В программировании нет вообще никаких непреложных истин. Даже самые очевидные правила могут иметь контекст, в которых их применять нельзя. К сожалению в 99% организаций есть прям заповеди, обязательные к исполнению. И есть правила, которые считаются правилами хорошего тона (как не сморкаться в занавеску). Однако всегда бывают ситуации, когда лучше все-таки сморкаться.
Вот примеры.
1) Например, DRY — don’t repeat yourself. Хорошее полезное правило, но его можно довести до маразма. Из того что я встречал на практике: есть два разных по бизнес-смыслу раздела, которые начинались с простого CRUD, и многие части (и фронта и бека) выглядели во многом абсолютно одинаково. Если их объединить с помощью общей высосанной из пальца абстракции и тем самым избавиться от небольшого дублирования кода, то потом (очень скоро) можно будет сойти с ума, потому что эти две вещи скоро разъедутся, обрастая кастомными фичами, и абстракция будет только вредить. Нельзя абстрагировать неабстрагуемое, даже если DRY нарушен.
«[Немного] дублирования обходится гораздо дешевле, чем неправильная абстракция» — Сэнди Мец
Т.е. DRY — хороший принцип, но бывают исключения.
2) KISS.
Keep it simple, stupid. Всем хотелось бы держать программу простой, но иногда приходится всё усложнить, чтобы добиться ускорения разработки, уменьшения количества ошибок и т.д. Например, KISS может войти в прямое противоречие с тем же DRY: код с дублированием зачастую проще понимать (меньше абстракций и зависимостей), зато это огромное поле для ошибок (забыл поправить в третьем файле) и замедление добавления новых фич.
3) В фунции не должно быть более чем X строк, длина строки должна быть не более чем Y и т.д. (правила линтера).
Обычно этот X придумывается от балды. В таких случаях хочется спросить, почему именно столько, а не на одну больше или на две меньше. И обычно время от времени появляется вполне валидный код, который по каким-то причинам не влезает, и люди извращаются как могут, переписывают через дичь, чтобы как-то пайплайн протащить.
4) Мы пишем только на таком-то языке.
И начинаются пляски с бубном вокруг PHP, на котором пытаются завести highload-решения. Это выливается в интереснейшие инженерные задачи, как из говна и палок сделать самолёт. Бесконечные темы для докладов на конференциях.
И тысячи таких.
У каждого программиста между ушей есть нейросеть, которой он пользуется. Нельзя рассматривать его как бездумного робота.
Если кто-то тупой и постоянно творит дичь, то может его надо просто уволить? Зачем вам такой сотрудник? Если это опытный программист, и в большинстве случаев поступает разумно, то может и не надо его ограничивать всякой фигнёй — это уменьшение эффективности, да еще и снижение мотивации
Мы так делали всегда, because f*** you
Я писал об этом в одном телеграм-канале, но упомяну еще раз.
Что если я скажу вам, что код ревью делать необязательно? Ручное тестирование замедляет процессы? Скрам только вредит? Ваш язык не подходит для ваших задач? Покрытие тестами замерять вредно?
Наверняка вас триггернуло хотя бы одно из этих высказываний (например: как это без код ревью, да там же говнокод польётся рекой! У всех нормальных команд оно есть!)
Тогда у меня встречный вопрос: а как принималось решение о введении этого в процессы команды? За всех говорить не буду, но держу пари, что во многих случаях примерно так: в прошлом проекте мы так делали, а когда формировали новую команду, то тоже решили так делать.
Проблема в том, что в прошлой команде процесс принятия решения был точно такой же. И вот мы видим, что код ревью есть везде и у всех, и теперь этот подход — непреложная истина. Съехать с него почти невозможно.
Или взять хотя бы скрам — он перетекает из организации в организацию как вирус, при том, что его ценность во многих случаях сомнительна. Самое смешное, что чаще всего скрам внедряется вообще без особого обсуждения, несмотря на то, что это очень серьёзно влияет вообще на всё. Просто все так делают, и мы будем. У кого-то на прошлом проекте был скрам, теперь и у нас будет. Даже если не решает никаких проблем.
И это удивительно, ведь айтишники любят говорить (особенно в твиттере), какие они избранные интеллектуалы, но в ключевых вопросах зачастую просто следуют “за стадом”, на ходу рационализируя выбор при малейших робких сомнениях.
Лирическое отступление по поводу код ревью, потому что наверняка будут вопросы. Как и любой инструмент, код ревью может быть как на пользу, так и во вред. В проекте, где затрагивается человеческая жизнь (медицинские приборы, автопилоты автомобилей) или есть вопросы безопасности — код ревью наверно необходим. Однако в несложном продуктовом коде делать обязательный апрув, т.е. блокер, на каждой задаче — это серьёзное ухудшение пресловутого time-to-market, и возможно в команде сработавшихся профессионалов эта обязательность будет только мешать: достаточно иногда смотреть старые комиты для контроля качества кода и заранее проговаривать словами особо сложные технические решения, но не блокировать всё подряд. Другими словами, нужность код ревью зависит от проекта и задачи, но не является абсолютной истиной.
В какой момент многократно повторенная мысль становится базовой истиной, от которой потом невозможно отойти? Думаю, что всё просто. Это банальная лень, экономия энергии. Пресловутые система 1 и система 2. Подумайте, сколько всего надо, чтобы перестроиться со скрама на что-нибудь другое: все привыкли к сторипоинтам, покеру и фибоначчи, знают свою роль, в jira уже всё настроено, в календаре забиты все нужные ретро и спринт-ревью. А для преобразований надо убедить каждого члена команды и руководство. Дохлый номер. То, что делают все, то истина, и так останется навсегда. Потому что система сейчас устойчива (даже если не очень эффективна), и переход к другому устойчивому состоянию требует огромной энергии.
Вывод
Cоветую хотя бы иногда пересматривать вообще всё. Любые процессы и технологии, особенно те, которые раздражают, должны регулярно подвергаться сомнению.
Комментарии (291)


vagon333
25.07.2023 05:29+64Что если я скажу вам, что код ревью делать необязательно?
Со многим согласен, особенно х-строк кода в классе, или скрамомания, но code review не соглашусь.
Я столько раз допускал ляпы, чтоб без дружеского просмотра мог легко выкатить трудно-отлавливаемые баги.
Да, и полезно во время review услышать иное мнение, или прийти к выводу что твое решение вполне себе надежное ...
Вобщем, говнокодом давно не страдаю, но обычные ляпы - легко. И code review мне в помощь.
varanio Автор
25.07.2023 05:29+16Не весь код настолько важен, чтобы блокировать разработку. Например, есть богом забытый раздел сайта, где надо немного поправить текст. Риски небольшие, зачем там проверять или перепроверять, отвлекая еще людей.
[Возможно] разработчик сам может принять решение о важности код ревью в его задаче. В любом случае, это предмет для обсуждения, не истина
valery1707
25.07.2023 05:29+10Нормальные сервисы позволяют вливать автоматически при успешной сборке и наличии необходимого количества аппрувов: просто уменьшите требуемое количество аппрувов до нуля и внезапно и ревью всё ещё возможно (пожеланию разработчика - можно пометить PR флагом драфта) и отвлекать никого не нужно и пайплайн сборки при этом общий.

Devakant
25.07.2023 05:29Но ведь код ревью относится только к новым правкам. Старый легаси код ( Богом забытый раздел.. ) относится уже к рефакторингу, решение о проведении которого принимается обычно +- архитектором, но точно не обычным "тимлидом" который проводит код ревью.

at_wrike
25.07.2023 05:29+13код ревью относится только к новым правкам
Как будто при рефакторинге накосячить нельзя)
относится уже к рефакторингу, решение о проведении которого принимается обычно +- архитектором
Тоже сильно спорное утверждение. Не стоит расширять свой субъективный опыт на всех.
Devakant
25.07.2023 05:29Я потому и написал что плюс минус. Понятное дело что если компания маленькая где нет архитектора и даже тимлида, решение может принять просто самый опытный разработчик
at_wrike
25.07.2023 05:29+5И опять же спорно) мой опыт в компании средней крупности, где есть и архитекторы, и тимлиды, и разработчики разных грейдов, говорит о том, что предложение о рефакторинге может поступить от кого угодно. Если кто-то заметил, что код можно отрефакторить и он станет сильно лучше, он и приносит предложение. Потом мы его обсуждаем в команде и принимаем решение о том - делать ли его или нет. Если это не касается изменения архитектуры, то и архитекторов не трогаем)
И да, если это изменение кода - то его должны ревьюить. Ну или, как написал @Shatun чуть ниже - можно поставить ревью самому себе, если изменение небольшое и ты берешь на себя всю ответственность за фикс.

tenzink
25.07.2023 05:29+13Для меня самый страшный коммит имеет комментарий "bla-bla-bla minor refactoring". Наблюдал не один раз серъёзные проблемы в проде, связанные с такими "рефакторингами". Сейчас особенно внимательно отношусь к review таких задач.
Одна из причин, что рефакторить пытаются старый код низкого качества со слабым тестовым покрытием. Отстрелить ногу тут легче лёгкого

Shatun
25.07.2023 05:29+10Например я настраиваю что обязателен минимум 1 аппрув и разработчик может его сам поставить. Если уверен что все ок или надо срочно пофиксить-без проблем, но сразу видно что ты берешь отвественность за свой код.

SpiderEkb
25.07.2023 05:29+3Да. Аппрув ПР обязателен. Причем, даже "для своих". Т.е. вот несколько человек, все на одной горизонтали, уровень лидов (тим и тех). Все в списке ревьюверов по умолчанию. И все равно друг друга контролируют.
В нашем случае так - оформил поставку - она уходит в компонентное ( IT) тестирование. Одновременно создается PR feature->develop. Если IT-тест прошел и нужно отправлять дальше, на бизнес-тест, тут уже нужен аппрув ПР, мерж в девелоп и отметка в задаче "Review Done" от ревьювера.
Да, есть вещи, которые формально не требуют ревью. Заливка настроек каких-то, например. Ну тогда можно сказать ревьюверу - "лайкни, пожалуйста, там только настройки, ничего серьезного".
Но ревью нужно даже для рефакторинга. Ибо были случаи когда вылавливали весьма потенциально опасные артефакты в mission critical модулях. Именно после рефакторинга.

FruTb
25.07.2023 05:29+6Ага-ага, лайкнул я так коммит где "только настройки". Потом все кольцо Кассандры пришлось переподнимать. Больше я по таким граблям не хожу)
SpiderEkb
25.07.2023 05:29Ну это ж "для своих" только :-) Лид лиду, так сказать :-) И это уже после того как IT-тест прошел т.е. аналитики убедились что настройки корректные и вкатываются корректно.

Sild
25.07.2023 05:29+1Аппрув зачастую часть процессов безопасников и регулярного аудита выкатываемого
Для "не важных кодов" у нас был пайплайн посткоммитного ревью - если ты уверен что это нужно катить, можешь катить. Но за тобой все-равно потом придут и посмотрят, все ли ок. Потому что если не придут и не посмотрят свои - с некоторой вероятностью потом придут смотреть чужие, и будут задавать неприличные вопросики виде "какого хрена"

DMGarikk
25.07.2023 05:29+3пайплайн посткоммитного ревью
скользкая дорожка… у нас так очень существенный онлайн уронили часа на три
сначала посткоммитный ревью, потом постдеплойные тесты… а потом изза ошибок инициализации в мерджтрейне рушится десяток сервисов друг на друга завязанных… хотя в коммите ты тупо значение константы поменял от которой смайлик меняется в окошке какогонить чата
ну типа этож неважно всё
Sild
25.07.2023 05:29+1Ну, фигня случается. Это ж все меряется деньгами.
Если у вас благодаря посткоммитному ревью time-to-market вырос на неделю, а раз в пол года на 15 минут кладете прод - это ок
Если прод из-за такого падает регулярно - заслуженно надают по шапке
Но у нас получилось выстроить процесс так, что сервис целиком не ложился даже если ну совсем плохо все сделать (canary-deployment, вот это все). В итоге ни единого разрыва за пару лет (из-за посткоммитного ревью. В целом разрывы случались)
DMGarikk
25.07.2023 05:29+4а раз в пол года на 15 минут кладете прод — это ок
ну там все за полгода дошло до того что прод начали класть раз в неделю стабильно… и собирать совещания "а как так вышлото?? а ктоэтосделал?" причем вернуть тесты перед деплоем после мерджа даже в теории не рассматривались… потомуштамедленно
прод — это не интернет магазин рыболовных крючков, это аналог гуглдокса (ну конечно не такого масштаба но с парой миллионов посетителей в сутки точно, причем платных)… класть его даже на 5 минут это залет
SpiderEkb
25.07.2023 05:29Если у вас благодаря посткоммитному ревью time-to-market вырос на неделю, а раз в пол года на 15 минут кладете прод - это ок
Это если у вас нет норматива от регулятора "максимальное время недоступности системы на более 5-ти минут".
А за 15 выкатят штраф с очень многими нулями. Практически гарантировано. Ну или сопровождение в мыле будет все откатывать и поднимать прод.
Но в любом раскладе потом будет "комиссия по инцидентам" на которой "А подать сюда Ляпкина-Тяпкина! " И чем все это для вас лично закончится... Да бог его знает...

Aquahawk
25.07.2023 05:29+11так в том и смысл, что бизнесы разные и условия разные, и есть много бизнесов где оперативность важнее стабильности. Ну вот хабр лежал час назад. И что? Организация полной стабильности стоит очень много, а измеримого профита, тот же хабр не получит. Для разных продуктов нужны разные настройки, об этом и пост, что надо не слепо применять практики, а думать что нужно данному бизнесу в данный момент.

AlexanderY
25.07.2023 05:29+3Оффтоп, но всегда было интересно, как большие ребята замеряют время недоступности системы, основанной на запросах-ответах. Допустим, в промежуток с 21:42 до 21:47 система на 95% запросов отвечала кодом 200, а на 5% кодом 500. Сколько минут система была недоступна?

datacompboy
25.07.2023 05:29+8Зависит от. Самое правильное глянуть в формулировки SLA, например, на BigQuery: https://cloud.google.com/bigquery/sla
"Downtime" means more than a ten percent Error Rate. Downtime is measured based on server side Error Rate.
"Error Rate" means the number of Valid Requests that result in a response with an HTTP Status in the 500 range divided by the total number of Valid Requests during that period, subject to a minimum of 20 Valid Requests in the measurement period. Repeated identical requests do not count towards the Error Rate unless they conform to the Back-off Requirements.
"Monthly Uptime Percentage" means total number of minutes in a month, minus the number of minutes of Downtime suffered from all Downtime Periods in a month, divided by the total number of minutes in a month.
"Valid Requests" are requests that conform to the Documentation, and that would normally result in a non-error response.
SpiderEkb
25.07.2023 05:29Ну, например, по всей стране люди в магазинах не могут расплатиться картами некоего банка в течении двух часов. Платеж не проходит с формулировкой "нет ответа от банка". Потому что "лег" процессинг.
Или клиент на может зайти в мобильное приложение - оно же само ничего не делает, там просто UI которому дали некое REST API, которое, в свою очередь, опирается на набор вебсервисов, а там каждый имеет соответствующий сервис-модуль на центральных серверах. Т.е. чтобы отрисовать картинку на экране телефона с остатками по счетам и прочим приложение дергает API, то дергает вебсервис, тот дергает сервис-модуль и вот в сервис-модуле на центральном сервере и "возникает синекдоха отвечания" (с) результат которой пробрасывается обратно.
Вообще разные запросы в банк идут постоянно "стремительным домкратом" (с)

merinoff
25.07.2023 05:29+5Ревью правки текста в богом забытом разделе занимает секунды (и то, можно опечататься и потом еще раз пиарить), а более-менее крупное изменение без ревью делать не надо. Смысл в исключении из правила? Разрабу еще надо потратить мыслетоплива, чтобы определить, надо ли ревьювить или нет. Ну а потом со спокойной совестью отдать управление обезьяне и читать хабр))

powerman
25.07.2023 05:29+1Со статьёй в целом я согласен, но насчёт конкретно ревью Вы смотрите на последствия, а не причину. Это не отменяет того факта, что действительно можно и нужно оценивать необходимость ревью по конкретной ситуации.
На мой взгляд ревью полезен в любом проекте. Но есть нюансы:
Упомянутое Вами блокирование. Нет такой проблемы, если правильно поставлен процесс ревью: у него должен быть достаточно высокий приоритет, чтобы долго ждать ревью никому не приходилось, плюс количество ревьюверов необходимо свести к минимуму (в идеале - к одному человеку).
Если это срочный хотфикс - можно мержить без ревью, но ревью этому PR стоит сделать всё-равно, уже после мержа.
Если адекватное ревью объективно делать некому - напр. разработчик один на проекте или он один владеет этой технологией или предметной областью - точно придётся обойтись без ревью.
Ревью надо уметь делать. В частности, избегая при этом крайностей вроде механической реакции LGTM "чтобы не обижать", отчаянных споров из-за вкусовщины или перехода с кода на личности. Если ревью команда делать не умеет - это самая веская причина отказа от ревью, но даже в этом случае правильнее поступить иначе: обучить команду как делать ревью вместо отказа от него.

