
Многие программисты пытались и пытаются сделать какую-нибудь диалоговую программу для общения с машиной на ЕЯ. Не счесть всяких ботов и тому подобных самоделок.
Кроме того, существует огромное количество коммерческих программ, которые как-то, приблизительно, решают проблемы машинного понимания ЕЯ. Примеры всем известны – поисковые системы, так называемые системы машинного перевода, системы анализа тональности, справочные системы, да и тот же FAQ – все они далеки от удовлетворительного решения проблемы общения с машиной на ЕЯ.
Причина видна невооруженным глазом – используются приблизительные, поверхностные, упрощенные способы обработки естественно-языковых предложений – поиск ключевых слов, использование статистических данных о встречаемости тех или иных синтаксических структур в языке. Тем самым как бы подразумевается, что ЕЯ слишком сложен для реализации полного машинного понимания, поэтому надо применять упрощающие задачу подходы.
Каким должно быть полное, бескомпромиссное решение проблемы? Очевидно, для этого машина должна обеспечивать такую же работу с естественным языком, какую выполняем мы, люди, когда читаем, слушаем, говорим, пишем и думаем. В чем наше отличие в этом деле от нынешних компьютерных программ? Человек работает со смысловым содержанием предложений, понимая, что одну и ту же мысль можно выразить множеством способов, хотя и не полностью эквивалентных. Значит, надо научить машину так обрабатывать предложения на естественном языке, чтобы извлекать мысль, смысловое содержание содержащуюся в этих предложениях. Машина должна работать с мыслью, а не с буквой.
Тут возникают два взаимосвязанных вопроса:
— как построить механизм извлечения смыслового содержания из текста?
— как формально представить это смысловое содержание текста?
Конечно, главной проблемой здесь является вторая, поскольку обеспечивает необходимую начальную формализацию задачи. Решения этой проблем известны достаточно давно. Кратко рассмотрим некоторые из них.
Еще в далеком 1980г. в переводе на русский язык вышла книга Р. Шенка «Концептуальная обработка информации», в которой он описал выполненную им со своими аспирантами работу по моделированию машинного понимания естественного языка. Он разработал метод формального представления смыслового содержания ЕЯ-предложения, а его аспиранты реализовали в виде программ на языке ЛИСП три основные необходимые функции:
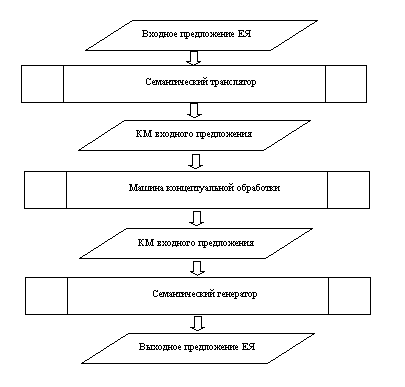
— семантическая трансляция – преобразование предложения нам естественном языке в соответствующую концептуальную модель;
— концептуальная память – манипулирование концептуальными структурами, соответствующее «человеческим» мыслительным операциям;
— концептуальная генерация – преобразование концептуальной структуры в текст на естественном языке.
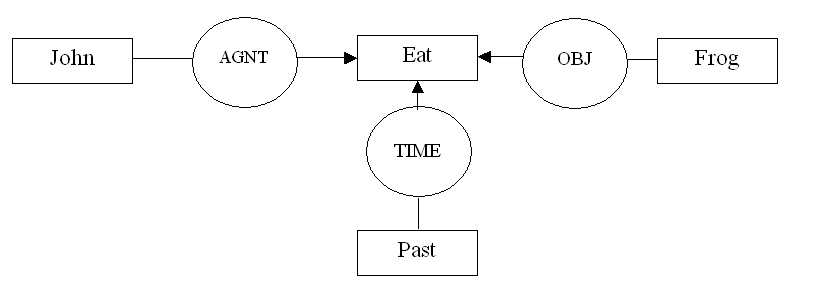
Пример концептуального представления предложения «Джон съел лягушку».

Подход Шенка основан на применение специального, разработанного им языка для описания мыслительных (концептуальных) операций и объектов. Он назвал свой подход теорией концептуальной зависимости (ТКЗ).
