Большую часть прошлого года я работал с Hexvarium. Базирующаяся в Атертоне, штат Калифорния, компания строит и управляет оптоволоконными сетями. В настоящее время у них есть несколько сетей в районе залива, но у них есть планы по расширению в США.
Моя роль заключается в управлении платформой данных, которая содержит 30 миллиардов записей примерно из 70 источников информации. Эти данные используются инженерами, разрабатывающими оптимальные планы развертывания оптоволоконной сети с помощью LocalSolver. Далее приведен пример одного из таких планов.
Наша платформа данных в основном состоит из PostGIS, ClickHouse и BigQuery. Данные поступают в самых разных, но чаще не в оптимальных форматах. Затем мы формируем и обогащаем данные, часто с помощью PostGIS или ClickHouse, прежде чем отправлять их в BigQuery. Затем инженеры, работающие с LocalSolver, будут получать свои данные из очищенной и актуальной версии в BigQuery.
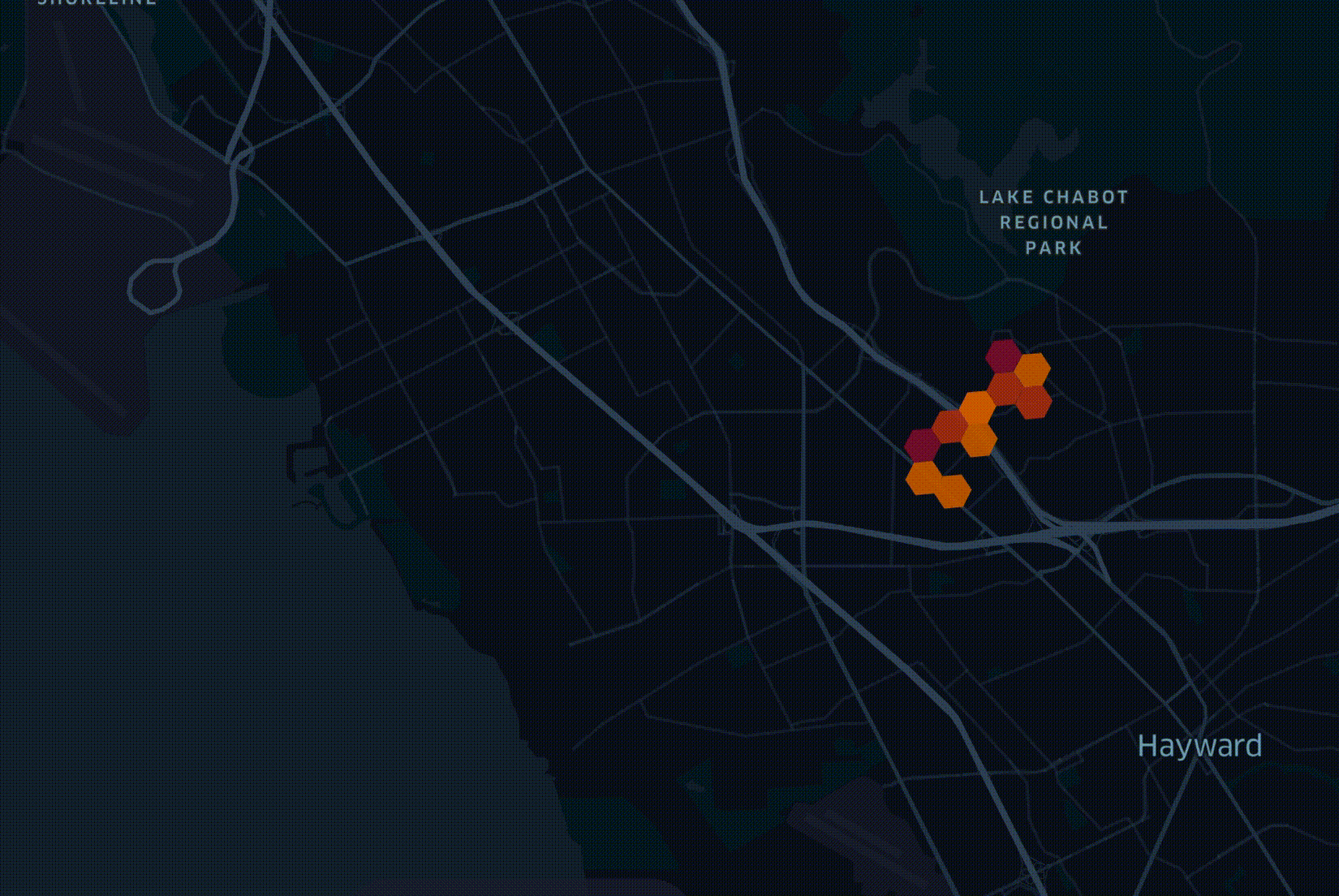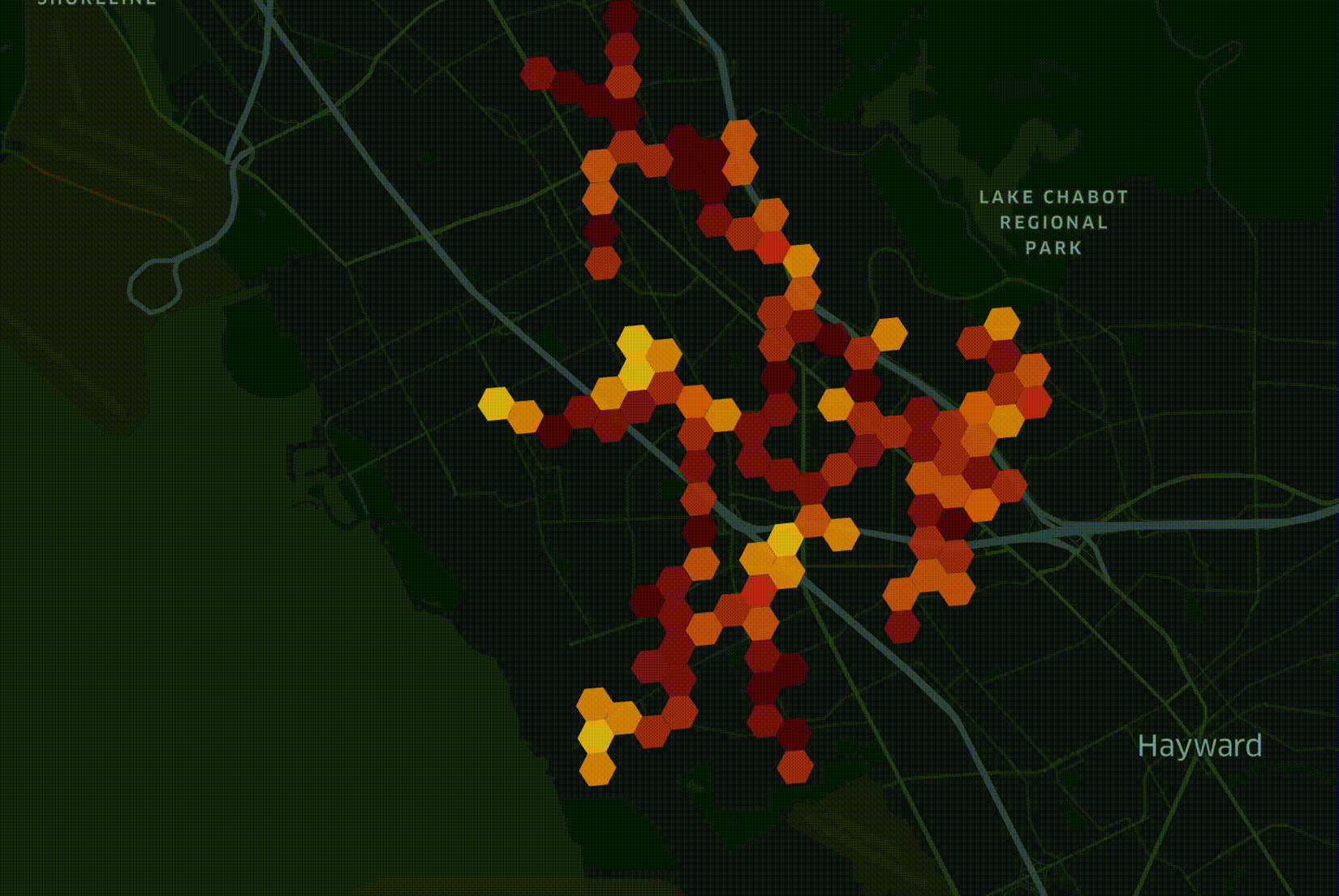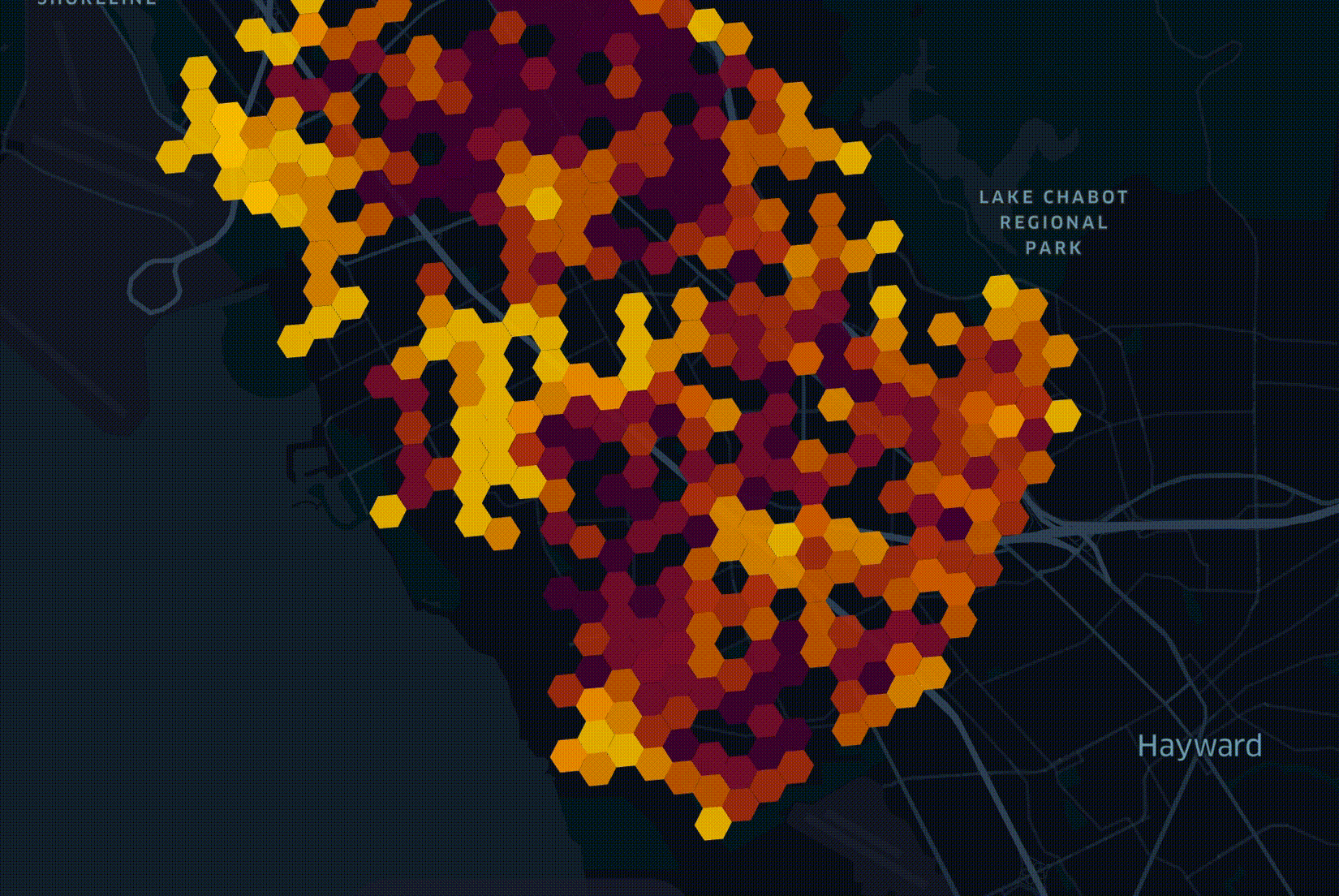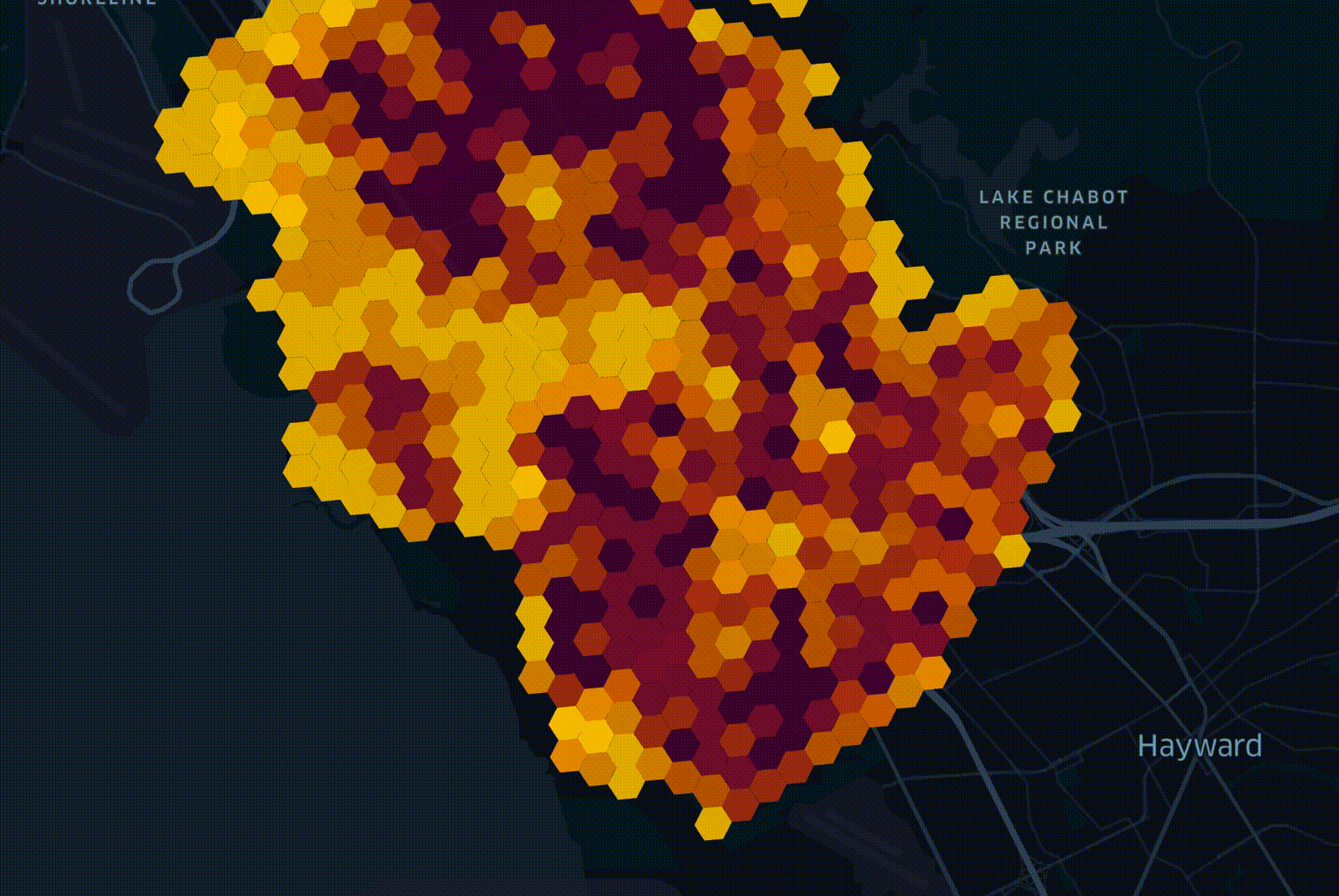
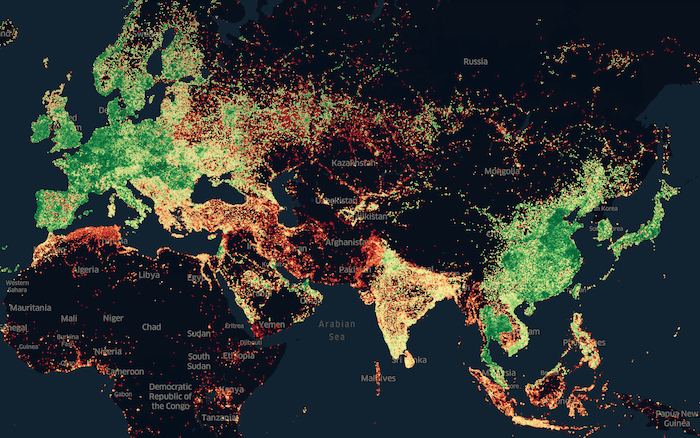
Анализ подпитывает воображение инженеров, поэтому мы часто визуализируем данные, полученные с помощью Unfolded. Ниже представлена визуализация, которую мы создали для Speedtest от Ookla прошлым летом. Мы сгруппировали записи по уровню масштабирования H3 9 и взяли самую высокую среднюю скорость загрузки из каждого шестиугольника, нанеся их на карту.