Politura
25.07.2023 05:29+3Но ведь это-же так просто проверить на себе: перестаньте работать в крупных конторах, уйдите в мелкий стартап и вот там вы как-раз получите и отсутствие тестов, и отсутствие код-ревью, никаких скрамов и работа будет быстро бежать рекой.
Я вот работал так, в мелком стартапе на десяток человек, который потом вырос в контору на три сотни разработчиков по всему миру. И отлично помню, как и зачем добавляли юнит тесты (да потому-что задолбались, одни и те-же ошибки исправлять снова и снова, котоые лезут и лезут всегда, после крупных изменений), как и зачем внедряли код-ревью (да потому-что задолбались переписывать снова и снова свой-же код, на который без слез не взглянешь). Вот внедрение скрама уже да, долго казалось каким-то ненужным говном. Груминг - мартышки выщипывают блох, тьфу. Но со временем как-то привык. Сейчас даже хз, хорошо оно, или плохо. Однозначно плохо когда много пустых митингов, там где скрам с минумумом митингов, вроде норм.

Ndochp
25.07.2023 05:29+1А мне интересно — без скрама это водопад или "как бог на душу положит".
Просто живого полного скрама я еще не видел, обычно просто понимают, что водопад это почти нереально, значит надо что-то гибкое, аджайл это манифест, а практики можно и из скрама надергать.
Интерсно, что автор имел в виду именно скрам или гибкие технологии вообще?

weqq
25.07.2023 05:29+1Код ревью помимо функции "линтера на стероидах" так же добавляет возможность команде быть в курсе новых фич / багофиксов, быть так сказать в курсе жизнедеятельности проекта.

sanapad
25.07.2023 05:29+2Например, есть богом забытый раздел сайта, где надо немного поправить
текст. Риски небольшие, зачем там проверять или перепроверять, отвлекая
еще людей.У меня есть контраргумент и я им буду кидаться) Как-то работал сисадмином и одной из рабочих обязанностей было - наполнение нашего раздела на сайте, основанном на самописном движке, застывшем во времени с вечной "0.1" версией. Очередное задание: разместить срочное важное объявление в установленные сроки (это было важно). Проверять результат как-то даже не стал: а какой смысл? С веб-технологиями знаком, а тут всего лишь несильно форматированный блок текста, тем более через админку движка добавленный. Увидел что-то вроде "сохранено" и успокоился.
В общем, приходят жалобы что блока текста нет. Оказалось, что движок настолько старый, что не поддерживал какой-то из тегов: в исходнике страницы вся информация была, но пользователи её не видели.
Конечно, код ревью - это про программистов. Но проверки никогда лишними не бывают: если бы хоть кто-то проверил раздел сайта вовремя - это бы всё изменило.

Wesha
25.07.2023 05:29-1Я столько раз допускал ляпы, чтоб без дружеского просмотра мог легко выкатить трудно-отлавливаемые баги.
А у меня столько раз code reviewer требовал изменить какую-нибудь запятую, не влияющую на работу программ, но ему, видите ли, не нравится внешний вид кода (при том, что я с примерами в руках могу доказать, что мой внешний вид кода менее подвержен опечаткам).
vagon333
25.07.2023 05:29+3Это особенности внедрения code review.
При правильной организации процедура может быть полезной - найти слабые места, обсудить решение, обменяться мнениями.
Думаю, атмосфера в команде играет роль, чтоб review воспринимался конструктивно.

san-smith
25.07.2023 05:29+13Для таких вещей придумали линтеры.
Достаточно один раз договориться в команде и настроить правило линтера — с этого момента вопросы о запятых/переносах/etc возникать не будут.
wapmorgan
25.07.2023 05:29+1Ппкс. Автоматическая проверка, единые правила для всех, отсутствие поля для разногласий или разной трактовки.

Rive
25.07.2023 05:29+1А в некоторых средах ещё и есть автоформаттеры, чтобы тратить на скучные дела минимум времени.

MiraclePtr
25.07.2023 05:29+4требовал изменить какую-нибудь запятую, не влияющую на работу программ, но ему, видите ли, не нравится внешний вид кода
В смысле, у вас в команде/проекте не было принято и утверждено единого code style, которого все должны придерживаться, и каждый в итоге калякал как хотел, а потом все ругались на эту тему? Печально.
Wesha
25.07.2023 05:29-1у вас в команде/проекте не было принято и утверждено единого code style
Принято-то было, волевым решением сверху. Только, как я уже сказал, в том-то и беда, что решение было принято не на основании логики, а на основании внутреннего чуства прекрасного.
san-smith
25.07.2023 05:29+4Есть мнение, что стоит придерживаться принятых в команде code style, даже если они лично вам не нравятся.
Да, эти правила можно изменить, от каких-то вообще отказаться, но пока они действуют — им нужно следовать.Wesha
25.07.2023 05:29им нужно следовать.
Да не проблема. Я давно уяснил две вещи. Во-первых, "кто платит — тот и заказывает музыку, поэтому за ваши деньги — любая ваша дурость" — как правило, чинить последствия этой дурости в будущем (обычно не особо отдалённом) придётся мне, то есть моя зарплата — в полной безопасности. А во-вторых, "самое главное в жизни — всегда иметь основание сказать "а я ведь предупреждал!"."

nin-jin
25.07.2023 05:29+1Не цените вы своё время и нервы, ой не цените.
Wesha
25.07.2023 05:29За время мне деньги платят, так что пишу ли я новый код или переписываю старый — не особо принципиально для моего кошелька, наоборот — чем больше нового кода остаётся написать, тем дольше мои услуги будут нужны. А о нервах отлично заботится здоровый пофигзм: если из-за эстетического чувства манагера в коде будут чаще (чем могли бы) появляться баги, то см. последнее предложение.
nin-jin
25.07.2023 05:29-1Когда ваша жизнь будет подходить к концу, вы задумаетесь на какую ерунду тратили свою жизнь. Но будет уже поздно.
Wesha
25.07.2023 05:29Ви будете смеяться, но к концу жизнь подходит чуть менее, чем у всех — вопрос только в расстоянии до этого конца, а с учётом естественных катастроф, межгосударственных тёрок и отдельных вооружённых мизантропов, оценка этого расстояния может весьма сильно варьироваться и частенько оказываться ошибочной. Так что расслабьтесь и постарайтесь
получить удовольствиежить одним днём — каждый из них может быть последним, а в могилу с собой ничего не утащишь (ну, кроме разве что врагов) — даже не-ерунду.
san-smith
25.07.2023 05:29+2Из ваших уст звучит так, будто принятое правило откровенно плохое, а ваше решение несомненно лучше.
Напомню контекст, мы сейчас говорим о правилах code style (вроде расстановки запятых или отступов). Так вот в этом контексте унифицированное правило однозначно лучше — хотя бы потому что не позволяет появиться мусорным изменениям в гите и не создаёт предпосылок для отклонения PR по этим причинам на ревью.Для продуктивности команды такое решение лучше и если члены команды не могут прийти к консенсусу, то вариант с волевым решением считаю приемлемым.
Насчёт "за ваши деньги любую дурость" не согласен — бизнесу вообще нет дела до ваших линтеров, это внутреннее дело разработчиков и решаться оно должно внутри команды.
Ну и кстати, "всегда иметь основание сказать "а я ведь предупреждал!" — не самое главное.

0xd34df00d
25.07.2023 05:29+1У меня в команде/проекте разок было интереснее.
Главный командир проекта не любил общий стиль, и тем более всякие там форматтеры — это ограничивало высоту полёта его мысли и мешало move fast. Когда новонабранный в команду чувак с более адекватными практиками разработки попытался ввести хотя бы форматтер, то командир проекта (проект был в основном на плюсах) прогнал форматтер (скажем, clang-format) на каком-то питоновском скрипте и пожаловался командиру командиров, что форматтер ломает питон. Где-то в процессе этого общения «форматтер кода на C++ ломает питон, если его запустить на питоновском скрипте» превратилось в «форматтер ломает код», и в итоге все форматтеры были запрещены, пока эти командирская часть этой клоунады не разбежалась по другим отделам и компаниям.

JustMoose
25.07.2023 05:29Код-ревью - это очень странная вещь.
Я лично встречался с ревьюиром, который считал, что он бог, и поэтому на ревью предлагал мне полностью переделать всё решение ( == архитектуру).
Да, там в MR было 200 строчек кода, да, я, возможно, не идеальный программист. Но сам факт того, что на ревью может найтись умник со своим очень личным и очень непоколебимым мнением - гарантия того, что вместо полировки кода будет -срач- жёсткие споры в команде. Как результат - готовый код попадёт в продукт/на рынок ещё не скоро. Нужно ли такое код-ревью - я не знаю.
DMGarikk
25.07.2023 05:29+2Нужно ли такое код-ревью — я не знаю.
именно такое не нужно, но в целом само по себе дело полезное
p.s. я так разок с работы ушел из-за того что начальник постоянно за всех задачи переписывал, потому что "вы делаете не так как я думаю"
san-smith
25.07.2023 05:29+4А если предположить, что "умник" действительно умник, без кавычек, и предлагает более хорошее (по каким-то критериям) решение, то всё ещё не нужно?
Ну и кстати, чтобы не попасть в такую ситуацию, можно перед началом выполнения задачи обсудить с коллегами решение — что-то вроде ревью результатов проектирования.
JustMoose
25.07.2023 05:29Сложный вопрос. Допустим, альтернатива действительно хорошая. И? Есть некий бизнес, бизнесу нужен на выходе какой-то продукт. Продукт делает несколько человек. Именно тех человек, которых удалось найти. "умник" предлагает лучшее решение. Лично мне не особо понятно, хорошо ли это вообще, или плохо. Ну ок, вот его решение внедрили. Код стал лучше. Но: в результате ушло время на повторную реализацию той же самой фичи, на это потрачены деньги компании, а с точки зрения конечного пользователя ничего не изменилось (есть фича, и она работает). Я не знаю правильного ответа. С одной стороны - очень здорово, когда код становится лучше. С другой стороны, мы всё же обычно работаем не для красоты, а для того, чтобы периодически выпускать релизы (которые позволяют продукту окупаться).
datacompboy
25.07.2023 05:29+3Оба решения отличались только косметикой, или так же алгоритмически и композиционно?
Плохой код в репозитории = плохой пример для подражания. Последующий код пойдёт деградировать её дальше.
Теория разбитых окон в действии. Вложения к хороший код окупаются, не надо путать допустимый технический долг и техническую ипотеку которая уводит в спираль банкротства.
JustMoose
25.07.2023 05:29Я не помню, это было несколько лет назад. Там точно не было кейсов пузырьковая Vs быстрая сортировка ;) Просто объекты, которые что-то обрабатывают, отдают результат и самоудаляются. На мой вкус, разница была незначительной.
Wesha
25.07.2023 05:29+2На мой вкус, разница была незначительной.
А не допускаете, что умник знал, как оно устроено под капотом, и используемые им методы были более эффективными (вроде O(n) вместо O(n^2))? На паре-тройке объектов, конечно, разница была незначительной — однако под рабочей нагрузкой она бы крайне быстро подняла свою уродливую голову.




panzerfaust
25.07.2023 05:29+83Я бы пересмотрел вообще всё
А почему "бы"? Вы ж тимлид. Делайте в своей команде все "правильно" - потом пишите отчет, как у вас все стало радужно. Ну а без фактуры - хайп для сбора лойсов от "бунтарей", которые ежедневно получают по кумполу от "неправильного" тимлида.
varanio Автор
25.07.2023 05:29-6Мне вернуться в прошлое и переписать статью, как вам нравится?
Да и есть вещи, которые я не могу рассказать.
Про программирование без код ревью - погуглите, есть много таких компаний. Без скрама тоже полно. Что именно, какие факты нужны?
vit1251
25.07.2023 05:29+2Опытного тимлида отличает понимание инструментов и стоимости тех или иных решений. В частности стоимость пересмотреть все это очередное бунтарство и перестройка ценой времени, комфорта и удобства многих сотрудников. Вот и выходит, что любые изменения нужно проводить постепенно с оглядкой на всю команду, процессы и прочее. Так сейчас многие толковые компании с PHP плавно переходят на Golang, но и там не всегда все хорошо, так как такой переход сопряжен с переучиванием персонала, вылезанием специфики языка и возникновению колосального технического долга. Так вот я к тому, что тут конечно может "наболело", но в любом случае все эти изменения очень сложные.

s-a-u-r-o-n
25.07.2023 05:29В статье критиковался не язык PHP (он приводится лишь в качестве примера), а использование одного и того же языка всей командой, в тех случаях, когда это приводит к росту впустую потраченного времени и технического долга.

bondeg
25.07.2023 05:29+3Php для описания бизнес логики прекрасно подходит и прекрасно чувствует себя в highload. Есть ряд низкоуровневых задач, где выгоднее использовать многопоточность go и получить выигрыш, но это не значит, что надо его пихать везде и говорить, что другие подходы неправильные)
SpiderEkb
25.07.2023 05:29+1Бизнес-логика понятие очень растяжимое. Это может быть, например, плотная и быстрая работа с БД напрямую. Т.е. чтобы проверить наличие записи в БД с заданным значением ключа или дернуть из таблицы одну запись по ключу совершенно не обязательно использовать SQL движок. Можно напрямую обратиться к индексу (для проверки наличия записи просто ищем ключ в индексе и смотрим - есть он там или нет, саму запись читать не нужно).
Или некие коммерческие вычисления с фиксированной точкой где могут присутствовать различные операции типа "присвоение с округлением". В специализированных языках все это есть на уровне языка.
Или мощный механизм описания структур данных - перекрывающиеся поля, например. То что с том же C/C++ придется делать сложными наборfvb union'ов, а частично установкой указателей в рантайме, в том же RPG делается очень просто на уровне описания структур данных и выполняется в compile time
wapmorgan
25.07.2023 05:29+1Есть у одного стэка неоспоримый плюс - вся команда его понимает и может разговаривать на нём.
Решать разные по сложности или направлению задачи, но на одном языке.

Farongy
25.07.2023 05:29+23Так DRY это не про то что в коде символы не должны совпадать. Если у вас "есть два разных по бизнес-смыслу раздела", то очевидно что здесь нет DRY
Принцип про то к чему стоит стремиться. Не нужно усложнять без необходимости
Потому что если можно Х + 1, то можно и Х + 2 не сильно ведь отличаются. А если можно Х + 2 то и Х + 3 можно. Чуете к чему идёт?
Идея, что за человеком кто-то перепроверит представляется вполне здравой. Просто потому что человек это человек, и даже супер профессионал может что-то упустить, не заметить. Если у вас ревью занимает столько времени, что является блокером может стоит научиться в процессы?
varanio Автор
25.07.2023 05:29+4DRY расшифровывается как don't repeat yourself, остальное уже трактовки, в том-то и дело.
Farongy
25.07.2023 05:29+14Речь о идёт о принципе или об аббревиатуре? Если о принципе, то даже книжка есть где рассказано, что он означает, от создателей так сказать.

markmariner
25.07.2023 05:29+9Если есть целая книжка, которая объясняет эти три слова, то значит не так они всем и понятны. А разных трактовок целой книги можно вообще не счесть.
Если нужен пример в качестве доказательства: вот библия вроде одна, а ветвей христианства много.

Moskus
25.07.2023 05:29+5Исключительно буквальная трактовка - это либо карго-культ в исполнении идиотов, либо симптом аутизма (та или иная форма психологической ригидности), либо характерная когнитивная черта представителей Gen-Z и молодых миллениалов.
Вы с кем из них спорите?

Boilerplate
25.07.2023 05:29+2Идиот, аутист, миллениал и представитель Gen-Z заходят в бар.
Идиот говорит:
- Мне пол литра пива, пожалуйста.
Аутист: "А мне четверть литра".
Миллениал: "А мне одну восьмую".
Представитель Gen-Z: "А мне одну шестнадцатую".
Бармен:
- Эй, эй, эй, стоп! Мальчик, мы несовершеннолетним не наливаем!