Для того чтобы дать начальное представление о ТКЗ приведем некоторые минимальные сведения о нем. Концептуализация – базовая единица концептуального уровня, из которой конструируются мысли. Концептуализация строится из следующих элементов:
— ДЕЯТЕЛЬ – понятие исполнителя АКТа;
— АКТ – действие, производимое по отношению к объекту;
— ОБЪЕКТ – нечто над которым производится действие;
— РЕЦИПИЕНТ – получатель ОБЪЕКТА в результате АКТа;
— НАПРАВЛЕНИЕ – местоположение, к которому направлен АКТ;
— СОСТОЯНИЕ – состояние ОБЪЕКТА.
Действия, объекты, отношения, состояния – вот основные элементы созданного им языка (для которого он не придумал имени).
Основные типы концептуальных действий в ТКЗ следующие:
— PROPEL, MOVE, INGEST, EXPEL, GRASP (физические действия, выполняемые человеком);
— PTRANS – «переместить физический объект»;
— ATRANS – «изменить абстрактное отношение для объекта
— SPEAK – «произвести звук»;
— ATTEND – «направить орган чувств к определенному стимулу»;
— MTRANS – «передавать информацию (между людьми или внутри одного человека)»;
— MBUILD – «создавать иди сочетать мысли».
Здесь мы не будем давать описание или хотя бы введение в язык ТКЗ, поскольку это не является целью данного текста. В книге Р. Шенка есть подробное описание этого языка.
Теория Шенка направлена на описание поведения и мышления человеческих субъектов, что очень интересно и актуально для моделирования личности. На основе ТКЗ можно создавать программы, обеспечивающие диалог мыслящих индивидуумов, когда диалог с машиной будет неотличим от диалога с человеком.
В то же время, для машинного понимания ЕЯ-текста не всегда нужно точное моделирование мыслительных процессов индивидуума. В качестве одного из более утилитарных подходов к моделированию семантики текста можно рассматривать теорию концептуальных графов. Первым автором, который подробно описал КГ и рассмотрел вопросы их применения является R. Sowa, книга которого «Conceptual Structures: Information Processing in Mind and Machine» на русский язык не переводилась.
Концептуальный граф представляет собой связную сеть бинарных отношений, описывающих смысловые связи соответствующего предложения. Этот подход превратился в целое научное направление, в котором есть различные ветви, имеется множество экспериментальных разработок, проводятся научные конференции.
В КГ тоже есть абстрактные концепты и отношения, но при описании концептуализации приводятся только непосредственно высказанные смысловые утверждения и концептуальные объекты, поэтому конкретная концептуализация выглядит намного проще.
В качестве одной из практических реализаций теории КГ можно рассматривать UNL – универсальный сетевой язык, созданный и развиваемый в институте развития ООН. UNL предназначен для решения проблемы машинного перевода в Интернет — планируется, что для каждого из существующих естественных языков будет создан транслятор в UNL и генератор из текста UNL в каждый ЕЯ, что позволит людям свободно общаться в Интернет, не зависимо от используемого языка. Несмотря на понятную и четкую концепцию, изложенную в соответствующих стандартах, язык UNL все еще развит не в такой мере, чтобы обеспечить решение проблемы машинного перевода.
Работа по созданию семантического процессора CONST, которая ведется в НПФ «Семантикс Рисеч» (г. Казань) позволит снять проблему машинного понимания естественного языка, предоставив программистам удобные инструменты для создания интеллектуальных приложений на основе механизмов решения всех основных типов задач, требующих машинного понимания ЕЯ — машинный перевод, базы знаний, естественно-языковый диалог с машиной, общение с роботом и т.п.
Язык CONST является одним из вариантов реализации теории КГ и предназначен для построения всех типов интеллектуальных систем, связанных с пониманием ЕЯ-текстов и ЕЯ-диалогом. Структура семантического процессора аналогична системе MARGIE, но предназначена для коммерческого использования.
Литература
1. Шенк Р. Обработка концептуальной информации, М.: Энергия, 1980, — 360с.
