Переход от распределенной архитектуры микросервисов к монолитному приложению помог достичь лучшего масштабирования, устойчивости и снизить затраты.
В Prime Video мы предлагаем тысячи прямых трансляций нашим клиентам. Чтобы гарантировать бесперебойную работу, Prime Video настроил инструмент для мониторинга каждой просматриваемой трансляции. Этот инструмент позволяет автоматически выявить проблемы с качеством видео и звука (например, повреждение блоков или проблемы с синхронизацией) и начать процесс их исправления.
Наша команда Video Quality Analysis (VQA) в Prime Video уже владела инструментом для проверки качества аудио/видео, но мы никогда не планировали и не разрабатывали его для работы в больших масштабах (наша цель была мониторить тысячи параллельных потоков с увеличением этого числа со временем). При добавлении большего количества потоков мы заметили, что запуск инфраструктуры становится очень дорогой. Также были обнаружены узкие места, которые мешали мониторить тысячи потоков. Поэтому нам пришлось пересмотреть архитектуру существующего сервиса, сосредоточившись на затратах и узких местах масштабирования.
Первоначальная версия нашего сервиса состояла из лямбд, которые оркестрировались с помощью AWS Step Functions. Две наиболее затратные операции - это рабочий процесс (workflow) и передача данных между компонентами. Чтобы решить эту проблему, мы переместили все компоненты в один процесс, чтобы хранить передаваемые данные в общей памяти, что также упростило оркестрацию. Также, благодаря этому, мы смогли перейти на хорошо масштабируемые инстансы Elastic Compute Cloud (Amazon EC2) и Amazon Elastic Container Service (Amazon ECS).
Накладные расходы распределенных систем
Наш сервис состоит из трех основных компонентов:
Медиа-конвертер преобразует входящие потоки в кадры или аудио-буферы, которые отправляются детекторам.
Детекторы дефектов выполняют алгоритмы, анализирующие полученные кадры и аудио-буферы в реальном времени, и ищут дефекты (например, замирание видео, его повреждение или проблемы с синхронизацией), отправляя уведомления при их обнаружении. Дополнительную информацию об этой теме можно найти в нашей статье о том, как Prime Video использует машинное обучение для обеспечения качества видео (How Prime Video uses machine learning to ensure video quality).
Третий компонент предоставляет собой оркестрацию, которая управляет потоком в сервисе.
Мы разработали наше первоначальное решение как распределенную систему с использованием беcсерверных компонентов (например, AWS Step Functions или AWS Lambda), что было хорошим выбором для быстрого создания сервиса. В теории это позволило бы нам масштабировать каждый компонент сервиса независимо. Однако, мы быстро достигли жесткого предела масштабирования приблизительно на 5% от ожидаемой нагрузки. Кроме того, общая стоимость стала слишком высокой для принятия решения о дальнейшем масштабировании.
Следующая диаграмма показывает первоначальную архитектуру нашего сервиса:
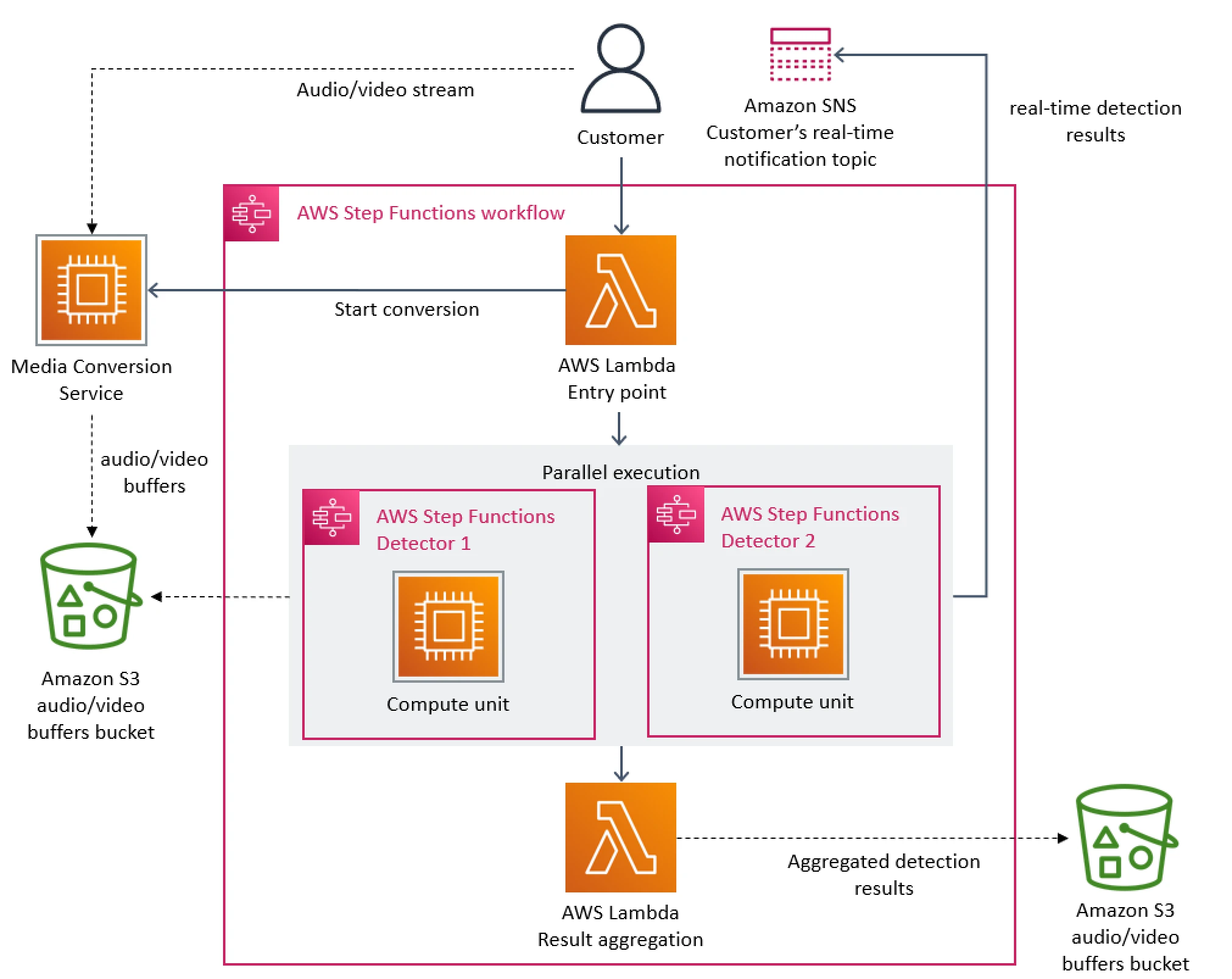
Основным узким местом в архитектуре было управление оркестрацией, реализованное с помощью AWS Step Functions. Наш сервис выполнял много переходов каждую секунду, поэтому мы быстро достигли лимитов для учетной записи. Кроме того, AWS Step Functions взимает плату у пользователей за каждый переход.
