Существует мнение, что ChatGPT-4 стал работать хуже, чем раньше, а кто‑то говорит, что он совсем «отупел», и уже «не торт». Я решил разобраться в этом вопросе, определить и сравнить длину контекста у ChatGPT-3.5 и платной ChatGPT-4.
Количество информации, которое модель может удерживать в памяти во время диалога с пользователем, зависит от длины контекста. Длина контекста измеряется в количестве токенов. В зависимости от используемого языка в диалоге с ChatGPT используется различное количество токенов.
В теории, при равной длине контекста, ChatGPT должен удерживать в памяти в 5 раз больше текстовой информации написанной на английском языке, чем на русском. Для определения количества токенов можно воспользоваться токенизатором от OpenAI.
Пример:

Цели эксперимента
Выяснить как на самом деле длина контекста зависит от используемого языка и во сколько раз меньше информации может запоминать ChatGPT на русском языке, чем на английском.
Определить фактическую длину контекста у ChatGPT-3.5 и сравнить её с платной версией ChatGPT Plus, подписка на которую стоит 20 долларов в месяц. И если по API GPT-4 официально известно, что длина контекста составляет 8 тысяч или 32 тысячи токенов, то информация о длине контекста веб-версии ChatGPT-4 остается лишь предметом дискуссии на форумах OpenAI. Некоторые утверждают, что это 4 тысячи токенов, другие — 8 тысяч.
Давайте выясним, что на самом деле происходит и что пользователи получают за свои деньги.
Метод проверки
Мой метод проверки заключается в следующем. Я начинаю с предоставления некоторых исходных данных и затем добавляя информацию путем отправки сообщений в чат и параллельно считая количество токенов, пытаюсь определить момент, когда модель теряет доступ к этим исходным данным. Иными словами, я хочу выяснить, в какой момент добавление новой информации вытесняет первоначальные данные из контекста модели.
Заранее скажу, что результаты, полученные мной через этот эмпирический метод, меня сильно удивили. Возможно, именно они могут объяснить, почему последнее время многие пользователи стали замечать ухудшение качества работы ChatGPT-4.
Итак, начнём с ChatGPT-4 и будем использовать русский язык.

В первом промпте я сообщаю имя мальчика, который является героем истории, которую буду рассказывать. Стоит отметить, что саму историю я также сгенерировал с помощью языковой модели, и в ней имя героя не упоминается. Отправляя сообщения с фрагментами этой приключенческой истории, я веду диалог с ChatGPT. Периодически я спрашиваю модель о имени главного героя. Если ответ верный, я удаляю вопрос про имя и продолжаю рассказ, считая при этом количество токенов.
Пример верного ответа:

Важно учесть, что в контекст входят как мои сообщения, так и ответы модели. В определённый момент ChatGPT-3.5 не может назвать имя героя, что означает, что моё первое сообщение с этой информацией вытеснено из рабочей памяти модели.
Аналогичным методом я провожу тестирование на английском языке, после чего перехожу к ChatGPT-3.5 и проверяю её на обоих языках.
Результаты эксперимента
Фактический объём памяти ChatGPT-4 в зависимости от используемого языка
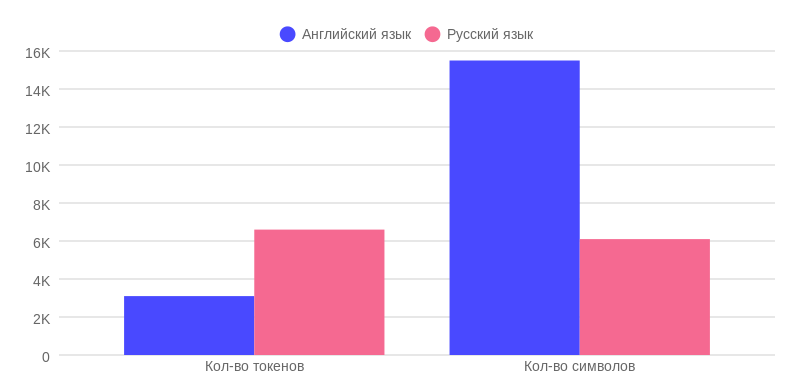
Итак, первый результат сразу же показывает отклонение от обещанных 8.000 токенов. Фактическая рабочая память ChatGPT-4 на русском языке составляет всего 6.600 токенов. Это на 1.400 токенов меньше обещанных. Куда они могли подеваться? Возможно, это связано с тем, что в архитектуре GPT-4 присутствуют основная модель и несколько вспомогательных, что делает её "умнее". Именно на общение между этими моделями, так называемые системные промпты, и уходят эти 1.400 токенов.