2. Sowa John F. Conceptual Structures: Information Processing in Mind and Machine, Addison-Wesley, Reading, Ma.
3. www.undlfoundation.org
4. Н. Ихсанов. CONST – инструмент создания прикладных интеллектуальных систем, Эвристические алгоритмы и распределённые вычисления, Самара, 2015, т.2. №2, с.69–78
Комментарии (41)

Infanty
20.11.2015 14:09Книгу читал, но на практике не всё так просто как на бумаге. При разборе предложения возникает проблема с тем, что часть понятий не знакомы. При исследовании таких понятий из словаря возникает циклическое исследованные новых найденных терминов. В таком варианте на выходе получается огромный массив информации на основе которых нужно например сформулировать ответ на вопрос. Люди при ответе на вопрос учитывают меру достаточности знаний об отмечаемом объекте (просто проанализировав взглядом спрашивающего, например — это студент ему скорее всего интересно вот это...), а машина этого не умеет пока. Её ответы будут либо слишком общими или она 20 раз переспросит то ли она имеет ввиду. Конечно это можно обойти анализатором спрашивающего и анализом какой приблизительно ответ ожидает спрашивающий, а после давать ответ на основе текста. Но в таком варианте сложность программы вырастает в разы и начинается сложные зависимости алгоритмов, т.е. шансов что это будет работать правильно будет довольно мало в определённых областях.

N_Ikhsanov
21.11.2015 08:53Для работы такой системы необходимо наличие базы знаний из соответствующей прикладной области приложения. Пока речь идет о проблемно-ориентированных прикладных системах со своим словарем и своей системой понятий и знаний.
Если же делать систему универсального интеллекта, база знаний будет побольше — хотя бы объем знаний выпускника средней школы.


excoder
21.11.2015 00:55А вы, как человек, так и рассуждаете? Проект компьютера пятого поколения с пролог-машинами и общей декларативной семантикой провалился ещё в начале девяностых. Некоторые громкие старты того времени, типа en.wikipedia.org/wiki/Cyc, доживают свои дни. Почитайте хабр по тегам NLP, машинное обучение, нейронные сети, word2vec, узнаете много нового. Я всё же счастлив, что в битве упорства (опишем логику мышления миллионом ручных правил и словарей) против таланта (создадим нейромодельку, автоматически выводящую нетривиальные признаки, и обучим её на числодробилках) сегодня с гигантским отрывом побеждает талант.
N_Ikhsanov
21.11.2015 09:11Проект пятого поколения потому и провалился, что не имел научного обоснования — модель искусственного интеллекта не была формализована. «Если не знаешь куда идешь — попадешь в никуда».
По вопросам NLP надо читать публикации ученых. Здесь же, на Хабре, публикуются в основном, описания различных наработок программистов, имеющих достаточно узкую направленность.
В ситуации с развитием исследований и разработок в области ИИ есть несколько интересных моментов.
Во первых, разрыв между наукой и программистами. Программисты не знают о прекрасных результатах по формальному моделированию в мировой компьютерной лингвистике, а ученые не могут и не стремятся построить практически полезные системы.
Пол Аллен так и решил — «хватит исследовать — надо делать» и открыл Институт искусственного интеллекта своего имени.
А насчет нейромоделирования — это один из многих компромиссных подходов, когда приспосабливают то что есть (алгоритмы) вместо построения новой теории.excoder
21.11.2015 17:00У меня сложилось впечатление. что программист и учёный в вашей трактовке – это исключающие понятия. К счастью, в свете современных результатов в машинном обучении и анализе данных, это не так. Используемые сегодня библиотеки и инструменты – результат практического применения более двух веков научного фундамента, восходящего, пожалуй, к методу наименьших квадратов Гаусса. RDF-графы и Semantic Web – это лишь небольшая часть современной картины. Ситуация со структурным подходом в лингвистике сродни ситуации с функциональными языками программирования. Чистые функциональные языки с трудом находят применение сегодня, т.к. требуют недюжинной математической подготовки и излишне пресыщены терминологией, типа теории типов, монад и пр. Однако реализации идей функционального программирования в императивных языках чрезвычайно плодотворны. И вот уже все наши монады, лямбда-исчисление и прочие прекрасные вещи идут в Java, C# и C++ из коробки. Также и в NLP: пуристский, структурно-формальный подход непродуктивен, т.к. человеческий мозг просто неспособен поддерживать и порождать требуемое количество правил. В каком-то роде это как программирование текстового процессора уровня MS Word на ассемблере или в байт-кодах руками.
