
В предыдущей статье мы развернули связку Prometheus+Grafana и теперь самое время подключить источники и настроить визуализацию. Но прежде напомню, с каких элементов ИТ инфраструктуры мы собираемся собирать метрики. Прежде всего это оборудование, операционные системы и дополнительное ПО, то есть все то, без чего нормальное функционирование нашего приложения было бы невозможно. Затем мониторинг самого приложения, например, какие компоненты расходуют больше тех или иных ресурсов. И наконец, мониторинг бизнес-логики приложения. Это может быть например сбор информации об активностях пользователей, поступлениях денежных средств и т.д.
Мало просто собрать метрики, важно их правильно интерпретировать, поэтому для начала мы посмотрим, что именно мы хотим мониторить и затем уже будем визуализировать необходимые метрики. В зависимости от типа ресурса, с которого собираются метрики, нам потребуется различная информация. Если мы собираем метрики с хоста, то нам потребуются: CPU, Memory, Processes, Disk, Network и т.д. Если же у нас Docker-контейнер, то тогда мы будем собирать: CPU, Memory, Network, Block I/O, + Docker Daemon.
С мониторингом приложений все несколько сложнее. Как правило разработчики лучше других знают, чем занимается ваше приложение и могут реализовать более релевантные метрики. Основными целями сбора метрик с приложений является выявление состоянии и производительности (performance) кода. Также, не лишним будет мониторинг использования приложения конечным пользователем. Примерами метрик, собираемых в приложениях является время ответа на запросы, количество неудачных логинов пользователей и т.п.
Отличительной особенностью сбора метрик с приложений является то, что данные метрики практически невозможно собрать внешними средствами, так как это делается, к примеру при мониторинге операционной системы. Сбор метрик всегда описывается в коде самого приложения.
Сбор бизнес метрик может осуществляться как средствами самого приложения, так и с помощью дополнительных средств, там где это возможно.
Рекомендации по сбору метрик
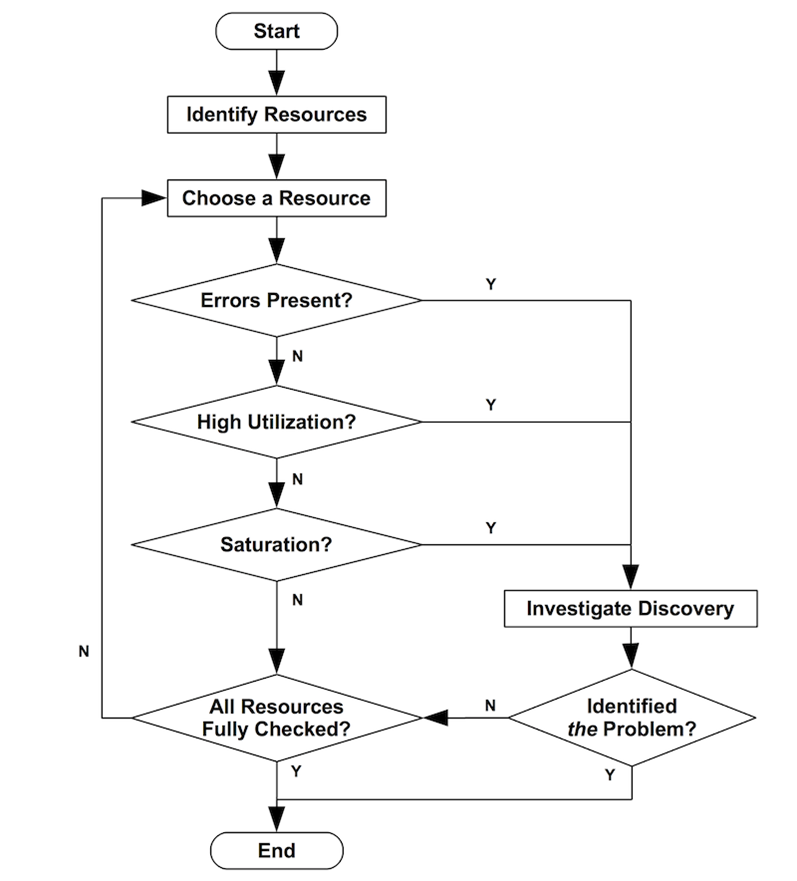
Рассмотрим рекомендации для сбора различных метрик. Для сбора инфраструктурных метрик лучше всего подходит метод USE: Utilization (использование), например загрузка диска, Saturation (насыщение), например очередь диска, Errors (ошибки), например ошибки I/O диска.
Вот типовой список ресурсов, с которых USE рекомендует осуществлять сбор метрик.
