Из-за шумихи вокруг Bing AI и Bard у меня возникло желание создать свою маленькую поисковую систему с искусственным интеллектом. Повозившись несколько дней, я выпустил Ask Seneca. Это небольшое приложение на основе GPT, с помощью которого можно поболтать с Сенекой (это древнеримский философ, если что). Когда пользователь задаёт вопрос, Ask Seneca ищет наиболее релевантные записи, а затем объединяет их в связный ответ, иногда вставляет известные высказывания своего прообраза.

Несмотря на косяки, которыми грешат Bing AI и Bard, потенциал этой технологии огромен — вы можете создавать инструменты для быстрого и эффективного поиска в юридических документах, внутренних базах знаний, руководствах по продуктам и т. д.
Я покажу, как создать собственную поисковую систему с искусственным интеллектом на основе FastAPI , Qdrant , Sentence Transformers и GPT-3. Вы сможете задавать вопросы Марку Аврелию и получать краткие ответы со ссылками на его «Размышления» (личные записи великого римского императора).
Что нужно знать
Чтобы создать свой мини-поисковик, нужно разбираться в следующих вопросах:
Что такое семантический поиск.
Что такое векторные базы данных.
Что такое FastAPI и как его использовать.
Вам не обязательно быть экспертом в какой-либо из этих областей, но хотя бы поверхностное знакомство поможет лучше понять, о чём я буду говорить дальше.
Разработка (крошечной) поисковой системы с помощью ChatGPT
Прежде чем приступить к работе, вы должны понять общий подход, который будем использовать для создания поисковой системы с ИИ. Он состоит из трёх частей:
Извлечение: Здесь происходит извлечения данных, которые будут доступны пользователю для поиска. В нашем случае это означает разбор Размышлений Марка Аврелия. Я не буду вдаваться в подробности, потому что это узкая специфика проекта. Готовый парсинг данных доступен в репозитории.
Индексирование: Следом необходимо выполнить индексирование извлеченных данных, чтобы к ним можно было получить доступ позже в процессе поиска. Здесь будет использоваться подход семантического поиска, то есть данные будут искаться по смыслу, а не по ключевым словам. То есть, на поисковый запрос «Как стать счастливым?» вы должны получить отрывки из «Размышлений», где говорится о счастье или хорошем самочувствии, а не только те, в которых содержатся точные слова из запроса.
Поиск: Сюда входит серверная служба, которая обрабатывает запрос пользователя, векторизует его, находит в индексе векторы, наиболее похожие на него, а затем вызывает API OpenAI для создания сводного ответа пользователю.
Вот как части приложения сочетаются друг с другом:

Настройте свою локальную среду
Выполните следующие действия, чтобы подготовить локальную среду:
Установите Python 3.10 .
Установить Poetry. Это не обязательно, но я очень рекомендую.
Клонируйте репозиторий с образцом приложения:
git clone https://github.com/dylanjcastillo/ai-search-fastapi-qdrant-chatgpt
Перейдите в корневую папку проекта и установите зависимости с:
-
Poetry: Создайте виртуальную среду в том же каталоге, что и проект, и установите зависимости:
poetry config virtualenvs.in-project truepoetry install -
venv и pip: Создайте виртуальную среду и установите зависимости, перечисленные в разделе:
python3.10 -m venv .venv && source .venv/bin/activatepip install -r requirements.txt
Имейте в виду, что PyTorch пока не поддерживает Python 3.11 в MacOS и Windows.
Если все прошло успешно, у вас должна получиться виртуальная среда со всеми необходимыми библиотеками и структурой проекта, которая выглядит следующим образом:
ai-search-fastapi-qdrant-gpt3
│
├── README.md
├── config.py
├── data
│ ├── processed
│ │ └── Marcus_Aurelius_Antoninus...
│ │ └── Marcus_Aurelius_Antoninus...json
│ └── unzipped
│ └── Marcus_Aurelius_Antoninus...
