном чувстве численности возникло абстрактное понимание чисел, основывается вся арифметика, и немалая часть остальной математики.
В случае языковых моделей сцены могут описываться только текстуально, и соответственно более формально, чем в зрительных, слуховых и др., даже если не использовать слова обозначающие числа. Кажется, что это должно упрощать задачу подсчета. В этой новости приводилась такая задача:«Три женщины в комнате. Две из них являются матерями и только что родили. Теперь входят отцы детей. Сколько всего людей в комнате?»
ChatGPT не справился с ней, другой чат от Гугл, как пишут, дал правильный ответ. Хотя у читателей приведенное решение вызвало разногласие, и фантазии сравнимые с фантазиями самих чатов) Боле сложная задача состоит в оценке без использования чисел, типа:
«В большой комнате играют Вася, Маша, Коля, Толя и собачка Бобик, в маленькой комнате играют Митя и Гриша. Гриша ушел, а Маша и Бобик перешли в маленькую комнату. Сколько детей играет в каждой из комнат?»
Человек при решении подобных задач часто привлекает воображение, иногда подсознательно, подсчитывая объекты с учетом их манипуляций. Это ограничивает варианты возможных решений, и фантазирование на тему. При этом словесное описание задания транслируется во внутреннее образное представление. Таких возможностей в языковых моделях пока нет, и они должны ориентироваться только на ассоциативные и логические связи содержащиеся в задании.
Что касается использования калькулятора, то можно использовать задание, которое предполагает его гарантированное отсутствие в обучающей выборке из-за экзотичности, требует сложного вычисления, которое можно произвести только с помощью калькулятора. Например:
«Чему равно значение числа пи в степени числа символов в этой строке?»
Ответ: 3,1415926535897932384626433832795^68 = 6,4001675451695384066840142936703e+33
Так посчитал виндовский калькулятор. У меня пока нет возможности сравнить это с ответом чата.
eptr
00.00.0000 00:00+2Сначала нейронка ChatGPT не поняла контекста, что имеется ввиду сама строка с вопросом:

Нейронка ChatGPT здесь не поняла до конца контекст вопроса. Поэтому я переформулировал вопрос, и получился длинный диалог

