Привет, Хабр! На связи команда Frontend-разработки Учи.ру. Знаем, что сейчас активно развиваются SSR-фреймворки — Next.js и другие. Если ваше приложение создано с использованием подобной технологии, вы можете отслеживать корректность его работы с помощью интегрального мониторинга. В этом материале мы расскажем, почему он важен, какие инструменты позволяют его проводить, как с ним работать Frontend-разработчику. И конечно, поделимся своим опытом — как нашли и исправили серьезную ошибку в продукте.
Зачем нужен мониторинг
Интегральный мониторинг охватывает все возможные уровни возникновения критических ситуаций. Он позволяет убедиться, что корректно работают обе части приложения — и клиентская, и серверная.
Если искать ошибки только на стороне фронтенда, легко пропустить проблему. Представим, что с бэкенда ответ приходит пустым или с большой задержкой — мониторинг на фронтенде этого не покажет, и вы будете терять пользователей. Аналогичная ситуация может происходить и в том случае, если вы мониторите только бэкенд.
При разработке SSR-приложения ответственность за все части интегрального мониторинга ложится на Frontend-разработчика. Это нестандартная задача для значительной части фронтендеров, поскольку требует знаний, выходящих за рамки разработки браузерного приложения. Но наша команда разобралась, как настраивать и проводить мониторинг — и мы готовы поделиться опытом! :-)
Какие инструменты использовать
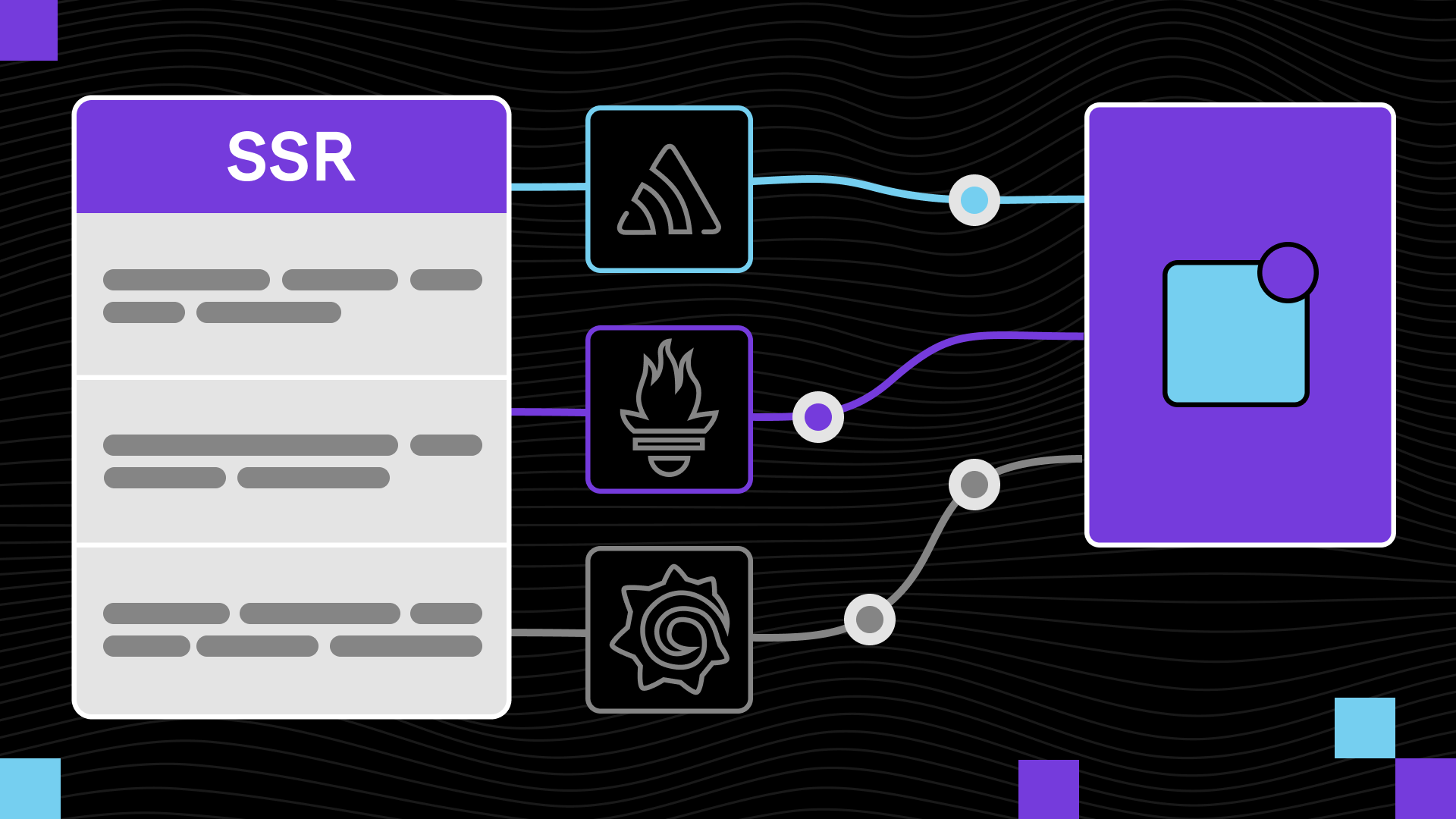
Интегральный мониторинг приложения можно проводить с помощью разных сервисов, но наша команда предпочитает работать с Sentry, Grafana, Prometheus и Elastic APM. Разберем подробнее, что из себя представляет каждый инструмент.
Sentry — это программа с открытым исходным кодом, предназначенная для отслеживания ошибок. Она показывает все сбои в стеке по мере их возникновения и предоставляет данные, которые помогут их исправить.
В процессе развития к сервису добавилась трассировка, которая позволяет оценивать производительность приложений. Однако мы этот инструмент используем именно для первоначальной задачи.
