
❯ Та девушка, которая поёт
Начнём со сжатого экскурса в историю.
После того, как люди научились синтезировать произвольные звуки, инженеры всего мира постоянно предпринимали попытки сделать его похожим на человеческий голос. Обыкновенный TTS, вполне пригодный для чтения текстов, существовал ещё в середине прошлого века, однако же заставить его именно петь не удавалось.
Всё изменилось с началом исследовательского проекта в Университете имени Пумпеу Фабра в Испании, возглавленного Хидеки Кенмоти и профинансированного компанией Yamaha. Результаты этого исследования впоследствии вылились в коммерческую технологию под названием Vocaloid.
Первые вокалоиды звучали довольно примитивно. По сравнению со всеми прошлыми технологиями это был прорыв, но оглушительным успехом назвать их было сложно. Ровно до тех пор, пока компания Crypton Future Media в 2007 году, взяв за основу движок Vocaloid 2, не выпустила то, что впоследствии совершило фурор в концепции гострайтинга: Хацуне Мику.

Хацуне Мику собственной персоной
Секретом успеха стал не только и не столько удачный голос, сколько то, что это по сути была «поп-звезда в коробке»: при покупке вы получали не только саму программу для синтеза голоса, но ещё и возможность использовать самого персонажа по Creative Commons CC-BY-NC.
Миловидный персонаж с новым для многих голосом лёг на благодатную почву активно развивавшегося тогда культурного сегмента японского интернета. Эпоху удачнее придумать было нельзя — активный бум User-Generated Media, параллельно с переползанием от Shockwave Flash к видеоконтенту на тогда ещё совсем молодом видеохостинге Nico-Nico Douga. Но главным плюсом было даже не это — ведь в отличие от настоящей, живой поп-звезды, Мику просто физически не могла отказаться спеть то, что вы ей там понаписали.
Это породило множество споров и дебатов, а также западающих в душу песен. Среди прочих отличился, например, deadballP — запаковывая в свои песни с лютейшим джазовым вайбом абсолютно неожиданные слова. Порой настолько неожиданные, что сам Nicovideo композитора неоднократно банил за «нарушение общественного порядка». Для примера, предлагаю читателям ознакомиться с его джазовой импровизацией с лейтмотивом «вот ты выпей молоко — сиськи будут о-го-го!» :-)
Бум user generated content подкрепился выходом игры Project DIVA на PSP, куда взяли самые популярные песни, разбавив 3D-графикой для видеоклипов, до кучи добавив возможность создавать свои клипы и карты из произвольных MP3-файлов.
Таким образом, разработчики получили не только дико популярную франшизу, но и неиссякаемый поток заведомо успешного готового контента для неё.
Редактирование сцены в Project DIVA на PSP:
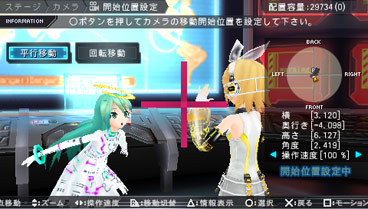
А популярность была на внутреннем рынке просто невообразимая! Первая версия игры побила все топы продаж в свой сезон, и разлеталась как горячие пирожки.
Редактирование карты в Project DIVA на PSP:
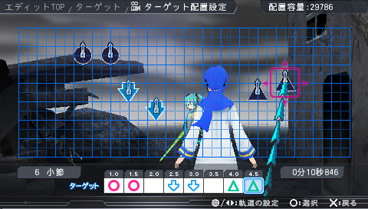
Вот, например, было подразделение SEGA AM2 — то самое, которое подарило нам такую классику, как Shenmue, Out Run, Virtua Fighter или Daytona USA. Его на тот момент возглавлял Макото Осаки — и даже ему не удалось получить копию игры по внутренним каналам, пришлось покупать в обычном магазине.
Впрочем, игра ему нужна была не для того, чтобы отдохнуть в свободное время, а ради того, чтобы внутри своей команды изобразить порт её на движок Virtua Fighter.
И вот когда порт был уже готов, и Осаки было уже пошёл к продюсеру Уцуми Хироши с идеей сделать аркадную версию Project DIVA — другой сотрудник AM2, Ясуси Ямасита, предложил: «А почему бы нам эти наработки не использовать для создания живого концерта?»
Идея менеджменту понравилась, за каких-то два месяца кранчей они подготовили революционный ивент — Miku Fes 2009. (Обо всей хронологии — как-нибудь в другой раз :-) Концерт собрал аншлаг, начало было положено — Мику и по сей день выступает с концертами чуть ли не каждые полгода, собирая огромные залы.
(Один из самых любимых концертных треков последних лет. До сих пор не верится, что мне выпала честь слушать его прямо из первого ряда!)
А писать для неё песни, в отличие от какой-нибудь Бритни Спирс и иже с ними, могла не только лишь конкретная команда шведов, а любой человек с мало-мальски развитым слухом и каким-никаким компьютером — прямо таки народное творчество во всей красе.
❯ А внутри у неё — неонка^W процессор!
Возможность создавать записи, конечно, весьма хороша, но ведь музыку зачастую принято исполнять живьём. В наше время Ямаха выпускает что-то наподобие клавитары на базе своей платформы от обычных цифровых клавиатур:

(к сожалению, на выставке разобрать и сфоткать процессор и разводку платы не разрешают :-))
Однако среди всего многообразия способов извлечения звуков из Мику и Ко. примерно 11 лет назад проскакивал такой интересный прототип, который и запал мне в душу:
Известно о нём было только то, что рабочие название технологии — eVOCALOID (Embedded Vocaloid). Впоследствии вышел пресс-релиз, в котором анонсировали микросхему с его поддержкой — YMW820-S.

Какая-то внутренняя девборда для чипа, которую они прозвали «RuSoBA» = the Real acoUstic Sound Operation Board with Amp %) [via]
Судя по даташиту и параметрам, мне думается, что это какая-то переработка старых чипов из серии Mobile Audio — из тех, что стояли в корейских телефонах с синтезом голоса для уведомлений.
Самым известным устройством на базе этого чипа был Pocket Miku — стилофон от Gakken из серии журналов «Otona no Kagaku».
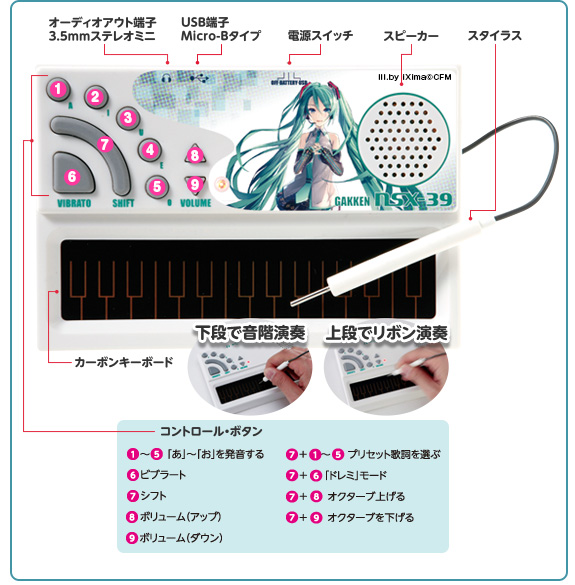
[via]
Сколько-то лет назад я покупал такой на Yahoo! Auctions, чтобы переслать другу, и стоил он очень недорого. Тогда я ещё удивился, что оно умеет работать как USB-MIDI синтезатор.
Поэтому, когда в этом году полез во всю эту MIDI-тему, то подумал — MIDI-to-USB-host адаптеры штука обыденная, а стилофон стоит копейки, можно бы что-то и сделать! Но тут меня ждал облом — ценник на эти штуки за последние пару лет вырос примерно на порядок с лишним.
За такие бабки уже и клавитару купить можно, даром что в ней миди-входа нет
Однако вдумчивое чтение пресс-релиза навело на ещё один вектор — некий шилд для ардуины eVY1 Shield, выпускавшийся компанией AIDES.
Более того, он выпускался и в виде готового устройства eVY1 BOX, но и дизайн и цена (¥27,500 = примерно $250) оставляли желать лучшего.

Зарядник от макбука словил кризис среднего возраста и решил податься в музыку

Поэтому я ухватил один из каким-то чудом оставшихся шести «сырых» модулей на амазоне безо всякой обвязки и решил скрафтить свою коробочку. И вот через пару дней у меня в руках самая дорогая микросхема в моей жизни:

С обратной стороны видим уже знакомый по Pocket Miku процессор GPEL3101A и SPI-флешку — то есть в теории оно должно суметь запустить и голос от Pocket Miku!