Tinkz
25.07.2023 05:29+9Я бы еще добавил: зачем нужно расставлять типы в не типизированных языках? Только гемора добавлять.

anatoly_kulikov
25.07.2023 05:29+9И typescript не нужен, ага
Shatun
25.07.2023 05:29+2Тайпскрипт вполне себе типизированный язык, компилятор проверяет типы при компиляции.

ilnuribat
25.07.2023 05:29+1а потом компилирует и выбрасывает все типы
я так понял ts нужен только в процессе разработки, в продакшене он ничем не отличается от нативного js

Kanut
25.07.2023 05:29+10Я вам даже больше скажу. Какой ЯП не возьми, а в итоге всё равно одни "нолики" и "единички" получаются :)
0xd34df00d
25.07.2023 05:29+3Выбрасывание типов после компиляции — лучшее, что с ними можно сделать. В рантайме типы не нужны, если они у вас не зависимые, а если зависимые — их наиболее эффективное вырезание является фронтиром текущего ресерча.
Именно поэтому в скомпилированном коде на хаскеле типов нет (если не попросить компилятор сгенерировать отдельные метки), идрис их тоже вырезает когда может, и так далее.

poxvuibr
25.07.2023 05:29Выбрасывание типов после компиляции — лучшее, что с ними можно сделать.
Задам дурацкий вопрос. Это про type erasure?
0xd34df00d
25.07.2023 05:29Смотря что вы имеете в виду. Если вы о type erasure в смысле C++ (когда у вас там внутри std::function полиморфизм, условно), то нет. Если вы об удалении иррелевантных аргументов — то да.
Если я нигде не пользуюсь конкретным
nв типеVect n Nat, то таскать с собойnв рантайме совершенно не обязательно.poxvuibr
25.07.2023 05:29Смотря что вы имеете в виду. Если вы о type erasure в смысле C++
Нет, я про type erasure в смысле дженериков в Java
Если я нигде не пользуюсь конкретным n в типе Vect n Nat, то таскать с собой n в рантайме совершенно не обязательно.
В смысле если мы у нас есть объект с полем, которое называется pole и мы этот объект передаём по значению и путём статического анализа кода мы поняли, что pole не используется внутри функции, то мы можем не делать копию pole при передаче?
0xd34df00d
25.07.2023 05:29+2Нет, я про type erasure в смысле дженериков в Java
А, тут уже я не так много знаю про дженерики в джаве, чтобы что-то утверждать.
В смысле если мы у нас есть объект с полем, которое называется pole и мы этот объект передаём по значению и путём статического анализа кода мы поняли, что pole не используется внутри функции, то мы можем не делать копию pole при передаче?
Всё несколько сложнее, но это неплохое нулевое приближение.
На самом деле, неполный список дополнительных тонкостей:
- pole можно и не вычислять в том месте, где вы создаёте объект для передачи в функцию,
- есть разница между компилтайм- и рантайм-вычислениями, и pole вполне может использоваться в компилтайм-вычислениях, но вырезаться при компиляции и не использоваться в рантайме,
- код может потребовать, чтобы pole вырезалось,
- всё это работает транзитивно.
Например, если у меня есть функция
index : (idx : Fin n) -> (vect : Vect n a) -> aгде
idx— натуральное число меньшеn(иnтут в типе, это важно),vect— вектор длиныn, то компилятор в компилтайме может проверить, что тут типы сходятся, что эта функция тотальная и никогда не упадёт и не полезет за границы вектора, а потом взять и вырезатьn(если функция написана адекватно), как будто его и не было никогда, и скомпилироватьidxв обычное число без следа всяких тамn, например.В языках с теориями вроде QTT (в идрисе 2, например) я могу прямо потребовать рантайм-иррелевантность
n, написав явно нолик (что означает примерно «аргумент в рантайм-контексте используется ноль раз»):index : {0 n : _} -> (idx : Fin n) -> (vect : Vect n a) -> aчто, впрочем, в данном случае полностью эквивалентно предыдущей записи (потому что не упомянутые явно аргументы в идрисе 2 по умолчанию считаются рантайм-иррелевантными).
В качестве более интересного примера можно рассмотреть
index' : (idx : Fin n) -> (vect : Vect (m + n) a) -> aгде появляется ещё какое-то другое натуральное
m, и где тоже в компилтайме тайпчекер может всё проверить (пользуясь тем, что ∀m. ∀n. n ≤ m + n), а потом вырезать и m, и n, и тем более ничего не складывать.
boldape
25.07.2023 05:29Это реально круть, постоянно использую типы (видимо как зависимые) в плюсах, боль конечно невыносимая нормаными девелоперами, поэтому только там где я один. Даже полностью в рантайме в плюсах это очень больно. Сможете запилить обзорную статью о том что там уже сделано какие проблемы существуют как их пытаются решать почему собственно говоря это круто (а это очень контринтуинтивно на самом деле) и ваше мнение где и когда это можно будет увидеть в языках обычных.
0xd34df00d
25.07.2023 05:29+1(видимо как зависимые) в плюсах
Только в плюсах нет зависимых типов (к сожалению, так как зависимые типы в языках с мутабельностью повсюду — это любопытно).
Сможете запилить обзорную статью о том что там уже сделано какие проблемы существуют как их пытаются решать почему собственно говоря это круто (а это очень контринтуинтивно на самом деле) и ваше мнение где и когда это можно будет увидеть в языках обычных.
Такие статьи очень тяжело писать, потому что очень тяжело оценить целевую аудиторию и сделать что-то, читабельное для кого-то, кроме
себя самогоидеального читателя по мнению себя самого.
0xd34df00d
25.07.2023 05:29Хорошо. Там можно сделать что-то вроде
int n = readFromSocket(); int array[n] = ...; foo(n, array);где
fooпринимает число и массив соответствующей длины?Если да, то что будет, если сделать
int n = readFromSocket(); int array[n] = ...; ++n;?

vanxant
25.07.2023 05:29Только в плюсах нет зависимых типов
Да ладно, на минималках всё-таки есть.
Берём прям первый пример с википедии. "Тип, описывающий n-кортежи действительных чисел" это ... тадам ...
float[n]Причём компилятор следит за совпадениемnи за тем, чтобыnбыло вычислимо на этапе компиляции, т.е. не даст подсунуть float[3] туда, где ожидается float[2].
nin-jin
25.07.2023 05:29Зависимые типы не про вычислимые на этапе компиляции значения, а про их множества. Конкретное значение известно только в рантайме. А то, чём вы написали - это просто обобщённые типы.
0xd34df00d
25.07.2023 05:29Ну начнём с того, что в плюсах нет VLA :]
Плюс,
nне обязано быть вычислимым на этапе компиляции с полноценными завтипами.
valery1707
25.07.2023 05:29Я обычно пишу на
Java, но сейчас нужно было наTypeScriptи возникла проблема как раз с типами.
Есть набор DTO описывающих структуру тела запроса, условно так:export class FieldX { @ApiProperty() field1: string; } export class Request { @ApiProperty({ type: FieldX }) fieldX: FieldX; }Только вот при обработке этого запроса
NestJSсоздаёт инстанс классаRequestв котором полеfieldXимеет тип сырогоObject, вместо моего конкретного классаFieldX, из-за чего я не могу вызывать на нём методы описанные в классеFieldX.Ничего хорошего в таком выбрасывании типов я не вижу.
0xd34df00d
25.07.2023 05:29-1Это не имеет никакого отношения к выбрасыванию типов при компиляции в целевой язык, о котором я писал, где вы по определению не работаете с результатом этой компиляции из вашего исходного языка.

leotsarev
25.07.2023 05:29+1Именно поэтому рантайм языка JS пытается заново типы угадать, да, заботливо вырезанные TS компилятором.
0xd34df00d
25.07.2023 05:29+1Ну потому что JS — таргет курильщика. Вызовы методов должны резолвиться до стирания типов, конечно, а не после.

bromzh
25.07.2023 05:29+9Как и в случае с кодревью - помогает избежать дурацких ляпов и опечаток. Плюс, проще рефакторить в будущем.
vanxant
25.07.2023 05:29Да не сказал бы про проще рефакторить. Одно дело когда функция возвращает any, другое - было T, стало T | array<T> , но массив только для какого-то нового юз кейса. Тут пахнет тем, что рефакторинг вообще лучше не затевать, а сделать новую функцию с новым возвращаемым типом и потом поддерживать обе (привет DRY)
0xd34df00d
25.07.2023 05:29Одно дело когда функция возвращает any, другое — было T, стало T | array<T>, но массив только для какого-то нового юз кейса.
А в чём проблема? Если разница в поведении для этого кейса небольшая, то можно и DRY соблюсти, и типы, если просто написать в качестве возвращаемого типа
if somePredicate(on, inputs) then T else array<T>.
fireSparrow
25.07.2023 05:29+17Я некоторое время провёл, внося изменения в питоновский код, где в половину функций передавались аргументы params или opts, или сразу оба вместе. Каждый из них был словарём с переменным набором параметров/опций, причём они не формировались в одном месте, а прокидывались через много уровней, и их содержимое могло обогащаться/изменяться по ходу этого прокидывания.
То есть не было никакого спосбоа узнать, а какие ключи в принципе там могут лежать, и в каком формате их значения. Эту информацию приходилось собирать по крупицам, ползая по всему коду.Если бы вместо словарей тут использовались нормальные датаклассы с типизированными значениями, то это лишь чуть-чуть увеличило бы трудозатраты при написании, но значительно сократило бы их при доработке, отладке и расследовании инцидентов. И дополнительно снизило бы вероятность ошибок и количество потраченных нервов.
DMGarikk
25.07.2023 05:29+9кстати к этому в каждом питоновском проекте приходят рано или поздно
причем забавно, сначала разрабы хейтят типизацию — типа бред, писанина, комунадо… а потом начинают и интерфейсы изобретать и типизацию тянуть и сериалайзеры разные прикручивать… и думаю иногда… а чё сразу на нормальном языке с типизацией не писать было?
я на каждом проекте с 15 года где работал в питоне на это попадал… (я стараюсь искать работу в крупных конторах с большими проектами)
fireSparrow
25.07.2023 05:29+7Мне в этом плане нравится утверждение, что в питоне фактически присутствует то, что можно назвать Gradual Typing (постепенная типизация).
То есть простой и очевидный код или прототип мы можем писать и менять очень быстро без заморочек с типами. А когда код стабилизируется и начинает обрастать логикой, мы можем постепенно вводить типы, основываясь на уже настоявшихся абстракциях.
Это даёт гибкость, но действительно требует определённой культуры разработки, которая не у всех есть.Впрочем, в последние годы всё больше вижу, что народ распробовал аннотирование типов.
0xd34df00d
25.07.2023 05:29+2Только и прототипы тоже быстрее с типами делать, если язык там не мешается.
vanxant
25.07.2023 05:29Вот про "язык не мешается" очень верное замечание. Большинство используемых в проде языков до сих пор не имеют не то что хотя бы тип-сумм, но даже и стандартного для этого языка типа result<T>. Ну или же завезли его слишком поздно, и встроенная в язык библиотека например швыряется исключениями.

RH215
25.07.2023 05:29+3сначала разрабы хейтят типизацию — типа бред, писанина, комунадо…
Это разрабы, которые вообще никогда не писали на других языках? Ибо я нелюбовь к строгой типизации видел только у убеждённых JS-фанатов.
DMGarikk
25.07.2023 05:29+2ну я очень часто слышал что отсутствие строгой типизации в питоне и то что там не принято писать километры абстракций это адский плюс и что разрабы пишут сразу бизнескод, а не обвязку первые три спринта
даже от тех кто был в нормальных языках… хотя поварившись в какойнить джаве очень сложно пиасть код "по питонячи"… на меня постоянно в кодревью на такое ругались по началу
RH215
25.07.2023 05:29+2ну я очень часто слышал что отсутствие строгой типизации в питоне и то что там не принято писать километры абстракций это адский плюс и что разрабы пишут сразу бизнескод
Странные ребята. Во времена py2 было хорошим тоном всё равно было принято писать типы. Только в документации. Тайпхинты, очевидно, делают этот процесс проще, очевиднее и ещё с автоматической валиадацией.
хотя поварившись в какойнить джаве очень сложно пиасть код "по питонячи"…
Но python-код написанный джавистами действительно выглядит... странно.
DMGarikk
25.07.2023 05:29Только в документации.
документацию вообще мало кто пишет и поддерживают…
я пока не видел ни одного проекта где это было бы нормальной практикой не просто написать но еще и поддерживать
зачастую даже swagger поддерживают "шоббыло" — (а что оно там рендерит смотрят только когда ктото жаловаться начинает)

evgenyk
25.07.2023 05:29+2отсутствие строгой типизации в питоне
В питоне строгая типизация и без хинтов и всегда таой была. Нестрогая - в JS.

Physmatik
25.07.2023 05:29+1а чё сразу на нормальном языке с типизацией не писать было?
Ну блин, статическая/динамическая типизации — далеко не единственный критерий выбора языка.

plFlok
25.07.2023 05:29+8Желаю Вам никогда не сталкиваться с багами "cannot read prop of undefined", вернувшегося из трёхкратных замыканий типа any.
UPD: кажется, я не распознал сарказм. В этих ваших интернетах не поймёшь...

Acuna
25.07.2023 05:29Очень помогает в поиски ошибок прям на лету без JIT, например в PHP array_search возвращает строку (значение) если значение найдено, и false если нет, поэтому если аргумент будет жестко string, то мы получим ошибку если значение не найдено, ибо а почему пришло false, может быть это следствие какой-то серьезной ошибки на сервере, который выдает ответ (а может и нет, в любом случае нужно разбираться), страшно даже представить что он пойдет дальше со значением false, а там и еще что-то ждет строку, а проверок-то у нас нет. С SQL то же самое, сколько было когда она ругалась когда кто-то пытался сунуть число вместо строки (ибо а почему он ждет строку, а приходит число), а не как раньше по недосмотру записывалось что не нужно. Поэтому после Java я понял что динамическая типизация порождает только говнокод и неотлавливаемые ошибки, которые в будущем могут проявиться так, что даже представить страшно, особенно когда на проде.

RAtioNAn
25.07.2023 05:29+2например в PHP array_search возвращает строку (значение) если значение найдено, и false если нет
О боже мой. Я, конечно, слыхал в инторнетах, что PHP супер кривой, но вот чтоб прям так. Как до такого вообще можно было додуматься? oO
vanxant
25.07.2023 05:29+2Да норм решение так-то. В более других языках тех же лет выпуска в данной ситуации возвращается -1. Которое, мать его, является валидным индексом для substr и прочих операций со строками (означает "последний символ"). И вот это НАМНОГО хуже.
На самом деле, вариантов решения этой проблемы (вернуть индекс подстроки или какое-то значение, обозначающее, что игла не входил в стог) не так уж много:
Стиль Си: в подобных случаях функция возвращает "0, NULL или -1" (это дословная цитата). А потом сервера не просто дидосят, а отправляют в состояние клинической смерти, выйти из которой помогает только Ctrl+Alt+Reset. Потому что fork при нехватке ресурсов возвращает -1 вместо pid, а парная ей kill понимает pid = -1 как "убить вообще все процессы, к которым есть доступ". Для рута это вообще все процессы в ОС кроме init, а базовый процесс сетевых демонов и всяких там служб как правило под рутом и запущен.
Вместо 0 и -1 ввести какие-то спецзначения в области NaN-ов (т.е. очень большие числа порядка INT_MAX). Это реализовали аппаратно в FPU, а вот в языки почему-то почти не завезли. Слышал, вроде js в старой опере так работал. Внутри PHP по факту сделано именно это, TRUE и FALSE это объекты - статические константы. Просто нужно было ввести дополнительные общеязыковые константы типа EMPTY или NOTFOUND.
Ввести тип-сумму result<T>. Но это в любом случае уже очень медленно аппаратно по сравнению с возвратом обычного инта в аккумуляторе, плюс нужно ломать сишное соглашение о вызовах.
Ввести свой тип int с блэкджеком и отсутствием переполнения, как в python. Оч. круто, но оч. медленно.
0xd34df00d
25.07.2023 05:29Но это в любом случае уже очень медленно аппаратно по сравнению с возвратом обычного инта в аккумуляторе, плюс нужно ломать сишное соглашение о вызовах.
Компилятору никто не мешает разворачивать
Maybe Tв голый T либо отдельное значение (как это происходит с -1), если вы пообещаете/докажете, что этого отдельного значения не бывает.vanxant
25.07.2023 05:29Ага, а потом я хочу положить результат функции в переменную или там в стор, чтобы фронт его потом реактивно отобразил. Но сначала вернуть на пару уровней выше по стеку или вообще через yield или resolve. И все ваши оптимизации в этот момент ломаются.
0xd34df00d
25.07.2023 05:29+1Почему? Компилятор статически знает, что если T реализует трейт/тайпкласс/етц
class SentinelValue a where sentinel :: aс вашим
newtype StringPosition = SP Int64 instance SentinelValue StringPosition where sentinel = -1поэтому никакая информация нигде не теряется, и везде, где используется
Maybe SentinelValue, оно при компиляции разворачивается в единственный объектSentinelValueбез всяких тегов отMaybe.Собсна, ЕМНИП ghc подобные оптимизации в некоторых частных случаях умеет делать.
SpiderEkb
25.07.2023 05:29+1Да норм решение так-то. В более других языках тех же лет выпуска в данной ситуации возвращается -1. Которое, мать его, является валидным индексом для substr и прочих операций со строками (означает "последний символ"). И вот это НАМНОГО хуже.
Ну тут сами себе на хвост наступили...
Сначала в С сделали индексацию массивов с 0 (логически объяснив это тем, что индекс есть смещение от начала массива - ок, в целом нормально). Потом сделали -1 как "не валидный индекс массива". Потом кому-то пришло в голову сделать в каких-то местах -1 как "последний элемент". Ну и приплыли ваши чемоданы...
В том языке с которым в основном работаю сейчас, массивы индексируются с 1 (да, это вызывает некоторый дискомфорт когда работаешь то с С, то в другим языком, но привыкаемо). А "не нашли" (функции типа %lookup, %check...) обозначается как 0.
Ошибка - это вообще отдельно. Или передачей отдельного параметра (т.н. "структурированная ошибка" - структура по которой можно получить подробную расшифровку по специальным message-файлам где будет и текст и уровень серьезности и т.п.), или установкой некоего внутреннего состояния, которое возвращается функцией %error() (и дополнительной информацией в виде %status()).
Как вариант - выкидывается системное исключение которое может быть перехвачено и обработано.
По крайней мере тут намного меньше ситуаций и потенциальными UB.
vanxant
25.07.2023 05:29+3выкидывается системное исключение которое может быть перехвачено и обработано.
Ага, а ещё можно вызывать
abort(). Ваши пользователи же не знают, где вы живёте, ведь правда?Библиотечные функции в общем случае не знают тяжесть ошибки с точки зрения вызывающего кода, и вообще ошибка ли это. Ну со
strpos/indexOfпонятно, но вот например системная ошибка чтения ( io read error ). Где-то это прям паника , диск посыпался и всё такое. Тот же самый код, с теми же самыми системными вызовами, но для сети - это норма жизни и всего-лишь повод сделать if. А в каких-то случаях эта ошибка может вообще быть ожидаемым "успешным" поведением (сброс кэшей после удаления / снятия прав / etc). Кидаться исключениями на каждый чих - ну, такое.SpiderEkb
25.07.2023 05:29Библиотечные функции в общем случае не знают тяжесть ошибки с точки зрения вызывающего кода, и вообще ошибка ли это.
На нашей платформе системное исключение - это ошибка с некоторым кодом.
например, перехватили ошибку MCH1202 - в соответвующем файле сообщений всегда можем посмотреть
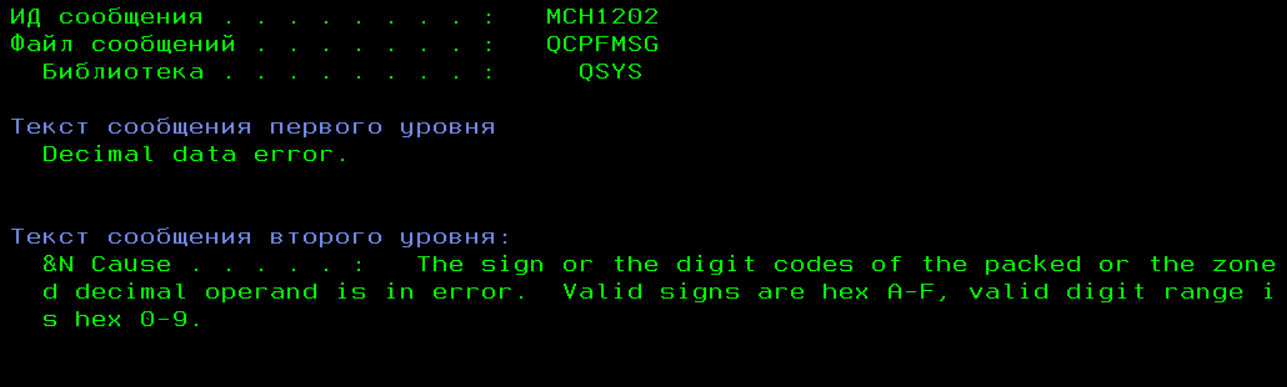
и получить эту информацию через системное API. И эта же ошибка будет записана в joblog. Если исключение не перехвачено и не обработано, то программа упадет, при принятии некоторых мер, создаст дамп где будет указана точка падения и опять код исключения.
Другой пример. Пишем на С API для работы с пользовательской очередью ( *USRQ). Чтение сообщений с таймаутом там идет через MI (машинная инструкция) DEQWAIT которая выкидывает исключение если таймаут истек, но в очереди ничего не появилось.
Пишем
#pragma exception_handler(UsrQExeptHandler, 0, _C1_ALL, _C2_ALL, _CTLA_HANDLE_NO_MSG) _DEQWAIT(pMessage, (_SPCPTR)pBuffer, &(pQueItem->spQueue)); #pragma disable_handlerи простейший обработчик, который фиксирует ошибку
static void UsrQExeptHandler(_INTRPT_Hndlr_Parms_T* __ptr128 pexcp_data) { // Запомним ошибку memset(usrqExeptionId, 0, 8); memcpy(usrqExeptionId, pexcp_data->Msg_Id, 7); wasError = true; }А дальше смотрим - если выставился флаг ошибки ее код MCH5801