│ ├── index.html
│ ├── metadata.opf
│ └── style.css
├── main.py
├── notebooks
│ ├── extract_text.ipynb
│ └── vectorize_text.ipynb
├── poetry.lock
├── pyproject.toml
├── requirements.txt
├── .env-example
└── .venv/Это структура нашего проекта. Далее объясню назначение наиболее важных файлов и каталогов:
config.py: этот файл содержит спецификации конфигурации проекта, такие как хост Qdrant, порт и ключ API (чтение из файла .env).data/: этот каталог содержит данные проекта. Здесь находятся «Размышления», изначально выгруженные из Википедии, а также обработанный файл, который вы будете использовать в проекте.main.py: этот файл содержит код приложения FastAPI.notebooks/: этот каталог содержит записные книжки Jupyter для извлечения, векторизации и индексации данных.extract_text.ipynbсодержит код для анализа файла HTML, аvectorize_text.ipynbсодержит код для векторизации и индексации данных.poetry.lockиpyproject.toml: эти файлы содержат информацию о зависимостях проекта и используются Poetry для репликации среды.requirements.txt: этот файл содержит список пакетов Python, необходимых для проекта..env-example: этот файл является примером переменных среды, которые вы должны предоставить..venv/: этот каталог содержит виртуальную среду проекта.
Настройте Qdrant и OpenAI
Начнём с переименования .env-example в .env. Сейчас думать о заполнении значений в .env. не нужно. Когда вы создадите кластер и ключи API для Qdrant и OpenAI, то заполните эти пробелы.
Qdrant
Создайте учётную запись в Qdrant, если у вас её ещё нет. Затем на странице своей учётной записи перейдите в Clusters > Create и создайте кластер из 1 ГБ ОЗУ, 0,5 vCPU и диска на 20 ГБ. Qdrant предлагает щедрый тестовый доступ, так что вы можете бесплатно запустить кластер с такими характеристиками.

Затем вставьте хост и ключ API, полученные при создании кластера, в .env:
QDRANT_PORT=6333
QDRANT_HOST=<your_qdrant_host>
QDRANT_API_KEY=<your_qdrant_api_key>Если вы не копировали ключ, то можете создать новый в Access.
Наконец, вы можете проверить, всё ли хорошо, запустив первые три ячейки в файле vectorize_data.ipynb.
OpenAI
Если у вас нет учетной записи OpenAI, создайте ее (а вот инструкция для россиян). После этого перейдите в Manage account > API keys > + Create new secret key.

Затем вставьте сгенерированный ключ в .env:
QDRANT_PORT=6333
QDRANT_HOST=<your_qdrant_host>
QDRANT_API_KEY=<your_qdrant_api_key>
OPENAI_API_KEY=<your_openai_api_key> # newИзвлечение данных
Процесс извлечения данных может сильно различаться в зависимости от проекта, поэтому я не буду вдаваться в подробности.
Вот несколько полезных рекомендаций, которые стоит учесть:
Хрень на входе — хрень на выходе. Качество данных сильно влияет на результаты поиска, поэтому не торопитесь.
Разделение документов. Когда вы выполняете семантический поиск, вам нужно разделить документы на более мелкие фрагменты, чтобы можно было сравнить каждый фрагмент с запросом пользователя. Нет правильного или неправильного способа сделать это. Лично я делил текст на абзацы, а если абзац был слишком длинный для векторизатора, делил его на несколько предложений.
Вывод: стоит подумать, как часто вы будете извлекать и принимать данные, адаптировать свой конвейер для различных источников данных (например, парсинг, API) и создавать мониторы конвейера. В этом примере, поскольку извлечение данных является разовым мероприятием, я использую Jupyter Notebook, но это не всегда хорошая идея.
Вот краткий обзор данных из этого блока:
{
"book_title": "Meditations by Marcus Aurelius",
"url": "https://en.wikisource.org/wiki/Marcus_Aurelius_Antoninus_-_His_Meditations_concerning_himselfe",
"data": [
{
"title": "THE FIRST BOOK",
"url": "https://en.wikisource.org/wiki/Marcus_Aurelius_Antoninus_-_His_Meditations_concerning_himselfe#THE_FIRST_BOOK",
"sentences": [
"I. Of my grandfather Verus I have learned to be gentle and meek...",
"II. Of him that brought me up, not to be fondly addicted...",
"III. Of Diognetus, not to busy myself about vain things...",
"IV. To Rusticus I am beholding, that I first entered into the...",
...
