В современном построенном на данных мире организации накапливают огромные объёмы информации, позволяющие принимать важные решения и выводы. Целых 80% от этой цифровой сокровищницы представляют собой неструктурированные данные, в которых отсутствует формат и упорядоченность.
Чтобы продемонстрировать объём неструктурированных данных, мы сошлёмся на десятую ежегодную инфографику Data Never Sleeps, показывающую, какое количество данных ежеминутно генерируется в Интернете.
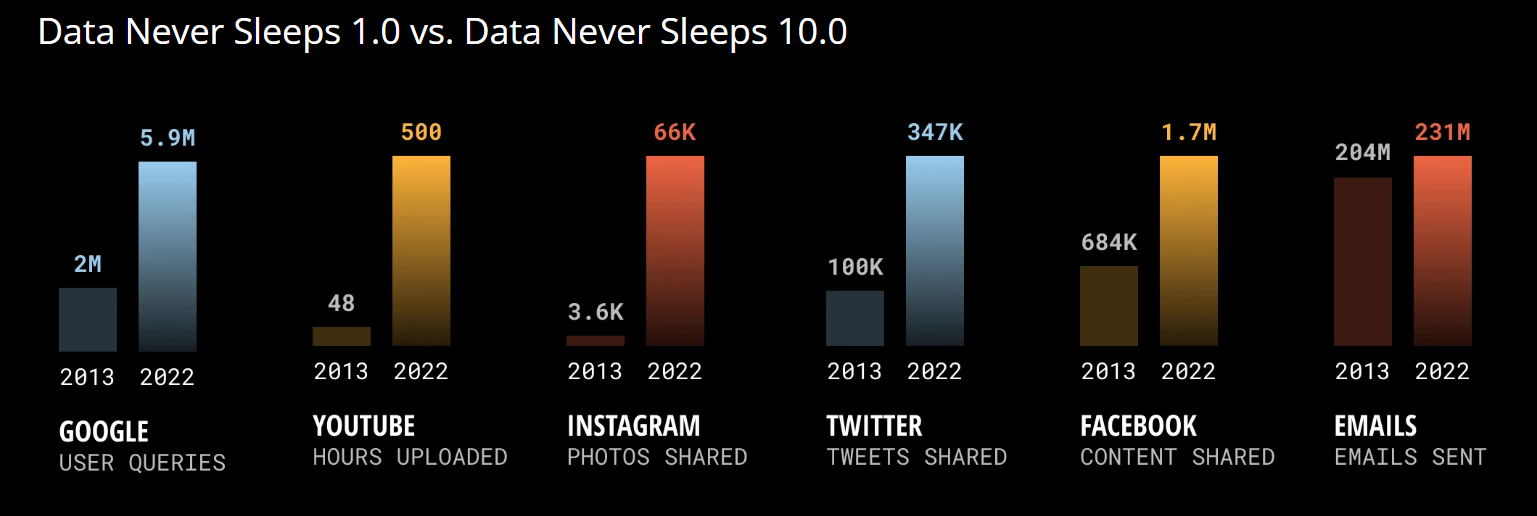
Сколько данных генерировалось ежеминутно в 2013 и 2022 годах. Источник: DOMO
Только представьте: в 2022 году пользователи каждую минуту отправляли 231,4 миллиона электронных писем, загружали на YouTube пятьсот часов видео и делились 66 тысячами фотографий в Instagram. Разумеется, доступ к такому огромному пулу неструктурированных данных может дать компаниям большие возможности глубже понимать своих клиентов, рынки и операции, в конечном итоге приводя к росту и успеху.
В этой статье мы окунёмся в мир неструктурированных данных, подчеркнём их важность и представим практичные советы по извлечению ценной информации из этого часто недооцениваемого ресурса. Мы рассмотрим разные типы данных, варианты хранения и управления ими, а также различные методики и инструменты для анализа неструктурированных данных. Подробно разобравшись в этих аспектах, вы сможете овладеть истинным потенциалом неструктурированных данных и преобразовать их в стратегический ресурс.
В своей простейшей форме неструктурированными данными называют любые данные, не имеющие заранее заданной структуры или организации. В отличие от структурированных данных, упорядоченных в удобные строки и столбцы базы данных, неструктурированные данные могут быть неотсортированной и обширной коллекцией информации. Она может поступать в различных видах: текстовые документы, электронные письма, изображения, видео, посты в соцсетях, показания датчиков и так далее.
Представьте стол, заваленный рукописными заметками, печатными статьями, рисунками и фотографиями. Этот информационный бардак и есть аналог неструктурированных данных. В нём много содержимого, но без первоначальной сортировки и категоризации его нельзя использовать и выполнять по нему поиск.
В общем виде неструктурированные данные можно классифицировать на две категории:
Вне зависимости от источника, неструктурированные данные сложно обрабатывать, поскольку часто для извлечения из них ценной информации требуются современные методики и инструменты. Однако несмотря на такие трудности, это ценный ресурс, который правильном анализе может предоставить компаниям ценную информацию и конкурентные преимущества.
Множество типов и форматов неструктурированных данных сильно варьируются в зависимости от содержащегося в них контента и способа хранения информации. Давайте рассмотрим несколько примеров, чтобы лучше понять концепцию неструктурированных данных.

Несколько примеров неструктурированных данных
Текстовые документы. Неструктурированные данные могут принимать вид текстовых документов (текстовых файлов без форматирования (.txt), документов Microsoft Word (.doc, .docx), файлов PDF (.pdf), файлов HTML (.html) и других форматов текстовых редакторов). В первую очередь они содержат письменный контент и могут включать в себя такие элементы, как текст, таблицы и изображения.
Электронные письма. Как вид электронной коммуникации электронные письма часто содержат неструктурированные текстовые данные и различные файловые вложения: изображения, документы или электронные таблицы.