Grafana — это мультиплатформенное веб-приложение для аналитики и интерактивной визуализации с открытым исходным кодом. Оно предоставляет диаграммы, графики и оповещения при подключении к поддерживаемым источникам данных.
Prometheus — это система сбора и хранения метрик в формате временных рядов, а также система оповещения об инцидентах. Prometheus предоставляет доступ к метрикам через web-интерфейс.
Grafana и Prometheus обычно используются в связке, поскольку перед тем, как отобразить данные, их нужно куда-то собрать. Как раз сервис Prometheus аккумулирует данные и передает их в Grafana. Хотя мы используем и другие источники данных: например, тот же Sentry (для мониторинга общего количества ошибок на фронтенде) и Kibana (для мониторинга событий).
3. Elastic APM — это мониторинг производительности приложений, который способен решать различные задачи. Наша команда чаще всего использует только одну его фичу — сквозную трассировку, которая позволяет отслеживать, как составляющие сервиса передают друг другу запросы из бэкенда, фронтенда и SSR, и сколько времени на это уходит.
На какие метрики обращать внимание
В первую очередь стоит заняться настройкой четырех «золотых сигналов SRE». Рассмотрим каждый подробнее.
Задержка показывает, сколько времени занимает обработка запроса. Например, сколько может пройти от момента выдачи в браузер до конца рендера или от начала запроса пользователя в адресной строке до момента загрузки приложения.
Трафик показывает, сколько запросов и транзакций происходит в единицу времени в сервисе.
Ошибки могут подсказать, с какими конкретно запросами есть проблема.
В случае с последней метрикой важно помнить, что на фронтенде всегда будут ошибки, если у вас высокий трафик — поскольку есть большая вариативность клиентов и негарантированный канал связи. И имеет смысл мониторить не наличие ошибок вообще и не абсолютное их количество, а относительное.
4. Насыщенность говорит о том, насколько вы близки к полной загрузке сервиса: то есть, как долго сервис сможет оставаться жизнеспособным, если трафик сильно вырастет.
Эта метрика не нужна, если в приложении нет бэкенда. Однако если есть SSR или бэкенд-код, мониторить ее состояние стоит.