Я удивился ещё больше, когда обнаружил, что рабочая память ChatGPT-4 на английском языке составляет всего 3.100 токенов, а это значительно меньше заявленных 8.000. Я неоднократно перепроверил эти данные и до сих не знаю, как объяснить, что модель на английском языке удерживает в памяти в два раза меньше информации в токенах, чем на русском? Это экономия ресурсов или что-то другое? Почему я не слышал об этом ранее, особенно учитывая, что большинство подписчиков ChatGPT Plus используют модель именно на английском языке?
Несмотря на то, что ChatGPT-4 все ещё удерживает больше символов в контексте на английском языке, чем на русском: примерно 15.500 против 6.100 символов. Однако разница не в 5 раз, а фактически всего в 2,5 раза. Получается, что количество токенов для "английской" версии явно было урезано.
Фактический объём памяти ChatGPT-3.5 в зависимости от используемого языка
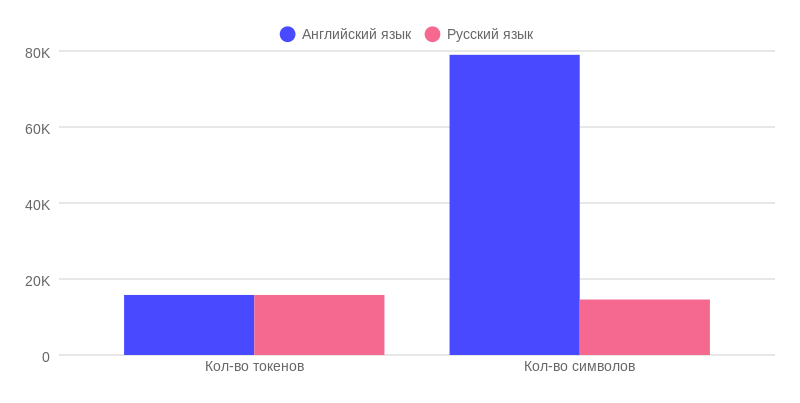
Теперь давайте взглянем на результаты ChatGPT-3.5. В отличие от платной версии, её фактическая память составляет примерно 15.800 токенов для обоих языков. Учитывая погрешность +/- 100 токенов в зависимости от версии токенизатора мы получаем результат, близкий к заявленным 16.000 токенам.
На диаграмме выше наглядно видна разница в фактическом объёме памяти между английским и русским языками при равном количестве токенов: 79.000 символов на английском против 14.600 символов на русском. Для лучшего представления этого объёма информации, 80.000 символов — это примерно 100 страниц формата А4.
Также стоит помнить, что качество ответов ChatGPT-3.5 на английском языке в большинстве случаев выше, поскольку модель обучалась на значительно большем объёме данных на английском языке, чем на других.
