Привет!
Меня зовут Александр Маркачев, я 3,5 года работаю на позиции Data Engineer в билайне и люблю открывать для себя что-то новое и интересное в работе. Так случилось и с темой, которой я сегодня хочу с вами поделиться — со spill-ами.
Под катом мы поговорим о том, что такое Spill-ы в контексте Spark, и почему именно для Spark это не такая уж сильно плохая штука. Рассмотрим, из-за чего Spill-ы в принципе возникают, разберем несколько видов Spill-ов (и даже вызовем их намеренно), а затем будем решать эту проблему.
Что такое spill-ы в Spark
Вообще, Spill — это термин для обозначения процесса перемещения данных из памяти на диск, а затем снова обратно в память. По крайней мере, именно так гласит официальная трактовка. Если проще, то дело вот в чем — когда у Spark не хватает ресурсов для обработки, он перемещает данные на диск.
В процессе обработки существуют разные участки — есть Executor Memory, есть Storage Memory, и когда эти участки оба целиком заполнены, то они начинают переполняться и вызывать утечку данных. Причем в отличие от утечки в C, Java или еще где-то, в Spark это преднамеренное действие для того, чтобы ваша задача не падала. Собственно, именно поэтому при нехватке ресурсов данные и «проливаются».
Можно ещё сильнее упростить аналогию.
Представьте, что вам надо вскипятить кастрюлю воды. Обычный процесс, ничего сложного — налили воды, поставили на плиту, вскипятили, все ОК.

А теперь представьте, что вам надо вскипятить ведро воды, но с помощью кастрюли — кипятить кастрюлю, выливать воду в ведро, кипятить следующую. Получится ли у вас таким образом вскипятить ведро? Вряд ли.
Spark фактически решает эту проблему — он заливает воду в ведро, нагревает ее снова и снова, пока все ведро целиком у вас не будет вскипячено (читай — обработано).
Виды spill-ов
Spill «потому что»

Возникает, как правило, непредвиденно, вообще непонятно почему, зачем и как, но у него все же есть причина (как и остальных Spill-ов) — ему недостаточно ресурсов для обработки этих данных. Он возникает при попытке прочитать большое количество данных, сделать COALESCE и при подобной активности.
Как воспроизвести
Для примера я сделал небольшой датафрейм на 3 миллиарда строк и сделал на нем COALESCE.
val t1 = spark.range(30000000).toDF("num")
.withColumn("id", lit(1))
t1.coalesce(1).sortWithinPartitions($"id").show()На картинке видно, что в логах заметны UnsafeExternalSorter и 308 мегабайт.

Тут штука вот в чем. Все расчеты делались на одном гигабайте на драйвер и на экзекьютор. External Spill в данном случае 300 мегабайт, потому что мы взяли общий объем 1 гигабайт, от него отняли 300 мегабайт обязательно зарезервированной памяти. У нас осталось 700 мегабайт, из них мы отняли еще 40% и у нас осталось как раз 420 мегабайт. Часть из них зарезервирована для Storage Memory, часть как раз используется в качестве обработки.
Когда все это заполнено, происходит пролив.
Как устранить
Прежде всего, никогда не стоит делать COALESCE один, в том случае, если мы работаем с большими данными. Для получения идентичного поведения можно использовать просто сортировку, а уже потом сжать.
t1.orderBy($"id").coalesce(1).show()В итоге получится, что за счет того, что мы сначала данные отсортировали так, как нам надо, а потом уже уменьшили это до одной партиции, мы не получим проблем.
И можно увидеть на картинке — время обработки увеличилось из-за spill-а приблизительно в 14 раз.