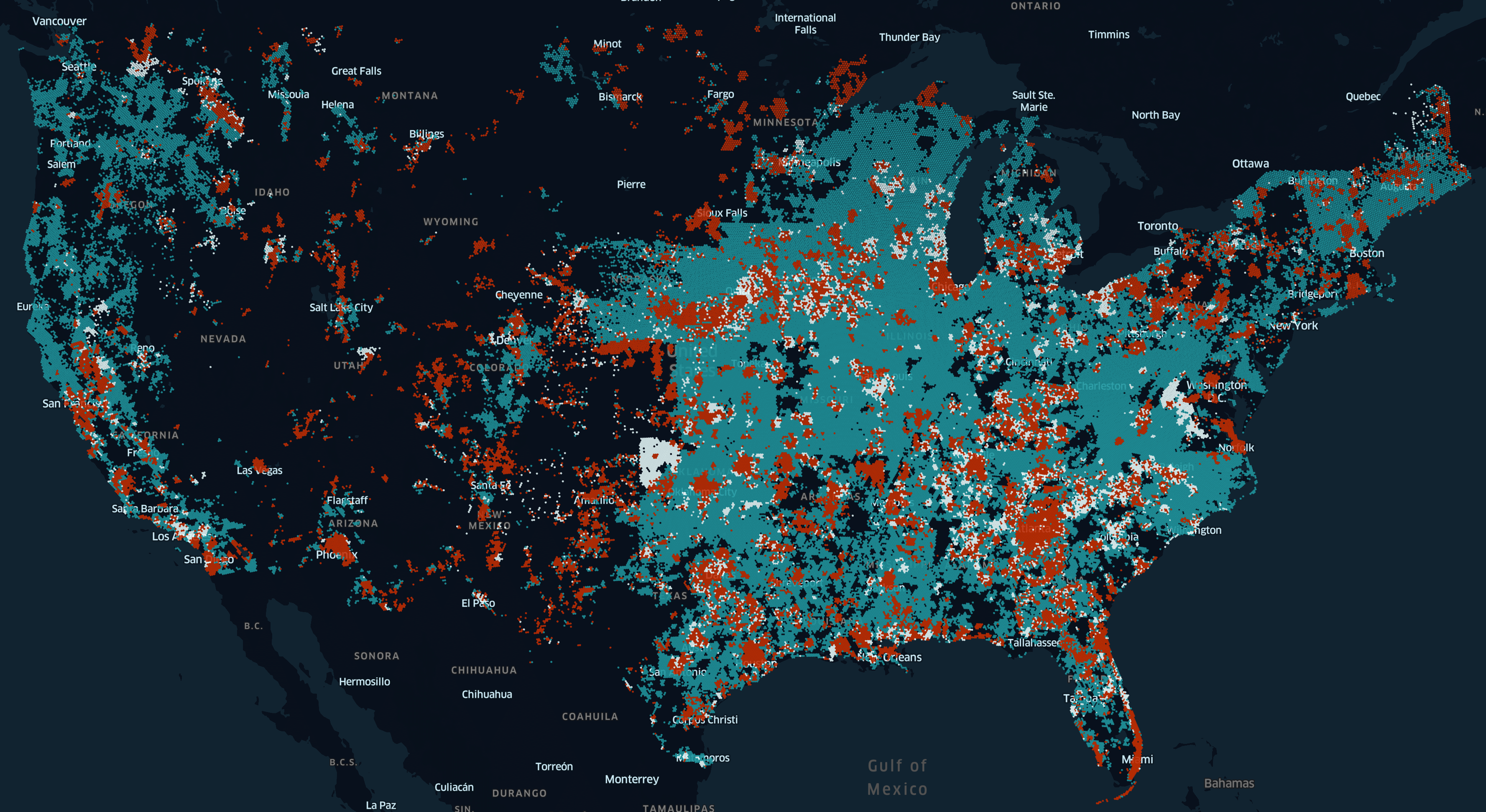
Ниже приведена еще одна визуализация, которую мы создали, показывающая разницу в максимальной скорости широкополосного доступа в период с июня по ноябрь прошлого года. Данные в FCC предоставили провайдеры широкополосного доступа из США.
Интересные особенности DuckDB
DuckDB — это прежде всего работа Марка Раасвельдта и Ханнеса Мюлейзена. Он состоит из миллиона строк C++ и работает как отдельный двоичный файл. Разработка идет очень активно: количество коммитов в репозитории GitHub удваивается почти каждый год с момента его запуска в 2018 году. DuckDB использует синтаксический анализатор SQL PostgreSQL, механизм регулярных выражений RE2 от Google и оболочку SQLite.