N_Ikhsanov
21.11.2015 23:07Вы затрагиваете очень интересные и актуальные вопросы о противостоянии алгоритмической и других парадигм программирования (функциональной, логической, объектно-ориентированной и др), ответ на которые постараюсь дать в отдельной публикации. Эти парадигмы должны дополнять друг друга, для каждой есть своя область применения.
Мне кажется, что Ваша аргументация основана на убеждении первостепенности алгоритмического подхода. Есть ученые, которые считают, что постепенно алгоритмическая парадигма отойдет на второй план, после того как будет решена проблема автоматического программирования. Тогда основным занятием программистов будет создание интеллектуальных систем.
lair
21.11.2015 23:37о противостоянии алгоритмической и других парадигм программирования (функциональной, логической, объектно-ориентированной и др),
А почему вы вообще противопоставляете алгоритмическую и объектно-ориентированную модель программирования?N_Ikhsanov
22.11.2015 01:42Потому что это не одно и то же — разные парадигмы (под термином «парадигма», здесь понимается система базовых понятий теории и связей между ними).
MichaelBorisov
21.11.2015 01:31Работа по созданию семантического процессора CONST, которая ведется в НПФ «Семантикс Рисеч» (г. Казань) позволит снять проблему машинного понимания естественного языка, предоставив программистам удобные инструменты…
… но предназначена для коммерческого использования
Вот и весь смысл статьи. «Мы нашли панацею от всех болезней. Платите ваши денежки». Банальная реклама. Как обзорный материал или как описание какого-то конкретного метода работы с естественным языком статья не годится.N_Ikhsanov
21.11.2015 09:16Цель статьи — дать начальное представление и малоизвестном в широких кругах программистов подходе, основанном на точном моделировании интеллекта.
Кто хочет подробностей — читайте мою диссертацию и другие научные работы.
Мы как раз и не говорим, что мы открыли этот подход — показываем основополагающие работы.
Наша роль — построить и реализовать систему, пригодную для широкого применения.
qw1
22.11.2015 15:40Из статьи непонятно, в чём новизна вашего подхода.
Логический подход к интеллекту пытались применить много раз, тот же Cyc к примеру.
Но если делать всё так же, как у предшественников, то и результат будет аналогичным.N_Ikhsanov
22.11.2015 20:26Это не логический подход, обычно его называют «онтологическая семантика текста». Новизна в том, что есть единый язык на основе концептуальных графов для представления семантики текста и для представления знаний. Текст на естественном языке транслируется в концептуальные графы и далее может обрабатываться на основе логического вывода.
qw1
22.11.2015 21:12Примеры описаний на CONST, например отсюда, отражают актуальное состояние языка? Если так, то большая часть модели (той же задачи о трубах и бассейне) находится в голове программиста, а не описана языком.
N_Ikhsanov
23.11.2015 09:54Да — это моя публикация, правда без моего согласия напечатано.
В нашем подходе концептуальная модель задачи создается автоматически, на основе базы знаний — модели предметной области. Это называется семантическая трансляция. Разработчик интеллектуальной системы должен создать базу знаний, например об основных арифметических соотношениях, характерных для тех предметных областей, которые применяются в школьных задачах. Дальше включается машинный интеллект.qw1
23.11.2015 13:57Движок логического вывода чей? Обычно вывод захлёбывается в экспоненциальном росте сложности уже на простых теоремах, которые можно вывести из аксиоматики арифметики.
N_Ikhsanov
23.11.2015 14:19Движок на основе модифицированного Пролога — есть защита от зацикливания.
Если навалить сотни простых правил, то да — вывод замедляется до полной потери работоспособности.