То все нормально - просто таймаут истек, а читать нечего (очередь пустая).
Т.е. это не ошибка, идем дальше. Если код иной - там уже смотреть что случилось.
0xd34df00d
25.07.2023 05:29В том языке с которым в основном работаю сейчас, массивы индексируются с 1 (да, это вызывает некоторый дискомфорт когда работаешь то с С, то в другим языком, но привыкаемо). А "не нашли" (функции типа %lookup, %check...) обозначается как 0.
У вас моноидальная структура индексов отвалилась, а это неприятно.
Если у вас есть два смещения
i,jот начала массива, индексируемого с нуля, то для того, чтобы получить суммарное смещение, достаточно просто написатьi + j. Если у вас массив индексируется с единицы, тоi + jуже не работает, надо не забыть вычесть единичку.Ошибка — это вообще отдельно. Или передачей отдельного параметра [...], или установкой некоего внутреннего состояния, которое возвращается функцией %error()
Какие свежие, современные и приятные подходы!
SpiderEkb
25.07.2023 05:29У вас моноидальная структура индексов отвалилась, а это неприятно.
Я бы скала что это непривычно после С, но ничего непряитного тут нет.
При этом интервал [1..n] - валидные индексы, 0 - не нашли, -1 - ошибка.
Если у вас есть два смещения
i,jот начала массива, индексируемого с нуля, то для того, чтобы получить суммарное смещение, достаточно просто написатьi + j. Если у вас массив индексируется с единицы, тоi + jуже не работает, надо не забыть вычесть единичку.Опять же, дело привычки...
Какие свежие, современные и приятные подходы!
Старое - не всегда плохое. Оно работает, причем, быстро. Кстати, по многим тестам способ возврата структурированной ошибки работает быстрее, чем проброс исключения т.к. там практически нет накладных расходов.
Способ, аналогичный исключениям тут тоже есть, причем, не языковый, а системный - отправка прерывающего значения в *PGMQ (очередь сообщений программы). И это более универсально. Просто потому что программа на RPG вызвала программу на С++, та выкинула языковое исключение, которое, если его не перехватить внутри программы С++, там и останется. А вот прерывающее сообщение уйдет выше по стеку и может быть перехвачено и обработано в вызывающей программе.
0xd34df00d
25.07.2023 05:29-1 — ошибка.
Ошибка чего?
Опять же, дело привычки...
И внимательности. А чем больше внимательности от меня требуют, тем хуже.
Старое — не всегда плохое. Оно работает, причем, быстро. Кстати, по многим тестам способ возврата структурированной ошибки работает быстрее, чем проброс исключения т.к. там практически нет накладных расходов.
Я топлю совсем не за исключения. Монадическая обработка ошибок — наше всё.
SpiderEkb
25.07.2023 05:29Ошибка чего?
А вот чего именно ошибка - это уже надо разбираться по ее коду.
Суть в том, что мы рассматриваем случай поиска чего-то где-то. Который имеет три возможных сценария:
Нашли что искали
Не нашли что искали потому что его там нет
Не нашли потому что в процессе поиска "что-то пошло не так".
И вот эти три сценария надо однозначно различать. В рассматриваемом выше случае, когда возвращается индекс найденного для первого случая 0 также является валидным индексом. А -1 остается ответом для второго и третьего и требует уточнения. Даже двух:
Не нашли потому что нет или потому что что-то помешало (ошибка)
Если ошибка, то что за ошибка.
Или надо вводить сразу код возврата (что тоже хороший вариант) - >= 0 - индекс найденного, < 0 - код ошибки (при этом -1 - отсутствие искомого в области поиска, < -1 - какая-то ошибка, помешавшая поиску т.е. результат "если или нет" не определен).
В случае когда индексация начинается с 1 (в мире достаточно много языков где это так), > 0 - нашли, =0 - не нашли (эти два случая дают нам строго определенный результат есть/нет) и <0 - результат не определен т.к. что-то помешало (и только в этом случае уже требуется уточнение что именно).
Я топлю совсем не за исключения. Монадическая обработка ошибок — наше всё.
В свое время, когда исключения появились в С++, лично мне они показались "серебряной пулей". Но быстро выяснилось что это не так.
Это внутризязыковая конструкция и работает только внутри языка
Требует дополнительных ресурсов
Зачастую замедляет процесс (особенно если ими пользоваться бездумно, раскидывай их направо и налево просто как способ выхода из объекта с каким-то результатом - такое доже встречал.
Возврат кода ошибки намного "легче". Но вот когда стогкнылся с платформой IBM i, увидел что там используется "структурированная ошибка". В общем случае это структура содержащая 7-значный код ошибки + ее данные. Полная текстовая расшифровка содержится в т.н. "message file" - нечто типа таблицы с кодами:
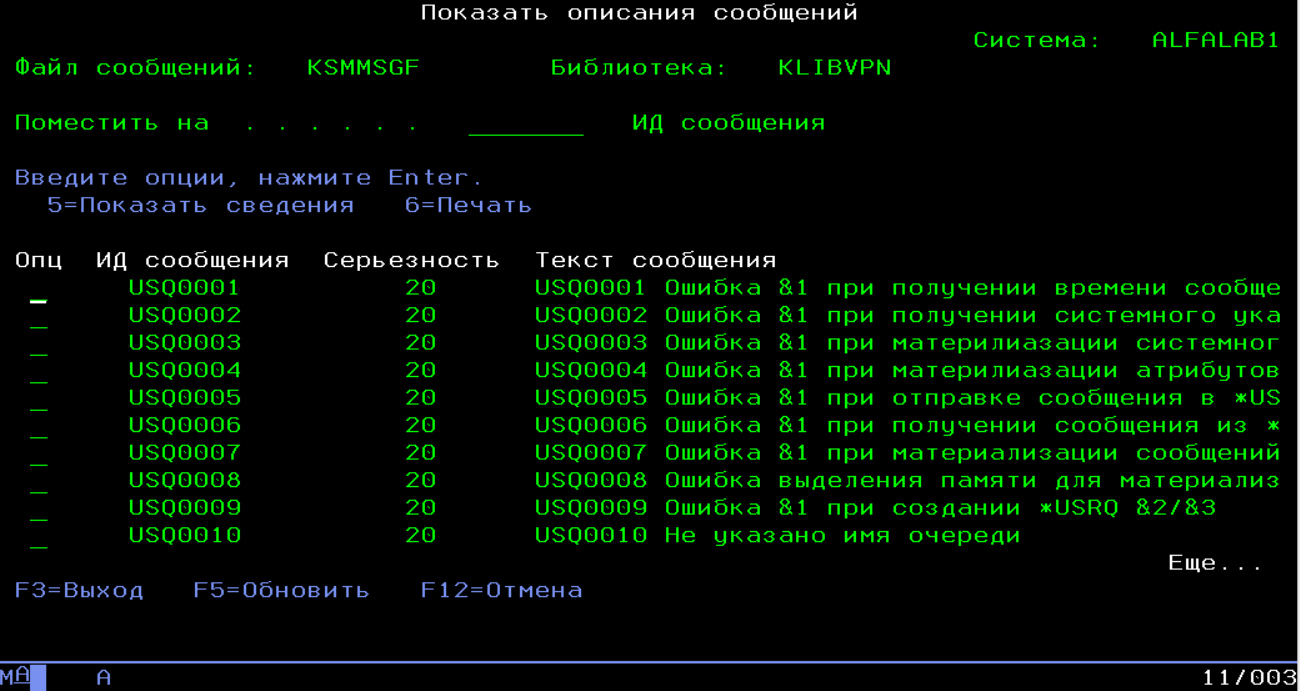
В этот файл можно добавлять свои сообщения, указывая код, серьезность и текстовую расшифровку. При этом &1, &2, &3 - параметры сообщения которые подставляются из данных.
Т.е. мы возвращаем структуру где содержится код + то, что будет подставлено в параметры. А дальше уже есть системные API, которые позволяют с этим сообщением делать что угодно - получить полный текст с подставленными параметрами, записать ошибку в очередь сообщений или joblog, вывести ее блокирующим сообщением (ожидающим ответа оператора) и получить ответ что делать дальше, вывести в очередь программы как блокирующее сообщение (тут есть полный аналог try/trow/catch, но на уровне системы в целом)...
Ну или просто посмотреть код ошибки и решить что с ней делать дальше...
Очень гибкий механизм с достаточно широкими возможностями и, при этом, единый для всей системы в целом, а не для какого-то конкретного языка.
При этом есть стандартные механизмы "подавления" не обработанных в программе исключений с их перехватом и обработкой выше по стеку.
Ну например - пишем программу на С где тупо делим на 0 не одумляясь последствиями. Потом вызываем ее из другой программы, на совсем другом языке. Если сделать это просто так - все упадет. Если сделать вызов с подавлением и перехватом исключения, то падения не будет - мы просто увидим что возникло исключение и сможет его обработать выше по стеку. Этакий try/catch, но на системном уровне.
Выглядит примерно так:
monitor; Pgm(Parm1: Parm2: Error); on-error; Error = 'KSM2053Pgm'; endmon;Error - та самая структурированная ошибка.
Pgm - некая вызываемая программа. Которая может выполнится нормально. Или завершиться нормально, но заполнить структуру Error какой-то своей внутренней ошибкой. Или просто упасть с треском. И в последнем случае влетаем в блок on-error и в простейшем случае просто заполняем структуру Error ошибкой с кодом KSM2053 и именем упавшей программы в качестве параметра
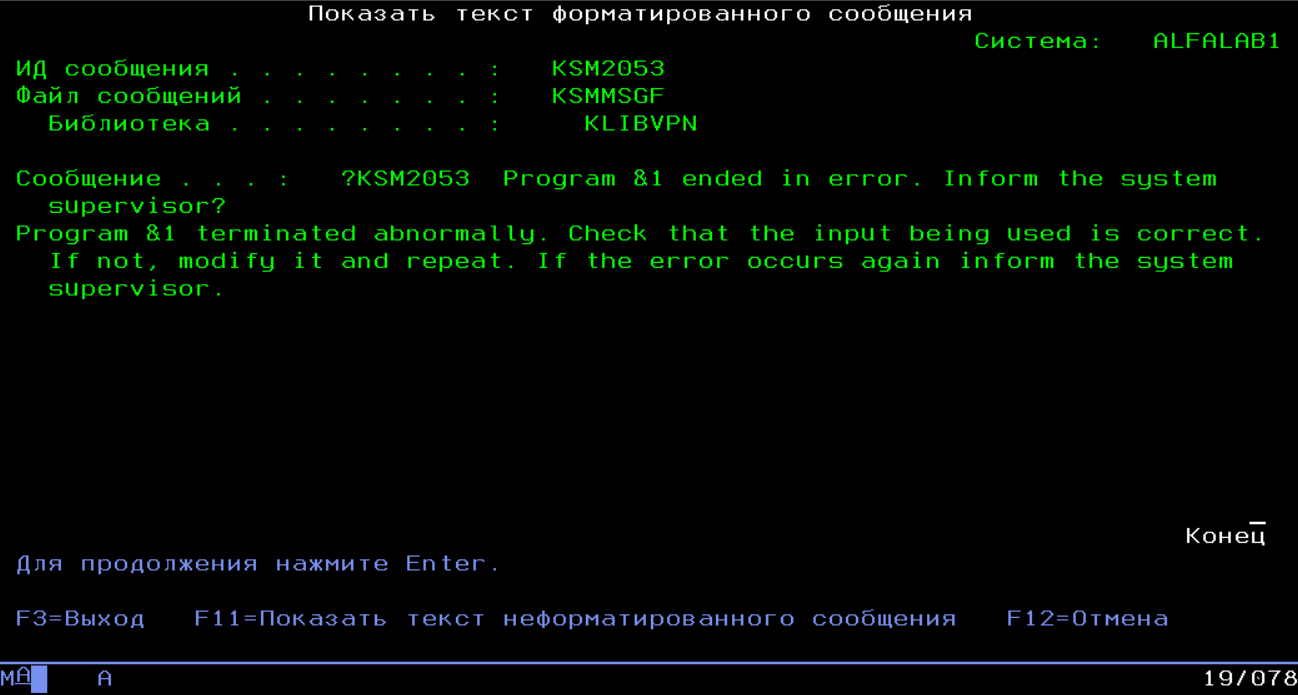
На самом деле там еще можно получить с каким именно исключением программа упала, если нам это потребуется для более полной диагностики.
Т.е. мы таким образом подавили падение всей программы, перехватили ошибку и может ее обработать по своему усмотрению.
И все это на уровне системы, а не какого-то одного языка.
И ошибки можем формировать сами какие нам надо.