SQLite поддерживает пять типов данных: NULL, INTEGER, REAL, TEXT и BLOB. Меня всегда это расстраивало, поскольку работа со временем требовала преобразований в каждом операторе SELECT, а невозможность описать поле как логическое означает, что программное обеспечение для анализа не могло автоматически распознавать и предоставлять определенные элементы управления пользовательского интерфейса и визуализацию этих полей.
К счастью, DuckDB поддерживает 25 типов данных из коробки, а дополнительные можно добавить с помощью расширений. Ведется работа над расширением, которое перенесет геопространственные функции PostGIS Пола Рэмси в DuckDB. Исаак Бродский, главный инженер Foursquare, материнской компании Unfolded, также недавно опубликовал расширение H3 для DuckDB. И хотя еще ничего не опубликовано, предпринимаются попытки встроить GDAL через его интерфейс на основе Arrow в DuckDB.
Min/Max индекс создается для каждого сегмента столбца в DuckDB. Именно благодаря этому типу индекса большинство баз данных OLAP так быстро отвечают на запросы агрегирования. Расширения Parquet и JSON поставляются в официальной сборке, и их использование хорошо задокументировано. Для файлов Parquet поддерживаются сжатие Snappy и ZStandard.
Документация DuckDB хорошо организована и очень лаконична, с примерами рядом с большинством описаний.
Запуск DuckDB
Официальная версия DuckDB не содержит расширений Geospatial и H3, используемых в этом посте, поэтому я скомпилирую DuckDB с этими расширениями.
Приведенные ниже команды были выполнены на экземпляре e2-standard-4 в Google Cloud под управлением Ubuntu 20 LTS. Эта виртуальная машина содержит 4 виртуальных ЦП и 16 ГБ ОЗУ. Он был запущен в Лос-Анджелесе, в регионе us-west2-b, и имеет сбалансированный персистентный диск объемом 100 ГБ. Запуск стоил 0,18 доллара в час.
Ниже будут установлены пакеты ПО, используемые в этом посте.
$ sudo apt update
$ sudo apt install \
awscli \
build-essential \
libssl-dev \
pigz \
unzipДля компиляции расширения H3 требуется CMake версии 3.20+, поэтому я сначала соберу его.
$ cd ~
$ wget -c https://github.com/Kitware/CMake/releases/download/v3.20.0/cmake-3.20.0.tar.gz
$ tar -xzf cmake-3.20.0.tar.gz
$ cd cmake-3.20.0
$ ./bootstrap --parallel=$(nproc)
$ make -j$(nproc)
$ sudo make installСледующие команды будет собирать как DuckDB, так и расширение H3 для него. Расширение geo привязано к коммиту DuckDB c817201, поэтому я также прикреплю к нему расширение H3.
$ git clone https://github.com/isaacbrodsky/h3-duckdb ~/duckdb_h3
$ cd ~/duckdb_h3
$ git submodule update --init
$ cd duckdb
$ git checkout c817201
$ cd ..
$ CMAKE_BUILD_PARALLEL_LEVEL=$(nproc) \
make releaseДалее будет создано расширение, которое перенесет части функциональности PostGIS в DuckDB.
$ git clone https://github.com/handstuyennn/geo ~/duckdb_geo
$ cd ~/duckdb_geo
$ git submodule init
$ git submodule update --recursive --remote
$ mkdir -p build/release
$ cmake \
./duckdb/CMakeLists.txt \
-DEXTERNAL_EXTENSION_DIRECTORIES=../geo \
-DCMAKE_BUILD_TYPE=RelWithDebInfo \
-DEXTENSION_STATIC_BUILD=1 \
-DBUILD_TPCH_EXTENSION=1 \
-DBUILD_PARQUET_EXTENSION=1 \
-B build/release
$ CMAKE_BUILD_PARALLEL_LEVEL=$(nproc) \
cmake --build build/releaseСоздам шелл скрипт, который запустит двоичный файл DuckDB с поддержкой неподписанных расширений.
$ echo "$HOME/duckdb_geo/build/release/duckdb -unsigned \$@" \
| sudo tee /usr/sbin/duckdb
$ sudo chmod +x /usr/sbin/duckdbНастрою файл конфигурации DuckDB для загрузки обоих расширений по умолчанию.
$ vi ~/.duckdbrc.timer on
LOAD '/home/mark/duckdb_h3/build/release/h3.duckdb_extension';
LOAD '/home/mark/duckdb_geo/build/release/extension/geo/geo.duckdb_extension';
Запущу DuckDB и проверю, работают ли расширения.
$ duckdbSELECT h3_cell_to_parent(CAST(586265647244115967 AS ubigint), 1) test;
┌────────────────────┐
│ test │
│ uint64 │
├────────────────────┤
│ 581764796395814911 │
└────────────────────┘SELECT ST_MAKEPOINT(52.347113, 4.869454) test;
┌────────────────────────────────────────────┐
│ test │
│ geography │
├────────────────────────────────────────────┤
│ 01010000001B82E3326E2C4A406B813D26527A1340 │
└────────────────────────────────────────────┘Мне кажется полезным, что по умолчанию тип данных отображается под каждым именем поля.
Набор данных Ookla Speedtest
Ookla публикует свои данные Speedtest в AWS в формате Parquet. Ниже я скачаю набор данных 2022 года для мобильных устройств.