Если же точно описать семантику — объем вывода (пространство поиска) резко уменьшается — так же, как это делает человек.
grossws
25.11.2015 11:21Спасибо, посмеялся. Сотни правил даже выделения, скажем, фактов купли-продажи маловато. Для описания чего-то нетривиального — безумно мало.
elingur
23.11.2015 08:59Да, странная статья. Несколько удивительно, что ни слова не сказано про Н.Хомского или И.Мельчука. Идея не нова, но я не разу не видел хорошего рабочего решения. Онотолгию «всего и вся» пока не представляется возможным реализовать. Во всяком случае, связи в ней должны быть устроены совсем иначе, чем принято думать. А пока что онтологии относительно хорошо работают только в узконаправленных областях.
— концептуальная память – манипулирование концептуальными структурами, соответствующее «человеческим» мыслительным операциям;
— а что вы понимаете под человеческими мыслительными операциями? Если логику, то боюсь вас разочаровать, это так лишь отчасти. На сколько мне известно, пока человеческий мозг — черный ящик.N_Ikhsanov
23.11.2015 10:07Что значит странная? Это новый материал, новые идеи, продолжающие и развивающие теории различных авторов, в том числе, Мельчука и Хомского.
И не так уж мы оригинальны, публикаций на английском языке достаточно, просто семантический подход в нашей стране мало известен.
Наша роль как раз в том, чтобы связать два мира — computer science и computer programming. Ученые не особо интересуются приложениями, а программисты не имею хорошего инструмента. Вот мы и хотим его им дать.
А насчет работы человеческого мозга мое мнение такое — есть логический уровень и физический, как в любой информационной системе. Технология экспертных систем дает необходимую основу для представления этого логического уровня.
grossws
25.11.2015 11:32А пока что онтологии относительно хорошо работают только в узконаправленных областях.
И то, стоимость разработки и поддержки остаётся довольно высокой. Так что, если задача позволяет (хотя бы частично), unsupervised learning — наше всё.N_Ikhsanov
25.11.2015 21:14Это называется «холивар»? Когда ведется аргументация на основе веры,
когда программисту кажется, что он все знает, потому что умеет писать сложные программы.
Думаю нет смысла продолжать это обсуждение.grossws
26.11.2015 01:36Я не видел смысла и начинать обсуждение с вами, как можно было заметить. Продолжать — тем более.
elingur
24.11.2015 09:32просто семантический подход в нашей стране мало известен.
Ну я бы сказал, это некомпетентное высказывание. Как раз в нашей стране этот подход наиболее развит. Мельчук, Апресян, Кибрик, Жолковский, Мартемьянов и десятки других ведущих специалистов, которые не только разрабатывали теорию, но и создавали реальные рабочие системы.N_Ikhsanov
25.11.2015 06:03Согласен с Вами, в нашей стране было много замечательных, пионерских работ выдающихся лингвистов. Только у них мало продолжателей и нет практических результатов. Есть замечательные работы группы Апресяна по машинному переводу в ИППИ, но они длятся уже более 30 лет и не внедряются в практику. Есть выдающиеся лингвисты Раскин и Ниренбург, работающие в США, авторы «Онтологической семантики». Однако и в США, как видно по неоднократным выступлениям В. Раскина превалирует упор на статистические, приближенные методы машинного понимания.

Cybersoph
24.11.2015 13:34Уважаемый Наиль Ихсанов!
Язык машины => двоично-логический; Мышление машины => импликативное (на базе одного условного оператора: «Если так, то этак, иначе энтак»)
Язык человека => множественно-знаниевый; Мышление человека => октадифное (восьмилогическое — на базе ВОСЬМИ операторов).
Стоит задача ТРАНСЛЯЦИИ, либо трансляция октадифной логики в двоичную, либо ЭМУЛЯЦИЯ октадифной логики на базе двоичной.
Для решения данной задачи нужно понимать, что это за операторы и как ими, извините за тавтологию, оперировать.
Для понимания этого надо, извините, понимать, что такое Октадифная Мысль и что такое Октадифный Смысл.
Наконец, необходимо определиться с понятием ЗНАНИЕ, поскольку человек использует знаниевую технологию мышления.