В дашборде важно всегда учитывать ключевые метрики жизнеспособности продукта: не только загрузку сервера, статусы кодов ответа, ошибки на бэкенде и фронтенде, трафик и задержки, но и любые другие метрики, которые помогают убедиться, что пользователи не испытывают проблем при использовании продукта. Например, если вы разрабатываете сложную форму, где важно учитывать конверсию (заполнение формы и ее отправка через кнопку), то следует учесть такую метрику в мониторинге.
Чтобы вовремя реагировать на критические моменты, следует определить условия для отправки оповещений ответственной за продукт команде. Они должны учитывать только самые ключевые проблемы, которые могут возникнуть в приложении. Если оповещений станет слишком много, то они превратятся в «шум», за которым можно пропустить действительно критическую ситуацию.
Как понять, где проблема
Мониторинг позволяет выгружать показатели «золотых сигналов» и других метрик с определенной частотой. Средние значения метрик лучше не считать — будет ничего не понятно (особенно, когда происходят выбросы).
Чем детальнее метрика, тем яснее картина. А увидеть значительные проблемы позволяют показатели перцентильные (описывают частоту большинства значений) и медианные (описывают типичные значения).
Давайте посмотрим, как это выглядит в Grafana. Вот, например, перцентильные значения для распределения времени отклика страницы: P50, P90, P99. P50 — это медиана, P90 и P99 — это 90-й и 99-й перцентили.

Видно, что у половины пользователей задержка составляет менее 281 миллисекунды. Для 90% пользователей задержка меньше или равна 725 миллисекундам, для red (99%) — менее 1 секунды. Метрика отклика страницы в диапазоне P90 находятся в приемлемом значении: значит, пользователи приложения не испытывают проблем с загрузкой страницы.
Как мониторинг помогает справляться с трудностями
В прошлом году наша команда запустила новый продукт — интерактивный учебник, для написания которого использовался фреймворк Next.js. Под этот продукт мы также настроили мониторинг. Когда все было готово, увидели в Grafana, что у 90% пользователей (P90) некоторые страницы учебника открываются с задержкой более двух секунд. Это высокое значение для довольно статичного контента. Поэтому мы стали выяснять, в чем проблема.

На графике за последние пять минут мы увидели другую картину: у большинства юзеров страница открывается в течение 1 секунды.

То же было и в Elastic. Однако 95 перцентиль (отображен на графике ниже) показал, что все же задержка отдачи страницы — меньше или равна 2 секундам.

Нам нужно было срочно это исправить: согласно исследованию Google, если пользователь ждет загрузки страницы 1–3 секунды, вероятность его ухода с нее возрастает до 32%.
Мы сделали сквозную трассировку в Elastic: посмотрели, как себя вели запросы с точки зрения всей системы в целом. Эта функция и помогла разобраться в проблеме — оказалось, что запрос из бэкенда проходил через внешний контур инфраструктуры. То есть, уходил в интернет, затем заново проходил через все слои: WAF, балансировщики, роутинг и т.д., что занимало много времени.
Бэкенд-часть нашего SSR-приложения и сервис, к которому шло обращение, находились в одной внутренней сети. Поэтому связь между ними можно и нужно организовать напрямую. Мы воспользовались Service Mesh для связи сервисов. После проведенной оптимизации проблему с загрузкой долгой страницы удалось устранить: значение P90 уменьшилось и составило меньше 0,5 секунды вместо 1 секунды.
Выводы
Выстраивая процесс мониторинга для сервиса, необходимо учитывать все уровни потенциального возникновения ошибок — от серверных до продуктовых. Для успешного и полного мониторинга вашего сервиса важно:
Определить ключевые метрики жизнеспособности и SLA, чтобы у вас было только необходимое количество данных.
Не усреднять значения метрик, использовать перцентили для полноты картины.
Настроить минимум уведомлений, добавить чуть больше информации в дашборде и оставить исчерпывающую картину в других сервисах мониторинга.
Это поможет точно не пропустить критические проблемы — или убедиться, что с вашим продуктом все в порядке и пользователь не испытывает трудностей при взаимодействии с ним.
Присоединяйся к команде Учи.ру, если хочешь развивать школьный EdTech вместе с нами!