$ aws s3 sync \
--no-sign-request \
s3://ookla-open-data/parquet/performance/type=mobile/year=2022/ \
./Структура путей к папкам предназначена для поддержки секционирования Apache Hive. Я буду использовать только четыре файла Parquet, поэтому я перемещу их в одну папку.
$ mv quarter\=*/*.parquet ./Ниже приведены размеры для каждого из файлов. Всего они содержат 15 738 442 строки данных.
$ ls -lht *.parquet
173M 2022-10-01_performance_mobile_tiles.parquet
180M 2022-07-01_performance_mobile_tiles.parquet
179M 2022-04-01_performance_mobile_tiles.parquet
174M 2022-01-01_performance_mobile_tiles.parquetНиже приведена схема, используемая в этих файлах Parquet.
$ echo "SELECT name,
type,
converted_type
FROM parquet_schema('2022-10*.parquet');" \
| duckdb
┌────────────┬────────────┬────────────────┐
│ name │ type │ converted_type │
│ varchar │ varchar │ varchar │
├────────────┼────────────┼────────────────┤
│ schema │ BOOLEAN │ UTF8 │
│ quadkey │ BYTE_ARRAY │ UTF8 │
│ tile │ BYTE_ARRAY │ UTF8 │
│ avg_d_kbps │ INT64 │ INT_64 │
│ avg_u_kbps │ INT64 │ INT_64 │
│ avg_lat_ms │ INT64 │ INT_64 │
│ tests │ INT64 │ INT_64 │
│ devices │ INT64 │ INT_64 │
└────────────┴────────────┴────────────────┘
Ookla использовала сжатие Snappy для каждого столбца. DuckDB может проводить диагностику того, как расположены данные, и предоставлять статистическую информацию по каждому столбцу. Ниже приведены сведения о столбце тайла.
$ echo ".mode line
SELECT *
EXCLUDE (stats_min_value,
stats_max_value)
FROM parquet_metadata('2022-10-01_*.parquet')
WHERE path_in_schema = 'tile'
AND row_group_id = 0;" \
| duckdb
file_name = 2022-10-01_performance_mobile_tiles.parquet
row_group_id = 0
row_group_num_rows = 665938
row_group_num_columns = 7
row_group_bytes = 31596007
column_id = 1
file_offset = 24801937
num_values = 665938
path_in_schema = tile
type = BYTE_ARRAY
stats_min =
stats_max =
stats_null_count = 0
stats_distinct_count =
compression = SNAPPY
encodings = PLAIN_DICTIONARY, PLAIN, RLE, PLAIN
index_page_offset = 0
dictionary_page_offset = 3332511
data_page_offset = 3549527
total_compressed_size = 21469426
total_uncompressed_size = 124569336Импорт Parquet данных
Теперь могу импортировать все четыре файла Parquet в DuckDB с помощью одного оператора SQL. Команда добавит дополнительный столбец с указанием имени файла, из которого происходит каждая строка данных. Из исходных 706 МБ Parquet и дополнительная колонка превратились в файл DuckDB размером 1,4 ГБ.
$ echo "CREATE TABLE mobile_perf AS
SELECT *
FROM read_parquet('*.parquet',
filename=true);" \
| duckdb ~/ookla.duckdbВ качестве альтернативы, используя расширение DuckDB HTTPFS, я могу загружать файлы Parquet непосредственно из S3.
$ echo "INSTALL httpfs;
CREATE TABLE mobile_perf AS
SELECT *
FROM parquet_scan('s3://ookla-open-data/parquet/performance/type=mobile/year=2022/*/*.parquet',
FILENAME=1);" \
| duckdb ~/ookla.duckdbЕсли его еще нет, расширение HTTPFS будет загружено и установлено автоматически. Имейте в виду, что иногда сборки еще не готовы, и вы можете увидеть следующее:
Error: near line 1: IO Error: Failed to download extension "httpfs" at URL "http://extensions.duckdb.org/7813eea926/linux_amd64/httpfs.duckdb_extension.gz"
Extension "httpfs" is an existing extension.
Are you using a development build? In this case, extensions might not (yet) be uploaded.Структура таблицы DuckDB
Ниже приведена схема таблицы, которую автоматически составляет DuckDB.
$ echo '.schema --indent' \
| duckdb ~/ookla.duckdbCREATE TABLE mobile_perf(
quadkey VARCHAR,
tile VARCHAR,
avg_d_kbps BIGINT,
avg_u_kbps BIGINT,
avg_lat_ms BIGINT,
tests BIGINT,
devices BIGINT,
filename VARCHAR
);Ниже приведен пример записи.
$ echo '.mode line
SELECT *
FROM mobile_perf
LIMIT 1' \
| duckdb ~/ookla.duckdb quadkey = 0022133222330023
tile = POLYGON((-160.043334960938 70.6363054807905, -160.037841796875 70.6363054807905, -160.037841796875 70.6344840663086, -160.043334960938 70.6344840663086, -160.043334960938 70.6363054807905))
avg_d_kbps = 15600
avg_u_kbps = 14609
avg_lat_ms = 168
tests = 2
devices = 1
filename = 2022-10-01_performance_mobile_tiles.parquet
Ниже приведены схемы сжатия, используемые в каждом из первых сегментов полей в первой группе строк.