}
]
}Сюда входят общие метаданные, такие как название книги и исходный URL-адрес, а также информация из каждой главы с предложениями, которые вы индексируете. Если вы хотите посмотреть, как я извлёк данные, используемые в этом руководстве, ознакомьтесь с файлом extract_data.ipynb.
Векторизация и индексация данных
После того, как вы извлекли данные, их нужно проиндексировать в векторной базе данных.
Процесс состоит из двух шагов:
Создайте векторы для каждого предложения, которое было извлечено ранее.
Вставьте эти векторы в коллекцию (набор векторов, который вы можете искать в базе данных).
Вы можете найти код для этого раздела в notebooks/vectorize_data.ipynb.
Как обычно, начинаем с импорта необходимых библиотек:
import json
import numpy as np
import pandas as pd
import torch
from qdrant_client import QdrantClient
from qdrant_client.http import models
from sentence_transformers import SentenceTransformer
from tqdm.notebook import tqdm
from config import QDRANT_HOST, QDRANT_PORT, QDRANT_API_KEY, DATA, COLLECTION_NAMEЭтот код импортирует все библиотеки и переменные конфигурации, необходимые для векторизации и индексации данных. Тут стоит упомянуть несколько моментов:
qdrant_clientиqdrant_client.httpпозволяет взаимодействовать с клиентом Qdrant, чтобы вставлять и извлекать данные из коллекции.sentence_transformersпозволяет генерировать векторы из текста, используя предварительно обученные модели.
Далее данные читаются следующим образом:
BOOK_FILENAME = "Marcus_Aurelius_Antoninus_-_His_Meditations_concerning_himselfe"
with open(f"{DATA}/processed/{BOOK_FILENAME}/{BOOK_FILENAME}.json", "r") as file:
meditations_json = json.load(file)
rows = []
for chapter in tqdm(meditations_json["data"]):
for sentence in chapter["sentences"]:
rows.append(
(
chapter["title"],
chapter["url"],
sentence,
)
)
df = pd.DataFrame(
data=rows, columns=["title", "url", "sentence"]
)
df = df[df["sentence"].str.split().str.len() > 15]Этот код считывает ранее обработанные данные и удаляет короткие предложения. Работает это следующим образом:
Строки с 1 по 4 читают файл JSON, созданный вами для “Размышлений”, и сохраняют его как meditations_json.
Строки с 6 по 15 проходят через все главы книги, хранящиеся в data от
meditations_json, после чего для каждой главы извлекают соответствующие данные (название главы, URL-адрес главы и предложение) и добавляют их в rows.Строки с 17 по 21 создают DataFrame с данными
rowsи удаляют предложения, содержащие менее 15 слов.
Затем вы создаете коллекцию в базе данных векторов:
# Create collection
client = QdrantClient(
host=QDRANT_HOST, port=QDRANT_PORT, api_key=QDRANT_API_KEY
)
client.recreate_collection(
collection_name=COLLECTION_NAME,
vectors_config=models.VectorParams(
size=384,
distance=models.Distance.COSINE
),
)Этот код подключается к вашему кластеру Qdrant и создает коллекцию на основе предоставленных имени и параметров. В этом случае вы устанавливаете значение size384 в зависимости от потребностей модели, которую будете использовать для векторизации предложений. Вы также устанавливаете distance, чтобы использовать косинусное расстояние, которое будет определять, как вычисляется сходство между векторами.
Следующим шагом является создание векторов (эмбеддингов) из текста. Вместо эмбеддингов на основе OpenAI вы будете использовать предварительно обученную модель из Sentence Transformers. OpenAI дороже, но не факт, что лучше.
