В наше время компьютерные системы и программы играют важнейшую роль в жизни организаций. Поэтому безопасность и надежность программного обеспечения является критически важным фактором для всех, кто использует их. Однако при получении исходного кода существует риск кражи конфиденциальная информация, алгоритмы работы или могут быть сделаны иные действия, приносящие ущерб компании или пользователям.
Для защиты от таких угроз существуют различные методы, одним из которых является обфускация кода. Обфускация кода - это процесс приведения исходного кода программы к виду, сохраняющему исходную функциональность, но затрудняющему анализ, понимание алгоритмов работы и модификацию при декомпиляции. Этот процесс используется в случаях, когда исходный код программы содержит конфиденциальную информацию, а также злоумышленниками, которые хотят скрыть свои злонамеренные действия от антивирусных программ.
Чтобы понять всю суть обфускации рассмотрим следующие вопросы:
Зачем нужна обфускация?
Как обфускация работает?
Алгоритмы обфускации
Виды обфускации
Проблемы и недостатки обфускации
Используют ли обфускацию сейчас?
Обфускация вирусописателей
Другие способы защиты
Зачем нужна обфускация?
Сначала разберёмся, что такое reverse engineering.
Реверсивная инженерия (reverse engineering) — изучение того, как устроено какое-то программное обеспечение, с целью понять механизм его работы. С помощью реверсивной инженерии можно, например, сделать кряк на лицензионную программу, наверно, самым востребованным для поиска кряков является виндоус. Именно поэтому разработчики, которые бояться за безопасность своих программ, стараются различными методами защититься от реверсивной инженерии.
Обфускация является одним из методов защиты от реверсивной инженерии. Обфусцировать можно не только скомпилированную программу, но и исходный код, что актуально для скриптовых языков. Для обфускации кода используют специальные программы – обфускаторы. Данный метод защиты создает лишние инструкции, запутывает, добавляет ложные зависимости в коде, тем самым делая код сложнее для анализа и реверса, однако это замедляет программу.
Как обфускация работает?
Методов обфускации несколько, но в общем все они нацелены на то, чтобы после проведения обфускации код не был понятен. Руками заниматься обфускацией крайне неэффективно для хоть сколь-нибудь больших проектов, поэтому используют обфускаторы, которые могут повредить исходный код, а кроме этого существуют деобфускаторы, которые нацелены на приведение обфусцированного кода к исходному. Но минусы мы рассмотрим позже.
В теории должно получиться так, чтобы после обфускации получился код, который работает корректно, но при его изучении нельзя было получить полезную информацию. На практике же это невозможно. Любую защиту можно обойти. Обфускация лишь предполагает, что обход займёт нецелесообразное количество времени.
На реальном примере обфускация может выглядеть как-то так:
До:
a = 'a'
_b = 'b'
def foo():
print(a)
def _bar():
print(_b)
foo() # func foo
_bar()
После:
O00O0O0 ='a'; _OO00000O00O0O0O0O ='b';
def foo ():print (O00O0O0 )
def _O000000O00OOO0OO0 ():print (_OO00000O00O0O0O0O )
foo ()
_O000000O00OOO0OO0 ()Мощные обфускаторы упаковывают код в более сложные конструкции.
Алгоритмы обфускации
Существует большое количество алгоритмов работы обфускаторов, однако большинство из них базируются на двух основополагающих алгоритмах:
Алгоритм Колберга;
Алгоритм Chenxi Wang’s.
Виды обфускации
Наиболее известными и частыми являются следующие виды обфускации:
-
Лексическая обфускация
Это самый простой вид обфускации, при котором происходит:удаление комментариев или замена их на бессмысленные
удаление символов форматирования кода
замена имён на трудно воспринимаемые (часто очень похожие последовательности нулей и букв О, единиц и букв I и тд)
изменение расположение частей программы
добавление лишних операций, которые не повлияют на итоговый результат выполнения
-
Обфускация структур данных
Преобразования данного вида связаны с трансформацией структур данных. Существует следующие методы преобразования данных:обфускация хранения
Обфускация хранения предполагает создание и использование нетривиальных типов данных, замена существующих типов данных и т.п.
