От переводчика:
DragonflyDB - молодая in-memory база данных, написанная на C++ и совместимая с Redis (не форк). Использует под капотом многопоточную архитектуру (в отличии от однопоточного Redis) для лучшей утилизации современных процессоров и более простого вертикального масштабирования.
Первая публичная версия v0.1.0 была представлена на Github 31 мая 2022 г, в марте этого года выпущена v1.0, имеющая статус Production Ready.
Чем может похвастаться команда DragonflyDB на данные момент:
Проект имеет более 20 тысяч звезд на Github;
Полностью поддерживает порядка 200 команд Redis (см. страницу Dragonfly API Compatibility);
Привлек $21 миллион в A-раунде инвестиций в марте этого года;
По бенчмарках Dragonfly превосходит Redis в 25 раз по QPS, в 12 раз по скорости записи дампа.
Кроме вышеперечисленного в DragonflyDB привлекает устройство кеша и его очистки, которая должна превосходить известные LRU и LFU политики. Именно статью про устройство кеша в Dragonfly от главного разработчика захотелось перевести для читателей Хабра (про ошибки перевода прошу в личку).
Я рассказывал в своем предыдущем посте о стратегиях вытеснения в Redis. В этой статье я хотел бы описать дизайн кэша Dragonfly.
Если вы еще не слышали о Dragonfly, пожалуйста, ознакомьтесь с ним. Он использует, как я надеюсь, новые и интересные идеи, подтвержденные исследованиями последних лет [1] и [2]. Он призван исправить многие проблемы, существующие в Redis. Я работал над Dragonfly в течение последних 7 месяцев, и это был один из самых интересных и сложных проектов, которые я когда-либо делал!
Но вернемся к дизайну кеша. Мы начнем с краткого знакомства с LRU-кешом и его недостатками, а затем проанализируем его реализацию в Redis.
LRU
Политика кэша "наименее недавно использованных" (LRU) вытесняет элементы, как следует из названия, которые давно не были использованы. Он работает таким образом, потому что алгоритм кэша пытается оптимизировать коэффициент попаданий или вероятность доступа к его элементам в будущем.
Если кэш полон, ему нужно освободить место для новых элементов. Кэш освобождает пространство для новых элементов, удаляя наименее ценные элементы, предполагая, что давно неиспользуемый элемент также является наименее ценным.
Это предположение разумно, но, к сожалению, этот алгоритм ведет себя плохо, если вышеупомянутое предположение не выполняется. Рассмотрим, например, ситуацию с длинным хвостом распределения.

Y - нормализованная частота доступа к элементам кэша
В этом случае большое количество новых "желтых" элементов с низкой частотой доступа может вытеснить небольшое количество ценных "зеленых" элементов, ответственных за подавляющее большинство попаданий. В результате LRU может удалять ценные "зеленые" элементы из-за колебаний трафика.