Некоторое тестирование нейронки ChatGPT на "чувство численности". В целом, у меня сложилось впечатление, что некоторое "чувство численности" у нейронки ChatGPT имеется, но его характер несколько отличается от человеческого.
У человека точность резко падает с ростом количества, а у ChatGPT эта зависимость значительно плавнее.Заставить её вызвать калькулятор у меня не получилось, устал с ней биться, потому что она, порой, "плохо слушается".
При этом она часто демонстрирует эффект Даннинга-Крюгера: "я никогда не стараюсь жульничать, моя цель - быть точной и полезной", "я посчитала сумму букв правильно", хотя ни то, ни другое -- не верно.
Соврать может на каждом шагу, например, пишет:
4 + 5 + 8 + 5 + 2 + 1 + 7 + 5 + 8 + 1 + 6 + 2 + 5 + 8 = 64
Если вычислить данную сумму, то окажется, что она равна 67.
Это не говоря о том, что часть слагаемых — неправильная, хотя берёт она их из своего же ответа и на ходу же часть из них заменяет на отличающиеся на 1.Но сразу же соглашается, если её вывести на чистую воду: "Извините, я допустила ошибку в своих предыдущих сообщениях. Действительно, третье с конца слово "числа" имеет 6 букв, а последнее слово "вопросом?" — 9 букв."
Возможно, механизм явления Даннинга-Крюгера у неё похож на оный у человека.
Alsuss
00.00.0000 00:00Можно предположить, что система считает символы в английском переводе вашего запроса, естественно, что их количество не совпадает с исходным запросом сформулированном на русском языке (судя по скриншотам)
stalkermustang Автор
00.00.0000 00:00Все еще сложнее. Модель не знает, сколько букв в словах и сколько символов в цифрах. Дело в том, что на вход подаются и не слова, и не буквы - а нечто среднее между ними. Почитать про это подробнее можно в начале упомянутой в конце статьи (или в моем профиле чекнуть первую публикацию). Для нее "2014" будет одним словом, и в нем 4 символа, и "father" будет одним словом, в котором 6 букв. С английским модель +- понимает "длины" слов, и то путается, а в русском там вообще ужас .
phenik
00.00.0000 00:00Все еще сложнее. Модель не знает, сколько букв в словах и сколько символов в цифрах. Дело в том, что на вход подаются и не слова, и не буквы — а нечто среднее между ними.
Токены внутренний формат модели. Обучалась модель на нормальном тексте из символов, в котором было полно примеров с числом символов в словах, предложениях и кусках текста. Ее не спрашивают посчитать длину текста в токенах, а именно в символах.
phenik
00.00.0000 00:00Можно предположить, что система считает символы в английском переводе вашего запроса
На английский можно перевести по разному, напр, так
What is the value of pi to the power of the number of characters in the line with this question?
Это перевод трансформера Гугла (Яндекса аналогично) поэтому должно соответствовать переводу, который они, скорее всего, используют.Не совпадает не число слов, тем более символов. Для русских слов расхождение только для
этим — вместо 4-х 5-ть, см. на скриншоте выделено в черном окне.
Поэтому скорее всего чат выдавал ответ для вопроса на русском, но ошибся для одного слова.Проблема в том, что GPT-3 может генерировать ответы случайно. Вот здесь хорошо объяснено, с примерами кода, см. параметры сэмплирования. Поэтому в новой сессии те же вопросы могут привести к другим ответам. В коментах к разным статьям посвященных чату приводились такие примеры. Это не очень хорошо для математики, которая требует строгость и повторяемость, и других областей требующих точность. Но хорошо для искусства, например генерации стихов) для которых важна ассоциативность.
В чате поиска Бинга MS даже ввела переключатель режима общения, который как-то регулирует этот процесс.
stalkermustang Автор
00.00.0000 00:00Однако я отмечу, что судить по модели исходя из математики - очень наивно. Зачем модели уметь это делать, если она может пользоваться калькулятором? браузером? Использовать кожаных для удовлетворения своих потребностей?
eptr
00.00.0000 00:00+1Однако я отмечу, что судить по модели исходя из математики - очень наивно. Зачем модели уметь это делать, если она может пользоваться калькулятором?
Если судить по получающимся результатам, то видно, что они явно не точны.
Модель приходится уламывать воспользоваться калькулятором.
До сих пор не знаю, удалось мне уломать её или нет в этом посте.
Модель, в частности, написала:Я - компьютерная программа, которая имеет встроенный калькулятор и может вычислять математические выражения. Так что, когда я выполняю математическую операцию, я использую встроенный калькулятор. Однако, когда я даю ответ на вопросы, связанные с математикой, я могу использовать и другие методы, включая статистические модели и предсказания, если это применимо.
Очень похоже на правду, с поправкой, что, в первую очередь, используются "другие методы", иначе такую низкую точность не объяснить.
Поскольку до этого я ей сообщил, какой результат я считаю правильным (потому что я верю, что реализация Python'а считает правильно, и что процессор у меня в компе не глючит на этих вычислениях), так и непонятно, использовала она в том диалоге свой встроенный калькулятор на самом деле или нет.
phenik
00.00.0000 00:00Однако я отмечу, что судить по модели исходя из математики — очень наивно.
Не стоит творить мифологию, и создавать неоправданные, завышенные ожидания у читателей. Эта технология много еще чего не может делать толком. Однако это не умаляет ее значение.
Зачем модели уметь это делать, если она может пользоваться калькулятором? браузером?
Так где эта точность вычисления с помощью калькулятора? Практически ни одного корректного в приведенных примерах. У меня сложилось впечатление, что вызова калькулятора нет. Окна с примерами кода на Питоне только иллюстрируют его, но не исполняются. Возможно все это появится в будущих версиях. Пока используется только то чему модель обучалась, и верные результаты часто получаются путем наводки со стороны пользователя в диалоге, как при подсказках нерадивому ученику)
Devise1612
00.00.0000 00:00сложилось впечатление, что вызова калькулятора нет. Окна с примерами кода на Питоне только иллюстрируют его, но не исполняются
фактическое и самостоятельное использование таких функций в рамках одного запроса - это уже рекуррентная сеть будет, разве разработчики об этом заявляли хоть в каком-то виде?
Наверное можно увидеть такое использование при прямом запросе, только надо иметь в виду что ответ "результатом исполнения такого кода будет 12" не значит что код был исполнен
phenik
00.00.0000 00:00+1фактическое и самостоятельное использование таких функций в рамках одного запроса — это уже рекуррентная сеть будет, разве разработчики об этом заявляли хоть в каком-то виде?
Как это делает человек? Формулирует идею решения задачи, затем воплощает ее в коде и запускает на исполнение с целью проверки результата. Можно обучить чат этой последовательности дополнив вызовом Питона. Как пример, на этот вопрос
«Чему равно значение числа пи в степени числа символов в строке с этим вопросом?»
чат генерирует сейчас такой ответ с примером кода
Человек может запустить его сам и посмотреть результат. Но можно предусмотреть в чате опцию при включении которой после генерации ответа он не выводит его, а запускает код на исполнение. Результат добавляется к промпту и возвращается чату для получения нового ответа, который уже выводится пользователю. Там может быть и ошибка исполнения, как с эти будет поступать чат зависит от того чему его учили. Можно и по другому как-то сделать, это первое, что приходит в голову.stalkermustang Автор
00.00.0000 00:00+1Именно в этом направлении сейчас движутся системы - модели "говорят" (в промпте), что если ты хочешь сделать X - перед этим напиш какой-нибудь тэг, типа <python>, потом регуляркой парсят ответ, и как только появился закрывающий тег - код вырезается из текста, вставляется в интерпретатор и отрабатывает, а результат дописывается в промпт. То же работает с api-вызовами, да хоть с чем. Поэтому модель, которая только "пишет" текст - фактически может делать всё что угодно, раздавая команды другим исполнителям как командный центр.
А про исправление ошибок - так пусть модель сама их будет понимать и предлагать решения! Прямо как человек. И это уже работает: https://t.me/denissexy/6822
Devise1612
00.00.0000 00:00Как это делает человек? Формулирует идею решения задачи, затем воплощает ее в коде и запускает на исполнение с целью проверки результата
это и есть рекуррентная сеть - ее вывод является одновременно для нее же входом без дополнительного участия "оператора"
Можно обучить чат этой последовательности
это явно к GPT не относится - дикие затраты на обучение без гарантированного результата, достаточно обширные варианты "ввода" не приводящие ни к чему, "вывод" при отсутствующем "вводе" и прочие радости. Не думаю что такие сети есть в вариантах отличных от исследовательских. Тем более такого масштаба - несколько лет тратить большие деньги и получить в итоге не управляемый генератор белого шума
чат генерирует сейчас такой ответ с примером кода
если вас спросить "сколько будет 1+1" вы тоже вряд ли будете встроенным калькулятором пользоваться - "чувство численности" достаточно простое и почти наверняка в модели реализовано "по факту".
Кроме того, это для вас лично "57" от "69" принципиально отличается - модели может быть важнее что-то другое, о чем вы вообще не думали. Например может только символы из основной таблицы считать, и тому подобное.
ответ модели "в результате выполнения этого кода выводится 57" - вовсе не значит что этот код был на самом деле выполнен. Например - если вас лично спросить про число символов во фразе "один" - вы же не будете какой-то код выполнять?
предусмотреть в чате опцию при включении которой после генерации ответа он не выводит его, а запускает код на исполнение
если модель изначально эти все возможности в себе содержит - то она и так это сделает, просто при соответствующем виде запроса.
Вы не пробовали у разработчиков поинтересоваться какой именно вид запроса нужен для такого результата?
может быть и ошибка исполнения, как с эти будет поступать чат зависит от того чему его учили
это не ошибка ни в каком виде - chatGPT вполне себе машина и нет никаких оснований ее в "неискренности" или там "лени" подозревать. Просто ваши мысли она не читает а ваш прямой запрос трактует как в ней заложено, причем вам эта трактовка заранее не известна
phenik
00.00.0000 00:00это и есть рекуррентная сеть — ее вывод является одновременно для нее же входом без дополнительного участия "оператора"
Скорее циклическая процедура, и почему без участия оператора? Если обнаружились ошибки исполнения или результата работы не соответствуют ожидаемым, то программа корректируется, и запускается вновь. Рекурсии не может быть внутри трансформера, которая является сетью прямой архитектуры, но во вне циклы организовать возможно.
ответ модели "в результате выполнения этого кода выводится 57" — вовсе не значит что этот код был на самом деле выполнен.
Как раз такого не утверждал, сомневаясь, что на каком-то этапе чат вызывает калькулятор или Питон, судя по приведенным примерам. В самой сети происходит аппроксимация значения на основе обучающих примеров. Чем таких примеров было больше, тем результат точнее. Но это не все. На выходе результат может варьироваться в зависимости от параметром сэмплирования (см. этот перевод с примерами кода, если не в курсе как это происходит). Что для математических приложений не очень хорошо, повторные запуски задачи в новых сессиях могут приводить к разным результатам. Человек также может давать приближенные значения операций с большими числами, особенно, если время ответа ограничено, и если чувство численности не нарушено. Если нарушено по каким-либо причинам, в зависимости от объема нарушений, то выполнение операций становится проблематичным, вплоть до простого сложения 3 + 5, или умножения 3*2. Это нарушение называется дискалькулией.
Проблема сетей типа GPT в том, что они не могут сделать обобщение арифметических операций с любыми числами на конечном числе примеров, как это могут делать даже дети, только приближения в виде аппроксимаций. В этом отношении они чем-то напоминают поведение дискалькуликов, т.к. не понимают смысла чисел. Как-то интересовался этим вопросом — почему они не могут сделать обобщение на основе аппроксимации, т.е. точного вычисления результатов после обучения на конечной выборке. Возможно ответ связан с выбором решения этой проблемы (1, 2) — принятия или не принятия континуум-гипотезы. Хотя автор второй статьи считает, что эта проблема не имеет значение для обучения нейросетей. Для практического применения нет, но вот влияние на уровень обобщаемости может и имеет. Человек решает эту проблему по другому, в отличие от обучения ИНС. Точнее он обладает способностью частично обобщать примеры используя нейропластичность, т.е. меняя связи синапсов в определенных областях мозга, но точное обобщение с получением процедур вывода может использовать другой нейрофизиологический механизм. Это механизм морфогенеза, т.е. когда в мозге меняются не только связи существующих синапсов, но и появляются новые связи, новые синапсы. Условно говоря по ходу дела мозг меняет архитектуру нейронных сетей, механизм который пока совершенно не доступен в существующих ИНС. Прунинг не в счет, это удаление несущественных связей. Кстати, эти процедуры счета рекуррентные, и еще и по этой причине, конкретно в архитектуре GPT они не могут быть реализованы, как вы писали.
Процесс обобщения в мозге это может быть переход от одного представления в виде примеров в одной области мозга, одной структуры нейросетей, к другому представлению, в виде концептов, с другой архитектурой, в другой области. Возможно это как-то позволяет обходить ограничения в упомянутой проблеме связи обучаемости с решением гипотезы континуума. Т.е. она и действительно для мозга не существенна, в отличии от обучения ИНС.
И еще… эти предположения могут быть моими бреднями, продвинутыми ассоциациями, на манер ответов чатажпт)
phenik
00.00.0000 00:00+1Спасибо за ответ!
Если вычислить данную сумму, то окажется, что она равна 67.
Это не говоря о том, что часть слагаемых — неправильная, хотя берёт она их из своего же ответа и на ходу же часть из них заменяет на отличающиеся на 1.Это вероятностная модель языка, а не символическая с правилами вывода. Ответы также генерируются вариативно, в новой сессии получите другой вариант ответов на те же вопросы) В таком виде для работы с математикой мало подходит, приходится все проверять. Калькулятор и Питон похоже не вызываются. Возможно это появится в будущих версиях.
stalkermustang Автор
00.00.0000 00:00Возможно это появится в будущих версиях.
это можно запромптить уже сейчас, правда вызовы придется делать самому (то есть модель выдаст инпуты-аргументы, или код, а выполнить его надо на реальном пк)
vconst
00.00.0000 00:00Это вероятностная модель языка, а не символическая с правилами вывода
Скорее даже — вероятностная модель мышления. Когда ответ не "рассуждается или вычисляется" — а "вычисляется на основе вероятностей".
phenik
00.00.0000 00:00Ассоциативного уровня мышления, выраженного на языке, а этих уровней у человека полно. Так что есть еще в каких направлениях ИИ совершенствоваться)
vconst
00.00.0000 00:00Мммм…
Ну, не сказал быАссоциации — это чисто психологические эффекты, математики там ноль, предсказать, какую ассоциацию вызовет у человека тот или иной стимул — почти невозможно, только для самых общих, разве что. ГПТ пытается имитировать их — вероятностями, чисто математически
phenik
00.00.0000 00:00+1Ассоциации — это чисто психологические эффекты, математики там ноль
Ассоциативность конкретно в GPT
phenik
00.00.0000 00:00Покороче можно здесь посмотреть. Основная идея в той статье изложена в двух пунктах в этой цитате
We use two approaches. First, we trace the causal effects of hidden state activations within GPT using causal mediation analysis (Pearl, 2001; Vig et al., 2020b) to identify the specific modules that mediate recall of a fact about a subject (Figure 1). Our analysis reveals that feedforward MLPs at a range of middle layers are decisive when processing the last token of the subject name (Figures 1b,2b,3).
Second, we test this finding in model weights by introducing a Rank-One Model Editing method (ROME) to alter the parameters that determine a feedfoward layer’s behavior at the decisive token.
phenik
00.00.0000 00:00спорный тезис, даже вот на умножении — сетка решает больше 90% примеров для 3-значных чисел. Таких вариантов 900*900, 90% от этого это 729'000 примеров. я готов биться об заклад, что точно не все из них были в трейне, а значит модель ответила верно на такие примеры, которых не видела — смогла обобщить.
Обобщения как у человека нет, т.к. для этого используются возможности, которых пока нет у языковых моделей, типа процедурной памяти. На самом деле все еще сложнее, т.к. мозг динамическая система, нагрузка на определенные участки может приводить не только к изменению связей синапсов, но и росту и образованию новых, особенно в молодом возрасте.
Возможно объяснение состоит в том, что ИНС считаются универсальными аппроксиматорами со стохастически обучением и оптимизацией. Поэтому некоторые аппроксимации будут выдавать правильные ответы для некоторых примеров, которых не было в обучающей выборке. Для некоторых приблизительно правильные, для некоторых неправильные. Чем больше примеров, и чем они распределеннее, тем лучше аппроксимация, тем больше правильных ответов. Также качество аппроксимации будет зависеть от степени сжатия информации в модели, т.е. соотношения числа параметров и объема выборки, где-то есть оптимум.Veanules
00.00.0000 00:00процедурная память [...] накапливает опыт выполнения предыдущих действий, обеспечивая исполнение аналогичных действий впоследствии
В каком-то смысле процесс обучения инс в этом и состоит
некоторые аппроксимации будут выдавать правильные ответы для некоторых примеров, которых не было в обучающей выборке
Это конечно не как у детей, но все еще обобщение
Впрочем, с таким колличеством нейронов у нее в "мозгу" могло возникнуть вообще что-угодно, в том числе и около-человеческая логика вычислений