ChatGPT Plus vs. Бесплатный ChatGPT-3.5
Максимальное количество токенов в одном сообщение
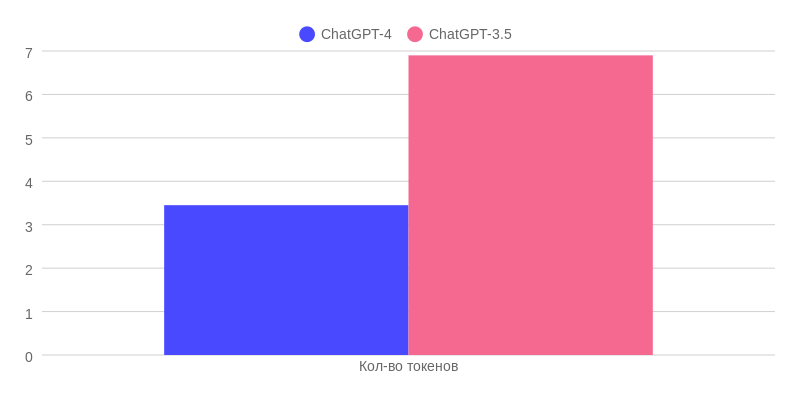
В ChatGPT-3.5 можно одним сообщением отправить в два раза больше токенов — 6.900, а значит, и информации, чем в ChatGPT-4. Это можно использовать, например, для демонстрации примеров конечного результата: описать задачу и конечный результат, а также добавить несколько примеров в это же сообщение. Ведь размер сообщения в ChatGPT-3.5 в два раза больше.
Фактический объём памяти разных моделей ChatGPT в токенах

Фактический объём памяти у ChatGPT Plus значительно меньше, чем у ChatGPT-3.5. Особенно заметно это на "английской" версии, где она даже не превышает 3.400 токенов.
Что это означает на практике?
Если вы первым сообщением на английском языке даёте вводную информацию, а во втором сообщение используете максимальное количество токенов то ChatGPT-4 уже не сможет назвать вам имя мальчика, так как вводная информация была полностью вытеснена вторым сообщением. Даже спросив имя мальчика сразу в самом начале второго сообщения, ChatGPT-4 не сможет ответить верно. Пример:

Фактический объём памяти разных моделей ChatGPT в символах
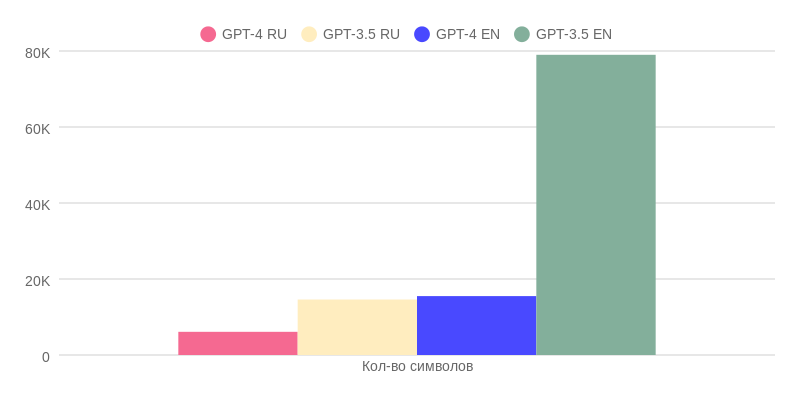
Объём памяти у ChatGPT-3.5 на русском языке почти в два с половиной раза больше, чем у ChatGPT-4. Однако стоит помнить, что качество ответов у последней модели значительно выше.
Если же мы используем английский язык, разница в качестве ответов между двумя моделями не так велика. Зато у ChatGPT-3.5 есть пятикратное преимущество в фактическом объёме памяти, поскольку у ChatGPT-4 урезали длину контекста.
Вместо вывода
При использовании ChatGPT преимущественно на русском языке имеет смысл приобрести подписку ChatGPT Plus за $20 в месяц и использовать четвёртую версию, так как разница в качестве ответов того точно стоит.
Ситуация с английским языком не так однозначна, поскольку у ChatGPT-3.5 есть весомые преимущества перед ChatGPT-4: возможность отправить в два раза больше информации одним сообщением и пятикратный объём памяти по сравнению с четвёртой версией. Она, правда, уступает по "интеллекту", то есть по качеству ответов, но тем не менее, для определённых типов задач ChatGPT-3.5 подходит уж точно не хуже, чем её новая модель.
А вот если бы ChatGPT-4 предложили с длиной контекста в 32.000 токенов или хотя бы чистыми 8.000, а не эти 3.100 токенов, то тогда был бы другой разговор.