Быстренько раскидываем на макетке:

Для минимального включения достаточно лишь пары разъёмов и 10кОм-резистора с VBus на USB_SENSE
И да, оно поёт! Правда тихо и шумно, ведь единственный близкий к линейному выход — «наушниковый», использующий ЦАП внутри процессора GPEL, который и дудок, и жнец, и вообще — трындец, в смысле сочетает в себе полный ящик переферии от флеш-контроллеров и прочих USB до генератора вторичных напряжений питания и ЦАП/АЦП :-)
❯ Но, как говорится, есть нюанс...
Поёт этот модуль голосом VY1, также известным как MIZKI — собственный голос от Ямахи. Что, в принципе, логично, ведь Мику для этого модуля не лицензировали. Но хотел-то я чиптюн именно с Мику!
Копание в различных слоях интернета приводит к домашней страничке некоего Hummtaro, который переделал программу-программатор от eVY1 в утилиту для сохранения и прошивки ПЗУ целиком (а я уже за прищепкой на алик бежать хотел...). Также он заботливо забыл удалить оттуда копию ПЗУ своего Pocket Miku :-)
До кучи у него же на канале есть видео, где он наоборот прошивает голос VY1 в Pocket Miku.
Поэтому качаем тулзы, дампим ПЗУ и смотрим, сходства и отличия.
Кажется, где-то тут и начинаются голосовые сэмплы:
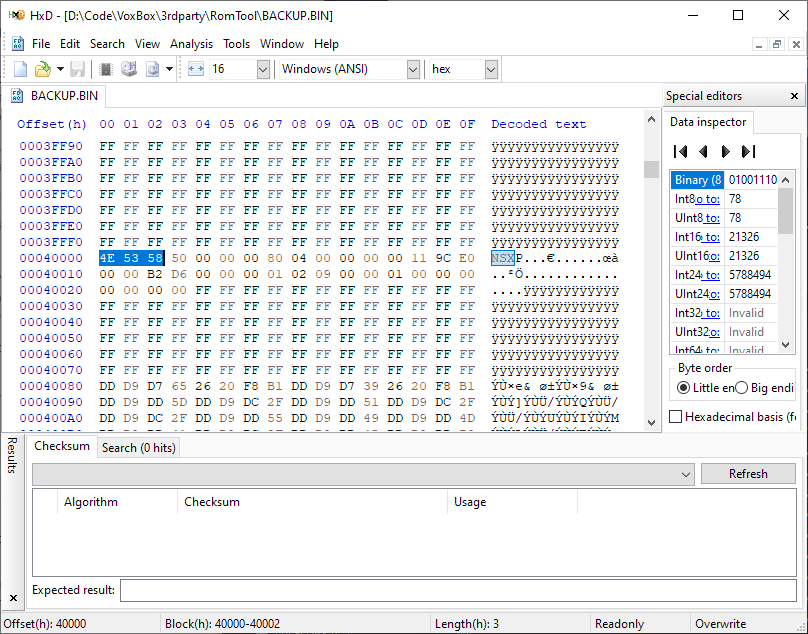
Сразу в глаза бросается большой блок данных на #40000h, который, судя по всему, и есть войсбанк. О, ну значит всё так просто! Удаляем из дампа ПЗУ родной блок данных, вставляем таковой из Pocket Miku — впритык, но поместилось. Прошиваем!
И первой композицией, которой мы насладимся в исполнении аппаратной Мику, будет 4'33" Джона Кейджа!
Пытаясь исполнить эту композицию на пианино, мой брат сломал обе ноги и руку:

Всё потому что на выходе ноль. Зеро. Ни-че-го. Ни откликов на ноты, ни даже на SysEx, который должен показать версию прошивки.
Значит, пришло время доставать драконоголовую змею и разбираться, что же там в прошивке. Но вот беда — есть бинарный блоб, который ни по какому адресу грузить непонятно, ни какая у него структура в целом неясно. Всё, что известно о процессоре — это то, что внутри ARMv7-ядро.
Эксперимента ради грузим прошивку от Pocket Miku. Ожидаемо, не работает, но на одном из пинов модуля, отмеченном как «UNUSED», появляется сигнал, подозрительно напоминающий UART. Цепляемся туда консолькой и, о чудо, там логи!
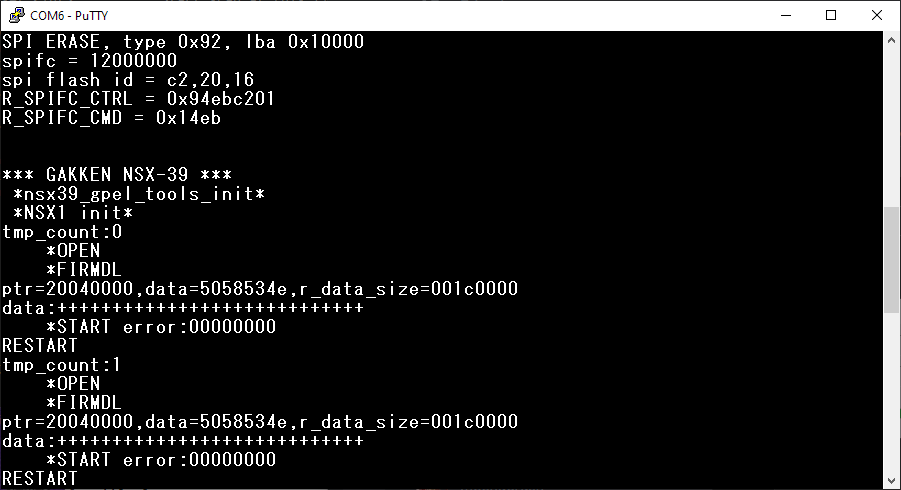
Фраза
ptr=20040000 как бы намекает нам, что наш блоб прошивки в адресном пространстве процессора попадает на адрес #20000000h, но как убедиться, что это не отдельный раздел, и исполняемый код находится в том же блоке адресов? Просто находим в блобе текст
ptr=%x,data=%x,r_data_size=%x… и дописываем к нему .%08x%08x%08x %)Всё развалилось, но не до конца:
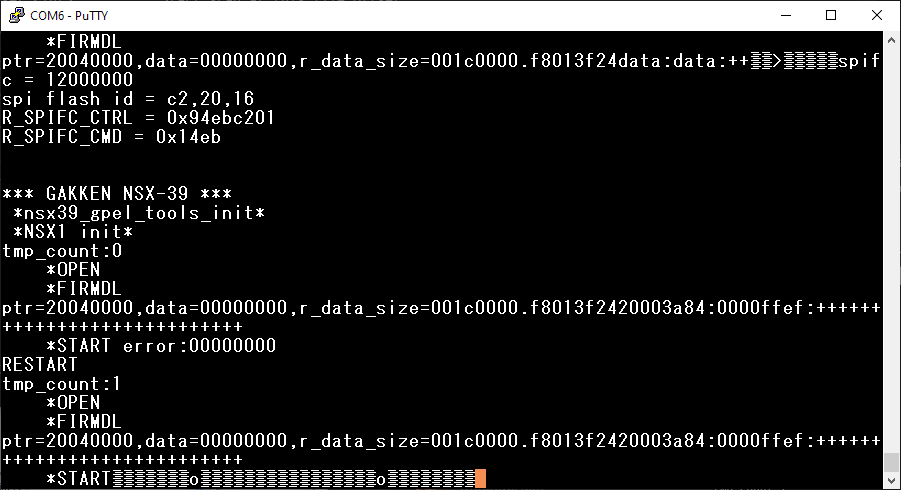
После строки логов видим ещё два 32-битных числа — первое является чем-то непонятным, а вот второе — #20003a84h — явно адрес того кода, который вызвал функцию логирования.
Как это работает? Очень просто: каждый следующий аргумент для формирования строки через printf берётся со стека, поэтому если мы возьмём оттуда больше, чем было заложено разработчиком — например, добавив ещё токенов форматирования — то напечатается то, что было на стеке дальше. В нашем случае там был и адрес возврата, который указывал на инструкцию, следующую за той, которая вызвала печать этой строки.
Грузим файл в гидру по адресу #20000000h, прыгаем на смещение #3a84h, жмём Disassemble — и всё взрывается, как попкорн в микроволновке.
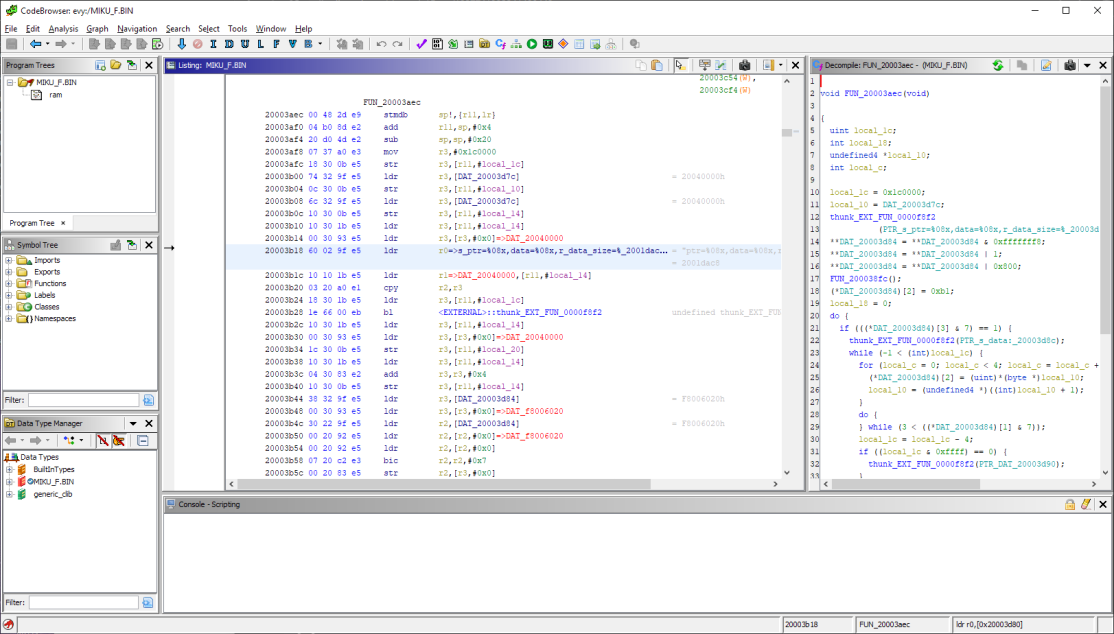
Дальше идёт полторы недели медитации над листингом с постоянными попытками перетащить куски инициализации DSP из прошивки Pocket Miku в прошивку eVY1, на случай если просто-напросто не выделяется достаточно памяти перед заливкой войсбанка в него. Но всё тщетно.
В какой-то момент от безысходности я начинаю просто рандомно обрезать войсбанк Мику и прошивать его — и замечаю, что если обрезать его по размеру родного голоса, но сохранив последние 4 байта как в оригинале, то частично всё начинает работать. Ну, пока не попытаешься воспроизвести фонему, которая в прошивку не попала :-)
Постепенно увеличивая блок данных, бинарным поиском прихожу к тому, что всё ломается на превышении прошивкой размера в #1CFE00h байт. Не, ну если бы хотя бы #1D0000h, я бы подумал, что контроллеру флешки не выделяется окно достаточного размера, а так это выглядит как какой-то глупый баг.
Беру родное ПЗУ, добавляю по подозрительному адресу 16 байт мусора — не работает, хотя ту часть памяти мы вообще читать не должны, ведь родной войсбанк существенно короче!
И почти тут же натыкаюсь на странный кусок кода, которого в прошивке Pocket Miku не было. Судя по всему, он проверяет, есть ли по этому самому подозрительному адресу какие-то данные, и если есть — инициализирует USB и вешает систему.
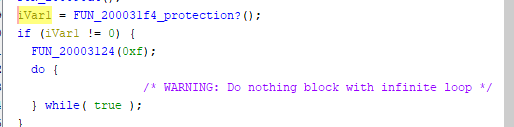
С учётом, что у нас одно ядро и один поток — где-то тут всё и закончится
Обидно, могли бы хоть рядом пасхалочку оставить :-(

