
Всем привет!
Меня зовут Валерий Локтаев, я backend-разработчик сервиса биллинга в CloudMTS.
В этой статье я расскажу, как насовсем убрать дублирующие записи в ClickHouse (CH). Логичный вопрос — откуда вообще взялась проблема? Можно взять движок таблицы ReplacingMergeTree, указать ORDER BY в качестве ключа дедупликации, и CH чудесным образом удалит все дубли в базе.
ReplacingMergeTree, безусловно, отличное решение. Но представьте, что ваша задача — сделать так, чтобы в таблице дубли никогда не появлялись, даже на несколько секунд.
Далее я расскажу, в каких случаях это необходимо и какое решение удалось подобрать.
Контекст: когда дубли становятся проблемой
CloudMTS использует CH в сервисе отчетов и предоставления клиентской детализации потребления ресурсов и их стоимости. Пользователь может зайти в личный кабинет и на графике увидеть все подробности потребления облачных ресурсов: по проектам, услугам, за конкретный период времени.
В личном кабинете потребление облачных мощностей подробно детализируется:
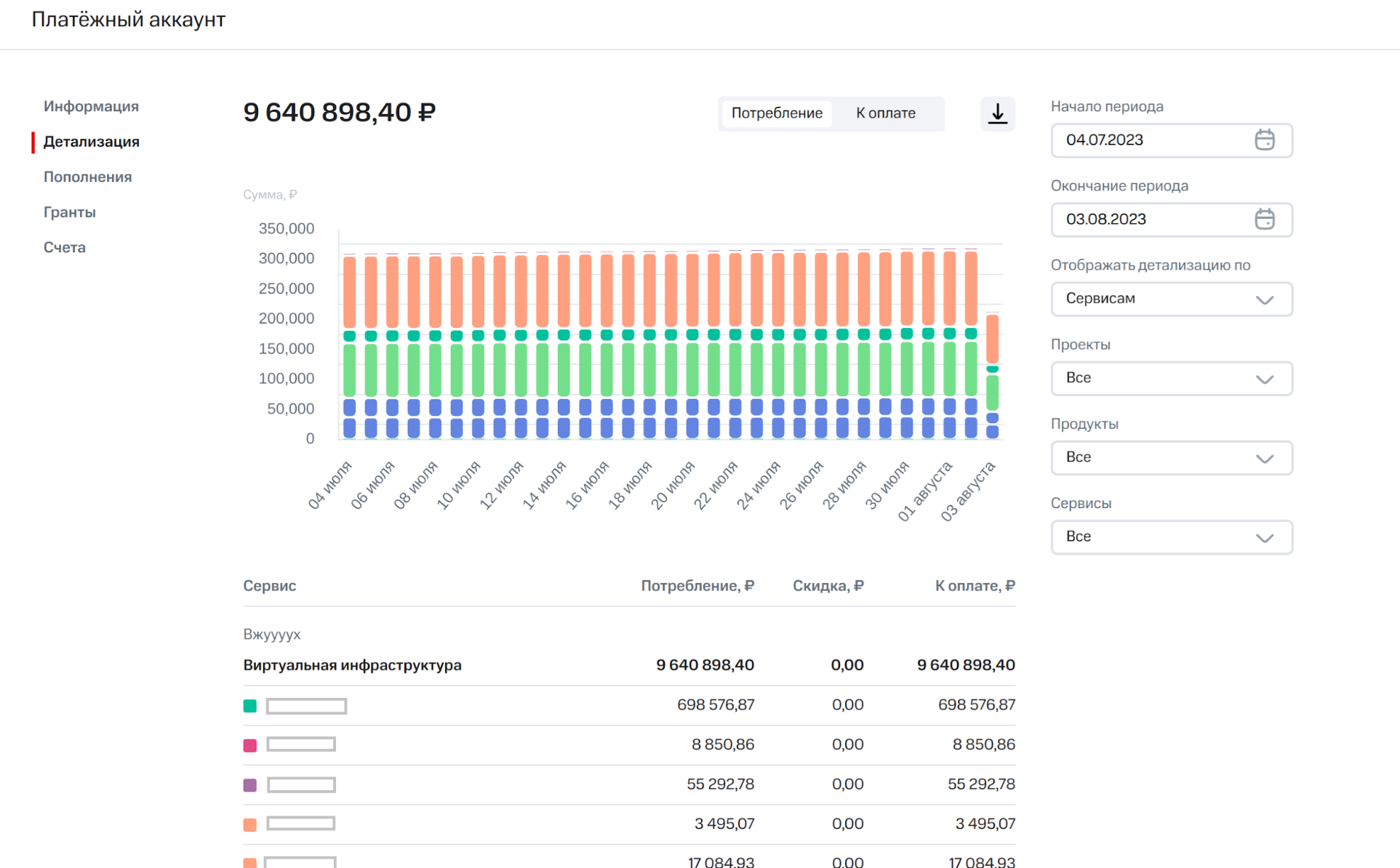
График формируется за счет агрегации метрик потребления.
Метрика потребления — уникальная сущность, которую биллинговая система получает от интегрированных с ней продуктов. В метрике находится информация о времени использования ресурса, количестве потребления, метаданные для идентификации пользователя и уникальный идентификатор.
Когда биллинговая система получает метрику, она процессит ее по пайплайну, где на каждом этапе над метрикой производятся какие-то действия, вычисления и т. д. В конечном итоге метрика попадает в сервис детализации.
Для общения между сервисами мы используем Kafka at-least-once, что может привести к появлению дублей. В свою очередь дублирующие записи ведут к искажению стоимости потребляемых услуг: если появится дубль, в личном кабинете сумма станет больше, чем пользователь потратил на самом деле. Такую ситуацию мы допустить не можем.
Поиск методов борьбы с дублированием данных
Изначально задача звучала так, что в теории у нее должен быть миллион решений. На практике для наших вводных ничего готового не существовало.
Обратившись к документации CH, отмечу следующие особенности движка ReplacingMergeTree:
- гарантируется отсутствие дублей во вставке (т. е. если в батче данных, которые летят на вставку, есть дубли — движок их удалит, в таблицу заедут уникальные значения);
- не гарантируется отсутствия дублей в таблице в определенный момент времени. Задача очистки от дублей происходит в фоне, в неопределенный неизвестный нам момент времени (CH лишь «обещает», что когда-нибудь дубли удалит);
- есть ручной вызов задачи по дедупликации с помощью OPTIMIZE (движок не начнет дедупликацию сразу, а лишь запланирует процесс, который когда-нибудь начнет);
- НЕТ точных гарантий, что дубли вообще будут удалены.
Такое решение нам точно не подходит.
Проведя ресерч, я нашел несколько реализаций, которые… почти работали, — всё равно так или иначе просачивались дубли.
Очевидный вариант — использовать движок Kafka, который напрямую может подключаться к брокеру, вычитывать сообщения и складывать в таблицу. К сожалению, движок не обеспечивает стратегию exactly once, что в итоге приводит к появлению дублей.
Следующая идея — развязочная таблица. Решение заключается в следующем:
{kind=link}
- Создаем таблицу Table 1, куда будем вставлять записи из «кафки». Мы не доверяем предыдущим в цепочке сервисам и проводим дедупликацию на своей стороне.
- Создаем развязочную таблицу Table 2, в которой будут храниться дедуплицированные ID уже вставленных в основную таблицу записей (в виде cityHash64).
- Создаем конечную таблицу Table 3, куда будут вставлены итоговые дедуплицированные записи.
- Создаем Materialized View (MW1), задача которой — при вставке новых записей в Table 1 проверить, нет ли записей с таким же ID в таблице Table 2. Если есть дублирующиеся записи, то их отбросим. Все остальные уникальные записи вставляются в таблицу Table 3.
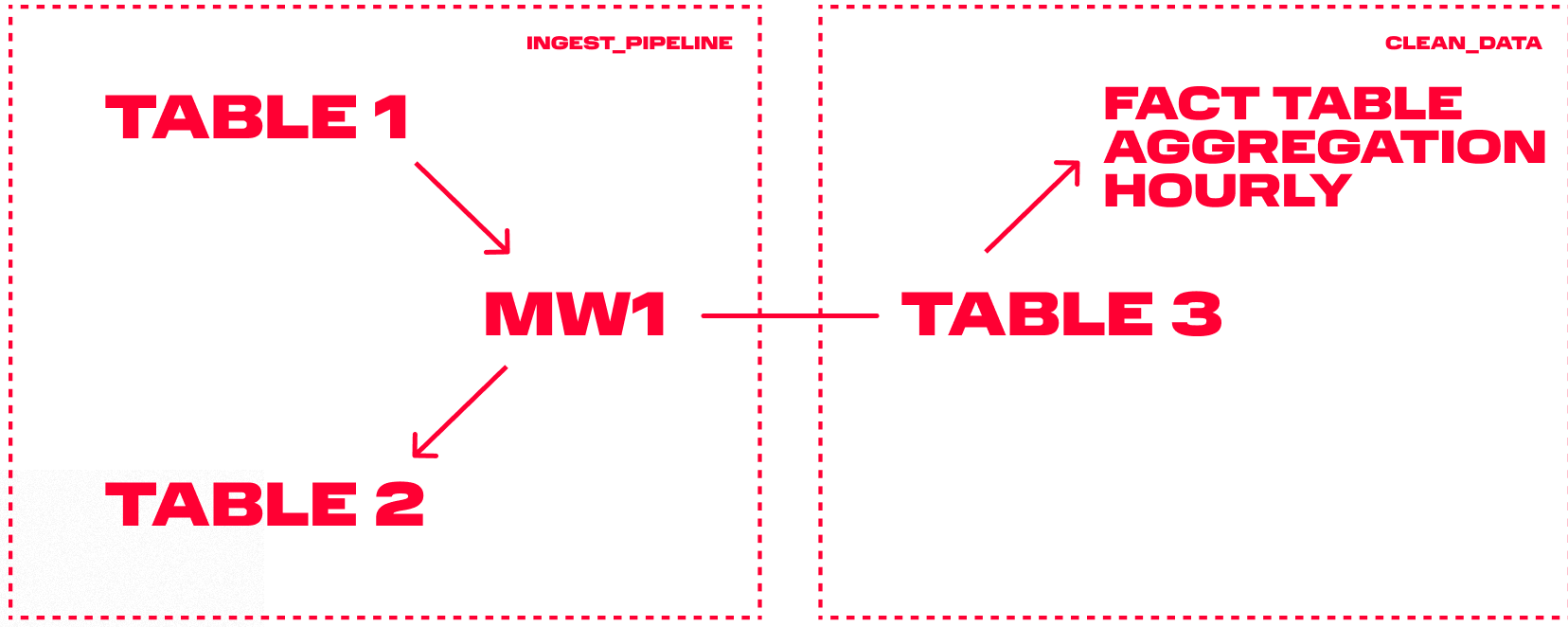
Звучит хорошо, но давайте разберемся, какие в схеме есть подводные камни.
Мы должны хранить ID всех уже вставленных записей в таблице Table 2. По мере роста количества записей замедляется время каждой вставки, так как каждый раз мы итеративно сверяем все записи друг с другом. Подразумевая в перспективе бесконечное количество записей, получаем бесконечное время на вставку.