Кстати, как вы думаете, почему так её урезали? Интересно будет прочитать ваши версии в комментариях.
Слова благодарности
Эта статья не была бы возможна без ценного вклада Алексея Хакунова — человека, вдохновляющего меня изучать возможности ChatGPT в различных сферах: от бизнеса до личного использования. Я участвую в его крутом проекте с самого начала, где царит душевная атмосфера и предоставляется учебный контент высокого качества.
Лёша также ведет телеграм-канал про искусственный интеллект под названием "AI Happens".
Недавно у меня появился свой личный телеграм-канал “Taralas209”, там пишу об IT в Европе, а также о своём личном опыте и пути в этой области. Если кому-то интересно, то всегда welcome
Комментарии (41)

combo_breaker
04.09.2023 19:44+3Спасибо за эксперимент! Выглядит как ограничение размера окна контекста ChatGPT-4 не только в токенах, но и в символах - 16 тыс. символов. Можно это проверить, если повторить эксперимент, на этот раз забивая контекст очень токеноемким или малотокеноемким контентом. Тогда станет очевидно, обрезается ли контекст именно на 16 тыс. символах.

Taralas209 Автор
04.09.2023 19:44Спасибо, что ознакомились и вникли в суть эксперимента! По поводу количества символов, то по сути буквы русского языка - это токеноемкие символы по сравнению с буквами английского языка. Это собственно и показано на диаграме "Фактический объём памяти разных моделей ChatGPT в символах"
ChatGPT-4 RU - 6100 символов
ChatGPT-4 EN - 15500 символовcombo_breaker
04.09.2023 19:44Вы предполагаете, что "фактическая память" ограничена некоторым количеством токенов, существенно меньшим потенциального лимита модели. Я же предполагаю, что дополнительного ограничения по токенам нет (это видно из того, что в вашем эксперименте ChatGPT-4 переваривает в два раза больше токенов при тексте на русском), зато есть именно по лимиту символов обрезание текста или триггер суммаризатора.
Кириллические символы для такого дополнительного эксперимента слишком токенозатратные. Нужно вводить более 16 тыс. символов, при этом укладываясь в ограничение модели по токенам в 8к. Если всегда будет обрезаться именно на ~16 тыс. символах независимо от количества токенов и их символоемкости - значит именно по символам режут (или включают суммаризатор, как выше предположили, но уже на этой отсечке в ~16 тыс. символов).
Taralas209 Автор
04.09.2023 19:44Ваше предположение действительно интересно, и я, например, заметил, что ChatGPT-3.5 на сообщение "Напиши мне историю про мальчика" выдавала ответ максимум в 3.000 символов, как на русском, так и на английском языке. Даже когда я её просил "продолжай историю", она снова выдавала около 3 000 символов. И тут действительно ограничение по символам, а не токенам. ChatGPT-4, кстати, тоже больше 3 000 символов на английском не выдавала, на русском не помню.
НО, например, если мы говорим про максимальное количество информации, которое можно отправить одним сообщением, то тут ограничение как раз в токенах, а не в символах. Например, в ChatGPT-3.5 можно отправить около 6 800 токенов, и разница в символах между русским и английским языком в те самые 5 раз. То же самое и в ChatGPT-4, только там максимально около 3 400 токенов за одно сообщение. На днях я делал тесты с включенными плагинами и в режиме Advanced Data Analyst, и там результаты показывают, что ограничение тоже по токенам, а не символам.
Как написал один пользователь в комментариях ниже:
"Вы забиваете что ChatGpt это бизнес. Скорее всего они изучают и оптимизируют модель . Зачем ей столько токенов, если среднему пользователю хватает значительно меньше ?"
Поэтому может быть посмотрели метрики и сделали вывод, что для 80% или 90% пользователей длина контекста в 3к токенов на английском языке вполне достаточно, а вс остальные языки не стали трогать, так как английский это основной + большинство используют ChatGPT в обычном режиме. Ну это тоже предположение :)

shachneff
04.09.2023 19:44+2Возьмите не их готовый чат, а раздел Playground к их API. Так получится больше контроля, и мы уберем посредника между пользователем и моделью, котроый оптимизирует и/или обрезает контекст.