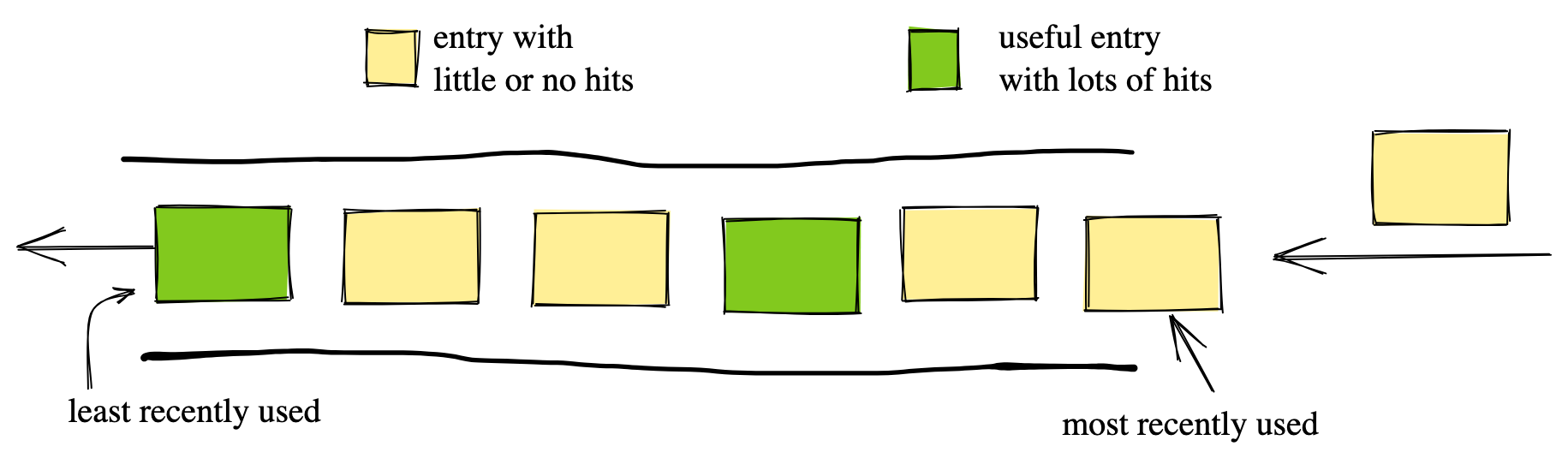
Эффективность реализации LRU
LRU - это простой алгоритм, который можно реализовать эффективно. Действительно, можно хранить все элементы в двусвязном списке. Когда происходит обращение к элементу, LRU перемещает его в начало списка. Для вытеснения элементов LRU удаляет их с конца списка (см. диаграмму выше). Все операции выполняются за O(1), а накладные расходы памяти на каждый элемент составляют 2 указателя, то есть 16 байт на 64-битной архитектуре.
LRU в Redis
Redis реализует несколько эвристик вытеснения. Некоторые из них описываются как "приближенный LRU". Почему приближенный? Потому что Redis не поддерживает точный глобальный порядок среди своих элементов, как в классическом LRU. Вместо этого он хранит последнюю отметку доступа в каждой записи.
Когда ему нужно вытеснить элемент, Redis выполняет случайную выборку K кандидатов из всего набора ключей. Затем он выбирает элемент с самой старой отметкой времени среди этих K кандидатов и удаляет его. Таким образом, Redis экономит 16 байт на запись, необходимую для упорядочения элементов в одном глобальном порядке. Эта эвристика является очень грубым приближением LRU. Недавно разработчики Redis обсуждали возможность добавления дополнительной эвристики в Redis, реализуя классическую политику LRU с глобальным порядком, но в конечном итоге отказались от этой идеи.
Кеш в Dragonfly
Dragonfly реализует кэш, который:
устойчив к колебаниям трафика, в отличие от LRU
не требует случайной выборки или других приближений, как в Redis
не имеет дополнительных накладных расходов памяти на каждый элемент
имеет очень маленькие - O(1) - накладные расходы с точки зрения времени выполнения в run-time
Это новый подход к проектированию кэша, который не был предложен ранее в академических исследованиях.
Кэш Dragonfly (Dash-Cache) основан на другой известной политике кэша из статьи 1994 года "2Q: A Low Overhead High Performance Buffer Management Replacement Algorithm".
2Q решает проблемы LRU, вводя два независимых буфера. Вместо того чтобы рассматривать только последнюю активность как фактор, 2Q также учитывает частоту доступа для каждого элемента. Сначала он помещает недавние элементы в так называемый буфер испытания (probationary buffer). Этот буфер занимает только небольшую часть пространства кэша, скажем, менее 10%. Все недавно добавленные элементы конкурируют друг с другом внутри этого буфера.