Изображения. Файлы изображений могут иметь различные форматы, например, JPEG (.jpg, .jpeg), PNG (.png), GIF (.gif), TIFF (.tiff), а также другие. В этих файлах хранится визуальная информация, для их анализа и извлечения из них данных требуются более специализированные методики обработки, например, компьютерное зрение.
Аудиофайлы. Аудиоданные обычно представлены в таких форматах, как MP3 (.mp3), WAV (.wav) и FLAC (.flac), а также в других. Эти файлы содержат звуковую информацию, для извлечения из которой значимых выводов требуются методики обработки аудио.
Видеофайлы. Видеоданные хранятся в популярных форматах наподобие MP4 (.mp4), AVI (.avi), MOV (.mov) и в других. Для анализа видео требуется совместное использование методик компьютерного зрения и обработки аудио, потому что часто они содержат визуальную и звуковую информацию.
Файлы журналов. Файлы журналов (логов), генерируемые различными системами или приложениями, обычно содержат неструктурированные данные, из которых можно извлечь информацию о показателях системы, безопасности и поведении пользователей.
Показания датчиков. Информация от датчиков, встроенных в носимые, промышленные и другие IoT-устройства, тоже может быть неструктурированной. Это такая информация, как показания температуры, координаты GPS и так далее.
Посты в соцсетях. Данные с платформ социальных сетей наподобие Twitter и Facebook, а также из приложений мессенджеров содержат тексты, изображения и другой мультимедийный контент, не имеющий заранее заданной структуры.
Это лишь некоторые из примеров форматов неструктурированных данных. С развитием мира данных могут возникать новые форматы, а уже имеющиеся форматы могут адаптироваться для включения в них новых неструктурированных типов данных.
Неструктурированные данные и big data — это связанные концепции, но это не одно и то же. Под неструктурированными данными понимают информацию, в которой отсутствует заданный формат или организация. Термином big data называют большие объёмы структурированных и неструктурированных данных, которые сложно обрабатывать, хранить и анализировать при помощи традиционных инструментов управления данными.
Различие заключается в том, что неструктурированные данные — это один из типов данных, относящихся к big data, а big data — это зонтичный термин, объединяющий в себе различные типы данных, в том числе структурированные и частично структурированные данные.
Итак, настало время чётко разделить все типы информации, относящиеся к миру big data.
Неструктурированные, частично структурированные и структурированные данные обладают конкретными свойствами, отличающими их друг от друга.

Сравнение структурированных, неструктурированных и частично структурированных данных
Структурированные данные отформатированы в таблицы, строки и столбцы, соответствующие чётко описанной схеме с конкретными типами данных, взаимосвязями и правилами. Постоянная схема означает, что структура и организация данных заранее задана и согласована. Такие данные обычно хранятся в системах управления базами данных (СУБД) наподобие SQL Server, Oracle и MySQL, а управляются аналитиками данных и администраторами баз данных. Анализ структурированных данных обычно выполняется при помощи SQL-запросов и методик дата-майнинга.
Неструктурированные данные непредсказуемы и не имеют постоянной схемы, что усложняет их анализ. Без постоянной схемы данные могут варьироваться в структуре и организации. К ним относят такие форматы, как текст, изображения, аудио и видео. Для управления неструктурированными данными и их анализа часто используются файловые системы, озёра данных и фреймворки обработки Big Data наподобие Hadoop и Spark.
Частично структурированные данные находятся между структурированными и неструктурированными данными, они имеют приблизительную схему, соответствующую различным форматам и меняющимся требованиям. Нечёткая схема обеспечивает определённую гибкость структуры данных, сохраняя при этом общую организацию. Распространёнными примерами таких данных являются форматы XML, JSON и CSV. Частично структурированные данные обычно хранятся в базах данных NoSQL наподобие MongoDB, Cassandra и Couchbase, имеющих иерархические и графовые модели данных.
Эффективное хранение и обработка неструктурированных данных крайне важны для полного использования их потенциала. Для обеспечения оптимального управления этим важным ресурсом нужно учесть множество основных аспектов и методик.

Инструменты и платформы для управления неструктурированными данными
Сбор неструктурированных данных требует решения уникальных проблем вследствие большого объёма, разнообразия и сложности информации. Для этого процесса необходимы извлечение данных из различных источников, обычно при помощи API. Для быстрого сбора обширных объёмов информации вам могут потребоваться разнообразные инструменты потребления данных и процессы ELT (extract, load, transform).
Интерфейсы программирования приложений (API) позволяют взаимодействовать различным приложениям и выполнять извлечение данных из разных источников, в частности, с платформ соцсетей, новостных веб-сайтов и других онлайн-сервисов.
Например, разработчики могут использовать Twitter API для сбора публичных твитов, профилей пользователей и других данных с платформы Twitter.
Инструменты потребления данных — это приложения или сервисы, предназначенные для сбора, импорта и обработки данных из различных источников в систему или репозиторий центрального хранилища данных.
После сбора неструктурированных данных следующий этап заключается в эффективном хранении и обработке этих данных. Для того, чтобы справиться со сложностью и объёмами неструктурированных данных, компании должны вкладываться в современные решения.
Кроме того, сложность, неоднородность и объёмность неструктурированных данных требуют специализированных систем хранения. В отличие от структурированных данных, их нельзя просто хранить в базах данных SQL. Для хранения неструктурированных данных система должна иметь следующие свойства.
Существует множество широко применяемых систем хранения неструктурированных данных, например, озёра данных (Amazon S3, Google Cloud Storage, Microsoft Azure Blob Storage и так далее), базы данных NoSQL (MongoDB, Cassandra и другие) и фреймворки обработки big data (Hadoop, Apache Spark). Также хорошими вариантами для решения этих задач могут быть современные облачные хранилища данных и data lakehouse.