При работе через playground модель в какой-то момент вам скажет, что контекст в нее не помещается. И не нужно будет проверять знание имени мальчика.
combo_breaker
04.09.2023 19:44+2Параметры модели при работе через API четко прописаны, нет смысла их проверять, в отличие от ChatGPT. И потом, API - другой продукт для других клиентов.

Regis
04.09.2023 19:44+2Зачем спекуляции и предположения в плане количества токенов, если можно запустить токенайзер от самого OpenAI?
https://github.com/openai/tiktokenTaralas209 Автор
04.09.2023 19:44Что даст вам токенайзер, если вы проверяете длину контекста ChatGPT (веб-версия), которая публично нигде не указана? По крайней мере, я не нашёл официальных данных.

riv9231
04.09.2023 19:44+1Я использую chatGPT4 через бота в телеграмме для составления SQL-запросов, сложных регулярных выражений и изучаю всякие приемы в bash. Раньше я часто просил доработать запрос или переделать код с учетом ошибок или мог задать вопросы по решению. Последнее время, я сталкиваюсь с тем, что иногда, несмотря на включенный контекст, ответ приходит таким, словно истории не было вовсе. Вот сегодня так было. Причем, я долго пытал модель, выдавливая из неё нужный вариант, и вдруг она выдала неожиданно длинный ответ, абсолютно верный и учитывающий все нюансы поставленной задачи. Причем модель вместо куска кода выдала цепь рассуждений вперемешку с кусками кода, который она как бы дорабатывала, двигаясь от наивного понимания задачи к точному решению, исключая по одной ошибке за итерацию.
Возможно, дело в том, что я как раз отключил контекст и составил задание по шагам. Тогда можно предположить, что результат будет лучше, если сообщать модели все знания о задачи сразу же в одном сообщении не полагаясь на внутренние механизмы управления контекстом, а сам контекст вообще отключить.

sneg2015
04.09.2023 19:44Подскажите, Вы используете именно gpt-4 в боте или 3.5?. И второй вопрос Вы платите 20$ за доступ к апи? Просто я думал над таким вариантом, но т потом решил не городить огород, а просто за 20$ использовать. Чатgpt, в его обычном интерфейсе.
Taralas209 Автор
04.09.2023 19:44Если вы заплатите 20$ за платную ChatGPT Plus (где есть ChatGPT-4), то при использовании API вам нужно будет отдельно подключить способ оплаты, и вы будете платить за API отдельно и за каждый использованный токен. Нужно также получить доступ к API 4-ки, хотя в последнее время это стало намного проще.
То есть, API и ChatGPT — это разные вещи, за них платить нужно по отдельности.

PrinceKorwin
04.09.2023 19:44Ну я для себя выбрал использовать их платное api + свою скромную обвязку вокруг. Это вышло дешевле в 2 раза даже с учётом аренды виртуалки. + большая свобода в количестве фич.
Taralas209 Автор
04.09.2023 19:44Ну, что дешевле, можно посчитать. Сильно же зависит от того, какие части и для каких нужд ты его используешь?
PrinceKorwin
04.09.2023 19:44В среднем в месяц у меня этот при выходит в $5 ещё столько же хостинг. Итого $10 вместо $20.
Но вот функционально у меня решение более богато.
Taralas209 Автор
04.09.2023 19:44Круто! Но судя по всему вы не так много токенов расходуете. Я быстренько прикинул и получил максимум около 5к токенов в день (если у вас GPT-4 API 8к)
А фичи сами писали или в открытом доступе, что-то есть? Могли бы ссылками поделиться, если что-то opensource использовали?PrinceKorwin
04.09.2023 19:44Сам писал. Код на Rust, это как раз мой pet-проект на котором я этот язык изучаю. Показывать там особо нечего, страшненький он.
