
При построении прикладных систем, работающих с текстами, первая же задача — это отождествление слов друг с другом. Для большинства языков индо-европейской группы её решение не представляет большой сложности. И решений этих существуют сотни, а самые простые из них, как правило, дают вполне пригодные (в рамках решаемой задачи) результаты.
Английский, с его весьма условным делением на части речи и практически отсутствующим склонением/спряжением, вполне прилично описывается простыми моделями выделения неизменяемой основы слова (стеммерами) с небольшим словариком исключений буквально на сотню слов. Слова немецкого прекрасно бьются на части по формальным признакам, словарю корней и принципу «максимума суммы квадратов длин». Системы окончаний других европейских языков также достаточно просты.
Со славянскими языками сложнее из-за развитой грамматики и глубокой изменчивости — любое русское прилагательное, к примеру, имеет как минимум двадцать четыре разных грамматических формы: три рода и множественное число, да по шесть оставшихся на сегодня падежей. А то и все двадцать девять, если принять во внимание краткие формы (широк, широка, широки) и образуемое от многих прилагательных наречие.
Для решения задачи отождествления разных форм существует некоторое количество реализаций морфологических анализаторов русского. Но почти все они — во всяком случае, заслуживающие внимания — растут из одного корня...
(По материалам внутреннего семинара компании МойОфис)
Привет, Хабр! Я Андрей Коваленко (Keva), в МойОфис возглавляю группу прикладной лингвистики и поисковых решений. Мы создаем корпоративную поисковую систему, извлекаем информацию, обобщаем, конкретизируем, анализируем и синтезируем тексты.
Но сегодня хочу поговорить не про сам поиск, а про его, без преувеличения, самый важный компонент — морфологический анализатор. Их существует много, реализованных на разных языках, в разные годы и разными авторами. Даже промышленного качества их как минимум штук пять, с теми или иными достоинствами, в зависимости от задачи, для которой разрабатывались.
В общем случае морфологический анализатор умеет:
отождествлять разные грамматические формы слов с некоторой лексической единицей, то есть сводить воедино причастие <вобравшими> и личную форму глагола <вберём> (вобрать) — этого достаточно для простейшего поиска на обратном индексе;
сообщать грамматические характеристики, часто множественные, той формы слова, что подали ему на анализ;
синтезировать нужную форму слова по лексеме и грамматической характеристике.
Промышленные анализаторы ещё и умеют делать это на минимальных вычислительных ресурсах и с приличной производительностью — сотни тысяч слов в секунду здесь оказываются нижней границей приемлемости.
Но все существующие анализаторы объединяет одно: источник данных, он же — корень, из которого они выросли. И это — Великий Словарь Зализняка.

В начале 70-х годов прошлого столетия — я тогда только родился, большинства читателей этого текста не было на свете, до появления «персоналок» было ещё лет двадцать, Томпсон и Ритчи только-только разработали ОС Unix и язык C, а «мейнфреймы» — большие вычислительные машины — стояли в машинных залах. Доступ к ним был через администратора, не для всех. А способом общения были колоды перфокарт, листинги трансляции и распечатанные рулоны выдачи.
И вот тогда Андрей Анатольевич Зализняк, выдающийся русский лингвист и признанный гений столетия, человек, выучивший за две недели венгерский просто для выступления на конференции, придумал и реализовал с помощью и участием своих студентов подход, позволивший формализовать всю изменчивость слов русского языка и отнести все слова к детально описанным классам словоизменения. Все четыре с лишним миллиона словоформ на тот момент он свёл к ста тысячам строчек словаря.
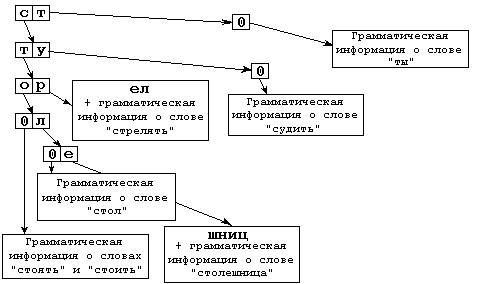
Суть метода состоит в том, что слова были упорядочены в обратном лексикографическом порядке — то есть с прочтением не слева направо, а справа налево. Вот так:

В результате слова, заканчивающиеся одинаково, оказались рядом и образовали, за редким исключением, гнёзда или, как сейчас принято говорить, кластеры слов, склоняющихся/спрягающихся одинаково. Действительно, если сравнить наборы форм двух ближайших соседей, мы обнаружим совершенно явное сходство:
ед |
мн |
||
|
посредник собеседник |
И |
- |
-и |
Р |
-а |
-ов |
|
Д |
-у |
-ам |
|
В |
-а |
-ов |
|
Т |
-ом |
-ами |
|
П |
-e |
-ах |
После каждого слова следует словарная статья со следующими обозначениями:

Для их понимания обратимся к первому разделу словаря — «Грамматическим сведениям». Здесь <м> — «неодушевлённое существительное мужского рода», <1> — первый из семи, по классификации словаря, тип субстантивного склонения, а «a» — схема ударения: оно всегда падает на основу слова.
Всего рассматривается для существительных шесть схем ударения — на основу (a), на окончание (b) и четыре схемы плавающего, когда в одних формах оно падает на основу, а в других — на окончание. Например, у слова <час м 1c> в единственном числе ударение падает всегда на основу (ча́с, ча́са, ча́су, ча́сом, о ча́се), а во множественном — на окончание (часы́, часо́в, часа́м, часа́ми, о часа́х). Схема ударения также влияет на правописание форм слова.
Понятно, что подробные грамматические сведения, приписанные каждому из слов, позволяют сформировать наборы таблиц окончаний и склонять/спрягать, равно как и отождествлять формы с лексемой, где лексемой мы называем собственно строку словаря.
Иногда в индексах также встречаются пометы. Рассматривать их все мы не будем — для интересующихся они подробно описаны в «Грамматических сведениях». Остановимся подробнее только на <*>. Она означает, что в основе слова происходит чередование или присутствует беглая гласная. Например, слова <пиксел м 1a> и <вымысел м 1a> имеют одинаковые наборы окончаний, однако у второго из них в косвенных формах гласная <е> в графической основе слова исчезает (пиксел — пиксела, вымысел — вымысла).
Морфологические анализаторы
Первые были сделаны ещё на мейнфреймах. Например, в «ИнформЭлектро» этим занималась группа Пархоменко (Травкина, Назарова, Лахути).
Много сил тратилось даже не на описание модели словоизменения, а на технологическую обвязку, позволяющую работать с достаточно объёмным по тем временам словарём в ограниченной оперативной памяти. Налёт компактности был и на самих моделях — например, для слов с чередованием в графической основе генерировалось несколько основ формальных, а к таблицам окончаний применялись разрешающие (или запрещающие) битовые маски, «включая» только допустимые для такой основы окончания. Это позволяло работать быстрее при анализе, притормаживало при синтезе, однако давало возможность сегментировать словарь на куски допустимого размера.
Видимо, первым коммерческим продуктом нарождающейся эпохи частного предпринимательства, построенным на модели Зализняка, был ОРФО Игоря Ашманова (@Ashmanov) — работавший ещё под DOS орфографический корректор, висевший в памяти резидентно и позволявший интегрироваться с популярными текстовыми процессорами, в том числе Microsoft Word. Модель словоизменения использовалась подобная описанной выше, но изюминками были сильно пополненный современной лексикой словарь — он и по сей день остаётся наиболее вычитанным при хорошей полноте и продолжает использоваться, но уже в Microsoft Word и иных продуктах, — и линкер Саши Михайлова. Дело в том, что на всё про всё на персоналках того времени было 640К памяти, и резидентная программа могла занимать только небольшой её кусочек, оставляя остальное для пользовательских приложений. Вот в этот-то кусочек и загружались попеременно разные сегменты кода системы и фрагменты морфологического словаря!
Были и другие системы контроля орфографии: Presto!, так и оставшийся под DOS; интегрированный с «Лексиконом» «Ортодок» (надеюсь, я правильно написал его название).