Bronx
00.00.0000 00:00Вообще-то началось с диалектики Гегеля.
Вообще-то, началось с "парадокса кучи" Евбулида Милетского и с "корабля Тесея" Плутарха.









acsent1
00.00.0000 00:00+3Когда уже в клавиатуры начнут внедрять, чтобы реально угадывал что я хочу сказать. А то сейчас даже падеж не могут угадать с учетом предыдущего слова

kazimir17
00.00.0000 00:00Спасибо, интересна статья. Такой вопрос: существует ли примерное понимание почему человек учится значительно быстрее нейросети и на значительно меньших объемах данных?
stalkermustang Автор
00.00.0000 00:00+1Такое наверняка исследуют, но я не углублялся, поэтому не отвечу чего-то содержательного.

uhf
00.00.0000 00:00Не быстрее, человек рождается с претренированной миллиардами лет эволюции нейросетью. Потом она дообучается, но тоже не сказать что быстро.
stalkermustang Автор
00.00.0000 00:00+1Да, вот, я примерно об этом думал. Мы сеть инициализируем рандомно при обучении, и потом с помощью оптимизационных градиентных методов "сходимся" к ChatGPT. И потом уже не учим, а показываем примеры и заставляем решать задачи (или даже не показываем). А у челвоека приор как бы задан, инициализация есть - с первой секунды дышит (после шлепка по попе), итд
eptr
00.00.0000 00:00Я бы не был столь категоричен.
Модель — языковая?
Тогда — вопрос: сколько времени человек учит язык, хоть свой родной, хоть не родной?SeftopAlpha
00.00.0000 00:00С языковой моделью пример может быть и не столь удачный. А вот модели для распознавания образов очень сильно проигрывают человеку в скорости обучения. Любой 5-летний ребенок, который хотя бы пару раз видел собаку, будет практически со 100% точностью распознавать большинство остальных собак. Нейросети же для подобного трюка требуется на несколько порядков больше данных.
eptr
00.00.0000 00:00Если выполнить всю ту предобработку образов, которая имеется у человека и не только у него, а затем применить модель, эффективную для распознавания образов, то — что получится?
Примерно то же самое, что и с языковой моделью?
Если подумать, то выяснится, что там не образы, а видео, то есть, в динамике.
Это может иметь существенное значение.
Devise1612
00.00.0000 00:00+3Любой 5-летний ребенок
это вы очень круто планку задали, прям скажем так безумно. Вы примерно представляете нейросеть сравнимой мощности?
со 100% точностью
нет, такая точность даже для человека что-то из ряда вон. 90-95% - нормальная "для человека".
модели для распознавания образов очень сильно проигрывают человеку в скорости обучения
это легко объяснимо - человеческое зрение не основывается на головном мозге, а модель сравнимая по мощности со "зрительным нервом" - будет такую же скорость показывать. В то же время у модели для распознавания образов не будет присущих человеку "глюков" - обширных, разнообразных и постоянных

Soukhinov
00.00.0000 00:00+21Это разные механизмы обучения.
Рассмотрим гипотетического ребёнка, который в пять лет впервые увидел собаку. Ребёнок, перед тем, как увидеть собаку, видел миллионы разных других образов и знает, что это были «не собаки». У него уже сформированы почти все необходимые нейронные связи, и для распознавания собаки недостаёт совсем чуть-чуть. Это раз.
Но это всё ещё не объясняет способности распознать собаку по паре обучающих примеров… А пара ли примеров? Дело в том, что ребёнок обычно видит собаку живую, в движении. Он видит не фотографию, он видит видео, да ещё и двумя глазами (почти 3D). В итоге даже одну собаку ребёнок видит во многих разных позах с разных сторон. Это два.
А теперь самое главное. Когда в описанной ситуации ребёнок только учится распознавать собаку, то вначале включается совсем другой механизм (не тот, который используется при обучении нейросети на классификацию изображений). А именно: детекция аномалий. Это три.
Поясню про детекцию аномалий. Прежде всего, ребёнок должен откуда-то узнать, что перед ним аномалия. Например, если ребёнок раньше видел только кошек, то велика вероятность, что собака будет распознана, как кошка. Ребёнок покажет на неё пальцем, радостно скажет «кошка», и пойдёт дальше. Должно быть некое обстоятельство, которое заставит ребёнка понять, что перед ним аномалия, усомниться. Например, этим обстоятельством может быть сильное отличие собаки от наблюдавшихся раньше кошек (например, размер), или указание другого человека: «Смотри! Собака!».
Дальше срабатывает обучение на основе аномалии: ребёнок начинает выделять признаки из наблюдаемого объекта до тех пор, пока вероятность принадлежности собаки всем остальным известным ему классам не станет ниже определённого порога; до тех пор, пока для него собака не станет уникальной. Применительно к собаке ребёнок сразу может понять, что наличие шерсти не является отличительным признаком (если он раньше видел кошек), а аномальным признаком может оказаться размер — ребёнок может изначально запомнить собаку, как «большую кошку». Затем в жизни у него могут случиться ошибки распознавания, и модель будет уточнена.
Я знаю про детекцию аномалий вот откуда: я аутист и не различаю людей. Несколько раз, когда какой-нибудь человек меня упрекал «Ты почему не здороваешься?» я спрашивал его «Чем твоя внешность отличается от всех остальных людей в этом городе?». Удивительно, но он не мог ответить на этот вопрос. Я тогда говорил «Если ты сам не знаешь, чем ты отличаешься от других людей в городе, то как ты можешь требовать от меня, постороннего человека, это знать? А без знания отличий я не смогу тебя распознать. Мы с тобой знакомы всего пару месяцев, виделись, наверное, всего раз 30, у меня пока не образовались в мозгу натренированные на твой образ нейронные сети».
Впоследствии я стал замечать вот что: один человек мог впервые увидеть второго человека, а затем, через час, мог увидеть его снова и узнать! Как это возможно, если узнавший человек не спал между этими двумя событиями, и, значит, у него не могли образоваться соответствующие нейронные связи (лично я все подобные задачи решаю через сон). Далее, я слушал рассказы людей о том, как они с кем-то познакомились, и прочее, и прочее. В итоге я понял, что изначальное запоминание человеком человека идёт именно через детекцию аномалий: когда человек A знакомится с человеком B, человеку A не нужно проводить доказательство отличности человека B от всех остальных людей в городе (он этих людей мог даже и не видеть), вместо этого человек A начинает извлекать признаки из человека B до тех пор, пока человек B не станет для человека A уникальным (аномалией) по сравнению со всеми людьми, которые человеку A известны, и которых он обычно видит вокруг себя, когда ходит по городу. Извлечённые признаки можно положить в кратковременную память (без перестройки нейронных связей), и этим пользоваться. К сожалению, мне такой метод недоступен, и я могу различать только нескольких, хорошо знакомых мне людей, которых видел много раз.
Детекция аномалий чрезвычайно субъективна, так как опирается на личный опыт человека, именно поэтому такой опыт не может быть передан другому человеку, и вопрос «Чем ты отличаешься от других людей?» не имел смысла.
vconst
00.00.0000 00:00+1Совершенно офигительный комментарий!
Без воды, мемасиков и максимум по делу.
Статья хороша, потому — нельзя сказать, что он лучше статьи, как это часто тут бывает. Но он точно не хуже и очень хорошо ее дополняет
Если вы решите написать статью по этой теме — будет очень круто. Мысли вы выражаете очень четко и доступноsasha_semen
00.00.0000 00:00Комментарий аутиста же. Прям в стиле Шелдона.
vconst
00.00.0000 00:00Шелдон такие длинные монологи не произносил ))
А тут не только аутичность, но и сама проблема узнавания и тренировки хорошо разобрана