Озёра данных обеспечивают гибкий и экономный способ управления неструктурированными данными и их хранения с высокой надёжностью и доступностью. Они могут хранить большие объёмы сырых данных в их нативном формате, позволяя организациям выполнять аналитику big data и в то же время предоставляя возможность преобразования и интеграции данных с различными инструментами и платформами.
Также при обработке неструктурированных данных могут быть полезны базы данных NoSQL: они предоставляют гибкие и масштабируемые опции хранения для разных форматов информации, позволяя обеспечивать эффективность запросов и извлечения данных.
Из-за объёма и сложности неструктурированных данных их обработка может быть вычислительно затратной задачей. Для решения этой проблемы существуют системы, распределяющие эту нагрузку по нескольким кластерам. Использование таких распределённых вычислительных систем позволяет эффективно обрабатывать неструктурированные данные, в конечном итоге расширяя возможности принятия решений внутри компании.
Представленные ниже фреймворки обработки Big data позволяют управлять огромными объёмами неструктурированных данных, обеспечивая распределение вычислительных мощностей между кластерами или компьютерами.
Для навигации по обширным хранилищам неструктурированных данных и эффективного нахождения в них релевантной информации требуются продвинутые функции поиска. Эту задачу решают специализированные движки поиска и аналитики, предоставляющие функции индексирования, поиска и анализа, адаптированные под обработку неструктурированных данных. Эти инструменты помогают организациям извлекать ценные данные, обнаруживать скрытые закономерности и принимать осознанные решения на основании неструктурированных данных.
Перечисленные ниже инструменты специально спроектированы для решения уникальных задач поиска и анализа неструктурированных данных.
Если вам требуется более сложный анализ неструктурированных данных, существуют различные методики машинного обучения, которые стоит рассмотреть.
Для правильного анализа и интерпретирования различных типов данных (аудио, изображений, текста и видео) необходимо использовать современные технологии — машинное обучение и ИИ. Методики на основе машинного обучения, в том числе обработка естественного языка (natural language processing, NLP), анализ аудио и распознавание изображений, критически важны для выявления скрытой информации.
Natural Language Processing (NLP) — это область искусственного интеллекта, упрощающая понимание, интерпретирование и генерацию человеческого языка компьютером. В основном она используется для анализа текстовых неструктурированных данных (электронных писем, постов в соцсетях и отзывов покупателей).
Базовая методика NLP под названием классификация текста упрощает упорядочивание и категоризацию текста для упрощения его понимания и использования. Эта методика позволяет выполнять такие задачи, как разметка важности и выявление негативных комментариев в отзывах. В популярной сфере применения классификации текста под названием «анализ эмоциональной составляющей» (sentiment analysis) текст категоризируется на основании чувств, суждений или мнений автора. Это позволяет компаниям понимать отношение аудитории к ним, расставлять приоритеты задач клиентской поддержки и выявлять тенденции в отрасли.
Ещё одна методика NLP для обработки неструктурированных текстовых данных называется «извлечением информации» (information extraction, IE). IE извлекает нужную информацию (имена, даты событий или телефонные номера) и упорядочивает её в базу данных. IE является важной частью интеллектуальной обработки документов и использует NLP и компьютерное зрение для автоматического извлечения данных из различных документов, их классификации и преобразования в стандартный выходной формат.
Распознавание изображений позволяет определять на изображениях объекты, людей и сцены. Это крайне полезно для анализа визуальных данных, например, фотографий и иллюстраций. Методики распознавания изображений помогают распознавать генерируемый пользователями контент, анализировать изображения товаров и извлекать тексты из сканированных документов для дальнейшего анализа.
Аналитика видео заключается в извлечении существенной информации из видеоданных, например, в выявлении паттернов, объектов или действий в роликах. Эта технология может использоваться для множества целей, например, для обеспечения безопасности, анализа поведения клиентов и контроля качества на производстве. Методики обнаружения движения, отслеживания объектов и распознавания действий помогают организациям получать информацию об их операциях, клиентах и потенциальных угрозах.
Инструменты анализа аудио позволяют обрабатывать и анализировать аудиоданные, в том числе голосовые записи, музыку и звуки окружающей среды, с целью извлечения полезной информации или выявления паттернов. Такие методики анализа аудио, как распознавание речи, определение эмоций и идентификация говорящего используются во множестве отраслей, например, в индустрии развлечений (генерация контента, музыкальные рекомендации), обслуживание клиентов (аналитика кол-центров, голосовые помощники) и безопасность (голосовая биометрия, акустическое распознавание событий).
Если для вашего проекта обработки данных требуется создание собственных моделей машинного обучения, то вы можете выбрать одну из платформ, рассчитанных на конкретные задачи, которые помогут вам эффективно выявлять в неструктурированных данных паттерны, тенденции и взаимосвязи. Довольно многие платформы машинного обучения и ИИ предоставляют возможности обработки и анализа различных типов неструктурированных данных (текста, аудио и изображений), которые можно использовать для создания и развёртывания ИИ-моделей. Например, можно создать и обучить собственные модели машинного обучения при помощи перечисленных ниже инструментов. Однако для обучения моделей на ваших данных потребуется команда data science.
Наконец, если вы обучаете модели под собственные задачи, вам может пригодиться разметка данных. В разметке данных используется аннотирование соответствующей информацией сырых данных, например, текста, изображений, видео или аудио. Это помогает моделям машинного обучения изучать паттерны и точно выполнять конкретные задачи.
Например, при обучении моделей NLP с целью анализа эмоциональной составляющей живые аннотаторы размечают образцы текста, указывая соответствующие эмоции: положительные, отрицательные или нейтральные. Аналогичным образом аннотаторы размечают изображения или их области, чтобы помочь моделям правильно распознавать и классифицировать их. В области аналитики видео разметка данных может заключаться в определении объектов, отслеживании их движения и идентификации конкретных действий. Наконец, в анализе аудио разметка может включать в себя транскрибирование речи, идентификацию говорящих или конкретных событий в аудио.