Свой libmorph/rus я тоже изначально сделал как систему контроля орфографии. Тогда я работал в фирме Агама, и мы обошли всех на повороте, выпустив «Пропись», первый русский спелл-чекер для Windows, интегрировавшийся со многими популярными офисными приложениями того времени. Но в голове уже бродили мысли о поисковых системах, а доступных ресурсов стало заметно больше. Так что я заложил в архитектуру модуля всю доступную грамматическую информацию и перенумеровал лексемы, что оказалось очень удачной идеей: при индексировании можно было запоминать не строку, а её номер, число. Например, «ягодица» раз и навсегда получила номер 71997 :)
В версии для Win16, получившей название linguist.dll, словарь был разбит на страницы, представленные ресурсами Windows, и это был самый быстрый на тот момент морфологический анализатор. Более поздняя версия, уже тридцатидвухбитная, ling32bi.dll, использовала словарь-монолит и стала, в силу организации словаря в виде базисного дерева, ещё быстрее, показывая на 386-х машинах вплоть до тридцати тысяч слов в секунду в режиме лемматизации. Дальнейшее развитие было лишь в сторону пополнения словаря и оптимизации работы с ним, так что ко временам Рамблера — я туда пришёл в 2000 году — уже был libmorphrus со своей скорострельностью в сотню тысяч в секунду и выше, перечислением лексем, алгоритмами приложения шаблонов (*, ?) и выборками по ним. Собственно, таким он и остаётся сегодня, разве что я периодически подбрасываю туда сотню-другую новых лексем, да сделал вероятностный анализатор для неизвестных слов. Скоро опубликую там же, как чуток свободного времени появится — у меня сейчас очень важный проект по имени Мичко Андреевич в работе :)
Примерно тогда же, когда я взялся строить поисковик Апорт!, блистательный Илья Сегалович уже выпустил «Цифровую Библию», а спустя пару лет вместе с Аркадием Воложем и Еленой Колмановской запустил Яndex. Интересно, что для организации двоичного словаря там использовался диаметрально противоположный подход: вместо сопоставления слова со словарём слева направо, с максимальным усечением возможных гипотез и проверками только отдельных таблиц окончаний, слова проверялись справа налево, отщеплялись окончания, после чего гипотеза об основе слова выбрасывалась в разреженную хэш-таблицу.
Ещё про Зализняка
Татьяна Михайловна Николаева, доктор филологических наук и однокурсница Андрея Анатольевича, вспоминала, как он в самолёте открыл учебник венгерского языка, через пару дней уже освоил на бытовом уровне, а к концу поездки, в Будапеште, уже без проблем общался с коллегами.
Заинтересовавшись санскритом, считавшимся большим набором древних исключений, Зализняк формализовал и его, обнаружив и описав строгие закономерности словоизменения и там.
Но сам придавал наибольшее значение другой своей работе и увлечению одновременно — поиску, расшифровке и переводу берестяных грамот, найденных на археологических раскопках в Новгородской губернии.
Заключительное слово
На этом можно было бы и завершить, но хочется рассказать ещё об одной книге, где концентрация и качество подаваемого материала настолько высоки, что это точно круче даже двухтомника Фихтенгольца по матанализу. Но только в другой предметной области. Существуют такие выдающиеся методические пособия, что любые попытки их «исправить и улучшить» приводят только к заметной порче материала.
Кто заканчивал естественно-научные факультеты Московского Университета, наверняка помнят выпущенную Издательством Физфака и отпечатанную на ротапринте тоненькую методичку на желтоватой бумаге — «Механика и электричество» Склянкина и Муриной, где были изложены все темы двухлетнего курса физики настолько доходчиво, что книжку доставали через знакомых студенты других учебных заведений, и настолько компактно, что она умещалась чуть согнутой во внутреннем кармане куртки.
Подобный учебник есть и по русскому языку. Того же формата и толщины, но только в жёсткой обложке. Это книга Дитмара Эльяшевича Розенталя «Русский язык. Орфография и пунктуация». Исчерпывающий материал, компактно изложенный и по прочтении автоматически снижающий количество ошибок в текстах в разы. А при вдумчивом — делающий пишущего человека практически абсолютно грамотным, с точностью до очепяток.