CPUs: sockets, cores, hardware threads (virtual CPUs)
Memory: capacity
Network interfaces
Storage devices: I/O, capacity
Controllers: storage, network cards
Interconnects: CPUs, memory, I/O
При этом стоит учитывать, что некоторые компоненты представляют собой ресурсы двух типов: устройства хранения данных - это ресурс запроса на обслуживание (I/O), а также ресурс емкости (capacity). Оба этих типа ресурсов могут стать узким местом в системе. Некоторые физические компоненты были опущены, такие как аппаратные кэши (например, MMU TLB/TSB, CPU). Метод USE наиболее эффективен для ресурсов, производительность которых снижается при высокой загрузке или насыщении, что приводит к возникновению узкого места. Кэши повышают производительность при высокой загрузке.
Принимать решение о том, нужно ли включать тот или иной ресурс в мониторинг необходимо опытным путем. То есть сначала включите мониторинг нужных ресурсов и посмотрите на результат – если он вас не устраивает (например, метрика не информативна, всегда 0 или константа) посмотрите в том же Prometheus другую аналогичную метрику для мониторинга.
Разработчик метода USE Brendan Gregg также предлагает другой метод определения тех ресурсов, метрики которых вам необходимо собирать. Автор предлагает нарисовать функциональную блок-схему системы, которая покажет взаимосвязи, которые могут быть очень полезны при поиске узких мест в потоке данных. Вот пример такой схемы для сервера SunFire:

На основании подобной схемы применительно к оборудованию можно указать пропускную способность шин и интерфейсов, где применимо можно указать объем памяти, частоту, температуру и другие параметры. В результате, благодаря такой “обогащенной” значениями схеме мы можем эффективно собирать метрики и вести мониторинг.
В целом, метод USE показан в виде блок-схемы ниже.
RED-метод
Если метод USE больше подходит для мониторинга инфраструктуры, то метод RED больше подходит для выбора метрик приложений и сервисов. Аббревиатура RED расшифровывается как: Rate - запросы в секунду, Errors - ошибки в секунду, Duration - время на каждый запрос. Основные метрики, которые предлагается снимать методом RED это:
Rate (количество запросов в секунду)
Errors (количество тех запросов, которые завершились неудачей)
Duration (количество времени, которое занимают эти запросы)
Отличительной особенностью метода RED является возможность мониторить, насколько могут быть довольны ваши клиенты. Если у вашего сайта много ошибок при загрузки, или время загрузки сайта исчисляется десятками секунд, то посетители сайта вряд ли будут этим довольны.
Four Golden Signals от Google
Четыре золотых сигнала - принцип выбора метрик, описанный в книге Site Reliability Engineering от Google. Это следующие четыре сигнала:
Latency - время ответа
Traffic - частота запросов
Errors (ошибки) - частота ошибок
Saturation (насыщение) - насколько утилизирован (загружен) ресурс
Осуществляя мониторинг этих четырех видов сигналов, вы сможете обнаружить большинство проблем и узких мест в системе. Данный метод может использоваться как для мониторинга инфраструктуры, так и для мониторинга приложений.
Визуализация
Зачем на самом деле нужна визуализация? Первый ответ, который может прийти в голову это для красоты. И на самом деле такой вариант не будет совсем уж бредовым. Дело в том, что на красивых графиках, которые в конечном итоге и получаются в результате визуализации можно достаточно эффективно наблюдать за изменениями в тех или иных системах, отслеживать тенденции работы и анализировать результат. Поэтому, совершенно законным этапом развития любой системы мониторинга является визуализация собираемых метрик.
В предыдущей статье мы развернули Prometheus и Grafana, теперь в качестве примера подключим и визуализируем метрики от Docker.
Следим за контейнерами
Для того, чтобы начать собирать метрик с Docker нам необходимо прежде всего создать файл /etc/docker/daemon.json со следующим содержанием:
{
"metrics-addr" : "127.0.0.1:9323",
"experimental" : true
}Где metrics-addr это адрес сервера Prometheus ( в моем случае все располагается на одном хосте) и порт 9323. Для того, чтобы настройки вступили в силу необходимо перезапустить Docker.
systemctl restart docker
Далее необходимо внести правки в настройки Prometheus. Нам потребуется файл /etc/prometheus/prometheus.yml. В нем находим scrape_configs (в нем уже должен быть блок настроек для сбора метрик самого Prometheus) и добавляем туда следующий блок:
- job_name: 'docker'
static_configs:
- targets: ['localhost:9323']Должно получиться примерно следующее:

Теперь идем в Prometheus, Status->Targets и убеждаемся в наличии задачи по сбору метрик от Docker.