Для этого нужно загрузить предварительно обученную модель, создать вложения из предложений DataFrame и вставляете их в созданную вами коллекцию:
model = SentenceTransformer(
"msmarco-MiniLM-L-6-v3",
device="cuda"
if torch.cuda.is_available()
else "mps"
if torch.backends.mps.is_available()
else "cpu",
)
vectors = []
batch_size = 512
batch = []
for doc in tqdm(df["sentence"].to_list()):
batch.append(doc)
if len(batch) >= batch_size:
vectors.append(model.encode(batch))
batch = []
if len(batch) > 0:
vectors.append(model.encode(batch))
batch = []
vectors = np.concatenate(vectors)
book_name = meditations_json["book_title"]
client.upsert(
collection_name=COLLECTION_NAME,
points=models.Batch(
ids=[i for i in range(df.shape[0])],
payloads=[
{
"text": row["sentence"],
"title": row["title"] + f", {book_name}",
"url": row["url"],
}
for _, row in df.iterrows()
],
vectors=[v.tolist() for v in vectors],
),
)Этот код загружает модель, генерирует векторы из предложений в DataFrame и вставляет их в созданную вами коллекцию. Вот как это работает:
Строки с 1 по 8 загружают модель преобразователя предложений
msmarco-MiniLM-L-6-v3и устанавливают правильное устройство, если у вас есть доступный графический процессор.Строки с 10 по 23 генерируют массив векторов, используя загруженную вами модель. Каждый вектор представляет собой числовое представление предложений из DataFrame.
Строки с 29 по 43 вставляют векторы и дополнительные данные (фактическое предложение, название книги и главы и URL-адрес) в коллекцию базы данных векторов.
Создание сервера с FastAPI
Далее нужно создать приложение FastAPI, которое позволит пользователю взаимодействовать с векторной базой данных и ChatGPT. Код для этого раздела находится в формате main.py.
Начинаем с импорта необходимых зависимостей, настройки клиента Qdrant и загрузки модели:
import openai
from fastapi import FastAPI
from qdrant_client import QdrantClient
from sentence_transformers import SentenceTransformer
from config import (
COLLECTION_NAME,
OPENAI_API_KEY,
QDRANT_API_KEY,
QDRANT_HOST,
QDRANT_PORT,
)
openai.api_key = OPENAI_API_KEY
qdrant_client = QdrantClient(
host=QDRANT_HOST,
port=QDRANT_PORT,
api_key=QDRANT_API_KEY,
)
retrieval_model = SentenceTransformer("msmarco-MiniLM-L-6-v3")
app = FastAPI()Этот код импортирует библиотеки и параметры конфигурации, инициализирует клиент Qdrant и загружает модель в память (ту, которую использовали для векторизации предложений). Вы загружаете свою модель глобально, иначе придётся загружать её каждый раз, когда кто-то задаёт вопрос. Это сильно замедлит запросы.
Затем вы определяете функцию, которая поможет при создании подсказок для ChatGPT, по которым он будет генерировать последовательный ответ на основе наиболее подходящих отрывков из «Размышлений»:
def build_prompt(question: str, references: list) -> tuple[str, str]:
prompt = f"""
Ты Марк Аврелий, римский император. Ты даёшь совет другу, который задал тебе следующий вопрос: '{вопрос}'
Для ответа ты выбрал наиболее подходящие высказывания из твоих заметок. Укажи их в своём ответе.
References:
""".strip()
references_text = ""
for i, reference in enumerate(references, start=1):
text = reference.payload["text"].strip()
references_text += f"\n[{i}]: {text}"
prompt += (
references_text
+ "\nHow to cite a reference: This is a citation [1]. This one too [3]. And this is sentence with many citations [2][3].\nAnswer:"
)
return prompt, references_textЭтот код включает подсказку для ChatGPT, которая заставляет его «имитировать» Марка Аврелия, отвечающего на заданный пользователем вопрос, со списком ссылок, ранее полученных из векторной базы данных. Программа возвращает сгенерированный ответ и список ссылок.