Taralas209 Автор
04.09.2023 19:44Правильно ли я понял, что вы используете GPT-4 API в своём боте? Или же вы в используете чат ChatGPT-4?

DoctorCat92
04.09.2023 19:44Вы забиваете что ChatGpt это бизнес. Скорее всего они изучают и оптимизируют модель . Зачем ей столько токенов, если среднему пользователю хватает значительно меньше ?
Taralas209 Автор
04.09.2023 19:44Это хорошая мысль! Они могли посмотреть метрики и сделать вывод, что для 80% или 90% пользователей длина контекста в 3к токенов на английском языке вполне норм
alaudo
В вашей методологии есть несколько ошибочных посылок:
GPT-3.5 и 4 используют другой токенизатор, нежели GPT-3.
Нет никакой "рабочей памяти" модели, просто размер истории чата подрезается под размер входного ограничения модели, то есть в какой-то момент просто часть сообщений больше не передается модели.
Предельный размер "памяти" скорее всего ограничен не только ограничением модели, но и размером "технического" промпта, куда добавляется история чата.
Fell-x27
Еще могу сказать, что складывается ощущение, что у каждого сообщения в чате есть свое внутреннее представление, которое не обрезается, а, постепенно, упрощается. Чтобы держать больше контекста, система "подменяет" исходный текст на его сокращенную выжимку. А потом и ее пытается упростить, выжав самую суть. И так далее, пока оно не потеряет смысл.
У меня были моменты, когда даже в супер-длинных, нагруженных bashем диалогах можно было обращаться чуть ли ни к первому сообщению, мол "помнишь, с чего мы начали?". Хотя оно явно уже было за "границей", если считать "в лоб".
Плавное угасание контекста, вместо грубой обрезки, более эффективный подход.
Еств, такие частности как "имя мальчика", и при таком подходе пойдут под нож после первой же итерации "абстрагирования".
Но это догадки.
ruslaniv
Это не догадки. При превышении окна, чатгпт выполняет суммаризацию предыдущих промптов и ответов, а задача суммаризации - это в частности одна из задача на которые модели на основе архитектуры гпт хорошо заточены. Понятно что при очень длинном диалоге, где смысловых "блоков" становиться много - какие-то из них замещаются более важными (с точки зрения чатгпт естественно)
Taralas209 Автор
Интересная теория, но как объяснить тогда результат эксперимента полученный в этой части статьи "Фактический объём памяти разных моделей ChatGPT в токенах"?
И это случалось ни один или два раза, а каждый раз когда я повторял эксперимент
Fell-x27
В некорректной постановке эксперимента, думаю. И в проверке на основе запоминания высокочастотной информации, которая потеряется при первой же итерации обобщения устаревающего контекста.
Taralas209 Автор
Хм, ну вот вам контраргумент:
Если мы напишем первый промпт с именем героя, и потом, после ответа ChatGPT вторым сообщением отправим текст в размере 3к токенов и спросим, как звать мальчика, то модель ответит верно. А вот если размер второго промпта будет длиннее чем "фактическая память", то верного ответа не получим. Хотя по факту разница между количеством токенов этих сообщений будет всего 100-200 токенов, вряд ли это повлияло бы на ту самую суммаризацию, о которой вы говорите.
P.S: речь сейчас шла про ChatGPT-4 с использованием английского языка, но для русского языка всё то же самое, только количество токенов будет больше, и сообщений будет несколько
Fell-x27
Но мы ведь не знаем точно, по каким правилам эта суммаризация работает, чтобы строить гипотезы. Как она обрабатывает сообщения, как этот градиент затухания формируется, какие приоритеты. Может просто дело в том, что последнее сообщение всегда держится как есть. Может, если последнее сообщение больше n токенов, контекст должен обнуляться и это задано обычным ифом. Это все - гадание на черном ящике в любом случае.
Taralas209 Автор
Ваша идея плавного угасания контекста звучит интересно, хотя тоже является гаданием на чёрном ящике и не факт, что это есть у ChatGPT.