Патчим эту проверку и ещё пару похожих, заложенных по разным адресам в разных функциях — и ура, играет, работает!
❯ Собираем в MIDI-модуль
Во-первых, раз уж у нас теперь есть два голоса, почему бы не иметь возможность их переключать? Благо, это делается очень просто — так как линия Chip Select у флешки инвертированная (активна при лог. «0»), то достаточно лишь двух элементов ИЛИ и одного инвертера, чтобы получить схему, переключающую флешки по необходимости:
Сигнал ALT_ROM выбирает, используется основное или дополнительное ПЗУ, а остальные идут напрямую на шину самого модуля:
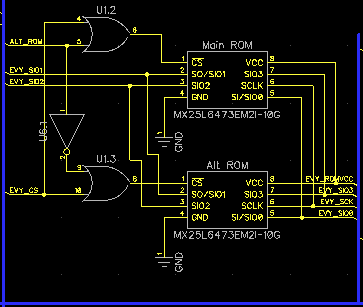
После переключения ПЗУ просто дёргаем RESET у модуля и он после перезагрузки начнёт петь другим голосом.
Во-вторых повесим на GPIO модуля светодиоды, раз уж они были на родном шилде. Правда не то в даташите ошибка, не то я криво читал — выходы GPIO там Active Low, поэтому в моём включении они постоянно горят и периодически гаснут, а не наоборот.
Так делать не надо, делать надо не так!
Добавляем операционник для того, чтоб привести звук хоть немного к линейному уровню, обыкновенную схему MIDI-входа как в прошлый раз (заменяя каждый логический буфер на пару инверторов, благо их у нас тут в достатке), и ардуину с экранчиком чтобы ловить SysEx'ы переключения ПЗУ и заодно отображать находящиеся в данный момент в ОЗУ фонемы.
Охапку дров, и плов готов!
Раскидываем на макетке, раунд 2:

Кажется, стоило наконец уже зарегистрироваться на JLC PCB...