Почему бы не сохранить только записи, которые пришли за последний расчетный период (день, неделю, месяц)? В таком случае существенно сократится количество проверок из каждой новой вставки. И действительно, это предположение валидно, мы могли так сделать. Вот только дополнительно мы закладывались на обработку аварийных случаев, когда нужно одним разом переотправить все метрики за неизвестный временной отрезок, чтобы иметь возможность что-то исправить, перерассчитать и т. д. В таком случае невозможно спрогнозировать, какое количество метрик будет в таблице и сколько времени займет вставка.
Вторая проблема заключается в параллельной вставке в таблицу Table 1 двух батчей, имеющих одинаковые записи. Для первой и второй вставки будет справедливо состояние таблицы Table 2, в котором нет повторяющегося в этих вставках ID. В таком кейсе мы все равно получаем дубли.
Неожиданное решение: две СУБД
Потратив достаточно времени на генерацию идей и танцев с бубном, я пришел к выводу, что нужно вынести таблицу Table 2 в инструмент, который хорошо умеет работать с удалением дублей за счет возможности строить уникальные индексы. Этот инструмент — MongoDB.
А зачем нужна еще какая-то зависимость, если можно все вставленные записи хранить в памяти сервиса, в кеше, и дедуплицировать их из кеша? Не забывайте, что наша задача — иметь возможность дедупликации за весь период. Мы не знаем конечное количество записей и, соответственно, не можем предположить конечное количество памяти.
В результате получилась следующая схема:
- Создаем коллекцию в MongoDB, где сохраняем только ID всех вставленных метрик. По этому же полю строим уникальный индекс.
- Создаем конечную таблицу в CH, где будут храниться метрики в дедуплицированном виде.
- При новой вставке в рамках транзакции вставляем записи в коллекцию MongoDB. Все записи, которые удалось вставить, считаем уникальными и инсертим их в основную таблицу CH. Всё, что не удалось вставить из-за отсутствия уникальности, — это дубли, которые мы игнорируем.
Такое решение хранит абсолютно все когда-либо вставленные ID записей в CH и позволяет дедуплицировать по ним за любой период времени. При этом затрачиваемое на дедупликацию время растет логарифмически, а не линейно.
В решении нет конкретной привязки к MongoDB. Команда выбрала ее, потому что имеет хороший опыт взаимодействия с этой СУБД и она подходит для решения подобной задачи. Если вы знаете другую технологию быстрой дедупликации, расскажите в комментариях.
Комментарии (28)