1dNDN
25.07.2023 05:29+2Мне один товарищ из бека на php присылал JSON следующего вида, если массив пустой был:
{ "property": "[]" }И следующего, если там что-то лежало:
{ "property": { 1: "first element", 2: "second element" } }Я уже несколько лет никак не могу понять, зачем и почему оно такое, а самое главное - что ему мешало сделать нормально

edogs
25.07.2023 05:29-2Что Вас тут собственно смущает? Пустой массив именно так и кодируется в json. https://www.ibm.com/docs/en/baw/19.x?topic=format-handling-json-null-empty-arrays-objects
1dNDN
25.07.2023 05:29+7По вашей же ссылке, кавычек вокруг квадратных скобок нет:
Empty property
The JSON empty concept applies for arrays and objects as shown below.
41 { 42 "address":{} 43 "homeAddresses":[] 44 "phoneNumbers":[] 45 }Ну и непустые массивы обычно выглядят как в примере ниже, а не как в моем предыдущем комментарии
{ "property": [ "first element", "second element" ] }edogs
25.07.2023 05:29+1Подумалось что Вы в принципе ожидали false/null что-то такое.
А так да, Вы правы, вдвойне странно учитывая что в php еще с 5 версии есть функция конверта в json ведущая себя адекватно.
Непустой ассоциативный имеет право иметь ключи, но тут тоже странно - они должны быть как "1":"first"

y_akopov
25.07.2023 05:29+2Между { "property": "[]" } и { "property": [] }
различие в том, что в первом случае -- это строка со скобками, а во втором (по вашей же ссылке) -- пустой массивПример выше с объектом так же очень кривой, если это массив строк, должно быть просто { "property": ["first element", "second element" ] }
FruTb
25.07.2023 05:29+3Если твой код будут использовать другие люди - типы вполне себе часть документации. А то надоело, к примеру в питоне, взял либу а что совать в параметры хрен разберёшься. Или что оно в ответ даёт.

sbw
25.07.2023 05:29+4Я бы в питоне везде расставлял типы, потому что постоянно любой небольшой рефакторинг приводит к ошибкам

pilot114
25.07.2023 05:29Преимущество нетипизированых ЯП не в том, что можно не писать типы, а в том, что можно самому решать, когда они нужны, а когда нет.
Есть понятие контрактов - на их уровне типизация крайне полезна. В остальных местах менее важна и во многом зависит от предпочтений разработчиков.
Очевидно, типы увеличивают предсказуемость кода. Не сколько для непосредственно программистов (если они привыкли писать без типов, для них типы реально выглядят как гемор, ну ок), сколько для стат. анализа. А если и стат.анализ не использовать - ну извините, вы просто выбрали нишу разработки, где качество не сильно важно, такое бывает.

SpiderEkb
25.07.2023 05:29+2Весь мир насилья мы разрушим
До основанья , а затем
Мы наш мы новый мир построим,
Кто был ничем тот станет всем!Я бы так сказал - не надо к "правилам" относиться как к догме и возводить их в абсолют.
Многие из них есть просто результат внутренней договоренности (тот же codestyle).
Нормализация БД хорошо, но порой от нее приходится отступать ради повышения быстродействия.
Абстракция хорошо, но абстракция ради абстракции может неоправданно усложнить все и отрицательно сказаться на быстродействии.
И так далее и тому подобное.
nin-jin
25.07.2023 05:29-7Нормализация БД хорошо, но порой от нее приходится отступать ради повышения быстродействия.
Либо менять СУБД на ту, что не требует выбирать между нормализацией и быстродействием.

Hardcoin
25.07.2023 05:29+10В реальном мире такой не существует. Всегда есть запрос, который по одной структуре базы будет быстрее, чем по другой, при условии одинакового результата. Конечно не каждый запрос, а только какие-то узкие случаи, но они существуют.
nin-jin
25.07.2023 05:29-10И эта структура называется "поисковой индекс". Денормализация хранения для этого не нужна.
Hardcoin
25.07.2023 05:29+4Нет, она не называется так. Конечно подразумевается, что индексы правильные в обоих случаях.
Для примера представьте пять join на огромных таблицах по нестандартным условиям (не по равенству). Вы можете утверждать, если хотите, что разницы в скорости не будет, но таймеру я доверяю больше.
Vlad_YaKo
25.07.2023 05:29+1В каких случаях смена СУБД может помочь не выбирать между нормализацией и быстродействием?
SpiderEkb
25.07.2023 05:29+3Дело не в СУБД. Она достаточно мощная и достаточно быстрая. Дело в объемах обрабатываемых данных и требованиями к скорости обработки.
Вот представьте - пишете вы запрос. Правильный со всех точек зрения. И план запроса хороший и все индексами покрывается... Но... выполняется он 3 секунды. А вам говорят что это допустимо. Требования - не более 300мсек. И тут начинаются пляски с бубном - высокоселективные предвыборки, создание (и поддержка актуальности) витрин, денормализация каких-то таблиц...
И часто речь не идет о задачах, которые можно решить одним запросом. Например, писк совпадений по нескольким параметрам в двух БД - одна ~50млн записей, вторая ~300-500тыс записей. Тут уже без распаралллеливания не обойтись. Головное задание делает отбор по одной БД и выкладывает отобранное на конвейер. Откуда данные разбираются 10-ю обработчиками и каждый из них ищет что по какому параметру где совпало (там важна классивкация совпадений - тут совпадение по параметрам 1 и 3, там по параметрам 2 и 5, здесь по параметру 4 и т.п.). Причем, совпадение может быть не прямым - две строки по 250 символов. Но одна на кириллице, вторая на латинице в транслитерации... Или паспорта - 66 09 345876, 6609 345876 и 6609345876 - это одно и то же. Или даты рождения - 12.08.1970, 12 авг 1970, 12-08-1970, 12081970... Т.е. просто сравнить А=Б нельзя, требуется предварительная "нормализация".
Вообще, когда приходится работать с БД в которой десятки тысяч разных таблиц, неизбежно где-то да отойдешь от нормализации в пользу ускорения.
nin-jin
25.07.2023 05:29-3А десятки тысяч таблиц у вас откуда взялись? Уж не от того ли, что каждое отношение многие-ко-многим в реляционке требует отдельной таблички с парой индексов и парой джойнов на каждый запрос?
SpiderEkb
25.07.2023 05:29+17Нет... Десятки тысяч таблиц - от обилия бизнесовых сущностей.
Это банк. Таблица тлиентов, таблица счетов, таблица допинфо по клиентам, таблица адресов клиентов, таблица субъектов клиентов, таблица доверенностей, таблица документов клиентов, таблица платежных документов и так далее и тому подобное... Это только по основным данным. А дальше еще настройки всякие - таблица влют, таблица курсов, таблица тарифов, лимитов...
А еще комплаенс - таблицы рисков клиентов, таблицы стоплистов, таблицы совпадений клиентов со всякими злодеями-бармалеями (террористы, экстремисты, оружейные бароны, решения суда, списки ООН, санкционные списки...) талицы этих самых злодеев (списки которых регулярно приходят от росфина в виде XML на десятки мегабайт и раскладываются по базе...
Куча настроечных таблиц всяких для разных систем... Куча "витрин" - какие-то срезы по актуальным данным чтобы не собирать это все когда надо...
У нас сейчас по очень грубым оценкам
27 тыс. программных объектов
15 тыс. таблиц и индексов базы данных
Более 150 программных комплексов
Занимает более 30 Терабайт дискового пространства
В день изменяется более 1,5 Терабайт информации в БД
За день выполняется более 100 млн. бизнес операций
Одновременно обслуживается более 10 тыс. процессовТолько в процедуре закрытия опердня производится более 500 миллионов изменений в БД, при этом eё длительность составляет около 4 часов.
И не уверен что это актуальные данные. На текущий момент может быть еще больше.
И это только то, что работает на центральных серверах в рамках АБС (т.н. "Централизированные банковские системы", они же "мастер-системы"). А есть еще порядка 60-ти внешних систем - там свои сервера, свои данные.
nin-jin
25.07.2023 05:29Так это не противоречит моим словам. 1к таблиц данных и ещё 14к таблиц связей. Ну плюс ещё каждая бизнес сущность наверняка разложена по нескольким таблицам не потому, что так надо, а потому, что в плоские строчки табличек сложно запихнуть структурированный документ.
SpiderEkb
25.07.2023 05:29Вы уверены что там реально 14к таблиц связей? Откуда вы это взяли?
плюс ещё каждая бизнес сущность наверняка разложена по нескольким таблицам не потому, что так надо, а потому, что в плоские строчки табличек сложно запихнуть структурированный документ.
Опять фантазируете? Откуда там структурированные документы? Номер счета с его атрибутами - это структурированный документ? А счетов на клиенте может быть десяток и более. Плюс еще всякие служебные счета. Плюс есть сччете в 13-значной нотации, а есть в 20-значной (все что вы видели - это 20-значка - там тип счета, валюта и т.п., 13-значка это внутренние дела - там код клиента, код отделения...) и соответсвенно таблица связей 13-20. Плюс бухрежимы.
А еще есть риски клиентов (репутационные, страновые...)
А еще у клиента могут быть субъекты (доверенные лица, бенефициары и т.п.).
Сущностей очень много, куда больше чем может себе представить человек, для которого банк ограничивается только счетами-проводками.
И, кстати, таблиц только для связей один-ко-многим тут практически нет (я вот вообще не знаю). Скажем, основная таблица клиентов. Основной ключ там - ПИН клиента. + еще паровоз всякой информации. Но у клиента еще есть адреса (из порядка 6-ти, если память не изменяет, типов). Это таблица (точнее, две - адрес неструктурированный и адрес структурированный) где опять же ПИН, тип адреса, адрес.
Дальше ДУЛы (документы удостоверяющие личность). Тоже много типов и несколько записей на клиента. И опять - ПИН + тип ДУЛ + данные.
Если брать то, что относится к комплаенсу - там "субъекты списков росфина" (террористы, экстремисты и т.п.). А там уже персонажи
Она же Анна Федоренко… Она же Элла Кацнельбоген… Она же Людмила Огуренкова… Она же… Она же Изольда Меньшова... Она же Валентина Понеяд.
Т.е. у каждого субъекта несколько имен, адресов, ИНН, ДУЛов... И все это по нескольким таблицам разложено - таблица субъектов, таблица адресов, таблица ДУЛ... Плюс еще надо хранить историчность - в рамках какой версии списка когда данный субъект последний раз изменялся. Т.е. еще таблица заголовков списков (когда какой загружался)...
Когда делал эту самую БД - там 25 таблиц (включая архивы и журналы) и порядка 80-ти индексов.
Это я не в курсе что там у тарифного, лимитного модулей, модуля пластиковых карт, системы расчетов... Это отдельные команды, я в основном по направлению комплаенса работаю.
А еще всякие рабочие таблицы, логи работы различных комплексов, настроечные таблицы...

vvbob
25.07.2023 05:29+2Люди любят догмы, они позволяют экономить время и силы. Что-бы обосновать необходимость того-же кодревью - нужно как-то осмыслить все процессы, возможно обсудить их с командой, разобраться в том насколько в ней опытные и ответственные разработчики, и насколько они останутся ответственными без необходимости апрувов для каждого чиха.. В общем сложно это, куда как проще - "Кодревью - это промышленный стандарт, поэтому он должен быть,точка!"
И так во всем, намного проще скопировать доказавшие успешность общепринятые практики, чем пытаться обосновать их (не)нужность в каждом конкретном случае.




n43jl
25.07.2023 05:29+12Норм нативная реклама телеграм канала на 5к символов.
А по контенту: согласен, но банально. Всю статью можно выразить одним предложением: "не используйте технологии/процессы бездумно, а спрашивайте себя и команду зачем и почему"varanio Автор
25.07.2023 05:29+4В этом парадокс: мысль банальна, но догмы есть в каждой первой команде
poxvuibr
25.07.2023 05:29"не используйте технологии/процессы бездумно, а спрашивайте себя и команду зачем и почему"
Представьте себе ситуацию - вы не значете, зачем вы используете именно эту технологию и почему процесс выстроен именно так. Ну, то есть спросили и не нашли ответа, который вас бы устроил. Что делать дальше?


longclaps
25.07.2023 05:29+4В программировании нет вообще никаких непреложных истин.
Вышесказанное - непреложная истина или как?
varanio Автор
25.07.2023 05:29Ахаха
Врет ли человек, который говорит, что он врёт?
baldr
25.07.2023 05:29+6Каждое категоричное утверждение - ложно, включая и это.
datacompboy
25.07.2023 05:29+1Только не надо путать -- отрицание этого выражения требует применение отрицания к квантору всеобщности ("Не каждое категоричное утверждение - ложно") а не туда, куда хочется поставить слыша это утверждение :)

lovermann
25.07.2023 05:29Ну, рисковать (добавлять категоричность) всё же придётся, а то останемся у "всё может быть так, или иначе, но это не точно, потому что оно это всё может вообще быть или не быть. Ничего не было ясно, не ясно сейчас, и никога не будет ясным!" :))))

Actaeon
25.07.2023 05:29+2Вы не прошли через линтер тов Тарского: использование метаязыка первого уровня (для описания мира) в качестве метаязыка второго уровня (описание языков первого) . Вот вам таск - закройте до вечера.


laatoo
25.07.2023 05:29+3код-ревью, который прям вредит time-to-market это нездоровый код ревью.
сколько он у вас занимает, что это прям становится проблемой?
и что, бизнес страдает прям от этого лага?без вторых глаз над кодом риск задержки только вырастет, потому что расслабимся и наворотим так, что потом не разобраться.
0xd34df00d
25.07.2023 05:29+3код-ревью, который прям вредит time-to-market
Конечно вредит, любой код-ревью. Без него можно быстро выкатить свои новые фичи, а потом фиксы своих новых фич. TTM улучшается кратно, количество выкаток тоже улучшается кратно!
сколько он у вас занимает, что это прям становится проблемой?
Пара часов — это уже слишком много, когда не терпится и we need to move fast. Даже пара часов убивает так милый дух стартаперства и движения.
и что, бизнес страдает прям от этого лага?
Бизнес не страдает, страдаете вы (меньше выкаток) и ваш менеджер (меньше выкаток в его отделе, меньше слышно про его отдел, меньше надувание щёк).
наворотим так, что потом не разобраться.
Job security — тоже плюс отсутствия ревью.

Oceanshiver
25.07.2023 05:29-1Эту бы статью да выдать всем работникам "галер" для обязательного изучения! Сколько сталкивался в разных командах с бывшими "галерными гребцами" - все они всегда тупо следовали описанным трендам, не пытаясь понять, а подходят ли они вообще в текущий проект, и спорить на эту тему с ними невозможно.
DMGarikk
25.07.2023 05:29+2не поможет, как сотрудник галеры я плачу от такого, но всеравно так делаю, а все очень просто
Мне прилетает задача, я ставлю на неё время, учитывающее это вот всё по правилам… а через неделю приходит разъяренный РП от заказчика с криками что он платит за реализацию ф-ции, а не рефакторинг и что мы (галера) охренели что простые задачи типа поменять текст в виджете ставим срок по 20 часов (а там архитектурно никак не сделать иначе) ведь явно явно для того чтобы бабла побольше содрать… потом начинают часы резать насильно и выкидывать из оплат такие доработки
в итоге приходится делать так как получается чтобы не бил заказчик и собственное руководство
Это кошмарно, но есть причины почему такую работу приходится делать и в таких местах работатьПричем когда я работал в другой галере, и там я был оутстаффером — ситуация была сильно лучше (оплаты не зависили от объемов работ, потому что я бы внутри комманды заказчика и часы не считали), но контора была очень большая и там упарывались на другое… и потратить полспринта на причесывание ужасов архитектуры можно только если гарантированно можно уложится в дедлайн — и я всегда переделывал такое… а коллеги не парились тупо дублировали ф-ции чтобы не бегать по десятку департаментов и узнават почему именно так сделали (тимлидов не было… плоская структура… задачу дали сам разбирайся, сам бегай к соседям, сам ищи почему так, сам вникай в десяток сервисов которые в процессе учавствуют)

CrashLogger
25.07.2023 05:29+8Для галер (больших компаний, выполняющих типовые рутинные задачи при помощи низкоквалифицированной рабочей силы) эта статья как раз не подходит. Там надо максимально все формализовывать и загонять в жесткие рамки. Она расчитана на небольшие команды из крутых профессионалов, у которых и так все хорошо.
Oceanshiver
25.07.2023 05:29+1Так и речь не про то, чтобы в галерах это использовать. Речь о том, когда галерщик приходит в нормальную компанию работать с этим всем "багажом" в голове

Fedorkov
25.07.2023 05:29+4Cоветую хотя бы иногда пересматривать вообще всё.
Ещё лучше завести привычку подвергать критике вообще всё, чем занимаешься, включая процессы разработки и бизнес-процессы. Оценивать, окупаются ли издержки ожидаемой будущей пользой. Поначалу это отвлекает от кодинга, но со временем остаётся просто интуитивное ощущение, что ты что-то делаешь не так.
Это как запах кода, только для правил и процессов разработки.

rdo
25.07.2023 05:29+1Ладно правила линтера на размер функции, один очень деятельный человек на моей памяти протолкнул ограничение на количество return в функции, тогда-то и началась веселуха.
panzerfaust
25.07.2023 05:29-2Как правило, ограничение на число ретурнов - абсолютно нормальная дисциплинирующая мера. Ни разу за карьеру ни сталкивался с тем, чтобы это становилось каким-то блокером. Даже если "я художник, я так вижу", то мои коллеги потом вряд ли захотят разбираться в месиве из 15 ретурнов, 8 из которых находятся внутри третьего вложенного цикла. Не скажу за всяких сишников-эмбеддеров, но на ЯП типа джавы, шарпа и особенно котлина вообще нет никакой сложности обходиться 1-2 ретурнами на функцию.