Как же тогда обрабатывать большие объемы данных?
Делать Repartition. Это разобьет большую таблицу на много маленьких блоков и позволит Spark итеративно их обрабатывать, не перегружая систему.
Как можно раньше фильтровать данные. Таким образом получится вместо терабайта данных на начальном этапе обработать всего 100 гигабайт.
Делить таблицы на маленькие блоки, в принципе, это то же самое, что Repartition, с той лишь разницей, что мы не разбиваем это с помощью Repartition, а берем отдельные сегменты и итеративно их обрабатываем.
Spill оконный

Достаточно неприятный, потому что замедление оконных функций будет происходить в любом случае при стандартном поведении окна, даже если там не будет вызван Spill. Все потому, что по умолчанию в Spark выставлен такой параметр как ограничение блока данных в 4096 элементов. Если это значение превышается, то он начинает скидывать на диск и обрабатываться медленнее.
Как воспроизвести
Создадим небольшой DataFrame на 200 тысяч элементов и сделаем на нем оконную функцию для подсчета количества элементов. Тут мы специально сделали все с одним номером для того, чтобы показать, как будет работать оконная функция.
Подготовим данные.
val t1 = spark.range(200000).toDF("num").withColumn("id", lit(1)) .withColumn("c1", lit("одна длинная фраза которая никогда не кончится").withColumn("c2", И вызовем spill.
t1.withColumn("rn", max($"num").over(Window.partitionBy($"id"))).withColumn("rn", row_number().over(Window.partitionBy($"id").orderBy($"num".desc))).show()
В логах видно, что Spill активируется на 4096 элементах. Если у вас достаточно большой объем памяти, то Spill вы не увидите, но строка с активацией Unsafe External Sorter в логах все равно будет, при условии, что вы выйдете за количество элементов.

Как устранить
Для устранения в Spark есть специальные функции — spark.sql.windowExec.buffer.spill.threshold на, допустим, 200 тысяч элементов. Максимальное число элементов, Int Max Value, -15. То есть, порядка двух миллиардов элементов в принципе можно в одну оконную функцию закинуть. После устранения видно, что никаких Spill-ов нет, но в то же время тут есть определенные риски.
Если мы говорим именно про оконную функцию для датафреймов с небольшим количеством колонок, то данная опция будет вредна при увеличении объема данных.
Например, тут был сделан датафрейм на 300 тысяч элементов.
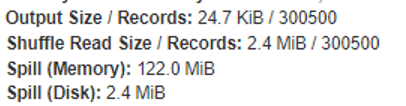
На скрине стандартное поведение — Spill на 122 мегабайта при увеличении до 300 тысяч строк. В то время как при изменении параметра оконной функции до 200 тысяч элементов Spill оконной функции становится 182 мегабайта, то есть больше.
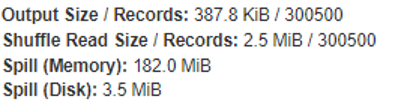
Учитывайте, что данное поведения актуальны только при датафреймах с небольшим количеством колонок. Таким образом, при увеличении до 300 тысяч элементов в логах вы также увидите, что Spill теперь стартует с 200 тысяч строк, а в остальном никаких отличий от варианта без настройки, то есть было 4096, а стало 200 тысяч строк. Потом начинаются Spill-ы.

Чем больше у вас будет колонок, тем меньше будет эта разница, и в определенный момент настройка оконной функции превзойдет стандартное поведение.
Если у вас мало колонок, то либо настраивайте параметр Spill-а для оконных функций на большее количество элементов, которые точно никогда не возникнет, либо не настраивайте, и стандартное поведение будет немного лучше.
Рекомендации
Перед оконной функцией, как всегда, отсеките лишние строки, лишние колонки. Чем меньше колонок, тем позже будет вызван Spill при стандартном поведении.
Если у вас много колонок — указывайте параметры для настройки оконной функции.
Если 2-3-4, не беспокойтесь и рассчитывайте стандартное поведение (что там Spill будет меньше).
Spill перекошенный
Перекос данных — это когда у вас какого-либо ключа очень много. Например, у вас миллион одного ключа, а остальных — по сотне. В результате один поток будет обрабатывать все эти ключи. На этот экзекьютор скинутся все данные по данному ключу и будут очень долго обрабатываться.
Возникает при join, возникает при groupBy. Скорее всего, возникает еще при каких-то операциях, если помните или сталкивались — напишите в комментах, пожалуйста.
Как воспроизвести
Можете воспользоваться данным кодом — создать таблицу на миллиард записей или 10 миллионов и вторую маленькую таблицу, допустим, по 100 строк.
val t1 = spark.range(10000000).toDF("num").withColumn("id", lit(1)).union(spark.range(100).toDF("num").withColumn("id", lit(2))).union(spark.range(100).toDF("num").withColumn("id", lit(3))).union(spark.range(100).toDF("num").withColumn("id", lit(4)))
val t2 = spark.range(100).toDF("num2").withColumn("id2", lit(1)).union(spark.range(100).toDF("num2").withColumn("id2", lit(2))).union(spark.range(100).toDF("num2").withColumn("id2", lit(3)))После чего попробуйте их соединить.
t1.join(t2, $"id" === $"id2", "inner") В логах вы увидите (на таймере выполнения), что работает всего лишь один экзекьютор и на нем будет spill memory.