Используются следующие методы: разделение одной переменной на комбинацию переменных, преобразование статистических данных в процедурные, изменение области действия переменной, изменение интерпретации данныхобфускация соединения
Обфускация соединения состоит в соединении нескольких зависимых данных или разделении независимых данных. Так, например, массив можно разделить на несколько или наоборот несколько массивов соединить в один.обфускация переупорядочивания
Обфускация переупорядочивания включает в себя изменение порядка объявления переменных или функций, изменение внутреннего порядка структур данных.
-
Обфускация потока управления
Данный вид преобразований направлен на изменения порядка выполнения блоков программы. Включает в себя следующие методы:вставка функций (вставка тела функции вместо вызова функции)
извлечение функции (выделение участка кода в отдельную функцию)
распараллеливание кода в тех участках, где это возможно осуществить
добавление «мёртвого» кода
добавление недостижимого кода
добавление избыточного кода
устранение библиотечных вызовов
преобразование графа потока управления
клонирование функций
объединение функций
реструктуризация циклов
расширение области действия переменной
переупорядочивание циклов, выражений, условных и безусловных переходов, вызовов функций.
Превентивная обфускация
Превентивная обфускация направлена в первую очередь на защиту от деобфускаторов, алгоритмы которых основаны на методах статического и динамического анализа, анализа неиспользуемого или недостижимого кода. Данный тип обфускации нацелен на использовании ошибок, недостатков и недоработок программ деобфускации.
Проблемы и недостатки обфускации
Скорость работы программы
Так как обфускация может нагружать программу, то после проведения обфускации может получиться, что скорость работы пострадала. А если использовать методы, которые, например, только переименовывают переменные, то никакой защиты не получится.Некорректность работы программы после обфускации
В попытках защитить программу можно наделать критических ошибок, которые приведут к неправильной работе программы. Можно элементарно забыть переименовать переменную или при использовании обфускатора не знать алгоритм его работы и запустить на коде, который несовместим с обфускатором. После этого на определения проблем может уйти много времени.Использование деобфускаторов
Деобфускатор - это программа, которая даёт возможность получить из запутанного кода читаемый код. Например, достаточно известная программа de4dot. Особенно хорошо такие программы работают при обфускации через бесплатные и популярные обфускаторы.
Используют ли обфускацию сейчас?
Этот подход был весьма популярен в прошлом, но сейчас интерес к нему снизился.
Во-первых, у разработчиков появилась возможность использовать более сложные методы защиты.
Во-вторых, обфускация может привести к неожиданным проблемам. Например, если обфускация была сделана неправильно, это может привести к неработоспособности программы. Кроме того, обфускация усложняет отладку и тестирование, что может замедлить разработку и повысить ее стоимость.
В-третьих, надеяться, что код спасёт лабиринт обфускации не стоит. Один из интересных способов обфускации был реализован компанией Dropbox. Способ заключался в том, что их код был написан на Python, но скомпилирован кастомным компилятором. Однако и на такой способ нашлась разгадка.
Несмотря на это, некоторые разработчики все еще используют обфускацию для защиты своих программ. Но зачастую обфускация кода — это всего лишь дополнительный инструмент для защиты кода от постороннего несанкционированного вмешательства. Как единственный инструмент защиты данный процесс не имеет особого смысла. Хотя в работе с другими инструментами защиты он снижает вероятность изучения исходного кода программы.
Обфускация вирусописателей
Кроме защиты кода от злоумышленников обфускация помогает и вредоносным программам замаскироваться.
Вирусописатели используют обфускацию кода, чтобы скрыть свои вредоносные программы от антивирусных программ и обходить системы безопасности. Этот метод позволяет им изменить код вредоносного программного обеспечения таким образом, чтобы он не совпадал с оригинальным кодом и не был распознан антивирусным программным обеспечением.
В качестве примера можно привести вредоносную программу, которая осуществляет утечку данных. Для того, чтобы избежать обнаружения и блокировки антивирусным ПО, вирусописатель может применить обфускацию кода. Это позволит ему изменить код таким образом, чтобы он не соответствовал типичным образцам, которые используются антивирусными программами для определения вредоносных программ.