Разумеется, это лишь небольшая часть технологий в океане множества других. Выбор конкретных инструментов сильно зависит от конкретного проекта обработки данных и задач бизнеса.
Понимание и внедрение рекомендаций поможет раскрыть истинный потенциал неструктурированных данных. Ниже мы исследуем эффективные стратегии обработки и использования неструктурированных данных, помогающие компаниям обнаруживать ценную информацию и принимать обоснованные решения.
Разработайте чёткую стратегию работы с данными. Определите цели своей организации и требования к анализу неструктурированных данных. Укажите источники данных, типы выполняемой аналитики и ожидаемые результаты.
Создайте архитектуру данных. Для эффективного использования неструктурированных данных выделите ресурсы для создания подробной архитектуры данных, поддерживающей хранение, обработку и анализ различных видов данных. Надёжная архитектура данных закладывает фундамент для эффективной обработки, масштабируемости и интеграции с другими системами, поэтому в реализации и поддержке этой архитектуры необходимо задействовать опытных архитекторов данных и других участников команды обработки данных.
Выберите подходящие инструменты и платформы. Вслед за предыдущим этапом необходимо проанализировать и выбрать подходящие инструменты и платформы для анализа неструктурированных данных на основании конкретных потребностей, типов данных и ресурсов организации. Учитывайте возможность масштабирования, гибкость и возможности интеграции каждого из решений.
Инвестируйте в data governance. Создайте надёжные политики и процессы data governance, чтобы обеспечить качество, безопасность и комплаенс данных. Внедрение каталогизации и классификации данных, управления метаданными может упростить доступ к неструктурированным данным, позволяя выполнять более тщательный анализ.
Соберите опытную команду аналитиков. Необходимо создать многодисциплинарную команду с опытом работы в data science, машинном обучении и имеющую знание предметной области, потому что такая команда сможет эффективно анализировать неструктурированные данные. Необходимо предоставить ей обучение и поддержку, чтобы развить их навыки и обеспечить актуальность их знаний в соответствии с тенденциями отрасли.
Развивайте культуру принятия решений на основе данных. Развитие в организации культуры принятия решений на основе данных можно реализовать повышением грамотности работы с данными и делая упор на важность данных в принятии решений. Делясь с руководством и отделами открытиями, сделанными при анализе неструктурированных данных, вы сможете стимулировать совместное принятие решений и развить его культуру.
Выпустите пилотный проект и итеративно совершенствуйтесь. Чтобы обеспечить реализуемость и эффективность проектов по аналитике неструктурированных данных, лучше начать с мелких пилотных проектов. Воспользуйтесь полученными знаниями для совершенствования своих методик и увеличения масштаба успешных проектов.
Обеспечьте конфиденциальность и безопасность данных. Внедрите надёжные меры защиты и придерживайтесь соответствующего законодательства по защите данных для обеспечения конфиденциальности и безопасности своих неструктурированных данных. Помочь в сохранении конфиденциальности может анонимизация или псевдонимизация данных. Также важно обеспечивать прозрачность практик обработки данных для высшего руководства.
Метрики и оптимизация. Регулярно оценивайте показатели и влияние аналитики неструктурированных данных, отслеживая соответствующие метрики и KPI. Это позволяет оптимизировать процессы, инструменты и методики с целью максимизации выгоды, получаемой от неструктурированных данных.
Чтобы продемонстрировать объём неструктурированных данных, мы сошлёмся на десятую ежегодную инфографику Data Never Sleeps, показывающую, какое количество данных ежеминутно генерируется в Интернете.
Сколько данных генерировалось ежеминутно в 2013 и 2022 годах. Источник: DOMO
Только представьте: в 2022 году пользователи каждую минуту отправляли 231,4 миллиона электронных писем, загружали на YouTube пятьсот часов видео и делились 66 тысячами фотографий в Instagram. Разумеется, доступ к такому огромному пулу неструктурированных данных может дать компаниям большие возможности глубже понимать своих клиентов, рынки и операции, в конечном итоге приводя к росту и успеху.
В этой статье мы окунёмся в мир неструктурированных данных, подчеркнём их важность и представим практичные советы по извлечению ценной информации из этого часто недооцениваемого ресурса. Мы рассмотрим разные типы данных, варианты хранения и управления ими, а также различные методики и инструменты для анализа неструктурированных данных. Подробно разобравшись в этих аспектах, вы сможете овладеть истинным потенциалом неструктурированных данных и преобразовать их в стратегический ресурс.
Что такое неструктурированные данные? Определение и примеры
В своей простейшей форме неструктурированными данными называют любые данные, не имеющие заранее заданной структуры или организации. В отличие от структурированных данных, упорядоченных в удобные строки и столбцы базы данных, неструктурированные данные могут быть неотсортированной и обширной коллекцией информации. Она может поступать в различных видах: текстовые документы, электронные письма, изображения, видео, посты в соцсетях, показания датчиков и так далее.
Представьте стол, заваленный рукописными заметками, печатными статьями, рисунками и фотографиями. Этот информационный бардак и есть аналог неструктурированных данных. В нём много содержимого, но без первоначальной сортировки и категоризации его нельзя использовать и выполнять по нему поиск.
Типы неструктурированных данных
В общем виде неструктурированные данные можно классифицировать на две категории:
- генерируемые людьми неструктурированные данные, к которым относятся различные виды создаваемого людьми контента: текстовые документы, электронные письма, посты в соцсетях, изображения, видео и так далее
- машиногенерируемые неструктурированные данные создаются устройствами и датчиками, это файлы журналов, данные GPS, результаты работы Internet of Things (IoT) и другая телеметрическая информация.