$ echo "SELECT column_name,
segment_type,
compression,
stats
FROM pragma_storage_info('mobile_perf')
WHERE row_group_id = 0
AND segment_id = 0
AND segment_type != 'VALIDITY';" \
| duckdb ~/ookla.duckdb
┌─────────────┬──────────────┬─────────────┬───────────────────────────────────┐
│ column_name │ segment_type │ compression │ stats │
│ varchar │ varchar │ varchar │ varchar │
├─────────────┼──────────────┼─────────────┼───────────────────────────────────┤
│ quadkey │ VARCHAR │ FSST │ [Min: 00221332, Max: 02123303, … │
│ tile │ VARCHAR │ FSST │ [Min: POLYGON(, Max: POLYGON(, … │
│ avg_d_kbps │ BIGINT │ BitPacking │ [Min: 1, Max: 3907561][Has Null… │
│ avg_u_kbps │ BIGINT │ BitPacking │ [Min: 1, Max: 917915][Has Null:… │
│ avg_lat_ms │ BIGINT │ BitPacking │ [Min: 0, Max: 2692][Has Null: f… │
│ tests │ BIGINT │ BitPacking │ [Min: 1, Max: 1058][Has Null: f… │
│ devices │ BIGINT │ BitPacking │ [Min: 1, Max: 186][Has Null: fa… │
│ filename │ VARCHAR │ Dictionary │ [Min: 2022-10-, Max: 2022-10-, … │
└─────────────┴──────────────┴─────────────┴───────────────────────────────────┘
Обогащение данных
Я запущу DuckDB с только что созданной базой данных, добавлю три столбца для уровней масштабирования 7, 8 и 9, а затем приготовлю значения шестиугольников из столбца "геометрия" тайла .
$ duckdb ~/ookla.duckdbALTER TABLE mobile_perf ADD COLUMN h3_7 VARCHAR(15);
ALTER TABLE mobile_perf ADD COLUMN h3_8 VARCHAR(15);
ALTER TABLE mobile_perf ADD COLUMN h3_9 VARCHAR(15);
UPDATE mobile_perf
SET h3_7 =
printf('%x',
h3_latlng_to_cell(
ST_Y(ST_CENTROID(ST_GEOMFROMTEXT(tile))),
ST_X(ST_CENTROID(ST_GEOMFROMTEXT(tile))),
7)::bigint),
h3_8 =
printf('%x',
h3_latlng_to_cell(
ST_Y(ST_CENTROID(ST_GEOMFROMTEXT(tile))),
ST_X(ST_CENTROID(ST_GEOMFROMTEXT(tile))),
8)::bigint),
h3_9 =
printf('%x',
h3_latlng_to_cell(
ST_Y(ST_CENTROID(ST_GEOMFROMTEXT(tile))),
ST_X(ST_CENTROID(ST_GEOMFROMTEXT(tile))),
9)::bigint);Ниже приведен пример расширенной записи.
.mode line
SELECT h3_7,
h3_8,
h3_9,
tile
FROM mobile_perf
LIMIT 1
h3_7 = 8730e0ae9ffffff
h3_8 = 8830e0ae9dfffff
h3_9 = 8930e0ae9d3ffff
tile = POLYGON((126.837158203125 37.5576424267952, 126.842651367188 37.5576424267952, 126.842651367188 37.5532876459577, 126.837158203125 37.5532876459577, 126.837158203125 37.5576424267952))
Когда я попытался выполнить описанное выше на 4-ядерной виртуальной машине GCP e2-standard-4, я оставил задание работать на ночь, и оно еще не было завершено, когда проверил его утром. Позже запустил описанное выше на 16-ядерной виртуальной машине GCP e2-standard-16, и 15,7 млн записей были обогащены за 2 минуты 21 секунду. Использование ОЗУ имело верхнюю границу ~ 7 ГБ. Я поделился этим с Исааком, чтобы понять, есть ли какие-то очевидные исправления, которые можно было бы применить.
Некоторые из баз данных могут создавать новые таблицы быстрее, чем изменять существующие. Не обнаружил, что это относится к DuckDB. Следующая попытка была значительно медленнее, чем прошлый подход.
CREATE TABLE mobile_perf2 AS
SELECT quadkey,
tile,
avg_d_kbps,
avg_u_kbps,
avg_lat_ms,
tests,
devices,
filename,
printf('%x',
h3_latlng_to_cell(
ST_Y(ST_CENTROID(ST_GEOMFROMTEXT(tile))),
ST_X(ST_CENTROID(ST_GEOMFROMTEXT(tile))),
7)::bigint) h3_7,
printf('%x',
h3_latlng_to_cell(
ST_Y(ST_CENTROID(ST_GEOMFROMTEXT(tile))),
ST_X(ST_CENTROID(ST_GEOMFROMTEXT(tile))),
8)::bigint) h3_8,
printf('%x',
h3_latlng_to_cell(
ST_Y(ST_CENTROID(ST_GEOMFROMTEXT(tile))),
ST_X(ST_CENTROID(ST_GEOMFROMTEXT(tile))),
9)::bigint) h3_9
FROM mobile_perf;Экспорт CSV
Далее создается CSV-файл сжатый с помощью GZIP для содержимого таблицы mobile_perf. Это было сделано для версии таблицы, которая не содержала шестиугольников H3 из приведенного выше обогащения.
$ echo "COPY (SELECT *
FROM mobile_perf)
TO 'mobile_perf.csv.gz'
WITH (HEADER 1,
COMPRESSION gzip);" \
| duckdb ~/ookla.duckdbИмейте в виду, что только один процесс может одновременно использовать DuckDB в режиме записи, а описанная выше операция требует режима записи. Если вы видите что-то вроде следующего, вам нужно сначала дождаться другого процесса, использующего базу данных.