Без аудиофильских конденсаторов звучать будет точно так же, но радости никакой не принесёт
В прошлый раз в корпусе осталось много свободного места, поэтому на сей раз я взял корпус на размер меньше. Конечно же, теперь его не хватило и всё пришлось сильно утрамбовывать! Также в этот раз взял вместо клавишного выключателя тумблер, так как с клавишным ощутимо проседает напряжение в зависимости от везения.

До кучи добавился USB-хаб, чтобы можно было прошивать оба чипа без разборки устройства
И вуаля, готово!


❯ Программирование музыки
Теперь нужно написать хотя бы один MIDI-файл, чтобы на этом всём слушать. Из всего обширного списка дополнительных команд нас интересуют только несколько:
F0 43 79 09 10 07 00 aa bb cc F7: отключение звука для определённых каналов:- Биты в позициях
aa, bb, ccотключают воспроизведение части каналов - Например, паттерн
7E 7F 7Fоставит только первый канал, что нам и нужно для использования модуля чисто для синтеза голоса без остальных MIDI-инструментов.
F0 43 79 09 01 01 00 F7: перезагружает модуль (например, после переключения ПЗУ).F0 43 79 09 10 04 nn F7: выставляет режим работы GPIO:- nn = 00: выключить
- nn = 01: ритм-визуализатор (вокал, бочка, средний, тарелки)
- nn = 02: реакция на note-on/note-off в 1-4 каналах
- nn = 03: визуализатор первого канала по нотам
- nn = 04: ручная установка в виде битовой маски командой
F0 43 79 09 03 00 xx F7
F0 43 79 09 00 50 10 dd dd ... F7: установить список фонем (слова песни):- Где dd: байты null-терминированной CSV-строки с фонемами в ASCII
- Фонемы можно найти в документации по системе команд YMW820 на 34 странице
- Их можно загружать и через NRPN-сообщения, но пока что обойдёмся без этого
В остальном по эффектам и прочему модуль по большому счёту совместим с системой команд Yamaha XG.
У первого MIDI-канала нельзя сменить инструмент — именно там и находится вокал. После задания фонем через SysEx-команду, каждое Note On событие в первом канале сдвигает указатель в буфере фонем на следующую, а после последней — перематывает его на начало. Проще говоря, одна нота — один слог, и так в цикле, пока не загрузишь новую строку в память :-)
Воспользуемся этим, чтобы отлавливать команды установки фонем ардуиной и отображать скроллер со «словами» на дисплее. До кучи добавим и пару своих команд:
F0 7B 7F F7: «жёсткий» сброс чипа, на случай если тот зависнет :-)F0 7B 00 0r F7: выбор ПЗУ голоса:- r=0 — основной, r=1 — вторичный
F0 7B 01 F7: установить текущий голос по умолчанию.F0 7B 02 tt dd dd... 00 [xx xx xx ... 00] F7: показать сообщение на экране:- tt — время в секундах
- dd dd… 00 — нуль-терминированная верхняя строка экрана
- xx xx… 00 — опциональная нуль-терминированная нижняя строка экрана
После пары часов мучений (и двух-трёх месяцев спровоцированной ими прокрастинации) выяснилось, что ноты, написанные в стиле караоке, уж совсем не совпадают с количеством фонем в песне, а выравнивать их, не видя, на каком месте строка ломается, практически невозможно.
Поэтому берём поллитру, вспоминаем MFC и патчим такой замечательный редактор, как Sekaiju, на отрисовку слогов под нотами:
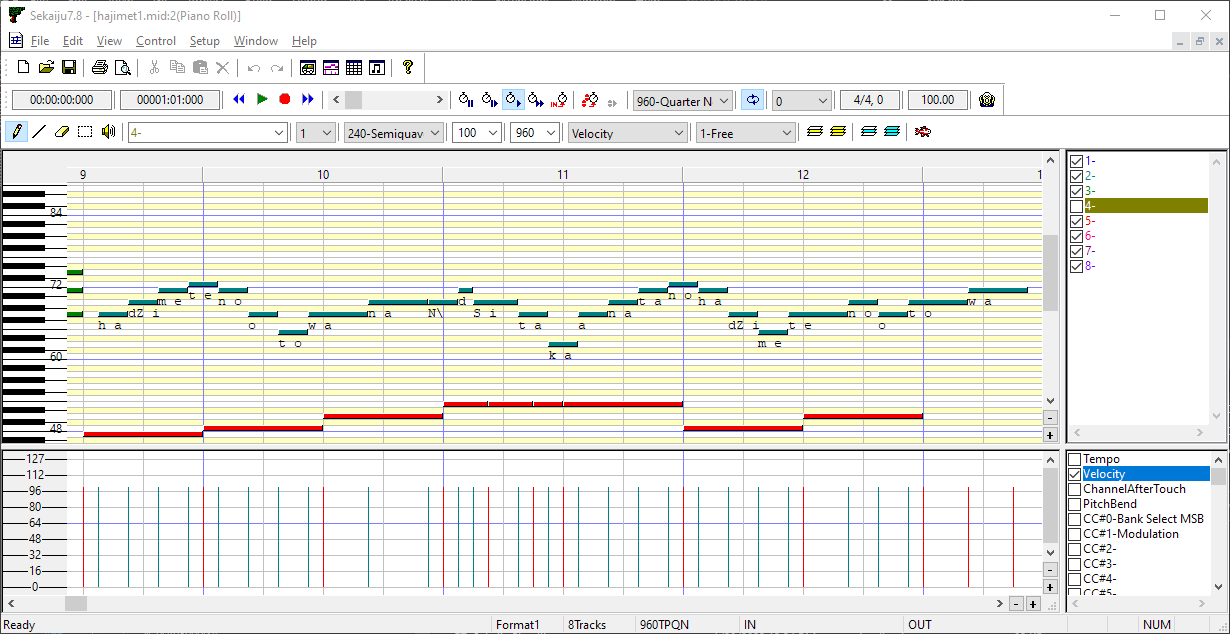
Если разваливается, то хотя бы сразу видно, где
Дорисовываем остаток совы… В смысле, дописываем аранжировку в Sekaiju, и потом доводим эффектами в Yamaha XGWorks. Попутно я докинул ещё пару партий в формате AYYMIDI (из прошлой статьи), написав их в ProTracker.
Помимо прочего, нашлось ещё несколько подводных камней:
Как и обещал производитель, поёт NSX-1 ну очень медленно. Даже в такой медленной песне есть места, где приходилось делать рокировочки таймингов десятки раз, чтобы получить более-менее вменяемый саунд. Какой-нибудь Intense Voice уж точно по битрейту не пролезет, разве что интерливом в несколько чипов через управляемый микшер :-)