Вне зависимости от источника, неструктурированные данные сложно обрабатывать, поскольку часто для извлечения из них ценной информации требуются современные методики и инструменты. Однако несмотря на такие трудности, это ценный ресурс, который правильном анализе может предоставить компаниям ценную информацию и конкурентные преимущества.
Примеры и форматы неструктурированных данных
Множество типов и форматов неструктурированных данных сильно варьируются в зависимости от содержащегося в них контента и способа хранения информации. Давайте рассмотрим несколько примеров, чтобы лучше понять концепцию неструктурированных данных.
Несколько примеров неструктурированных данных
Текстовые документы. Неструктурированные данные могут принимать вид текстовых документов (текстовых файлов без форматирования (.txt), документов Microsoft Word (.doc, .docx), файлов PDF (.pdf), файлов HTML (.html) и других форматов текстовых редакторов). В первую очередь они содержат письменный контент и могут включать в себя такие элементы, как текст, таблицы и изображения.
Электронные письма. Как вид электронной коммуникации электронные письма часто содержат неструктурированные текстовые данные и различные файловые вложения: изображения, документы или электронные таблицы.
Изображения. Файлы изображений могут иметь различные форматы, например, JPEG (.jpg, .jpeg), PNG (.png), GIF (.gif), TIFF (.tiff), а также другие. В этих файлах хранится визуальная информация, для их анализа и извлечения из них данных требуются более специализированные методики обработки, например, компьютерное зрение.
Аудиофайлы. Аудиоданные обычно представлены в таких форматах, как MP3 (.mp3), WAV (.wav) и FLAC (.flac), а также в других. Эти файлы содержат звуковую информацию, для извлечения из которой значимых выводов требуются методики обработки аудио.
Видеофайлы. Видеоданные хранятся в популярных форматах наподобие MP4 (.mp4), AVI (.avi), MOV (.mov) и в других. Для анализа видео требуется совместное использование методик компьютерного зрения и обработки аудио, потому что часто они содержат визуальную и звуковую информацию.
Файлы журналов. Файлы журналов (логов), генерируемые различными системами или приложениями, обычно содержат неструктурированные данные, из которых можно извлечь информацию о показателях системы, безопасности и поведении пользователей.
Показания датчиков. Информация от датчиков, встроенных в носимые, промышленные и другие IoT-устройства, тоже может быть неструктурированной. Это такая информация, как показания температуры, координаты GPS и так далее.
Посты в соцсетях. Данные с платформ социальных сетей наподобие Twitter и Facebook, а также из приложений мессенджеров содержат тексты, изображения и другой мультимедийный контент, не имеющий заранее заданной структуры.
Это лишь некоторые из примеров форматов неструктурированных данных. С развитием мира данных могут возникать новые форматы, а уже имеющиеся форматы могут адаптироваться для включения в них новых неструктурированных типов данных.
Неструктурированные данные и big data
Неструктурированные данные и big data — это связанные концепции, но это не одно и то же. Под неструктурированными данными понимают информацию, в которой отсутствует заданный формат или организация. Термином big data называют большие объёмы структурированных и неструктурированных данных, которые сложно обрабатывать, хранить и анализировать при помощи традиционных инструментов управления данными.
Различие заключается в том, что неструктурированные данные — это один из типов данных, относящихся к big data, а big data — это зонтичный термин, объединяющий в себе различные типы данных, в том числе структурированные и частично структурированные данные.
Итак, настало время чётко разделить все типы информации, относящиеся к миру big data.
Неструктурированные, частично структурированные и структурированные данные
Неструктурированные, частично структурированные и структурированные данные обладают конкретными свойствами, отличающими их друг от друга.
Сравнение структурированных, неструктурированных и частично структурированных данных
Структурированные данные отформатированы в таблицы, строки и столбцы, соответствующие чётко описанной схеме с конкретными типами данных, взаимосвязями и правилами. Постоянная схема означает, что структура и организация данных заранее задана и согласована. Такие данные обычно хранятся в системах управления базами данных (СУБД) наподобие SQL Server, Oracle и MySQL, а управляются аналитиками данных и администраторами баз данных. Анализ структурированных данных обычно выполняется при помощи SQL-запросов и методик дата-майнинга.
Неструктурированные данные непредсказуемы и не имеют постоянной схемы, что усложняет их анализ. Без постоянной схемы данные могут варьироваться в структуре и организации. К ним относят такие форматы, как текст, изображения, аудио и видео. Для управления неструктурированными данными и их анализа часто используются файловые системы, озёра данных и фреймворки обработки Big Data наподобие Hadoop и Spark.
Частично структурированные данные находятся между структурированными и неструктурированными данными, они имеют приблизительную схему, соответствующую различным форматам и меняющимся требованиям. Нечёткая схема обеспечивает определённую гибкость структуры данных, сохраняя при этом общую организацию. Распространёнными примерами таких данных являются форматы XML, JSON и CSV. Частично структурированные данные обычно хранятся в базах данных NoSQL наподобие MongoDB, Cassandra и Couchbase, имеющих иерархические и графовые модели данных.
Как обрабатывать неструктурированные данные
Эффективное хранение и обработка неструктурированных данных крайне важны для полного использования их потенциала. Для обеспечения оптимального управления этим важным ресурсом нужно учесть множество основных аспектов и методик.
Инструменты и платформы для управления неструктурированными данными
Сбор неструктурированных данных
Сбор неструктурированных данных требует решения уникальных проблем вследствие большого объёма, разнообразия и сложности информации. Для этого процесса необходимы извлечение данных из различных источников, обычно при помощи API. Для быстрого сбора обширных объёмов информации вам могут потребоваться разнообразные инструменты потребления данных и процессы ELT (extract, load, transform).
Интерфейсы программирования приложений (API) позволяют взаимодействовать различным приложениям и выполнять извлечение данных из разных источников, в частности, с платформ соцсетей, новостных веб-сайтов и других онлайн-сервисов.