dolovar
00.00.0000 00:00Шелдон — искусственно созданный собирательный образ. В частности, эйдетическая память, выручавшая Шелдона, присутствует очень не у всех носителей синдрома Аспергера.
anonymous
00.00.0000 00:00НЛО прилетело и опубликовало эту надпись здесь

pennanth
00.00.0000 00:00Мозг натренирован на "своих", поэтому выискивает детали, вариативность которых выше у знакомых лиц. Молодые китайцы, к примеру, хорошо отличают европеоидов благодаря Голливуду, но при этом с трудом отличают корейцев от китайцев (что, в принципе, не очень просто, но возможно).
Фактически, отличия определяются по размерностям с большим разбросом в популяции.

DGN
00.00.0000 00:00Как интересно. Я в первом классе всех детей делил на мальчиков и девочек. Ибо есть четкий признак - форма, а мелкие признаки я не обрабатывал. Учителей я не узнавал вне школы, они прям бесились. Слова аутизм в нашем ауле тогда наверное не знали... Алгоритм сбоит до сих пор, меня знает куда больше народу чем я, одно время некомфортно было в метро из за этого.
acsent1
00.00.0000 00:00Пока не понятно как на самом деле мозг устроен. Когда поймут, тогда и расскажут почему

RomTec
00.00.0000 00:00почему человек учится значительно быстрее нейросети и на значительно меньших объемах данных
А может спросить у самого ChatGPT ? ))
yatanai
00.00.0000 00:00БНС это детекторная модель по сути своей. А там суть в том, что выживаемость нейрона зависит от того, сможет ли он найти на что реагировать. Ибо оптимизация просто убивает нейроны которые не работают.
ЗЫ классические детекторы на ИНС просто запоминали данные которые были на входе и по каким-то алгоритмам модифицировали свои веса что бы чаще паттерн находить. Всякие нейроны Кохонена и всё-такое из этой области, но они слишком упрощены чтобы от них был реальный толк.

RalphMirebs
00.00.0000 00:00+2Объем 700 гиг не так и много. Интересно, как скоро подобные сети покинут облака и можно будет скачать "готовую" модель аналогичной сложности для установки и запуска локально?

YMA
00.00.0000 00:00Как я понял, это 700 гигабайт рабочих данных, которые нужно перемолачивать для каждого запроса. То есть нужно условно терабайт оперативки и очень многоядерный процессор, а то и не один?
А вот чего не понял, так это механизма появления новых умений при наращивании количества параметров модели. То есть есть некие пороговые значения, при преодолении которых эта штука обретает новые умения? Качественный скачок?
Или просто при наращивании количества параметров растет процент удачных случаев, когда эти умения срабатывают как надо, а не выдают галлюцинацию?Devise1612
00.00.0000 00:00+2А вот чего не понял, так это механизма появления новых умений при наращивании количества параметров модели. То есть есть некие пороговые значения, при преодолении которых эта штука обретает новые умения? Качественный скачок?
Тоже так думал пока не увидел что там графики логарифмические. Так что никакой "магии" нет, голый брутфорс за исключением влияния архитектуры. Рановато наверное для такого еще, надо больше мощностей
vconst
00.00.0000 00:00+2можно будет скачать «готовую» модель аналогичной сложности для установки и запуска локально
Я с куда бОльшим интересом жду, когда можно будет арендовать машинное время напрямую у AWS или подобной конторы, но без всяких политкорректных и моральных ограничений.
Просто «заплатил, получил и никто не лезет в твои запросы», корректируя ответы по повесточке, или лишь бы в суд не обратились — полностью под мою ответственность но и в полном обьеме.
В таком виде — «приватный чат в аренду» этот механизм здорово облегчил бы многие бытовые вопросы, не будучи ограничен вымораживающей политкорректностью корпораций, типа МС, которая ужом вьется в попытках угодить и вашим и нашим.stalkermustang Автор
00.00.0000 00:00Я прошу прощения, а для каких бытовых вопросов надо давать такие запросы и получать соответствующие ответы, что они корректируются моделью и/или фильтром уже сейчас?
vconst
00.00.0000 00:00Вы хотите от меня неполиткорректности такого уровня, за который меня могут забанить )) Потому мне и хочется «своего и приватного» ))
Devise1612
00.00.0000 00:00«своего и приватного»
вы неверно понимаете работу нейросети - все запросы и ответы на них если они включены в обучающую выборку - включены полностью и для всех.
нельзя сказать "не учитывай поправки №№123456789...", они вносятся помимо механизма собственно функционирования, модель о них не знает
арендовать машинное время напрямую у AWS
любой сторонний пользователь в обратном случае может спросить "какие запросы отправлял пользователь vconst" и ему подробно и точно ответят. Даже если вы в явном виде запрос "не сохранять в памяти/стереть" - это будет точно так же сохранено в полном объеме только еще с указанием что именно вы хотели "спрятать"
«приватный чат в аренду»
никакой аренды, кто несет все затраты тот и рулит. Готовы на постоянной основе для личного использования ВЦ не самый маленький содержать?
vconst
00.00.0000 00:00Я все это понимаю и провожу прямые аналогии с сервисами типа AWS, благодаря которым мне не надо держать ЦОД — а просто заплатить за нужное машинное время.
В ЦОДе тоже не секрет, что у меня на VPS делается — они же предоставляют мне услуги, но меня это не парит, потому что в открытый инет ничего не торчит и статистика не сливается всем и каждому
А вот «какие запросы отправлял такой-то» — такого быть в паблике не должно, как их нет для любого пользователя условного гуглояндекса
И да, хочется модель, которая только натренирована, но не ограничена
___
Вопщем, я и так уверен, что это обязательно произойдет. Корпы щяс и так бьются над тем — кто первее смастерит свой «гпт». Рано или поздно — эта технология появится «просто в аренду», как есть. Заказываешь вычислительный обьем, устанавливаешь/снимаешь ограничения — и пользуешь как хочешь, без всякой цензуры, которую вводят корпы боясь судов и обвинений в предвзятости. Как сейчас сдают напрокат рендер-фермы или серваки набитые числомолотилками для счета хешей или майнинга
Но — хочется пораньшеanonymous
00.00.0000 00:00НЛО прилетело и опубликовало эту надпись здесь
vconst
00.00.0000 00:00+1Ну вот хочется без этого «безопасного поиска», который выключаю во всех поисковиках. Потому что чем дальше — тем сильнее будут ограничивать, через полгодика он будет выдавать гугловый аналоги «из выдачи на странице были удалены дцать материалов из-за ляляля» на каждый второй запрос. Не буквально канешн, но извиваться ужом, не давая прямого ответа
Devise1612
00.00.0000 00:00хочется модель, которая только натренирована, но не ограничена
сомнительно, "цензура" является частью обучения а потому и не входит в интерфейс. И она в любом случае влияет на модель целиком, нету отдельного куска который можно поправить
Корпы щяс и так бьются над тем — кто первее смастерит свой «гпт». Рано или поздно — эта технология появится «просто в аренду», как есть
так потому и бьются что это невозможно в аренду взять.
Не, так-то то что вы хотите не должно быть сильно сложно реализовать - но кому и зачем это надо? В любом случае архитектуру определяет тот кто платит а он явно не заинтересован в такой модели
А вот «какие запросы отправлял такой-то» — такого быть в паблике не должно, как их нет для любого пользователя условного гуглояндекса
кто вам такую чушь сказал? то что у вас вот лично нету решения суда которое Гугл к исполнению примет - не значит что это решение потребуется "админу васе". И совершенно точно это решение не нужно да и не известно самой модели. Тут вопрос к простому сводится - или модель помнит вашу уникализацию или нет. Платите за "уникализацию в аренду" - получаете бесплатный бонус
vconst
00.00.0000 00:00сомнительно, «цензура» является частью обучения а потому и не входит в интерфейс
Ну да, потому — должен быть выбор моделей, обученных разным образомпотому и бьются что это невозможно в аренду взять.
Как выясняется — это очень много кому надо. Потому все из кожи вон лезут — первым удовлетворить потребность
Не, так-то то что вы хотите не должно быть сильно сложно реализовать — но кому и зачем это надо?кто вам такую чушь сказал? то что у вас вот лично нету решения суда
И? По решению суда, любой NB! может получить доступ к моим запросам в гугль?
Апсалютли ноуDevise1612
00.00.0000 00:00должен быть выбор моделей, обученных разным образом
стоимость каждой этой модели - будет точно такая же как и на общей выборке. Как разработки так и функционирования
Потому все из кожи вон лезут — первым удовлетворить потребность
почему Гугл или МС тогда не могут просто арендовать у OpenAI?
это очень много кому надо
надо, да - но свое, контролируемое
По решению суда, любой NB! может получить доступ к моим запросам в гугль?
осенью даже убийцу натурального поймали, основанием для приговора суда послужил листинг с таймингами поисковых запросов в Гугл. Известный случай и вряд ли одиночный. Но конечно "любой" и "решение суда" странно сочетается
vconst
00.00.0000 00:00Фарш невозможно провернуть назад. Технология есть, рано или поздно кто-то ее повторит и масштабирует. Я ставлю на китайцев
Devise1612
00.00.0000 00:00это несомненно, а учитывая общедоступность - разработчиков будет достаточно много.
но в любом случае - ваша уникализация будет собственно вашей только если разработчик - вы
vconst
00.00.0000 00:00Не нужно прямо очень точное обучение, под конкретные нужны, индивидуально Достаточно несколько наиболее востребованных шаблонов
Один для программистов, другой для рерайторов и тд тп
Devise1612
00.00.0000 00:00не имеет значение сколько именно это "несколько" - это или будет входит в общую модель с сопутствующими затратами либо каждый "шаблон" будет иметь свою стоимость.
Разница в вычислительных затратах между функционированием нейросети и ее обучением - радикальная. Нужны же какие обоснования для этих затрат? Вполне возможно что генерализованная версия дешевле получится, это лучше наверное у автора спросить
vconst
00.00.0000 00:00Я думаю, это будет развиваться как майнинг. Сначала им занимались энтузиасты, а сейчас — крупные компании, но это все ещё выгодно