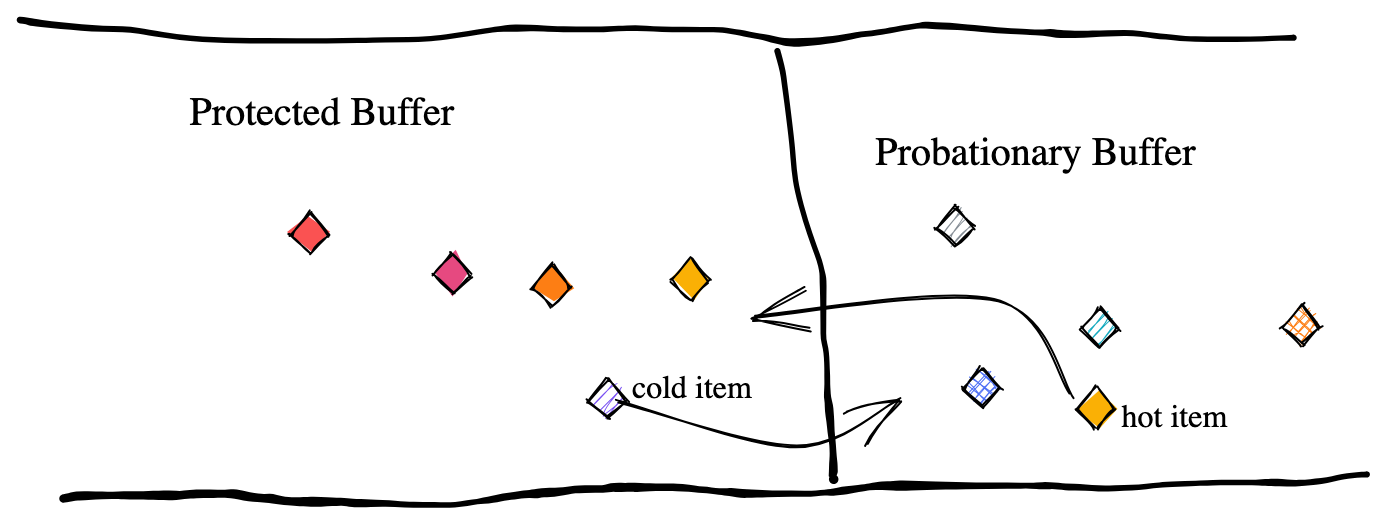
Только если элемент буфера испытания был запрошен хотя бы один раз, он считается достойным и переносится в защищенный буфер (protected buffer). При этом из защищенного буфера самый правый элемент, к которому не обращались дольше всего, вытесняется обратно в буфер испытания. Вы можете прочитать этот пост для получения более подробной информации.
Для 2Q попадание элемента в кеш не делает его полезным. В этом плане 2Q превосходит LRU-кеш. Для того, чтобы считаться полезным, элемент должен быть запрошен хотя бы один раз. Благодаря этому кэш 2Q более устойчивый и способный достичь более высокого коэффициента попаданий, чем политика LRU.
От переводчика. Далее автор делает достаточно резкий переход к структуре данных Dashtable, не пугайтесь. Как именно идеи 2Q и Dashtable работают сообща внутри Dragonfly будет написано чуть ниже.
Dashtable за 60 секунд
Для глубокого погружения в тему использования Dashtable в Dragonfly я рекомендую к прочтению этот пост или оригинальную научную работу.
Но для быстрого знакомства я предлагаю следующие основные факты о Dashtable в реализации Dragonfly:
Dashtable состоит из сегментов постоянного размера. Каждый сегмент содержит 56 обычных бакетов с несколькими слотами. Каждый слот содержит ровно один элемент.
Алгоритм маршрутизации Dashtable использует хэш элемента для вычисления идентификатора сегмента. Кроме того, он предопределяет 2 из 56 бакетов, где элемент может находиться внутри сегмента. Элемент может находиться в любом свободном слоте в этих двух бакетах.