Например, разработчики могут использовать Twitter API для сбора публичных твитов, профилей пользователей и других данных с платформы Twitter.
Инструменты потребления данных — это приложения или сервисы, предназначенные для сбора, импорта и обработки данных из различных источников в систему или репозиторий центрального хранилища данных.
- Apache NiFi — это опенсорсный инструмент интеграции данных, автоматизирующий перемещение и преобразование данных между системами, предоставляющий веб-интерфейс для создания потоков данных, управления ими и их мониторинга.
- Logstash — это серверный конвейер обработки данных, потребляющий данные из множества источников, преобразующий их и отправляющий их в реальном времени различным точкам наподобие Elasticsearch или файлового хранилища.
После сбора неструктурированных данных следующий этап заключается в эффективном хранении и обработке этих данных. Для того, чтобы справиться со сложностью и объёмами неструктурированных данных, компании должны вкладываться в современные решения.
Хранилище неструктурированных данных
Кроме того, сложность, неоднородность и объёмность неструктурированных данных требуют специализированных систем хранения. В отличие от структурированных данных, их нельзя просто хранить в базах данных SQL. Для хранения неструктурированных данных система должна иметь следующие свойства.
- Масштабируемость. Объём неструктурированных данных может расти экспоненциально. Чтобы отвечать растущим потребностям, системы хранения должны иметь возможность масштабироваться как горизонтально (добавлением новых машин), так и вертикально (добавлением новых ресурсов на уже имеющуюся машину).
- Гибкость. Так как неструктурированные данные имеют разнообразные форматы и размеры, системы хранения должны быть достаточно адаптивными, чтобы содержать разные типы данных и подстраиваться под изменения в форматах данных.
- Эффективный доступ и извлечение информации. Чтобы достичь этой цели, системы хранения должны иметь доступ с низкими задержками, высокую пропускную способность и поддержку различных методик извлечения данных, например, поиск, запросы и фильтрацию. Это гарантирует быстрый и эффективный доступ к данным и их извлечение.
- Надёжность и доступность данных. Системы хранения неструктурированных данных должны обеспечивать надёжность данных (защиту от их потери) и доступность (возможность получать доступ к ним по мере необходимости). Именно поэтому должна использоваться какая-то репликация данных, стратегии резервного копирования и механизмы защиты.
- Безопасность и конфиденциальность данных. Для защиты уязвимой информации системы хранения должны обеспечивать сильные меры безопасности: шифрование, контроль доступа и маскирование данных. Эти надёжные меры защиты обеспечивают постоянную безопасность и конфиденциальность данных.
Существует множество широко применяемых систем хранения неструктурированных данных, например, озёра данных (Amazon S3, Google Cloud Storage, Microsoft Azure Blob Storage и так далее), базы данных NoSQL (MongoDB, Cassandra и другие) и фреймворки обработки big data (Hadoop, Apache Spark). Также хорошими вариантами для решения этих задач могут быть современные облачные хранилища данных и data lakehouse.
Озёра данных обеспечивают гибкий и экономный способ управления неструктурированными данными и их хранения с высокой надёжностью и доступностью. Они могут хранить большие объёмы сырых данных в их нативном формате, позволяя организациям выполнять аналитику big data и в то же время предоставляя возможность преобразования и интеграции данных с различными инструментами и платформами.
- Amazon S3 в качестве платформы озера данных позволяет организациям хранить, анализировать и обрабатывать big data, в том числе выполнять резервное копирование и архивирование. Она обеспечивает доступ с низкими задержками, практически неограниченный объём хранилища и различные варианты интеграции со сторонними инструментами и другими сервисами AWS.
- Также в качестве системы озера данных можно использовать Google Cloud Storage. Она позволяет организациям хранить данные в инфраструктуре Google Cloud Platform, предоставляя услуги глобального пограничного кэширования, многоклассового хранения, автоматического масштабирования и простого в работе RESTful API для эффективного доступа к данным.
- Microsoft Azure Blob Storage, предназначенный для крупномасштабной аналитики — это масштабируемый сервис облачного хранилища, особенно подходящий для неструктурированных данных, в том числе для текста и двоичных данных. Он обеспечивает низкие задержки доступа к данным и интегрируется с другими сервисами Azure, например, с Databricks и Azure Synapse Analytics для расширенных обработки и анализа. Также этот сервис поддерживает такие функции, как хранилище Azure CDN (Content Delivery Network) с высокой степенью доступности, помогающие оптимизировать производительность.
Также при обработке неструктурированных данных могут быть полезны базы данных NoSQL: они предоставляют гибкие и масштабируемые опции хранения для разных форматов информации, позволяя обеспечивать эффективность запросов и извлечения данных.
- MongoDB — это популярная опенсорсная база данных NoSQL, хранящая и обрабатывающая большие объёмы неструктурированных данных в гибком формате, напоминающем JSON. Она обладает горизонтальной масштабируемостью и богатым языком запросов, что упрощает манипулирование данными.
- Apache Cassandra — это база данных NoSQL, известная своей высокой масштабируемостью и распространённостью, она используется для обработки огромных объёмов неструктурированных данных на множестве серверов. Она обеспечивает высокий уровень доступности, настраиваемую согласованность и надёжный язык запросов CQL (Cassandra Query Language).
Фреймворки обработки Big data
Из-за объёма и сложности неструктурированных данных их обработка может быть вычислительно затратной задачей. Для решения этой проблемы существуют системы, распределяющие эту нагрузку по нескольким кластерам. Использование таких распределённых вычислительных систем позволяет эффективно обрабатывать неструктурированные данные, в конечном итоге расширяя возможности принятия решений внутри компании.
Представленные ниже фреймворки обработки Big data позволяют управлять огромными объёмами неструктурированных данных, обеспечивая распределение вычислительных мощностей между кластерами или компьютерами.