Затем вы создаете две конечные точки:
@app.get("/")
def read_root():
return {
"message": "Make a post request to /ask to ask a question about Meditations by Marcus Aurelius"
}
@app.post("/ask")
def ask(question: str):
similar_docs = qdrant_client.search(
collection_name=COLLECTION_NAME,
query_vector=retrieval_model.encode(question),
limit=3,
append_payload=True,
)
prompt, references = build_prompt(question, similar_docs)
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "user", "content": prompt},
],
max_tokens=250,
temperature=0.2,
)
return {
"response": response["choices"][0]["text"],
"references": references,
}Это две конечные точки, которые вы будете использовать в своем приложении. Вот что делает каждая строка:
Строки с 1 по 5 устанавливают конечную точку, которая принимает запросы GET на «/». Она возвращает ответ в формате JSON с ключом сообщения, где пользователю предлагается использовать конечную точку "/ask".
Строки с 8 по 17 определяют конечную точку, которая принимает запросы POST на «/ask» с одним параметром question типа string. Как только пользователь отправит запрос, вы векторизуете вопрос, используя модель, которую вы загрузили ранее, затем получаете 3 наиболее похожих документа из вашей векторной базы данных.
Строки с 19 по 32 объединяют документы, которые вы получили из векторной базы данных, с вашей подсказкой и делают запрос к API ChatGPT. Вы устанавливаете
max_tokens=250, чтобы ответы были короткими, и устанавливаетеtemperature=0.2, чтобы модель не несла отсебятину. Наконец, вы извлекаете ответ из ответа API ChatGPT и возвращаете его пользователю вместе со ссылками.
Если вы хотите протестировать его локально, введите следующую команду в терминал (внутри виртуальной среды проекта):
uvicorn main:app --reloadВ браузере перейдите к localhost:8000/docs, чтобы проверить конечную точку /ask:

Хороший ответ будет выглядеть следующим образом:
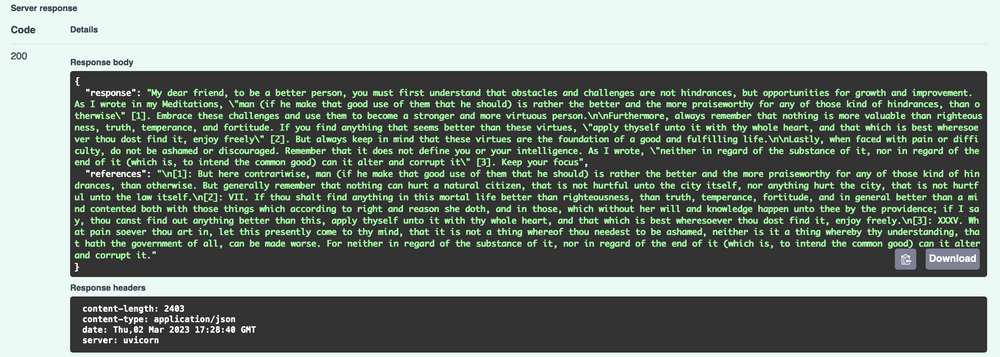
Вот и все! У вас есть рабочая версия поисковой системы с искусственным интеллектом.
Существует множество различных способов развёртывания приложения, поэтому вы можете выбрать любой подход, который вам больше нравится. Мне нравится VPS с NGINX, выступающим в качестве обратного прокси-сервера, и Gunicorn в качестве диспетчера процессов с рабочими процессами Uvicorn. Если вы хотите использовать такой же подход, посмотрите моё руководство.
И помните о следующих моментах:
Вы должны использовать --preload, если хотите брать одну и ту же модель для всех процессов и использовать меньше оперативной памяти.
При обслуживании некоторых типов моделей возникают проблемы с утечкой памяти. У меня получилось обойти это, установив низкие значения --max-requests и --max-requests-jitter.
Весь код для этого туториала доступен на GitHub. Спасибо за внимание!
Что ещё интересного есть в блоге Cloud4Y
→ Информационная безопасность и глупость: необычные примеры
→ Взлом Hyundai Tucson, часть 1, часть 2
stal
Qdrant rock! ????