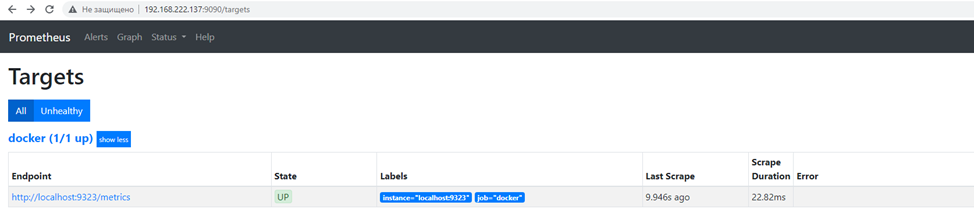
На этом с Prometheus все. Теперь переходим в интерфейс Grafana и проверяем, что у нас есть источник данных Prometheus по порту 9090 в разделе Data Sources. Переходим к созданию нового дашборда. В моем примере будет четыре панели: engine_daemon_image_actions (график будет показывать общее количество действий с контейнерами), engine_daemon_network_actions (сетевые активности), engine_daemon_events_total (общее количество событий) и engine_daemon_container_states (статистика по состояниям контейнеров).
Для добавления панелей нажимаем New dashboard -> Add query. Далее указываем нужные метрики. Например engine_daemon_container_states_containers.
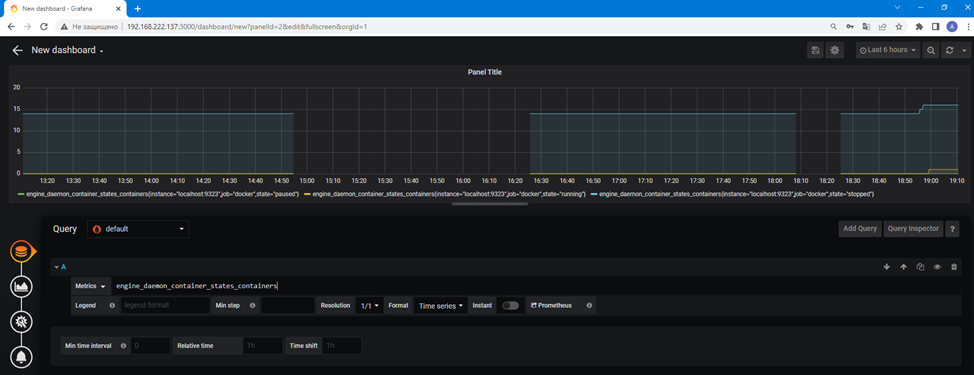
Введенный запрос выведет статистику по контейнерам. Далее выбираем значок Visualization (слева внизу). И выбираем вид графика. В своем примере для этой метрики я оставлю первый вариант.

На третьем шаге можно ничего не менять. На четвертом вы можете указать условия для создания Alert.
Повторим все эти действия для остальных панелей и получим дашборд следующего вида.

Теперь у нас есть дашборд, отображающий состояние Docker.
Заключение
В этой статье мы рассмотрели основные рекомендации по мониторингу инфраструктуры и приложения и в качестве примера подключили к Prometheus и Grafana сбор метрик от Docker и сделали соответствующий дашборд. Следующая статья будет полностью посвящена сбору трейсов непосредственно из приложений.
В заключении хотелось бы напомнить одну простую истину. Сбор данных дешев, но отсутствие их в случае необходимости может обойтись очень дорого. Поэтому нужно обеспечить сбор всех полезных данных, которые разумно собирать.
Также хочу пригласить вас на бесплатный вебинар, где рассмотрим основные инструменты для работы с сетью в Linux, встречающиеся в таких популярных дистрибутивах как CentOS, Ubuntu, ArchLinux.
konstantin42f
при работе с визуализацией существуют следующие аспекты -
1. Цветовая схема: выбор цветов, которые будут использоваться в визуализации, может влиять на ее эффективность и понятность для зрителей. Рекомендуется использовать контрастные цвета и избегать слишком ярких или насыщенных цветов.
2. Тип графика: выбор типа графика (линейный, круговой, столбчатый и т.д.) может быть важным фактором при создании визуализации. Необходимо выбирать график, который наилучшим образом отображает данные и обеспечивает легкость восприятия.
3. Масштабирование: масштабирование данных может быть необходимо, чтобы график был понятным для зрителя. Необходимо учитывать, что слишком большие или слишком маленькие значения могут привести к неправильному восприятию данных.
4. Шрифт и размер шрифта: шрифт и размер шрифта могут влиять на читабельность визуализации. Необходимо выбирать шрифт, который хорошо читается и соответствует тематике визуализации.
5. Надписи и легенда: надписи и легенда могут быть важными элементами визуализации, которые помогают объяснить данные и обеспечить их понимание. Необходимо убедиться, что надписи и легенда четко отображают информацию и соответствуют тематике визуализации.
6. Анимация: анимация может быть полезной для демонстрации изменений в данных и помочь зрителю лучше понять, какие изменения происходят. Однако необходимо использовать анимацию умеренно, чтобы не отвлекать зрителя от основной информации.
7. Контекст: контекст визуализации может иметь большое значение при ее создании. Например, если визуализация используется для представления данных в научной статье, то необходимо учитывать требования к научной графике. Если же визуализация будет использоваться в рекламных целях, то необходимо учитывать требования к маркетинговой графике.
Artima
Где этому учат?