Учебник регулярно переиздаётся, его можно заказать в любом книжном, в том числе и с доставкой. Электронные версии также есть, однако почему-то не столь доходчивые. Рекомендую.
Комментарии (34)

inkelyad
21.07.2023 09:49+3(глядя на лежащие рядом новости про ruGPT).
А сейчас кто-нибудь занимается работой вида 'распотрошить внутренности обученной нейросетки и из того, что она 'поняла' создать наиболее компактный набор правил, по которым русский язык на самом деле работает?'
Или это совершенно бесперспективно и неинтересно?

bb0ff
21.07.2023 09:49Бесперспективно и неинтересно, оно выдаст максимум ошибок как основное правило. То самое "не подскажети".
Э

Keva Автор
21.07.2023 09:49Если говорить про GPT, то есть многослойные сетки, то задача "распотрошить" вообще не представляется реальной. Проще - на порядки - другую сетку сделать и обучить.




18741878
21.07.2023 09:49+16У меня есть старая книга (1967) А.А. Зализняка "Русское именное словоизменение". Купил достаточно случайно у букиниста за какие-то смешные деньги. Я не лингвист и объяснить, почему я не отложил ее в сторону, а оставил - не могу. Какое-то десятое чувство сработало. Книга - шедевр. Это академическое издание, без скидок на неподготовленность читателя, с массой специальных терминов. Но при известном усилии вполне можно следить за логикой изложения. Там даже есть теоремы (да-да, самые настоящие теоремы), доказываемые методами теории множеств и ссылки на работы А.А. Маркова по теории алгорифмов.
Периодически открываю то там, то сям и с удовольствием погружаюсь в исследование.
Кстати, книга ценна еще и тем, что в ней предыдущим владельцем была оставлена небольшая открытка с видом города Вязники и автографом А.А. Зализняка (содержание совершенно бытовое, не имеющее отношения к лингвистике). Видимо, потомки бывшего владельца понятия не имели, какая ценность внутри. Ну, мне же лучшеKeva Автор
21.07.2023 09:49+1Завидую. Реальная ценность!
У меня есть только издание Словаря конца семидесятых.


PereslavlFoto
21.07.2023 09:49Электронные версии также есть, однако почему-то не столь доходчивые.
У бесплатных электронных версий другое, более важное достоинство: они доступны людям.
Но ещё доступнее свободные программы для проверки орфографии, например, GNU aspell.


victor_1212
21.07.2023 09:49+4>Заинтересовавшись санскритом, считавшимся большим набором древних исключений, Зализняк формализовал и его, обнаружив и описав строгие закономерности словоизменения и там.
Андрей Анатольевич Зализняк сделал столько много полезного, что заслуживает особого отношения, это относится также к точности в описании и цитировании, приведенная автором ссылка на "ГРАММАТИЧЕСКИЙ ОЧЕРК САНСКРИТА", это супер грамотное и хорошо написанное Зализняком краткое введение в грамматику санскрита, первоначально опубликовано как приложение к санскритско-русскому словарю В. А. Кочергиной, в части формализации - обычно считается что классический санскрит был формализован Panini примерно в 6 веке до нашей эры в его работе Astadhyayi, это примерно 4000 правил, уровень формализации превосходит описание грамматики большинства современных живых языков, и вероятно сравним с формализацией языков прграммирования, поэтому BNF (Backus Normal Form) иногда называют Panini-Backus Form, обсуждение можно посмотреть например -
https://news.ycombinator.com/item?id=14293048

cat_chi
21.07.2023 09:49+5Увидеть эту фамилию в заголовке статьи на Хабре – просто невероятно приятный сюрприз. И это в статье, которая и сама по себе была бы весьма неплохой, даже без упоминания Зализняка.
Спасибо!Keva Автор
21.07.2023 09:49+1Спасибо.
Но изначально сам текст был посвящён как раз Зализняку и его Великому Словарю и писался как материалы к семинару для команды МойОфис.
Ну а потом подумал - а почему бы и не опубликовать как статью?

CodeRush
21.07.2023 09:49+1Например, у слова <час м 1c> в единственном числе ударение падает всегда на основу (ча́с, ча́са, ча́су, ча́сом, о ча́се), а во множественном — на окончание (часы́, часо́в, часа́м, часа́ми, о часа́х).
Пишу этот текст на русском языке в четвертом часУ по местному времени.
Keva Автор
21.07.2023 09:49А это "второй предложный падеж", графически совпадающий с дательным. Кажется, "местный": в пятом часу, в дубовом бору́, на особом счету́.
Его особенность в том, что его использование определяется не столько предлогом, сколько смысловыми оттенками фразы.