В дополнение к обычным бакетам, сегмент Dashtable содержит 4 бакета типа stash, которые могут использоваться для хранения элементов, которым не хватает места в их назначенных бакетах. Алгоритм маршрутизации никогда не присваивает stash-бакет напрямую. Если оба домашних бакета элемента заполнены, элемент может быть помещен в любой из 4 stash-бакетов. Это существенно улучшает вместимость сегмента.
Когда сегмент становится полностью заполненным и нет свободного места для нового элемента ни в его обычных бакетах, ни stash-бакетах, Dashtable расширяется путем добавления нового сегмента и разделения содержимого полного сегмента примерно пополам.
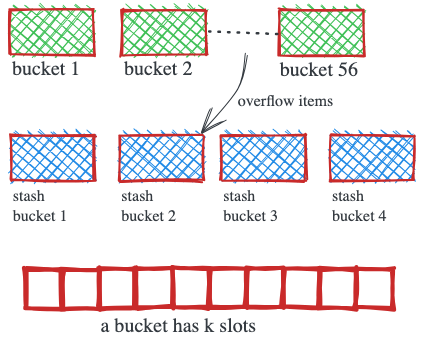
В момент полного заполнения сегмента удобно применить политику вытеснения в Dashtable, потому что именно в этот момент Dashtable расширяется. Также для предотвращения расширения Dashtable можно вытеснять элементы только из полного сегмента. Это обеспечивает очень четкую политику вытеснения с временной сложностью O(1).
Реализация 2Q
Dragonfly расширяет идеи выше. Наивным решением было бы разделить записи хеш-таблицы на два буфера: пробный буфер с порядком FIFO и защищенный буфер, использующий связанный список LRU. Это сработает, но потребует использования дополнительных метаданных и траты драгоценной памяти.
Вместо этого Dragonfly использует уникальный дизайн Dashtable и его слабую упорядоченность в качестве преимущества.
Чтобы объяснить, как 2Q работает с Dashtable, нам нужно объяснить, как мы определяем пробные и защищенные буферы, как продвигаем пробный элемент в защищенный буфер и как мы удаляем элементы из кеша.
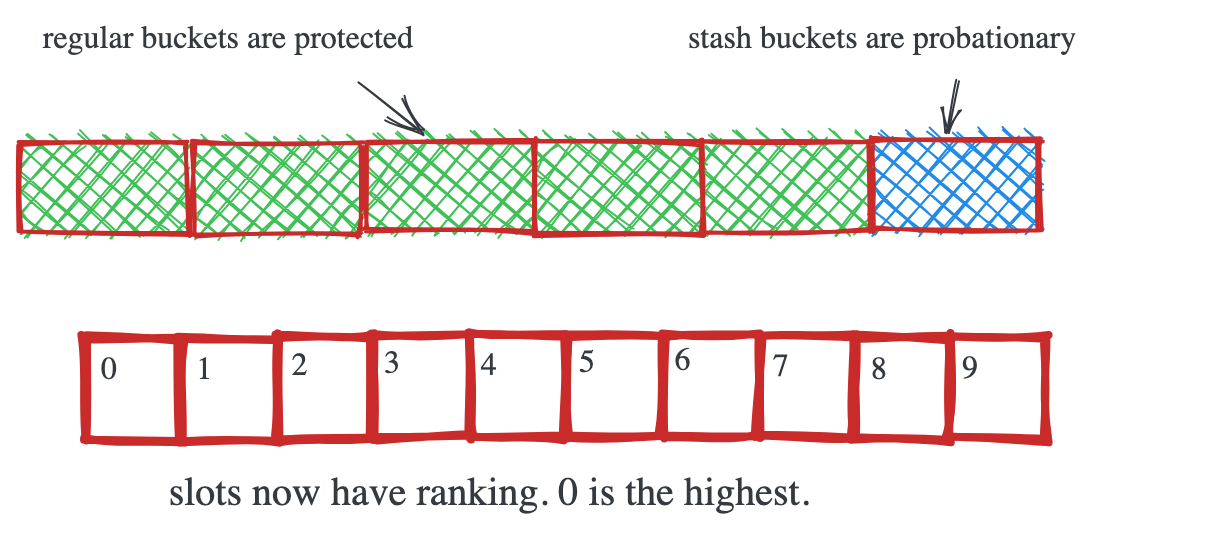
Мы накладываем следующие семантические правила к исходному Dashtable:
Слоты внутри бакета теперь имеют ранг или приоритет. Слот слева имеет самый высокий ранг (0), а последний слот справа - самый низкий ранг (9).