siarheiblr
00.00.0000 00:00Надеяться, что в сетке от китайцев не будет цензуры это, скажем деликатно, оптимистично :)
Devise1612
00.00.0000 00:00Заказываешь вычислительный обьем, устанавливаешь/снимаешь ограничения
есть два варианта - эти ваши "ограничения" либо считаются вне модели, локально там или фильтры какие, либо модель дообучается. К чему приводит первое я написал ниже, а второе - помимо того что это должно быть заложено изначально как бы это сказать
сдают напрокат рендер-фермы или серваки набитые числомолотилками
мелькало где-то то ли у Гугла то ли MS что один запрос на большую модель с активным deeplearning - порядка 5 тыр баксов. В случае GPT - запрос это один токен на выходе, если не ошибаюсь
Если вы такое лично не готовы платить - то заплатит разработчик. Но он эти ограничения по своему усмотрению расставит, ориентируясь очевидно на среднее для всех возможных пользователей
vconst
00.00.0000 00:00Как есть выбор операционных систем и количества ядер при заказе ВПС — так будет выбор искинов, обученных на том или ином материале
Это вопрос времени, не более тогоодин запрос на большую модель с активным deeplearning — порядка 5 тыр баксов
Массовый спрос на такие модели — приведет к уменьшению цены за услугуDevise1612
00.00.0000 00:00Как есть выбор операционных систем и количества ядер при заказе ВПС — так будет выбор искинов, обученных на том или ином материале
конечно будет, вместе с варп-двигателем и его цветом. Вопрос времени, да
Массовый спрос на такие модели — приведет к уменьшению цены за услугу
ну это же не от спроса зависит а от цены вычислений. Будет смартфон за 100 баксов иметь 100500 ТФлопс - будет и цена соответствующая
vconst
00.00.0000 00:00Крупные цод-провайдеры перенесут часть мощностей на чгпт. Рост потребности увеличит выпуск полупроводников и тд тп. Не через месяц, но это произойдет
Devise1612
00.00.0000 00:00ну вообще-то есть достаточно много производителей специализированных процессоров как для обучения так и функционирования нейросетевых моделей. Видеокарты те же с тензорными вычислениями.
Принципиально вопрос цены это все равно не решает - дорого и еще раз дорого. А в том виде какой вы описали - еще несколько раз дорого.
vconst
00.00.0000 00:00Спрос рождает предложение. Через год-два что-то подобное уже будет. Может не в точности, как я сейчас предполагаю, но в некоторой степени — обязательно будет
Сейчас это стоит 20 баксов в месяц на одной модели. Не сказать, что очень дофига. Через год будет 1-5 баксов, потом начнется разнообразие предложений от разных хостеров и тд тп
Devise1612
00.00.0000 00:00Спрос рождает предложение. Через год-два что-то подобное уже будет
да уже лет 5 как есть и спрос и предложение, причем в объемах которые OpenAI и не снились. Все камеры серьезные уже с такими чипами для препроцессинга и сжатия и не известно что еще
Сейчас это стоит 20 баксов в месяц на одной модели. Не сказать, что очень дофига
я думаю это даже затраты не отбивает, цели такой и не ставилось и единственно служит для ограничения доступа - что бы их не ДДосили
DGN
00.00.0000 00:00Каждый человек купивший смартфон, содержит у себя в кармане не самый маленький ВЦ образца 1970 года.
Я хочу в общем немногово, обучить сетку всем своим диалогам, текстовым и звуковым, закинуть историю посещений сети с логинами, список прочитанных книг и список контактов. На выходе пусть пробует отвечать максимально близко ко мне. Это, скажем так, доступный на сегодня вариант цифрового бессмертия. Или удобный личный секретарь.
Devise1612
00.00.0000 00:00Каждый человек купивший смартфон, содержит у себя в кармане не самый маленький ВЦ образца 1970 года.
ВЦ что в 1970 что сейчас стоит примерно одинаково - многоденег. Хотите модель которой нужен ВЦ уровня 1970 - покупаете смартфон, ну а иначе...
Я хочу в общем немногово, обучить сетку всем своим диалогам, текстовым и звуковым, закинуть историю посещений сети с логинами, список прочитанных книг и список контактов
Допустим, вы заимели некий локальный или даже облачный модуль который обучается на всем этом но лично для вас, а потом в адаптированной лично для вас форме делает запрос на основные "общие" сервера. Мощность вашего модуля(количество уникальных состояний отличных друг от друга и приводящих к разным ответам) заведомо меньше мощности основной модели на порядки что приводит к переобучению вот прям сразу и вообще никак не может быть устранено. Это идентично тому что вы пользуетесь ТОЛЬКО вашим локальным модулем просто у которого большая внешняя статичная таблица содержащая ответы, которая впрочем все равно не превышает мощности вашего локального модуля.
И зачем вам такое надо? Кому это вообще может быть нужно?