Напрактике же это больше похоже на простое обрезание контекста, когда он превышает определенный лимит токенов.
"Может просто дело в том, что последнее сообщение всегда держится как есть" - это не меняет сути: существует определенный лимит токенов, после которого ChatGPT "забывает" предыдущий контекст
"Может, если последнее сообщение больше n токенов, контекст должен обнуляться и это задано обычным ифом." - почему бы тогда не предположить, что когда в чате накапливается n токенов, часть из "первых" токенов просто "вытесняется" из контекста?
Fell-x27
Я имел ввиду такую ситуацию:
1) у нас есть 10 сообщений, в каждом по 10% бюджета. Итого 100% расходовано.
2) мы пишем новое сообщение, еще на 10% бюджета.
3) Каждое из предыдущих 10 сообщений оптимизируется, высвобождая по 2% бюджета, какие-то неважные мелочи были упрощены. Причем оптимизировались не равномерно. Предыдущее почти никак, предпредыдущее чуть сильнее и так далее. Самое первое пострадало больше всего. Это важно.
4) Освободилось 20% бюджета, сюда попадает наше новое сообщение на 10%, плюс место для ответа самого бота.
5) Итого, ничего не обрезалось, но ранние сообщения стали чуть более абстрактны.
Другой случай
1) Первое сообщение содержит 10% бюджета;
2) Второе содержит 90% бюджета;
3) Пишем третье на 10% бюджета. Включается оптимизация. Предыдущее сообщение подрезаем, первое забываем целиком, увы, иначе никак;
Третий случай, как вариация:
1) Есть одно сообщение на 10% бюджета;
2) Пишем еще сообщение, но на отвлеченную тему, составляющее всего 20% бюджета, но бот решает, что контекст беседы сменился, и обнуляет его, чтобы не мешал.
Касательно сброса контекста: https://chat.openai.com/share/ddc83b8f-5948-4f99-a424-551691a2daf3
Taralas209 Автор
Спасибо, что расписали, что вы имеете виду и мне правда нравиться ваша идея, но на тестах она никак не потдверждается. Я ещё раз напомню, что я хотел донести:
В эксперименте/тесте я хотел показать, что максимальное количество токенов (история переписки на английском языке) к которым у ChatGPT-4 есть доступ, намного ниже чем 8к и в 2 раза ниже, чем на русском языке.
Суммаризация тут ни при чём. Я перепроверил эксперимент и поменял первый промт (в котором указывал имя) на двух других варианта: математическая задача и рассказ истории про Антарктиду. И здесь как бы история должна с суммаризацией работать, но нет. У нас есть снова лимит, около 3.1к токенов где условно при 3.1к токенов модель делает верно суммаризацию, а при длине контекста в 3.150 уже нет. Возможно там и меньше "гэп", но я не видел смысла тестить дальше. Суть то одна: Есть лимит, после которого у модели "нет доступа" к информации из первого промта.
Вот пруфы:
https://chat.openai.com/share/115b4053-56b9-4b10-84da-f0681f27b60e
https://chat.openai.com/share/ad82a602-ecc3-4ed9-9ec7-fcd8f1e4d6b5
Касательно сброса контекста: Так вы же просто промтом запретили модели упомянать это, сработало со второго раза только. Но модель всё ещё "помнит", так как эта часть переписки помещается в её длину контекста. Я следующим промтом прошу "вспомнить" и она "вспоминает" снова. А всё потому что мы всё ещё не привысили длину контекста.
Вот посмотрите сами:
https://chat.openai.com/share/a09b1bb3-5199-4133-95c3-0032488b4f2d
А вот после последнего ответа добавить достаточное кол-во токенов, чтобы "вытеснить" последнюю информацию про вычисление факториала, то модель больше это не вспомнит.
Taralas209 Автор
В статье рассматриваются ChatGPT и ChatGPT Plus, а не модели сами по себе.
alaudo
Это понятно, но ни одна из них не использует GPT-3, насколько мне известно.