Wan-Derer
25.07.2023 05:29+1По-моему, это правильно: в начале метода проверить краевые условия и корректность входных данных и сделать
return(или бросить исключение) если что-то не так. А потом писать основную логику. Это лучше чем оборачивать её в дополнительныйif. Как правило, основная логика на экран не помещается и мотать её туда-сюда замучаешься при отладке/улучшайзинге. Поэтому хочется разбить метод на более мелкие "блочки" кода.Но 15
returnэто перебор, согласен :)внутри третьего вложенного цикла
Это (вложенные циклы) уже само по себе не очень читаемо :) Иногда помогает переход на более декларативный стиль с лямбдами и Stream API.
Fedorkov
25.07.2023 05:29Целая MISRA C (индустриальный стандарт для разработки прошивок в автопроме) запрещает больше одного return.
tenzink
25.07.2023 05:29+3В C без этого неверное тяжело в контексте очистки ресурсов. В идиоматичном C++/python/Java/C# это скорее всего не нужно - там есть деструкторы/context managers/using/...
Actaeon
25.07.2023 05:29+8А в чем проблема ;)
ret= ....
goto exit;
exit:
return ret ;и все дела
SpiderEkb
25.07.2023 05:29+3Ну тут уже от языка зависит.
Сам по себе return - это просто команда. Вред не в том, что вы его куда-то там воткнули, вред в том, что нет одной единственной точки выхода. И вот тут уже пользуемся тем, что нам предоставляет язык.
В том, с которым работаю я, есть во-первых, subroutines - подпрограммы в рамках процедуры (как в древнем бейсике было - gosub). Без нового уровня стека, без собственных локальных переменных, без своих параметров. Но хорошее средство для структурирования кода. И точку выхода можно организовать через такую вот сабрутину:
где надо ставим
exsr srExit;и пишем
begsr srExit; // делаем что нам надо на выходе return; endsr;А еще есть блок on-exit куда попадаем после выполнения return (и можем заменить возвращаемый результат если нужно). Тут return уже не так страшен т.к. у нас есть одна контролируемая точка выхода.
Но это все языковая специфика.

altmf
25.07.2023 05:29Иногда одна точка выхода из функции может усложнять ее логику, но по моему мнению влияет скорее положительно. Те же PMD и Checkstyle для Java включают соответствующие правила.
Справедливости ради, к их реализации есть вопросы, например, при перегрузке того же equals часто удобнее делать return в случае непрохождения проверки типа или, например, хочется выбросить исключение в функции, помеченной
@ NonNull,а дополнительные проверки делать не хочется.Однако, на мой взгляд, эти проблемы перевешиваются такими плюсами как:
Удобство отладки. Можно гарантировано поставить точку останова на единственный
returnи ждать.Упрощение потока управления и затрат на понимание кода: чтобы понять, что будет возвращено функцией не требуется анализировать весь код, в котором
returnмогут вызываться в произвольных местах: внутри условий, циклов, условий в циклах и т.д.

Antra
25.07.2023 05:29+5И обычно время от времени появляется вполне валидный код, который по каким-то причинам не влезает, и люди извращаются как могут, переписывают через дичь, чтобы как-то пайплайн протащить.
Это реальность? Не передергивание? Многие линтеры настолько не доросли до возможности задавать исключения, что вынуждают творить дичь?


bel1k0v
25.07.2023 05:29+7И начинаются пляски с бубном вокруг PHP, на котором пытаются завести highload-решения.
Грязно, очень грязно, особенно с учётом того, что на PHP 80% Интернета работает, а ваш go на 14 лет младше, да и не в языке дело, как известно. А в прослойке между монитором и сиденьем.

init0
25.07.2023 05:29+3Ну я бы не относился на вашем месте серьезно к подобного рода статьям, это же типичный байт и манипуляции. Достаточно заглянуть в профиль автора - там только твиттер и телега с тремя калеками в подписчиках, и при этом нет гитхаба - так что и экспертиза автора под большим вопросом.
bel1k0v
25.07.2023 05:29+1Понимаю, забайтился. Ни о чём не жалею. Экспертиза автора, да, местами вызывает вопросы. Но, возможно он и пришёл разубедиться в своих текущих утверждениях. Все мы когда-то думали подобным образом, а некоторые ещё и фантазии свои туда умудрялись запихивать. Может как раз он больше в публицистику умеет, чем в код, его профиль как раз об этом говорит.

TaksShine
25.07.2023 05:29+1Может автор что-то свое под хайлоадом понимает? Если приложение не скейлится, то хайлоад не вывезет, на чем его ни пиши. А если на пыхе и норм скейлится, то почему бы и не хайлоад.
bel1k0v
25.07.2023 05:29В моём понимании хайлоад это бренд, а не термин, поэтому у всех своё видение. Масштабирование по данным это к БД, масштабирование сетевого трафика это веб-сервер или балансировщик. Часто и много пишешь - ставь в очередь. Масштабирование оно про архитектуру и ресурсы, а не про код вашего приложения и предпочтения в плане выборе ЯП для бекенда, инстансов которого можно поднять достаточно, при наличии ресурсов.

ildarin
25.07.2023 05:29<ловите-пхпшника-мем.жпг>
Хайлоад он разный бывает. Можно интерпретировать и как количество пользователей, и как количество операций. Поэтому - заявление двусмысленное. С точки зрения нагрузки на сеть - странно было бы, если язык предназначенный исключительно под веб - плохо бы работал в вебе) Однако нейросети на нем не пишут.
nikalone555
25.07.2023 05:29+2Насчет линтеров и ограничений на количество строк, то мне кажется это имеет смысл.
Когда читал Мартина с его Чистым кодом меня прямо до глубины поразил пример переписанный с принципом максимального сокращения размеров функции. Получилось прямо что ты ЧИТАЕШЬ код как обычный текст, а не как в фильме Матрица среди зеленых цифр видишь блондинку в красном. Так что вынести в отдельную функцию с названием даже обычное использование stream api в яве мне кажется хорошей идеей. Это проще читать. Если из функции можно выделить отдельную функцию - то обычно лучше сделать.
shashurup
25.07.2023 05:29+8Есть противоположный взгляд на труды Мартина. https://qntm.org/clean
Проблема с большим количеством мелких функций в том, что создавая отдельную функцию ты создаешь новую абстракцию, а создание абстракции не такая простая задача как многим кажется. В итоге, часто получается, что разбив "большую" - едва влезающую в экран функцию на десяток мелких мы можем многократно усложнить восприятие этого кода за счет неудачных абстракций.
nikalone555
25.07.2023 05:29+1А где тут выделение новой абстракции, когда вы кусок кода, который делает что-то конкретное выносите в отдельную функцию с понятным описательным названием? И как это может привести к усложнению понимания?
shashurup
25.07.2023 05:29+2Чтобы назвать функцию понятно и описательно необходимо как-то обобщить происходящее в ней чтобы у нас название было короче самого кода. Здесь абстракция, как правило, и появляется. Или не появляется, тогда название получается непонятным и неописательным.

select26
25.07.2023 05:29И не забывайте, что вызов функции - это дополнительный оверхэд: время на ее инициализацию, сам прыжок / возврат, стек и т.п.
Иногда это имеет большое значение.MiraclePtr
25.07.2023 05:29вызов функции - это дополнительный оверхэд
Не всегда, хоть немного умные компиляторы умеют инлайнить (если, например, видят, что эта функция вызывается только вот здесь и ее интерфейс не торчит за пределы модуля).
nin-jin
25.07.2023 05:29Даже если и умеют, то делают далеко не всегда. И это поведение может меняться между версиями компилятора.

tetelevm
25.07.2023 05:29+3ТЛДР: для любого инструмента своя сфера применения, а возводить всё в абсолют глупо.

TokminD
25.07.2023 05:29+1Зачастую это просто ошибочные выводы, перепутаны причина и следствие. В хорошем продукте был Code Review? Значит Code Review обязателен для хорошего продукта. А правда состоит в том, что инструменты и подходы в хороших продуктах выбираются понимающими людьми, и именно они создают хороший продукт, а не инструмент. Когда методологии спускаются "сверху" ⬆ "вниз" проект манагерами и т.п. то получается такое описанное буквоедство. И не стоит забывать, что основная цель этих подходов не помогать разработке, а сделать роль разработчика "несущественной". Чтобы можно было менять команды как перчатки, без ущерба для скорости и качества. И кстати эта цель весьма достижима, ведь при тупом следовании концепции можно достичь результата, что все команды будут вносить изменения одинаково медленно и некачественно.
Aquahawk
25.07.2023 05:29Всецело одобряю и поддерживаю. Это называется суоя голова на плечах. И это дико не приветствуется в медийной части разработки.
markowww
25.07.2023 05:29Культ-карго не только ведь в программировании, у тех же девопсов та же самая история: стандартный набор инструментов, потому что все так делают.
DMGarikk
25.07.2023 05:29+2это важно кстати использовать типовые и стандартные вещи
потому что когда приходишь в контору, а там 90% инструментов или самописные или из какихто мудреных проектов которые гений сеньор который 5 лет назад тут работал притащил… хочется взяться за голову и убежатьпомню был проект, там половина ci/cd была написана на инструментах из гитхаба от какихто странных челов типа Vasya1995ef111111 c 5 звездами и 40 коммитами 2х летней давности — причем это форк какогото известного инструмента который уже настолько вперед ушел что вернуться нереально
и ты вместо того чтобы работу работать изучаешь костыли и мигрируешь задеприкейченные тулзы которые ктото сюда припер вместо общепринятых подходов...markowww
25.07.2023 05:29+2Я всеми руками за стандартные инструменты, был у меня опыт работы с самописной инфраструктурой. Я больше про то, что конкретный инструмент выбирается без какого-либо анализа требований. Взять тот же k8s - его везде пихают, но по моему опыту, это часто бывает избыточно.
TokminD
25.07.2023 05:29+1GIT тоже самописная система. Просто не все самописные инфраструктуры хорошие :)
DMGarikk
25.07.2023 05:29+2обычно люди работают на работе чтобы какойто продукт делать, а не эксперименты ставить в стиле "а давайте мы этот проект на object pascal напишем, я слышал что в какомто институте он популярен, значит люди опомнятся и вернуться к нему" (с)

dsh2dsh
25.07.2023 05:29+1Чем это отличается от "а давайте этот проект на X напишем, я слышал, что в Гугле он очень популярен"? А ведь сейчас решения именно так и принимаются.
DMGarikk
25.07.2023 05:29+1А ведь сейчас решения именно так и принимаются
решения надо принимать по принципу
"сколько разрабов у нас знают язык X? готовы мы еще набирать людей на язык X? как быстро мы найдем людей если все уволятся, на язык X"
А не по принципу "в Гугле популярно"Я уже даже Ruby немного выучил, поскольку у меня было несколько задач по переписыванию микросервисов с руби на питон, из-за того что в команде из 10 разработчиков, был один рубист и он все сподвиг в начале 10х годов перехдить на руби… а потом гдето в районе 15 годов уволился… и в 18 году питонисты отчаялись искать миддла на руби ради одного сервиса и решили тупо мигрировать на типовой для компании стек и не плодить больше таких экспериментов
сейчас вот у меня есть задача на C#… потому что ктото сделал сервис на нем, а из всей комманды разработки в 20 человек, шарп только я когдато трогал и на яве писал, все остальные чистые питонисты...

gev
25.07.2023 05:29+1Выбрал язык для проекта, перефразировав фразу:
"Пойми, на небесах только и говорят, что о море. Как оно бесконечно прекрасно. О закате, который они видели. О том, как солнце, погружаясь в волны, стало алым, как кровь. И почувствовали, что море впитало энергию светила в себя, и солнце было укрощено, и огонь уже догорал в глубине. А ты? Что ты им скажешь? Ведь ты ни разу не был на море. Там наверху тебя окрестят лохом."
Заменив слово на "море" на "хаскель" =)
dsh2dsh
25.07.2023 05:29решения надо принимать по принципу
Эх... Какой смысл писать о том, как надо принимать решения? Из моей практики:
Нанимают CTO/нового менеджера и он говорит: будем использовать Domo, snowflake и Go. Притом, что весь проект написан на перле и работает уже 10 лет. Ах да, про микросервисы же забыл. И кому вы тут будете рассказывать, как надо принимать решения? Этому CTO/новому менеджеру? Так он во первых, никого не спрашивал. А во вторых, на первой же встрече публично сказал всем: мы будем уважать желание любого из вас покинуть нашу компанию.
DMGarikk
25.07.2023 05:29Нанимают CTO/нового менеджера и он говорит: будем использовать Domo, snowflake и Go. Притом, что весь проект написан на перле и работает уже 10 лет.
а в данном случае означает что в этой компании ваше мнение не учитывается, но возникает вопрос, как вас программиста на перле заставляют переписывать проект на Go? вам доплатят? вам снизят грейд с сеньора-перла на джуна-го?
также я вижу два противоположных звоночка
= если у конторы есть бабло на такое странное мероприятие, значит она не обанкротится прямщас, в некотром роде это плюс и вам можно поднять свою квалификацию
= у конторы нет задач и она делает чтото только ради того чтобы чтото делатьвсе эти звоночки плюс отсутствие участия в выборе инструментов отдела разработки означает то что вам пора менять работу


amateur80lvl
25.07.2023 05:29Очень правильный mindset ибо best practices иногда оказываются порочными.

akamap
25.07.2023 05:29+2Если их объединить с помощью общей высосанной из пальца абстракции и тем самым избавиться от небольшого дублирования кода, то потом (очень скоро) можно будет сойти с ума, потому что эти две вещи скоро разъедутся, обрастая кастомными фичами, и абстракция будет только вредить.
поэтому и придумали Single responsibility principle

serginho
25.07.2023 05:29+10Классика кунг-фу:
Сначала ты не знаешь, что нельзя делать то-то
Потом знаешь, что нельзя делать то-то
Потом ты понимаешь, что иногда таки можно делать то-то
Ну а потом ты понимаешь, что помимо того-то существует еще шестьдесят шесть способов добиться желаемого, и все из них практически равноправны.
Когда тебя спрашивают "как мне добиться желаемого", ты быстро перебираешь в уме эти шестьдесят шесть способов, прикидываешь то общее, что в них есть, вздыхаешь и говоришь: "вообще-то, главное — гармония."
На вопрос обиженных учеников: "а как ее добиться?", ты говоришь: "никогда не делайте то-то".
Gotcha7770
25.07.2023 05:29Бъешь по голове *тут должна быть ссылка на коан про то, что объекты это процедуры, но я не нашёл его*

karanarqq
25.07.2023 05:29+10Про код-ревью вас зацепило
Да, зацепило. Потому что time-to-market хоть и в минусе, но в общем и целом бизнес в плюсе почти всегда (почти - потому что испортить можно все и всегда).
1. Код-ревью как средство обучения сотрудников - когда бородатый сеньор объясняет джуну в чем он не прав, что качает одному софты, а второму харды;
2. Код-ревью как шаринг знаний по проекту - когда ты в один прекрасный момент получаешь задачку в той части кода, в которую лез один раз тысячу лет назад, но зато смотрел ревью коллеги, который там работает, и у тебя уже есть знания, иначе ты можешь порушить устойчивые костыли или просто надолго там задуматься;
3. Код-ревью как валидация ошибок - опять же, если у одного человека есть bus-фактор, то он как кодовнер может отвалидировать и исправить ошибки еще до влития куда-либо, их потом не нужно искать!
4. Код-ревью как "о офигеть, я не знал что так можно" - я вот не знал, что в JS стало можно обращаться кtestString[0], вместоtestString.charAt(0), и пусть конкретно это - минорное и незначительное знание, но если это будет касаться чего-то крупнее? Человек с любым опытом может не знать/забыть какие-то вещи.
Испортить действительно можно всегда, и 5 обязательных аппрувов на изменение отступов - не нужно, но кодовнерство и сама практика ревью кода в принципе - благо почти со всех сторон. Лично я не знаю примеров, где ревью кода не нужно было бы вообще как процесс, а еще я думаю, что лучше однообразие, и пусть кому-то придется пойти и поставить аппрув на этом дурацком отступе, но лучше так, чем кто-то по ошибке сможет влить и выкатить в прод без единой проверки второго человека (ведь ручное тестирование тоже нужно не всегда, верно?).

MadMaxLab
25.07.2023 05:29+2Пожалуйста приложите ссылку на эту статью к вашему CV, чтобы нанимающие вас люди не тратили на собеседование свои ресурсы.
dsh2dsh
25.07.2023 05:29-3Нет возможности поставить плюс, поэтому словами напишу: браво! Сразу видно опытного человека, который походил по многим граблям. А во многих комментаторах, кстати, сразу видно людей, по этим граблям не ходившим, но зато с мартинами и бандами четырёх на перевес.