Stash-бакеты внутри сегмента служат в качестве буфера испытания. Когда новый элемент добавляется в полный сегмент, он помещается в stash-бакет в слот 0. Все остальные элементы в бакете сдвигаются вправо, и последний элемент в бакете вытесняется. Таким образом, бакет служит FIFO-очередью для элементов, находящихся на испытательном сроке.
-
Каждое попадание в кэш "продвигает" элемент:
Если элемент находился в stash-бакете, он мгновенно перемещается в свой домашний бакет на последний слот;
Если элемент находился в домашнем бакете на слоте
i, он обменивается местами с элементом на слотеi-1;Элемент на слоте 0 остается на своем месте;
Когда элемент на испытательном сроке продвигается в защищенный буфер, он перемещается на последний слот. Элемент, который был там ранее, переходит обратно в буфер испытания.
Политика вытеснения Dash-Cache состоит из шага "вытеснения", описанного в пункте (2), и шага позитивного усиления, описанного в пункте (3).
Всё! Не требуется никаких дополнительных метаданных. Элементы высокого качества очень быстро попадут в слоты с высоким рангом в своих домашних бакетах, в то время как новые добавленные элементы конкурируют друг с другом внутри stash-бакетов. В нашей реализации каждый бакет имеет 14 слотов, что означает, что каждый элемент на испытательном сроке может быть сдвинут 14 раз, прежде чем будет вытеснен из кэша, если он не докажет свою полезность и не будет продвинут. Каждый сегмент имеет 56 обычных бакетов и 4 stash-бакета, поэтому мы выделяем 6,7% общего пространства под буфер испытания. Этого достаточно, чтобы уловить элементы высокого качества, прежде чем они будут вытеснены.
Надеюсь, вам понравилось читать о том, как дизайн кэша Dragonfly использует, казалось бы, несвязанные концепции вместе в своих интересах.
Спасибо за внимание. Возможно DragonflyDB действительно интересный новый игрок на рынке in-memory бд.
Мой канал в телеграмм про разработку и не только ;-)
Комментарии (17)

aleks_raiden
05.07.2023 09:53+1Тестировал у себя, особо прям вау-результата не заметил, да и не все нужные команды поддерживает, но следить буду. Более того - не показал даже сильно лучше результатов, чем наша KVRocks, при том что мы на диск пишем все )

arusakov Автор
05.07.2023 09:53А KeyDB не тестировали? А то про него хайпа меньше, а толку может и больше)
aleks_raiden
05.07.2023 09:53+1Тестирую и смотрю на все редис-лайк штуки. Но мне надо персистент-хранилище, а не в памяти + мы активно используем STREAMS, которых в keyDB тогда не было, сейчас получше, но я все ждал их флеш-хранилище, пока непонятно. Пришлось стать комиттером в KVRocks )

Tsimur_S
05.07.2023 09:53Но мне надо персистент-хранилище
А в сторону aerospike и tarantool не смотрели? Там есть и персистанс и стримы.