- Apache Hadoop — это опенсорсный фреймворк распределённой обработки, способный анализировать и хранить в кластерах огромные объёмы неструктурированных данных. В экосистеме Hadoop также есть множество инструментов и библиотек для работы с крупными датасетами. Однако он может быть более сложным в изучении, чем другие решения.
- Apache Spark — это высокоскоростной и гибкий фреймворк кластерных вычислений. Он поддерживает обработку больших неструктурированных датасетов практически в реальном времени. Более того, у него есть высокоуровневые API на разных языках, функции обработки внутри памяти и простая интеграция с различными системами хранения.
Поиск по неструктурированным данным
Для навигации по обширным хранилищам неструктурированных данных и эффективного нахождения в них релевантной информации требуются продвинутые функции поиска. Эту задачу решают специализированные движки поиска и аналитики, предоставляющие функции индексирования, поиска и анализа, адаптированные под обработку неструктурированных данных. Эти инструменты помогают организациям извлекать ценные данные, обнаруживать скрытые закономерности и принимать осознанные решения на основании неструктурированных данных.
Перечисленные ниже инструменты специально спроектированы для решения уникальных задач поиска и анализа неструктурированных данных.
- Elasticsearch — это движок распределённого поиска и аналитики в реальном времени, способный на горизонтальное масштабирование, выполнение сложных запросов и мощный полнотекстовый поиск в неструктурированных данных. Этот построенный на основе Apache Lucene движок способен интегрироваться со множеством других инструментов обработки данных и имеет RESTful API для эффективного доступа к данным.
- Apache Solr — это опенсорсная платформа поиска, созданная на основе Apache Lucene и обладающая мощными возможностями полнотекстового поиска и аналитики неструктурированных данных. Она поддерживает распределённый поиск и индексацию (маршрутизацию) и без проблем может интегрироваться с фреймворками обработки big data наподобие Hadoop.
Если вам требуется более сложный анализ неструктурированных данных, существуют различные методики машинного обучения, которые стоит рассмотреть.
Анализ неструктурированных данных
Для правильного анализа и интерпретирования различных типов данных (аудио, изображений, текста и видео) необходимо использовать современные технологии — машинное обучение и ИИ. Методики на основе машинного обучения, в том числе обработка естественного языка (natural language processing, NLP), анализ аудио и распознавание изображений, критически важны для выявления скрытой информации.
Natural Language Processing (NLP) — это область искусственного интеллекта, упрощающая понимание, интерпретирование и генерацию человеческого языка компьютером. В основном она используется для анализа текстовых неструктурированных данных (электронных писем, постов в соцсетях и отзывов покупателей).
Базовая методика NLP под названием классификация текста упрощает упорядочивание и категоризацию текста для упрощения его понимания и использования. Эта методика позволяет выполнять такие задачи, как разметка важности и выявление негативных комментариев в отзывах. В популярной сфере применения классификации текста под названием «анализ эмоциональной составляющей» (sentiment analysis) текст категоризируется на основании чувств, суждений или мнений автора. Это позволяет компаниям понимать отношение аудитории к ним, расставлять приоритеты задач клиентской поддержки и выявлять тенденции в отрасли.
Ещё одна методика NLP для обработки неструктурированных текстовых данных называется «извлечением информации» (information extraction, IE). IE извлекает нужную информацию (имена, даты событий или телефонные номера) и упорядочивает её в базу данных. IE является важной частью интеллектуальной обработки документов и использует NLP и компьютерное зрение для автоматического извлечения данных из различных документов, их классификации и преобразования в стандартный выходной формат.
Распознавание изображений позволяет определять на изображениях объекты, людей и сцены. Это крайне полезно для анализа визуальных данных, например, фотографий и иллюстраций. Методики распознавания изображений помогают распознавать генерируемый пользователями контент, анализировать изображения товаров и извлекать тексты из сканированных документов для дальнейшего анализа.
Аналитика видео заключается в извлечении существенной информации из видеоданных, например, в выявлении паттернов, объектов или действий в роликах. Эта технология может использоваться для множества целей, например, для обеспечения безопасности, анализа поведения клиентов и контроля качества на производстве. Методики обнаружения движения, отслеживания объектов и распознавания действий помогают организациям получать информацию об их операциях, клиентах и потенциальных угрозах.
Инструменты анализа аудио позволяют обрабатывать и анализировать аудиоданные, в том числе голосовые записи, музыку и звуки окружающей среды, с целью извлечения полезной информации или выявления паттернов. Такие методики анализа аудио, как распознавание речи, определение эмоций и идентификация говорящего используются во множестве отраслей, например, в индустрии развлечений (генерация контента, музыкальные рекомендации), обслуживание клиентов (аналитика кол-центров, голосовые помощники) и безопасность (голосовая биометрия, акустическое распознавание событий).
Если для вашего проекта обработки данных требуется создание собственных моделей машинного обучения, то вы можете выбрать одну из платформ, рассчитанных на конкретные задачи, которые помогут вам эффективно выявлять в неструктурированных данных паттерны, тенденции и взаимосвязи. Довольно многие платформы машинного обучения и ИИ предоставляют возможности обработки и анализа различных типов неструктурированных данных (текста, аудио и изображений), которые можно использовать для создания и развёртывания ИИ-моделей. Например, можно создать и обучить собственные модели машинного обучения при помощи перечисленных ниже инструментов. Однако для обучения моделей на ваших данных потребуется команда data science.
- TensorFlow — это опенсорсный фреймворк машинного обучения, использующий множество алгоритмов машинного и глубокого обучения. Он обладает возможностью обработки неструктурированных данных и широкий выбор библиотек и инструментов для создания, обучения и развёртывания ИИ-моделей.