По ощущениям, использование NSX-1 для всех инструментов ещё сильнее замедляет воспроизведение голоса, поэтому лучше использовать его чисто для вокала, даром что по качеству звучания его даже Yamaha MU50 уделывает с лихвой. Сделать это можно последовательностью команд:
-
F0 43 79 09 10 07 00 7E 7F 7F F7: NSX Channel Mute, оставляем только 1 канал. - GM Volume Ch1 = 127: выставляем громкость вокала на максимум.
- XG Volume Ch1 = 0: отключаем первый канал на MU50. За счёт того, что NSX игнорирует многие XG команды на первом канале, его громкость останется на 127.
Из-за того, что Vendor ID у NSX и у серии MU совпадает, использовать тот же MU50 как RS232-MIDI интерфейс не получилось — слишком сильно задерживаются SysEx'ы задания фонем и слова начинают съезжать относительно нот.
Воспроизведение отдельных нот напоминает скорее чтение текста, чем пение, поэтому Note Off каждой ноты вокала лучше ставить чуть дальше, чем Note On следующей за ней:
- Это создаёт проблемы, когда несколько слогов идут одним тоном, что нужно учитывать при написании аранжировки.
- Однако, эту особенность можно использовать для реализации удвоения (っ、напр. в демо-песне для этой статьи слово わらった [waratta] чаще всего записано путём двух «наложенных» нот [wa] [ra], затем Note Off второй, и только после этого «впритык» Note On для [ta].
- Ни сам чип, ни генератор команд eVo Phonetic не поддерживают удвоение согласных, поэтому единственный другой способ — продублировать слог целиком, но обрезать ноту так, чтобы чип «не успел» дойти до гласной. Иногда это работает, но часто звучит странно и упирается в проблему скорости из п. 1.
Ударения как такового в японском языке нет, но лучше всё равно добавлять экспрессии и подрезать редуцирующиеся звуки через Velocity.
Для конвертации файлов под аппаратные плееры многие пользуются программной MIDI Formatter — оказалось, она перемешивает местами каналы, поэтому для композиций написанных под NSX-1 её использовать нельзя. Впрочем, конвертировать файлы в SMF0 можно через диалог «Сохранить как» в программе XGWorks.
❯ Демо!
Не буду погружать во все остальные тонкости написания MIDI-аранжировок, ведь статья получилась и так слишком длинной — лучше дам послушать итоговый результат :-)
Первым делом, конечно же, была запрограммирована классика жанра: malo — Hajimete no Oto (The First Sound)
❯ И второе!
Казалось бы, одним треком можно было и ограничиться — голос слышно, вроде как будто даже поёт, всё хорошо. Но хотелось всё-таки выжать из конструкции побольше музыкальности, а не просто мелодию в трёх дорожках… Поэтому статья была отложена больше чем на полгода, пока я допишу аранжировку той самой песни Shabon — как дань уважения всей этой культуре, на удивление тёплоламповому вопреки всем событиям 2020 году, да и в целом, потому что душа просила что-то поинтереснее :-)
Впрочем, чип оказался всё же слишком сложным, поэтому звучания прямо один к одному не вышло.
❯ А компот?
Увы, код в этот раз слишком простой и никаких особых лайфхаков не содержит, а схема паялась в основном по наитию из головы.
Если вдруг кто-то имеет такой чип и захочет повторить конструкцию — могу, конечно, причесать всё и расшарить, но пока что вот так ¯\_(ツ)_/¯
Возможно, захочется почитать и это:
- ➤ MFOS Echo Rockit — простой, но могучий аналоговый синтезатор
- ➤ Подключаем дисплей к любому одноплатнику с SPI: большой мануал о поиске экранчиков для ваших проектов
- ➤ Светофор на логике со схемотехникой в стиле Beatles. Как электроника вновь стала моим хобби
- ➤ Создаем I2C Master Controller на Verilog. Логический уровень
- ➤ Будущее живой музыки или причуда миллиардера? Как устроена самая крупная сферическая конструкция в мире