m0ody
31.08.2023 10:13Версионирование строк + FINAL не подходит?
И что будет, если вы вставили в mongo ключи, но при этом в КХ вставить не удалось по какой то причине?

sshawnta Автор
31.08.2023 10:13Версионирование строк + FINAL не подходит?
Такой вариант не рассматривали, будет здорово если расскажешь идею поподробнее.
Вставка в клик происходит в рамках монговской транзакции, в случае ошибки клика, откатим монгу.
Тут понятно, что может быть риск ошибки коммита или ролбека, попробуем еще раз, в крайнем случае - принимаем такой риск и захендлим волшебным скриптом, но пока не приходилось
m0ody
31.08.2023 10:13Для движка ReplacingMergeTree можно передать поле version в качестве параметра. version - это версия строки. Т.е. может быть N версий одного primary key.
Обычно для version удобно использовать timestamp изменения строки во внешней таблице, например.
Самая старшая версия в КХ является актуальной во внешней системе.
Далее используете модификатор FINAL для выборки самых последних версий строк.
SELECT * FROM table FINAL WHERE ...
И КХ вернет самую последнюю версию строк.
Так же вместо FINAL можно использовать ORDER BY pk, version DESC LIMIT 1 By pk, а так же argMax(field, version) с группировкой по pk.
sshawnta Автор
31.08.2023 10:13У нас есть основная таблица, где хранятся записи за короткий промежуток времени. (1-6 минут) При селекте мы агрегируем записи (час, день, месяц), на таком большом объеме данных это работает медленно, поэтому мы строим materialize view, где хранятся записи схлопнутые по часу, что существенно ускоряет выборку и агрегацию. Но записи в эту вьюху залетают при инсерте в основную таблицу. Как будто бы в твоём решение, мы сможем получать дедуплицированные данные из основной таблицы, но вставить во вьюхи без дублей мы не сможем, как думаешь?