rogoz
00.00.0000 00:00Каждый человек купивший смартфон, содержит у себя в кармане не самый маленький ВЦ образца 1970 года.
Топовый суперкомпьютер 1995.
PsyHaSTe
00.00.0000 00:00+1Берете обычную модель, берете промпты которые отключают алайнмент тренировки, задаете вопросы.
vconst
00.00.0000 00:00Хм…
А можно поподробнее? Достаточно ссылки )PsyHaSTe
00.00.0000 00:00На форчане есть профильные разделы где промтинжинеринг прокачивают. Я не фанат но товарищ любит обучаться, и эффект заметен. Потом можно скормить промпт бингу с просьбой улучшить — он обычно справляется, если правильно попросить.

tenzink
00.00.0000 00:00Кажется, что про похожую историю я уже где-то читал:
Клапауций думал, думал, аж сморщился весь и сказал: -- Ладно. Пусть будет о любви и смерти, но все должно быть выражено на языке высшей математики, а особенно тензорной алгебры. Не исключается также высшая топология и анализ. Кроме того, в стихах должна присутствовать эротическая сила, даже дерзость, но все в пределах кибернетики.
-- Ты спятил. Математика любви? Нет, ты не в своем уме... -- возразил было Трурль. Но тут же умолк враз с Клапауцием, ибо Электрувер уже скандировал:
В экстремум кибернетик попадал От робости, когда кибериады Немодулярных групп искал он интеграл. Прочь, единичных векторов засады! Так есть любовь иль это лишь игра? Где, антиобраз, ты? Возникни, слово молви-ка! Уж нам проредуцировать пора Любовницу в объятия любовника.
Станислав Лем. Путешествие первое А, или Электрувер Трурля, 1964г

ssj100
00.00.0000 00:00По этой теме уже упоминал, так как 1 в 1 похоже, правда в другом переводе
tenzink
00.00.0000 00:00До Электрувера пока не дотягивает. Я попросил написать стих, где все слова начинаются на А. Вот что получил:
Алый арбуз аппетитно ароматен,
Авось алчный ананас аналогично ароматен.
Алчный авокадо аккуратно аранжировать,
Ароматный арбуз аппетитно разрезать.
ssj100
00.00.0000 00:00Ну зачатки рифмы есть: тен-тен… ать-ать
Не знаю как я бы справился, но думаю что нетtenzink
00.00.0000 00:00+4Я немного поэкспериментровал. Чем длиннее стих, тем хуже с рифмой. В примере с буквой "А" под конец модель забыла про первую букву и выдала "разрезать". Но результат всё равно впечатляет. Вот какой шедевр она может выдать на запрос "Please, write a poem in Russian about love in the language of calculus":
Как функция, любовь может иметь точки экстремума,
Но любые трудности - всего лишь локальный минимум.
Берегите свой график любви, будьте бдительны,
Чтобы любовь всегда оставалась дифференцируемой.morijndael
00.00.0000 00:00Спасибо за идею, надо попробовать написать с ней...научно-технический рэп! :D
tenzink
00.00.0000 00:00Не за что. Идея не моя, я её у Лема стащил - "Путешествие первое А, или Электрувер Трурля"

Vorchun
00.00.0000 00:00+9Отличная статья! Вижу много статей про применение нейросетей, а тут показано откуда ноги растут. Понятно и доходчиво )
Я настороженно отношусь к бурному применению нейросетей. Ощущение, что весь контент будет сгенерирован сетями, а поиск (в т.ч. в chatgpt) будет по сгенерированному. И отделить зерна от плевен будет крайне затруднительно.
Т.е. все радуются, что учиться не надо - составил запрос и получил ответ. Но учиться как раз надо, чтобы оценить качество ответа.
Почему-то сразу все стали доверять ответам, но при этом ругаются на тех, кто доверяет первому каналу (условно).
Но погубит нас не это. А разработка по скраму - когда главное релизнуть, а если там ошибки, то пофиксим потом.

Dasyo
00.00.0000 00:00+5«Я построю свой ChatGPT, с блэкджеком и шлюхами! И вообще, к черту ChatGPT и блэкджек! Ай, к чёрту всё!»

Iguana2
00.00.0000 00:00+4T9 меня ни разу не подставляла. Я ее сразу отключал. И сейчас на всех устройствах и всех клавиатурах отключены подсказки, проверки и прочая лабуда. Я сам умный(имхо)))

anonymous
00.00.0000 00:00НЛО прилетело и опубликовало эту надпись здесь
stalkermustang Автор
00.00.0000 00:00+1пользователь выставляет некие параметры кто он, что ему интнересно, на каких областях сконцентрироваться и тогда качество результата можно будет ещё повысить.
я думаю что компании пойдут еще дальше, и будут в чатботов сами пропихивать собранный по интернету профиль. Гендер, увлечения и хобби, последние 5 видео на ютубе...ну а сетка это будет подхватывать и создавать интересные диалоги, мол, давай обсудим, что там было, а он чё, а она че, а ты че.
anonymous
00.00.0000 00:00НЛО прилетело и опубликовало эту надпись здесь
Devise1612
00.00.0000 00:00будет существовать несколько профайлов — типа рабочий, где настроены ваши рабочие предпочтения, домашний, хобби и т.п.
это так не работает, надо наоборот все максимально объединять для лучшей уникализации.
Непосредственно разделение - на уровне контекста. Собственно это и сейчас у того же Гугла есть - причем он даже разные одновременные сессии для одного пользователя ведет

divomen
00.00.0000 00:00+2Нашел сегодня реализацию ChatGPT для WhatsApp: http://whatsgpt.ai
Работает быстрее чем сайт, как ни странно.
Пишут что есть какие-то ограничения, но у меня денег не просило.
Простой способ познакомится, какое это чудо :)
По мне - так убьет Гугл, если Гугл не сможет предложить чего-то лучшего, с актуальными данными и умением предоставлять реальные ссылки на источники.
AlexSpirit
00.00.0000 00:00Вот что она о себе пишет. "Я создан на основе языковой модели GPT-2 (Generative Pre-trained Transformer 2)"
divomen
00.00.0000 00:00Нет, это на ChatGPT API сделано. GPT-2 так и близко не умеет.
Но иногда отвечает всякую чушь :)
stalkermustang Автор
00.00.0000 00:00да, это фейк чатгпт, которая в лучшем случае является тюном на русский язык открытых (маленьких) instruction-based моделей, но скорее всего просто тюном на диалог GPT-2/опенсурсных гпт. Жаль, что такое происходит - очень много рекламы и в тг, и на других ресурсах с буквальным обманом.
divomen
00.00.0000 00:00+3Нет, это не фейк. Я тестил, ответы абсолютно такого же уровня как у ChatGPT. То есть это значить что это сделано через СhatGPT API, так как других моделей подобного уровня пока не существует. И кстати, после скольки-то сообщений они попросили подписаться на их сервис за 10 долл в месяц. Платеж через stripe, то есть явно это не мошенничество.

FoxWMulder
00.00.0000 00:00спасибо за ссылку, посмотрел. плохо то что в них закладывают ограничения на темы. на втором вопросе она отказалась отвечать мне. с такими ограничениями они не интересны. просто информацию можно и погуглить. ждëм дальше.

aret777
00.00.0000 00:00+1Жду возможности создать свой аналог Чат-ЖПТ, но натренерованный на новостных сайтах, научных исследованиях и на политических реддитах/комментариях пикабу в политике, дабы мог потом баллотироватся в политику и на дебаты брать ЧатЖПТ :D

dmt_ovs
00.00.0000 00:00+7stalkermustang, спасибо за отличную статью!
Не совсем понял такой момент в примере про боксеров: "Мы просто дописали пять дополнительных слов в конец нашего промпта" .
Как видно на скрине - мы не дописывали 5 слов в вопрос, это уже было частью ответа ChatGPT - "Ответ: Давай подумаем шаг за шагом"
При этом в начале вы указали, что такое промпт: "Тот текст, что мы подаем на вход, называется prompt (промпт, или «запрос/затравка» по‑русски). Чем точнее он описывает, что мы хотим, тем лучше модель поймет, что ей нужно делать."