Также обфускация кода может использоваться для скрытия секретной информации, такой как пароли и ключи, которые могут быть использованы для взлома системы. В этом случае, вирусописатель может использовать обфускацию кода для того, чтобы закодировать эту информацию и скрыть ее от детектирования антивирусных программ.
Из-за этого некоторые антивирусы начали реагировать на обычные программы, если в них использовалась обфускация. Но разработчики защитных программ, хорошо знают все эти методики уже давно и сейчас успешно определяют такие угрозы.
Другие способы защиты
Создание зависимостей между протектором и основным кодом.
Нужно написать код таким образом, чтобы от наличия протектора зависела дальнейшая работа ПО. В протекторе могут, например, храниться какие-то значения переменных, которые в свою очередь будут получаться из сети интернет.
Но, используя этот метод, необходимо защитить от отладчика. Да и в целом от отладчика стоит защищаться всегда.
Виртуализация нативного кода.
Вместо обфускации может использоваться более надёжная мутация - виртуализация. При виртуализации код будет исполняться на виртуальной машине. Но этот способ съедает производительность в разы, поэтому необходимо создать протектор, который будет исполняться на виртуальной машине, чтобы производительность основной программы не пострадала.
Веб приложения.
Почти все популярные приложения для телефонов и компьютеров, которые не требуют сверхбольшой производительности, используют клиент-серверную архитектуру. При таком подходе пользователь не видит всю логику обработки данных, а только получает визуальное отображение. Такая логика перешла из сайтов, так как помимо защищённости очень удобно переносить приложение на другие операционные системы.
Минус такого подхода очевиден - сильное взаимодействие с интернетом, поэтому не для всех это подойдёт.
Электронная подпись.
Метод довольно простой. Необходимо вставить в приложение код, который будет получать хеш ключа текущей цифровой подписи пакета и сравнивать его с ранее сохраненным. Совпадают — приложение не было перепаковано (и взломано), нет — значит было. Однако код такой подписи взломщик может просто вырезать.
Частые обновления.
Скорее не способ, а просто рекомендация. Ведь при обновлении взломщику скорее всего нужно будет снова мучаться. Но не стоит обновлять каждый день в надежде, что это поможет, потому что и с этим можно справиться. Так, разработчики игры PUBG для защиты от читеров выпускали микрообновления каждый день, чтобы разработчики читов не успевали адаптировать свой софт. В начале это действительно помогло, но через непродолжительное время эти обновления стали бесполезными.
Заключение
Создать на 100% защищенное приложение не получится, можно даже не пытаться. Не существует метода абсолютной защиты, любую защиту можно обойти. В таком случае главная цель защиты - сделать так, чтобы для взлома понадобилось больше времени, чем для выхода обновления. В таком случае программа может считаться хорошо защищённой.
Главное понимать, какие убытки потенциально принесёт получение исходного кода. И исходя из этого решать насколько защищённое приложение необходимо создавать и какие способы стоит выбирать.
Хоть приложение рано или поздно взломают есть очень простые способы существенно усложнить жизнь среднестатистическому ревёрсеру, а самому не тратить существенного количество времени.