kolya7k
31.08.2023 10:13Раз уж вы упомянули про OPTIMIZE есть еще OPTIMIZE FINAL, который выполняет оптимизацию сразу.

AIring
31.08.2023 10:13Но может быть такая проблема, что в clickhouse все успешно вставилось, а вы об этом не узнали, скажем, из-за сетевой ошибки. И пошлете данные еще раз. Как-будто это не сильно отличается от ситуации с кафкой и коммитом оффсета вместо коммита транзакции.

titan_pc
31.08.2023 10:13Всё Вам правильно рассказывают. На стороне клиента/сервиса который складывает данные в Kafka - пишете сюда(version) метку времени (вплоть до наносекунды). Не важно сколько раз Вы там ошиблись или послали одно и тоже хоть 100 раз (Например в браузере пользователь судорожно жмёт на кнопку "Сохранить" и не останавливается). На стороне сервиса/потребителя СУБД, который строит отчёт - всё элементарно, как и сказали "argMax(field, version) с группировкой по pk." или СрезПоследних по-старинке, если не доверяете argMax. Вы всегда будете получать только свежие строки среди дублируемых (Например у вас 20 строк с номером=1 - на выходе запрос покажет одну - самую свежую).
Суть этой идеи в том, что вообще не надо бороться с дублями, а просто контролировать их поток и отбирать самое нужное на уровне языка запросов.
Накладных расходов на эту идею в разы меньше, чем на супер схемы с MongoDB это уж точно. Так ещё и потом ClickHouse сам в фоне 19 строк грохнет =)AIring
31.08.2023 10:13Мой комментарий относился к этому
Вставка в клик происходит в рамках монговской транзакции, в случае ошибки клика, откатим монгу.
Не очень понятно в чем разница между коммитом транзакции в mongo и коммитом в kafka. Почему в одном случае риск приемлем, а вдругом - нет.
Суть этой идеи в том, что вообще не надо бороться с дублями, а просто контролировать их поток и отбирать самое нужное на уровне языка запросов.
Идея понятна, и что-то похожее, кажется, даже упоминалось в документации. Но надо учитывать, что подобная техника написания запросов сильно подвержена ошибкам. Очень легко забыть вставить нужное условие, а заметно это будет только когда дубли уже просочились. Аналитические запросы и так бывают на несколько страниц текста, усложнять их еще дополнительной фильтрацией мало кому захочется. Вероятно, проще 1 раз решить этот вопрос на уровне архитектуры и добавить накладных расходов, чем потом снова и снова править баги фильтрации дублей в различных запросах.
На самом-то деле проблема в том, что в самой базе отсутствует функциональность для такого важного и востребованного случая. Если бы авторы clickhouse не перекладывали заботу о дублях на плечи пользователей, то и не рождались бы супер-схемы с mongo или супер-запросы с фильтрацией по версии.
titan_pc
31.08.2023 10:13Идея понятна, и что-то похожее, кажется, даже упоминалось в документации. Но надо учитывать, что подобная техника написания запросов сильно подвержена ошибкам. Очень легко забыть вставить нужное условие, а заметно это будет только когда дубли уже просочились. Аналитические запросы и так бывают на несколько страниц текста, усложнять их еще дополнительной фильтрацией мало кому захочется
Хм. Кажется этот путь мы прошли уже своей командой. Он привёл нас к тому - что мы создали библиотеку, в которой пишем запросы, как набор JSON инструкций, которые движок потом в SQL на clickhouse переводит. Или в SQL на postgres. И у нас нет проблемы с поддержкой запросов и на 1000-10 000 строчек, не знаю сколько это в листах (в коде на JSON это мало строк - 100-300 в красивом если виде с отступами, обычно в 10-15 раз меньше и проще). Не подумал я, что большие запросы - это проблема, вот я к чему.
В аналитических отчётах 100% будет group by и агрегация и джоинов мешок и СКД. И рассказать разработчику что нужно ну argMax(field) писать вместо просто field ну не проблемно вроде (для нас точно). Поэтому и дальше идём этим курсом (версии строк).
Ценность в том, что на момент вставки не нужно ничего дедублицировать и вычислять что-то. Ресурсы не траться, как бы много данных не было на входе. И отдельная СУБД не нужна - с дополнительными кэшами. Вставляй-не хочу называется.
Да - запрос становиться чуть сложнее. И выполняется он чуть дольше. Процентов на 10%, что легко компенсировать дав кластеру не знаю, на 1-2 ядра больше на ноду, ну и разработчику - шоколадку с кофем, да и всё.
А если хочется и вовсе вернуться к прежнему запросу. То Можно 2 таблицы сделать. Одна первичная. А во вторую как раз свежак скидывать, и из неё уже черпать. Но это инпут-лаги. Например, сохранил документ в браузере, он такой ОК. А там не ок ещё) И тут Redis приехал или другой mem-cache. Ну кароче зоопарк. И зукипер ещё поставить за зоопарком смотреть. Или толстый фронт с кэшированием данных на клиенте. Или всё вместе...
А можно просто 1 таблицу и argMax вместо вот этого всего и 2 ядра по братски на кластер выбить за ящик пива.
А про clickhouse и его разработку думается - что там нет волшебной пелюли от дублей, потому что там как раз есть версии. Мы как эту волну поймали - так на ней и плывём на всех проектах.AIring
31.08.2023 10:13А про clickhouse и его разработку думается - что там нет волшебной пелюли от дублей, потому что там как раз есть версии.
Скорее просто этой задаче не выделялось достаточно ресурсов. В принципе, тот же подход с фильтрацией по версиям можно было реализовать на уровне базы и скрыть от пользователя.
А вообще уникальные ключи есть в roadmap на 2023 и даже есть PR на новый движок таблиц от неравнодушного пользователя.
sshawnta Автор
31.08.2023 10:13Пробовали что-то похожее. Проблема в том, в основной дедуплицированной таблице хранятся метрики за коротки промежуток времени, и их агррегация по часу, дню, месяцу на селекте отрабатывает достаточно долго из-за большого количества. Поэтому мы строим Materialize View, где храним агрегированный по часу метрики, но поскольку записи во вьюху залетают во время вставки в основную таблицу, то если в основную заедут дубли, то они заедут и вовьюху. Хотя в таком варианте, можно закидывать во вьюху "только свежие строки среди дублируемых