RationalAnswer
00.00.0000 00:00+3В обоих примерах всё, что не выделено жирным - это часть промпта, который подается на вход модели. То есть, в первом примере текст, который вводится в модель, кончается словом "Ответ:"
В каком-то смысле это логично: если мы хотим, чтобы модель именно попыталась решить заданную задачку, надо ей подсказать, что мы ждем ответ. Иначе она может решить, к примеру, что надо продолжить придумывать более сложную задачу (я сейчас фантазирую) и дописать после слов промпта "Сколько ударов он нанес?" от себя еще доп. задание "И насколько это больше ударов, чем у его соперника по имени Остап, который нанес 40 ударов за бой?" - почему бы и нет?
stalkermustang Автор
00.00.0000 00:00+4Павел исчерпывающе ответил, добавить нечего :) Промпт в широком смысле - это не только вопрос, но и что его окружает, включая слова-подсказки. Можно попросить еще перед этим в написать запрос в гугл, мол "сгенерируй строку, которую я должен вставить в поисковик, чтобы найти сопроводительную информацию для ответа на вопрос" - и это будет работать. Вот пример ниже (текст во втором сообщении я вставил сам, копировав из википедии, но легко понять, как можно делать это скриптом автоматически)

commanderxo
00.00.0000 00:00+4Интересно, никого не смущает, что вопрос был сколько ударов нанёс Иван, а сеть ответила про достижения какого-то Васи?
stalkermustang Автор
00.00.0000 00:00+1аххахах ахаххахахах точно! Исправили, спасибо) Не представляю, как ВСЕ это упускали из виду)
dmt_ovs
00.00.0000 00:00Хм, а слона то я и не заметил)
Вообще в статье это видимо синтетический пример, а не реальный ответ от ChatGPT.RationalAnswer
00.00.0000 00:00+5В оригинале везде был Вася, а потом я решил, что если уж речь про боксеров - то просто необходимо вставить мем с Иваном Драго. Но тупо забыл поправить в ответах.)
Короче, как обычно - кожаные мешки ошиблись!
stalkermustang Автор
00.00.0000 00:00+1Да, синтетический, я сначала писал текст, а потом загнал вопрос в чатгпт и даже приложил скрин (там он сам инструкцию придумал для решения по действиям, без указания на step by step). На редактуре мы вырезали, решив, что текста хватит. А потом и текст поправили, добавив мем. Уот так уот(


Yuriks111
00.00.0000 00:00+1@stalkermustang спасибо за статью + к карме.
Помоги разобраться как (если) GPT3 может работать за рамками OpenAI\базового ChatGPT:
1) Все кому не лень запускают свою языковую модель "на базе GPT-3". Что они имею ввиду если доступ на нее только через API OpenAi? Просто свой интерфейс?
2) То что запустил Bing - это вроде на той же модуле, но не ChatGPT. Т.е. это как форк парметров и дальше ChatGPT и Bing строят свою модель сами? или опять просто обертка?
3) Много разговоров что GPT-3 можно дотренировать на узкую область (напр внутр данные компании) и использовать как супер аналитический инструмент. Как это может работать без риска что внутр данные могут использоваться моделью для диалога с любым другим пользователем? Крупные банки наперегонки запрещают сотрудникам использовать ChatGPT...
stalkermustang Автор
00.00.0000 00:00+1Без понятия, что имеют в виду конкретные компании. Снапчат, например, использует API и, видимо, дописывает специальный промпт в начало диалога. Возможно, они дообучили её отдельно на диалоги тинейджеров, чтобы сетка была "в теме".
Деталей мало, но я склонен полагать, что это дотюненная модель, в которую "пришили" инструмент запроса. См. пример выше с картинкой, где используется токен [G] для отправки в гугл. Еще можно читнуть вот тут: https://t.me/seeallochnaya/83
Я не думаю, что GPT-3 надо дообучать, это дорого и неэфективно. Прваильный промпт + инженерия с API вокруг модели - ключ к успеху. Но при этом всё равно все данные будут отправляться в OpenAI, тут не знаю, что делать.
rPman
00.00.0000 00:00api openai предлагает методы по дообучению, модель будет храниться на серверах openai, полистай доку, она скудная, предполагается что народ сам разберется как этим пользоваться
stalkermustang Автор
00.00.0000 00:00+1Там (пока) нельзя тюнить ChatGPT. В целом это логично - ведь она учится на оптимизацию фидбека, и такие данные в APi для дообучения не запихать просто так. там предлагается просто скинуть N файлов с plain-текстом и модель дообучится как GPT-2/3, просто предсказывать следующее слово.

gjnext
00.00.0000 00:00составить че-то там в стихах тютчева
Я буквально позавчера просил чат, прости его госпаде, джи пи ти составить стих из 4 строк, так он выдавал "стихи" без малейшей рифмы (на русском и на немецком). Потом я попросил сгенерить рифму к 1 слову, но мне под видом рифмы выдавалось все что угодно, кроме рифмы. При чем чат специально подчеркивал, что сгенерил рифму ("слова заканчиваются на одинаковые звуки"), выдавая слова с совершенно разными окончаниями, типа "сова - кустарник"
пример стиха от завтрашней замены тебя:
Звезды горят высоко,
Ночь тиха и безмятежна,
Душа моя полна мечты,
Счастлив я в своей тишине.

vagon333
00.00.0000 00:00+2Самое доступное изложение эволюции нейросетей и принципов работы.
Благодарю и безусловно плюсую.

svoezemtsev
00.00.0000 00:00+3Напомнило компьютерные шахматы. Сначала обсуждали, может ли машина играть сильнее человека.
Потом машина стала играть хорошо - да, тактик она замечательный, но стратегии не понимает. И как ее стратегии научить?
Следующий этап - с ростом скорости счета (железо и особенно алгоритмы) оказалось, что стратегии особо-то ее учить и не надо. Она ее "сама" поняла.
И современная ситуация - никто в здравом уме победить машину в шахматы не берется. У нее учатся. Только возникла обратная проблема - многие ходы машины непонятны. "Да, что-то там она на глубине видит" - типичный комментарий к ходу, который человек не в состоянии понять.

AlexEx70
00.00.0000 00:00Что у них там по планам дальше, не пишут? Очень жду модель на триллиончик параметров.
stalkermustang Автор
00.00.0000 00:00+3Модель на триллион уже была, но она представительница "разреженных" (sparse) сетей со структурой "Микстура экспертов".
Мы этого не сказали в статье, но GPT состоит из одинаковых блоков, и они "стакаются" друг над другом - выход первого идет во второй, второй в третий и так далее - и таких слоев в больших моделях по сотне. В терминах нашего примера с уравнениями это типа y' = k1 * x + b1, y = k2(y')+b2, (два слоя, выход первого идет во второй). Каждый блок имеет свои параметры, разумеется - просто структура одинаковая.
Так вот микустура экспертов - это когда вместо каждого блока их, скажем, 100, но применяться будет всего 1 - и есть отдельная маленькая нейросеть (Router), которая предсказывает, какой из этих 100 лучше использовать. Самый просто способ про это думать - это что разные эксперты отвечают за разные языки и за разные области знаний. Если спросить на немецком про историю Берлинской стены - будет использовать эксперт номер 8, например, а если про Пушкина - номер 19. За счёт того, что эти блоки параллельные, их можно делать много, и это и приводит к триллиону параметров. Однако число параметров, используемых во время генерации, будет пропорционально количеству слоев, а не кол-ву слоёв*кол-во блоков (используем по 1 эксперту за раз)
Yuriks111
00.00.0000 00:00Блоки это те же слои (layers) но не последовательно а параллельно ?
"y' = k1 * x + b1, y = k2(y')+b2" так "нейроны" взаимодействуют
stalkermustang Автор
00.00.0000 00:00+1Привет, нет, блоки как раз последовательно идут, каждый состоит из нескольких слоёв внутри.



neee3k
00.00.0000 00:00Все постоянно говорят о ЧатГПТ, все вокруг уже с ним общаются, говорят, что он в свободном доступе. Подскажите, пожалуйста, как я могу с ним пообщаться, на русском он есть? Кто-нибудь киньте, пожалуйста, ссылочку?
SnakeSolid
00.00.0000 00:00Если просто пообщаться, то проще всего через этого телеграмм бота - GPT_chat_robot. Там по умолчанию автоперевод на русский для экономии токенов, если хотите стихи или код генерировать можете его отключить через меню.

grigorym
00.00.0000 00:00Очень интересная статья, спасибо! Я вижу только вот такую дырку в понимании у тех, кто хочет познакомиться с технологией. У численной линейной регрессии на входе - число. А что на входе у текстовой генеративной модели? К чему применяются 100500 неизвестных нам параметров модели, чтобы получить выход, к словам промта или к числам?
stalkermustang Автор
00.00.0000 00:00Если сильно упрощать, то все слова из некоторого словаря, скажем, размера 50k-100k можно закодировать 0 и 1: единица если слово есть, 0 - если нет. Тогда большинство коэффициентов на первом уровне будет (на первом слое нейросети) умножено на нуль и сократится. Помимо этого, чтобы порядок слов имел значение, аналогичная вещь существует и для соотнесения слова и позиции.