Error: unable to open database "/home/mark/mobile_perf.duckdb": IO Error: Could not set lock on file "/home/mark/mobile_perf.duckdb": Resource temporarily unavailableЕсли вы создаете файл для массового распространения, возможно, стоит повторно сжать вышеуказанное с помощью pigz. Его уровень сжатия настраивается, он может использовать преимущества нескольких ядер и создавать файлы меньшего размера, чем GNU GZIP.
Следующая команда завершилась в 1,12 раза быстрее, чем предыдущая, с файлом результата на 2,5 МБ меньше.
$ echo ".mode csv
SELECT *
FROM mobile_perf;" \
| duckdb ~/ookla.duckdb \
| pigz -9 \
> mobile_perf.csv.gzЕсли размер файла не является такой проблемой, использование параметра -1 создаст файл в 1,6 раза быстрее, только в 1,25 раза больше.
Порядок полей и ключи сортировки сильно влияют на способность GZIP к сжатию. С 8 полями существует 40 320 перестановок порядка полей, поэтому попытка найти наиболее сжимаемый вариант займет слишком много времени. Тем не менее, переупорядочить строки по каждому столбцу и посмотреть, какие из них сжимаются больше всего, можно сделать достаточно быстро.
$ COLUMNS=`echo ".mode list
SELECT column_name
FROM information_schema.columns
WHERE table_name = 'mobile_perf';" \
| duckdb ~/ookla.duckdb \
| tail -n +2`
$ for COL in $COLUMNS; do
echo $COL
echo "COPY (SELECT *
FROM mobile_perf
ORDER BY $COL)
TO 'mobile_perf.$COL.csv.gz'
WITH (HEADER 1,
COMPRESSION gzip);" \
| duckdb ~/ookla.duckdb
doneДля приведенного выше требуется доступ для записи в базу данных, поэтому я буду выполнять команды последовательно, а не параллельно с xargs.
DuckDB может использовать несколько ядер для большей части вышеуказанной работы, но некоторые задачи должны выполняться последовательно на одном ядре. Возможно, стоит продублировать исходную базу данных DuckDB и протестировать каждый ключ сортировки в своей собственной базе данных, если вы хотите максимально использовать доступные вам процессорные ядра.
При сортировке по avg_u_kbps был получен файл CSV, сжатый с помощью GZIP, размером 841 МБ, а при сортировке по quadkey — файл размером 352 МБ.
Вышеупомянутое потребовало почти всех 16 ГБ ОЗУ, которые у меня были в этой системе. Помните об этом для больших наборов данных и/или сред с ограниченным объемом оперативной памяти.
ZStandard — это более новый компрессор для сжатия без потерь, который должен сжимать так же, как GZIP, но примерно в 3-6 раз быстрее. Я подробно рассказывал про это в своем минималистском руководстве по сжатию без потерь. Если потребители ваших данных могут открывать файлы, сжатые ZStandard, их создание будет намного быстрее.
Следующая команда закончилось в 3,4 раза быстрее, чем его аналог GZIP, при этом вывод был примерно на 6% больше.
$ echo "COPY (SELECT *
FROM mobile_perf)
TO 'mobile_perf.csv.zstd'
WITH (HEADER 1,
COMPRESSION zstd);" \
| duckdb ~/ookla.duckdbОпять же, если вышеперечисленное было отсортировано по avg_u_kbps, будет создан файл CSV со сжатием ZStandard размером 742 МБ, а сортировка по quadkey даст файл размером 367 МБ.
Экспорт Parquet
В моей публикации «Faster PostgreSQL To BigQuery Transfers» в блоге обсуждалось преобразование Microsoft Buildings, набора данных GeoJSON на 130M записей в файл Parquet, сжатый Snappy. В том посте ClickHouse справился с этой задачей в 1,38 раза быстрее, чем его ближайший конкурент. Теперь запускаю ту же рабочую нагрузку через DuckDB.
Используя внешний SSD-накопитель на моем MacBook Pro с процессором Intel 2020 года выпуска, ClickHouse создал файл за 35,243 секунды. После работы над оптимизацией совместно с командой DuckDB, я смог выполнить ту же рабочую нагрузку за 30,826 секунды, и, если бы я был готов обработать восемь файлов Parquet вместо одного, это время сократилось до 25,146 секунды. Это был SQL, который работал быстрее всего.
$ echo "COPY (SELECT *
FROM read_ndjson_objects('California.jsonl'))
TO 'cali.duckdb.pq' (FORMAT 'PARQUET',
CODEC 'Snappy',
PER_THREAD_OUTPUT TRUE);" \
| duckdbОбратите внимание на использование read_ndjson_objects вместо read_json_objects, это значительно улучшило производительность. Кроме того, PER_THREAD_OUTPUT TRUE создаст несколько файлов. Уберите этот параметр, если вы хотите создать один файл Parquet.
Но с учетом сказанного, та же рабочая нагрузка, выполняемая на виртуальной машине Google Cloud e2-highcpu-32 с Ubuntu 20 LTS, показала, что ClickHouse превзошел DuckDB в 1,44 раза. Марк Раасвелдт предположил, что на этапе анализа сжатия DuckDB могут быть дальнейшие улучшения, поэтому есть шанс, что в ближайшем будущем мы увидим уменьшение разрыва в производительности по сравнению с ClickHouse.
PS. Ну а если вам не хочется тратить время на настройку компиляции и хотите легко собрать расширения для более свежей версии duckdb с новыми фичами(как например map_entries, map_values, map_keys из #6522), то можете взять этот Docker файл за основу.