Ivan22
31.08.2023 10:13а как эта Matview джоинит таблицу CH с таблицей Монги????
sshawnta Автор
31.08.2023 10:13Не очень понял вопроса. matview не джойнит таблицу ch с монгой, мы делаем в ставку в монгу, проверяя тем самым записи на уникальность, все уникальные записи вставляются и в монгу и в таблицу в CH, на основании этой вставки мы закидываем данные в matview с агрегацией метрик по часу
AIring
31.08.2023 10:13+2Пару лет назад, когда перевозили аналитику из postgres в clickhouse, тоже столкнулись с такой проблемой отсутствия гарантии уникальности в кликхаусе. Решено это было путем проверки id не в сторонней базе, а в самом clickhouse. Перед тем как вставить пачку записей, мы делаем select по их id из clickhouse и удаляем из пачки те записи, которые в базе уже есть. Проблемы с одновременной вставкой у нас нет - в один момент времени у нас всегда один консьюмер очереди и он же вставляет данные в кликхаус. Для наших нагрузок такого способа вполне хватило.

Opeth24
31.08.2023 10:13Вы не рассматривали AggregatingMergeTree c anyLast?
sshawnta Автор
31.08.2023 10:13Из за того, что строим materialize view от основной таблицы, где храняться агрегированные по часу записи, куда записи залетают при инсерте в основную таблицу. Если на моменте инсерта будет дубль в основной таблице, то он залетит во вьюху и убрать оттуда его будет уже куда сложнее, т.к там нет уникальных идентификаторов

iimos
31.08.2023 10:13+1А как обеспечивается атомарность этих двух инсертов? Что если после вставки в монгу, сервис упал?
sshawnta Автор
31.08.2023 10:13Думаем как лучше захендлить эту историю, а пока принимаем такой риск, пока такого не случалось, но если случится, етсь скрипт, который все подправит. А вот история с дублями при чтении из кафки постоянно случается с первых минут работы сервиса

SSukharev
31.08.2023 10:13Нагородили непойми чего на пустом месте. А все от того,, что нет у вас базовых знаний по хранилищам данных и etl. Дом пионеров, кружок умелые руки.
sshawnta Автор
31.08.2023 10:13Привет, возможно)) но я долго пытался найти решение, которое будет полностью покрывать наш кейс, и хорошее, быстро работающие я не смог найти. Если ты знаешь как решить эту задачку для описанного кейса - буду рад ознакомиться!

scribe224
31.08.2023 10:13почему бы вместо монго не воспользовались таблицей мемори энджаина? второй вопрос, неужели нельзя обойтись без id строки, уникальность строки обеспечивает её содержимое, разве нет? сам столкнулся с аналогичной проблемой, и да, терплю долгую вставку данных тк есть матвью на результат вставки...

iboltaev
31.08.2023 10:13Может я что-то не понял, а в чем проблема сделать:
1) таблица1, в нее льется из кафки, она НЕ replacingMergeTree, и там есть дубли
2) таблица2, которая в теории уже дедублицирована
3) матвьюха из т1 в т2, которая содержит оконку типа count по ключу дедубликации и фильтр where count = 1 ? Ну то есть чтобы следующие дубликаты уже не пропускал
?
ADDED: попробую у себя погонять
Aquahawk
А у вас у записи что нет таймстампа? Откуда берётся
В клике же всегда рекомендуется использовать в качестве первичного ключа время (или другой растущий идентификатор). Это решило бы ваши проблемы
Про монгу вы пишете
Это же на одну запись логарифмически а не линейно. Т.е. на вставку N новых строк в базу где есть M уже имеющихся получится N*log(M). К лике если правильно селектить получится ближе к N * const, потому что если учтён таймстамп то клику вообще пофигу сколько там за его пределами лежит
Да, гонку параллельной вставки моё предложение не решает
sshawnta Автор
Таймстампы есть, как вариант можно их использовать, для сокращения выборки при проверки на уникальность, но это действительно не отменяет параллельной вставки.
Если говорить про первичный ключ, то мы используем временноую переменную в ключе для партицирования, но поскольку движок Replacing не умеет в отсутсвие дублей на уровне всей таблицы в любой момент времени, то можно выбрать любой ключ, нашей задаче это не поможет.
Если говорить про вставку батчем тут действительно N*log(M)
Throwable
Не берусь говорить о конкретной реализации движка, но теоретически хеш индексы дают константный доступ для одной записи, соответственно время растет линейно. Для дедуплицирования нет необходимости использовать btree.