Источники информации
Комментарии (3)

theLulz
17.05.2023 16:06+2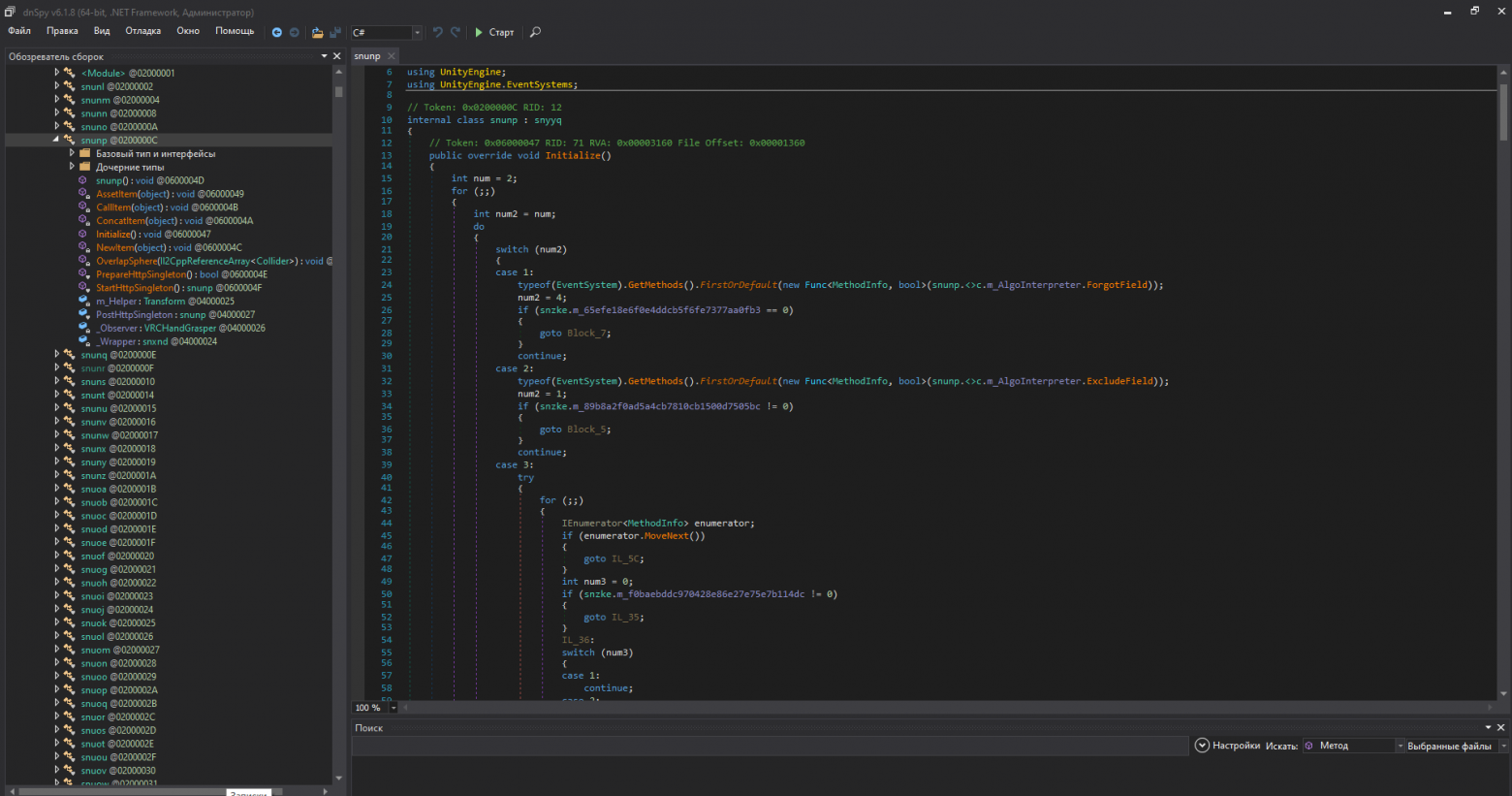
Интересный вариант использовать в коде классы-модули которые грузятся через рефлексию. Добавить несколько тысяч фейковых модулей и потом еще поверх этого пройтись обфускацией.

KvanTTT
17.05.2023 16:06Думаю это тоже может повлиять на работоспособность программы, особенно если в ней используется рефлексия, а также повлиять на производительность.
На мой взгляд, самый лучший метод обфускации по соотношению запутывание/влияние на программу — переименование всего, чего возможно. Это не влияет на логику программы (разве что рефлексию надо осторожно настраивать), но безвозмездно удаляет всю информацию об идентификаторах. При этом программа даже может уменьшиться в размере. Остальные методы ничего не удаляют, они именно запутывают.

PrinceKorwin
Просто пишите программы на Perl. Как известно, это единственный язык исходные коды которого до обфускации и после выглядят одинаково!