Комментарии (8)

{kind=link}

kulhaker478
15.08.2023 08:26Статью читать только под синты с Miku! Очень добротно, VFDшка прям очень в тему. Кстати, насколько подобный MikuBox будет отличается от эмулции в каком-нибудь условном фрутилупсе?
И ожидать ли вторую часть с причёсыванием содержимого внутри?) А то после просмотра, вспомниается мем с мужчиной в подтяжках в зеркале

vladkorotnev Автор
15.08.2023 08:26+2Нормальный софтварный вокалоид на комп будет сильно лучше, как в видео с концерта. В NSX из-за недостатка ресурсов всего лишь дифоновый синтез вместо трифонового, не говоря уже про частоту дискретизации где-то в районе 4кГц.

Daddy_Cool
15.08.2023 08:26Очень интересно!
Я как-то развлекался с ямаховским программным голосовым синтезатором. Берется миди, берется текст, расставляются слоги - результат терпим, но смысла в нем мало, если только хочется послушать как сочиненная песня будет звучать именно голосом.vladkorotnev Автор
15.08.2023 08:26Тут беда именно в том, что просто миди взять, как оказалось, мало. Дофига времени ушло именно на расстановку длительностей и разбивку по слогам, ведь когда сам говоришь/поёшь — не задумываешься, сколько длится каждый слог, какой громче, какой тише...
Есть профессионалы, которые так параметры прописывают, что чуть ли не живее человека звучит :-)
Ну и как человек, побывавший пару раз в шкуре звукорежиссёра понемножку, скажу, что для меня главный плюс что вокалоидов, что того же барабанщика из LogicPro, в том, что в отличие от живых людей их не нужно херачить палкой и загонять под 100500 компрессоров с лимитерами на 10 разных шин, чтобы получить плюс-минус ровный сигнал и ритм, не съезжающий в зависимости от погоды на марсе %)
Daddy_Cool
15.08.2023 08:26+1)))) Минусы живых людей это одновременно и плюсы. Вот вопрос где взять этих живых людей...
В японском трудно оценить "живость", но звучит интересно.
Kudriavyi
Любопытное исследование. Но от звуков в статье у меня чуть кровь из ушей не пошла. Звук как из пластмассового дешёвого синтезатора 90-х
vladkorotnev Автор
Если речь о тембрах самого NSX, то и неудивительно, в дешёвых синтезаторах и стояли подобные чипы либо их клоны. А MU50 можно, если заморочиться, заставить звучать шикарно, но из-за того, что канал DSP там всего один, это работает только на довольно монофонических композициях.
Ну и опять же, правило "лучше выложить как есть, чем закинуть в дальний ящик ещё на 10 лет" :-)