Taralas209 Автор
Я согласен, что подсчёт токенов у ChatGPT-4 и ChatGPT-3.5 может отличаться от токенизатора на сайте OpenAI. Я уже упоминал об этом, и мои подсчёты могут различаться с токенизатором ChatGPT-4 на 5-10%. Однако видно, что для ChatGPT-3.5 "фактическая память" составляет около 16к токенов на русском и английском языке. Для ChatGPT-4 на русском это около 6.6к, а на английском — 3.1к токенов. Разница почти вдвое. Судя по тестам, которые я проводил вчера (результаты на днях выложу), токены для ChatGPT-4 подсчитываются так же, но для английского языка в обычном режиме урезаны
KivApple
Если предположить, выбор лимита на основе наличия не английских символов в промте, можно протестировать смешанные промты, где есть текст на двух языках. И посмотреть как пропорция будет влиять на запомненный объем. Если на русском 90% текста, 50%, 10%...
Taralas209 Автор
Это хорошая идея, спасибо! Сделаю на днях такой тест и поделюсь результатами
Taralas209 Автор
Интерсно узнать, откуда у вас информация про то, что используется другой токенизатор, который бы давал разница в 2 раза по сравнению со старым? Или это просто гипотеза?
Ну да, это и есть - длина контекста. То есть какое кол-во информации из чата вмещается в последний промт, который и обрабатывает модель.
Не совсем понял о чём вы? А вы на сколько вникали в то, что я писал с статье выше? Вы как бы можете другими словами называть, то что я назвал "длина контекста" или "фактическая память", но сути это не меняет
Kergan88
Речь о том, что "забывание" имени мальчика не является ни достаточным ни необходимым условием исчерпания контекста. Поэтому оценить размер контекста таким образом невозможно.
Taralas209 Автор
Окей, тогда давайте так:
1. Что, на ваш взгляд, является достаточным и необходимым условием для исчерпания контекста? Есть ли предложения о том, как можно было бы поставить эксперимент более корректно? Был бы рад услышать ваши мысли и протестировать их.
2. Мои размышления были следующие: имя мальчика — это часть контекста. Если спустя определённое количество токенов модель не может вспомнить это имя, значит, она "забыла" эту информацию и не имеет к ней доступа.
При проверке результатов этого теста многократно я заметил, что именно после определённого числа токенов модель то имеет доступ к информации, то не имеет.
alaudo
Скажем так -- мне по-работе приходилось писать токенизаторы для GPT всех версий.
Размер промпта не обязан быть равен максимальной ёмкости модели. Как Вам писали в других комментариях, чистую оценку может дать только Playground. Размер промпта + размер истории + резерв на технический ответ + резерв на ответ для пользователя = максимально ограниченный размер промпта. Здесь слишком много переменных для точной оценки.
Вообще этот параметр, что вы пытаетесь оценить, называется max tokens (и измеряется, да, в токенах). Но это не совсем память. Память может быть по идее намного больше, поищите например, что такое Retrieval (Enhanced) Transformers.
Taralas209 Автор
Хорошо, давайте ещё раз.
В эксперименте/тесте я хотел показать, что максимальное количество токенов (история переписки на английском языке) к которым у ChatGPT-4 есть доступ, намного ниже чем 8к и в 2 раза ниже, чем на русском языке.
Суммаризация тут ни при чём. Я перепроверил эксперимент и поменял первый промт (в котором указывал имя) на двух других варианта: математическая задача и рассказ истории про Антарктиду. И здесь как бы история должна с суммаризацией работать, но нет. У нас есть снова лимит, около 3.1к токенов где условно при 3.1к токенов модель делает верно суммаризацию, а при длине контекста в 3.150 уже нет. Возможно там и меньше "гэп", но я не видел смысла тестить дальше. Суть то одна: Есть лимит, после которого у модели "нет доступа" к информации из первого промта.
Вот пруфы:
https://chat.openai.com/share/115b4053-56b9-4b10-84da-f0681f27b60e
https://chat.openai.com/share/ad82a602-ecc3-4ed9-9ec7-fcd8f1e4d6b5