Всё остальное является не более чем ухищрениями, поскольку ни лингвистика, ни статистика, ни стохастика или даже двоичная логика ни сами по себе, ни все вместе не способны решить задачу СМЫСЛОВОГО ПОНИМАНИЯ текста (речи), вследствие того, что эти инструменты не предназначены для формализации мыслеформ человека.
Все разработки на основе таких инструментов могут оперировать только с Базами Данных, а человек способен справиться одновременно и с Базой Данных, например, таблица умножения, и с Базой Знаний.
Для машины пока ещё никто в мире не придумал формат машинного хранения Знаний, поскольку не могут определиться с самой формулировкой этой дефиниции. Когда научатся понимать, что есть Знание, тогда будет открыта дорога и к Знаниевой технологии, с помощью которой только и можно решить обозначенную задачу.
N_Ikhsanov
25.11.2015 06:15Это Ваше учение, и Вы имеете полное право его развивать и пропагандировать.
Наша идея состоит в том, что на сегодняшний день нет никаких препятствий для создания систем машинного понимания естественно-языковых текстов в различных прикладных областях, поскольку все необходимые средства в области компьютерной лингвистики и искусственного интеллекта для этого созданы учеными в последние годы.
Мы не ставим вопрос о создании полноценной искусственной личности, но для создания прикладных интеллектуальных систем препятствий нет.
В качестве примера можно назвать такие задачи, как машинный перевод, автоматическое программирование, диалог с машиной на естественном языке.qw1
25.11.2015 08:32О каком понимании идёт речь, если что у вас, что у ABBY, модель предметной области тщательно описывает специально обученный онтоинженер. Нет модели — нет понимания, нет решения задач. Есть модель — решается строго тот класс задач, который предусматривает модель.
N_Ikhsanov
25.11.2015 21:20Речь идет о понимании конкретной задачи интеллектуальной системой (ИС). Есть текст задачи на естественном языке, например, ТЗ на программирование.
ИС должна его понять, провести в диалоге работу с пользователем по устранению противоречий и неполноты документа, после чего выдать текст работающей программы с возможностью диалога с пользователем по структуре и тексту созданной программы, а также по всем техническим моментам по запуску и тестированию программы.lair
25.11.2015 21:53И вы туда же?
С этой задачей человек не справляется, а вы предлагаете ее поручить ИС.
(Я не говорю, что это невозможно, но чтобы это стало возможно, необходимо, чтобы разработка ПО стала формализуемой задачей)
Cybersoph
25.11.2015 09:35Уважаемый Наиль Исханов!
Вы пишите: "… все необходимые средства в области компьютерной лингвистики и искусственного интеллекта для этого созданы учеными в последние годы".
Не могли бы Вы привести примеры этих «необходимых средств»?
Также очень интересно, какие именно препятствия сегодня устранены "… для создания систем машинного понимания естественно-языковых текстов"?
N_Ikhsanov
25.11.2015 21:23Дискуссию считаю завершенной. Все основные вопросы обсуждены, а дополнительные рассуждения можно продолжать бесконечно.
Cybersoph
25.11.2015 21:47Спасибо за откровенность, уважаемый Наиль Ихсанов. Баллон, как и прежде, оказался пустым.

retran
26.11.2015 19:09Распарсить предложение по грамматике и наложить его на заранее готовую модель — это не «понять» предложение. И, собственно, парсер — тут самое простое.
ServPonomarev
То есть, решением всех проблем с пониманием естественного языка будет книжка 80-го года? Неужели с тех пор ничего лучше так и не придумали?
Фреймы Минковского появились тоже в те времена, но на них по крайней мере делали системы — можно оценить результаты.
N_Ikhsanov
Работа 80-х годов Шенка года заложила основу, подход к точному моделированию машинного понимания отечественного языка и приведена для лучшего понимания идеи точного моделирования интеллекта.
С тех пор много усовершенствовалось с дрейфом в сторону формальной логики. Есть много зарубежных исследований и разработок с достаточно подробным описанием формальной модели естественного языка.
Наиболее практически ориентированная разработка ведется в Институте искусственного интеллекта, который финансирует сооснователь Микрософт Пол Аллен.
Фреймы Минского были первым и основополагающим шагом на пути моделирования мышления. Основная идея применения знаний — решение проблемы комбинаторного взрыва.