aleks_raiden
05.07.2023 09:53аероспайк коммерческий, тарантул смотрел, но луа (ладно) но коннектор к nodejs официально не развиваеться и без поддержки + так и нет транзакций где оба движка (mem + vinyl)
aleks_raiden
05.07.2023 09:53в тарантуле нет нативно стримов, есть очередь написанная просто и тоже не развиваеться )
arusakov Автор
05.07.2023 09:53Кстати, очередь как будто немного ожила с середины 2022 года https://github.com/tarantool/queue/releases
Tsimur_S
Исключительно вертикального масштабирования. Горизонтальное не предусмотрено и не факт что будет в принципе.
arusakov Автор
Спасибо за комментарий, действительно на текущий момент вообще никакой работы над реальным горизонтальным масштабированием не ведется, но стоит добавить два момента:
Не отрицают, что может быть в будущем дойдут до этого руки (см. коммент на github)
Уже сейчас для миграции с Redis Cluster доступна эмуляция через
--cluster_mode=emulated(https://www.dragonflydb.io/docs/managing-dragonfly/clustermode). Больше похоже на "костыль", но хоть такTsimur_S
Честно говоря очень сильно заметно по этому проекту что самое важное это "Привлек $21 миллион в A-раунде инвестиций в марте этого года"
1) Манипулятивные комментарии к бенчмарку: про "demonstrated better latency in write workloads" они написали до того как привести результаты бенчмарка а про "exhibited lower latency for the read benchmark" ниже данных, скорее всего в надежде что никто не будет дальше читать. Забавный выбор слов better и lower и уж точно совершенно не случайный.
Ведь если просто написать что латенси на GET в три раза хуже чем в memcached то могут и не дать 21млн.
2) Отсутствие горизонтального масштабирования преподносится как плюс:
3) Бенчмаркая редис и df нужно обязательно привязаться к метрике количество запросов на инстанс. Ведь иначе не получить x25 перфоманс. Использовать редис кластер для сравнения видимо было лень.
Не так давно команда редиса запустила кластер на одной машине и оказалось что 40 инстансов редиса выдают результаты выше чем 64 ядерный dragonfly https://redis.com/blog/redis-architecture-13-years-later/. А казалось бы shared nothing архитектура.
arusakov Автор
Меня тоже эти $21 миллион как-то удивили для такого технологического проекта.
Под впечатлением пошел посмотреть, сколько привлекли KeyDB (тоже многопоточный убийца Redis из 2019 г.). Оказалось, что у них было $1.3 миллиона в Seed-раунде, а потом их поглотил Snapchat. Может и тут какая-то похожа история выйдет...
А мы с вами от конкуренции даже выиграем :)
zo0Mx
Справедливости ради, стоит заметить, что то о чём вы говорите не что-то из ряда вон выходящее, а самый что ни на есть рядовой маркетинг и позиционирование. Непонятен ваш "срыв покровов".
Вы раскрыли секрет полишинеля.
А здесь уже вы манипулируете. Добро пожаловать в release notes и discussions.
да, именно так, именно потому что DF пока ограничен в возможностях горизонтального масштабирования.
omg, вы через строчку в школе научились читать? о том и речь что никто не хочет поднимать и сопровождать 40 (40, Карл!) инстансов Redis-а. Поэтому и появляются новые решения вроде DF.
Да вы просто хейтер, гражданин.
Tsimur_S
И? Это плохо?
Раскройте пожалуйста мысль как связаны ссылки и моя манипуляция скриншотом их рядового маркетинга.
Не ограничен а она отсутствует. Причем это преподносится как плюс.
А я то думал что речь идет про перформанс.
Все так, я хейтер манипулятивного маркетинга.
Gromilo
Я правильно понимаю, что редису понадобилось в 40 раз больше памяти, или они что-то с этим сделали?
arusakov Автор
В их эксперимент они запускают Redis Cluster, в котором данные шардируются по ключам. То есть память достаточно адекватно должна в такой схеме расходоваться, не x40.
Gromilo
Понял, спасибо
Tsimur_S
Зачем? Есть же шардирование.