- IBM Watson — это коллекция ИИ-сервисов и инструментов, в том числе для обработки естественного языка, анализа эмоциональной составляющей и распознавания изображений, позволяющий обрабатывать и неструктурированные данные. В нём есть множество готовых моделей и API, а также инструменты для создания специализированных моделей, что упрощает интеграцию функций ИИ в уже имеющиеся системы.
Наконец, если вы обучаете модели под собственные задачи, вам может пригодиться разметка данных. В разметке данных используется аннотирование соответствующей информацией сырых данных, например, текста, изображений, видео или аудио. Это помогает моделям машинного обучения изучать паттерны и точно выполнять конкретные задачи.
Например, при обучении моделей NLP с целью анализа эмоциональной составляющей живые аннотаторы размечают образцы текста, указывая соответствующие эмоции: положительные, отрицательные или нейтральные. Аналогичным образом аннотаторы размечают изображения или их области, чтобы помочь моделям правильно распознавать и классифицировать их. В области аналитики видео разметка данных может заключаться в определении объектов, отслеживании их движения и идентификации конкретных действий. Наконец, в анализе аудио разметка может включать в себя транскрибирование речи, идентификацию говорящих или конкретных событий в аудио.
Разумеется, это лишь небольшая часть технологий в океане множества других. Выбор конкретных инструментов сильно зависит от конкретного проекта обработки данных и задач бизнеса.
Рекомендации по оптимальной обработке неструктурированных данных
Понимание и внедрение рекомендаций поможет раскрыть истинный потенциал неструктурированных данных. Ниже мы исследуем эффективные стратегии обработки и использования неструктурированных данных, помогающие компаниям обнаруживать ценную информацию и принимать обоснованные решения.
Разработайте чёткую стратегию работы с данными. Определите цели своей организации и требования к анализу неструктурированных данных. Укажите источники данных, типы выполняемой аналитики и ожидаемые результаты.
Создайте архитектуру данных. Для эффективного использования неструктурированных данных выделите ресурсы для создания подробной архитектуры данных, поддерживающей хранение, обработку и анализ различных видов данных. Надёжная архитектура данных закладывает фундамент для эффективной обработки, масштабируемости и интеграции с другими системами, поэтому в реализации и поддержке этой архитектуры необходимо задействовать опытных архитекторов данных и других участников команды обработки данных.
Выберите подходящие инструменты и платформы. Вслед за предыдущим этапом необходимо проанализировать и выбрать подходящие инструменты и платформы для анализа неструктурированных данных на основании конкретных потребностей, типов данных и ресурсов организации. Учитывайте возможность масштабирования, гибкость и возможности интеграции каждого из решений.
Инвестируйте в data governance. Создайте надёжные политики и процессы data governance, чтобы обеспечить качество, безопасность и комплаенс данных. Внедрение каталогизации и классификации данных, управления метаданными может упростить доступ к неструктурированным данным, позволяя выполнять более тщательный анализ.
Соберите опытную команду аналитиков. Необходимо создать многодисциплинарную команду с опытом работы в data science, машинном обучении и имеющую знание предметной области, потому что такая команда сможет эффективно анализировать неструктурированные данные. Необходимо предоставить ей обучение и поддержку, чтобы развить их навыки и обеспечить актуальность их знаний в соответствии с тенденциями отрасли.
Развивайте культуру принятия решений на основе данных. Развитие в организации культуры принятия решений на основе данных можно реализовать повышением грамотности работы с данными и делая упор на важность данных в принятии решений. Делясь с руководством и отделами открытиями, сделанными при анализе неструктурированных данных, вы сможете стимулировать совместное принятие решений и развить его культуру.
Выпустите пилотный проект и итеративно совершенствуйтесь. Чтобы обеспечить реализуемость и эффективность проектов по аналитике неструктурированных данных, лучше начать с мелких пилотных проектов. Воспользуйтесь полученными знаниями для совершенствования своих методик и увеличения масштаба успешных проектов.
Обеспечьте конфиденциальность и безопасность данных. Внедрите надёжные меры защиты и придерживайтесь соответствующего законодательства по защите данных для обеспечения конфиденциальности и безопасности своих неструктурированных данных. Помочь в сохранении конфиденциальности может анонимизация или псевдонимизация данных. Также важно обеспечивать прозрачность практик обработки данных для высшего руководства.
Метрики и оптимизация. Регулярно оценивайте показатели и влияние аналитики неструктурированных данных, отслеживая соответствующие метрики и KPI. Это позволяет оптимизировать процессы, инструменты и методики с целью максимизации выгоды, получаемой от неструктурированных данных.
Комментарии (3)

dyadyaSerezha
24.08.2023 18:44+1Пока вижу крайне тупое использование даже небольших структурированных данных. Например, если я искал активно и купил телевизор в инете, то мне в течение месяцев упорно суют рекламу телевизоров, хотя и ежику ясно, что сейчас для меня минимальная вероятность покупки телевизора. То есть, рекламные движки даже не разбираются в типах товаров, услуг и покупок.
С другой стороны, если мне нужен телек, то почти наверняка независимо от подсунутой мне рекламы я проведу минимальный анализ нескольких предложений и выберу лучший для меня.
Так что значение анализа big data сильно преувелияено, на мой взгляд. Не спорю, что есть отдельные ниши, где это важно и уместно, но текущий хайп вокруг этого явно завышен.
Kahelman
К сожалению ещё одна статья с теоретической компиляцией и отсутствуем примеров/ личного опыта.
Если верить специалистам «оттуда» то про лесу больших данных - отпада сама собой, в основном за счет роста производительности компьютеров( закон Мура)
Рекомендую к прочтению: https://motherduck.com/blog/big-data-is-dead/
Там автор с цифрами и фактами рассматривает почему у вашей компании нет про лес больших данных если вы не Google/FB/Yandex
dyadyaSerezha
Что такое про лес?