Ramayasket
25.07.2023 05:29-1Сказанному здесь есть математическая основа: https://habr.com/ru/articles/656773/
varanio говорит о том, что ничто не должно быть возведено в абсолют, т.е. золотая середина, гармония (смотрим формулу).
Отличная статья!
rmrfchik
25.07.2023 05:29+2Ну это же три стадии профессионализма:
Делать по правилам
Придумывать правила
Нарушать правила

background_space_jpg
25.07.2023 05:29точно)
а потом дорогой друг на стадии 1, на пике Даннинга-Крюгера, с бешеными глазами осуждает тебя за несоблюдение паттернов из десятых годовrmrfchik
25.07.2023 05:29Не обязательно на пике. Обычная защитная реакция, все через это проходили. Даннинг-Крюгер это, скорее, про патологию, про яму, из которой человек не может выбраться.
А неофит может дойти до третьего этапа, главное не оставаться на первом вечно.
On_Luck
25.07.2023 05:29+3заповеди, правила
Если DRY, KISS и иже с ними доведено именно до непреложных правил и заповедей, то тут явно что-то не так. Если все еще и утрируется, как в примерах, то это уже надо звать людей в белых халатах. Можно же и SRP интерпретировать как необходимость создавать отдельное DTO для каждой операции над основным объектом...
Если это опытный программист, и в большинстве случаев поступает разумно, то может и не надо его ограничивать всякой фигнёй — это уменьшение эффективности, да еще и снижение мотивации
Ядро проекта пишем на Java, добавляем кусок на Python, пара кусков на Go, еще один прям микро-микросервис на PHP, обработку данных делаем на С++ и немного макросов в Excel.... Зато все очень эффективно и замотивировано было сделано. А потом разработчик, который был ответственен за вот эти все языковые "причуды", увольняется и вам приходится искать такого "многофункционального", эффективного и замотивированного разработчика на проект с непонятным стеком. Нормальная идея, да.
По факту же, DRY & KISS & другие заголовки - это скорее принципы, концепция, если хотите, которые позволяют держаться в некоторых рамках и с большей вероятностью получить на выходе качественный код, с которым будет удобно дальше работать, независимо от смены состава команды. И их нужно не просто прочитать и запомнить, а именно обдумать почему, что, как, где можно отойти, где нельзя и т.д. Все это приходит только с опытом.
И какие-то минимальные строгие рамки должны быть, иначе есть немалая вероятность, что на выходе получите кусок "продукта", с которым дальше никто не захочет работать, ибо разгребать авгиевы конюшни - неблагодарное дело.
SpiderEkb
25.07.2023 05:29Ядро проекта пишем на Java, добавляем кусок на Python, пара кусков на Go, еще один прям микро-микросервис на PHP, обработку данных делаем на С++ и немного макросов в Excel.... Зато все очень эффективно и замотивировано было сделано.
Ну не надо в крайности.
У нас основная бизнес-логика пишется на RPG Но есть достаточное количество низкоуровневых вещей, которые удобнее и эффективнее писать на С/С++ (более того, платформа позволяет вообще линковать модули на разных языках в один программный объект). А в RPG код еще можно вставлять SQL выражения - выборка скулем, обработка на RPG, например.
А еще есть CL - командный язык системы (тоже компилируемый) - на нем тоже иногда всякие небольшие программки пишутся, те же инсталляторы поставок.
Естественно, что разработчиков так и готовят - RPG основной язык, CL должен знать основы, С/С++ - бонусом.
И вот как-то нет проблем, знаете-ли...
Kanut
25.07.2023 05:29+1И вот как-то нет проблем, знаете-ли...
Допустим я устроился к вам на работу и решил начать писать на Java. Мне это разрешат или нет?
SpiderEkb
25.07.2023 05:29У вас это просто не получится :-) Тут нет джавы на центральных серверах.
Потому что жрет много ресурсов и все равно работает медленнее того же RPG или C/С++.
Ну и те задачи, которые нам приходится решать на джаве просто не напишете - ни взаимодействия с БД там не будет (то, что на RPG пишется), ни низкоуровнего взаимодействия с системными сервисами (теми же "машинными инструкциями").
Исхитрится как-то, наверное, сможете, но ни одна поставка ваше нагрузочное тестирование не пройдет - там очень жестко смотрят и на время и на утилизацию CPU.
У нас есть вебсервисы на джаве, но под них отдельная машина в кластере выделена чтобы основные сервера не грузить. Да и логики там никакой нет преобразовать данные к нужным форматам да дернуть соответствующий сервис-модуль. Там сейчас, по-моему, вообще автогенератор для этой хтони есть - по специальному описанию сам генерит готовый код.
Kanut
25.07.2023 05:29+1У вас это просто не получится :-) Тут нет джавы на центральных серверах.
То есть меня ограничат? Это однозначно уменьшит мою эффективность и снизит мотивацию… :)
SpiderEkb
25.07.2023 05:29А вам на берегу обозначат стек с которым аридется работать. Не нравится - за шиворот никто тянуть не будет. Просто найдете себе другое место.
Тут речь идет о том, на чем получается наиболее эффективно, а не о том, на чем кому-то нравится писать.
Если вы собеседуетесь на пощицию водителя карьерного самосвала никому не интересно насколько вас мотивирует вождение спорткара.
Wan-Derer
25.07.2023 05:29Тут нет джавы на центральных серверах.
Потому что жрет много ресурсов и все равно работает медленнее того же RPG или C/С++.
Честно говоря, это звучит максимально странно. Нет, конечно, жава (плюс жава-машина) потребляет память. И конечно какая-нить математика на жава будет работать медленнее чем на Ц++. Но ведь обычно программа не работает, а ждёт :) пока отработает какой-нибудь ввод/вывод.
Поэтому жава давно умеет в параллельность/асинхроннось (правда, это приводит к ещё большему жору памяти). Это позволяет компенсировать "медленный" язык более плотной "упаковкой" потоков исполнения.
Ведь всякая Кафка/Кассандра/далее-везде написаны на жава и никто особо не страдает что они медленные.
Другое дело что спец-язык является предметно-ориентированным и его компилятор сразу знает какие места надо максимально оптимизировать. И набор выразительных средств тоже заточен под предмет, поэтому краток и ёмок. Не то что в ц++: куча крутых команд борются за включение в стандарт "своих" фишек, поэтому в стандарте есть всё! И даже жаву вон прогнули на
var, непонятно зачем :)SpiderEkb
25.07.2023 05:29+2Но ведь обычно программа не работает, а ждёт :) пока отработает какой-нибудь ввод/вывод.
Здесь это не так. Весь основной код, реализующий бизнес-логику, работает в фоновых заданиях. Он не ждет ничего (ну некоторые классы задач ждут события какого-то). Он должен максимально быстро и с минимальными затратами ресурсов процессора (в периоды пиковых нагрузок утилизация процессора может достигать 90%, а это, на минуточку, Power9 - 4 сборки по 4 проца, каждый 12 SMT8 ядер - итого 1536 параллельных потоков на сервере). С памятью попроще - там только оперативки (на считая виртуальной) 12Тб стоит (насколько знаю).
И тут надо понимать, что ваша программа не одна на сервере. Там параллельно работают десятки тысяч заданий. И подавляющее большинство из них - mission critical.
Ну вот просто пример - Вася через мобильное приложение отправляет Пете по номеру телефона 5 000 рублей. Для этого мобильное приложение должно у Васи спросить с какого счета? А хватит там денег? А Петя это кто - на какой счет в какой банк?
После всего этого формируется платежный документ и отправляется в систему расчетов. Там он прогоняется через комплекс проверок (в не террорист ли Петя? А нет ли у Васи запретов на счетах?...) - там порядка десятка проверок, на основе которых принимается решение о том, пропустить платеж или отправить его на ручной контроль в финмон с указанием что именно вызвало подозрения...
И таких платежей (и каждый контролируется!) через банк за сутки миллионы проходят. И это только малая толика того, что там на серверах крутится.
Расписывать даже то, что я знаю и с чем сталкивался - много страниц текста.
Ну и такой момент. На нашей платформе программный объект содержи не только исполняемый, но и т.н. TIMI-код (машинные инструкции - что-то типа ассемблера, но уровнем повыше). И метку под какой именно проц собран исполняемый код.
Если эту программу перенести на другой комп с другим (более новым, например) процем, то при первом запуске система обнаружит несоответствие и пересоберет по TIMI коду исполняемый с максимальной оптимизацией под тот конкретный процессор на котором все это здесь и сейчас работает.
А джава... Это в любом случае интерпретатор. Пусть байткода, но интерепретатор. Т.е. оно по определению более ресурсозатратно и менее эффективно чем машинный код предельно оптимизированный под конкретный проццессор.
В общем, все это уже давно проверено, испытано и обсосано. И выбор стека, набор нефункциональных требований - все это обосновано опытом работы и мночисленными нагрузочными тестами. Вплоть до рекомендаций когда и где лучше использовать всякие сортированные списки ключ-данные, а когда и где - статический сортированный массив с двоичным поиском по нему.
Wan-Derer
25.07.2023 05:29Спасибо, интересно. А ещё интересно как это всё внедрялось исторически. Альфа же один из первых коммерческих банков, да и всякие цифровые услуги они внедряли в первых рядах. Там сразу влезли на технологии IBM или были какие-то промежуточные метания?
On_Luck
25.07.2023 05:29+1И вот как-то нет проблем, знаете-ли...
У вас есть четко установленные рамки. Это разумный подход, без них - проект превратился бы именно в такую мешанину технологий в разных модулях.
Вы определились с ядром системы (IBM RPG, как я понял). Применение С/С++ - обосновано удобством разработки и быстродействием, а значит у вас в команде все (или какая-то часть) понимают и умеют писать на этих языках. И т.д. У вас все равно установлены определенные рамки по разработке, по допустимым технологиям и т.д.
Давайте просто допустим что в вашей команде я новенький и единственный знаю Python, в добавок к текущему стеку. Получаю задачу сделать какую-то фишку и я ее уже делал на Python в другом проекте, и хочу применить его здесь - это будет более эффективно, с точки зрения времени разработки, и более мотивированно, т.к. я смогу закрыть задачу. Правильно? Но что будет если никто не знает Python, или на условном С++ модуль будет работать быстрее?
Вы не можете по своему желанию или просто потому что знаете как что-то сделать на условном Python, использовать именно его для разработки какого-то модуля. Вам так же необходимо, как минимум, обосновать необходимость его применения перед командой и убедиться что есть другие разработчики, которые "умеют в Python". Это и есть те самые "ограничения всякой фигней", которые просто необходимы, дабы кодовая база оставалась в более-менее адекватном виде.
Если нет вообще никаких ограничений, то разработка очень быстро может скатиться в "Повелителя мух"
SpiderEkb
25.07.2023 05:29Давайте просто допустим что в вашей команде я новенький и единственный знаю Python, в добавок к текущему стеку. Получаю задачу сделать какую-то фишку и я ее уже делал на Python в другом проекте, и хочу применить его здесь - это будет более эффективно, с точки зрения времени разработки, и более мотивированно, т.к. я смогу закрыть задачу. Правильно? Но что будет если никто не знает Python, или на условном С++ модуль будет работать быстрее?
Специфика в том, что "будет работать быстрее" здесь является абсолютным приоритетом.
Если вы знаете Питон и умеете Питон и хотите Питон - вам не надо идти к нам, а надо искать место где будет Питон. И это сразу проговоаривается "на берегу".
Условия такие - вам будет дано три месяца (и персональный наставник) для изучения технологического стека (платформа + язык). Официально это называется "испытательный строк", но на самом деле просто обучение т.к. готовых разработчиков под этот стек очень мало. ТД подписывается с первого дня, полная оплата с первого дня, отпуск, регулярный бонус - все с первого дня (единственное - ДМС и НС .оформляются после трех месяцев).
Но никто не заставит сразу что-то делать реальное. Сначала учебные задачи, потом потихоньку переход к несложным реальным. Обычно люди через полтора-два месяца уже что-то несложное делают сами.
Во главу угла в разработке здесь всегда ставится эффективность полученного кода (быстродействие, утилизация CPU) - все это проверяется на обязательном нагрузочном тестировании. Технологический стек жестко определен. Кроме того, есть достаточно объемные "нефункциональные требования" - что можно что нельзя. На самом деле правил очень много. Кому все это не нравится - уходит. Хотя особой текучки у нас нет.
On_Luck
25.07.2023 05:29Специфика в том, что "будет работать быстрее" здесь является абсолютным приоритетом.
Технологический стек жестко определен. Кроме того, есть достаточно объемные "нефункциональные требования" - что можно что нельзя. На самом деле правил очень много.
Так в этом и суть - у вас есть правила и ограничения на стек, которые необходимы именно вашей команде. Эти правила были обоснованы, а не придуманы с потолка. Они призваны решать множество вопросов связанных с разработкой продукта, его приоритетов, кодовой базой и т.д. И если кто-то решит написать кусок проекта на Python, даже если он будет работать быстрее аналогичного кода на IBM RPG и С/С++ - это будет порицаться, надо будет переделывать на имеющийся стек, потому что есть ограничения.
В статье же прямо говорится, что подобное ограничение - "неразумно" и нуждается в переосмыслении. Прочитайте пункт 4 ("Мы пишем только на таком-то языке") в статье.
Дальше идет не менее важный кусок:
Если это опытный программист, и в большинстве случаев поступает разумно, то может и не надо его ограничивать всякой фигнёй — это уменьшение эффективности, да еще и снижение мотивации
И ежу понятно, что вникнуть в суть вашего стека и сделать задачу, в сравнении с реализацией этой задачи на известном кандидату стеке - менее эффективно по скорости разработки и меньше мотивирует кандидата, т.к. вместо написания кода и получения плюшек за сделанную задачу - придется потратить больше времени, лазить по документации в поисках нужных функций и только когда-то потом сделать задачу.
Но несмотря на это, ограничения стека разумны и необходимы, чтобы итоговый продукт не превращался во франкенштейна.SpiderEkb
25.07.2023 05:29+1Так в этом и суть - у вас есть правила и ограничения на стек, которые необходимы именно вашей команде. Эти правила были обоснованы, а не придуманы с потолка.
Ну... Не то чтобы придуманы. Есть чисто технически ограничения. Например, Питона у нас нет. На нашей платформе (IBM i). Т.е. оно может быть и есть в природе, но у нас не установлено. Чтобы установить, нужно очень аргументированно обосновывать что это даст реальный результат. Т.е. многочисленные тесты, доказывающие что это реально выгодно с точки зрения производительности, эффективности и т.п.
Конечный вопрос всегда один - "сколько на этом заработает банк?".
И если кто-то решит написать кусок проекта на Python, даже если он будет работать быстрее аналогичного кода на IBM RPG и С/С++ - это будет порицаться, надо будет переделывать на имеющийся стек, потому что есть ограничения.
Если удастся доказать что Питон эффективнее для решения задач чем RPG или С/С++ - будет внедряться Питон. Но это надо доказать.
Здесь все решения выбираются не потому что кому-то хочется или не хочется делать именно так, а исключительно исходя из соображений предельной эффективности. Количество клиентов растет постоянно (три года назад было порядка 36млн, сейчас уже почти 50млн), растет количество бизнес-операций (мне лично приходилось переделывать один модуль, который изначально писался исходя из нагрузки 50 000 операций в сутки, а потом вдруг этих операций стало 5 000 000 в сутки). А железо все то же (железо очень специфическое, так просто не купишь, тем более сейчас). Посему, сейчас огромное количество задач связано с оптимизацией строго кода. Как пример - то, что было написано в 2015-м году и всех устраивало по скорости, сейчас перестало устраивать т.к. ввиду возросшего кратно объема данных работает слишком долго и начинает тормозить остальные процессы в рамках отведенного временного окна. Приходится пересматривать алгоритмы, искать какие-то хитрые пути решения (обычно это кеширование и/или распараллеливание обработки больших объемов данных, если используется SQL, то его т.н. "линеаризация" - избавление от разных group by и агрегатных функций с последующей потоковой постобработкой избыточной выборки). Тут много опыта накоплено уже что и где работает эффективнее.
Если говорить конкретно про RPG - он выбран не просто так. Во-первых, более 80% кода на платформе IBM i написано на RPG. Это специализированная платформа для коммерческих серверов, а RPG язык для коммерческих расчетов (нативные типы с фиксированной точкой, очень гибкие возможности описания сложных структур данных, работа со строками, датой, временем - все это уже есть в языке).
Я с 91-го по 17-й год писал только на С/С++. С 17-го больше пишу на RPG. И когда приходится возвращаться к С/С++ очень часто возникает вопрос - "ну зачем так сложно все? можно же намного проще и удобнее сделать...". Например, почему я должен помнить все эти макросы _MIN_INT и т.п. (которые еще и в разных компиляторах могут быть по разному определены и помнить в каком хидере они определены? Почему я не могу использовать универсальные *loval/*hival которые компилятор сам понимает как минимальное/максимальное значение для данного типа?
Почему я не могу инициализировать поля структуры дефолтными значениями непосредственно при ее описании?
И таких вопросов много возникает.
Хотя с другой стороны некоторые другие вещи на С/С++ пишутся проще и естественнее.
Нет одного какого-то языка на все случаи жизни. Что-то удобнее делать на одном, что-то на другом. И упираться в "я пишу только на С/С++" непродуктивно. Разработчик - это прежде всего подходы к решению задач. А язык - инструмент. Знаешь несколько языков - можешь выбирать наиболее подходящий инструмент для решения конкретной задачи.
Wan-Derer
25.07.2023 05:29А рабочие станции у вас "обычные" или тоже на этой специальной ОС? А IDE и прочие средства разработки/ отладки - "привет из 80-х" или более-менее современно выглядят?
Я без прикола, просто правда интересно каково это, прогать на спецплатформе.
SpiderEkb
25.07.2023 05:29+3А рабочие станции у вас "обычные" или тоже на этой специальной ОС?
Ну, к счастью, время аппаратных терминалов IBM5250 уже прошло.
Сейчас используется эмулятор. Самое простое и доступное - бесплатный пакет от IBM - ACS (IBM i Access Client Solutions) под любой десктоп - Win, Mac, Linux. Там кроме терминала еще много чего есть (работа с БД - посмотреть структуру таблиц, индексы, хранимые процедуры и прочее и прочее, есть "интерактивный SQL" где можно не только запросы погонять, но и посмотреть их "демонстрацию" - план запроса как движок его будет выполнять - что там с покрытием индексами и прочее).