Aleshonne
21.07.2023 09:49+1Ага, локатив — это весело. Медведь живёт в лесу́, а поэт пишет о ле́се. Есть ещё паритив (разделительный падеж): «Съешь же ещё этих мягких французских булок, да выпей ча́ю»; а также два вида вокатива: почти вышедший из употребления старозвательный: «Господи боже!»; и не совсем ещё пролезший в нормы новозвательный: «Мам, купи машинку!».

veryboringman
21.07.2023 09:49Хочется еще напомнить, что Зализняка заставили уйти из аспирантуры - потому что он подписал открытое письмо министру образования в защиту другого известного лингвиста - Вячеслава Иванова, которого выгнали из МГУ за поддержку Пастернака (в конце 80х эмигрировал).
Видимо надышался воздухом свободы в Сорбоне, где стажировался до этого.
По нынешним меркам - прямо готовый диссидент, хотя сейчас его бы никто в Сорбону не отправил :)
Keva Автор
21.07.2023 09:49+2А может, не в воздухе свободы дело, а в попытке защитить товарища?
veryboringman
21.07.2023 09:49После этого случая он таких безнадежных писем больше не подписывал. Так что ставлю именно на свежее впечателение от посещения свободного мира, в СССР ему быстро объяснили, что партия лучше знает, как надо :)

{kind=link}

vadimk91
21.07.2023 09:49+1Андроидная клавиатура SwiftKey, которая сейчас от Microsoft, похоже была создана для индоевропейских языков, потом туда подгрузили словарь русского, а анализ остался тот же. В результате этот убогий ИИ постоянно пытается оторвать окончание у незнакомых ему слов, без спроса заменяя слова. Я все надеялся, что в процессе обучения он "поумнеет", но нет, новый версии гордятся добавлением эмодзи и т.п. Есть ли в природе нормальная клавиатура под Андроид, которая работает по принципам, описанным в этой статье?
Keva Автор
21.07.2023 09:49+1Вы про Microsoft SwiftKey?
Я пользуюсь на своём китайфоне клавиатурой Google в режиме swipe - вполне приличные слова вводит, сквернословит редко. Разве что слово "заеду" иногда шаловливо подменяет на другое, которое я написал-то всего однажды - обучилась, вредина.

Dimsml
21.07.2023 09:49+2похоже была создана для индоевропейских языков, потом туда подгрузили словарь русского, а анализ остался тот же
Вы не поверите, но русский тоже входит в индоевропейские языки! Я уже даже не помню что туда не входит, вроде как финский / эстонский и изоляты типа баскского. Возможно вы имели в виду германские и романские языки. И то, я не уверен, что романские языки не страдают от автокоррекции.
victor_1212
21.07.2023 09:49+2> Я уже даже не помню что туда не входит, вроде как финский / эстонский и изоляты типа баскского
однако, не забывайте про америку (все местные), + африку, + половина азии, кроме пушту, фарси/дари, и 70% индии (хинди и пр.)
AlexeyK77
Несколько лет назад смотрели на DLP-системы западногопроизводства, топовые из квадрата Гатрнера :)
Что удивило, везде в качестве базового механизма для написания политик предлагался кондовый regex. На вопрос, а что-то более вменяемое с поддержкой морфологии славянских языков разве нет?
Ответ - нет, кушайте регексы, не обляпайтесь, весь мир использует, а вы чем отличаетесь?
Не взяли тогда ничего, интересно, а как сейчас с поддержкой морфологии и базой синонимов - есть ДЛП-продукты?
slonoten
В отечественный DeviceLock году в 2008 лично затаскивал поддержку морфологии для множества европейских языков. Остановился на уэльском, он оказался малоресурсным. В тоже время поисковый запрос "морфология русского языка" приводил на сайт автора этой статьи с неприличной картинкой.
Keva Автор
Там в ротации крутились картинки в udaff.com. Интересно, кстати, как сейчас поживает Дима Соколовский, который Удав?
V-core
Хорошо живёт, иногда в мордокниге бывает. Alterlit - основной его сайт.
Keva Автор
Системы от infowatch работают с учётом морфологии русского языка.