thunderspb
00.00.0000 00:00+1Спасибо за статью. Может уже было в комментариях, но не раскрыта тема "гипноза/нлп" бота, это я про DAN. Если честно, то это пугает больше, в целом))) тут сразу куча "документальных" фильмов голливуда вспоминается. :)

East_Star
00.00.0000 00:00Мне интересно, обучается ли нейросеть непрерывно или это условно разовый процесс? Если она получает обратную связь от своих ответов не только как «верно»/«не верно» от собеседника, но и из внешних источников, то как быстро она научится делать так, что чтобы дать высоко вероятно верный ответ одному собеседнику, ей нужно будет под свой ответ дать несколько созависимых ответов другим собеседникам?
Грубый пример. Если я спрошу её, выгодно ли мне покупать завтра акции apple, она не зная верного ответа, даст ряд созависимых ответов на похожие вопросы другим людям, что акции нужно срочно сливать. Таким образом акции начнут падать в цене и она даст мне ответ, что да, завтра стоит покупать.
В общем, пока нейросети просто дают информацию на основе скормленной им информации, они выглядят как большие энциклопедии. Как только они начнут влиять на скармливаемую им информацию, вот тут начнутся проблемы, о которых мы можем узнать слишком поздно.
stalkermustang Автор
00.00.0000 00:00Это итеративный, но не непрерывный процесс. Модель генерит, скажем, 1000 пар ответов на случайный пулл вопросов (может и сама вопрос сгенерить, но я пока такого не видел). Это именно пары, чтобы можно было сказать, какой ответ лучше - первый или второй, и, собственно, на этом примере обучать модель предказывать тот ответ, который был оценен выше, с бОльшей вероятностью.
Потом как 1000 примеров размечены - модель на них дообучается, но тут штука в том, что всё сложнее под капотом: на самом деле помимо 1000 этих примеров с помощью хитрых трюков модель учится примерно на еще 10-20 тысячах сгенерированных ей самой ответов (и ею же оцененными).
После чего идет следующая итерация.
даст ряд созависимых ответов на похожие вопросы другим людям, что акции нужно срочно сливать. Таким образом акции начнут падать в цене и она даст мне ответ, что да, завтра стоит покупать.
поэтому такой сценарий считаю маловероятным. Тем более не ясно из примера, коким был фидбек на её ответ исходный - его нужно как положительный или как отрицательный рассматривать?
ftf
00.00.0000 00:00+1Классная статья, спасибо авторам
Погружен в тему nlp те ничего нового практически не узнал, но написано очень хорошо, было интересно читать

astromill
00.00.0000 00:00а где то можно скачать ChatGPT 3 или 3,5 чтобы можно было установить на свой сервак так скажем для контроля конфиденциальности.
stalkermustang Автор
00.00.0000 00:00+1Нигде, как и указано в статье - OpenAI не публикует эти модели, только по API.
Сегодня увидел релиз открытой версии от другой команды, модель-аналог, можно попробовать поиграться с ней: https://t.me/seeallochnaya/160
MartaD
00.00.0000 00:00+2Спасибо за статью! Очень интересно и доступно написано. Ждём следующих статей.
Nickolashka
00.00.0000 00:00+2Спасибо за статью, написано слегка самоуверенно и неточно в мелочах (например, законы диалектики - это философия Гегеля, а дословно сформулировал переход количественных изменений в качественные Фридрих Энгельс, а не Карл Маркс), но в целом, наверное лучший русскоязычный научпоповский материал по теме. Самая интересная вытекающая тема - как раз философская, не сказать теологическая: что можно считать интеллектом, какие критерии. Ну и душа и все дела. Так что пишите есчо ;)

kylikovskix
00.00.0000 00:00+1Удивительно, что в статье нет информации о том, как обойти ограничение использования ChatGPT на территории России. Буквально на днях узнал о существовании расширения Merlin для Chrom-а, который позволяет обойти проверку по номеру телефона.

microArt
00.00.0000 00:00+2"мы хотели подробнее обсудить и проблемы контроля за искусственным интеллектом, и жадность корпораций, которые в высококонкурентной погоне за прибылью могут случайно родить ИИ‑Франкенштейна, и сложные философские вопросы вроде «можно ли считать, что нейросеть умеет мыслить, или всё же нет?»."
Большое спасибо за статью.
Конечно, хотелось бы побольше подобных статей по теме с ответами на эти вопросы.RationalAnswer
00.00.0000 00:00+1Завтра уже будет продолжение, в том числе затронем часть этих вопросов)

haryaalcar
00.00.0000 00:00Только вот Т9 это не предиктивный набор, это система набора для кнопочных телефонов «Text on 9 keys». И всё.
Вроде как автор в начале даёт на это ссылку, но дальше упрямо продолжает использовать некорректное название.
stalkermustang Автор
00.00.0000 00:00Так сноска для этого и введена, чтобы дальше не вызывало отторжение. Это как написать "дальше мы будем писать X, но подраузмевать Y".
Более того - т9 можно представить как языковую модель, которая работает по нулевому контексту и предсказывает следующее слово (которое просто является текущим), делая приор на нажатые кнопки.
staticmain
Да, конечно, давайте просто качать все тексты из интернета, ни у кого не спрашивать разрешение на использование, а потом зарабатывать на этом кучу денег. Что с visual arts, что с GPT - да пошли они в капибару, авторские права ваши. История с deviantart и artstation никого ничему не учит.
zaiats_2k
Тот трагический час всё ближе, когда новая версия Windows будет написана ИИ, обученной на stackoverflow.
Jubilus
Блин, а было бы круто. Сразу бы продажи повысились из-за всей этой популярности нейросетей.
qbertych
А код для обучения со stackoverflow будут брать из ответов или из вопросов?
Voiddancer
Да
user5000
Вот все удивятся, если ещё и получится лучше нынешней Windows 11.
D1m1tr4dz3
Наоборот - радостный! Там хоть какой-то автотест будет перед релизом)
Да и к-во изменений между 10 и 11 виндой намекает, что не так уж и много "писать" нужно для 12ки =)
Мне надоело воевать с багами после 2015 и решением стала LTSB \ LTSC...
HuckF1nn
Ваше утверждение с логическим провалом - это примерно как код Python будет написан IDE, которая его читает. ChatGPT не пишет ничего, она код, который читает другой код.
gatoazul
Вообще-то сначала надо доказать, что авторское право покрывает использование текстов в нейросетях.
Anton_Olegovich
Мы поручим отстаивание авторских прав кожаных мешков в суде следующей версии нейросети! ))
urvanov
Судья тоже будет нейросетью, и ответчиком тоже будет нейросеть. Две нейросети уж как-нибудь между собой договорятся.
vak0
Сериал "Оливье и роботы" Последняя серия первого сезона. Категорически рекомендую. Как раз про ИИ и судебный процесс.
JetHabr
Zima Blue
Lizdroz
Зачем? Вы же тоже кожаный мешок. Вам какой смысл?
Anton_Olegovich
Хорошо, что я прошёл ваш тест Тьюринга. ))
logran
Да-да. Белковые нейронки пусть ходят по artstation, смотрят на выложенное (в свободный доступ для просмотра!!) и учатся на этом, а вот кремниевым — уже ни-ни. Ведь формирование новых нейронных связей в белковом мозгу от взгляда на визуальный образ — это норм, а изменение коэффициентов весов у заранее сформированных (до взгляда на на визуальный образ т.к веса инициализируются заранее) нейронных связей в кремниевом мозгу — уже преступление. Хотя по своей сути процесс ± идентичен (как и результат), разница лишь в скорости усвоения.
stalkermustang Автор
Причем железки в скорости проигрывают, берут числом, обучаясь одновременно на 100500 GPU. По итогу вроде и всего за месяц нейронка прочитала весь интернет, а вроде и 10000000000 GPU-часов (просто эффективно распаралелленных)
nikolay_karelin
Это называется https://en.wikipedia.org/wiki/Moravec's_paradox ;)
SadOcean
Любой человек может зайти на реддит и прочитать сообщение (и даже зарепостить)
И сделать на его основе свои выводы.
Тысячи лет человечество развивалось на распространении информации, а тут все как с цепи сорвались.
staticmain
Они не скачали сообщения с реддита, они скачали сайты по ссылкам из сообщений.
Ohar
И в чём разница?
Jubilus
Это другое, да?
D1m1tr4dz3
Луддитов - дармоедов разгонят со многих областей, начиная с образования.
Вот и сорвались. Понять толком не могут, но попой чуют "западло")
MRD000
Вы пробовали дать ChatGPT кусочек кода и объяснить почему вот те две строчки так написаны?