Ну а сам терминал как-то так выглядит
Там уже общение с системой через команды языка CL (отдельная тема)
Каждое окошко терминала - отдельное задание (JOB) на сервере. Открою два окошка - будет два задания. Туту тоже отдельная тема
Все это на обычном компе работает.
А IDE и прочие средства разработки/ отладки - "привет из 80-х" или более-менее современно выглядят?
Долгое время особых альтернатив не было - была только RDi (Rational Development for i) от IBM. Штука мощная, но жутко тяжелая - это Eclipce к набором специфических плагинов для работы с серверами.

К тому же еще и платная...
Сейчас большинство переходит на VSCode - во-первых, к нему есть хороший набор плагинов (тот же IBM i Development Pack и еще ряд полезного)
Ну и свои плагины, по конкретно наши сервера тоже есть у нас.
Самое заморочное - сборка. Когда пришел в банк (в 17-м году) все собирали руками. Это значит закинуть на сервер (через RDi, впрочем, она позволяет и прямо на сервере в объектами работать) все объекты поставки, потом написать программу-инсталлятор на CL, скомпилировать ее на сервере (CL компилируемый язык) и запустить. Оно уже само все соберет.
Сейчас все это автоматизировано гредлом. Пишутся скрипты, запускается гредл на компе, он закидывает все что надо на сервер, сам генерит инсталятор, сам его там компилирует и запускает. Подробности тут
В целом сейчас работает весь цикл CD/CI - Тестовые сборки - с компа на сервер. Поставка для дальнейшего внедрения - git + jenkins + artifactory.
Несколько мешают требования УИБ - с локального компа через VPN невозможно достучаться даже до тестового сервера (и всего что с ним связано - тот же jenkins). Это можно только с виртуалки во внутреннем периметре через VDI. Кто-то постоянно там работает, мне некомфортно. Я предпочитаю на локалке все делать, потом с гит выкинуть, зайти на VDI (у меня под это дело от дельный старый ноут выделен - VDI терминал), там подтянуть из гита и собрать. Т.е. рабочее место дома примерно так:

Справа - VDI ноут (там как раз эмулятор 5250 запущен). Слева - локальный рабочий с допмонитором.
Отладка... Ну вроде как можно в RDi или VSC делать, но я привык к хардкорному встроенному системному STRDBG в терминале.
Там, в принципе, и редактор есть SEU, но он уж слишком хардкорен :-)
Так что в целом ничего такого уж страшного нет. Все достаточно комфортно, хотя и с особенностями.
On_Luck
25.07.2023 05:29+1Нет одного какого-то языка на все случаи жизни. Что-то удобнее делать на одном, что-то на другом. И упираться в "я пишу только на С/С++" непродуктивно. Разработчик - это прежде всего подходы к решению задач. А язык - инструмент. Знаешь несколько языков - можешь выбирать наиболее подходящий инструмент для решения конкретной задачи.
В целом, я согласен с этим утверждением.
Но, для некоторых задач может быть несколько оптимальных инструментов достижения поставленной цели. И здесь необходимо следовать регламентам и правилам, установленным в команде, в том числе и по стеку.


igrishaev
25.07.2023 05:29+3Вброс ради рекламы говно-канала.
varanio Автор
25.07.2023 05:29+195% статей на хабре что-то рекламируют, явно или неявно. Да и сам хабр создан ради денег с рекламы.
Всё, что написано в статье - это то, что я думаю. Это не бессмысленный вброс, как вы написали. И это очень обидно, честно говоря: без аргументов, без обсуждений просто обделать статью. Капец.igrishaev
25.07.2023 05:29Конечно, поэтому самый значимый комментарий вы проигноировали: https://habr.com/ru/articles/750114/comments/#comment_25784076
varanio Автор
25.07.2023 05:29Ой, нет, это тоже атака без аргументов.
Как я должен был почему-то писать статью. Пойду вернусь в прошлое, и перепишу правильно.
Newbilius
25.07.2023 05:29https://habr.com/ru/articles/750114/comments/#comment_25784512
Ну тут то точно аргумент есть, а вы и мимо него прошли ;-)

nivorbud
25.07.2023 05:29+1Согласен со многим. Любые технологии надо применять разумно, а не бездумно (ради моды, выпендрежа и т.д.).
Я, например, раньше всегда пытался предусмотреть возможность изменений всего и вся в будущем, в результате создавал множество абстрактных слоев. Но потом... почти всегда жалел об этом.
Ну, простой пример: для интернет-магазина на джанго делал калькулятор... rest api, json, сериализаторы... Жалею. Не нужно было там этого. Сейчас кайфую от htmx и пары вьюх. Никакого JS, никакого JSON, никаких сериализаторов и прочей абстракции мне в данном случае не нужно.
Или... Здесь на хабре недавно кто-то выложил простенький проект на питоне (вроде на джанго) по сокращению ссылок, который его попросили сделать на проваленном собеседовании. В комментах сразу посыпались советы, что надо было всё сделать в докере, метод по сокращению ссылки вынести из модели в отдельный слой - в модуль services.py (или типа того - для бизнеслогики)... У меня сразу возникает вопрос: А нафига? Зачем для единственного метода (на несколько строк) создавать отдельную абстракцию? Вот одна единственная модель, вот в ней передо мной метод... зачем этот метод выносить в отдельную абстракцию? Потому что модно? И модуль с названием services - ну, так себе, ни о чем не говорящее общее название.
Недавно работал над проектом, обратил внимание, что всё фанатично сделано по всем вышеуказанным канонам: тысячи функций/методов/классов буквально по 1-5 строк, и все они раскинуты по сотням директорий. Функция из пары строк вызывает другую функцию из трех строк, которая вызывает еще пару функций... и т.д., приходилось делать десятки переходов, чтобы понять реализацию. После метания по сотням/тысячам файлов у меня сложилось впечатление, что уж лучше работать с простынями на тысячи строк...
Вот смотрю код Wagtail - там много длинных файлов на тысячу и более строк и... весьма комфортно себя чувствую.
В общем мой вывод: не надо использовать технологии бездумно по шаблону или ради моды. Не надо вводить абстракции ради абстракций.

auddu_k
25.07.2023 05:29Так и на это есть общепринятаярекомендация - избегай преждевременной оптимизации.
Короче в программировании куда ни плюнь, всюду ограничения -)


KongEnGe
25.07.2023 05:29+1Хороший кодревью еще поискать сильно надо. Обычно все вырождается в одну из крайностей:
формальный просмотр глазами, не вникая в суть -- строчки кода неприличных пятен Роршаха не образуют и то хлеб. Это еще довольно безобидный вариант.
парное колупание каждой буквы изменений с автором; от п.1 отличается только тем, что автор занимается пересказом кода, а ревьюер по-прежнему лениво скользит глазами и рандомно ставит вопросы "почему?" В итоге вместо полезных изменений с рефакторингом и погашением техдолга обычно выбирается то, где поменьше про код рассказывать нужно.
Потому что нормальный кодревью -- это, по большому счету, "сделать ту же задачу другим человеком, а потом сверить решения", восходящий к древнему принципу "у дураков мысли-то сходятся". Но никто время на такое в здравом уме в планирование не закладывает.
А случайно выявленные ошибки стиля написания, правил работы с сущностями и т.п. -- на такое при нормальной организации работ давно формальные тесты понаписаны, которые поэффективнее человеков будут.

alexhott
25.07.2023 05:29+5"Я бы пересмотрел вообще всё" - в первый месяц воодушевленно высказывался на ВКС новый разработчик.
Спустя год - "Да в принципе неплохо, а тут вообще зачетно сделано"

Timofeuz
25.07.2023 05:29длина строки должна быть не более чем Y
Такие вещи начинаешь ценить, просматривая на двух панелях изменения в vcs
datacompboy
25.07.2023 05:29Два 4k ultra wide монитора и нет проблем
dsh2dsh
25.07.2023 05:29+1Два 4k ultra wide монитора и нет проблем
Кроме больной шеи, которой приходится постоянно туда-сюда вращать голову, что бы все видеть. Но пока молодой, да, какие проблемы.
datacompboy
25.07.2023 05:29Два 4k ultra wide монитора на расстоянии 4х метров? И всё головой вертеть не надо.. ????

tsypanov
25.07.2023 05:29+2Ручное тестирование замедляет процессы?
Ручное тестирование сильно улучшает качество конечного продукта и позволяет находить ошибки, из-за которых дальнейшая разработка может колом встать. ИМХО, лучше в моменте несколько замедлить процессы, получив качественный продукт и равномерной и предсказуемой скоростью разработки, чем резко сорваться с места и влететь в стену.
medstrax
25.07.2023 05:29-1айтишники любят говорить (особенно в твиттере), какие они избранные интеллектуалы
Это так и есть. Чуть менее, чем все айтишники мнят себя эдакими мессиями, которым положено получать на порядок больше водителя троллейбуса только по той причине, что в молодые годы они не бухали, а изучали условный С++. И неважно, что от водителя троллейбуса в целом обществу куда больше пользы, чем от кучи айтишников, чья цель и задача (преимущественно, конечно, не у всех так) - поднимать продажи коммерсов.
Wesha
25.07.2023 05:29+2"Работа програмиста заключается в том, чтобы заменить ваше рабочее место на небольшой скрипт" (c)
MiraclePtr
25.07.2023 05:29+3то от водителя троллейбуса в целом обществу куда больше пользы
Но есть один нюанс. Айтишники сделали кучу вещей, начиная от CAD/CAM/CAE-систем, в которых этот троллейбус и все его детали конструировались, и ERP-систем через которые поставлялись комплектующие для его сборки, заканчивая прошивкой контроллера асинхронного электродвигателя, без которого этот троллейбус вообще не поедет.
Хотя, казалось бы - их задача была поднимать эффективность бизнеса и экономить деньги коммерса (производителя троллебусов)...
А еще айтишники разработали программы, управляющие электросетью и генерацией, чтобы в проводах было электричество, благодаря которому троллейбус едет, и софт для банковских транзакций, благодаря которому водитель троллейбуса получает зарплату, а пассажиры могут покупать проездные билеты...

anonymous
25.07.2023 05:29НЛО прилетело и опубликовало эту надпись здесь
SpiderEkb
25.07.2023 05:29+1В моем окружении код-ревью зачастую становится культом карго. Нельзя сделать merge request без того, чтобы пара ревьюеров дали свое добро. При этом, пока модуль еще не стабилен, код может меняться несколько раз за спринт, и у ревьюеров начинается день сурка.
А зачем мержить нестабильный код?
Уже писал тут - у нас мерж (с необходимым апрувом ПР) происходит только после прохождения первого этапа тестирования и перед вторым (бизнес-тестом). К этому моменту код уже стабилен.
anonymous
25.07.2023 05:29НЛО прилетело и опубликовало эту надпись здесь
SpiderEkb
25.07.2023 05:29его публикация в репозитории позволит перейти к разработке зависящих от него модулей
У нас разработка зависящих модулей не требует мержа в девелоп. ДОстаточно раскать поставку на нужном тестовом юните.
Я не знаю, что такое "бизнес-тест", но у меня код перед включением в основную ветку должен последовательно пройти статический анализ, модульные, интеграционные, функциональные, системные и приемочные тесты.
Если без лишних подробностей, то есть BRD - хотелки бизнеса. Есть ОТАР - архитектурное решение. На основе всего этого составляется FSD - это уже ТЗ.
После разработки первый этап - компонентное тестирование в тестовых юнитах. Это тест на соответствие FSD. Этим занимается аналитик и тестировщик. На этом этапе в поставку еще могут вноситься изменения.
Когда компонентное тестирование закончено, поставка уходит в бизнес-тест на соответствие BRD. Этим уже занимается заказчик в специальном юните. И в этот момент ветка мержится в девелоп (фактически девелоп соответствует состоянию юнита бизнес-тестов). На этом этапе, если требуются какие-то правки, делается уже следующая версия поставки (на основе ветки девелоп).
Когда все ок, поставка уходит на нагрузочное тестирование, интеграционное тестирование (и то и то на копии промсреды делается), техническое тестирование (тестовая установка на прелайв-среду). И только после всего согласуется внедрение в бой. После чего в гите ветка девелоп мержится в мастер (мастер всегда соответсвует бою).
В силу ряда особенностей платформы все поставки еще хранятся в готовом для раскатывания в нужный юнит виде в специальном юните-хранилище поставок. И все поставки при установке в любой юнит региструются в специальной таблице (мнемоника, версия, дата установки и т.п.). И если ваша поставка является пререквизитом к другой, то в той она прописыватеся как пререквизит и установщик по этой таблице обязательно проверит установлена ли она в юните.
При этом для установки в юнит разработчиков (это такая помойка, там просто проверить что все собирается) или в песочницу (песочницы - копии компонентных юнитов которые могут быть в любой момент пересозданы) можно вообще не занося код в гит - в юнит разработчиков с локального компа гредлом, в песочницу - просто копируем исходники и запускаем инсталлятор.
Вот в сам компонентный юнит - это уже через портал DevOps наш. Для этого поставка должна лежать в артифактори, куда она помещается дженкинсом. А он собирает из гита по указанному коммиту.
anonymous
25.07.2023 05:29НЛО прилетело и опубликовало эту надпись здесь
SpiderEkb
25.07.2023 05:29Ну просто процессы везде выстраиваются по разному. Нет каких-то единых правил (есть общие направления в рамках которых каждая команда свои правила вводит).
У нас только разработчиков, которые пишут под центральные сервера (те, что на IBM i) сотни две (наверное, точно не скажу - много команд по направлениям разным - лимиты, тарифы, ядро, комплаенс, пластиковые карты, система расчетов, кассовый модуль, депозиты...). У каждой команды свой круг задач, свой проект в гите. Пересечения незначительны (хотя они есть, конечно).
Ну и есть жесткое правило - любое, даже самое минимальное, изменение кода влечет за собой полный ретест всего модуля.
san-smith
25.07.2023 05:29А когда наступает это волшебное время для ревью и рефакторинга в вашей модели?
Есть все основания полагать, что послебыстрее выпустить MVP и получить обратную связь
стейкхолдеры попросят проделать то же самое с новой бизнес-хотелкой.

sharpMouse
25.07.2023 05:29+3Ревью дает две важные вещи:
Сам факт того, что код будет кто-то смотреть и оценивать, усиливает внимание разработчика к коду. Одно дело быстро сделать правочку для себя, и другое - показать свою работу коллегам.
Обмен мнениями повышает уровень и культуру разработчика. Особенно если он начинающий, а ревьюит его опытный. В первую очередь это касается интерфейсов и взаимодействия между компонентами, абстракций. Но и для остального ревью это хороший способ привить культуру разработки.

Soukhinov
25.07.2023 05:29Самое первое нарушение принципа DRY — использование одного и того же имени переменной в нескольких местах. То есть именованные переменные нарушают DRY, особенно если эти имена длинные (тогда получается много повторений в проценте от общего объёма кода).
Альтернатива есть — так называемое «бесточечное программирование» (tacit programing). Удачи в чтении этого кода (это APL):
((+.×⍨⊢~∘.×⍨)1↓⍳)17Имеем код без повторений, больше напоминающий мусор.

dolovar
25.07.2023 05:29Это банальная лень, экономия энергии. Пресловутые система 1 и система 2.
Вот тут я бы поспорил. Во-первых, лень с экономией - миф, нет такого стремления. Есть эмоция усталости и потребность "прекратить бесполезное", но они не про экономию, а про перестройку поведения, изменение приоритетов для выбора следующего действия.
Во-вторых, систем не две, и деление на системы (large-scale brain networks) не имеет отношения к экономии. Следовать плану - это потребность, использовать шаблоны - это оптимизация, такие механизмы разума встроенные или естественные, но они не про деление на системы.
В статье тоже рассказано о шаблоне - золотой молоток обыкновенный. Встречается повсеместно, примеры найти легко, они получаются яркими, рассказывать о них приятно, публике нравится. Более общее правило - если каким-то приемом мы пытаемся уйти от какой-то нехорошей крайности, то нужно следить, чтобы не приблизиться к крайности противоположной и тоже нехорошей. Баланс рулит. Если кто-то слишком часто хватается за привычный инструмент, то это не приведет к добру. Да, привычки нужно регулярно пересматривать, освежать список используемых инструментов.
ildarin
25.07.2023 05:29В фунции не должно быть более чем X строк В таких случаях хочется спросить, почему именно столько, а не на одну больше или на две меньше.
Сколько помещается в один экран без прокрутки.
Статью в целом можно описать одной фразой: "Думайте, прежде чем повторять за другими", вообще это не только разработки касается.
А так можно любой полезный совет/принцип довести до абсурда: SOLID, dependency inversion - возникает ситуация, когда разработчик вместо использования int - делает свой интерфейс и передает его управляющему коду для реализации.
Для меня это все очевидно, но для кого-то может показать путь к критическому мышлению.

botyaslonim
25.07.2023 05:29+1Ещё не хватает пункта "а нафига этот ваш Git, а на jQuery раньше скрипты писал и сразу в прод катил".
Вы не тимлид, вы хайпожор
smart_alex
25.07.2023 05:29У каждого программиста между ушей есть нейросеть, которой он пользуется.
Мало того, у некоторых есть даже производные от неё — ум, разум, интеллект и т. д.
А по поводу кода — да, он должен строится не в соответствии с догмами, а в соответствии со здравым смыслом и целесообразностью.
18741878
Зачет :) Смачно плюнули