Как устранить
В стандартной практике создаются искусственные ключи, допустим, при соединении какого-либо элемента либо соединением нескольких строк колонки, и потом все это соединяется. У нас в билайне есть функция Salted для устранения данной проблемы. Она достаточно легко пишется — высчитывается количество элементов в датафрейме, после чего берется среднее от него, делится, и для всего, что больше, добавляется искусственный ключ, чтобы перемножать не все данные в датафреймах, а именно перекошенные.
import ru.beeline.dmp.tools.spark.utils.skewjoin.SkewJoin._
salted(t1, t2, List($"id"), List($"id2"), "inner")()()(50000)
В результате мы увидим ситуацию получше — распараллеливание запроса и намного более быструю обработку. Естественно, скорость будет зависеть от того, насколько сильно были перекошены данные.
Рекомендации
Добавлять больше условий при соединениях или агрегациях. Чем больше условий, тем ниже вероятность того, что какой-либо из ключей будет перекошен, и тем больше параллельных потоков сможет запуститься.
Если вы знаете, что есть перекос, то можете добавить искусственный ключ, либо придумать какую-либо другую обработку, допустим, разделить это на отдельные блоки и обработать итеративно.
Если вы работаете в билайне (если хотите, приходите к нам в бигдату), можете воспользоваться Salted-функцией, а если не работаете, то можете написать свою функцию и внедрить ее в своей компании.
Spill соединительный

В целом, это тот же самый Spill, что в самом начале — когда очень много данных, но в то же время он не возникает на этапе считывания, он возникает именно при попытке каких-либо действий.
Как воспроизвести
Создадим DataFrame по 100 миллионов записей и соединим его с другим датафреймом по 100.
val t1 = spark.range(100000000).toDF("num").withColumn("id", lit(1)).union(spark.range(100000000).toDF("num").withColumn("id", lit(2)))
val t2 = spark.range(100).toDF("num2").withColumn("id2", lit(1)).union(spark.range(100).toDF("num2").withColumn("id2", lit(2)))
t1.join(t2, $"id" === $"id2", "inner“) Видно, что в первом случае мы обрабатывали, условно, в два потока и есть Spill Memory. В логах мы точно так же, как и при других типах Spill-ов, видим UnsafeExternalSorter, видим 308 мегабайт Spill-а.


Снова нам на выручку придет функция Salted (которую вы, наверное, уже написали после предыдущей главы?), но в данном случае мы разделим наши большие блоки по 100 миллионов на маленькие блоки — по 5 миллионов записей (а если вы не написали функцию для “соления” — можно просто с помощью rand добавить число от 1 до 20).
В случае же с функцией Salted мы опять-таки параллелим запрос точно так же, как было с перекошенным join. Для groupBy придется писать самим под каждый тип группировки, потому что для Max, допустим, и для среднего это будут абсолютно разные условия.
import ru.beeline.dmp.tools.spark.utils.skewjoin.SkewJoin._
salted(t1, t2, List($"id"), List($"id2"), "inner")(0.05)()()
Как устранить
Разделить на более маленькие блоки в результате и обрабатывать параллельно, как и в случае с любым Spill-ом.
Spill зашафленный

Это снова комбинация предыдущих Spill-ов, но возникает при работе с большим объемом данных малыми ресурсами. Можем наблюдать при попытке разбить большое количество данных на большое количество блоков. В результате будет происходить shuffle External Sorter. В отличие от unsafeExternal Sorter, он возникает именно в случае перемешивания данных между разными нодами.
Как воспроизвести
На вход подаем большое количество записей (5 миллиардов) и потом на нем пытаемся выяснить максимальное число. В результате, так как там у нас 2000 партиций, при перемешивании между нодами происходит большой шафл. Как следствие — происходит Spill.