Вторая проблема с затратами, которую мы обнаружили, касалась того, как мы передавали видеокадры между компонентами. Чтобы сократить вычисления по конвертации видео, мы создали микросервис, который разбивает видео на кадры и временно загружает изображения в S3. Детекторы дефектов (каждый из которых также работает как отдельный микросервис) загружают изображения и обрабатывают их параллельно с помощью AWS Lambda. Однако большое количество вызовов к S3 стоило недешево.
От микросервисов к монолиту
Чтобы решить возникшие проблемы, мы рассматривали вариант по отдельности устранять недостатки, чтобы снизить стоимость и упростить масштабирования. Мы экспериментировали и приняли смелое решение: переделать архитектуру.
Распределенный подход не приносил большой пользы в нашем конкретном случае, поэтому мы упаковали все компоненты в один процесс. Это устранило необходимость использования S3 в качестве промежуточного хранилища для видеокадров. Мы также реализовали оркестрацию, которая контролирует компоненты в пределах одного экземпляра.
На следующей схеме показана архитектура системы после перехода к монолиту:

Концептуально, высокоуровневая архитектура осталась прежней. У нас все еще есть те же компоненты, что и в первоначальном дизайне (конвертеры, детекторы или оркестрация). Это позволило нам много кода использовать повторно и быстро перейти к новой архитектуре.
В первоначальном дизайне мы могли горизонтально масштабировать несколько детекторов, поскольку каждый из них работал как отдельный микросервис (так что добавление нового детектора требовало создания нового инстанса и его подключение). Однако в нашем новом подходе количество детекторов масштабируется только вертикально, потому что они все работают в пределах одного экземпляра. Наша команда регулярно добавляет новые детекторы в сервис, и мы уже превысили возможности вертикального масштабирования. Чтобы решить эту проблему, мы сделали несколько параллельно работающих инстансов, параметризовав каждую копию разным подмножеством детекторов. Мы также реализовали легковесный слой оркестрации для распределения запросов клиентов.
На следующей диаграмме показано наше решение для развертывания детекторов, когда одного инстанса недостаточно:

Результаты и выводы
Микросервисы и компоненты беcсерверной архитектуры - это инструменты, которые подходят для больших масштабов, но решение о том, использовать ли их вместо монолита, должно быть принято индивидуально для каждого конкретного случая.
Перенос нашего сервиса на монолит уменьшил затраты на инфраструктуру более чем на 90%. Это также увеличило наши возможности по масштабированию. Сегодня мы можем обрабатывать тысячи потоков, и у нас все еще есть запас для дальнейшего масштабирования сервиса. Перенос решения на Amazon EC2 и Amazon ECS также позволил нам использовать Amazon EC2 Compute Saving Plans, что также дополнительно снизило затраты.
Некоторые принятые нами решения не были очевидными, но привели к значительным улучшениям. Например, мы реплицировали сложный вычислительный процесс конвертации медиа-контента и поместили его ближе к детекторам. В то время как запуск конвертации один раз и кэширование его результатов может быть более дешевым вариантом, мы считаем, что это неэффективный подход с точки зрения затрат.
Внесенные нами изменения позволяют Prime Video отслеживать все просмотренные потоки, а не только самые популярные у зрителей. Этот подход увеличивает качество обслуживания наших клиентов.