Как устранить
Настроить Spark Memory Fraction и Storage Fraction. Так вы увеличите доступную память для Spark, но делать я это крайне не рекомендую, потому что мы повышаем риск Out of Memory Exception. Тогда все может упасть.
Более надежный способ — разделить нашу таблицу по какому-нибудь ключу. В примере — это Market Code.
Как видно на картинке, началась параллельная обработка по городам (мы не могли разделить по месяцам и разделили по городам). Все запараллелилось, проблема исчезла.

Что важно. Все параметры были Shuffle Partition 2000. В случае, если мы сделаем Shuffle Partition 200, мы получим похожую проблему, но только уже не из-за шаффла, а из-за того, что мы пытаемся обработать большое количество данных на малом количестве экзекьюторов. Проблема не устраняется ни так, ни так.
Самый надежный способ — это разделить по городам. Всегда можно найти какой-либо дополнительный ключ, по которому можно произвести разделение.
Рекомендации
Смотреть применимость параметров в случае каждого расчета. Если у вас мало данных, то действительно можно использовать первый способ и настроить Memory Fraction.
Если у вас много действий, то есть большой расчет, то нужно искать выходы. В данном случае, допустим, разделить по городам. В ваших случаях это может быть какой-либо другой способ.
Возможно, решение проблемы решит вообще не в области ресурсов, и дело в том, что вы пытаетесь забрать слишком много данных, которые вам реально не нужны. Это нужно рассматривать и помнить всегда.
Spill Декарта (Cartesian Join)

Возникает в случае Cross Join.
В логах видно, что произошло падение.


В принципе, со всеми другими Spill-ами мы тоже можем увидеть падение, но с Cartesian это наиболее вероятно. По умолчанию там так же, как с оконными функциями, настройка на 4096 элементов.
Как воспроизвести
val t1 = spark.range(1000000).toDF("num").withColumn("id", lit(1))
val t2 = spark.range(1000).toDF("num").withColumn("id", lit(1))
spark.conf.set("spark.sql.cartesianProductExec.buffer.spill.threshold", 10)t2.crossJoin(t1) Я уменьшил размер буфера для Cartesian Join до 10 элементов. И у нас очень быстро всё упало, так как произошел очень большой Spill на 2 ГБ.

Как устранить
Можно изменить порядок джоинов. Ведь проблема возникла именно из того, что мы маленький DataFrame пытались сджойнить с большим. В итоге большой DataFrame перемещался между экзекьюторами и вызывал Spill. А если мы поменяем и будем к большому DataFrame джойнить маленький, проблема исчезнет.
t1.crossJoin(t2)Это относится вообще ко всем видам джойна — всегда джойните к большому DataFrame малый DataFrame.
А можно установить больший размер буфера - spark.conf.set("spark.sql.cartesianProductExec.buffer.spill.threshold", 100000)
Возможно, в вашей практике spill-ы встречались и в других ситуациях, при которых вы нашли необычный или обычный способ их устранить— будет здорово, если поделитесь этим в комментариях.
Комментарии (3)

barloc
22.06.2023 14:19Случай 1 меня всегда забавлял. На всех собеседованиях (ну, где я был) всегда спрашивали про том, чем отличается коалесце от репартишна - и ответ про принудительный сброс данных на диск.
Но коалесце никогда не работала и не работает, до сих пор коалесце ломает план и превращает код в нерабочий на сколько-нибудь нормальном размере датасета :(
Geckelberryfinn
Или используйте хинт broadcast
SacredDiablo Автор
Да, это хороший вариант если размеры таблиц позволяют